2. Background
Many devices in the environment around us, such as electrical appliances, automotive elements, etc., are controlled by small computers or micro-controllers which interface with sensors/actuators through digital or analog inputs/outputs. There is currently a growing interest in interconnecting these small computers to increase their interoperability and control through internal or external networks. This is called the Internet of Things (IoT) [
1], which, in turn, is reinforcing the usage of these hardware platforms.
The specifications of these micro-computers (clock frequency, memory size, kind and number of peripheral devices such as timers, analog-to-digital converters (ADC), etc.) are set according to the number and type of input/output lines and the complexity of the algorithms running in them. In digital signal processing (DSP), most of the algorithms are based on the implementation of a finite number of sum-product operations that must be executed very quickly for real-time applications. The size of the data and its representation (floating or fixed) are also important for the accuracy of the results and must be taken into account in the selection of the hardware. For example, for audio processing, the data size should be equal to or greater than 16 bits with a sampling frequency of 44.1 kHz, (although some audio projects work at lower sampling frequencies, such as 32.25 kHz [
2]), which gives a time interval of 22.7
s to carry out all the processing in real time.
There are specific processors that speed up the execution of DSP algorithms by incorporating hardware such as 1-clock-cycle multipliers, barrel shifters, hardware loops, support for implementing circular buffering, multiple address and data buses to increase the bandwidth between the processor and the memory [
3].
Several vendors offer digital signal processors and development kits for audio and video signal processing applications. It is even possible to find cheap and non-proprietary hardware platforms, aka Open-Source Hardware (OSHW) [
4] or Libre Hardware that include these kinds of processors. In [
5], for example, there are three boards (freeDSP, PiDSP and nanoDSP), costing around 60 €, based on the Analog Devices (AD) SimgaDSP processor familiy and containing up to 2-input/4-output analog channels. Users can easily implement audio processing algorithms through the SigmaStudio
™ [
6], a proprietary computer software which can be downloaded for free. Another OSHW platform can be found in [
7], which is also based on the SigmaDSP processor’s family.
Libre Hardware is gaining significant traction in the scientific hardware community, where there is evidence that open development creates both technically superior and far less expensive scientific equipment than proprietary models, which have the option of manufacturing their own equipment [
8]. Libre Hardware businesses already benefit from potentially lower costs, but there are several other advantages. By avoiding intellectual properties based licensing models (e.g., involving patents, lawyers, legal fees, lawsuits, etc.), Libre Hardware firms have substantially reduced legal fees compared to more conventional businesses. It is shocking that, today, many firms spend more on legal fees than engineering. For example, both Apple and Google spend more on legal fees than R&D [
9].
Other popular OSHW platforms [
10], but non specific for signal processing, include Arduino [
11], RaspberryPi [
12] and BeagleBoard [
13]. RaspberryPi and BeagleBoard are based on ARM processors, while Arduino models are mainly based on Atmega processors. Some Arduino boards are also based on the ARM processor (e.g., Arduino Due). Arduino is better for beginners, for interfacing with external sensors or for battery powered applications [
14]. In an embedded market study about integrating IoT and Advanced Technology Design [
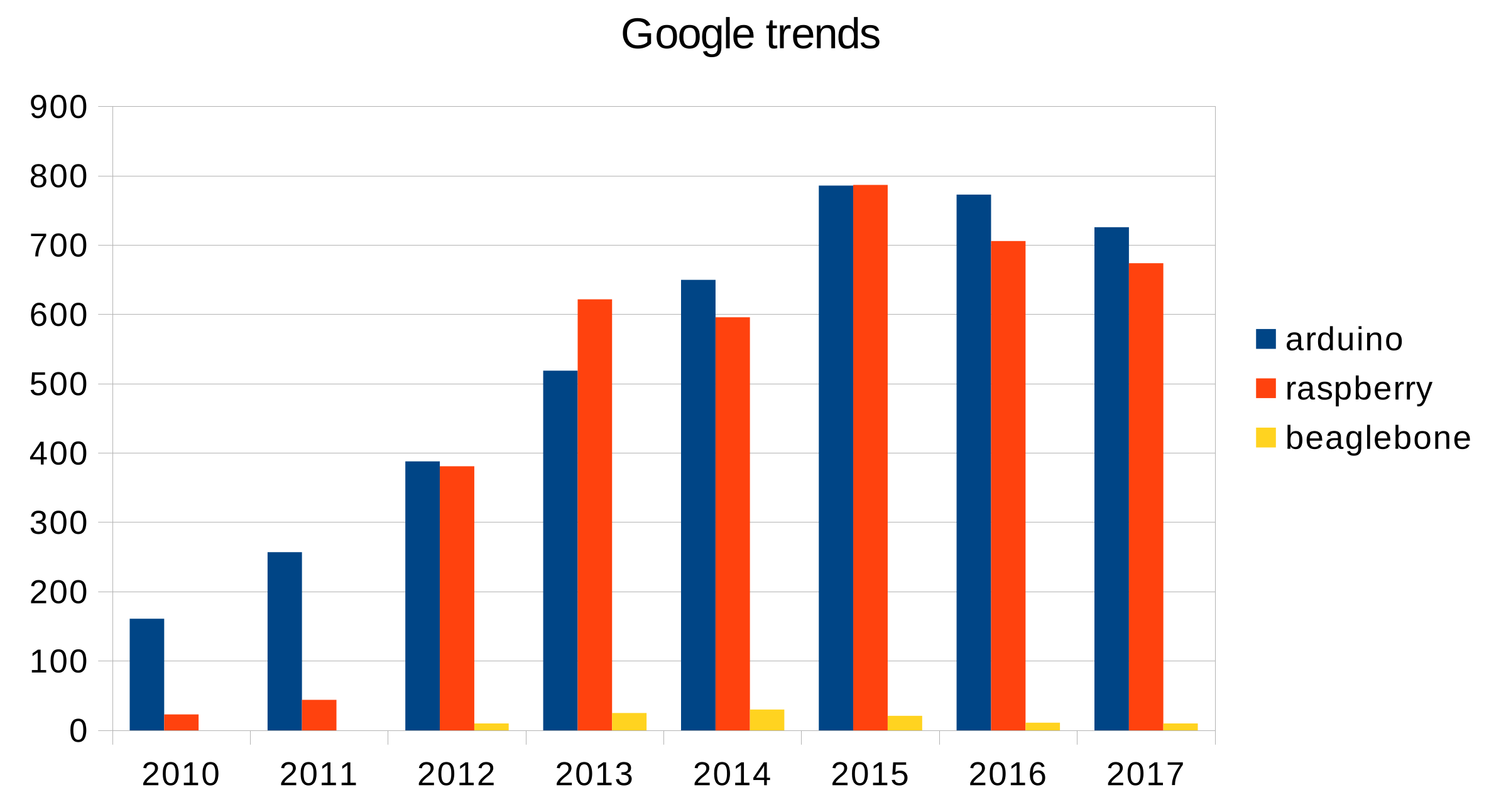
15], Arduino was the OSHW platform used most in current embedded designs (5.6%) or considered and being considered for use in the near future (17%), followed by Raspberry Pi (4.2% and 16%) and BeagleBone (3.4% and 10%). The interest in these boards is also supported by the searching trends in Google (
Figure 1), where Arduino boards show slightly higher results than Raspberry Pi.
These platforms have been positively included in the electrical and electronic engineering studies [
16] with a huge benefit to both curriculum and students. Students like the low cost of these devices and the ease of use that allows them to create significant projects, improve the system design and allow them to delve into real engineering systems motivated by their own creativity. Although there is no specific board for DSP in the Arduino family, one of the simplest ones (Arduino Uno), based on the 8-bit ATMega processor, has been used for teaching simple digital signal processing algorithms [
17]. According to [
18], Arduino platforms based on Atmega are not suitable for digital signal processing. However, they can work very well from an educational perspective because they allow more time to be spent on teaching fundamentals of DSP, and less on learning the integrated development environment, along with the support of a huge community [
19]. Some studies benefit from easiness of the Arduino IDE and the supporting community to interface with Arduino with a shield containing DC/DC converters [
20] or DSP processors for real-time digital signal processing [
21,
22,
23,
24].
Arduino boards have been used as single signal acquisition elements that deliver data to a computer where the digital signal algorithm is executed [
25,
26,
27] or as processing units as well. Arduino boards containing 32-bit processors, such as Due or Uno32 have been used for different real-time applications: audio [
28], finite or infinite impulsive impulse digital filters [
29], image compressing [
30] or for detecting R waves in electrocardiogram signals [
31]. Nevertheless, boards based on 8-bit processors have been successfully used in biomedical applications such as cardio monitoring [
32], online heart-rate detection [
33], amputee rehabilitation [
34], or for movement detection in people with disabilities based on the processing of signals delivered by accelerometers or flexometers [
35]. As such applications do not need to process a large amount of data, the time constraints for real-time processing are more relaxed than in audio or video applications. Hence, this lets us consider using these single platforms for real-time DSP applications. Even for tiny audio applications, these single boards have been successfully used to make stereo audio output and a vocal effect device running at a rate of 44.1 kHz [
36], some guitar effects [
37] including echo, reverberation, etc. or tremolo [
38] at a rate of 32.5 kHz. In [
39], a project involving Arduino Uno to make a sound card can be found. The author develops a shield containing a digital-analog converter (DAC), a memory, which temporally stores incoming data, and amplifiers to adapt the voltage level of an input microphone and an output speaker. The project includes a set of routines that perform several sound effects like pitch up/down, delays, etc. at a rate of 44.6 kHz.
