A Correlation Driven Approach with Edge Services for Predictive Industrial Maintenance

Abstract
:1. Introduction
2. Related Works
2.1. Predictive Industrial Maintenance
2.2. Edge Computing
2.3. Service Relationship
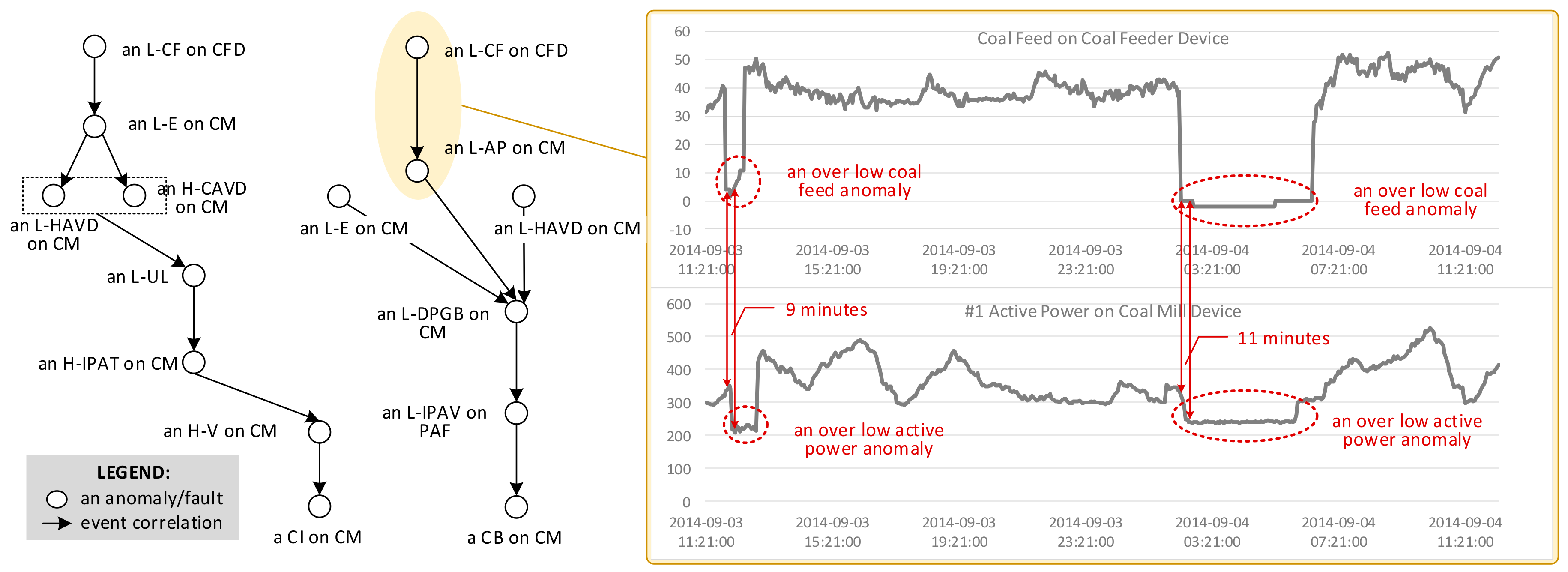
2.4. Event Relationship
2.4.1. Event Correlation
2.4.2. Event Dependency
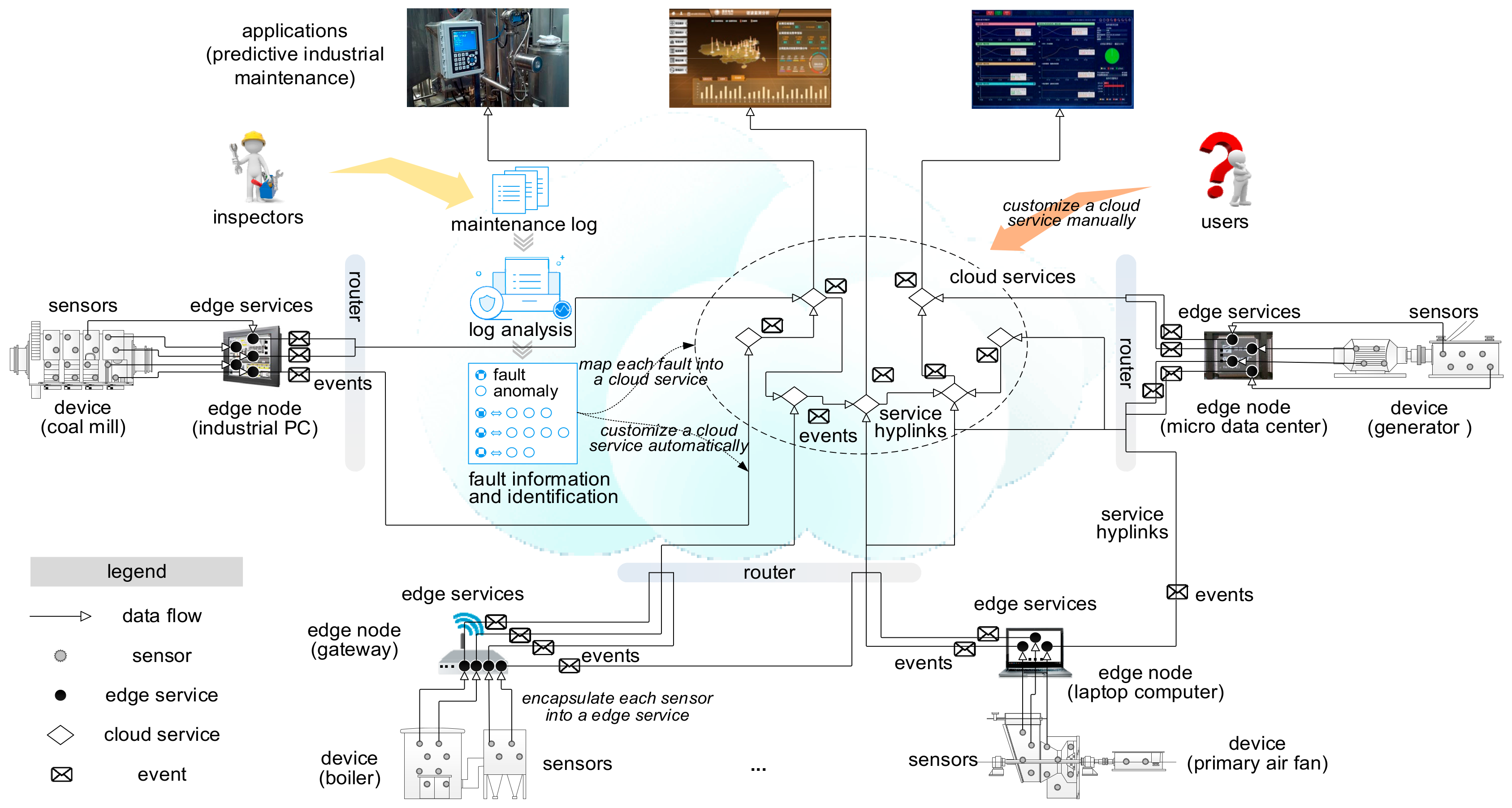
3. Proactive Data Service Model
3.1. Preliminaries
3.2. Proactive Data Service Model Refinement
- edge service: the service model for encapsulating sensor data from one sensor, where event_handler = ϕ, and input_channels is used for receiving sensor data.
