3.2. Parameters and Modelling Uncertainties
Three parameters that influence the structural behaviour are selected for model updating, namely: the equivalent Young’s modulus of the aluminium deck (
), the rotational stiffness of the North-bank hinges (
), and the axial stiffness of the hydraulic jacks (
). The initial intervals for each parameter are presented in
Table 1. The bridge deck consists of aluminium planks with an omega-shaped cross-section bolted to secondary beams. In the FE model, the deck has been modelled using a plate with the equivalent thickness simply supported by secondary beams. Considering this simplification, a uniform distribution with sufficiently large bounds was conservatively chosen to describe the initial knowledge of this parameter. The values for the rotational stiffness cover the full range from a constrained to a pinned support, in order to include potential effects due to the corrosion of bearings. The axial stiffness of hydraulic jacks is used to simulate their contribution as additional load-carrying supports. The lower bound for the axial stiffness is equivalent to assuming the two girders simply supported at the abutments. The upper bound corresponds to the introduction of a semi-rigid support at jack connections.
An initial population consisting of 3000 instances is generated from the uniform distribution of each parameter value using Latin hypercube sampling. Uncertainties associated with the FE model class are defined as percentages that are applied to the mean values of the initial-model-set predictions. The forms and magnitudes of the estimated uncertainties are reported in
Table 2.
The main source of uncertainty due to FE model simplifications is not symmetric. All secondary beams are perfectly fixed to the longitudinal girders, instead of having perfectly pinned connections. Therefore, the FE model is actually stiffer than the real structure, thus, justifying the increment of the model predictions up to 20%. However, assumptions such as the omissions of non-structural elements (for example, barriers) could have the opposite effect, leading to a more flexible behaviour than the real one. The latter omission has a smaller influence on the bending behaviour, thus, the model uncertainty range is asymmetric. The bounds for this source of uncertainty have been defined using conservative engineering judgments, as recommended in Reference [
37].
Typical uncertainties that relate to the FE method such as the mesh refinement and additional uncertainties are estimated according to the technical literature. The mesh-refinement uncertainty has been quantified through a convergence analysis, by increasing the mesh density until the model response converged asymptotically and the prediction variations were lower than 1%. An analogous practice is described in Reference [
38]. Additional uncertainties help account for accidental omissions and for the phenomena that, when taken individually, have a negligible impact. Finally, the uncertainties have been initially reduced by site inspection, which also involved the checking of element geometry. Values similar to those reported in
Table 2 have been previously employed in studies concerning full-scale bridges [
32,
39].
3.4. Results for Model–Class Validation
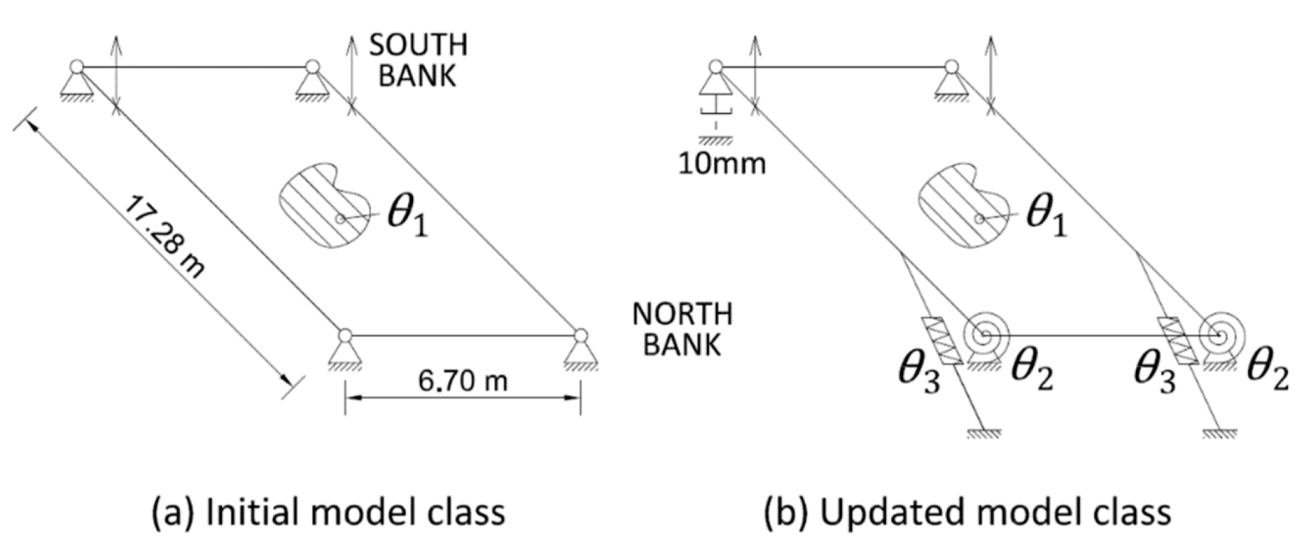
In order to perform the model–class validation, the two model classes depicted in
Figure 7 are generated. The initial model class involves typical design assumptions idealising the bridge as a frame that is simply supported by four non-friction bearing devices. Assuming the structure geometry and the elastic properties of steel to be well-known, the equivalent Young’s modulus of the aluminium deck (
) is the only parameter to be identified.
