Data Fusion Architectures for Orthogonal Redundant Inertial Measurement Units

Abstract
:1. Introduction
2. Data Fusion Algorithms
2.1. Centralized Architecture
2.2. Distributed Architecture
2.3. Baseline Architecture
3. Fault Detection and Isolation Algorithm
4. Performance Analysis
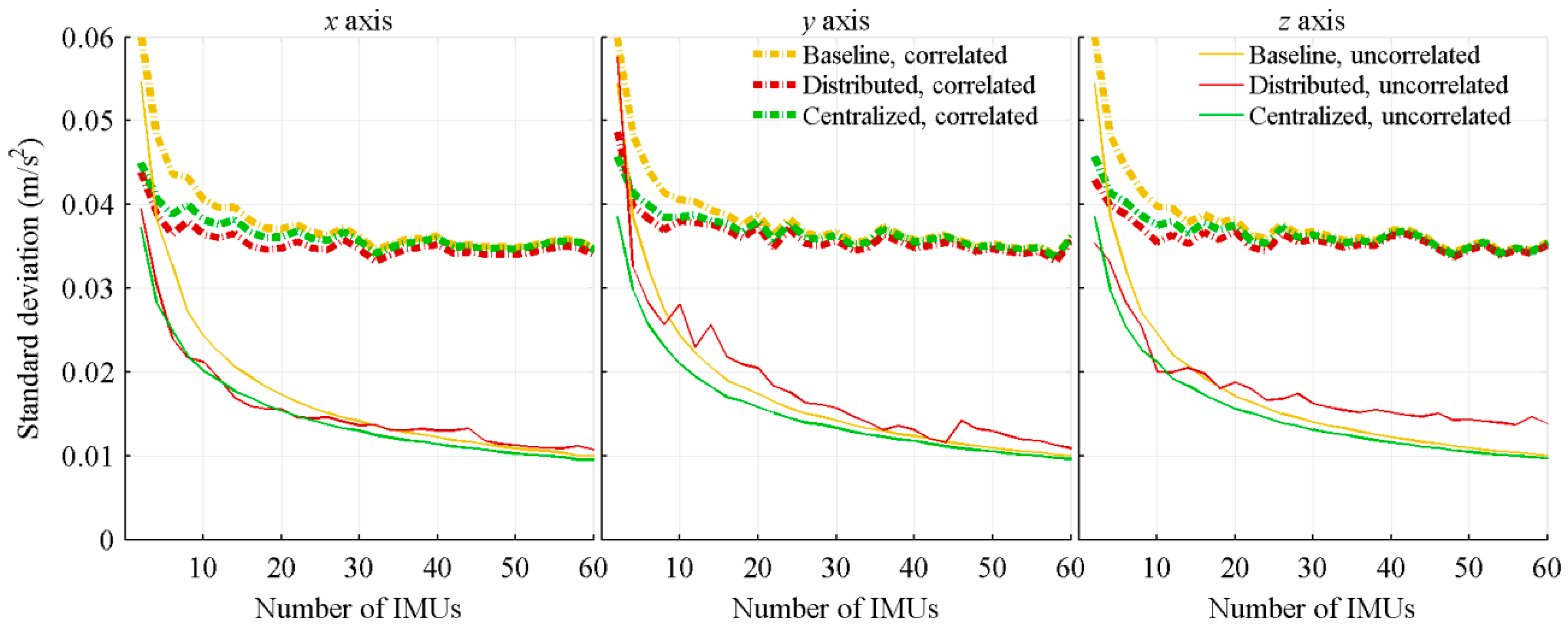
4.1. Estimation Precision and Accuracy
4.1.1. Relative Locations of the IMUs
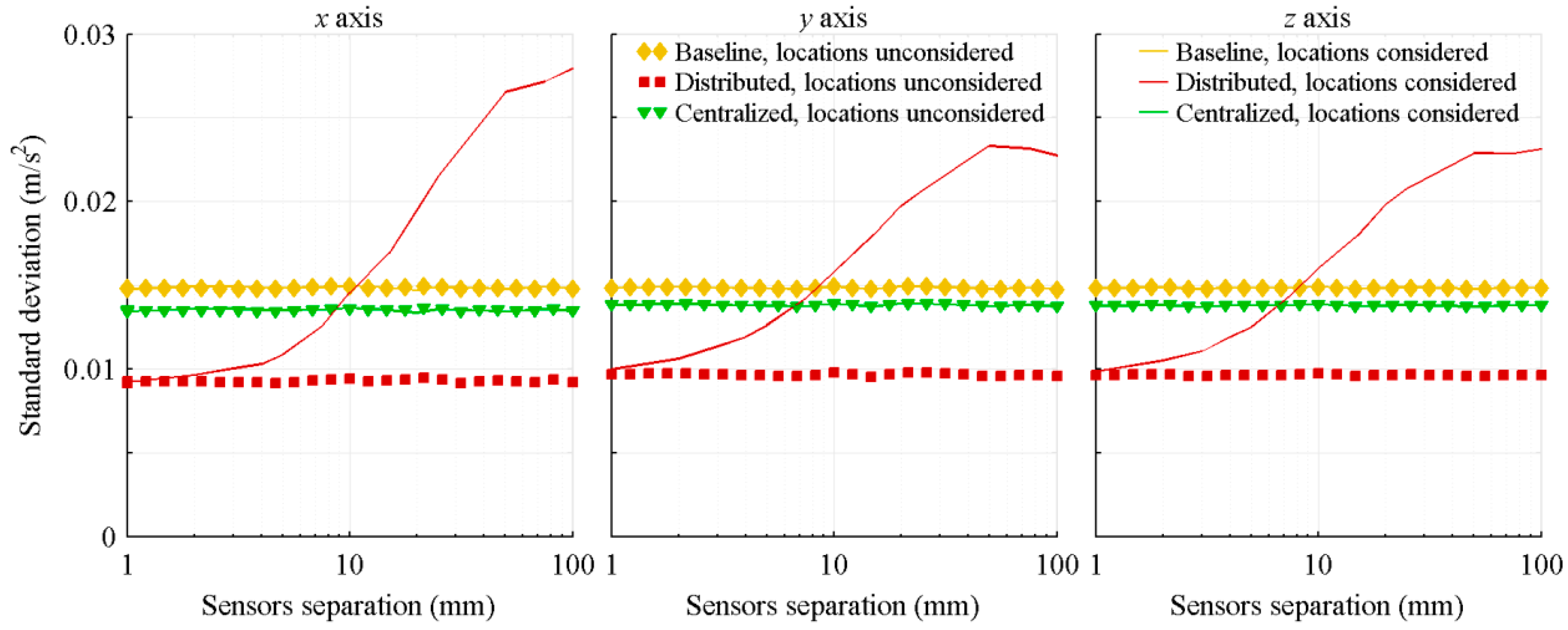
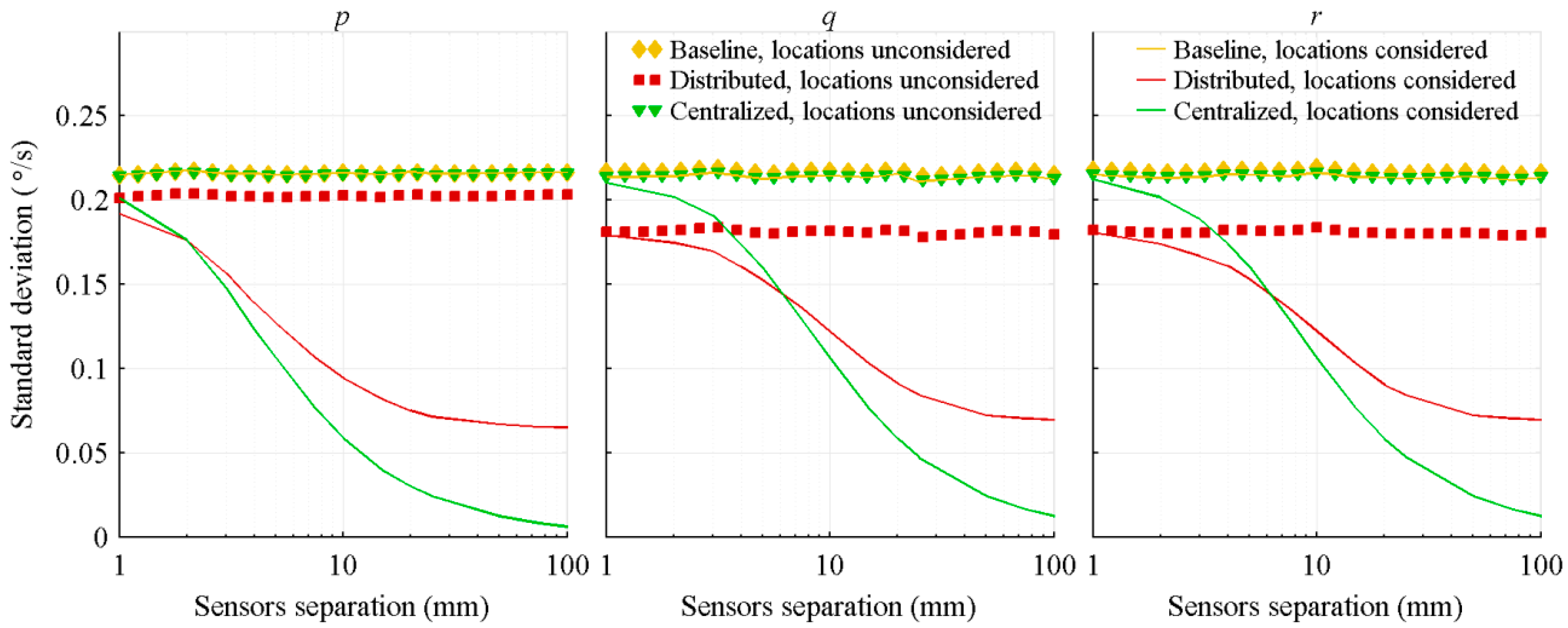
4.1.2. Relative Distance between the IMUs
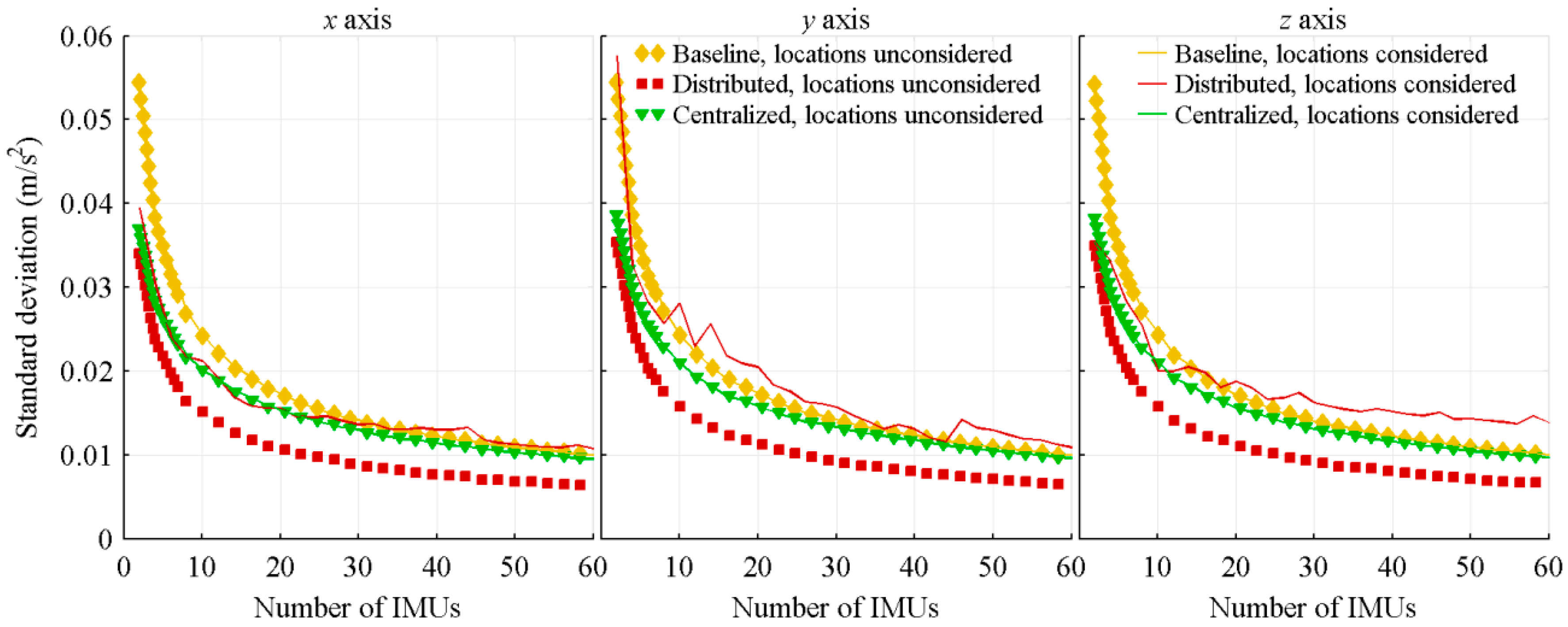
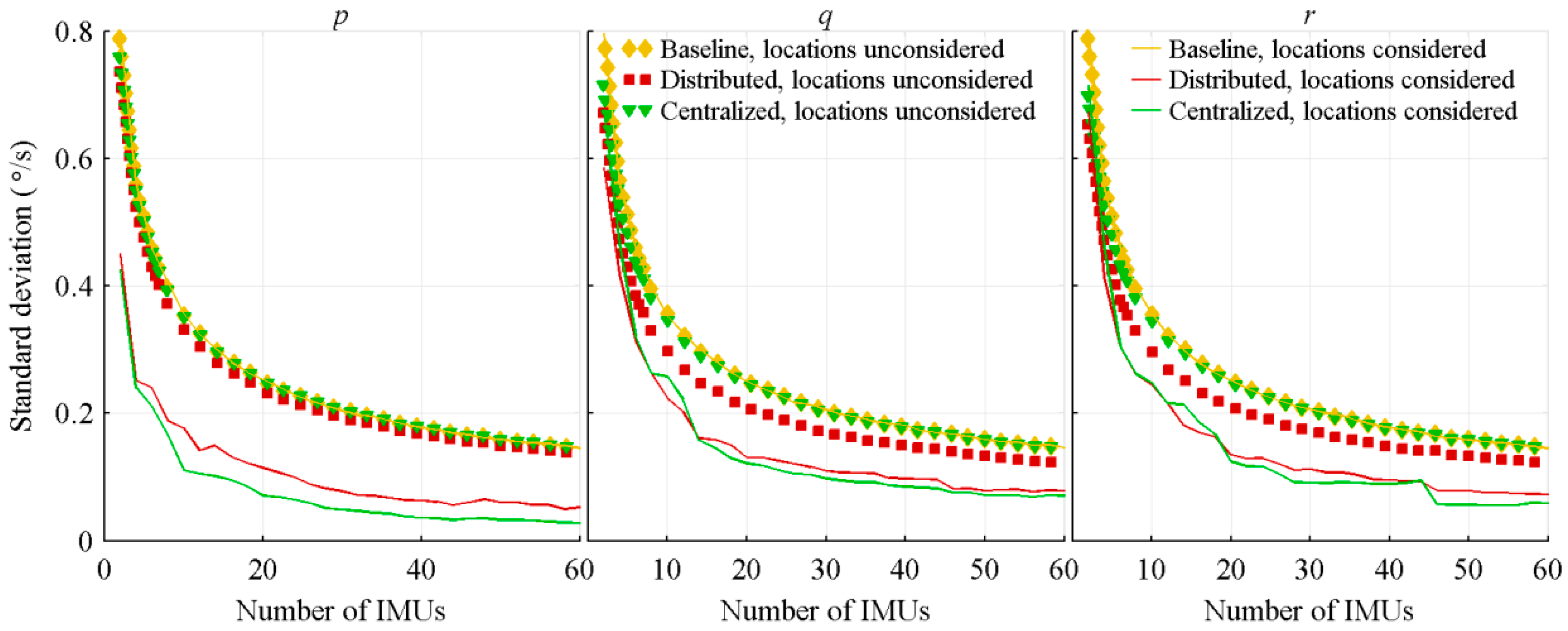
4.1.3. Number of Near Symmetrically Located IMUs
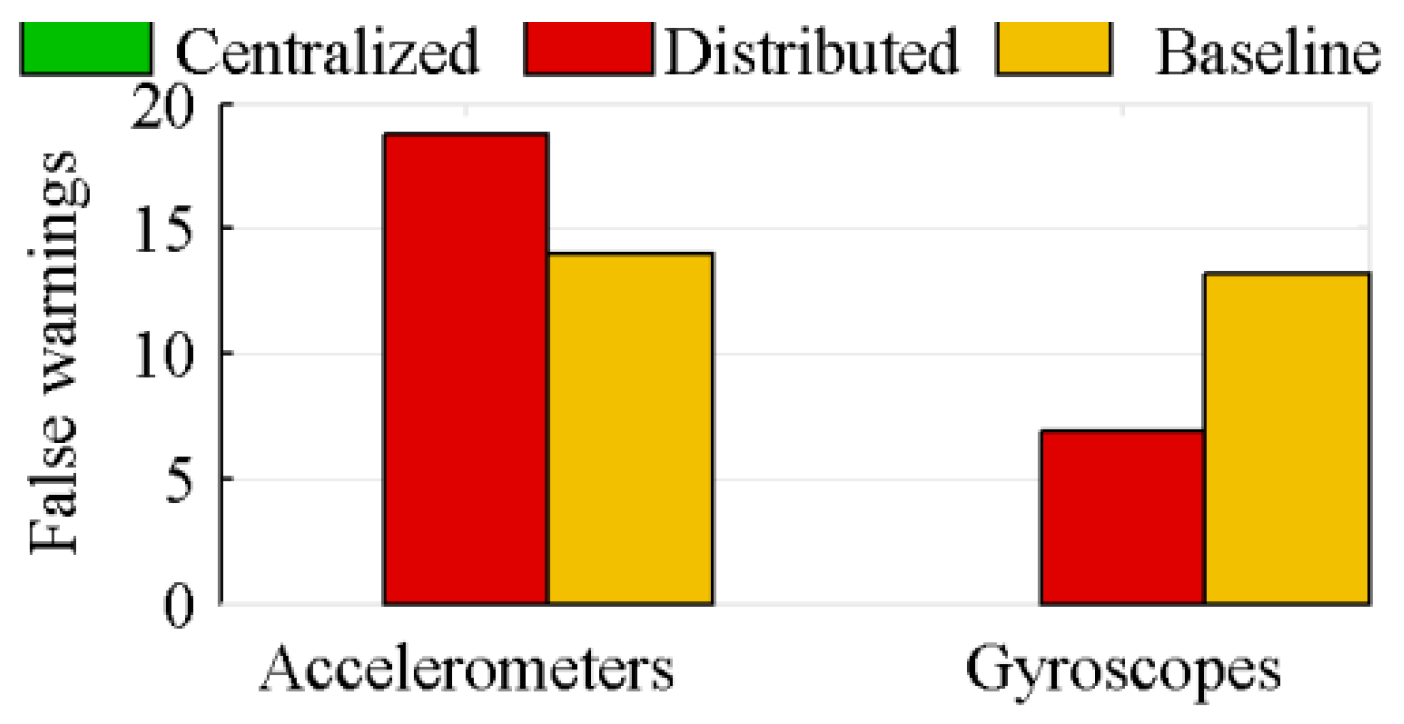
4.2. Fault Detection
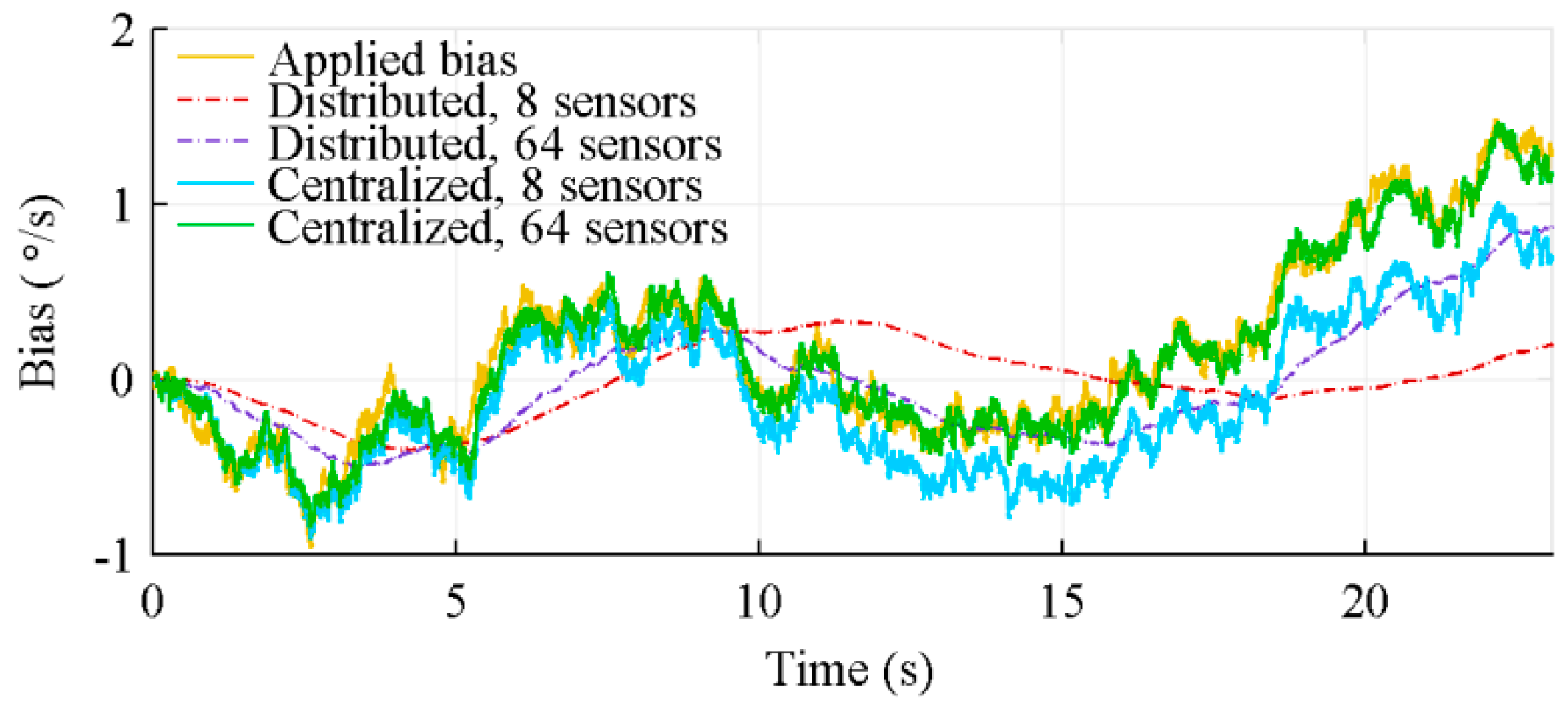
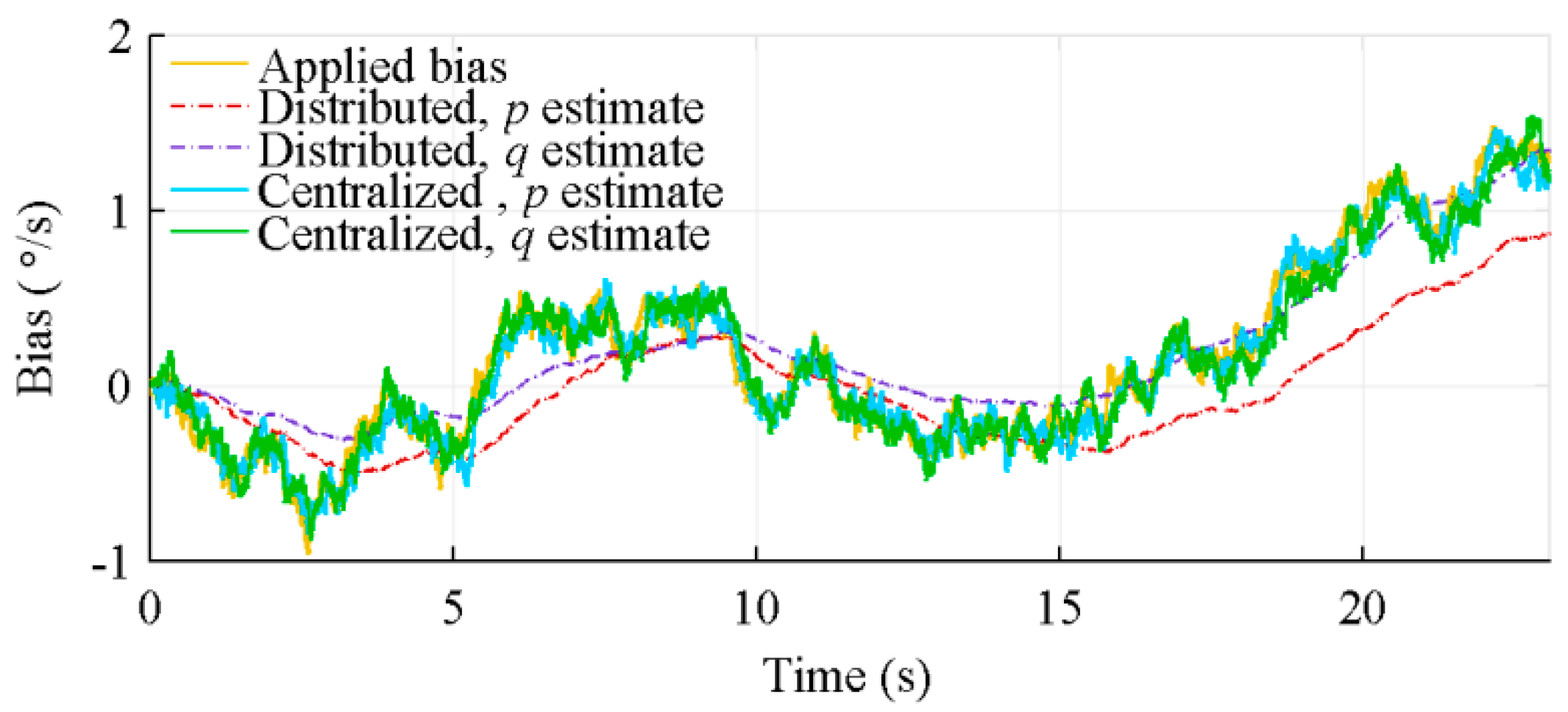
4.3. Bias Estimation
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Nilsson, J.-O.; Skog, I. Inertial sensors arrays—A literature review. In Proceedings of the 2016 European Navigation Conference, Helsinki, Finland, 30 May–2 June 2016. [Google Scholar] [CrossRef]