- cloud service: the service model for encapsulating a fault, where input_channels s used for receiving service events.
4. Service Hyperlink Model
5. Service Hyperlink Generation
5.1. Problem Analysis
5.2. Service Event Correlation Generating
5.2.1. Frequent Co-Occurrence Pattern Mining
5.2.2. TFCP Mining
5.2.3. Service Hyperlink Generating
6. Our Predictive Industrial Maintenance Approach
6.1. The Framework of Our Approach
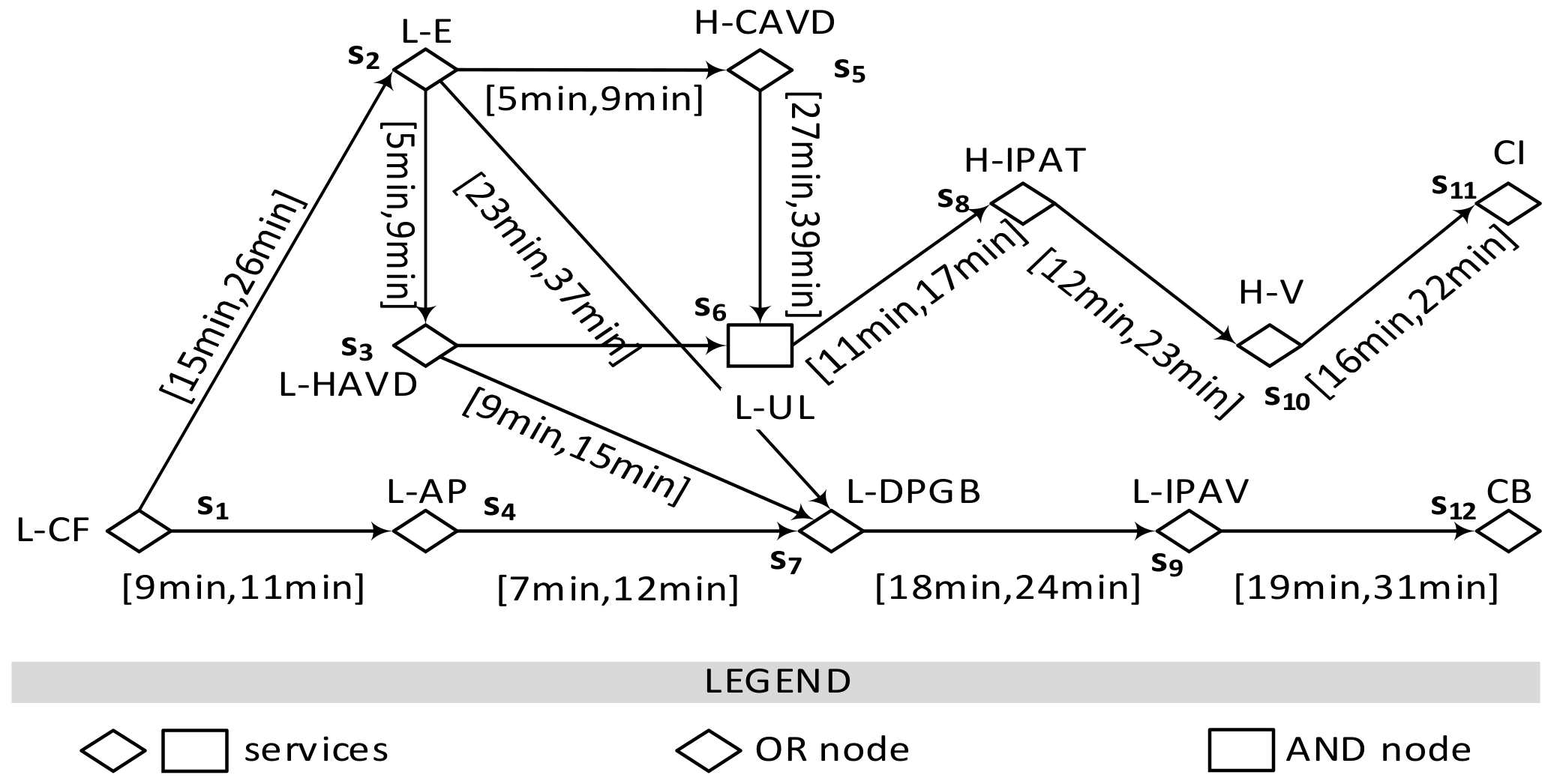
6.2. Proactive Data Service Graph Generating
- V = A∪F, F is the complete set of edge proactive data services, and F is the complete set of cloud proactive data services. Each node v ∈ F should be AND type or OR type. AND type implies that the fault represented by v occurs if all anomalies and faults pointing to v occur; OR type implies that the fault represented by v occurs if any anomaly or fault pointing to v occurs.
- E ⊆ V × F is a non-empty edge set. Each edge e ∈ E is labelled with a propagation time interval Tint.