The updated model class includes friction connections on the North-bank side of the bridge, the two hydraulic jacks that are used for lifting, and the presence of a 10-mm gap between the base plates of the main girders and the abutment at the South-West support. The presence of the gap was observed during the visual inspection of the structure, confirming the iterative nature of structural identification.
When the initial model class is employed (
Table 4), the prediction ranges of the initial population include the measured value at only one sensor location (that is,
) out of seven. Additionally, at an few locations (for example,
, and
), the measurements are extremely far from the prediction ranges. On the contrary, the observed behaviour of the bridge is captured by the updated model class, which is intrinsically more detailed than the initial one. In
Table 5, all the measurements belong to the initial prediction ranges, which include the combined uncertainties.
3.5. Results for Outlier Detection
The detection of suspicious values in the measurement datasets is carried out according to the two-step methodology presented in
Section 2.2.2.
The analysis of each sensor is performed individually in step 1. In
Figure 8, the CDFs of the CMS populations computed using simulated measurements for the three most effective sensors (
, the deflection camera, and
), are plotted. Then, the cumulative probability of observing the
obtained using the real measurement of each sensor (identified as a dot of the CDF) is computed. A probability of 2% is obtained for sensor
, while the other sensors show probability values around 40%. The high falsification performance of sensor
compared with the average of the sensor network, suggests that this sensor provides suspicious data. The results for the remaining four sensors (
to
) are similar to those shown in
Figure 8 for sensor
and the deflection camera.
Although removing would be a simple solution, at the current stage, no information is available on the relative falsification performance of sensor . Therefore, further investigation is necessary to avoid the risk of wrongly excluding effective sensors.
In step 2, the expected performance of each sensor is assessed and compared with the actual values of falsification performance. In
Figure 9a,
Figure 10a, and
Figure 11a, two CDFs are shown: one (continuous line) using the entire sensor network, and the second one (dashed line) using the network without sensor
. To help compute the maximum distance
, the difference between the CDFs is represented in function of the expected #CMs using dotted lines and dashed areas above the x-axis in
Figure 9b,
Figure 10b, and
Figure 11b.
Figure 9c,
Figure 10c, and
Figure 11c show, in greater detail, the portions of interest of the CDFs. The CMS populations are computed using real measurements; first, while sensor
is omitted #CMs(A), then, using the entire network #CMs(B). The values of the cumulative probability for each condition (points
and
) are available from the corresponding CDFs. Finally,
is used as a metric to define whether the variation in the #CMs—the horizontal distance between
and
—is plausible or suspicious.