- Bancroft, J.; Lachapelle, G. Data Fusion Algorithms for Multiple Inertial Measurement Units. Sensors 2011, 11, 6771–6798. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pesja, A. Optimum Skewed Redundant Inertial Navigators. AIAA J. 1974, 12, 899–902. [Google Scholar] [CrossRef]
- Waegli, A.; Guerrier, S.; Skaloud, J. Redundant MEMS-IMU integrated with GPS for Performance Assessment in Sports. In Proceedings of the IEEE/ION PLANS 2008, Monterey, CA, USA, 5–8 May 2008. [Google Scholar] [CrossRef]
- Shim, D.-S.; Yang, C.-K. Optimal Configuration of Redundant Inertial Sensors for Navigation and FDI Performance. Sensors 2010, 10, 6497–6512. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giroux, R. Capteurs bas de Gamme et Systèmes de Navigation Inertielle: Nouveaux Paradigmes D’application, Ph.D. Thesis, École de Technologie Supérieure, Montréal, QC, Canada, 17 September 2004. [Google Scholar]
- Levy, L.J. Suboptimality of Cascaded and Federated Kalman Filters. In Proceedings of the 52nd Annual Meeting of the Institute of Navigation, Cambridge, MA, USA, 19–21 June 1996. [Google Scholar]
- Allerton, D.; Jia, H. A Review of Multisensor Fusion Methodologies for Aircraft Navigation Systems. J. Navig. 2005, 58, 405–417. [Google Scholar] [CrossRef]
- Lawrence, P.; Berarducci, M. Comparison of federated and centralized Kalman filters with fault detection considerations. In Proceedings of the IEEE PLANS 1994, Las Vegas, NV, USA, 11–15 April 1994. [Google Scholar] [CrossRef]
- Sukkarieh, S.; Gibbens, P.; Groscholsky, B.; Willis, K.; Durrant-Whyte, H.F. A Low-Cost, Redundant Inertial Measurement Unit for Unmanned Air Vehicles. Int. J. Robot. Res. 2000, 19, 1089–1103. [Google Scholar] [CrossRef]
- Miller, M.M.; Soloviev, A.; Uijt de Haag, M.; Veth, M.; Raquet, J.; Klausutis, T.J.; Touma, J.E. Navigation in GPS Denied Environments: Feature-Aided Inertial Systems; Air Force Research Laboratory: Eglin AFB, FL, USA, 2010. [Google Scholar]
