A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities



Abstract
:1. Introduction
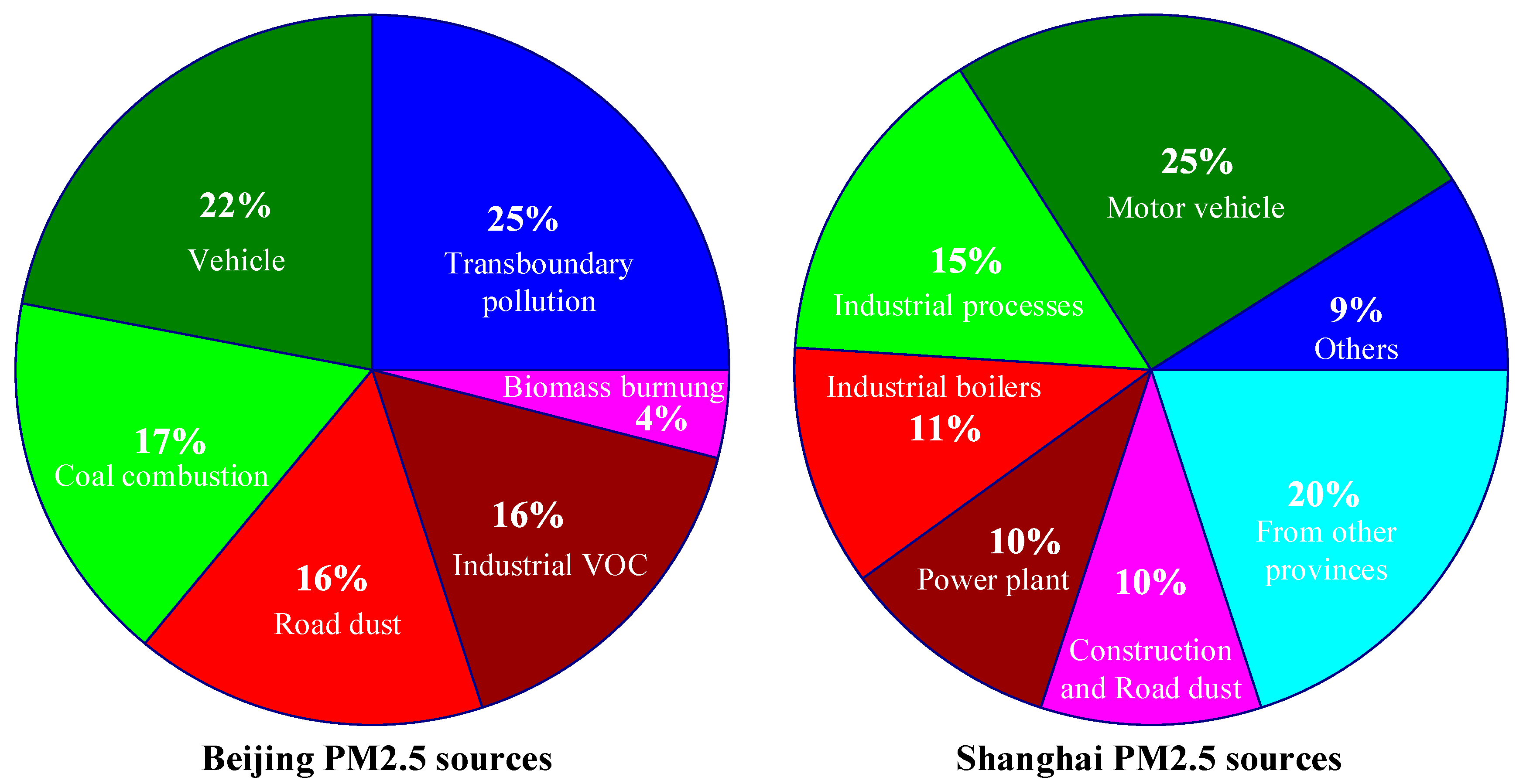