Implementing digital filters is an important issue in DSP. There are some available libraries including very simple filters. In [
40], the filters are based on one- or two-pole analog designs for low/high pass filters. In [
41], a low pass filter (1st and 2nd order, Chebychev and Bessel) and median filter are implemented. To change cutoff frequencies, the code needs to be reconfigured. In [
29], the authors connect an Arduino Due to Matlab (Mathworks Inc., Natick, MA, USA) which sends up to 30 float-type coefficients for the implementation of the real-time filter. It has been shown that Arduino Due is suitable for audio application in real time although the developed program does not consider the samples to come at a fixed rate, which could affect the operation of the filter, especially when using infinite impulsive response (IIR) designs. In [
39], the author implements a low pass finite impulse response (FIR) filter and a notch filter based on Arduino 8-bit processors. Although the author shows how to build a digital filter, its implementation cannot be considered as in real time and a fixed rate of sampling is not guaranteed. In [
28,
42], the flow of data is guaranteed at a fixed rate and both implement FIR filters for audio applications. The former implemented a 32-tap FIR filter with an execution time of 32
s but based on an Arduino Uno32. The latter showed that the maximum length for a FIR filter in 8-bit-mono audio applications running at 31.25 kHz based on Arduino Uno was equal to 13.
Another important topic in DSP is frequency analysis, which is often done by applying the fast Fourier Transform (FFT). There is an Arduino library for computing the FFT algorithm [
43] using blocks of data ranging between 16 and 256 words (16 b). The execution time of the FFT for the smallest block is 120
s while for the largest one it is 7 ms. This means that, for an audio application running at a sample rate of 31.25 kHz (32
s), the FFT algorithm could be executed in real time because it takes 256 × 32
s ≈ 8.2 ms to fill a buffer with the incoming data and, then, compute the FFT. However, the memory requirements are very high because, according to the authors of the library, applying the FFT to a 256 word block of data requires 1 KB of memory, and to store the following block of data, while the FFT is computed, would need an additional 512 B of memory.For some simple Arduino models, like Arduino Uno, this means that 75% of the memory would be employed for the FFT computation for real-time processing in audio and there would be little memory left for the user application. Furthermore, while the FFT can be used for audio applications, this may be impractical due to the limitations of the block of data, which affects the frequency resolution
, where
is the sampling rate, and N the block size. For example, with a sampling frequency of 32.25 kHz and a block size of 256 samples, the frequency resolution is equal to 122 Hz, which might be insufficient for certain types of applications.
Storing chunks of data before applying the DSP algorithm is a good practice and is necessary in some cases. On the one hand, it is mandatory for certain type of algorithms such as FFT, correlation, etc., and, on the other hand, it gives more time for the algorithm to be executed, relaxing the time constraints [
28,
42].
In this work, we propose a software architecture comprising a set of classes that allows programmers to easily and quickly make applications that include some DSP topics in 8-bit Arduino platforms. The main reason for starting with 8-bit platforms is the information we obtained from Google trends. The latest 2017 information shows that the interest in Arduino Uno accounted for 91% of searches in Google compared to 8% for Arduino Due and Uno32 together. The software architecture comprises several levels that allow it to adapt to other hardware platforms.
This software is an evolution of a previous work [
35] where a five-layer software architecture for movement detection was proposed. That software contains low pass filters, guarantees sampling rate, includes a K-means algorithm and a finite state machine using software timers. Its main drawbacks are that the programmer needs to know the hardware, make use of low-level programming and that the software elements were not encapsulated, which, in turn, means that, for example, if two filters are needed, the code has to be repeated twice.
The DSP topics will include the capacity to process chunks of data or execute the algorithm sample by sample, guaranteeing a fixed sampling rate and offering FIR or IIR filters and frequency analysis based on FFT or Goertzel algorithm [
44].
3. Software Architecture
One of the main goals of this work is to develop a software architecture wherein several processes, such as data acquisition, DSP algorithms and the user program can be independently executed as they receive data. To accomplish this, we propose structuring the software like a pipeline containing the processes in different layers. By segregating an application into layers, developers can modify or add a specific layer, creating flexible and reusable code, instead of having to rework the entire application. Several studies have included this multilayer architecture in their designs [
35,
45].
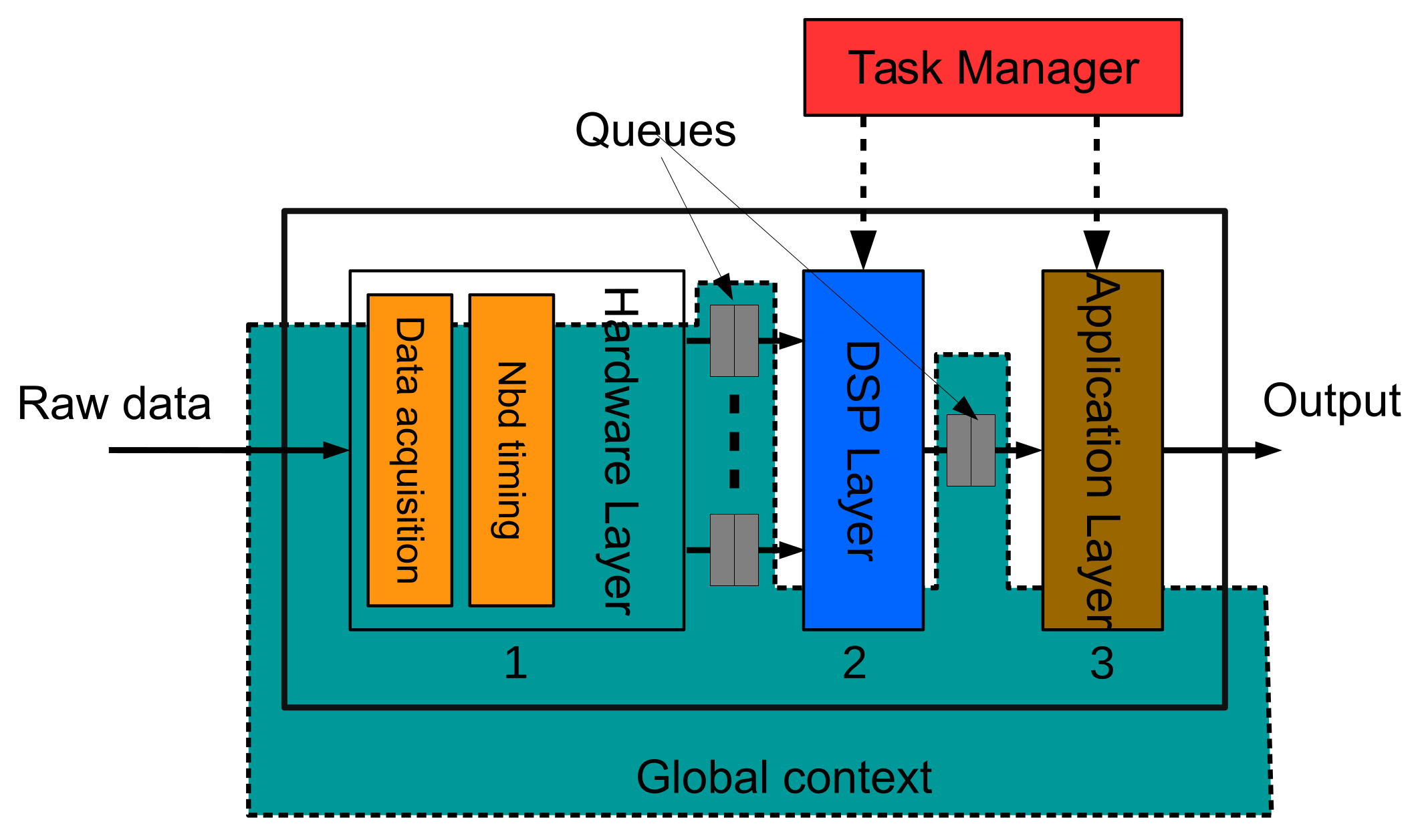
To start with,
Figure 2 shows a simple pipeline with three layers: hardware, DSP, and application. The pipeline shown is the example that we will follow in this paper to simplify explanations. There is a queue between two layers, storing data until the following data is able to read it. The hardware layer is the ‘heart’ of the pipeline. It contains a synchronous process that periodically samples the channels of the analog to digital converter (ADC) and dispatches the data to the following layer (DSP layer in our example) at a fixed rate through a set of queues. Each one of these queues, at this level, is associated with an ADC channel. The number of analog inputs or, in other words, the number of sensors that can be connected to the platform is limited by the hardware itself.
Another synchronous process in the hardware layer is in charge of updating the software timers that support the use of non-blocking delays as we will explain in detail later on in
Section 3.1.2. The rest of the processes contained in DSP and application layers are sequentially executed by the Task Manager. The programmer decides the order of execution of each one. Processes in DSP and application layers are executed when the layer input queue contains new data or a timer object has expired. Following the guidelines of this software architecture, developers will be able to build more sophisticated pipelines including branches to parallel and longer lines.
The DSP layer contains a set of classes that allows programmers to implement typical digital signal processes like filters, basic frequency analysis and data segmentation (
Section 3.2). The last layer, or the application layer, contains the end-user processes. Programmers should ensure they develop software that does not block the pipeline, assigns queue size appropriately to prevent data loss and allows the task manager to execute all the layers in less execution time than the time taken to process a block of samples. The usage of delay functions, long loops, etc. should be carefully considered in each layer. Finally, the architecture defines a global area containing the objects (queues, global variables, timers, etc.) that all processes share.
Algorithm 1 summarizes how to build the single three-layer pipeline. The hardware layer is not included because it is a periodic process performed by an interruption mechanism and it will be explained in the following section.
| Algorithm 1: Pseudocode for implementing the proposed three-layer architecture in the example shown in Figure 2. |
![Sensors 18 01033 i001]() |
3.1. Hardware Layer
The hardware layer, HL, guarantees that samples are acquired at a fixed rate and supports the non-blocking delays (NBD). This layer acts as the ‘motor’ of the pipeline, periodically dispatching samples towards the following layer.
Two synchronous processes coexist in this layer: the data acquisition and the non-blocking timing processes.
