Enhancing the Discrimination Ability of a Gas Sensor Array Based on a Novel Feature Selection and Fusion Framework


Abstract
:1. Introduction
- (1)
- We propose a feature selection method, which couples the filter and wrapper strategies, to evaluate the subfeatures of a gas sensor array using two indicators, i.e., separability and dissimilarity, as well as the KNN classifier, for effectively describing the characteristics of different odors under the premise of reducing the data redundancy as much as possible.
- (2)
- We propose a weighted feature fusion framework combining information according to a classification dominance strategy, for achieving better description of odor and increasing the accuracy of final classification.
- (3)
- The novel feature selection and feature fusion framework can not only improve the recognition rate of a gas sensor array, but also greatly suppress the negative effects of sensor drift effect on gas identification.
2. Methodology
2.1. Feature Selection
2.1.1. Separability Index
2.1.2. Dissimilarity Index
2.1.3. Feature Selection Algorithm
| Algorithm 1. Feature Selection |
| Input: Original feature matrix with M-dimensional features. Output: Selected feature subset with D-dimensional features . Procedure: 1: D = 1. Compute of each dimension of the original feature matrix and record the score1: . Choose the feature with the largest as the first element of the optimal feature subset S. Then, the remaining feature element is . 2: do Step 1: D = D + 1. Then, choose a feature element from in turn, and combine the element with S into a new feature subset , all subset make up a new feature matrix . Compute the class separability index () of each feature subset in the and the is defined as . Step 2: For the formed new feature matrix in Step 1, obtain subsets. Then, compute the average of the pairwise dissimilarity of all the subsets. Step 3: For each subset, compute the score2 defined as , which reflects whether the feature subset is appropriate. Step 4: Put the feature element with the largest value of into and reset the remaining feature element . Step 5: Input the selected feature subset with D-dimensional features into the classifier. Then, the classification accuracy of the D-dimensional features will be obtained. End while until the number of selected elements D reaches M. 3: Choose the best classification accuracy from as the final accuracy for this kind of feature after feature selection. If but , can be considered as the optimal feature dimension. Return: = {s1, s2, …, sM}. Note: The larger score2 means the feature is more beneficial to increasing classification performance. |