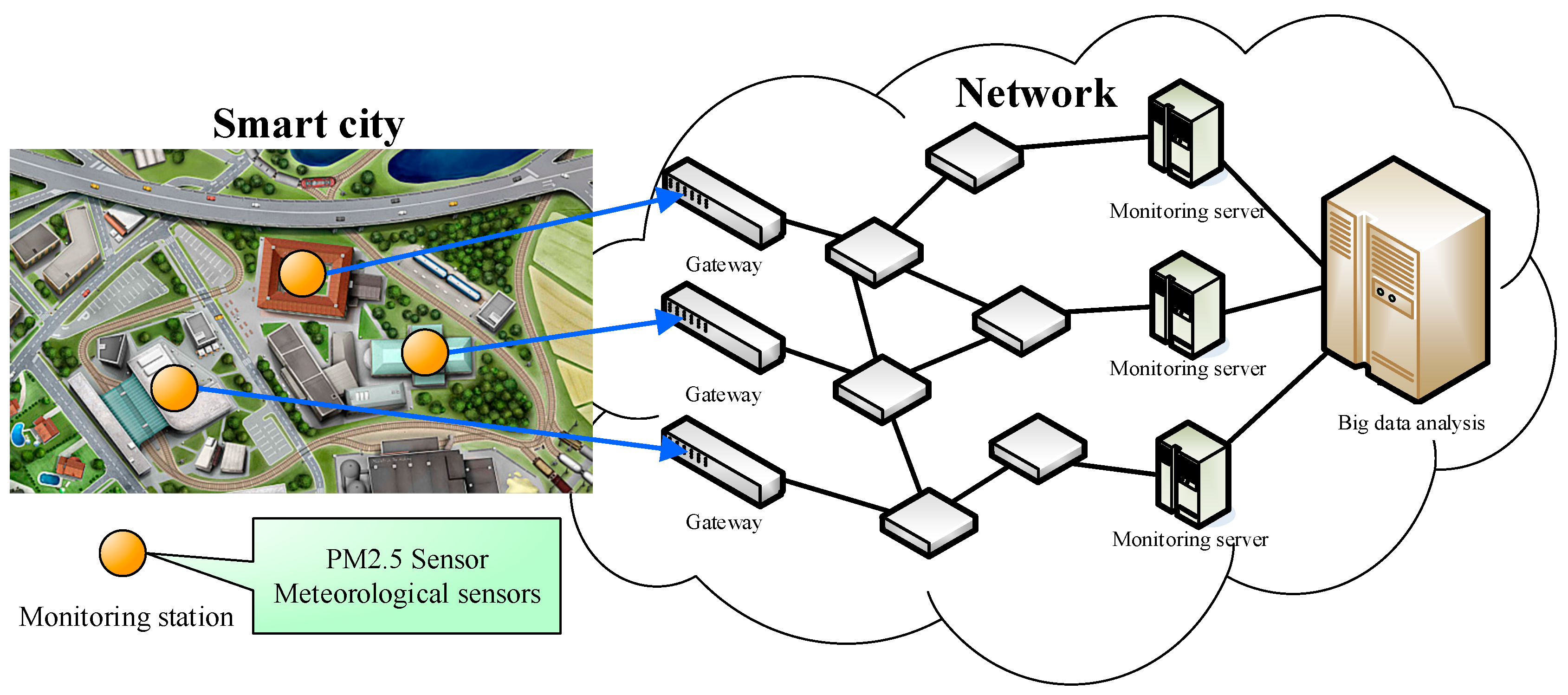
2. PM2.5 Monitoring and Forecasting in Smart Cities
3. The Background Knowledge of the Artificial Neural Network