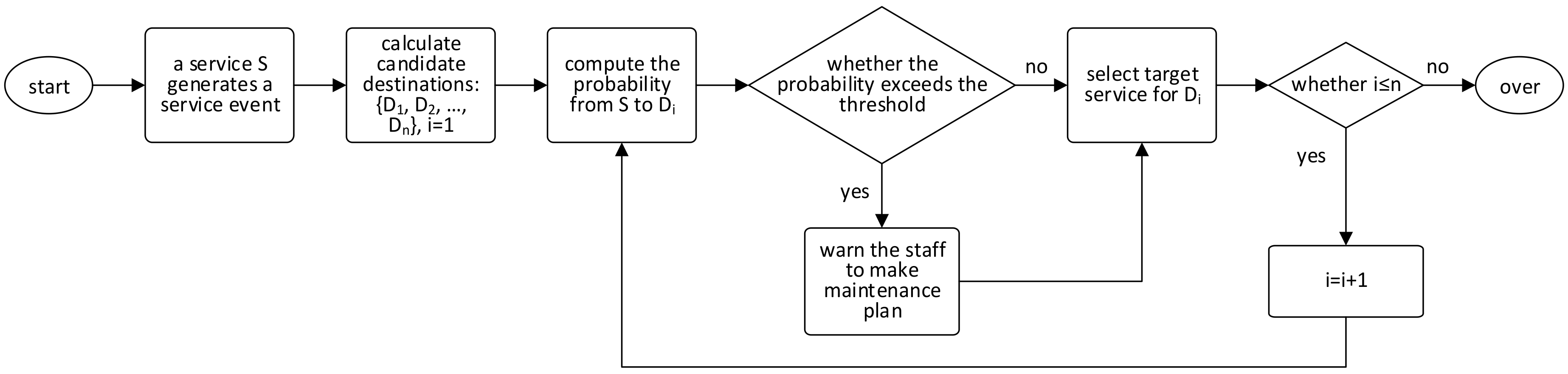
6.3. Event Routing on Proactive Data Service Graph
7. Proactive Data Service Graph Validation
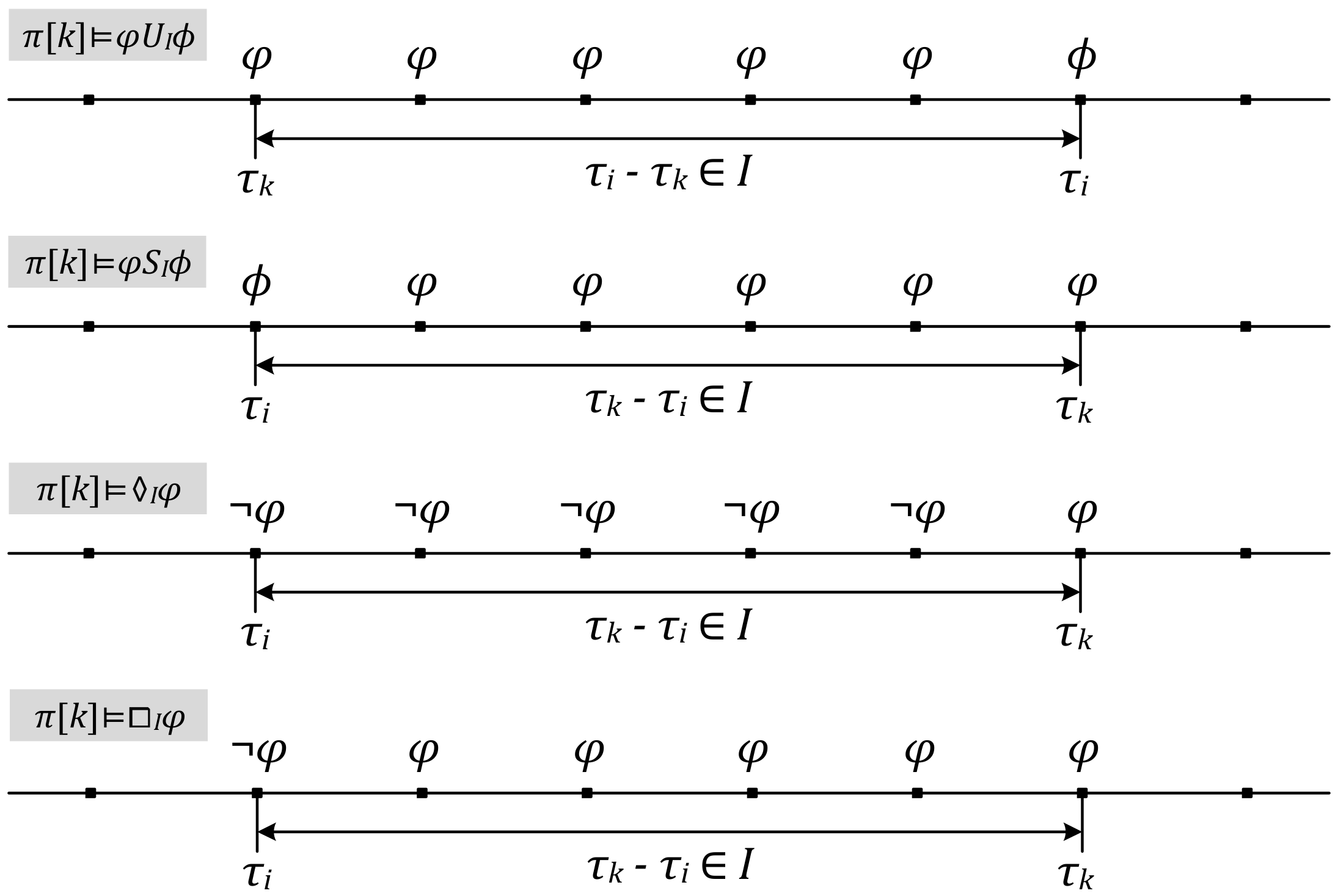
- π[k] ⊨ p, if and only if p is an atomic proposition which is true under π[k].
- π[k] ⊨ ¬φ, if and only if not π[k] ⊨ p.
- π[k] ⊨ φ∧ϕ, if and only if π[k] ⊨ φ and π[k] ⊨ ϕ.
- π[k] ⊨ φ∨ϕ, if and only if π[k] ⊨ φ or π[k] ⊨ ϕ.
- π[k] ⊨ φUIϕ, if and only if ∃i > k, π[i] ⊨ ϕ, τi-τk ∈ I, ∀k ≤ j < i, π[j] ⊨ φ.