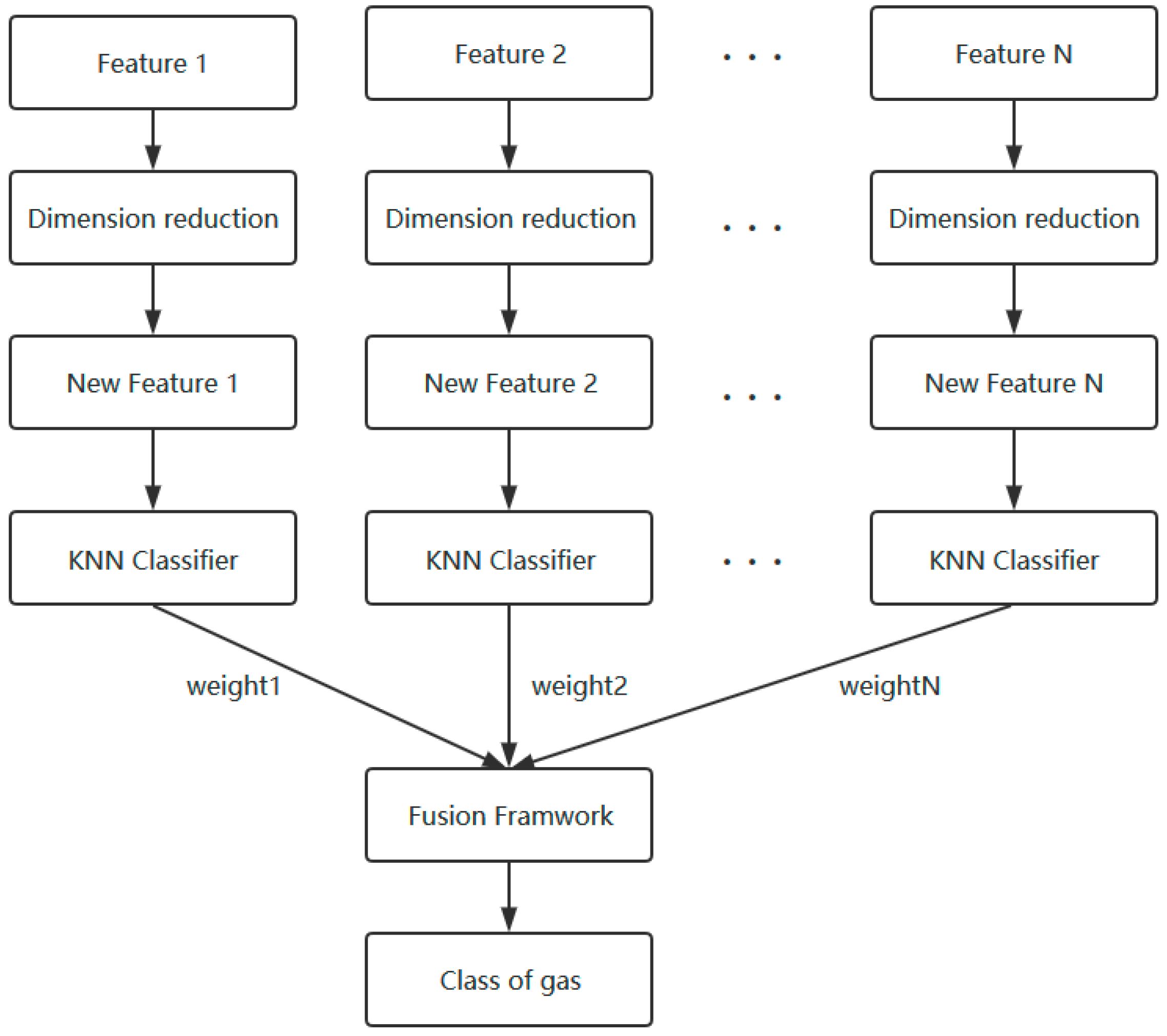
2.2. Feature Fusion Framwork
3. Description of Experimental Data
3.1. Dataset I
3.2. Dataset II
4. Results and Discussion
4.1. The Optimal Value of k and the Distance Metrics
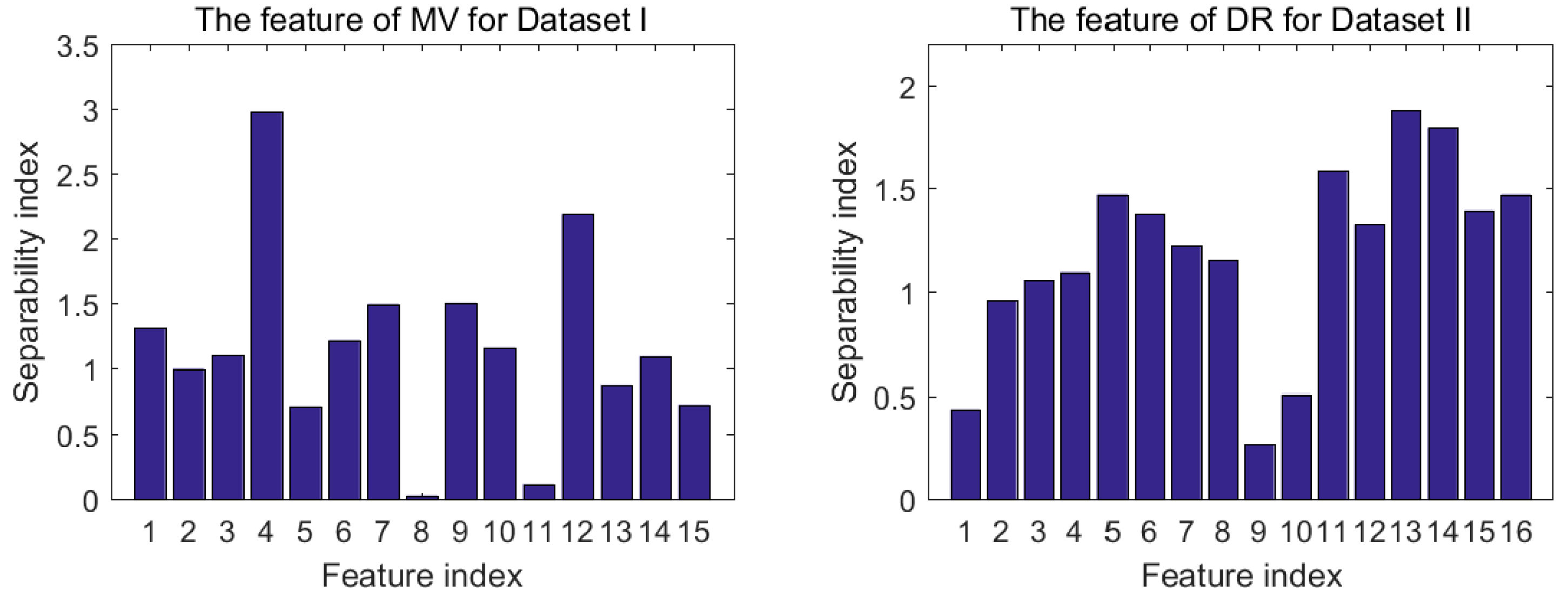
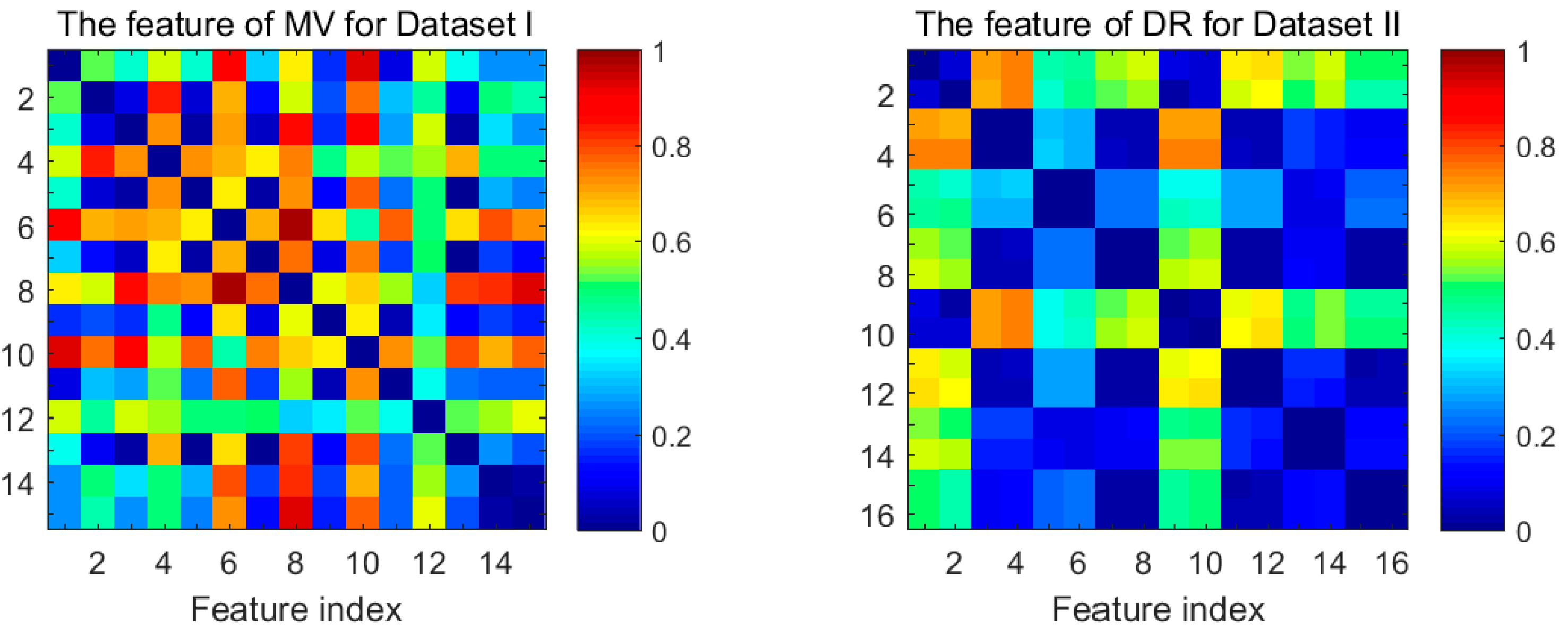
4.2. Separability Index and Dissimilarity Matrix
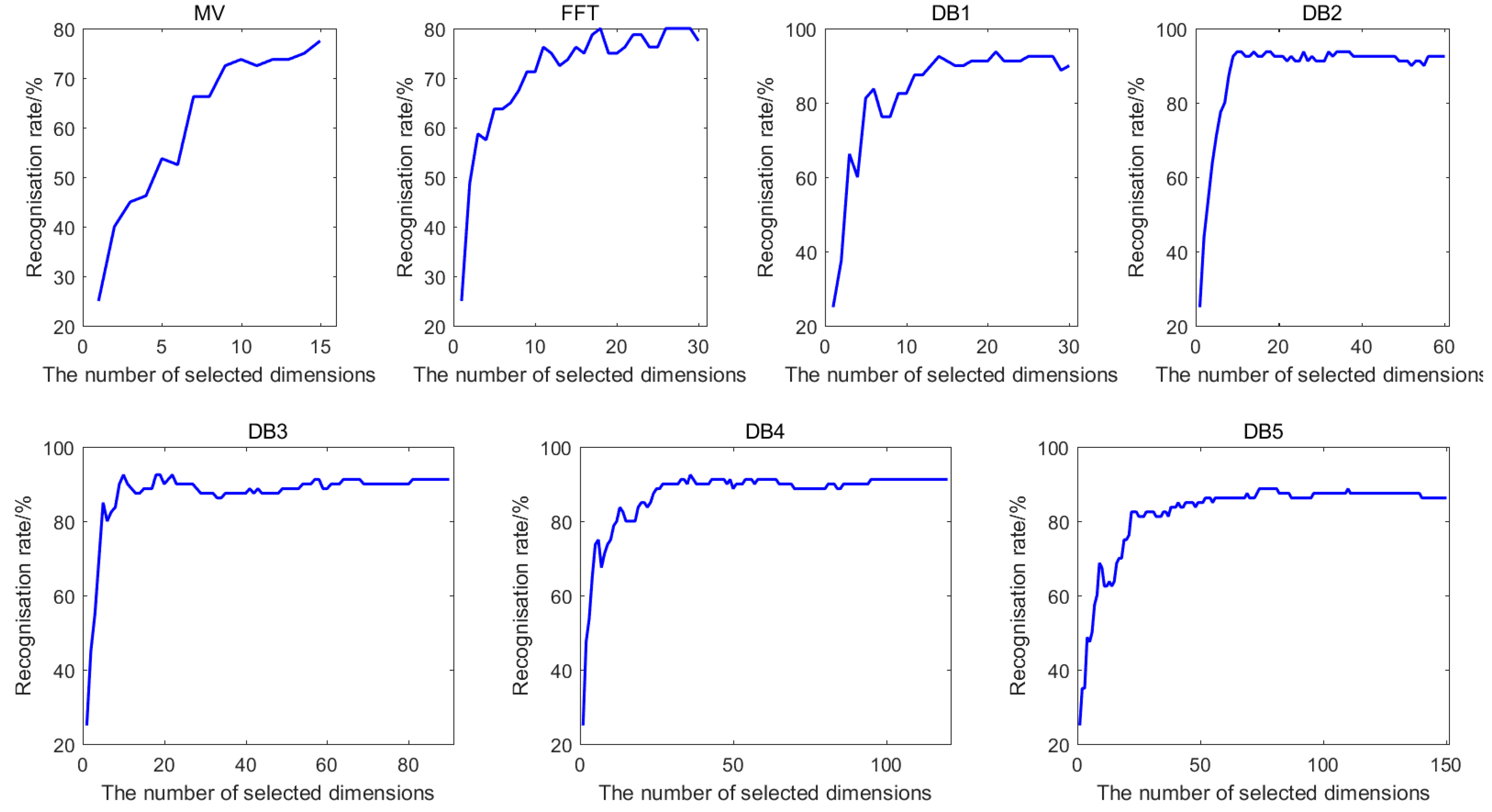
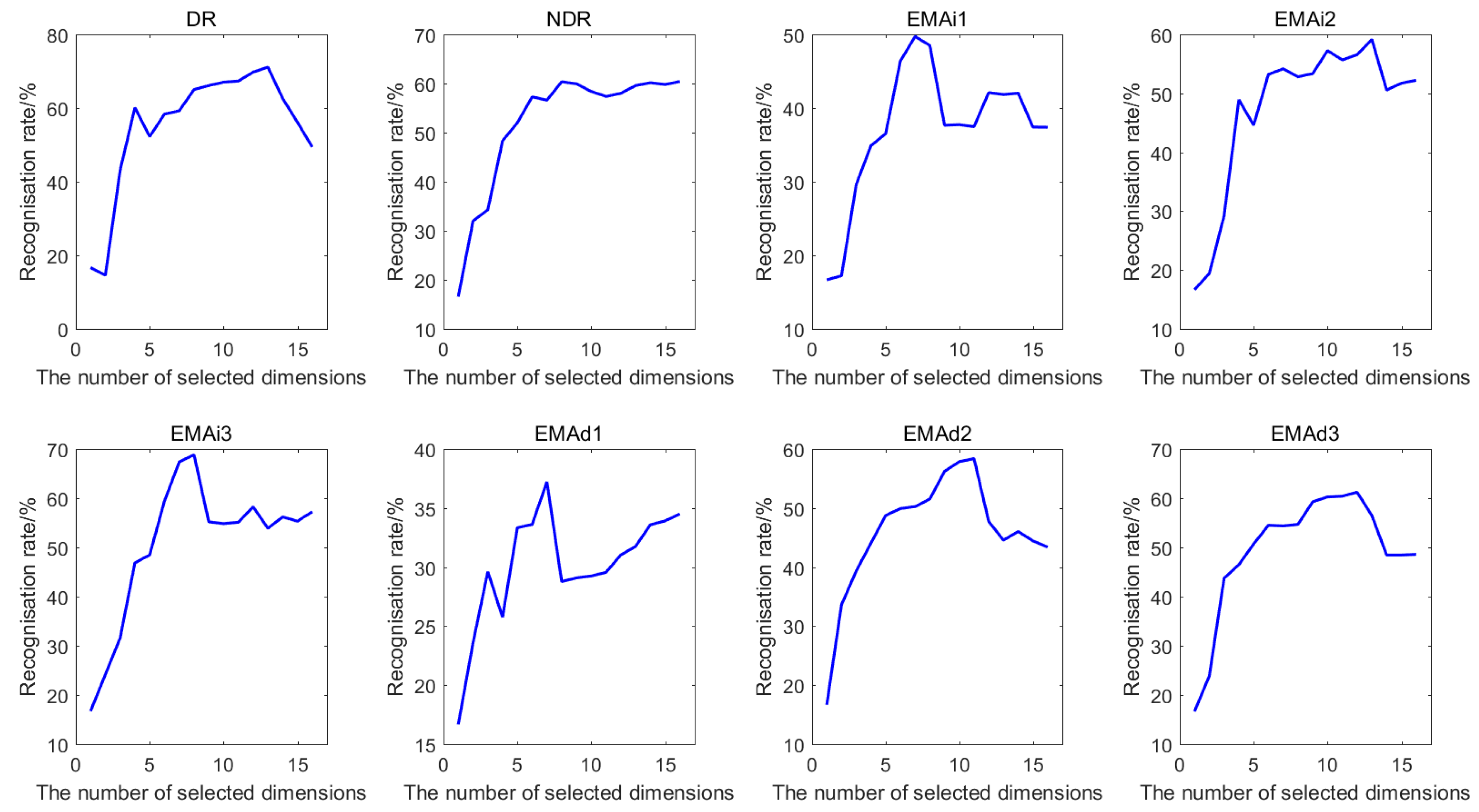
4.3. Optimal Numbers of Different Kinds of Features after Selection
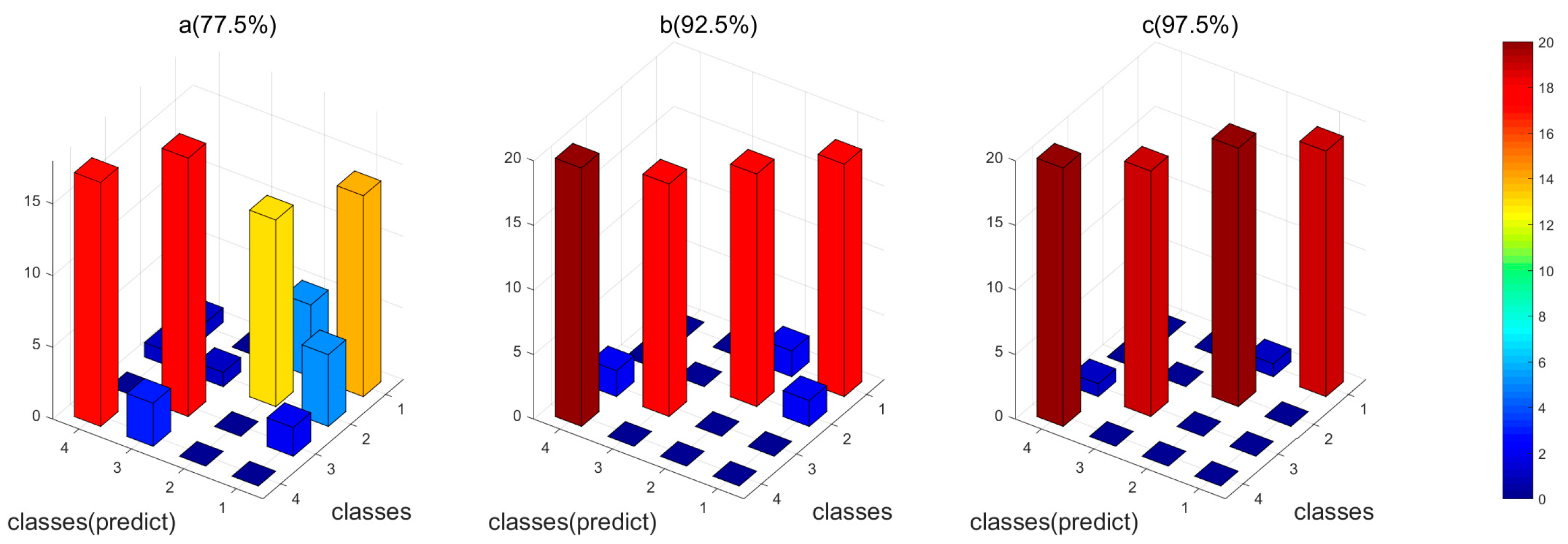
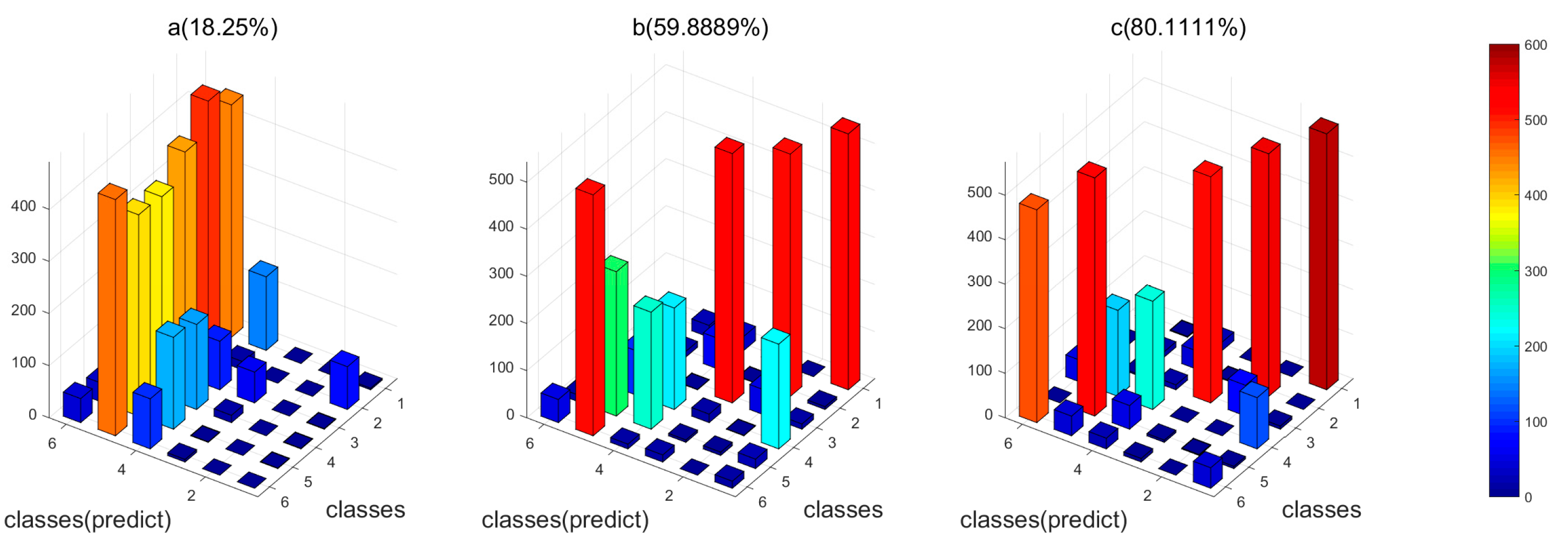
4.4. Comparison of Classification Accuracies with and without Feature Selection
4.5. Results of Feature Fusion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gardner, J.W.; Bartlett, P.N. A brief history of electronic nose. Sens. Actuators B 1994, 18, 211–215. [Google Scholar] [CrossRef]
- Natale, C.D.; Macagnano, A.; Martinelli, E.; Paolesse, R.; Proietti, E.; D’Amico, A. The evaluation of quality of post-harvest oranges and apples by means of an electronic nose. Sens. Actuators B Chem. 2001, 78, 26–31. [Google Scholar] [CrossRef]
- Stuetz, R.M.; Fenner, R.A.; Engin, G. Characterisation of wastewater using an electronic nose. Water Res. 1999, 33, 442–452. [Google Scholar] [CrossRef]
- Campagnoli, A.; Cheli, F.; Polidori, C.; Zaninelli, M.; Zecca, O.; Savoini, G.; Pinotti, L.; Dell’Orto, V. Use of the Electronic Nose as a Screening Tool for the Recognition of Durum Wheat Naturally Contaminated by Deoxynivalenol: A Preliminary Approach. Sensors 2011, 11, 4899–4916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahgal, N.; Magan, N. Fungal volatile fingerprints: Discrimination between dermatophyte species and strains by means of an electronic nose. Sens. Actuators B Chem. 2008, 131, 117–120. [Google Scholar] [CrossRef] [Green Version]
- Gębicki, J.; Szulczyński, B. Discrimination of selected fungi species based on their odour profile using prototypes of electronic nose instruments. Measurement 2017, 116, 307–318. [Google Scholar] [CrossRef]
- Wang, X.R.; Lizier, J.T.; Berna, A.Z.; Bravo, F.G.; Trowell, S.C. Human breath-print identification by E-nose, using information-theoretic feature selection prior to classification. Sens. Actuators B Chem. 2015, 217, 165–174. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Muezzinoglu, M.K.; Vergara, A.; Huerta, R.; Rabinovich, M.I. A sensor conditioning principle for odor identification. Sens. Actuators B Chem. 2010, 146, 472–476. [Google Scholar] [CrossRef]
