1. Introduction
The rapid increase of vehicles contributes heavily to the air pollution in cities; thus, the optimization of urban transportation is of upmost importance. Vehicle classification plays a significant role in road maintenance, traffic flow modeling, and road safety management [
1] and thus is one of the most important tasks of an intelligent transport system (ITS).
Since the 1980s, researchers have studied automatic vehicle classification systems in ITSs and concluded that the magnetic field distortion caused by vehicles can be used for vehicle detection and classification [
2]. Many different sensor schemes can achieve desirable results in vehicle classification. Among them, three technologies are widely used, inductive loop detectors [
3,
4,
5], magnetic sensor detectors [
6,
7,
8], and vision-based detectors [
9,
10,
11]. These three technologies have their own specific applicable scenarios. In this paper, the anisotropic magnetoresistive sensor (AMR) approach is introduced to accomplish the task of vehicle classification.
Vehicle classification based on an AMR sensor is a highly challenging but practical task. With an increasing number of vehicles on roads, the demand for automatic traffic monitoring system is growing. Therefore, a low-cost vehicle detection system, called Sensys Networks’ VDS240 [
12], sprung into popularity. Using its small wireless AMR sensor nodes on lanes, the system captures the magnetic signal caused by vehicles, which can be used for vehicle detection. As a result, the study of vehicle classification based on a single magnetic sensor is crucial for automatic monitoring systems, allowing vehicle types to be introduced into other similar vehicle detection systems.
Great strides in automatic monitoring systems and ITSs are being made with the development of artificial intelligence technology [
13]. In our previous work, a feature extraction and comparison method was presented for vehicle classification with a single magnetic sensor. The core lies in the smart feature extraction method and correct selection of classification algorithms. The experimental simulation results show that the proposed approach can reach 83.62% classification accuracy, which is essentially a time-domain-based method [
14]. Similarly, some researchers classify vehicles by using the frequency domain methods. For example, Zhang et al. [
15] has proposed one based on a frequency domain energy spectrum of a geomagnetic sensor for real-time vehicle classification, achieving an average accuracy above 90%.
There is, however, a crippling limitation. Traditional machine learning classification researches are based on the assumption that the number of samples in a dataset is relatively balanced. Unfortunately, this assumption does not hold true in traffic applications and many models are imbalanced. In Chinese cities for instance, the number of sedans is much higher than that of buses. So far, no satisfactory solution has been provided to solve this issue. Some studies have directly constructed vehicle classifiers by using a balanced dataset [
8], while others avoid discussing the influence of imbalanced vehicle datasets [
16].
Sections in this paper are as follows.
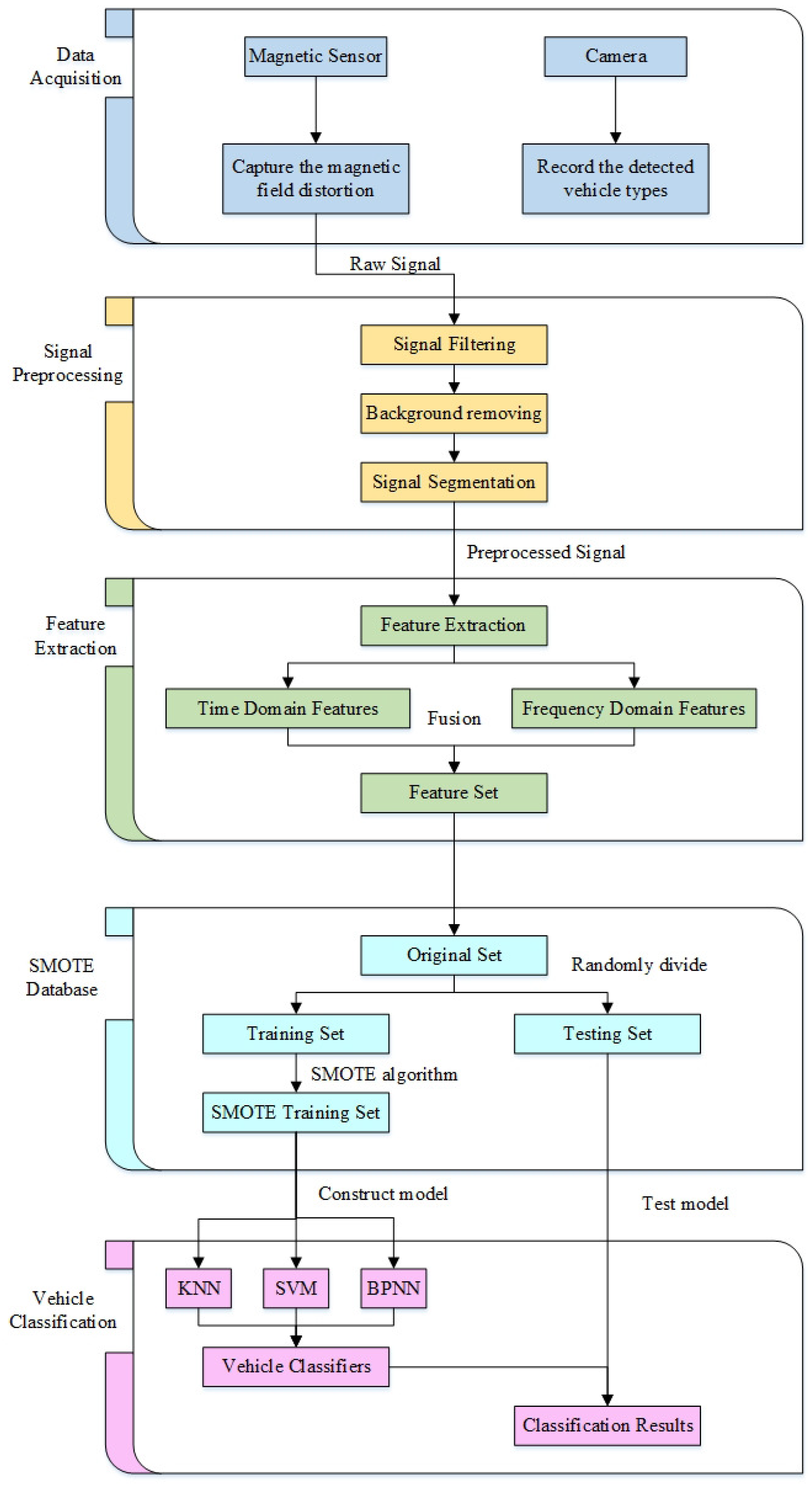
Section 2 introduces the designed data acquisition system, which is composed of a single magnetic sensor, a camera, and a laptop.
Section 3 introduces the signal preprocessing method and lists the obtained original vehicle magnetic dataset. An innovative feature extraction method is proposed in
Section 4, which will be used to construct feature sets. However, the vehicle classifiers have poor performance on rare vehicle types, and the reasons are given in
Section 5.
Section 6 proposes an oversampling approach, which is called the SMOTE algorithm. Not only will the SMOTE algorithm solve the issue of imbalanced vehicle datasets, but it will also improve the performance of classifiers. Experimental results and discussions are presented in
Section 6, which confirms that the SMOTE algorithm does indeed work. Conclusions are then given in
Section 7.