- π[k] ⊨ φSIϕ, if and only if ∃i < k, π[i] ⊨ ϕ, τk-τi ∈ I, ∀i < j ≤ k, π[j] ⊨ φ.
- π[k] ⊨ ♢Iφ, if and only if ∃i < k, π[k] ⊨ φ, τk-τi ∈ I, ∀i ≤ j < k, π[j] ⊨ ¬φ.
- π[k] ⊨ ◻Iφ, if and only if ∃i < k, π[i] ⊨ ¬φ, τk-τi ∈ I, ∀i < j ≤ k, π[j] ⊨ φ.
8. Results
8.1. Experiment Setup
8.2. Effectiveness
8.2.1. Effects of Our Approach
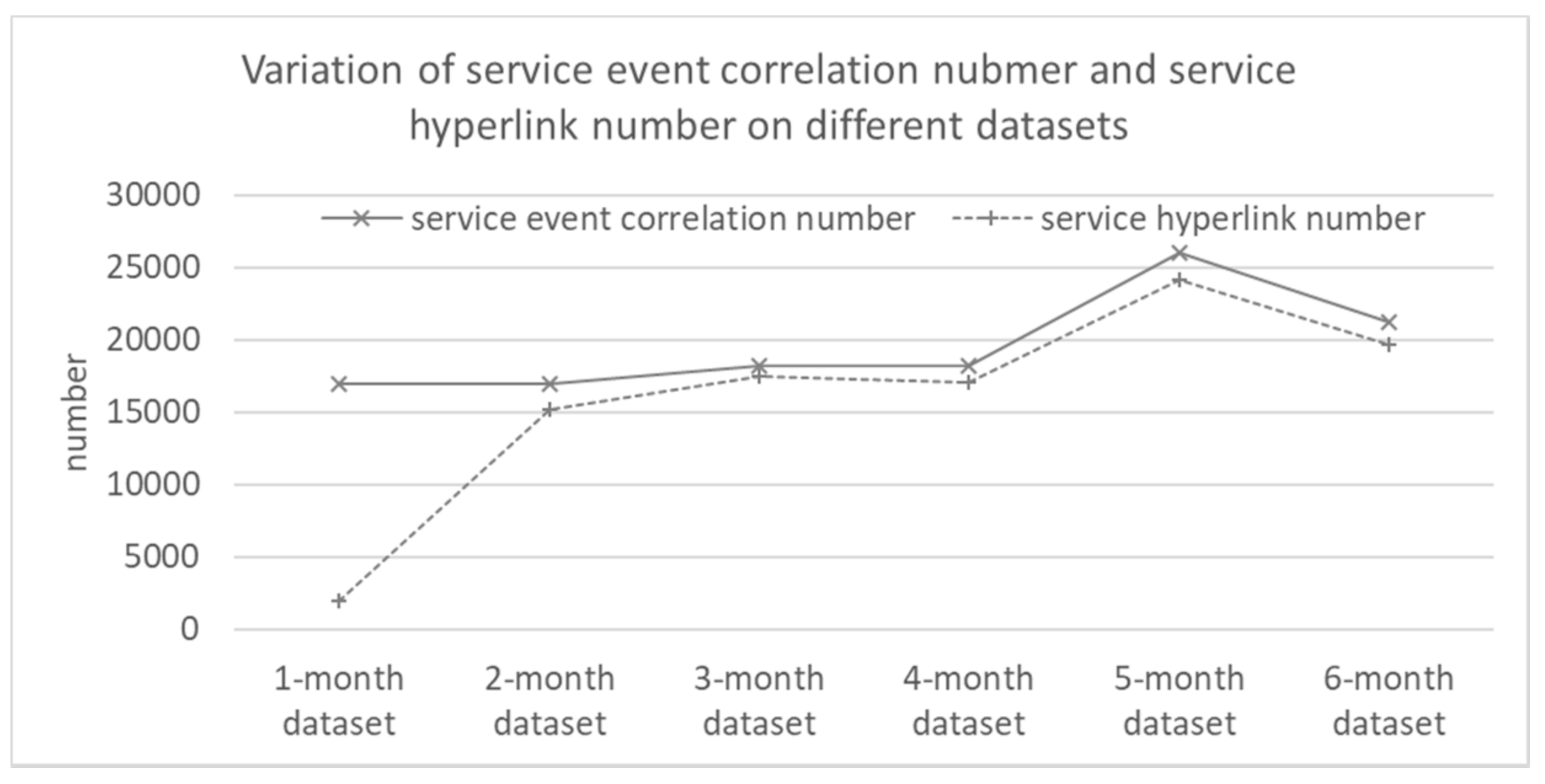
Variation of Correlation Number and Hyperlink Number
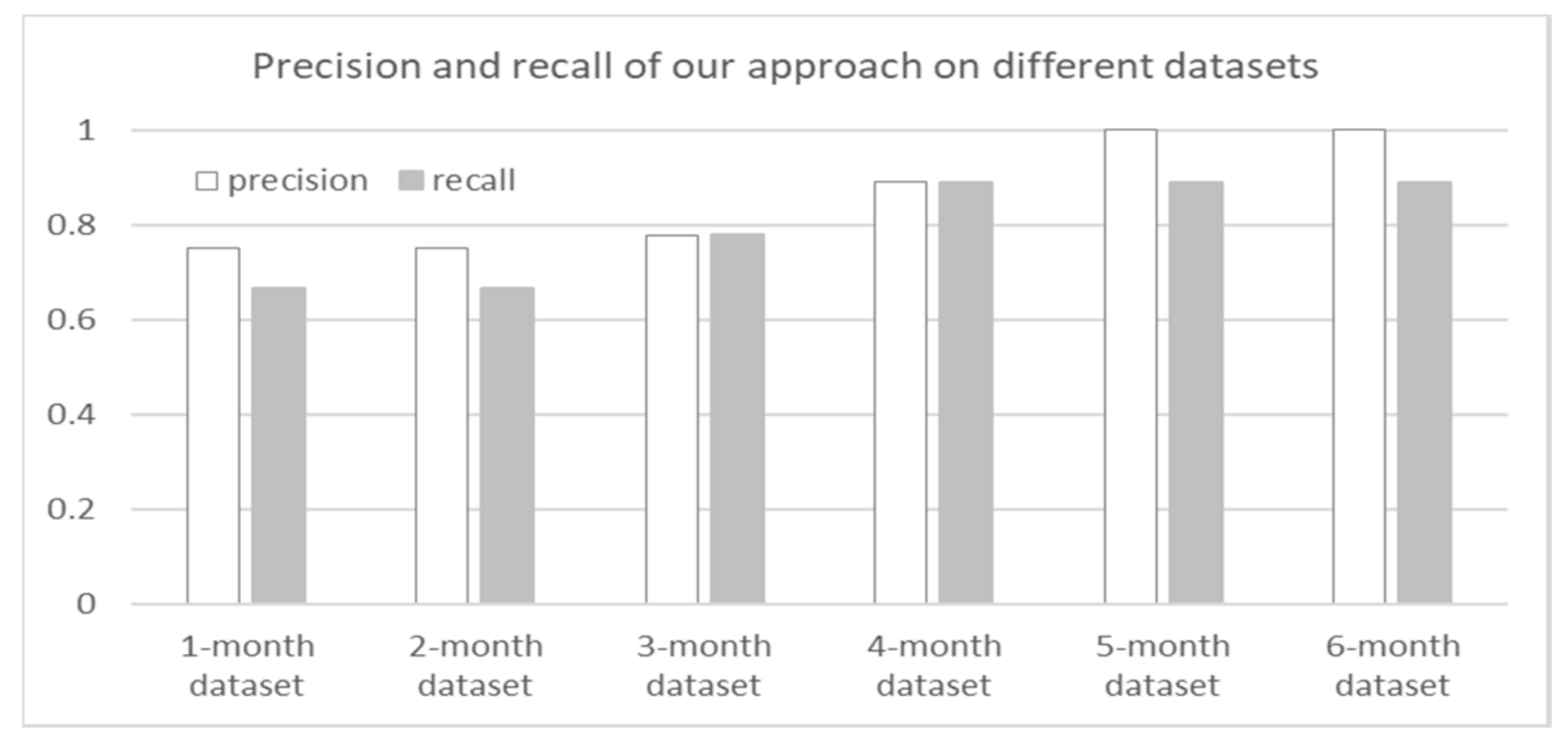
Effectiveness of Our Approach
8.2.2. Comparative Effects of Different Approaches
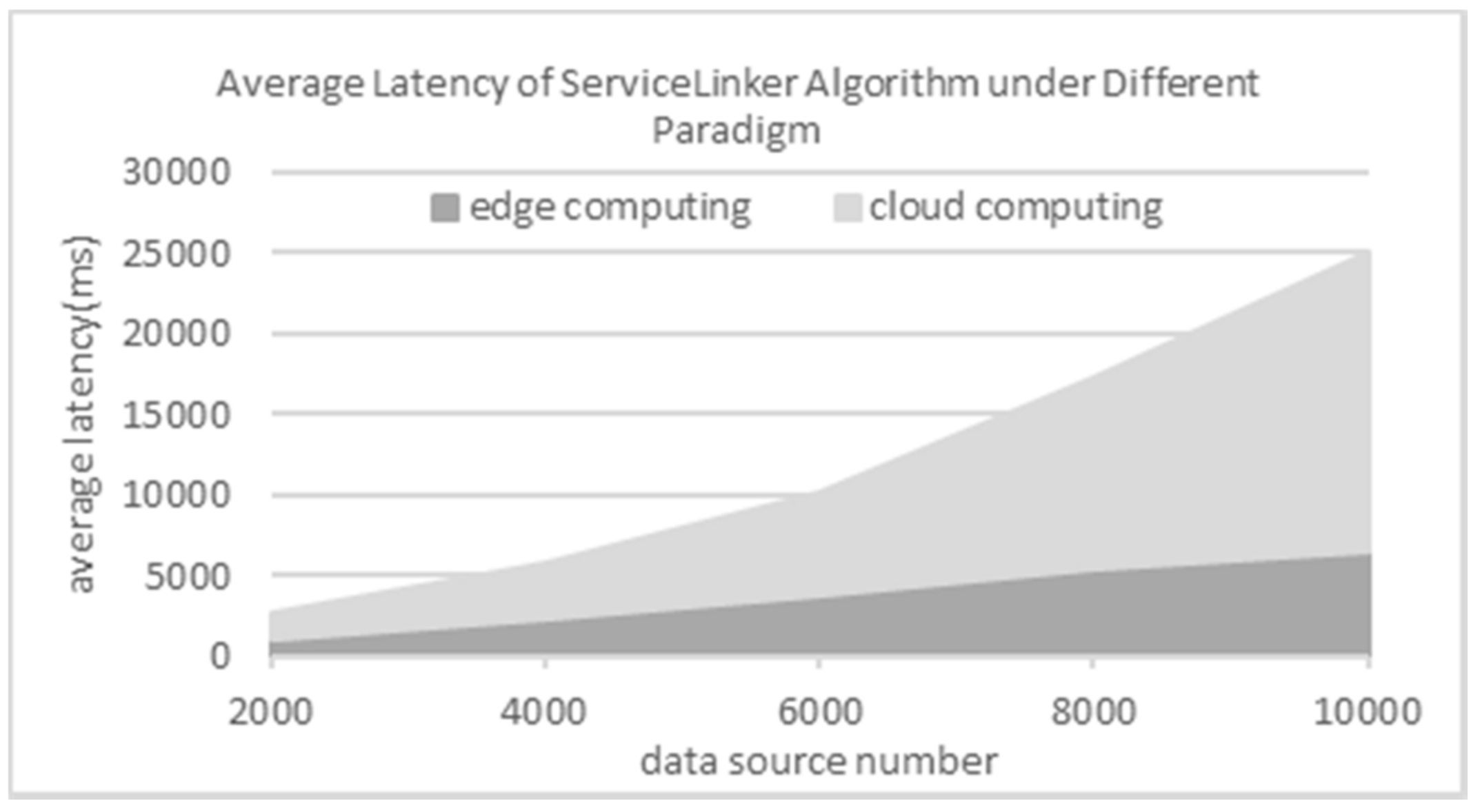
8.3. Efficiency
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Qiu, H.; Liu, Y.; Subrahmanya, N.A.; Li, W. Granger Causality for Time-Series Anomaly Detection. In Proceedings of the 12th IEEE International Conference on Data Mining (ICDM 2012), Brussels, Belgium, 10–13 December 2012; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2012; pp. 1074–1079. [Google Scholar] [CrossRef]
- Yan, Y.; Luh, P.B.; Pattipati, K.R. Fault Diagnosis of HVAC Air-Handling Systems Considering Fault Propagation Impacts among Components. IEEE Trans. Autom. Sci. Eng. 2017, 14, 705–717. [Google Scholar] [CrossRef]
- Ye, R.; Li, X. Collective Representation for Abnormal Event Detection. J. Comput. Sci. Technol. 2017, 32, 470–479. [Google Scholar] [CrossRef]
- Han, Y.; Wang., G.; Yu, J.; Liu, C.; Zhang, Z.; Zhu, M. A Service-based Approach to Traffic Sensor Data Integration and Analysis to Support Community-Wide Green Commute in China. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2648–2657. [Google Scholar] [CrossRef]
- Han, Y.; Liu, C.; Su, S.; Zhu, M.; Zhang, Z.; Zhang, S. A Proactive Service Model Facilitating Stream Data Fusion and Correlation. Int. J. Web Serv. Res. 2017, 14, 1–16. [Google Scholar] [CrossRef]
- Zhu, M.; Liu, C.; Wang, J.; Su, S.; Han, Y. An Approach to Modeling and Discovering Event Correlation for Service Collaboration. In Proceedings of the 15th International Conference on Service Oriented Computing (ICSOC 2017), Malaga, Spain, 13–16 November 2017; Springer: Berlin, Germany, 2017; pp. 191–205. [Google Scholar] [CrossRef]
- Legutko, S. Development Trends in Machines Operation Maintenance. Maint. Reliab. 2009, 42, 8–16. [Google Scholar]
- Królczyk, G.; Legutko, S.; Królczyk, J.; Tama, E. Materials Flow Analysis in the Production Process—Case Study. Appl. Mech. Mater. 2014, 474, 97–102. [Google Scholar] [CrossRef]
- Krolczyk, J.B.; Krolczyk, G.M.; Legutko, S.; Napiorkowski, J.; Hloch, S.; Foltys, J.; Tama, E. Material Flow Optimization—A Case Study in Automotive Industry. Tech. Gaz. 2015, 22, 1447–1456. [Google Scholar] [CrossRef]
- Vianna, W.O.L.; Yoneyama, T. Predictive Maintenance Optimization for Aircraft Redundant Systems Subjected to Multiple Wear Profiles. IEEE Syst. J. 2018, 12, 1170–1181. [Google Scholar] [CrossRef]
- Jung, D.; Zhang, Z.; Winslett, M. Vibration Analysis for IoT Enabled Predictive Maintenance. In Proceedings of the 33rd IEEE International Conference on Data Engineering (ICDE 2017), San Diego, CA, USA, 19–22 April 2017; IEEE Computer Society: Piscataway, NJ, USA, 2012; pp. 1271–1282. [Google Scholar] [CrossRef]
- Simões, A.; Viegas, J.M.; Farinha, J.T.; Fonseca, I. The State of the Art of Hidden Markov Models for Predictive Maintenance of Diesel Engines. Qual. Reliab. Eng. Int. 2017, 33, 2765–2779. [Google Scholar] [CrossRef]