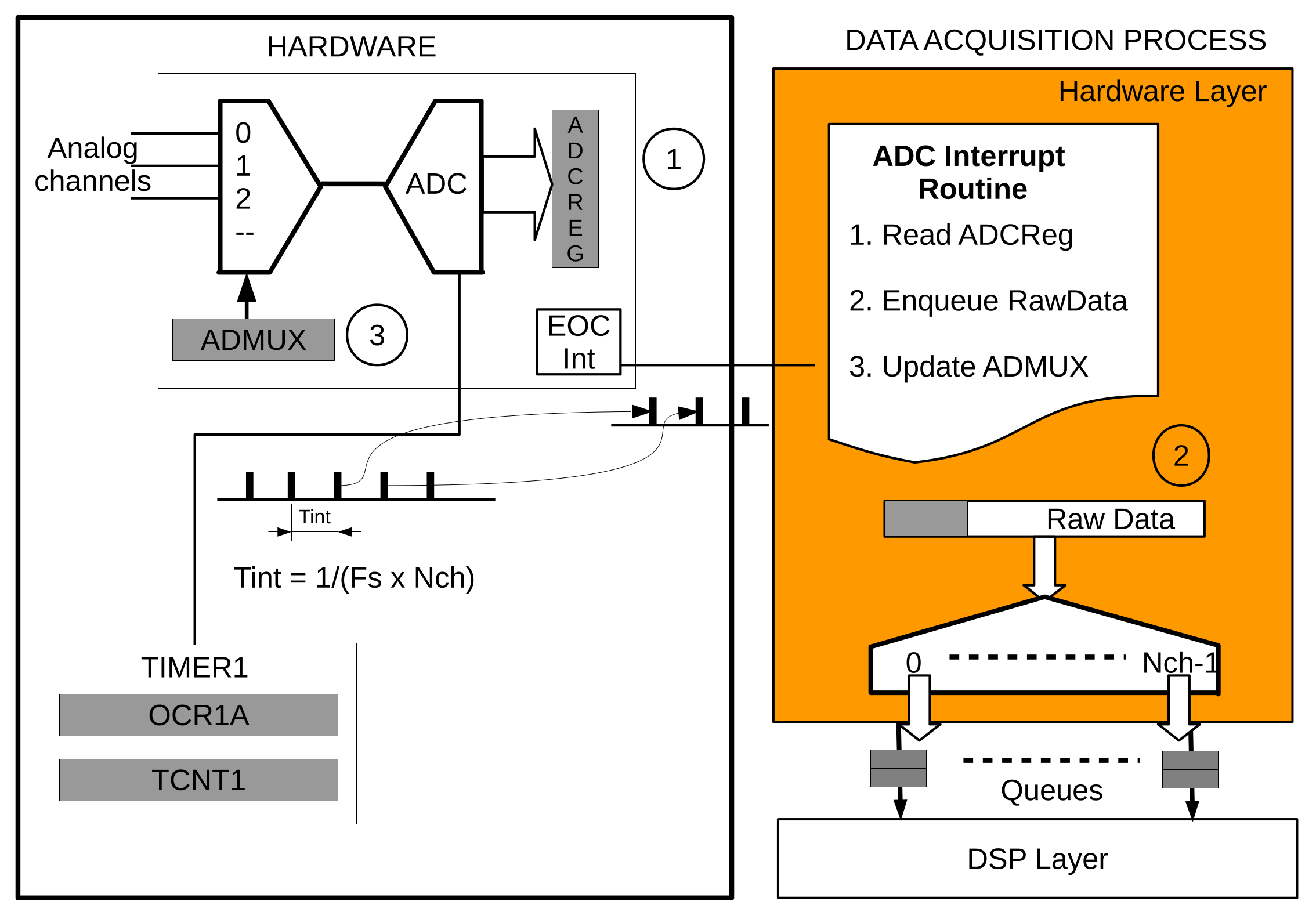
3.1.1. The Data Acquisition Process
The processor’s Timer1 is configured to trigger the ADC at a rate equal to
, where
is the sampling rate and
the number of channels. The End-of-Conversion (EOC) interrupt is executed when new data is available in the ADC. The interrupt subroutine reads the ADC, sends it to the following layer through the queue associated with the channel and selects the ADC channel for the following conversion.
Figure 3 graphically depicts the processes involved in the data acquisition.
According to the manufacturer, the sampling rate at maximum resolution (10 b) is 15 kHz. Higher sampling rates are also possible, but with a reduced 8-bit resolution. In this work, only the maximum resolution scenario has been considered for the design of the library.
Another timer, Timer0, is configured to support the use of non-blocking delays, which, as happens with typical delay functions, wait for an established amount of time, but without blocking the execution of instructions or stopping the data flow in the pipeline. The timer class implements the non-blocking delays, and the
class creates a list of pointers to timer objects. Timer0 makes interrupts to periodically access the list of timer pointers and decrease all the timer objects (see
Section 3.3 for more details).
Additionally, this layer contains a set of routines to configure the micro-controller timers and the analog-to-digital converter. Programmers can configure the sampling rate and the number of channels used in this layer by changing certain variables in the code. Data is then automatically sent to the HL queues and are ready to be read by the next layer.
To create a Hardware Layer object, programmers only have to include two lines in their code: lines 2 and 6 shown in Algorithm 1.
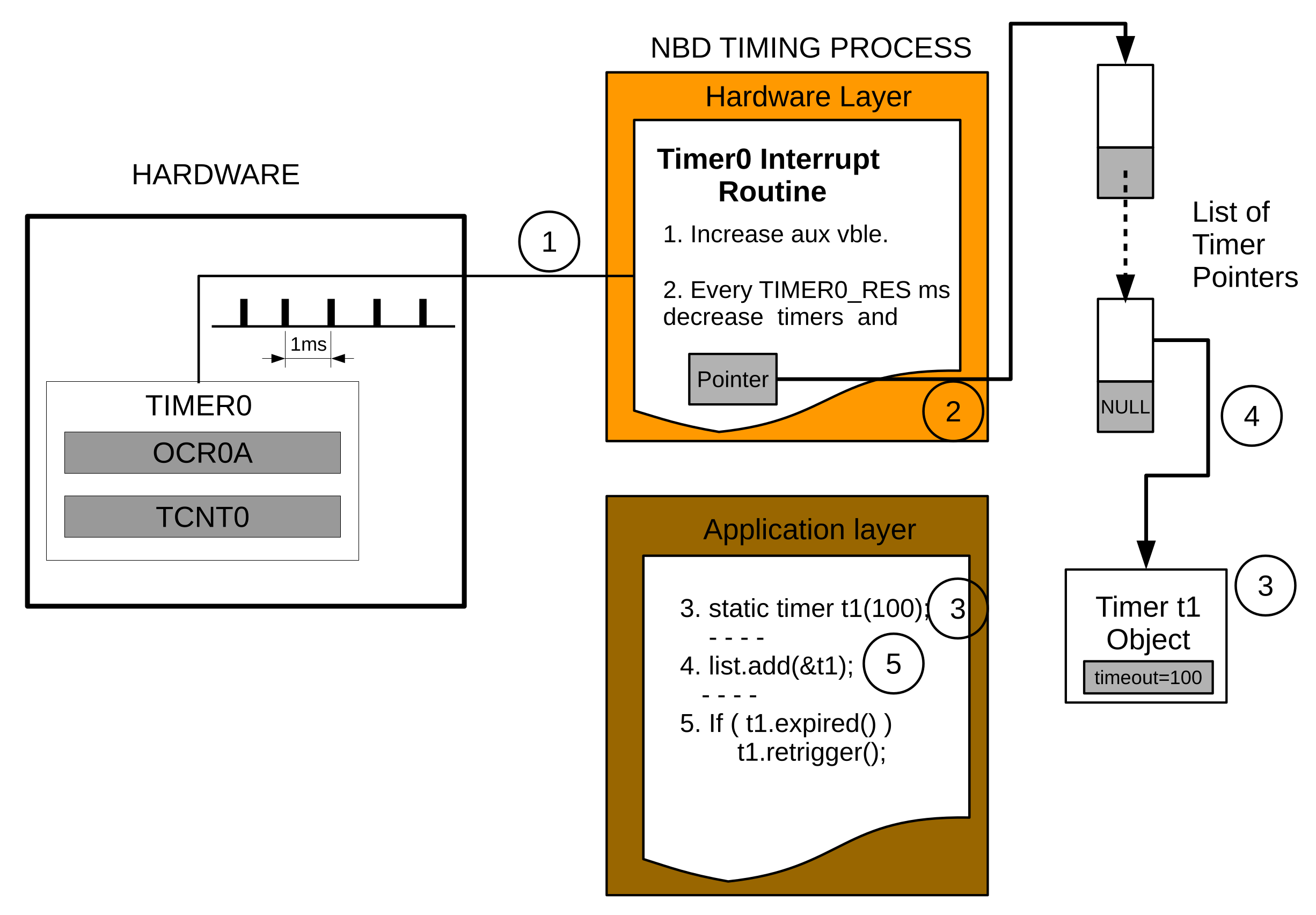
3.1.2. The NBD Timing Process
Delays are often used to make the processor wait for a timer to expire, as, for example, in the implementation of finite state machines. So as not to block the pipeline using traditional delays and prevent data from being lost, this software includes non-blocking delays. Two classes have been added to accomplish this goal.
The class timer includes two variables: timeout, which contains the actual timer value and timeout initial, which stores the initial value in case the timer object is restarted again. Several methods allow the timer to decrease, view its content, retrigger it or signal when the timeout has expired (timeout equal to zero). The timer class itself can be used as a counter/timer according to the rate of the process calling the decrease method. For example, if a timer interrupt periodically calls such a method, the timer class would be operating as a timer, otherwise it would work as a descent counter.
The Timer0 interrupt routine is called every 1 ms. Every TIMER0_RES seconds (the default Timer0 resolution is 10 ms) the routine searches for all installed timers in order to decrease them.
Figure 4 depicts this procedure and Algorithm 2 contains a reduced code explaining how to use them.
| Algorithm 2: Pseudocode explaining how to use non-blocking delays. |
![Sensors 18 01033 i002]() |
3.2. DSP Layer
If needed, this layer contains a set of basic digital signal processing applications for filtering and frequency analysis.