2. Data Acquisition System Overview
When a vehicle passes close to a magnetic sensor, it will detect all of the different dipole moments of its various parts. Sufficient information could be obtained from the magnetic field distortion, including the trajectory of target metal objects and other intrinsic parameters [
17]. Moreover, different types of vehicles come in different sizes and structures, leading to different magnetic field distortion. In summary, vehicle classification can be realized based on the magnetic sensor. The data gathered on vehicle types can then help to improve existing traffic monitoring systems.
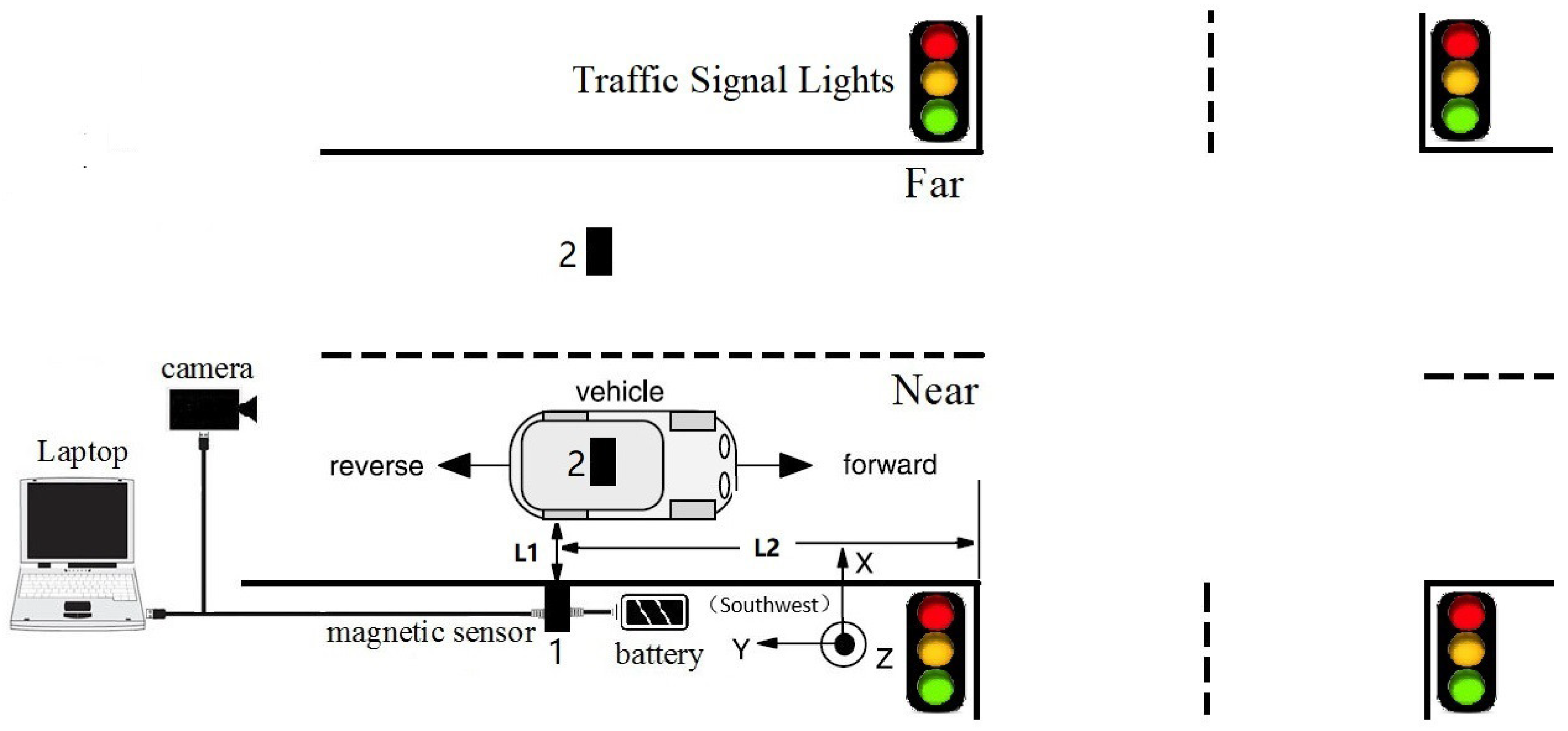
As shown in
Figure 1, a magnetic sensor was used to capture the magnetic signal caused by vehicles, while vehicle types were recorded by a camera. In our experiments, the HMR2300, a three-axis smart digital magnetometer, was chosen as the magnetic sensor. The HMR2300’s advantage lies in its ability to detect the strength and direction of a magnetic field and is therefore able to feed the x, y, and z components directly to a computer. Moreover, it has a range of ±2 Gauss, with a 67
Gauss resolution. In addition, the direction of the magnetic sensor installation is shown in the lower right corner of
Figure 1, with its
Y-axis pointing towards the opposite direction (southwest) parallel to the moving vehicle.
The sampling rate of the HMR2300 was set to 123 samples/s, which is close to the rate of the magnetic sensor in VDS240 (128 samples/s). We used this setup to collect magnetic data on real life traffic, in order to obtain information on behaviors of real life traffic flow. Please note that it is a two-way four-lane intersection, while the data acquisition system is deployed in a one-way two-lane intersection, where the speed is limited to 80 km/h. In addition, the distance between the sensor and the crossroads (
in
Figure 1) was limited to 50–100 m. This distance is used to install the magnetic sensor, where the speed of the detected car is low, yet it rarely stops. According to China’s traffic laws, the vehicle must slow down at least 100 m from the intersection. As a result, vehicle speeds were already reduced before passing the sensor, and the data indicates that most vehicle speeds were less than 20 km/h. In summary, there are some advantages to setting the length of
as 50–100 m. For example, if the speed of the detected vehicle is lower, then we can obtain more sample points at the same sampling rate. Additionally, due to the presence of the camera at the crossroads, driving behavior will be more civilized (no bad driving behavior such as lane change or overtaking), which led to more robust magnetic data collection.
The roadside (Position 1 in
Figure 1) and the middle of lanes (Position 2 in
Figure 1) are two common positions in which sensors can be installed.