- Johnson, K.J.; Rosepehrsson, S.L. Sensor Array Design for Complex Sensing Tasks. Annu. Rev. Anal. Chem. 2015, 8, 287. [Google Scholar] [CrossRef] [PubMed]
- Nowotny, T.; Berna, A.Z.; Binions, R.; Trowell, S. Optimal feature selection for classifying a large set of chemicals using metal oxide sensors. Sens. Actuators B Chem. 2013, 187, 471–480. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Shahid, A.; Choi, J.H.; Rana, A.U.H.S.; Kim, H.S. Least Squares Neural Network-Based Wireless E-Nose System Using an SnO2 Sensor Array. Sensors 2018, 18, 1446. [Google Scholar] [CrossRef] [PubMed]
- Licen, S.; Barbieri, G.; Fabbris, A. Odor Control Map: Self Organizing Map built from electronic nose signals and integrated by different instrumental and sensorial data to obtain an assessment tool for real environmental scenarios. Sens. Actuators B Chem. 2018, 263, 476–485. [Google Scholar] [CrossRef]
- Lippolis, V.; Cervellieri, S.; Damascelli, A. Rapid prediction of deoxynivalenol contamination in wheat bran by MOS-based electronic nose and characterization of the relevant pattern of volatile compounds. J. Sci. Food Agric. 2018. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paulsson, N.; Larsson, E.; Winquist, F. Extraction and selection of parameters for evaluation of breath alcohol measurement with an electronic nose. Sens. Actuators A Phys. 2000, 84, 187–197. [Google Scholar] [CrossRef]
- Li, J.; Gutierrez-Osuna, R.; Hodges, R.D.; Luckey, G.; Crowell, J. Using Field Asymmetric Ion Mobility Spectrometry for Odor Assessment of Automobile Interior Components. IEEE Sens. J. 2016, 16, 5747–5756. [Google Scholar] [CrossRef]
- Li, Y.; Shi, X.; Tong, L.; Tu, J. Manifold Regularized Multi-View Feature Selection for Web Image Annotation. Adv. Multimed. Inf. Process. PCM 2014, 204, 103–112. [Google Scholar]
- Anwar, K.; Harjoko, A.; Suharto, S. Feature Selection Based on Minimum Overlap Probability (MOP) in Identifying Beef and Pork. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 316–322. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.K.R.; Dehghantanha, A.; Xu, Z. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. Eurasip J. Wirel. Commun. Netw. 2016, 1, 130. [Google Scholar] [CrossRef]