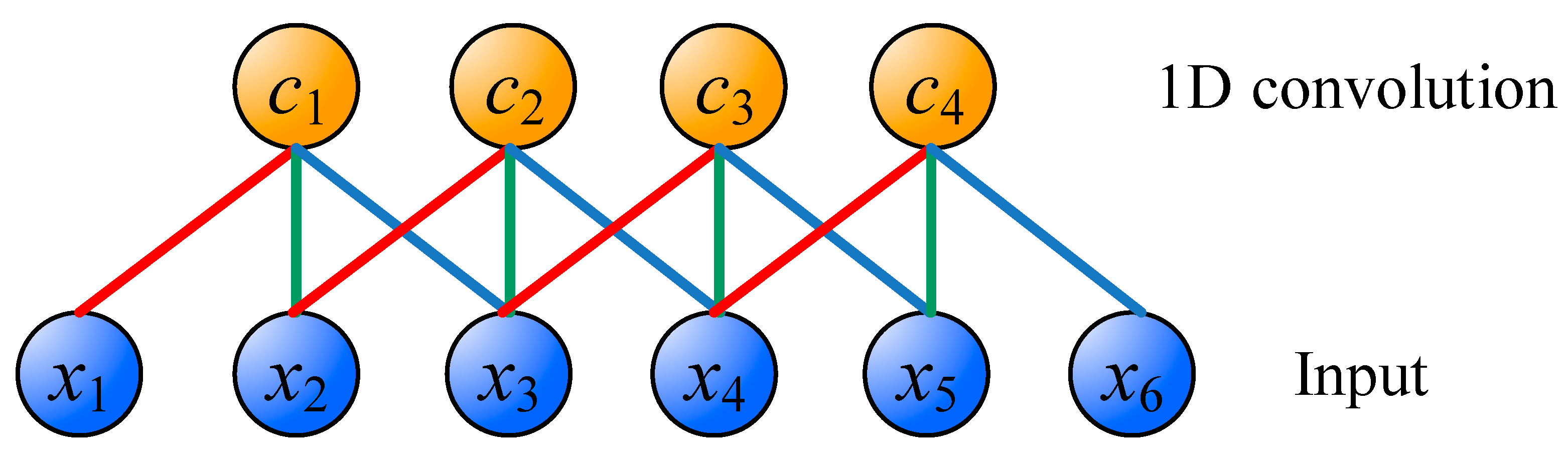
3.1. Convolutional Neural Network
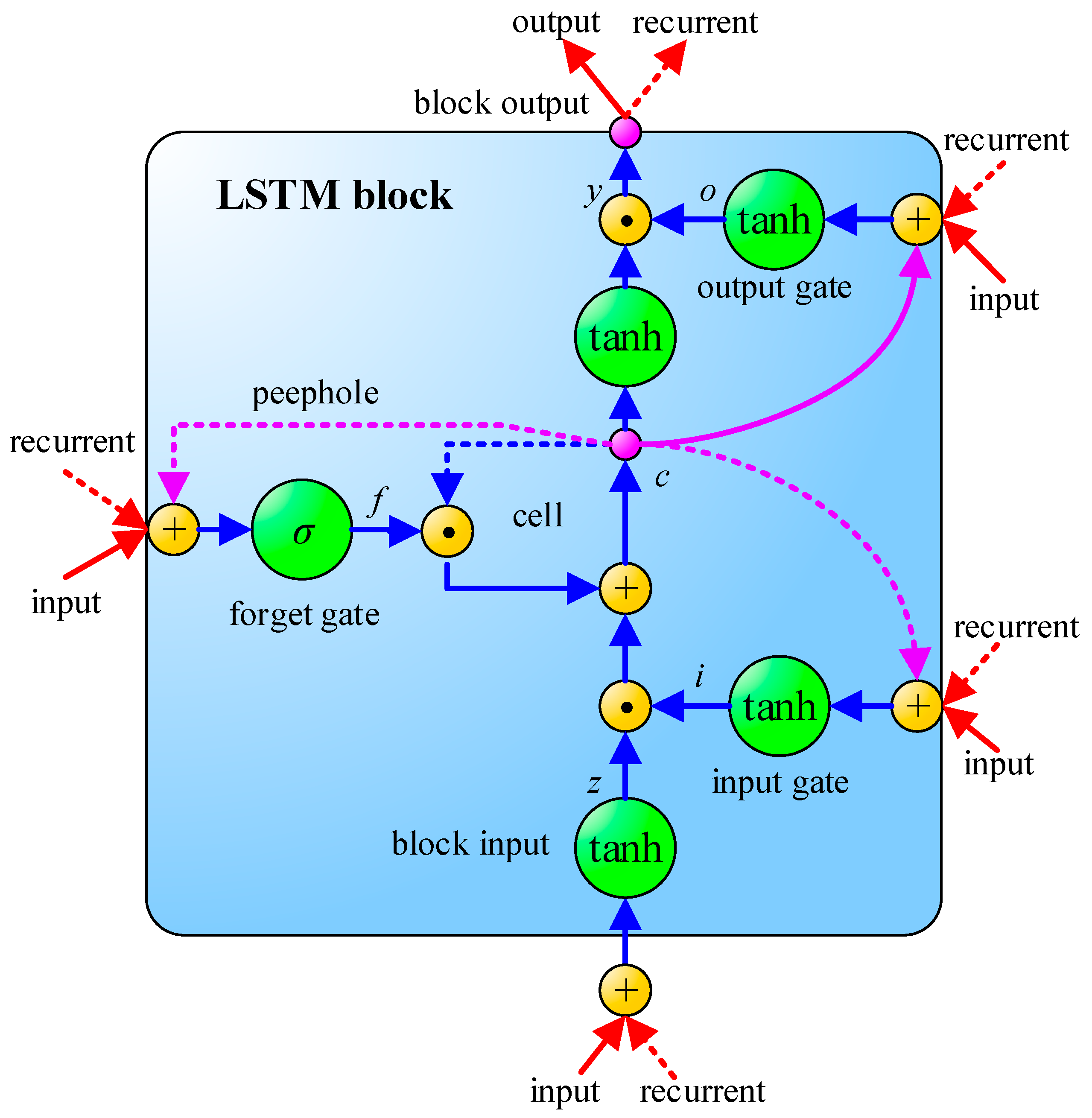