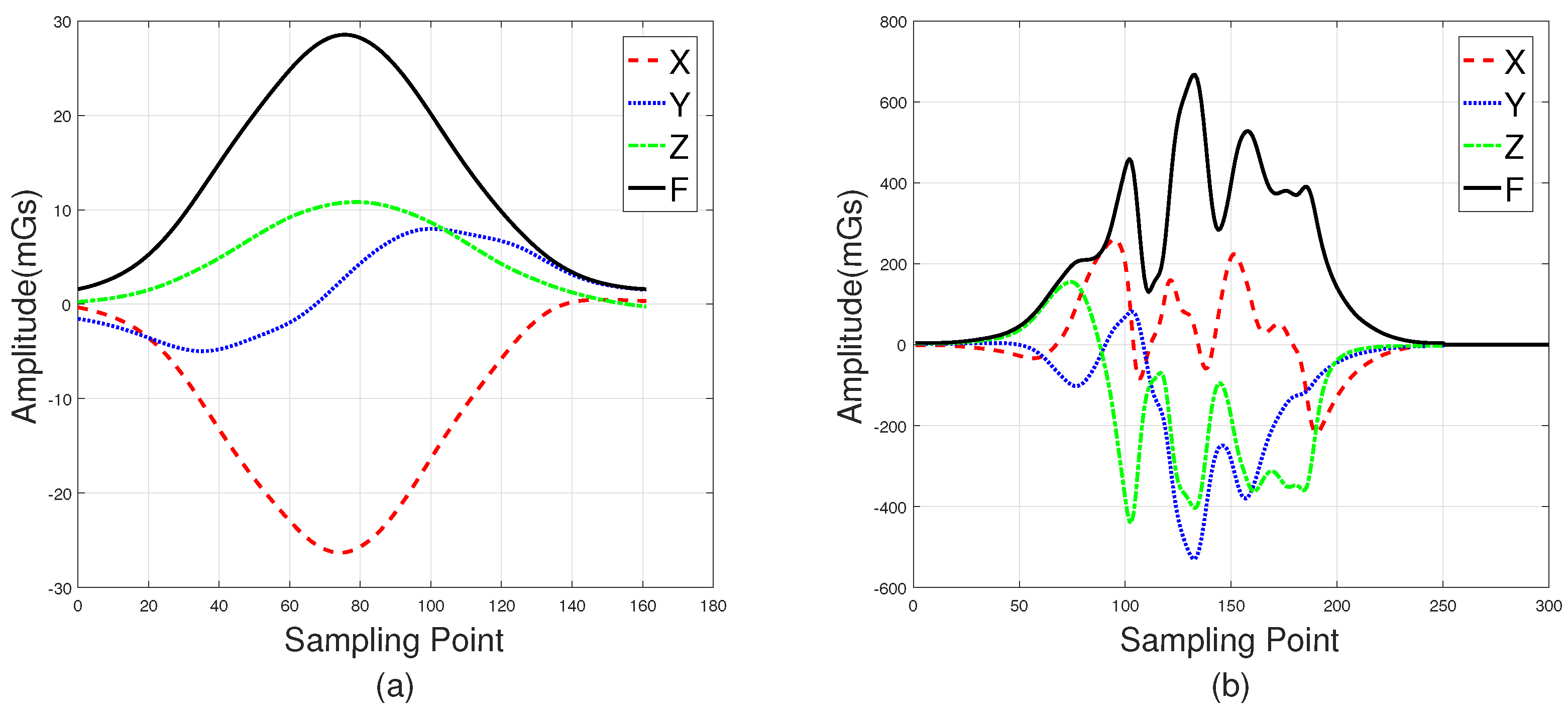
Figure 2a shows three-axis magnetic signals of X, Y, and Z and the F signal (the magnetic field intensity of the measured signal) of a sedan collected roadside, with
Figure 2b showing data collected through a sensor in the middles of lanes. Intuitively, the magnetic disturbance signals collected by these two deployment methods are different, and the magnetic field intensity captured by the middle-of-lane installation scheme is about 24 times larger than the one on roadside. Both of these two sensor installation schemes are able to realize vehicle classification, and each have their own applicable scenarios. However, from the view of deployment, the roadside method is simpler, while the one in the middle of lanes is more time-consuming and may even disrupt traffic. Thus, the roadside installation was chosen for capturing magnetic signals in our experiments.
Note that, in