3.2.1. Filter Class
This class allows programmers to implement digital filters [
46] with p+1 and q+1 coefficients in the causal and anti-causal part of Equation (
1), respectively:
The class has the following methods:
assign, which allocates a buffer in memory with
words to store the current and the
past inputs/outputs; the
reset method empties the whole buffer and initializes the pointers; the
view method provides access to the content of the buffer; and, finally, the
assess method introduces the input data in the buffer using the modulo addressing technique [
3] to reduce the execution time and evaluate the output of the filter.
The coefficients of the filter are given using the Q15 format [
47], which ranges from roughly −1.0 up to 1.0. Q format numbers that are notionally fixed point numbers, that is, they are stored and operated upon as regular binary signed integers, thus allowing standard integer hardware/ALU to perform rational number calculations.
Computation of Equation (
1) is performed using long words (32 b) to avoid overflows; then, the result is cast to an integer using the banker’s rounding that returns the even result if there are two nearest integers. This is good practice for IIR filters, which are very sensitive to rounding errors. Algoritm 3 shows an example using the filter class to implement a Butterworth low pass filter.
| Algorithm 3: Simple example illustrating how to use the filter class. |
![Sensors 18 01033 i003]() |
3.2.2. Polyphasic Filter Class
This class implements a p-tap FIR polyphasic filter in decimation [
48] that outputs results at a rate of
(Equation (
2). It is based on the filter class and its methods are fairly similar:
assign and
assess. The
assign method allocates a buffer in memory with
words and initializes the object and the
assess receives data and outputs a result when available depending on the decimation factor:
Algorithm 4 shows a segment of pseudocode illustrating how to include a polyphasic filter in a program.
| Algorithm 4: Programming example illustrating the usage of pfilter class. |
![Sensors 18 01033 i004]() |
3.2.3. Goertzel Class
Spectrum analysis is a very essential requirement in instrumentation and normally carried out by online or offline FFT processing. The Goertzel algorithm [
48] is a digital signal processing (DSP) technique for identifying frequency components of a signal. While the general Fast Fourier transform (FFT) algorithm computes evenly across the bandwidth of the incoming signal, the Goertzel algorithm looks for a specific or predetermined frequency:
The first stage of the algorithm is based on the implementation the IIR filter given in Equation (
3) where
is the frequency to be analyzed. The output
is iterated
N times. In the last iteration,
is set to 0. Then, power,
P, is obtained by applying the Equation (
4):
Goertzel’s class has two methods: the
constructor, which receives the
and
N as input arguments and sets the filter given by Equation (
3) and
power method, which receives a new data (
), performs an iteration and computes Equation (
4) in Q-format as the number of iterations equals
N. Algorithm 5 shows a programming example illustrating the usage of the Goertzel class.
| Algorithm 5: Programming example illustrating how to use the Goertzel class. |
![Sensors 18 01033 i005]() |
3.2.4. Sliding Windows
In digital signal processing it is very common to collect a certain number of samples before applying a specific algorithm (FFT, auto-correlation, etc.). In real-time applications, samples are stored in a buffer and, when this is full, the algorithm to process it is called. This procedure is repeated continuously, collecting new blocks of data, which may, or may not, contain or share part of the samples of the previous blocks.
The technique of collecting blocks of data is known as sliding windows, where the two key parameters are: the number of data stored in a block, or length of the buffer (L), and the displacement or hop size (H), which represents the number of new samples that substitute the oldest ones. This technique reduces the time constraints for the DSP algorithm since it allows them to be executed in a time equal to which may be higher than the constrains for a digital filter ().
Two classes have been developed to support the segmentation of incoming data in real time. The first one is the segmentation class, which has four main methods: add, which adds new data into the buffer, using the technique of circular buffering; ready, that returns 1 if the buffer is full or 0 otherwise; access, which enables access to an indexed element of the buffer; and advance, which makes it possible to empty the oldest H samples stored in the buffer.
The second class is block, which inherits from the segmentation class and is almost empty. Only a method to estimate the energy of a block of data has been provided. In this class, the programmer must write the algorithms that process the block of data.
To prevent data loss, the queue, which temporally stores samples from the hardware layer, must be correctly dimensioned. For example, if an algorithm took less than to execute, the displacement of the sliding windows and the size of the queue supplying data should be greater or equal to H samples. Algorithm 6 shows how to use the block class to obtain the energy of a block of 10 samples with a displacement of four samples.
| Algorithm 6: Programming example illustrating how to use the block class. |
![Sensors 18 01033 i006]() |
3.3. Application Layer
This layer hosts the set of functions that make the end-application. The programmer can split up this layer in others, if necessary, following the procedure proposed in this architecture. This is to include queues between adjacent layers and add the new functions in the Task_Manager. It is important that the execution does not stay in a single function for too long. For this reason, the use of long loops and delays must be carefully considered.
3.4. SWOT Analysis
To highlight the positive/negative aspects of the software architecture, a Strengths-Weaknesses-Oportunities-Threats (SWOT) analysis has been performed (
Table 1). This kind of analysis allows for maximizing the strengths, taking advantage of their opportunities and overcoming their weaknesses [
49]. The main weakness and threat of the software is the dependency it shows on the hardware platform until now. Nevertheless, having released the code under an open-source license and structuring it in several layers will allow programmers to develop new hardware layers for other platforms, besides increasing the functionality of the whole software.
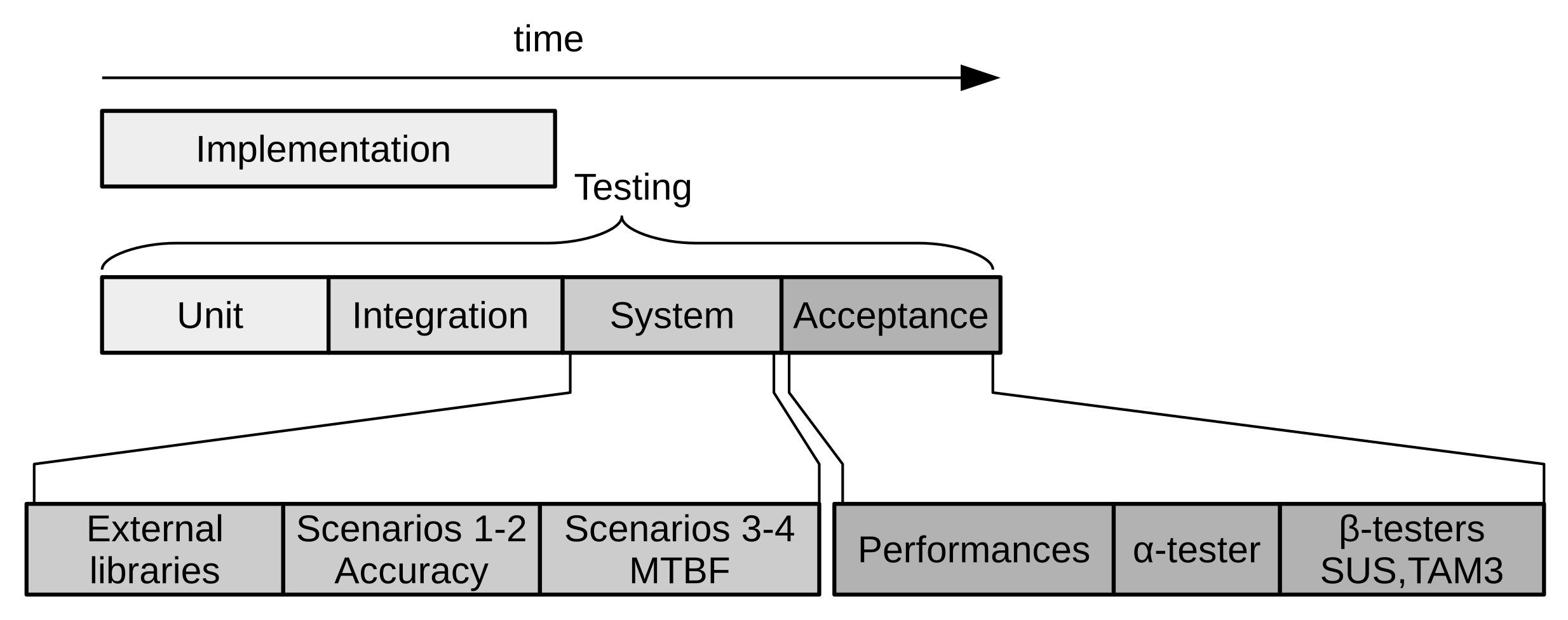
5. Results
This section shows the results obtained after applying the methodology described above.
Section 5.1 contains the measurements of the failure and correctness/accuracy tests, while
Section 5.2,
Section 5.3 and
Section 5.4 include the performances, usability and TAM3 tests, respectively.
5.1. System Test Results
In this test, the correct operation of the whole software was checked.