- Giungato, P.; Laiola, E.; Nicolardi, V. Evaluation of Industrial Roasting Degree of Coffee Beans by Using an Electronic Nose and a Stepwise Backward Selection of Predictors. Food Anal. Method 2017, 10, 3424–3433. [Google Scholar] [CrossRef]
- Zhi, R.; Zhao, L.; Zhang, D. A Framework for the Multi-Level Fusion of Electronic Nose and Electronic Tongue for Tea Quality Assessment. Sensors 2017, 17, 1007. [Google Scholar] [CrossRef] [PubMed]
- Hong, X.; Wang, J. Detection of adulteration in cherry tomato juices based on electronic nose and tongue: Comparison of different data fusion approaches. J. Food Eng. 2014, 126, 89–97. [Google Scholar] [CrossRef]
- Buratti, S.; Malegori, C.; Benedetti, S. E-nose, e-tongue and e-eye for edible olive oil characterisation and shelf life assessment: A powerful data fusion approach. Talanta 2018, 182, 131–141. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Mendez, M.L.; Apetrei, C.; Gay, M.; Medina-Plaza, C.; De Saja, J.A.; Vidal, S.; Aagaard, O.; Ugliano, M.; Wirth, J.; Cheynier, V. Evaluation of Oxygen Exposure Levels and Plyphenolic Content of Red Wines Using an Electronic Panel Formed by an Electronic Nose and an Electronic Tongue. Food Chem. 2014, 155, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Dang, L.; Tian, F.; Zhang, L.; Kadri, C.; Yin, X.; Peng, X.; Liu, S. A novel classifier ensemble for recognition of multiple indoor air contaminants by an electronic nose. Sens. Actuators A Phys. 2014, 207, 67–74. [Google Scholar] [CrossRef]
- Miao, J.; Zhang, T.; Wang, Y.; Li, G. Optimal Sensor Selection for Classifying a Set of Ginsengs Using Metal-Oxide Sensors. Sensors 2015, 15, 16027–16039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, K.S.; Choi, H.H.; Moon, C.S.; Mun, C.W. Comparison of k-nearest neighbor, quadratic discriminant and linear discriminant analysis in classification of electromyogram signals based on the wrist-motion directions. Curr. Appl. Phys. 2011, 11, 740–745. [Google Scholar] [CrossRef]
- Yesilbudak, M.; Sagiroglu, S.; Colak, I. A new approach to very short-term wind speed prediction using k-nearest neighbor classification. Energy Convers. Manag. 2013, 69, 77–86. [Google Scholar] [CrossRef]
- Feng, J.; Tian, F.; Yan, J.; He, Q.; Shen, Y.; Pan, L. A background elimination method based on wavelet transform in wound infection detection by electronic nose. Sens. Actuators B Chem. 2011, 157, 395–400. [Google Scholar] [CrossRef]
- Vergara, A.; Vembu, S.; Ayhan, T.; Ryan, M.A.; Homer, M.L.; Huerta, R. Chemical gas sensor drift compensation using classifier ensembles. Sens. Actuators B Chem. 2012, 166, 320–329. [Google Scholar] [CrossRef]