- Wang, J.; Li, C.; Han, S.; Sarkar, S.; Zhou, X. Predictive Maintenance Based on Event-Log Analysis a Case Study. IBM J. Res. Dev. 2017, 61, 121–132. [Google Scholar] [CrossRef]
- Patil, R.B.; Patil, M.A.; Ravi, V.; Naik, S. Predictive Modeling for Corrective Maintenance of Imaging Devices from Machine Logs. In Proceedings of the 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC 2017), Jeju Island, Korea, 11–15 July 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 1676–1679. [Google Scholar] [CrossRef]
- Sipos, R.; Fradkin, D.; Moerchen, F.; Wang, Z. Log-based Predictive Maintenance. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD 2014), New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1867–1876. [Google Scholar] [CrossRef]
- Susto, G.A.; Wan, J.; Pampuri, S.; Zanon, M.; Johnston, A.B.; O’Hara, P.G.; McLoone, S. An Adaptive Machine Learning Decision System for Flexible Predictive Maintenance. In Proceedings of the 10th IEEE International Conference on Automation Science and Engineering (CASE 2014), Taipei, Taiwan, 18–22 August 2014; IEEE Computer Society: Piscataway, NJ, USA, 2014; pp. 806–811. [Google Scholar] [CrossRef]
- Sammouri, W.; Côme, E.; Oukhellou, L.; Aknin, P.; Fonlladosa, C.-E. Pattern Recognition Approach for the Prediction of Infrequent Target Events in Floating Train Data Sequences within a Predictive Maintenance Framework. In Proceedings of the 17th IEEE International Conference on Intelligent Transportation Systems (ITSC 2014), Qingdao, China, 8–11 October 2014; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2014; pp. 918–923. [Google Scholar] [CrossRef]
- Bezerra, C.G.; Costa, B.S.J.; Guedes, L.A.; Angelov, P.P. A Comparative Study of Autonomous Learning Outlier Detection Methods Applied to Fault Detection. In Proceedings of the 16th IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2015), Istanbul, Turkey, 2–5 August 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015; p. 1. [Google Scholar] [CrossRef]
- Baptista, M.; Sankararaman, S.; de Medeiros, I.P.; Nascimento, C.; Prendinger, H.; Henriques, E.M.P. Forecasting Fault Events for Predictive Maintenance Using Data-Driven Techniques and ARMA Modeling. Comput. Ind. Eng. 2018, 115, 41–53. [Google Scholar] [CrossRef]
- Liao, W.; Wang, Y. Data-Driven Machinery Prognostics Approach Using in a Predictive Maintenance Model. J. Comput. 2013, 8, 225–231. [Google Scholar] [CrossRef]
- Cuervoy, E.; Balasubramanian, A.; Cho, D.; Wolman, A.; Saroiu, S.; Chandra, R.; Bahlx, P. Maui: Making Smartphones Last Longer with Code Offload. In Proceedings of the 8th International Conference on Mobile Systems Applications, and Services (MobiSys 2010), San Francisco, CA, USA, 15–18 June 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 49–62. [Google Scholar] [CrossRef]
- Gupta, H.; Nath, S.B.; Chakraborty, S.; Ghosh, S.K. SDFog: A Software Defined Computing Architecture for QoS Aware Service Orchestration over Edge Devices. arXiv, 2016; arXiv:1609.01190v1. [Google Scholar]
- Zhang, T.; Chowdhery, A.; Bahl, P.; Jamieson, K.; Banerjee, S. The Design and Implementation of a Wireless Video Surveillance System. In Proceedings of the 21st Annual International Conference on Mobile Computing and Networking (MobiCom 2015), Paris, France, 7–11 September 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 426–438. [Google Scholar] [CrossRef] [Green Version]