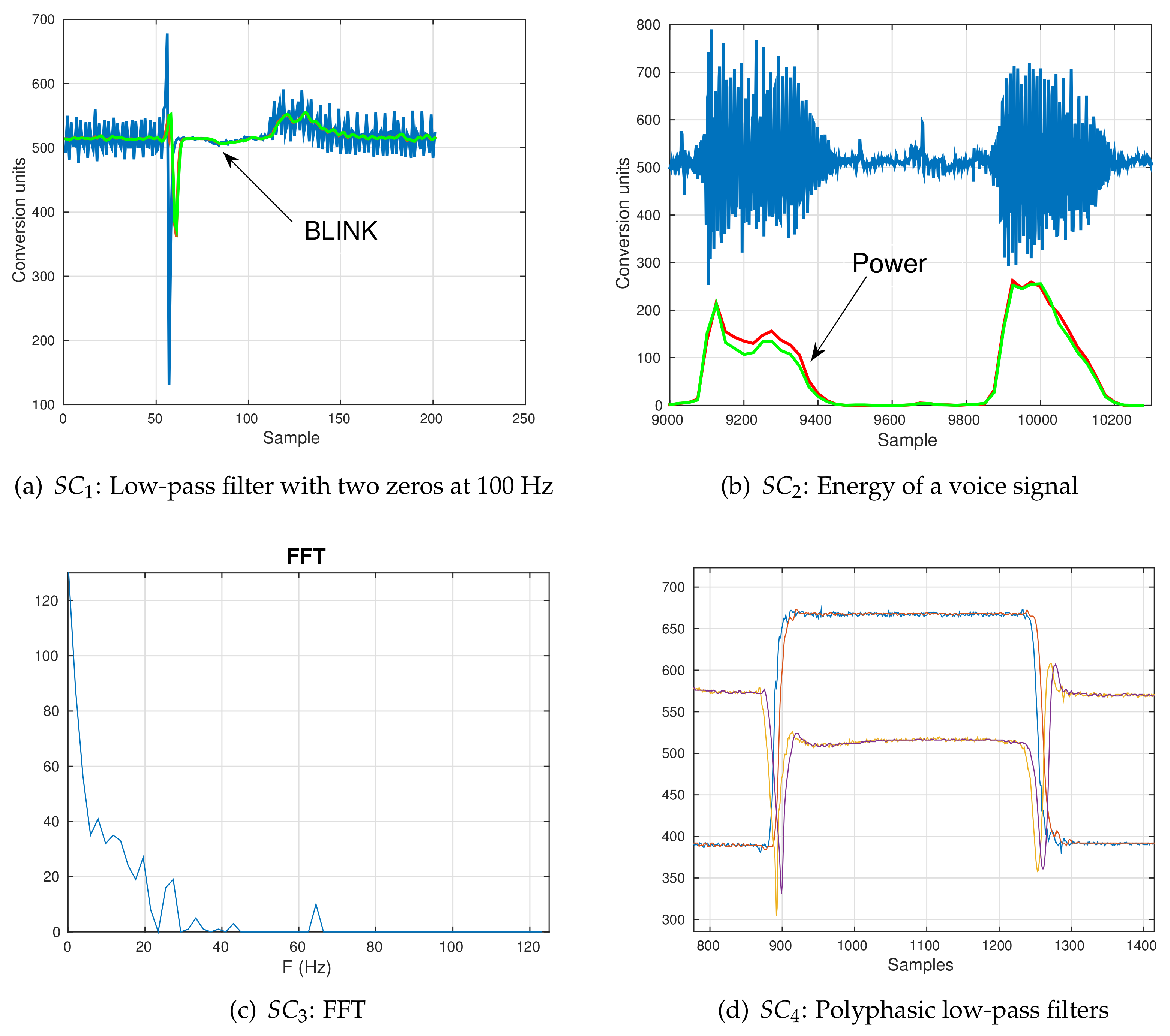
Figure 6 shows some output segments obtained in the proposed testing scenarios.
Figure 6a shows a noisy signal coming from an infrared (IR) LED mounted on glasses worn by subjects to detect blinks or winks (
). The output of the filter running in the hardware is plotted in red and the one obtained in Octave in green. The Pearson correlation coefficient was equal to 0.982.
The output results and the voice signal from scenario
are shown in
Figure 6b. The power signals were scaled by 50 in order to include the voice signal in the same plot. The Octave result is shown in green while the library output is shown in red. Both signals are almost identical, with a Pearson correlation coefficient of 0.971.
Figure 6c shows the FFT of a signal by including the FFT library configured to send 64 frequency bins of a signal sampled at 250 Hz (Scenario
). There were no errors, so
.
In
Figure 6d, two polyphasic 50-tap low-pass filters with a decimation factor of 4 were applied to smooth the data coming from a two-axis accelerometer. The delay can be seen between the smoothed filter outputs and the input raw signals due to the length of the digital filter. This experiment was run for 8 h and there were no errors, which means that the
.
All of these examples show that the software worked properly in different situations, sampling rates and when several channels were simultaneously being acquired.
5.2. Acceptance Test Results: Performances
In this section, we analyze the performances of the set of classes included in the software architecture using as metric the memory size in bytes and the number of clock cycles for their execution.
Table 5 summarizes the results.
5.2.1. Hardware Layer
The hardware layer contains a set of configuration functions (for timers 0,1 and ADC) and interrupt routines to support the non-blocking delays and the data acquisition. Configuration functions are only called once at the beginning, when the computer is turned on, so the time they take in executing is unimportant. However, Timer0 interrupt is called every 1 ms and Timer1 and ADC interrupts are called periodically depending on the established sampling rate. Therefore, it might be interesting, for the developing of real-time application, to find out how long those routines take to execute. This includes the number of cycles in executing the Timer0 interrupt when there are no active non-blocking delays, updating the Timer1 and ADC registers, reading the 2-byte data and pushing it into the specific channel queue (see
Figure 3).
The number of cycles is roughly constant for the interrupt routines, although there is variable dependency on the depth of channel queue,
(Equation (
6)). When the pointers used to manage the data stored in such queues reach the ending address of the memory assigned to them, they need to be updated to the initial memory address. This operation spends some additional clock cycles. Therefore, the worst scenario would happen when the queue depth is equal to 1. Then, pointers must be updated every time new data is placed in the queue. As the queue depth increases, the number of clock cycles to execute this layer decreases on average according to the following relationship:
The maximum number of cycles,
, is 97 for
.
The size of the program memory (PM) to allocate Hardware Layer routines is
= 1934 B or, approximately, 6% of the whole PM. The size of data memory (DM) is variable and depends on how many channels,
, have been configured for acquisition Equation (
7). As each channel needs its own queue, and the queue class also needs some memory to allocate their pointers and internal variables, the total data memory size is given by the following relationship:
In the equation above, the leftmost placed constant represents the size of the variables used in interrupt routines. The number 24 is associated with the internal variables in the queue class, and the term
the memory allocated to store the integer-size data in the queue.
5.2.2. Filter Classes
In this section, we analyze the performances of three filter classes, which are implemented based on the first of them.
Filter Class
The two most important methods of filter class are those that allow programmers to assign coefficients (
in Equation (
1)) and assess filter output. The former is called once, during the booting-up, and it will not be considered in our analysis. The latter is called every time new data is available and knowing the execution time is important in real-time applications.
As seen in
Section 3.2.1, the length of the filter, (
), depends on the number of coefficients it has in the causal part (
coefficients) and anti-causal part (
) of Equation (
1). We have analyzed the number of clock cycles used by the assess method of the filter class for different filter lengths (from 15 up to 254). We have not tested longer filter lengths because the class limits the size of causal/anti-causal part in order not to exceed 255 different coefficient (
) due to the reduced data memory size in Arduino Genuino boards. Up to 10 repetitions of each tested filter length were carried out. In each repetition, the coefficients were randomly generated to obtain the
and
(Equation (
8)), and the input sequence was also randomly generated. Our results show that a linear relationship exists between the number of cycles and the filter length (
):
There was a small difference between the
and the average
less than five clock cycles. The filter class requires 996 B of the PM and a space in DM given by the following relationship (Equation (
9)):
The independent term is related to the internal variables used by the class. The remainder is employed to store the input/output terms (
,
) that appears in Equation (
1)).
Filter class also needs p + q + 2 coefficient as was said above, but the filter class does not store them internally. It has two pointers to a matrix containing such coefficients. Therefore, the memory used to store them is not part of the class, although it must be taken into account when computing the global resources of the whole software application.
Polyphasic Filter Class
The polyphasic filter class implements an FIR filter, based on building an array of D filter classes, where D is the decimation factor. This class also contains two main methods: assign and assess. Only the execution time of the assess method is taken into account in this study. When the assess method is called with new input data, the computation only takes part in one of the D filter classes. Every D input data, the filter output is returned. This means that the computation time of the polyphasic filter should be similar to the filter class but scaled by a factor of 1/D.
The length of the polyphasic filter is
, which corresponds to the causal part of Equation (
1), and is bound to an upper limit of 255 terms. Experimentally, we have tested different filter lengths ranging from 16 up to 64, and a decimation factor ranging from 1 up to 32 at a power of 2. The coefficients and the inputs are randomly generated, following the same procedure as described above. The linear regression is then applied, which gave us the following relationship (Equation (
10)):
As the decimation factor increases, the number of clock cycles decreases. The above equation is correct as the length of the filter is greater than the decimation factor (); otherwise, the number of clock cycles would reach a constant value that is not affected by the decimation magnitude. This relationship is fairly similar to the one obtained in the analysis of the filter class.
The room in the PM to allocate the polyphasic filter code is of 626 B plus an additional 996 B in case the filter class has not been previously loaded in memory. The DM size depends on the filter length and decimation according to the Equation (
11), where function
returns the upper integer of the input argument:
Goertzel Class
The Goertzel algoritm uses the filter class to evaluate the output of an IIR filter given by Equation (
3), which is tuned to the frequency to be detected. For
N iterations, the Goertzel class only assesses the output of the IIR filter, and then the power is obtained by applying Equation (
4). The
power method performs these two operations (filter output assessment and energy calculation) spending a number of clock cycles given by Equation (
12):
To obtain the equation above, we followed the same criteria as in previous experiments: the signal supplied was randomly generated and the experiment was repeated 10 times. The worst scenario happens when ; then, the number of cycles is .
The Goertzel class only needs 55 bytes of PM (and an additional 996 bytes in case the filter class has not been previously loaded in the memory). The data memory size is constant here and equals 62 B.