Figure 2, the two waveforms contain 120 samples and 200 samples, respectively. This is because
—the distance between the detected car and the sensor—of these two deployment methods are different. In addition, the distance between the detected car and the magnetic sensor (
in
Figure 1) changes with the mounted height, which directly leads to different magnetic field distortion. In other words, the height suitable for different types of vehicle are not the same, which increases the difficulty of vehicle classification. In this study, the magnetic sensor was installed close to the ground, allowing it to detect all vehicle classes. This may not be the most optimal solution, but it is the simplest, and the classification results validate this. Considering that the height parameter is a key factor, we plan to find out the optimal value for different classes of vehicles in future studies.
4. Feature Extraction
Based on the magnetic database above, this section will introduce an innovative feature extraction method, which is essentially the fusion of time-domain and frequency-domain methods. The raw magnetic signal consists of the
X-,
Y-, and
Z-axis signals, and the magnetic field intensity of measured signals (notated as
F) can be easily calculated using Equation (
1). There are four signal waveforms in total, whose features will be extracted in this section.
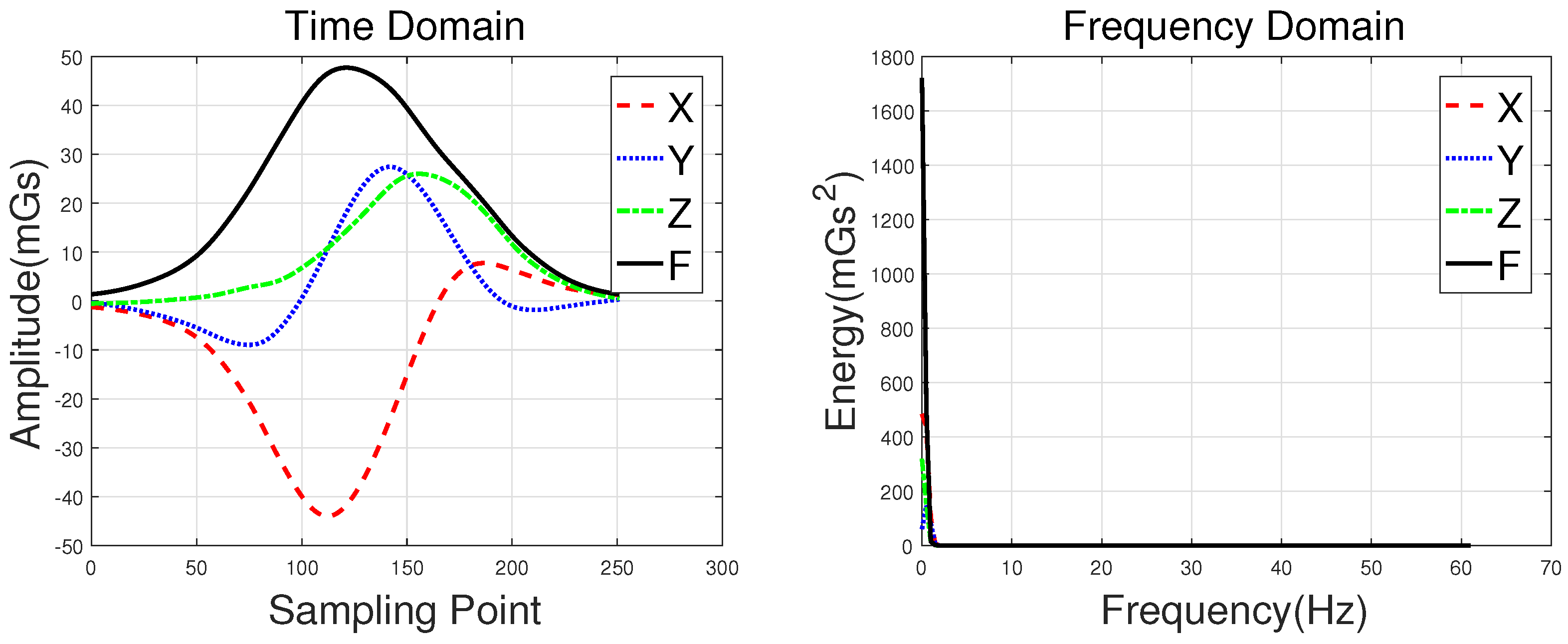
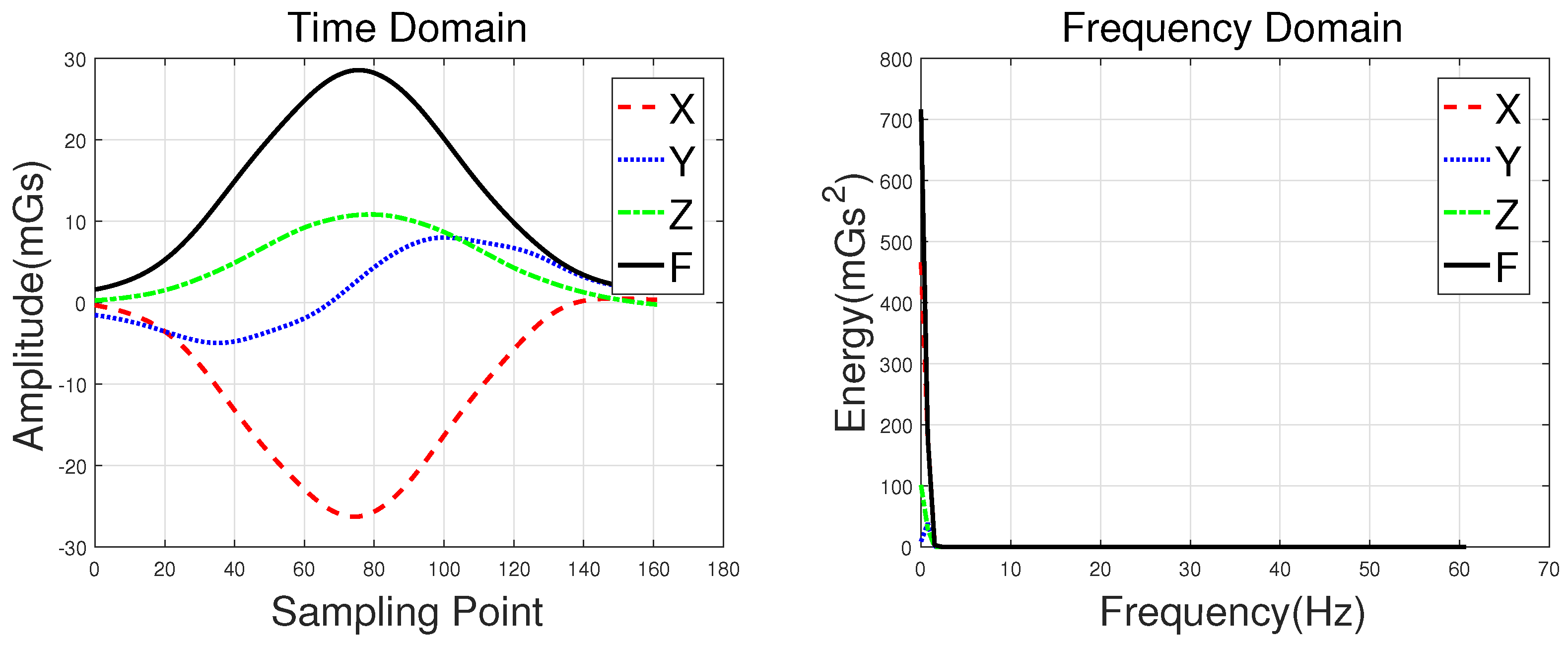
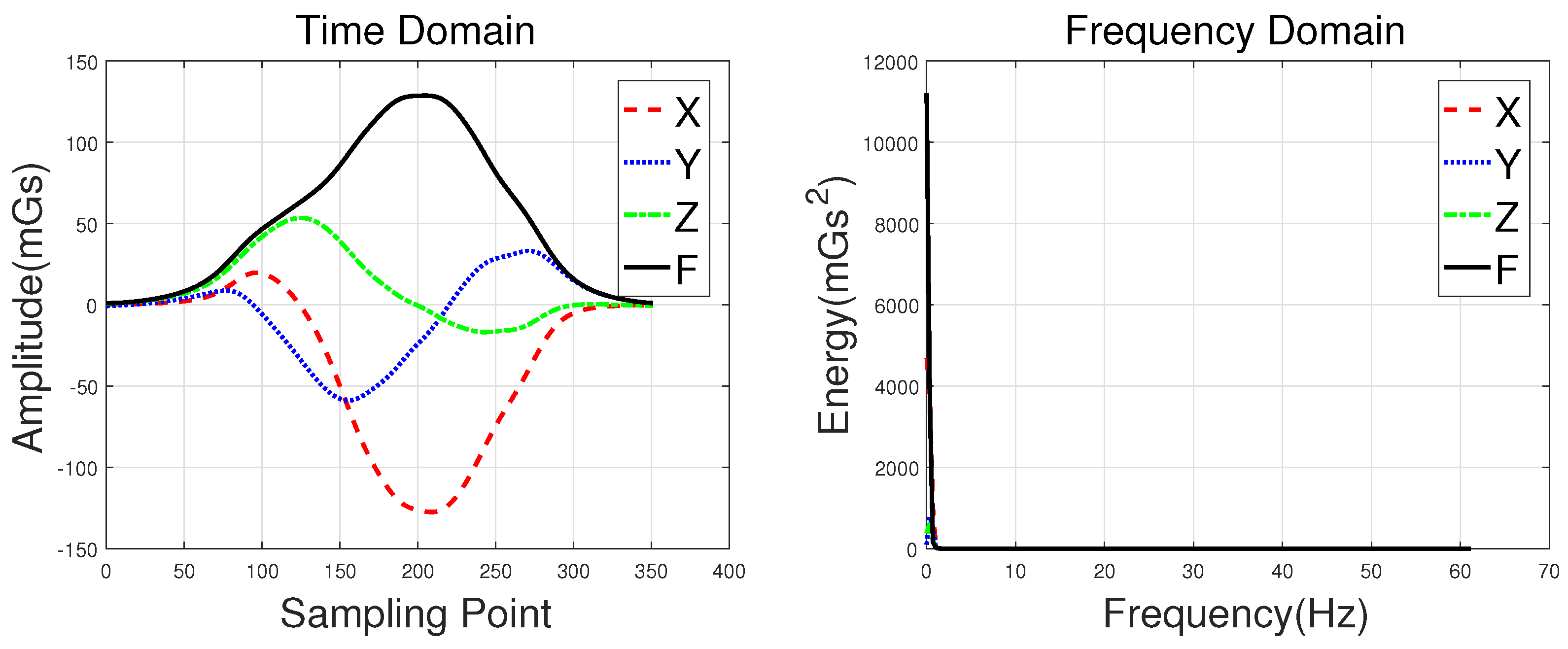
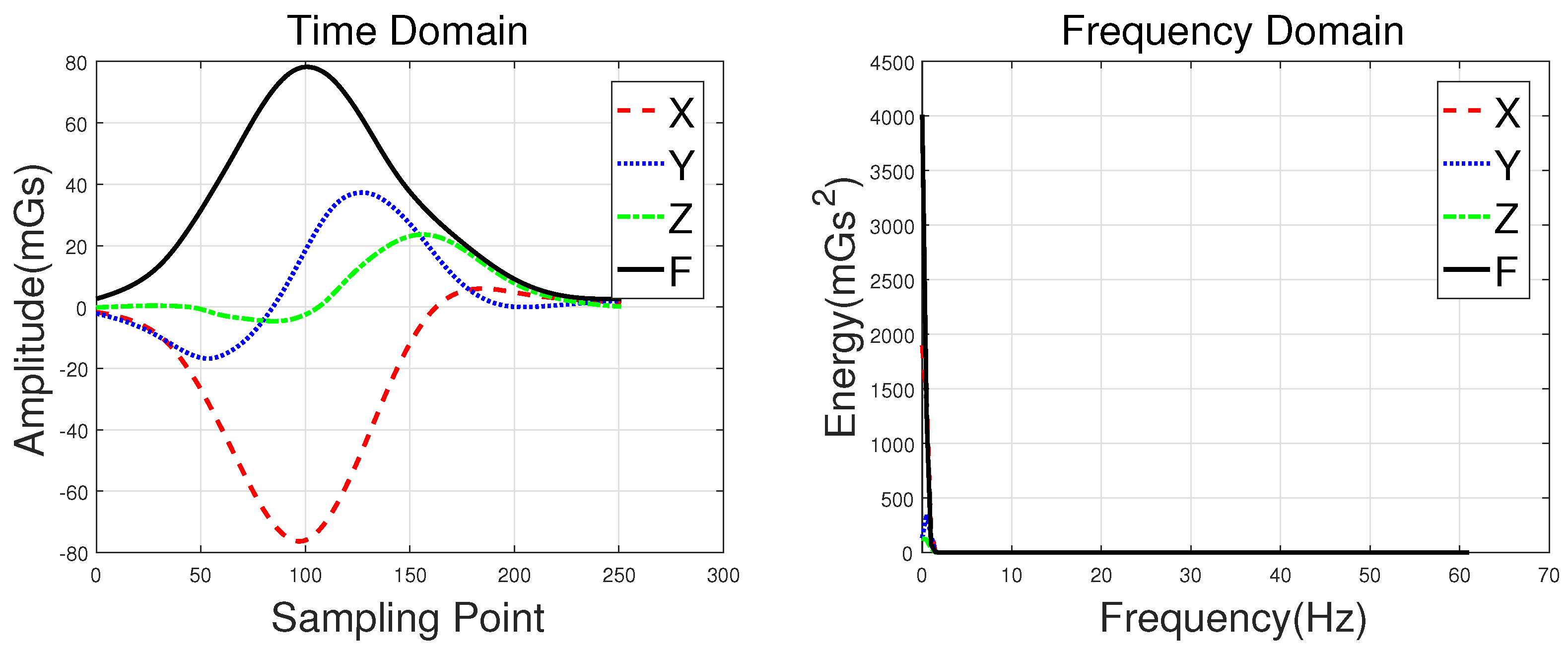
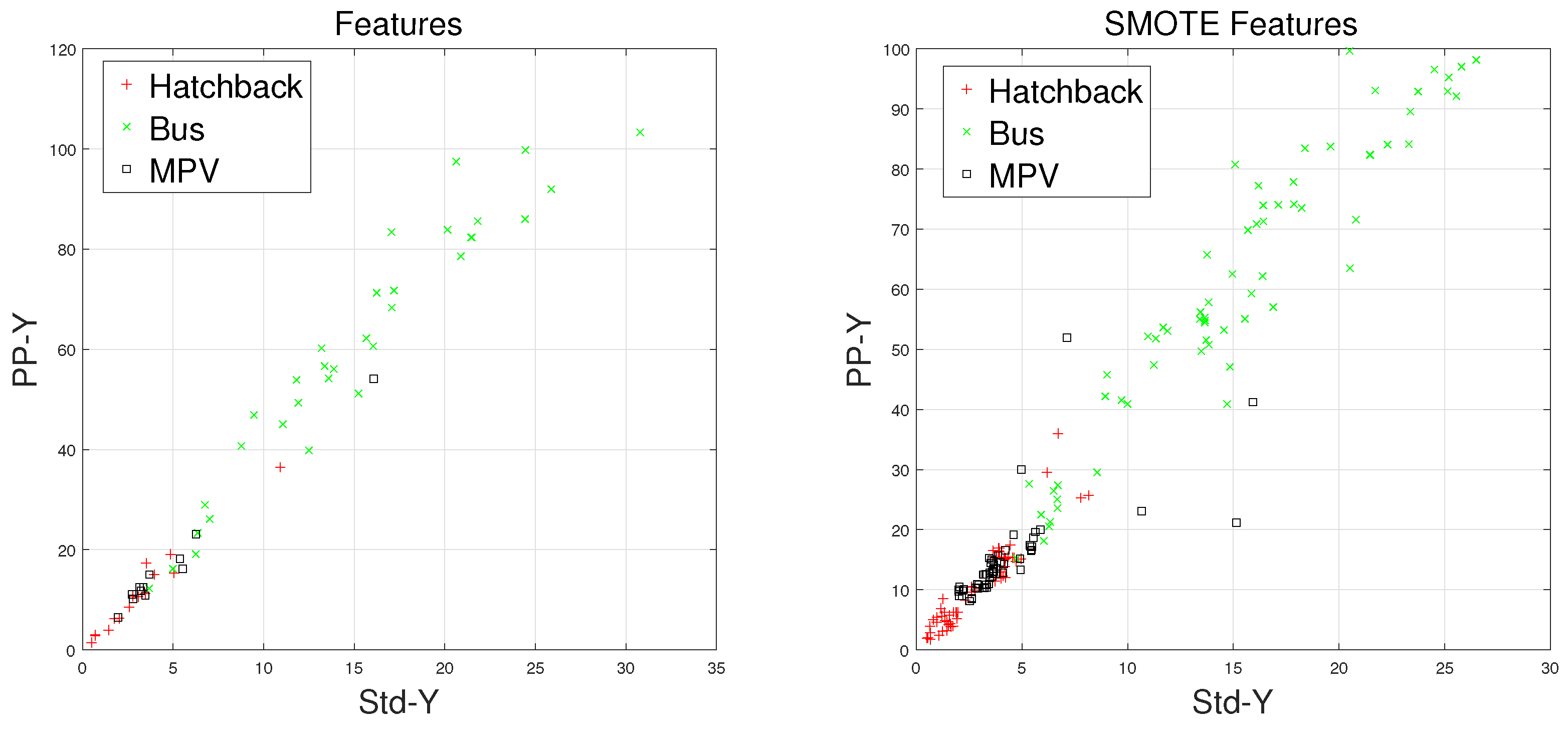
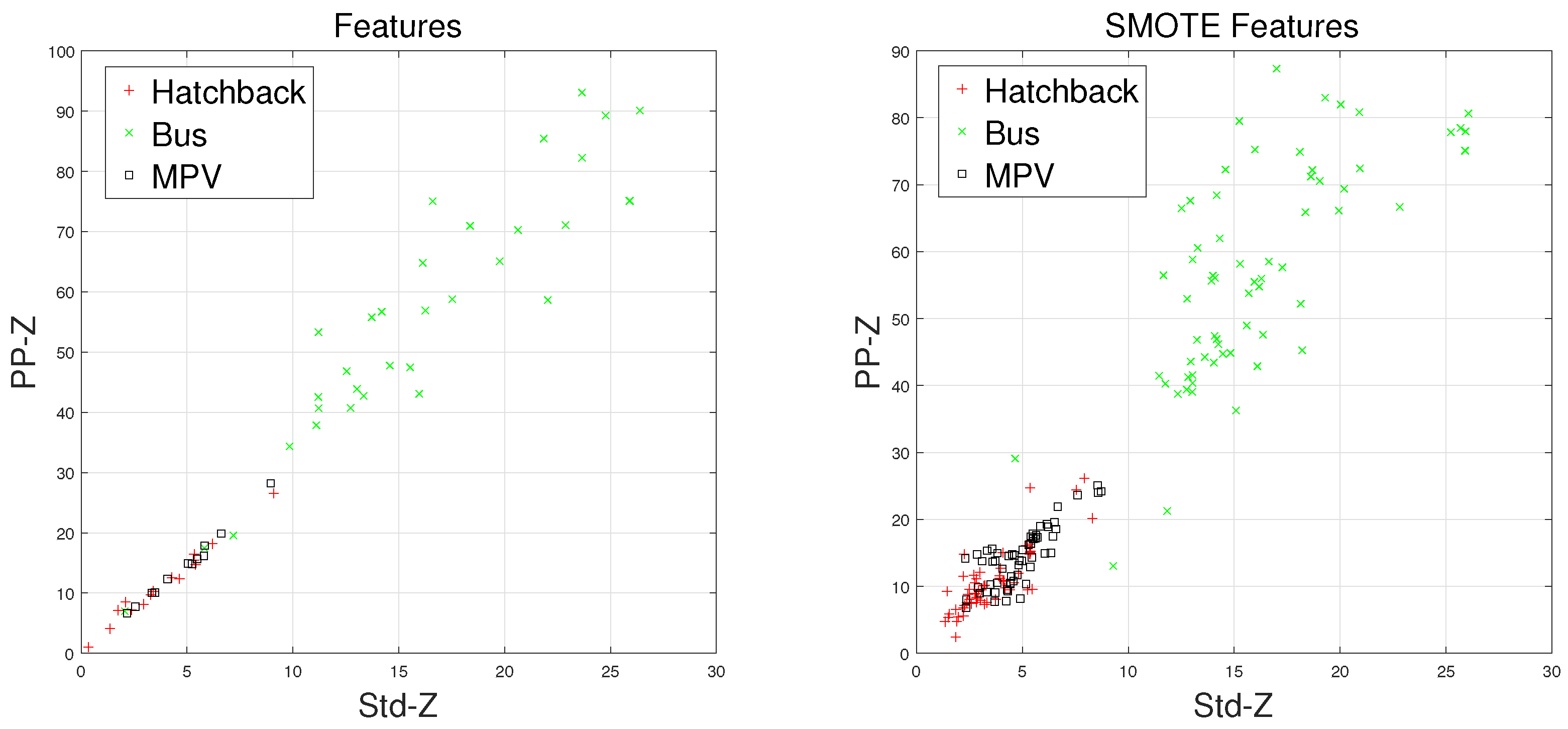
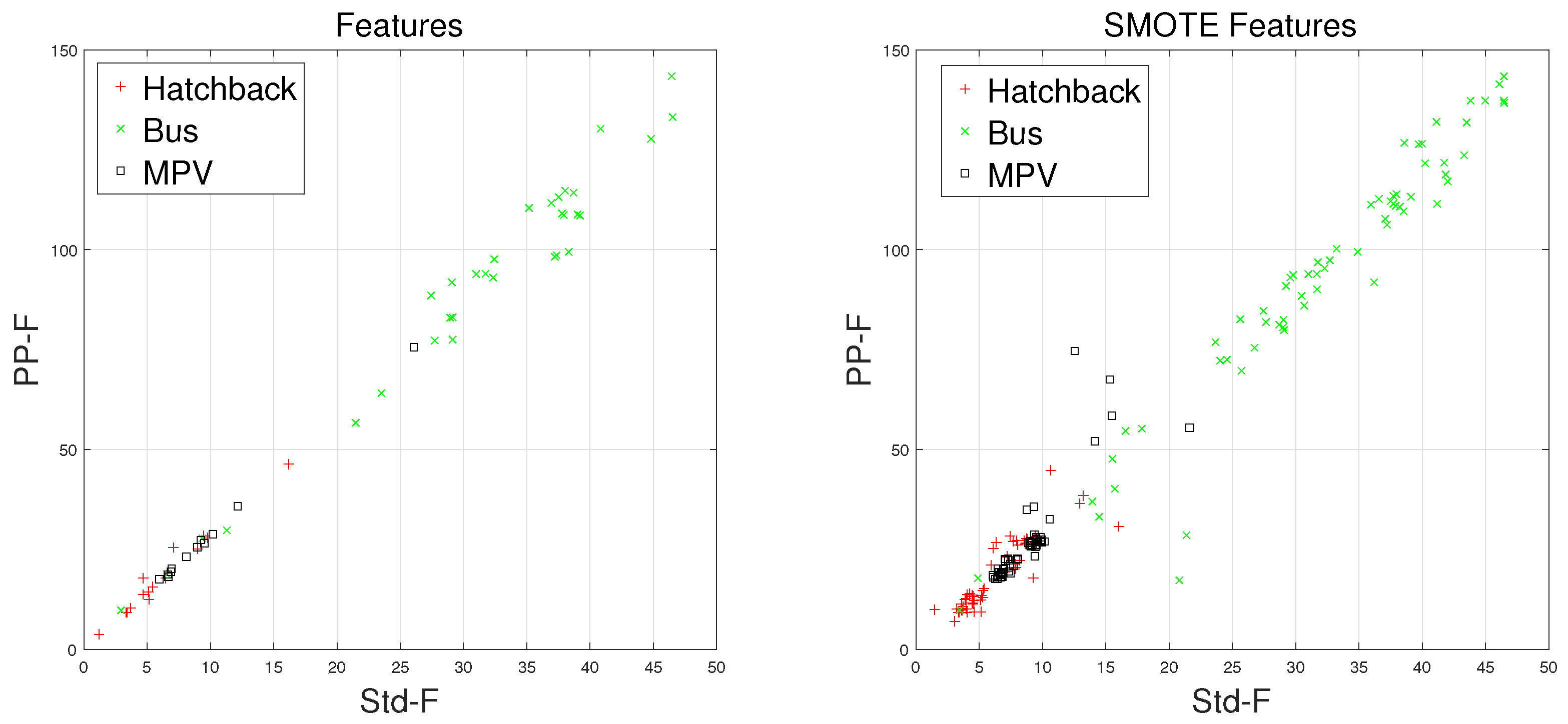
Waveforms of a hatchback, a sedan, a bus, and an MPV along with their frequency spectrums are shown in
Figure 3,
Figure 4,
Figure 5 and
Figure 6, with the upper subgraphs consisting of the
X-,
Y-, and
Z-axis components and the curve of the
F signal in the time domain. Figures on the lower subgraphs are the corresponding signal waveforms in the frequency domain. There is significant difference among these waveforms, which is mainly caused by the vehicles detected belonging to different classes. In this paper, the detected vehicles are classified into hatchbacks, sedans, buses, and MPVs. For the magnetic sensor, the difference between these types is mainly reflected in length, structure, and the distribution of ferromagnetic materials of the vehicles. Their frequency spectrums can be easily obtained by using the fast Fourier transform (FFT) method. In this study,
X,
Y,
Z represent the feature sets extracted from the
X-,
Y-, and
Z-axis triaxial magnetic field components, and F represents the feature sets extracted from the magnetic field strength. For brevity, the feature set constructed based on the time domain method is notated as
Time, and the one obtained by the frequency domain method is notated as
Frequency.