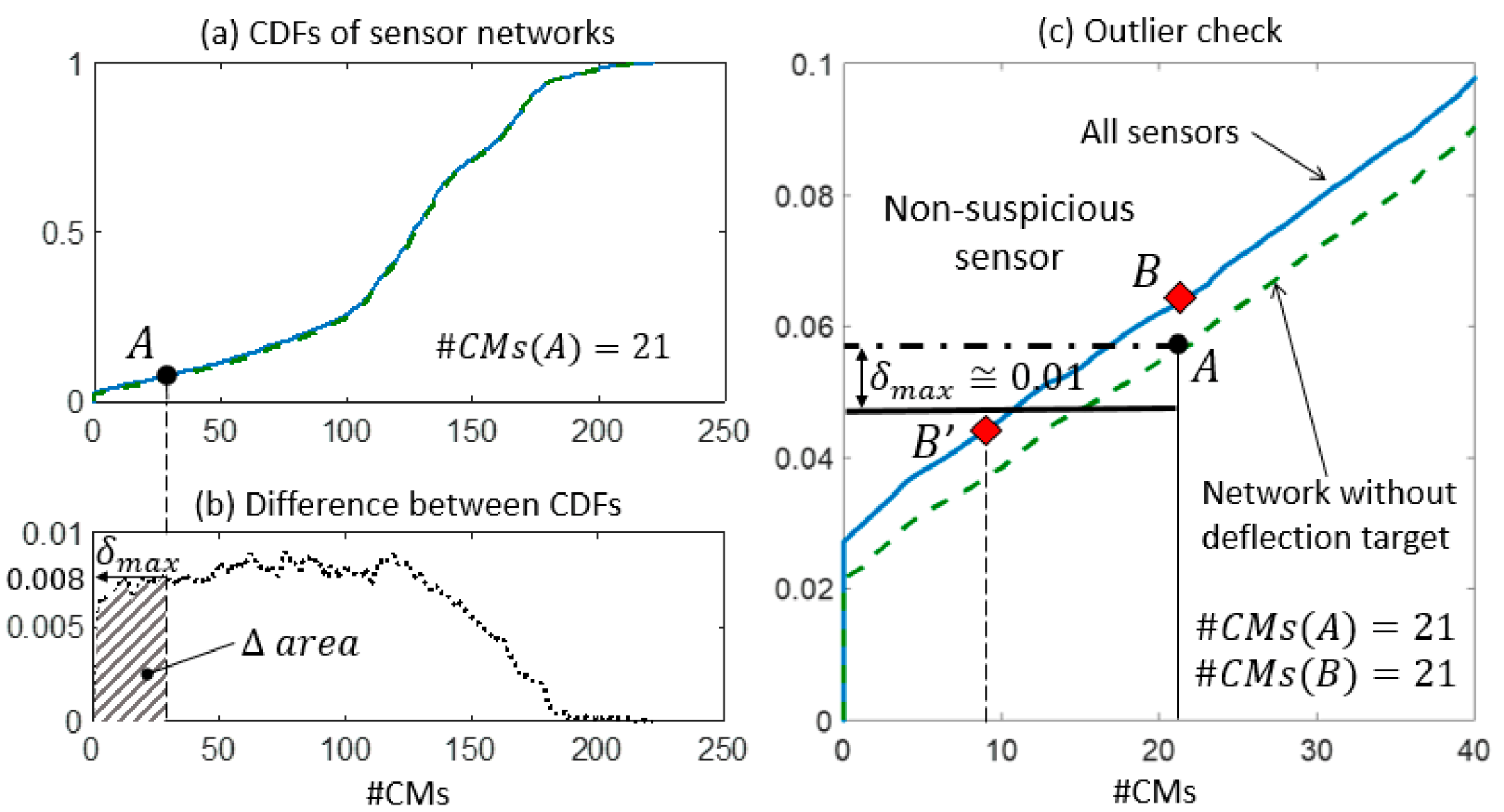
In
Figure 9c, the contribution of sensor
to the falsification performance of the network is shown by the reduction of #CMs from 76 to 21. This variation can be explained by the expected performance of
, which is estimated as a reduction of the cumulative probability of 7% (
. Since the observed reduction is lower than the expected one, the measurement provided by
is deemed to be plausible.
Similarly, in
Figure 10c, the falsification performance of the deflection measurement is analysed. However, this sensor does not contribute to the falsification since no variation of
is observed and #CMs(A) is equal to #CMs(B). Therefore, the information provided by the deflection measurement is redundant with respect to the current sensor configuration. Since the CDF computed using all sensors is always above the CDF obtained when a sensor is removed from the network, point
is located above point
in
Figure 10c. In this situation, the computation of
is superfluous, since no outliers can be detected using the presented methodology. When a redundant sensor is removed from the network, the corresponding CDF is almost coincident with the CDF that is computed using the entire network and low values of
are possible. However, since no variation of
occurs, the redundant sensors are not detected as outliers. For B to become a suspicious sensor, a variation of the candidate model set using real measurements would need to be approximately 50% of the number of candidate models of A (see point B’ in
Figure 10). This illustrates the robustness of the method when the difference between the two CDFs is small.