5.2.3. Block Class
The block class has two methods for adding data to a window and knowing if a window has been filled and is ready for being processed. Both methods take between 10 and 68 cycles to be executed. The method that consumes more clock cycles is the energy, which, in turn, depends on the length of the window,
L, according to the Equation (
13):
The PM size for this class is 390 B and DM size depends on the window length as well (Equation (
14)):
5.2.4. Non-Blocking Delays
Non-blocking delays use the Timer0 interrupt routine, the timer_list and timer classes. The number of clock cycles depends on two factors: the TIMER0_RES, or
for short, which is set at 10 by default (that means 10 ms) and the number of timers,
. Every time the interrupt routine is called, an internal counter is compared to the preset resolution,
. In case of equality, the timers in the list are updated. The number of cycles employed to perform such periodic operations is five for the interrupt routine plus
for to update the timers. As timers are only updated once in
times, the average number of cycles is given by Equation (
15):
For example, at the default Timer0 resolution, . In the worst case, when the timer resolution is 1, the number of clock cycles is . Additionally, using the results derived from the analysis of the number of clock cycles, we obtained the timers’ accuracy, which gave us a deviation value of less than 4 s.
With respect to the memory resources, the non-blocking delays require 148 B of PM and B of DM.
5.3. Acceptance Tests Results: SUS and General Assessment
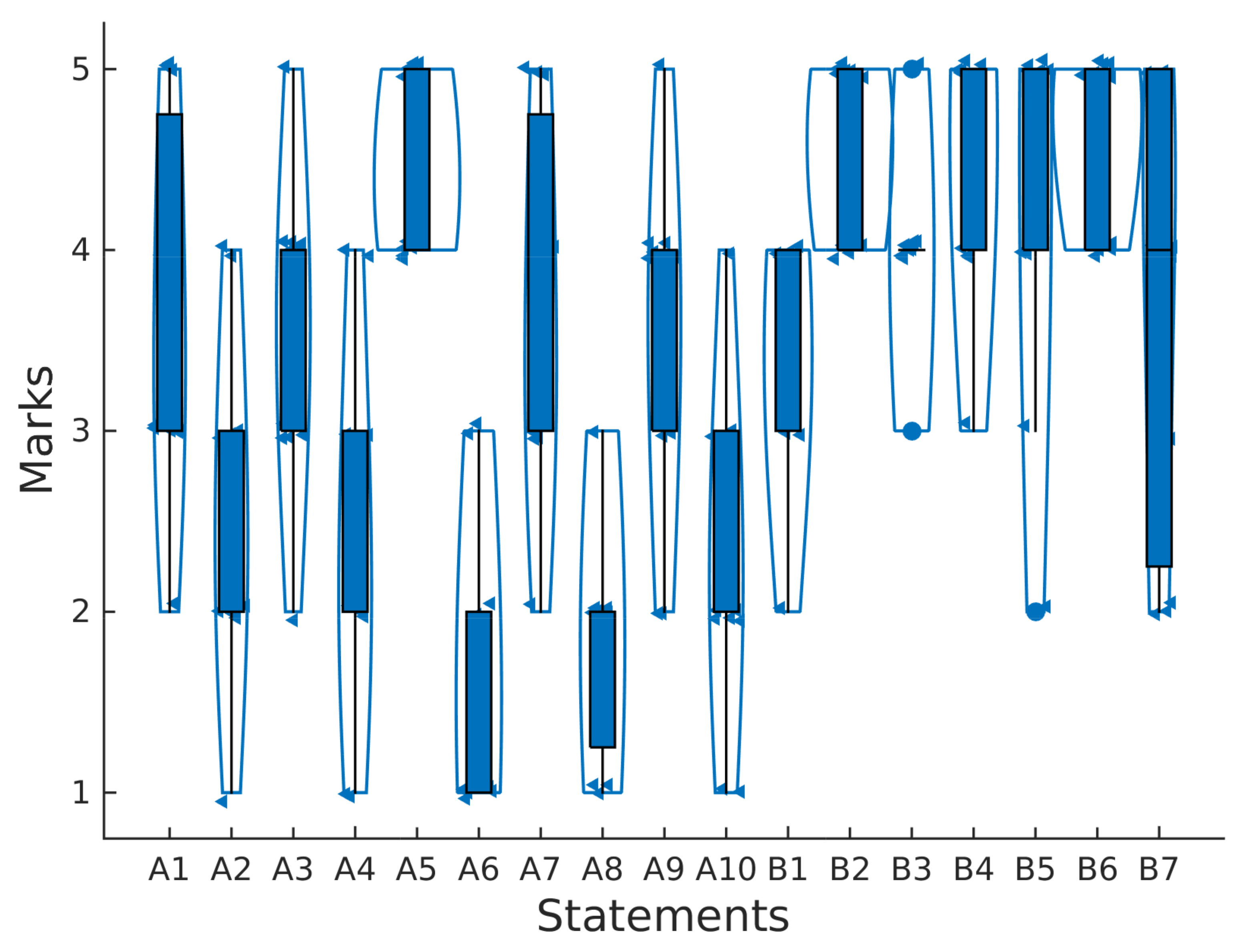
Data collected in the usability test have been processed with Matlab as follows. Firstly, we have represented the descriptive statistics of the answers to questions shown in
Table A1 and
Table A2 for the SUS statements and for our specific library (
Figure 7). In this figure, we can see violin diagrams containing all the data (small triangles), box plots and outliers (solid dots).
In general, even answers (A2, A4, ..., A10) have less marks than odd ones (A1, A2, ..., A9) as expected in good usability tests. Namely, the average SUS score for all participants was 70.2 out of 100, which means that the product is “almost good”. For participants S2, S3, the product was “excellent”, “good” for S4, S10, S11 and “ok” for the remainder.
The implementation of the proposed filters or the sliding window to obtain the energy was very easy for the participants, getting an average score of 4.6 4.4 and 4.6 for statements B4, B5 and B6, respectively. However, the implementation of non-blocking delays was more difficult, obtaining an average score of 3.7 out of 5 with higher variability among subjects, as can be seen in
Figure 7.
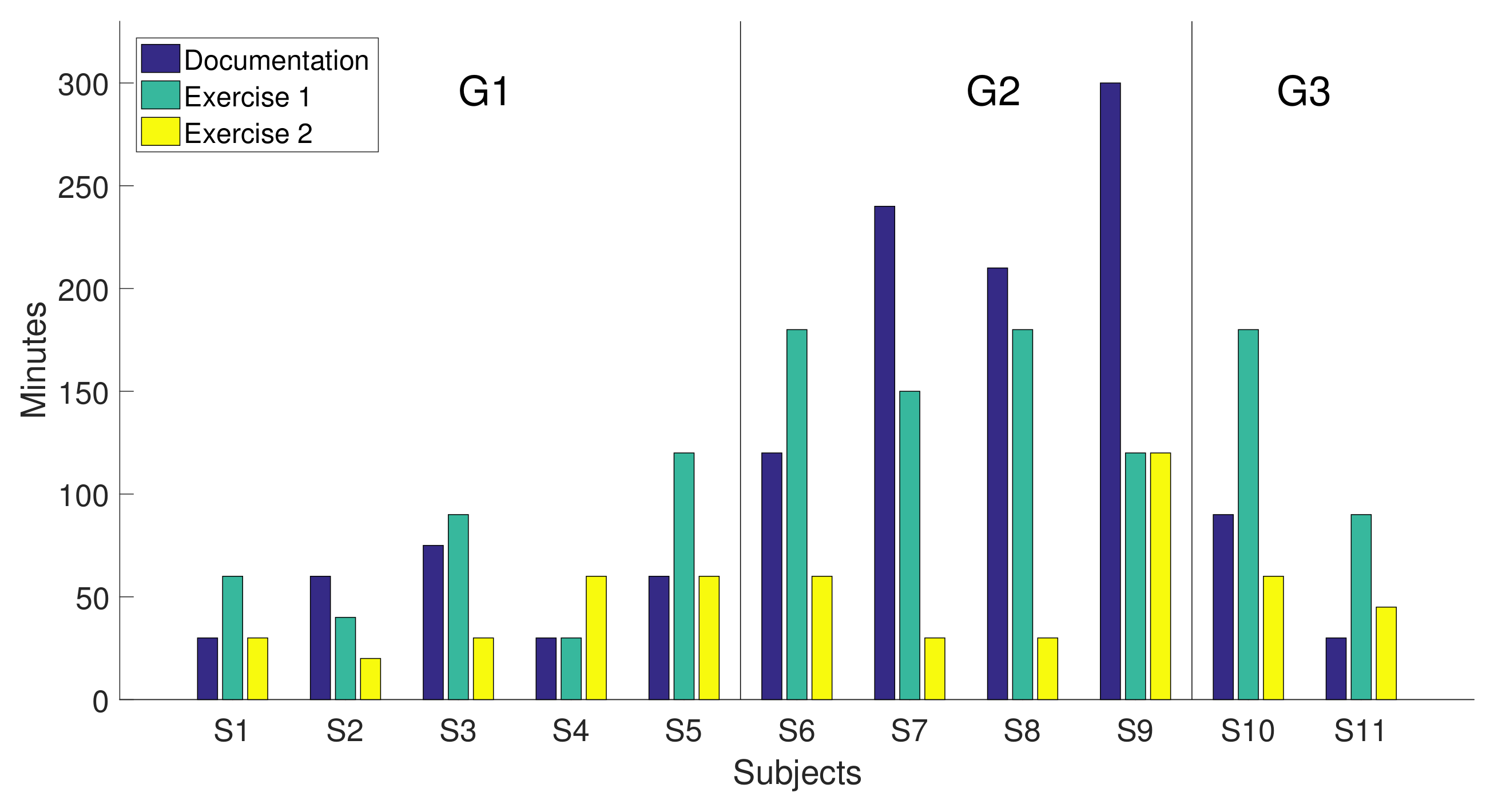
Figure 8 shows the time spent by each of the subjects on the different parts of the experiment: the study of the documentation and the realization of the two programming exercises, each one represented with a bar. The order of the subjects on the
x-axis is chosen according to groups shown in
Table 4.
According to statements B1 and B3, the perception that the time spent to accomplish the exercises was ‘ok’ (4 on average) although it took longer to understand the documentation (3.4). In general, participants felt they could finish the programming exercise without external support (4.6).