First, let us introduce the
Time feature set. Its definition is shown in Equation (
2).
PMax and
PMin are defined as the position of the maximum and the position of the minimum, and
L is the sampling points of the detected signal.
PP,
Me, and
Std are peak-to-peak value, mean value, and standard deviation value of the detected signal, respectively.
NoExt,
ASign, and
ZCNo are the number of extremes, the sign of the first extreme, and the number of zero-crossing.
E is defined as the energy of the detected signal, and
AvgE is the ratio of
E to
L. Lastly,
RtoE is defined as the ratio of the energy of the
X-,
Y-, and
Z-axis signals to the energy of the
F signal (e.g.,
RtoE_X is the ratio of
E_X to
E_F). According to Equation (
1), it is clear that the value of the
F signal is non-negative, whose DC component has been removed. As a result, the
PMin,
ASign, and
ZCNo of the
F signal are not included in the
Time set. The
RtoE feature is also not adapted for the
F signal, because its value is always equal to 1.
An FFT is an algorithm that samples a signal over a period of time (or space) and divides it into its frequency components. In this study, we used the
fft function in MATLAB to achieve the signal transformation process, which is shown in Equation (
3).
T represents the obtained magnetic signals ( the
X-,
Y-, and
Z-axis signals and the
F signal), and
W is the discrete Fourier transform (DFT) of vector
T.
However,
W is a sequence of complex numbers, which is not suitable for further processing. It needs to undergo conversions in order to be used. In this study, the energy spectrum is chosen for extraction features in the frequency domain, which is an often-used method in the signal processing field. As shown in Equation (
4), the energy is the square of the magnitude of the frequency signal.
The signal energy is notated as
WE, and
AMP is the magnitude of the frequency signal, which is calculated in Equation (
5).
is the number of sampling points, and
AMP(1) is the DC component of the frequency signal.
Based on the energy spectrum curves, we can obtain 2∼9 non-zero samples of the frequency spectrum, which limits a reliable estimation of the features extracted in the frequency domain. In other words, feature extraction based on 2∼9 non-zero samples does not make sense. A simple solution is directly using these non-zero samples to construct the
feature set, which is shown below.
is the first
points of the
(defined in Equation (
4)), whose value is 9 in this paper.
In conclusion, the
Feature set is defined as Equation (
7), which is the fusion of the
Time set and the
Frequency set.
In order to simplify the model, this study is under a strong assumption: When the detected vehicle passes by the magnetic sensor, its speed is uniform. This assumption is inaccurate in most scenarios, but we can assume it is approximately correct in this study. The reasons are as follows. First, the detected vehicle’s speed is low, and the driving behavior is civilized, both of which are thanks to the smart sensor’s installation position. Secondly, most features in the
set are not easily affected by the speed, and those that are have been optimized by speed normalization. For example, both
and
are easily affected by speed, so the ratio between them and
(the sampling points of the detected signal) have been used in the
set instead. With the sampling ratio at 123 samples/s (notated as
), the speed (notated as
) can be easily calculated using Equation (
8):
is the length of the vehicle.
From the above equation, we can reach a conclusion that is inversely proportional to . Furthermore, values of a single vehicle model are relatively close. Lastly, features easily affected by speed account for a smaller proportion in the set, which leads to a smaller influence on the classification results. Thus, the influence of speed has a minimal effect on the feature extraction method proposed in this study, as proven mathematically. In other words, as long as the sampling data is sufficient, the feature extraction method proposed in this paper can work well at a higher speed.
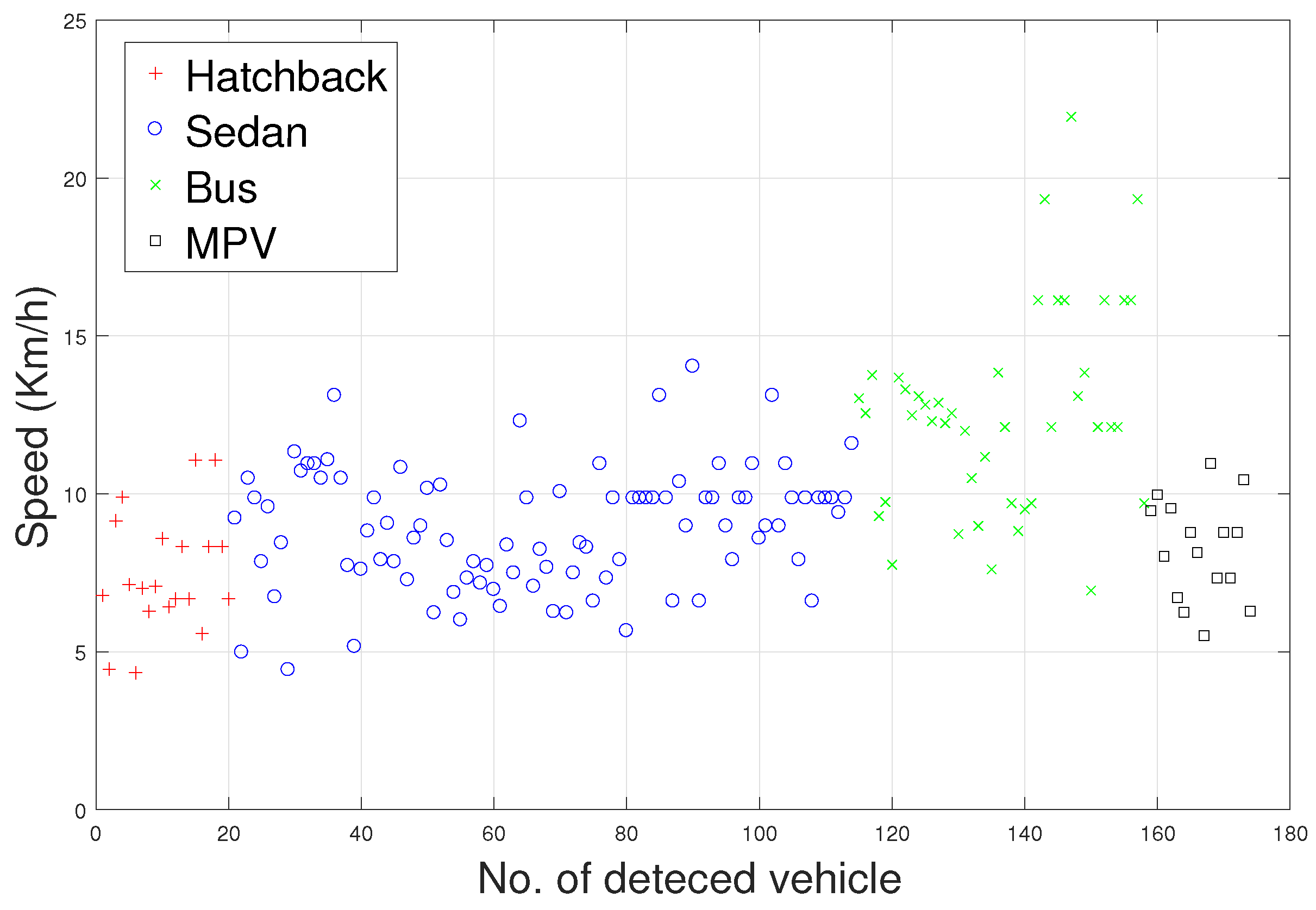
The speed of the detected vehicle directly determines the number of sampling points that can be obtained, and has a significant effect on the magnetic disturbance waveform. As mentioned earlier, the sampling rate of the HMR2300 was set to 123 samples/s. In this paper, we assume that the average lengths of the
,
,
, and
are 3.8, 4.5, 11, and 5 m, respectively. Thus, according to Equation (
8), the approximate speeds of the detected vehicles can be calculated. As shown in
Figure 7, the speed of the vehicles collected in the original database is approximately 4–23 km/h. In the obtained database, the number of sampling points (time domain) is in the range of 142–702, and these data have the ability to distinguish the models discussed in this paper.