- Bachrach, A.; Prentice, S.; He, R.; Roy, N. RANGE—Robust Autonomous Navigation in GPS-denied. J. Field Robot. 2011, 28, 644–666. [Google Scholar] [CrossRef]
- Wu, A.D.; Johnson, E.N.; Kaess, M.; Dellaert, F.; Chowdhary, G. Autonomous Flight in GPS-Denied Environmnets Using Monocular Vision and Inertial Sensors. J. Aerosp. Inf. Syst. 2013, 10, 172–186. [Google Scholar] [CrossRef]
- Grigorie, T.L.; Botez, R.M.; Sandu, D.G.; Grigorie, O. Experimental Testing of Data Fusion Algorithm for Miniaturized Inertial Sensors in Redundant Configurations. In Proceedings of the 2014 International Conference on Mathematical Methods, Mathematical Models and Simulation in Science and Engineering, Interlaken, Switzerland, 22–24 February 2014. [Google Scholar]
- Chen, T. Design and Analysis of a Fault-Tolerant Coplanar Gyro-Free Inertial Measurement Unit. J. Microelectromechan. Syst. 2008, 17, 201–212. [Google Scholar] [CrossRef]
- Skog, I.; Nilsson, J.-O.; Händel, P.; Nehorai, A. Inertial Sensor Arrays, Maximum Likelihood, and Cramér–Rao Bound. IEEE Trans. Signal Process. 2016, 64, 4218–4227. [Google Scholar] [CrossRef]