- Yuriyama, M.; Kushida, T. Sensor-Cloud Infrastructure-Physical Sensor Management with Virtualized Sensors on Cloud Computing. In Proceedings of the 13th International Conference on Network-Based Information Systems (NBiS 2010), Gifu, Japan, 14–16 September 2010; IEEE Computer Society: Piscataway, NJ, USA, 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Dong, F.; Wu, K.; Srinivasan, V.; Wang, J. Copula Analysis of Latent Dependency Structure for Collaborative Auto-scaling of Cloud Services. In Proceedings of the 25th International Conference on Computer Communication and Networks (ICCCN 2016), Waikoloa, HI, USA, 1–4 August 2016; IEEE Computer Society: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Hashmi, K.; Malik, Z.; Najmi, E.; Alhosban, A.; Medjahed, B. A Web Service Negotiation Management and QoS Dependency Modeling Framework. ACM Trans. Manag. Inf. Syst. 2016, 7, 1–33. [Google Scholar] [CrossRef]
- Wang, R.; Peng, Q.; Hu, X. Software Architecture Construction and Collaboration Based on Service Dependency. In Proceedings of the 2015 IEEE 19th International Conference on Computer Supported Cooperative Work in Design (CSCWD 2015), Calabria, Italy, 6–8 May 2015; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015; pp. 91–96. [Google Scholar] [CrossRef]
- Pourmirza, S.; Dijkman, R.; Grefen, P. Correlation Miner: Mining Business Process Models and Event Correlations without Case Identifiers. Int. J. Coop. Inf. Syst. 2017, 26, 1–32. [Google Scholar] [CrossRef]
- Pourmirza, S.; Dijkman, R.; Grefen, P. Correlation Mining: Mining Process Orchestrations without Case Identifiers. In Proceedings of the 13th International Conference on Service Oriented Computing (ICSOC 2015), Goa, India, 16–19 November 2016; Springer: Berlin, Germany, 2016; pp. 237–252. [Google Scholar] [CrossRef]
- Cheng, L.; Van Dongen, B.F.; Van Der Aalst, W.M.P. Efficient Event Correlation over Distributed Systems. In Proceedings of the 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID 2017), Madrid, Spain, 14–17 May 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Reguieg, H.; Benatallah, B.; Nezhad, H.R.M.; Toumani, F. Event Correlation Analytics: Scaling Process Mining Using Mapreduce-Aware Event Correlation Discovery Techniques. IEEE Trans. Serv. Comput. 2015, 8, 847–860. [Google Scholar] [CrossRef]
- Friedberg, I.; Skopik, F.; Settanni, G.; Fiedler, R. Combating Advanced Persistent Threats: From Network Event Correlation to Incident Detection. Comput. Secur. 2015, 48, 35–57. [Google Scholar] [CrossRef]
- Fu, S.; Xu, C. Quantifying event correlations for proactive failure management in networked computing systems. J. Parallel Distrib. Comput. 2010, 70, 1100–1109. [Google Scholar] [CrossRef] [Green Version]
- Forkan, A.R.M.; Khalil, I. PEACE-Home: Probabilistic Estimation of Abnormal Clinical Events Using Vital Sign Correlations for Reliable Home-Based Monitoring. Pervasive Mob. Comput. 2017, 38, 296–311. [Google Scholar] [CrossRef]
- Forkan, A.R.M.; Khalil, I. A Probabilistic Model for Early Prediction of Abnormal Clinical Events Using Vital Sign Correlations in Home-Based Monitoring. In Proceedings of the 14th IEEE International Conference on Pervasive Computing and Communications (PerCom 2016), Sydney, Australia, 14–19 March 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Song, W.; Jacobsen, H.A.; Ye, C.; Ma, X. Process Discovery from Dependence-Complete Event Logs. IEEE Trans. Serv. Comput. 2016, 9, 714–727. [Google Scholar] [CrossRef]