- Saini, I.; Singh, D.; Khosla, A. QRS detection using K-Nearest Neighbor algorithm (KNN) and evaluation on standard ECG databases. J. Adv. Res. 2013, 4, 331–344. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Training Set | Test Set |
|---|---|---|
| No infection | 20 | 20 |
| Pseudomonas aeruginosa | 20 | 20 |
| Escherichia coli | 20 | 20 |
| Staphylococcus aureus | 20 | 20 |
| Total | 80 | 80 |
| Features | MV | FFT | Db1 | Db2 | Db3 | Db4 | Db5 |
|---|---|---|---|---|---|---|---|
| Feature structure | 15 × 80 | 30 × 80 | 30 × 80 | 60 × 80 | 90 × 80 | 120 × 80 | 150 × 80 |
| Analytes | Ammonia | Acetaldehyde | Acetone | Ethylene | Ethanol | Toluene |
|---|---|---|---|---|---|---|
| Concentration Range (ppm) | 50–1000 | 5–300 | 10–300 | 10–300 | 10–600 | 10–100 |
| Batch ID | Month | Number of the Data | |||||
|---|---|---|---|---|---|---|---|
| Ethanol | Ethylene | Ammonia | Acetaldehyde | Acetone | Toluene | ||
| Batch 1 | 1, 2 | 83 | 30 | 70 | 98 | 90 | 74 |
| Batch 2 | 3~10 | 100 | 109 | 532 | 334 | 164 | 5 |
| Batch 3 | 11, 12, 13 | 216 | 240 | 275 | 490 | 365 | 0 |
| Batch 4 | 14, 15 | 12 | 30 | 12 | 43 | 64 | 0 |
| Batch 5 | 16 | 20 | 46 | 63 | 40 | 28 | 0 |
| Batch 6 | 17~20 | 110 | 29 | 606 | 574 | 514 | 467 |
| Batch 7 | 21 | 360 | 744 | 630 | 662 | 649 | 568 |
| Batch 8 | 22, 23 | 40 | 33 | 143 | 30 | 30 | 18 |
| Batch 9 | 24, 30 | 100 | 75 | 78 | 55 | 61 | 101 |
| Batch 10 | 36 | 600 | 600 | 600 | 600 | 600 | 600 |
| Distance | k | MV | FFT | Db1 | Db2 | Db3 | Db4 | Db5 |
|---|---|---|---|---|---|---|---|---|
| EU | 1 | 68.75 | 73.75 | 90.00 | 91.25 | 87.50 | 88.75 | 83.75 |
| 3 | 63.75 | 72.50 | 75.00 | 78.75 | 78.75 | 81.25 | 80.00 | |
| 5 | 46.25 | 45.00 | 66.25 | 70.00 | 70.00 | 71.25 | 73.75 | |
| 7 | 51.25 | 53.75 | 60.00 | 68.75 | 70.00 | 73.75 | 75.00 | |
| 9 | 43.75 | 60.00 | 57.50 | 66.25 | 66.25 | 66.25 | 70.00 | |
| CB | 1 | 66.25 | 70.00 | 91.25 | 91.25 | 86.25 | 86.25 | 82.50 |
| 3 | 60.00 | 62.50 | 71.25 | 75.00 | 76.25 | 77.50 | 75.00 | |
| 5 | 41.25 | 47.50 | 61.25 | 71.25 | 70.00 | 72.50 | 72.50 | |
| 7 | 52.50 | 53.75 | 57.50 | 71.25 | 71.25 | 72.50 | 73.75 | |
| 9 | 48.75 | 48.75 | 55.00 | 65.00 | 63.75 | 65.00 | 67.50 | |
| COS | 1 | 77.50 | 77.50 | 90.00 | 92.50 | 91.25 | 91.25 | 86.25 |
| 3 | 72.50 | 78.75 | 80.00 | 82.50 | 82.50 | 82.50 | 82.50 | |
| 5 | 57.50 | 60.00 | 68.75 | 68.75 | 72.50 | 73.75 | 80.00 | |