To the question “Write a general assessment of the software”, the most common perception was that the software was easy and intuitive to use. About the documentation, they said it was well structured but that it could be improved by providing more examples.
For the last question “Suggestions for future improvements”, the subjects would like to have a more detailed explanation about the non-delay timers. Some of them proposed this software for other programming environments like Matlab or Octave as well as other platforms (like the ones based on ARM processors).
5.4. Acceptance Tests Results: TAM3
This analysis allows us to figure out the determinants that may, or not, influence the behavioral intention to adopt this new software. We excluded subjects belonging to group G2 from the analysis because: (a) they are undergraduate and not still integrated in a business or departmental environment; (b) the use/implantation of this software is being promoted in a university department, where it is more likely that people related to it can see the benefits or drawbacks of its use.
Subjects S5 and S11 did not fill in this survey, so the population under testing was reduced down to only five people, which limits the significance of the results.
Table 6 shows the averages and standard deviations for all participants, and the Spearman coefficients between any two parameters, including its statistical significance.
As it can be seen, the Behavioral Intention (BI) obtained an average of 6.3 in a scale ranging from 1 to 7. It shows statistical dependency (, p < 0.05) on Perceived Usefulness (PU) and Perceived Ease of Use (PEOU) (, p < 0.05). This means that the intention to adopt this technology is mainly due to the fact that it is perceived as easy to use (PEOU = 5.55 in average) and useful (PU = 6.45) in general. Additionally, people perceived that the system is useful in part because the software is easy of use (, p < 0.01).
6. Discussion
Filtering and frequency analysis are two important aspects in digital signal processing. The proposed software includes classes for both topics, allowing programmers to easily set up applications that might need to incorporate them.
6.1. Filtering
The and parameters, explained in the previous section, provide valuable information that tells us to what kind of real-time applications the classes can be employed in when using an OSHW architecture like Arduino Genuino.
The filter class should be able to make a new output in less time than the period of time between samples. In other words, the number of cycles available,
for this algorithm to compute a new output must be equal to
, where
is the clock frequency minus the number of cycles for the hardware class to acquire new data
(Equation (
16)):
Therefore, the
and
parameters for the filter class must be less than the
and the whole size of the data memory. The maximum length of the filter must satisfy both of these conditions.
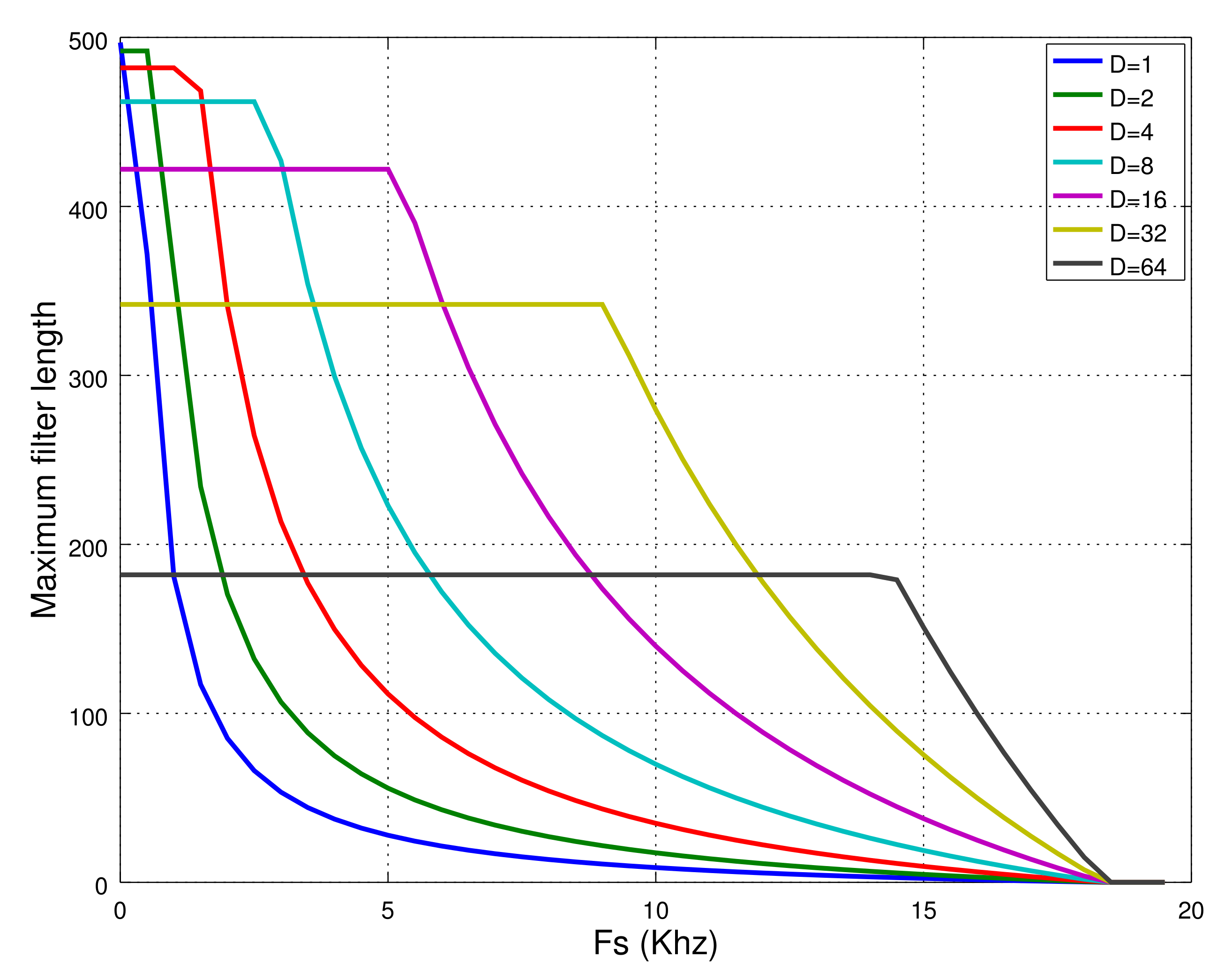
Figure 9 shows the maximum length as a function of sampling rate and decimation factor when using only one analog channel.
The filter class limits the number of coefficients up to 256. This is because the coefficients and the data have been indexed by byte-size variables. By simply replacing them with integer-type variables, the length of the filter can be increased up to 64 k. In the discussion, we have preferred not to consider these library internal constraints and find out the computational limits of the class according to the memory usage and computation time. Therefor, such limits set a maximum filter length of 497 coefficients when using a sampling rate of 1 Hz, or 182 coefficients for a polyphasic filter with a decimation factor of 64 at a sampling rate of 14 kHz. As the decimation factor increases, so do the memory resources, which limits the length of the polyphasic filter as can be seen in
Figure 9 for the lower sampling rate.
Figure 9 also shows that the maximum sampling rate for these classes when running in Arduino Genuino is theoretically set at 18.5 kHz. This rules out the possibility of using the filter class in Arduino for real-time audio applications. In fact, as explained in
Section 3, we decided not to apply this software for audio applications in order to avoid reducing the resolution of the ADC. The Arduino Genuino platform limits the maximum sampling rate at 15 kHz for the maximum resolution of 10 bits. This fact forced us to use the integer size (16 bits) in the filter class, which is higher than the processor native data size. The filter class even uses long integer data for accumulating the sum of products given in Equation (
1) and reducing overflow errors. All of these facts make the filter class take longer than if it had been built using the native 8-bit data size. In [
42], the length of the convolution for a channel at a sampling rate of 31.25 kHz was analyzed. The results showed that it was only possible to implement a filter with a length of 1. However, if the integer division/multiplication could be replaced by shifting (in case of power of 2), the length of the filter could be increased up to 12–13. This could be a line to follow to improve the performance of the designed software. Nonetheless, the use of Arduino Genuino for real-time audio applications does not seem to be appropriate.
Other real-time applications need lower sampling rates than audio does. For example, authors in [
55] show the minimal and optimal requirements for digital polysomnography, which includes a wide range of sources of measurement: electrocardiography (ECG), electroencephalography (EEG), body temperature, muscular activity (EMG), movement detection, oxygen saturation, breathing sounds, electro-oculography (EOG), etc. Most of them are under 250 Hz excluding the breathing sounds, whose optimal sampling rate is 5 kHz. Another example is shown in [
56], which shows that the optimal sampling rate for human movement monitoring is 20 Hz.
For 250 Hz, the maximum filter length is roughly 500, which gives us a good idea of what kind of processing could be accomplished. In fact, one of the most common filtering applications in bioelectrical signals is a Notch filter, which just requires a small number of coefficients. A previous version of this software was used in the implementation of a notch filter with six coefficients to reduce the power line interference in the acquisition of an electrocardiogram signal [
57]. With a similar filter length, this software has been used to implement a low pass filter with zeros at 100 Hz to guarantee the reduction of the lighting interference when using an infrared system to detect blinks [
45]. The polyphasic filter class has also been used in [
35] to apply a 64-tap low pass filter, with a decimation factor of 16, in order to smooth the three-axis data of an accelerometer in order to detect movements in children with cerebral palsy.
6.2. Frequency Analysis
There are two main aspects to be considered when performing frequency analysis. The first one is frequency resolution, , which depends on the length of the input data vector, N, and the sampling rate, according to the relationship: . The second aspect is whether the algorithm used to compute the analysis will be able to perform the required operations in real-time. Both aspects are limited by both computational costs and data memory size.