- Plantevit, M.; Robardet, C.; Scuturici, V.M. Graph Dependency Construction Based on Interval-Event Dependencies Detection in Data Streams. Intell. Data Anal. 2016, 20, 223–256. [Google Scholar] [CrossRef]
- Kansal, A.; Nath, S.; Liu, J.; Zhao, F. SenseWeb: An Infrastructure for Shared Sensing. IEEE Multimedia 2007, 14, 8–13. [Google Scholar] [CrossRef]
- Aberer, K.; Hauswirth, M.; Salehi, A. Infrastructure for Data Processing in Large-scale Interconnected Sensor Networks. In Proceedings of the International Conference on Mobile Data Management (MDM 2007), Mannheim, Germany, 7–11 May 2007; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2007; pp. 198–205. [Google Scholar] [CrossRef]
- Xu, B.; Xu, L.; Cai, H.; Xie, C.; Hu, J.; Bu, F. Ubiquitous Data Accessing Method in IoT-based Information System for Emergency Medical Services. IEEE Trans. Ind. Inform. 2014, 10, 1578–1586. [Google Scholar] [CrossRef]
- Perera, C.; Talagala, D.; Liu, C.; Estrella, J. Energy-efficient Location and Activity-aware On-demand Mobile Distributed Sensing Platform for Sensing as a Service in IoT Clouds. IEEE Trans. Comput. Soc. Syst. 2015, 2, 171–181. [Google Scholar] [CrossRef]
- Potocnik, M.; Juric, M. Towards Complex Event Aware Services as Part of SOA. IEEE Trans. Serv. Comput. 2014, 7, 486–500. [Google Scholar] [CrossRef]
- Bucchiarone, A.; De Sanctis, M.; Marconi, A.; Pistore, M.; Traverso, P. Design for Adaptation of Distributed Service-based Systems. In Proceedings of the 13th International Conference on Service-Oriented Computing (ICSOC 2015), Goa, India, 16–19 November 2015; Springer: Berlin, Germany, 2015; pp. 383–393. [Google Scholar] [CrossRef]
- Cheng, B.; Zhu, D.; Zhao, S.; Chen, J. Situation-aware IoT Service Coordination Using the Event-driven SOA Paradigm. IEEE Trans. Netw. Serv. Manag. 2016, 13, 349–361. [Google Scholar] [CrossRef]
- Brauckhoff, D.; Dimitropoulos, X.; Wagner, A.; Salamatian, K. Anomaly Extraction in Backbone Networks Using Association Rules. IEEE/ACM Trans. Netw. 2012, 20, 1788–1799. [Google Scholar] [CrossRef] [Green Version]
- Asghar, N. Automatic Extraction of Causal Relations from Natural Language Texts: A Comprehensive Survey. arXiv, 2016; arXiv:1605.07895. [Google Scholar]
- Yagci, A.M.; Aytekin, T.; Gurgen, F.S. Scalable and Adaptive Collaborative Filtering by Mining Frequent Item Co-Occurrences in a User Feedback Stream. Eng. Appl. Artif. Intell. 2017, 58, 171–184. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, X.; Liu, Y.; Li, W.; Pei, J. Mining Frequent Co-Occurrence Patterns Across Multiple Data Streams. In Proceedings of the 18th International Conference on Extending Database Technology (EDBT 2015), Brussels, Belgium, 23–27 March 2015; OpenProceedings.org, University of Konstanz, University Library: Konstanz, Germany, 2015; pp. 73–84. [Google Scholar] [CrossRef]
- Mooney, C.H.; Roddick, J.F. Sequential Pattern Mining - Approaches and Algorithms. ACM Comput. Surv. 2013, 45, 1–39. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.-C.; Cheung, D.W. Enhancing Effectiveness of Outlier Detections for Low Density Patterns. In Proceedings of the 6th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2002), Taipei, Taiwan, 6–8 May 2002; Springer: Berlin, Germany, 2002; pp. 535–548. [Google Scholar] [CrossRef]