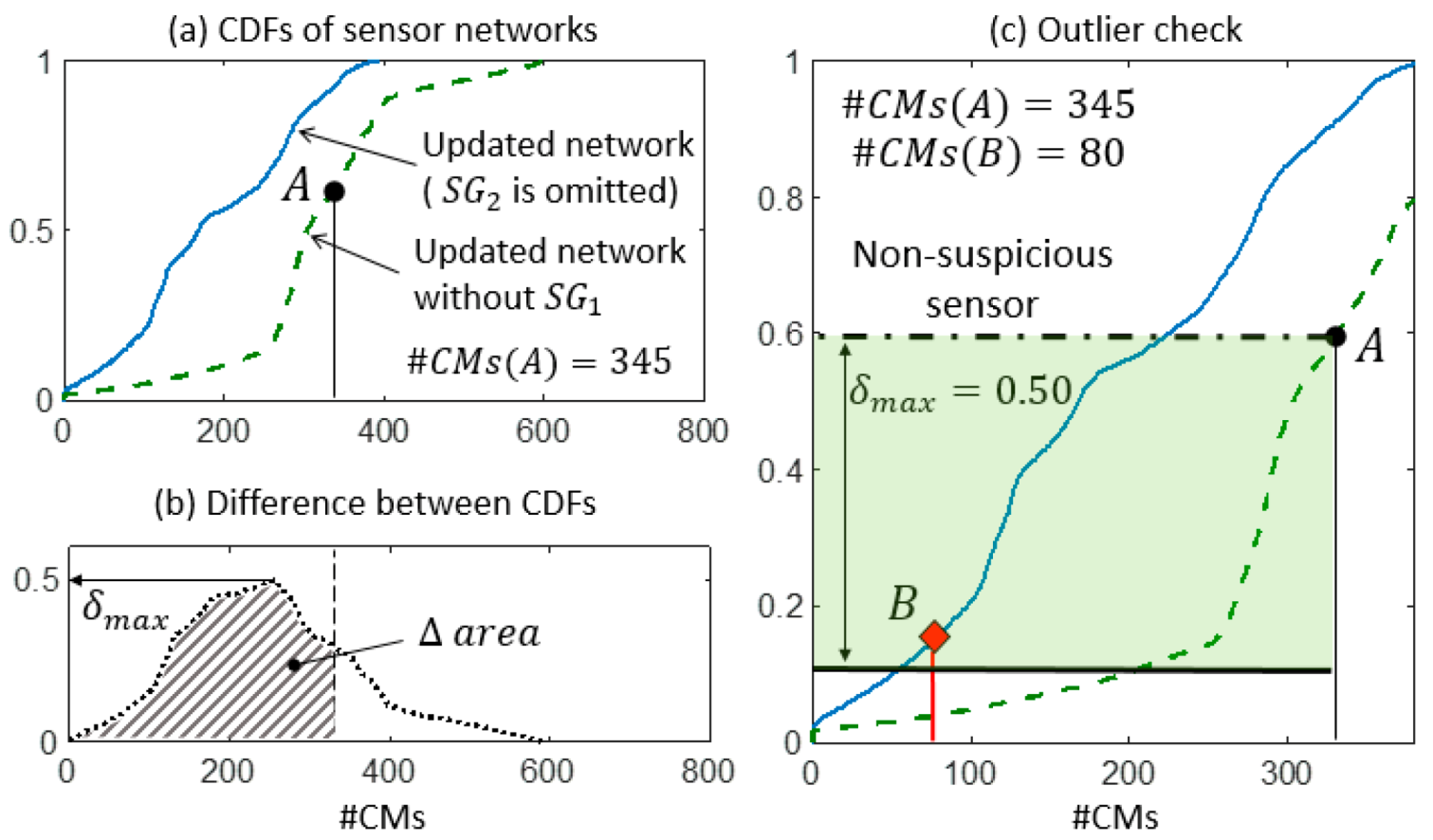
The falsification performance of
is analysed in
Figure 11. In step 1, Sensor
was detected as a possible source of outliers because of its high falsification performance compared with the average of the network.
Figure 11c shows the reduction from #CMs(A) = 80 to #CMs(B) = 21 that occurs when
is included in the network. Such a variation cannot be justified by the reduction of the cumulative probability by 4% (
since point B lies outside the
band. Therefore, the anomalous measurement provided by
should be treated as an outlier.
It is worth noting that a large variation of #CMs is not always connected to anomalous measurements. For example, #CMs variations for sensor and are similar; however, the expected reduction for is almost twice the reduction for . As a conclusion, the metric introduced by the expected reduction provides a rational support in evaluating the CMS variations.
Finally, in step 3, the sensor network is updated by removing sensor
and step 2 is performed again to ensure that no outlier remains.
Figure 12 shows, for example, the outlier-detection check for sensor
when the updated sensor network is employed. Since no sensor provides suspicious variations of
, the updated sensor network is considered to be reliable and the CMS can be computed.