| 7 | 58.75 | 53.75 | 63.75 | 65.00 | 67.50 | 71.25 | 75.00 | |
| 9 | 46.25 | 43.75 | 55.00 | 62.50 | 61.25 | 61.25 | 66.25 | |
| COR | 1 | 78.75 | 77.50 | 93.75 | 92.50 | 91.25 | 92.50 | 87.50 |
| 3 | 71.25 | 76.25 | 81.25 | 85.00 | 85.00 | 85.00 | 85.00 | |
| 5 | 56.25 | 57.50 | 66.25 | 76.25 | 75.00 | 76.25 | 82.50 | |
| 7 | 52.50 | 61.25 | 63.75 | 66.25 | 67.50 | 71.25 | 76.25 | |
| 9 | 51.25 | 58.75 | 50.00 | 58.75 | 63.75 | 65.00 | 67.50 |
| Distance | k | DR | NDR | EMAi1 | EMAi2 | EMAi3 | EMAd1 | EMAd2 | EMAd3 |
|---|---|---|---|---|---|---|---|---|---|
| EU | 1 | 53.53 | 60.00 | 36.31 | 53.61 | 59.06 | 36.31 | 43.56 | 48.78 |
| 3 | 54.25 | 58.89 | 37.28 | 54.03 | 58.42 | 36.61 | 43.47 | 49.39 | |
| 5 | 54.06 | 59.42 | 38.47 | 54.28 | 58.00 | 37.11 | 43.47 | 49.00 | |
| 7 | 53.47 | 59.53 | 38.61 | 54.08 | 57.97 | 37.39 | 43.25 | 48.42 | |
| 9 | 53.50 | 59.50 | 38.11 | 53.64 | 57.61 | 37.03 | 43.00 | 48.31 | |
| CB | 1 | 57.33 | 61.97 | 38.22 | 54.03 | 60.25 | 36.64 | 44.36 | 50.50 |
| 3 | 60.58 | 62.19 | 37.50 | 55.78 | 58.89 | 36.75 | 44.42 | 51.36 | |
| 5 | 60.00 | 61.28 | 38.69 | 55.58 | 59.36 | 36.81 | 44.31 | 51.28 | |
| 7 | 60.03 | 61.78 | 38.11 | 54.53 | 59.61 | 37.03 | 44.36 | 51.03 | |
| 9 | 59.97 | 62.17 | 37.86 | 53.69 | 60.28 | 36.89 | 44.31 | 51.50 | |
| COS | 1 | 49.42 | 60.42 | 37.39 | 52.22 | 57.25 | 34.50 | 43.39 | 48.58 |
| 3 | 51.33 | 59.81 | 37.97 | 50.47 | 55.28 | 35.00 | 43.56 | 48.69 | |
| 5 | 51.31 | 59.22 | 38.28 | 50.42 | 55.58 | 35.64 | 43.19 | 48.50 | |
| 7 | 51.53 | 59.31 | 38.08 | 50.28 | 55.42 | 36.17 | 42.94 | 48.42 | |
| 9 | 52.00 | 59.00 | 37.78 | 50.06 | 55.42 | 36.19 | 42.58 | 48.19 | |
| COR | 1 | 49.56 | 59.72 | 37.89 | 51.03 | 56.44 | 35.72 | 40.86 | 46.69 |
| 3 | 49.94 | 59.97 | 37.75 | 49.50 | 54.58 | 35.61 | 41.06 | 47.31 | |
| 5 | 50.25 | 59.53 | 37.86 | 49.94 | 55.00 | 35.08 | 40.56 | 47.78 | |
| 7 | 50.36 | 59.14 | 37.36 | 49.11 | 54.69 | 35.67 | 40.47 | 47.50 | |
| 9 | 50.22 | 59.28 | 36.97 | 48.81 | 55.69 | 36.28 | 40.14 | 47.14 |
| Features | MV | FFT | Db1 | Db2 | Db3 | Db4 | Db5 | |
|---|---|---|---|---|---|---|---|---|
| Distance metrics | COS | 15 | 18 | 21 | 10 | 10 | 36 | 74 |
| COR | 14 | 26 | 25 | 23 | 18 | 49 | 109 |
| Features | DR | NDR | EMAi1 | EMAi2 | EMAi3 | EMAd1 | EMAd2 | EMAd3 | |
|---|---|---|---|---|---|---|---|---|---|
| Distance metrics | COS | 13 | 16 | 7 | 13 | 8 | 7 | 11 | 12 |
| COR | 13 | 9 | 7 | 10 | 8 | 16 | 11 | 12 |
| Features | MV | FFT | Db1 | Db2 | Db3 | Db4 | Db5 | ||
|---|---|---|---|---|---|---|---|---|---|