- Sabatini, A. Kalman-Filter-Based Orientation Determination Using Inertial/Magnetic Sensors: Observabiliy Analysis and Performance Evaluation. Sensors 2011, 11, 9182–9206. [Google Scholar] [CrossRef] [PubMed]
- Tereshkov, V. A Simple Observer for Gyro and Accelerometer Biases in Land Navigation Systems. J. Navig. 2015, 68, 635–645. [Google Scholar] [CrossRef] [Green Version]
- Noureldin, A.; Karamat, T.; Eberts, M.; El-Sahfie, A. Performance Enhancement of MEMS-Based INS/GPS Integration for Low-Cost Navigation Applications. IEEE Trans. Veh. Technol. 2009, 58, 1077–1096. [Google Scholar] [CrossRef]
- Jiang, C.; Xue, L.; Chang, H.; Yuan, G.; Yuan, W. Signal Processing of MEMS Gyroscope Arrays to Improve Accuracy Using a 1st Order Markov for Rate Signal Modeling. Sensors 2012, 12, 1720–1737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwaab, M.; Reginya, S.; Sikora, A.; Abramov, E. Measurement analysis of multiple MEMS sensor array. In Proceedings of the 24th Saint Petersburg International Conference on Integrated Navigation Systems, St. Petersburg, Russia, 29–31 May 2017. [Google Scholar] [CrossRef]