For comparison,
Figure 13 reports results that could be obtained by implementing the outlier-detection strategy proposed in Reference [
32]. The approach proposed by Pasquier et al. requires that the falsification is carried out iteratively while measurements provided by sensors are removed one at a time. The corresponding variations of
are recorded and, in case of anomalous high values of variation being obtained, the measurement is removed from the dataset. However, when two or more sensors produce high variations of
, it is hard to distinguish the powerful sensors from those that are affected by the outliers. On the contrary, the methodology proposed here clearly identifies the anomalous data source in sensor
.
Since sensor is considered to be an outlier, in the remainder of this paper, it is excluded from the sensor configuration.
3.6. Detection of Simulated Outliers
Simulated outliers are used in this section to test the proposed methodology.
Table 6 presents a range of noteworthy scenarios in which outliers have been generated by applying percentage variations to real measurements or by replacing measured values with wrong data.
In all the scenarios, the proposed methodology is able to detect the simulated outliers. In scenario 2, a reduction of 20% of the true measurement leads to the complete falsification of the model class, while in scenario 5, 8 candidate models are found despite the fact that the
measurement increased by about 4 times its original value. The outliers that cause complete falsification (
) can be detected using the model–class validation presented in
Section 2.2.1.
When the variations of
that result from simulated outliers are analysed using the methodology proposed in Reference [
32], several issues are encountered.
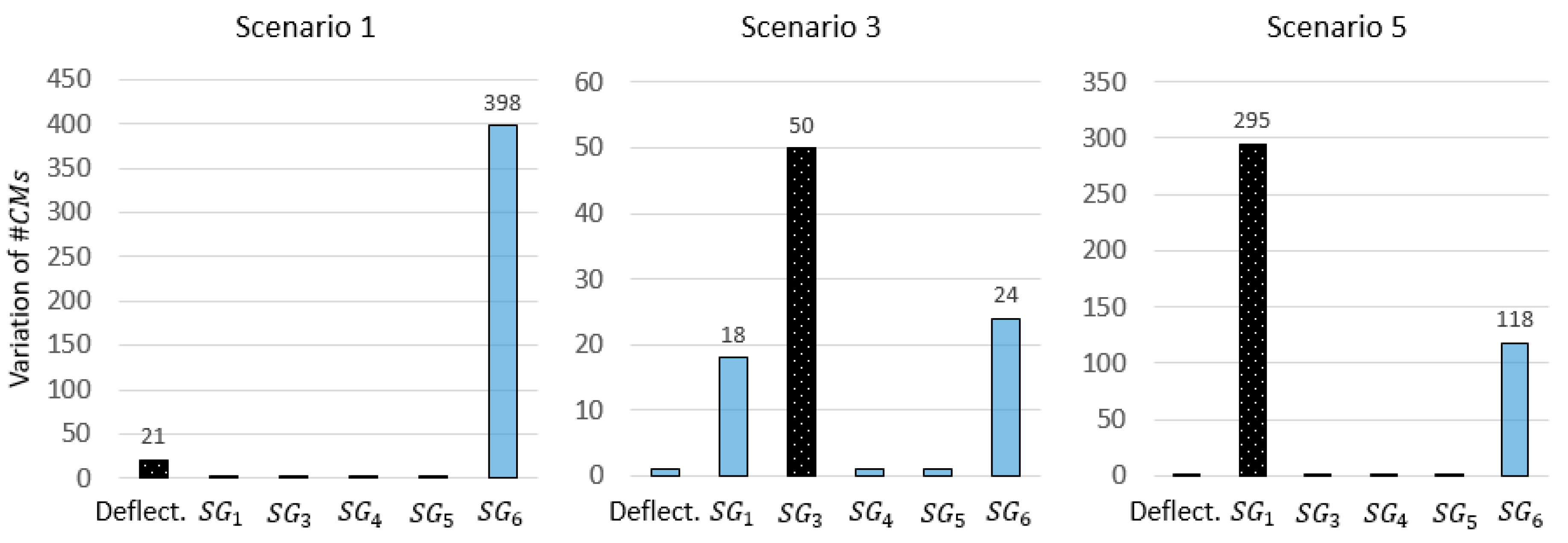
Figure 14 shows the results corresponding to scenarios 1,3, and 5 in
Table 6. Although the two sources of outliers show the highest variation in scenarios 2 and 3, no guidance is provided regarding the other sensors that show high variations. As a result, engineers may conservatively opt to remove all sensors that show high variations, leading to a drastic reduction of the global identification performance.
In scenario 1, sensor clearly exhibits the highest variation of , when the outlier is simulated in the deflection measurement. This results in the wrong identification of the outlier source. Again, the variation of the CMS population alone is not a reliable metric to evaluate the plausibility of the measurement data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}