| Without selection | COS | Dimension | 15 | 30 | 30 | 60 | 90 | 120 | 150 |
| 1 | 80.00 | 85.00 | 90.00 | 90.00 | 95.00 | 95.00 | 95.00 | ||
| 2 | 80.00 | 80.00 | 90.00 | 95.00 | 85.00 | 85.00 | 80.00 | ||
| 3 | 65.00 | 70.00 | 95.00 | 90.00 | 90.00 | 90.00 | 90.00 | ||
| 4 | 85.00 | 75.00 | 85.00 | 95.00 | 95.00 | 95.00 | 80.00 | ||
| Average | 77.50 | 77.50 | 90.00 | 92.50 | 91.25 | 91.25 | 86.25 | ||
| COR | 1 | 75.00 | 85.00 | 95.00 | 90.00 | 90.00 | 95.00 | 95.00 | |
| 2 | 85.00 | 85.00 | 100.00 | 90.00 | 90.00 | 90.00 | 85.00 | ||
| 3 | 70.00 | 65.00 | 90.00 | 90.00 | 90.00 | 90.00 | 90.00 | ||
| 4 | 85.00 | 75.00 | 90.00 | 100.00 | 95.00 | 95.00 | 80.00 | ||
| Average | 78.75 | 77.50 | 93.75 | 92.50 | 91.25 | 92.50 | 87.50 | ||
| With selection | COS | Dimension | 15 | 18 | 21 | 10 | 10 | 36 | 74 |
| 1 | 80.00 | 85.00 | 95.00 | 95.00 | 95.00 | 95.00 | 95.00 | ||
| 2 | 80.00 | 80.00 | 90.00 | 90.00 | 95.00 | 90.00 | 85.00 | ||
| 3 | 65.00 | 75.00 | 95.00 | 95.00 | 90.00 | 95.00 | 85.00 | ||
| 4 | 85.00 | 80.00 | 95.00 | 95.00 | 90.00 | 90.00 | 90.00 | ||
| Average | 77.50 | 80.00 | 93.75 | 93.75 | 92.50 | 92.50 | 88.75 | ||
| COR | Dimension | 14 | 26 | 25 | 23 | 18 | 49 | 109 | |
| 1 | 85.00 | 85.00 | 95.00 | 95.00 | 90.00 | 90.00 | 95.00 | ||
| 2 | 90.00 | 85.00 | 100.00 | 95.00 | 95.00 | 100.00 | 85.00 | ||
| 3 | 70.00 | 70.00 | 95.00 | 95.00 | 95.00 | 95.00 | 90.00 | ||
| 4 | 80.00 | 80.00 | 95.00 | 100.00 | 95.00 | 95.00 | 85.00 | ||
| Average | 81.25 | 80.00 | 96.25 | 96.25 | 93.75 | 95.00 | 88.75 | ||
| Features | DR | NDR | EMAi1 | EMAi2 | EMAi3 | EMAd1 | EMAd2 | EMAd3 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| without selection | COS | Dimension | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| 1 | 61.00 | 26.00 | 73.17 | 98.67 | 65.00 | 61.17 | 69.67 | 85.00 | ||
| 2 | 85.17 | 98.67 | 67.17 | 83.33 | 84.50 | 54.00 | 62.83 | 67.67 | ||
| 3 | 90.33 | 91.83 | 10.00 | 37.17 | 89.33 | 27.33 | 58.50 | 79.50 | ||
| 4 | 6.67 | 17.33 | 40.67 | 59.50 | 67.67 | 1.33 | 5.83 | 15.00 | ||
| 5 | 46.17 | 58.17 | 30.83 | 23.83 | 27.50 | 23.33 | 55.50 | 40.67 | ||
| 6 | 7.17 | 70.50 | 2.50 | 10.83 | 9.50 | 39.83 | 8.00 | 3.67 | ||
| Average | 49.42 | 60.42 | 37.39 | 52.22 | 57.25 | 34.50 | 43.39 | 48.58 | ||
| COR | 1 | 53.00 | 25.50 | 73.33 | 98.83 | 65.50 | 60.83 | 70.67 | 83.00 | |
| 2 | 85.17 | 98.83 | 67.67 | 83.83 | 83.83 | 54.33 | 63.17 | 68.67 | ||
| 3 | 90.17 | 90.17 | 6.33 | 29.50 | 86.33 | 27.33 | 45.67 | 78.67 | ||