- Yeh, C.-C. M.; Zhu, Y.; Ulanova, L.; Begum, N.; Ding, Y.; Dau, H.A.; Zimmerman, Z.; Silva, D.F.; Mueen, A.; Keogh, E. Time Series Joins, Motifs, Discords and Shapelets: A Unifying View That Exploits the Matrix Profile. Data Min. Knowl. Discov. 2018, 32, 83–123. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Explanation | |
|---|---|---|
| device | CFD | coal feeder |
| CM | coal mill | |
| PAF | primary air fan | |
| sensor/service | AP | active power |
| BT | bear temperature | |
| CAVD | cold air valve degree | |
| CF | coal feed | |
| DPGB | differential pressure of grinding bowl | |
| DPSF | differential pressure of strainer filter | |
| E | electricity | |
| HAVD | hot air valve degree | |
| IAP | inlet air pressure | |
| IPAP | inlet primary air pressure | |
| IPAT | inlet primary air temperature | |
| IPAV | inlet primary air volume | |
| OTT | oil tank temperature | |
| UL | unit load | |
| V | vibration | |
| anomaly/fault/event type | CB | coal blockage |
| CI | coal interruption | |
| H-CAVD | over high cold air valve degree | |
| H-DPSF | over high differential pressure of strainer filter | |
| H-HAVD | over high hot air valve degree | |
| H-IPAT | over high inlet primary air temperature | |
| H-V | over high vibration | |
| L-AP | over low active power | |
| L-BT | over low bear temperature | |
| L-CF | over low coal feed | |
| L-DPGB | over low differential pressure of grinding bowl | |
| L-E | over low electricity | |
| L-HAVD | over low hot air valve degree | |
| L-IAP | over low inlet air pressure | |
| L-IPAP | over low inlet primary air pressure | |
| L-IPAT | over low inlet primary air temperature | |
| L-IPAV | over low inlet primary air volume | |
| L-OTT | over low oil tank temperature | |
| L-UL | over low unit load |
| Fault Type | Associated Anomalies | Conf 1 | |
|---|---|---|---|
| L-IPAV fault on a PAF device | AE12 | L-IPAT, L-HAVD, L-IPAP. | 100.00% |
| AE2 | L-E on CM. | 100.00% | |
| AE3 | L-IPAT, L-IPAP. | 80.00% | |
| L-IPAP fault on a PAF device | AE1 | H-CAVD, L-OTT. | 86.96% |
| CB fault on a CM device | AE1 | H-HAVD, L-IAP. | 100.00% |
| AE2 | L-IPAT. | 88.89% | |
| H-DPSF fault on a CM device | AE1 | L-BT on PAF. | 100.00% |
| Fault Type | L-IPAV | L-IPAP | CB | L-DPSF | ||||
|---|---|---|---|---|---|---|---|---|
| Approaches | AE1 | AE2 | AE3 | AE1 | AE1 | AE2 | AE1 | |
| Our Approach | 70 | 58 | 82 | 152 | 63 | 96 | 132 | |
| Range-based Approach | - 1 | 12 | 9 | - | 15 | 2 | - | |
| Outlier Detection Approach | 18 | 21 | - | 31 | 23 | 19 | 33 | |
| Discord Discovery Approach | - | 21 | 19 | 31 | 35 | 26 | 34 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Liu, C. A Correlation Driven Approach with Edge Services for Predictive Industrial Maintenance. Sensors 2018, 18, 1844. https://doi.org/10.3390/s18061844
Zhu M, Liu C. A Correlation Driven Approach with Edge Services for Predictive Industrial Maintenance. Sensors. 2018; 18(6):1844. https://doi.org/10.3390/s18061844
Chicago/Turabian StyleZhu, Meiling, and Chen Liu. 2018. "A Correlation Driven Approach with Edge Services for Predictive Industrial Maintenance" Sensors 18, no. 6: 1844. https://doi.org/10.3390/s18061844
APA StyleZhu, M., & Liu, C. (2018). A Correlation Driven Approach with Edge Services for Predictive Industrial Maintenance. Sensors, 18(6), 1844. https://doi.org/10.3390/s18061844