7. Conclusions
Using discrete Fourier transform (DFT) and principal component analysis (PCA) to automatically extract features from magnetic signatures, a vehicle classification system of three categories could be made based on a single wireless magnetometer [
25]. Moreover, by using the SVM algorithm, a total classification accuracy of approximately 87% was obtained. Compared to this method, our approach can not only obtain a higher classification accuracy but also cope with more types of vehicles. Furthermore, vehicle classification based on the magnetic length and average magnetic height of vehicles using a portable roadside sensor system may also achieve desirable results [
7], but this sensor system requires four magnetic sensors and a GPS sensor. By contrast, our proposed method for vehicle classification only uses a single magnetic sensor while achieving comparable results.
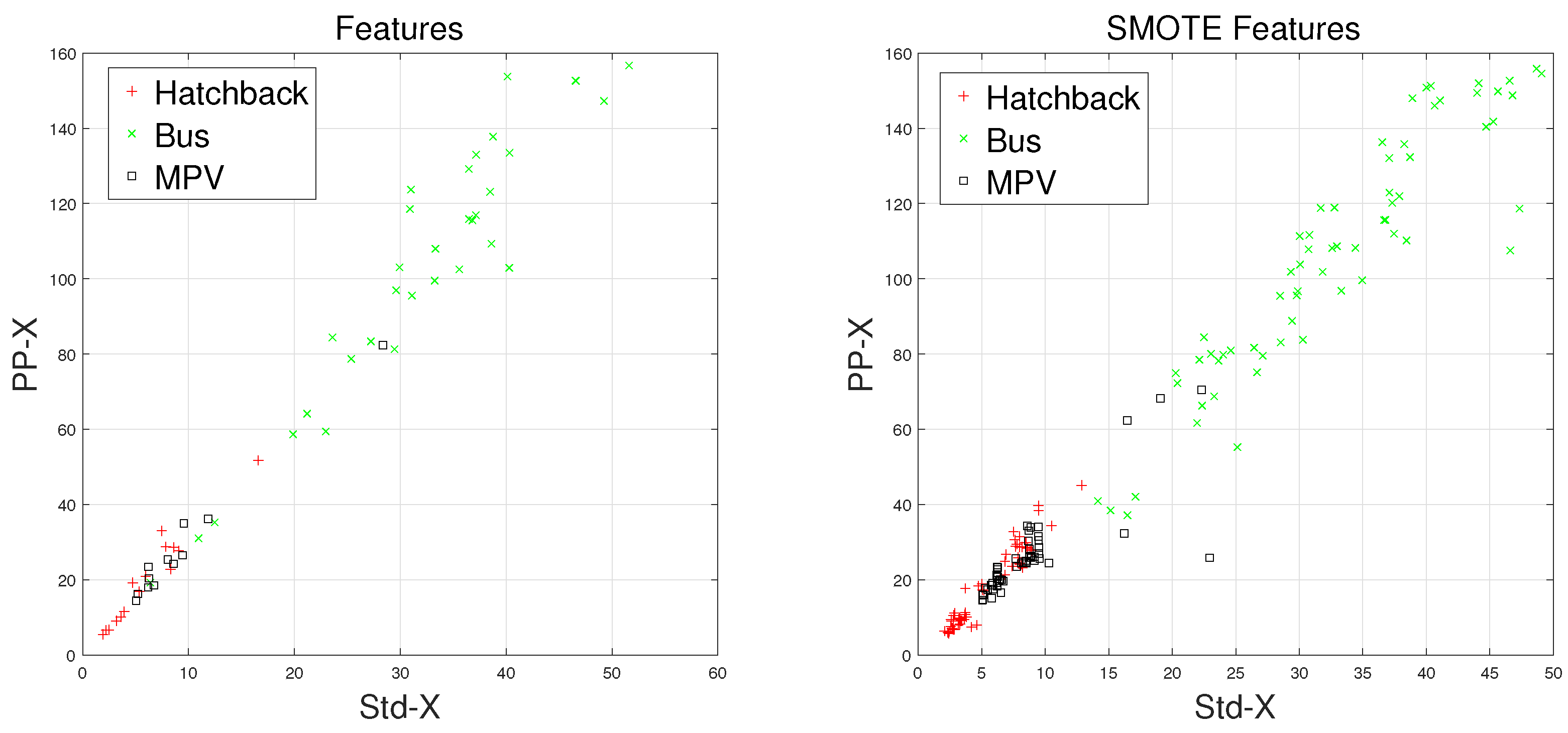
In this study, we first introduced the data acquisition system, which has been used for constructing the original vehicle classification magnetic database. Next, a clever feature extraction method is proposed, which is the fusion of time-domain and frequency-domain methods. For improving the performance of vehicle classifiers, the F1-Measure method was introduced to contribute to the classification results of each vehicle type. By comparing the F1 values, we find that the classifiers, with an imbalanced dataset, are biased heavily toward Majority vehicles, leading to poor prediction for Minority vehicles. In order to solve this problem, the SMOTE algorithm is introduced to reconstruct the Training Set. Experimental results show that, after using the SMOTE algorithm, the KNN classifier with the Feature set reaches an excellent classification accuracy of 95.46%. In addition, the prediction of Minority vehicles becomes more accurate.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}