| 4 | 5.17 | 14.83 | 43.67 | 58.17 | 67.67 | 0.83 | 4.50 | 11.50 | ||
| 5 | 51.83 | 59.83 | 32.17 | 22.67 | 24.00 | 20.67 | 51.50 | 34.67 | ||
| 6 | 12.00 | 69.17 | 4.17 | 13.17 | 11.33 | 50.33 | 9.67 | 3.67 | ||
| Average | 49.56 | 59.72 | 37.89 | 51.03 | 56.44 | 35.72 | 40.86 | 46.69 | ||
| with selection | COS | Dimension | 13 | 16 | 7 | 13 | 8 | 7 | 11 | 12 |
| 1 | 47.17 | 26.00 | 75.00 | 87.50 | 82.00 | 52.50 | 77.83 | 82.50 | ||
| 2 | 92.00 | 98.67 | 67.17 | 84.33 | 90.17 | 53.00 | 66.00 | 79.33 | ||
| 3 | 85.83 | 91.83 | 31.83 | 32.83 | 75.33 | 31.67 | 58.67 | 76.50 | ||
| 4 | 31.67 | 17.33 | 16.50 | 71.33 | 43.00 | 1.50 | 30.50 | 20.00 | ||
| 5 | 93.67 | 58.17 | 88.17 | 49.33 | 62.83 | 41.00 | 70.00 | 47.00 | ||
| 6 | 76.33 | 70.50 | 19.67 | 29.50 | 59.67 | 43.67 | 47.17 | 62.00 | ||
| Average | 71.11 | 60.42 | 49.72 | 59.14 | 68.83 | 37.22 | 58.36 | 61.22 | ||
| COR | Dimension | 13 | 9 | 7 | 10 | 8 | 16 | 11 | 12 | |
| 1 | 41.00 | 51.00 | 73.33 | 92.17 | 85.83 | 60.83 | 74.00 | 79.50 | ||
| 2 | 92.67 | 99.17 | 72.33 | 87.50 | 91.17 | 54.33 | 64.00 | 79.33 | ||
| 3 | 86.67 | 98.67 | 24.17 | 60.50 | 59.33 | 27.33 | 44.83 | 76.67 | ||
| 4 | 31.33 | 0.00 | 9.50 | 5.33 | 43.67 | 0.83 | 16.00 | 9.33 | ||
| 5 | 93.17 | 30.33 | 81.83 | 43.33 | 65.33 | 20.67 | 69.00 | 42.17 | ||
| 6 | 81.33 | 95.67 | 37.17 | 52.83 | 91.00 | 50.33 | 47.17 | 60.33 | ||
| Average | 71.03 | 62.47 | 49.72 | 56.94 | 72.72 | 35.72 | 52.50 | 57.89 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, C.; Lv, K.; Shi, D.; Yang, B.; Yu, S.; He, Z.; Yan, J. Enhancing the Discrimination Ability of a Gas Sensor Array Based on a Novel Feature Selection and Fusion Framework. Sensors 2018, 18, 1909. https://doi.org/10.3390/s18061909
Deng C, Lv K, Shi D, Yang B, Yu S, He Z, Yan J. Enhancing the Discrimination Ability of a Gas Sensor Array Based on a Novel Feature Selection and Fusion Framework. Sensors. 2018; 18(6):1909. https://doi.org/10.3390/s18061909
Chicago/Turabian StyleDeng, Changjian, Kun Lv, Debo Shi, Bo Yang, Song Yu, Zhiyi He, and Jia Yan. 2018. "Enhancing the Discrimination Ability of a Gas Sensor Array Based on a Novel Feature Selection and Fusion Framework" Sensors 18, no. 6: 1909. https://doi.org/10.3390/s18061909
APA StyleDeng, C., Lv, K., Shi, D., Yang, B., Yu, S., He, Z., & Yan, J. (2018). Enhancing the Discrimination Ability of a Gas Sensor Array Based on a Novel Feature Selection and Fusion Framework. Sensors, 18(6), 1909. https://doi.org/10.3390/s18061909