The developed software provides the Goertzel class, which makes it possible to measure the power of a specific frequency component of the input signal with a resolution given by the sampling rate and the number of iterations used in Equation (
3). This algorithm does not need to store a vector of
N input data. According to the results obtained in
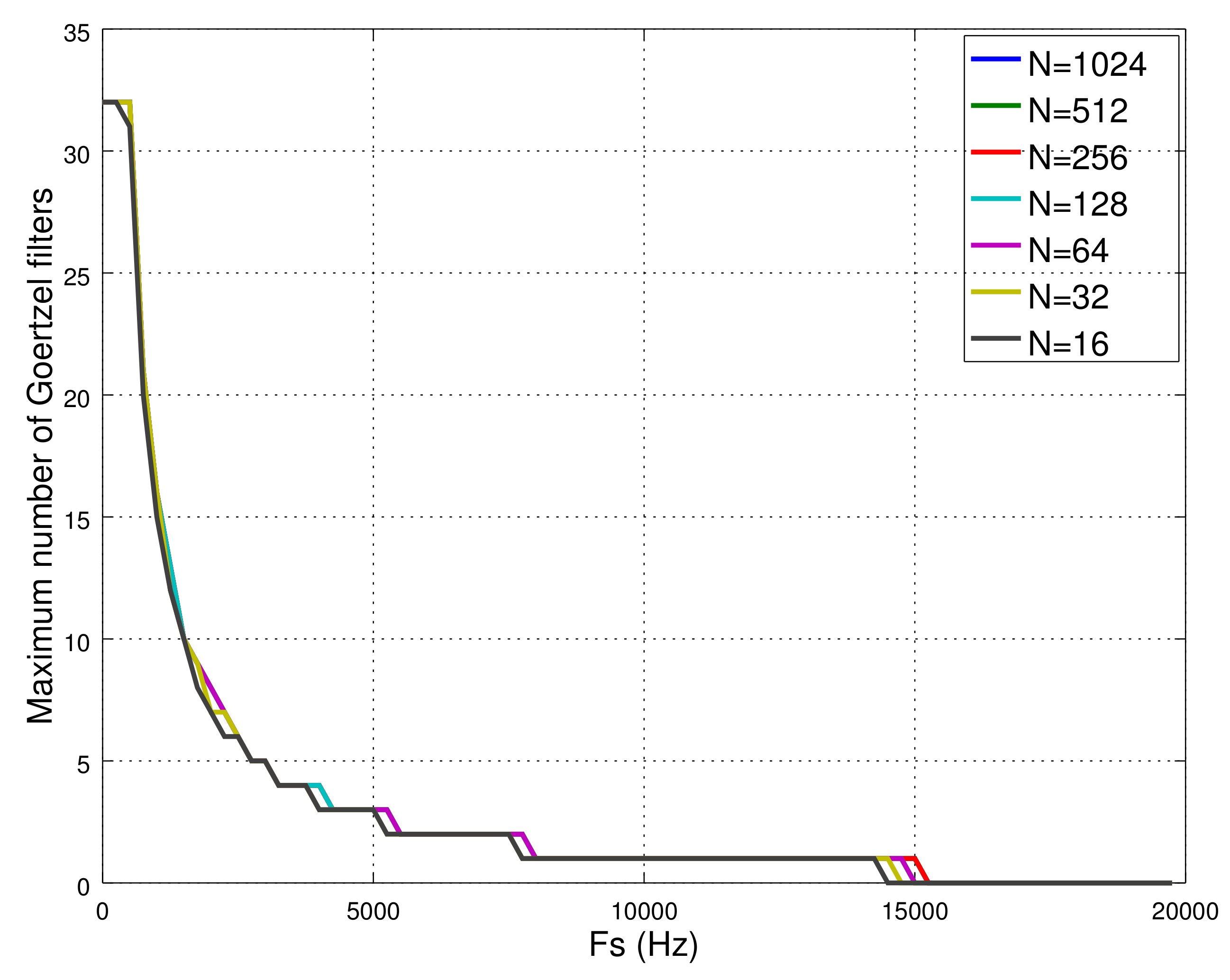
Section 5, this class uses 62 B of data memory, which limits the number of possible Goertzel filters to be operating simultaneously up to 32. Another factor limiting the number of Goertzel objects is the sampling rate, so that, as it increases, the time to compute the algorithm decreases (see
Figure 10). Thus, with a sampling rate over 8 kHz, it is only possible to compute one Goertzel object, with none possible over 15 kHz. It is remarkable that the frequency resolution, in this algorithm, is given by the number of iterations. Therefore, it is possible to analyze, for example, the power of a frequency component of 1 Hz of a signal sampled at 10 kHz only by iterating the algorithm
N = 10,000 times. Any frequency resolution is possible. Here, the cost is how long it takes the system to generate the output, which is the inverse of the frequency resolution.
There is an external library for computing the FFT of chunks of data (up to 256 bytes) for Arduino platforms [
43]. We have analyzed the number of cycles and memory resources needed by this library. These results are summarized in
Table 7.
The frequency resolution in the FFT depends on the length of the input vector,
N. For example, at a sampling rate of 10 kHz and an input vector length of
N = 256, the maximum frequency resolution would be
Hz. During the computation of the FFT algorithm, it is necessary to store the following
N input data. This can be done by the hardware layer class with a queue channel length of
N elements. Obviously, this needs extra data memory room, which, in the worst scenario (
N = 256), would be of 512 extra bytes.
Table 7 shows that there is memory available to accomplish this. The number of clock cycles available to compute the FFT is given by Equation (
17):
This library has been optimized to compute the FFT algorithm very quickly. In fact, our results show that it is possible to assess an FFT with any N number of bins up to 10 kHz and with N = 16 bins up to 21 kHz. This means that such a library outperforms the Goertzel class in terms of the number of different frequencies that can be simultaneously analyzed and at higher sampling rates. This superiority is partly due to the fact that the library was implemented in assembler language, so its execution is faster, but with the certain drawbacks. These mean that: (1) its usage is strongly bound to the processor family; and (2) the number of the bins cannot be changed in execution time. Furthermore, the memory size per frequency is higher in Goertzel’s algorithm due to it needing to implement a filter.
The fact that the Goertzel class allows us to study certain frequency components with higher resolution frequency than the FFT library was what made us include this class in the software library.
6.3. Usability Test
The global assessment of the usability test gave an overall mark of “almost good” to the developed library after obtaining a score of 70.2 out of 100. Due to the average score obtained in the B1 statement (3.4), the fact that the time taken to study the documentation for G2 (around 200 min, which is much higher that the time spent by the other two groups around 50 min), and that more examples are required for future improvements, it seems that we need to revise the documentation and include more programing examples in the library. This might cut down the study time and speed up the implementation of applications.
Figure 11a shows the boxplots containing the time spent studying the documentation and performing the two exercises for the three groups of participants. It is remarkable that G2 (undergraduate students) spent more time studying the documentation than the other two groups. This means that graduate students and lecturers caught up with the required knowledge very quickly (it was not necessary to perform any statistical test since the corresponding boxplots of G1 and G3 did not overlap with G2).
Another aspect is that lecturers were able to carry out the two exercises faster than the other participants (Wilcoxon rank sum test p = 0.013). Even though lecturers are familiar with Arduino IDE, this did not influence the time taken to perform the exercises. Groups G1 and G2 included people familiar with Arduino IDE, and the time spent by G2 was similar to the time spent by G3. In a formal comparison between experienced and non-experienced Arduino users, we did not find significant differences between the two groups (Wicoxon rank sum test p = 0.55).
Another aspect to highlight is the duration of the second exercise in comparison to the first one.
Figure 11b shows the boxplots of the time spent by the eleven participants in both exercises. There is a statistically significant difference between the two groups (Kruskal–Wallis test
p = 0.0085). This suggests that the learning and the usage of this library might be very fast. The time required to complete exercise 2 (40 min) was much less than that needed in exercise 1 (120 min).
Finally, to find out the specific reasons that make this technology suitable, we extended the Spearman correlation analysis among the items of the TAM3 survey. The behavioral intention statements show that people predict or will use/intend to use the system in the future (averages: = 6, = 6.4 and = 6.6). There are relationships between and ( = 0.918, p < 0.05), with ( = 0.889, p < 0.01) and ( = −0.968, p < 0.01), and with ( = −0.889, p < 0.01) and ( = 0.968, p < 0.01). This means that people intend to use the software because they find it easy to use and predict/plan to use the software in the future because it is useful and there are enough resources to do it.
With respect to the perceived usefulness, we have found relationships between (using the system enhances my effectiveness in my job, 6.4 in average) with ( = 0.899, p < 0.05), (, p < 0.05) and (, p < 0.05), and (the system is useful in my job, 6.4 in average) with (, (, p < 0.05) and (, p < 0.05). Putting all these determinants together, it can be concluded that the perceived usefulness comes from the fact that the system is easy to use and pertinent to the professional environment. Participants feel that given the necessary resources to use the software they will not need anyone around to help them complete the exercises.
Two statements in the perceived ease of use showed relationships with other determinants. Namely, (the interaction with the system is clear and understandable, 5.4 in average) with (, p < 0.01), (, p < 0.05) and (, p < 0.01) while (it is easy to get the system to do what the users want to do, 5.8 in average) with only (, p < 0.01). This means that the perceived ease of use mainly comes from the belief that users have control over using the system and the environment offers the material and human resources necessary to use the system.
7. Conclusions
This software allows programmers to implement basic signal processing applications easily in OSHW platforms like Arduino Genuino, one of the most popular, well-known, supported and inexpensive platforms.
The software includes a set of classes that implements filters, polyphasic filters, Goertzel’s algorithm, sliding windows, non-blocking delays and a hardware level class that guarantees that data are acquired at a fixed rate and delivered to a higher level of the software architecture through dedicated channel queues. Our results show that the library itself, together with a simple OSHW platform like Arduino Genuino, can be used for small biomedical real-time applications.
The product, which includes the library and documentation, obtained a score of 70.2 out of 100 in a standard SUS test. The implementation of typical signal processing elements was very easy and obtained a score over 4.4 on a scale with a maximum value of 5. Most participants perceived that the software was easy and intuitive to use, although it was also suggested that more examples should be included.
We will keep on improving the classes to make them more computationally efficient and exportable to other platforms such as those based on the ARM 32-bit processor, like Arduino Due, with higher data memory capacities, native data buses and clock frequencies than Arduino Genuino. This will widen the range of applications where the library can be used.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