- Woodman, O. An. Introduction to Inertial Navigation; University of Cambridge: Cambridge, MA, USA, 2007. [Google Scholar]
- Zipfel, P.H. Modeling and Simulation of Aerospace Vehicle Dynamics, 2nd ed.; AIAA Inc.: Reston, VA, USA, 2000; ISBN 1-56347-875-7. [Google Scholar]
- Crassidis, J.L.; Junkins, J.L. Optimal Estimation of Dynamic Systems; Chapman & Hall/CRC: Boca Raton, FL, USA, 2011; ISBN 1-58488-391-X. [Google Scholar]
- Ray, A.; Phoba, S. Calibration and estimation of redundant signals. In Proceedings of the 2002 American Control Conference, Anchorage, AK, USA, 8–10 May 2002. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IMUs Distribution | Axis | Locations Considered (m/s2) | Locations Unconsidered (m/s2) | ||||
|---|---|---|---|---|---|---|---|
| Centralized | Distributed | Baseline | Centralized | Distributed | Baseline | ||
| Symmetric | axis | 0.0136 | 0.0146 | 0.0150 | 0.0136 | 0.0094 | 0.0150 |
| axis | 0.0139 | 0.0158 | 0.0149 | 0.0139 | 0.0098 | 0.0149 | |
| axis | 0.0139 | 0.0160 | 0.0149 | 0.0139 | 0.0097 | 0.0149 | |
| Random | axis | 0.0142 | 0.0150 | 0.0171 | 0.0158 | 0.0124 | 0.0169 |
| axis | 0.0142 | 0.0174 | 0.0173 | 16.01 | 16.11 | 16.01 | |
| axis | 0.0142 | 0.0173 | 0.0174 | 22.93 | 23.08 | 22.93 | |
| IMUs Distribution | Axis | Locations Considered (m/s2) | Locations Unconsidered (m/s2) | ||||
|---|---|---|---|---|---|---|---|
| Centralized | Distributed | Baseline | Centralized | Distributed | Baseline | ||
| Symmetric | axis | 0.0135 | 0.0279 | 0.0148 | 0.0135 | 0.0092 | 0.0148 |
| axis | 0.0137 | 0.0227 | 0.0148 | 0.0137 | 0.0096 | 0.0148 | |
| axis | 0.0138 | 0.0231 | 0.0148 | 0.0138 | 0.0096 | 0.0148 | |
| Random | axis | 0.0151 | 0.0377 | 0.0876 | 0.0839 | 0.0833 | 0.0842 |
| axis | 0.0144 | 0.0416 | 0.0910 | 160.14 | 161.12 | 160.16 | |
| axis | 0.0143 | 0.0469 | 0.0914 | 229.29 | 230.75 | 229.32 | |
| Architecture | Locations Considered | Locations Unconsidered |
|---|---|---|
| Centralized | Invert a matrix | Invert 6 matrices |
| Distributed | Invert matrices | Compute divisions |
| Baseline | Compute cross-products | Mean computations |
© 2018 Her Majesty the Queen in Right of Canada, as represented by the Minister of National Defence. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gagnon, E.; Vachon, A.; Beaudoin, Y. Data Fusion Architectures for Orthogonal Redundant Inertial Measurement Units. Sensors 2018, 18, 1910. https://doi.org/10.3390/s18061910
Gagnon E, Vachon A, Beaudoin Y. Data Fusion Architectures for Orthogonal Redundant Inertial Measurement Units. Sensors. 2018; 18(6):1910. https://doi.org/10.3390/s18061910
Chicago/Turabian StyleGagnon, Eric, Alexandre Vachon, and Yanick Beaudoin. 2018. "Data Fusion Architectures for Orthogonal Redundant Inertial Measurement Units" Sensors 18, no. 6: 1910. https://doi.org/10.3390/s18061910
APA StyleGagnon, E., Vachon, A., & Beaudoin, Y. (2018). Data Fusion Architectures for Orthogonal Redundant Inertial Measurement Units. Sensors, 18(6), 1910. https://doi.org/10.3390/s18061910