3.2. Long Short-Term Memory
3.3. Batch Normalization
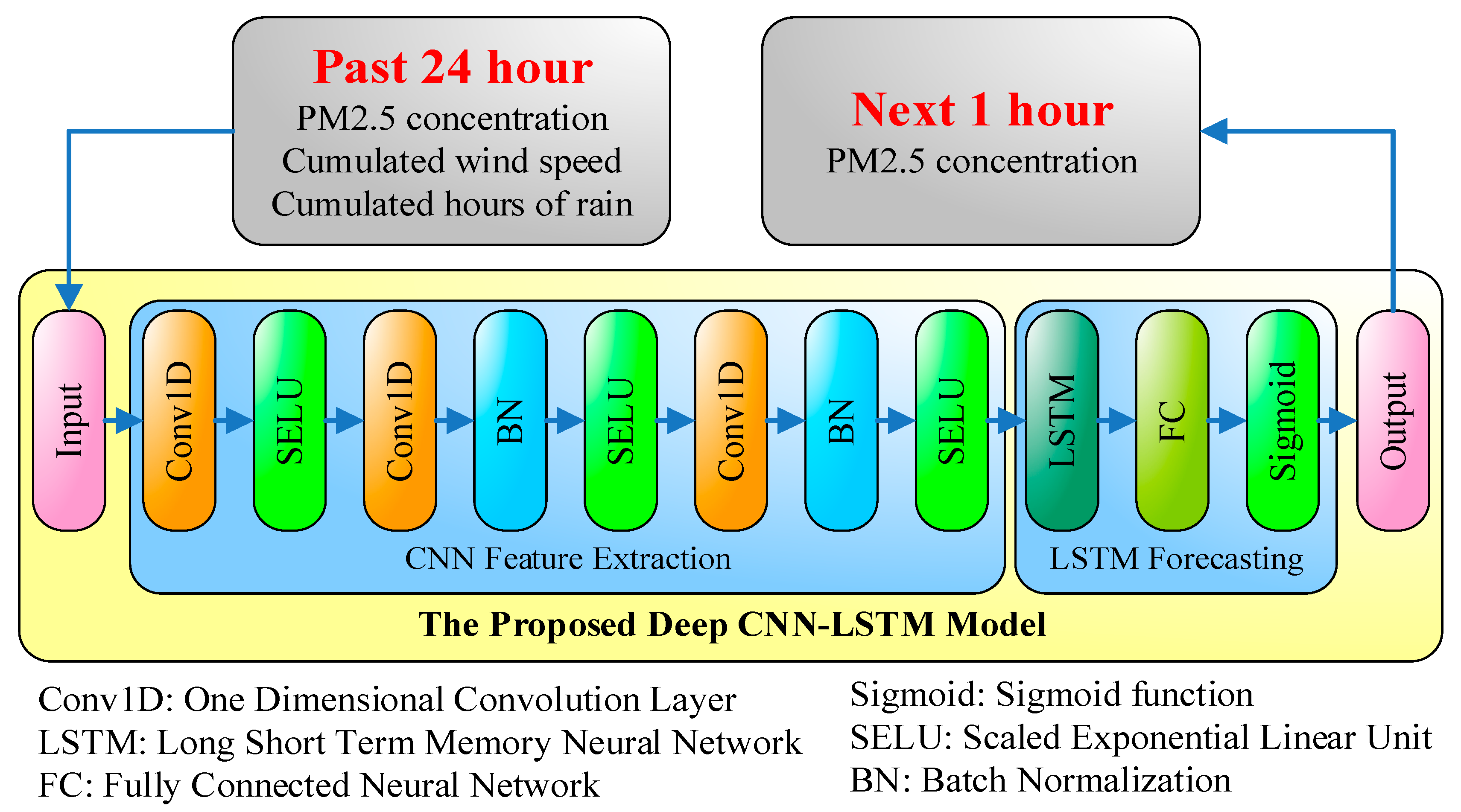
4. The Proposed Deep CNN-LSTM Network
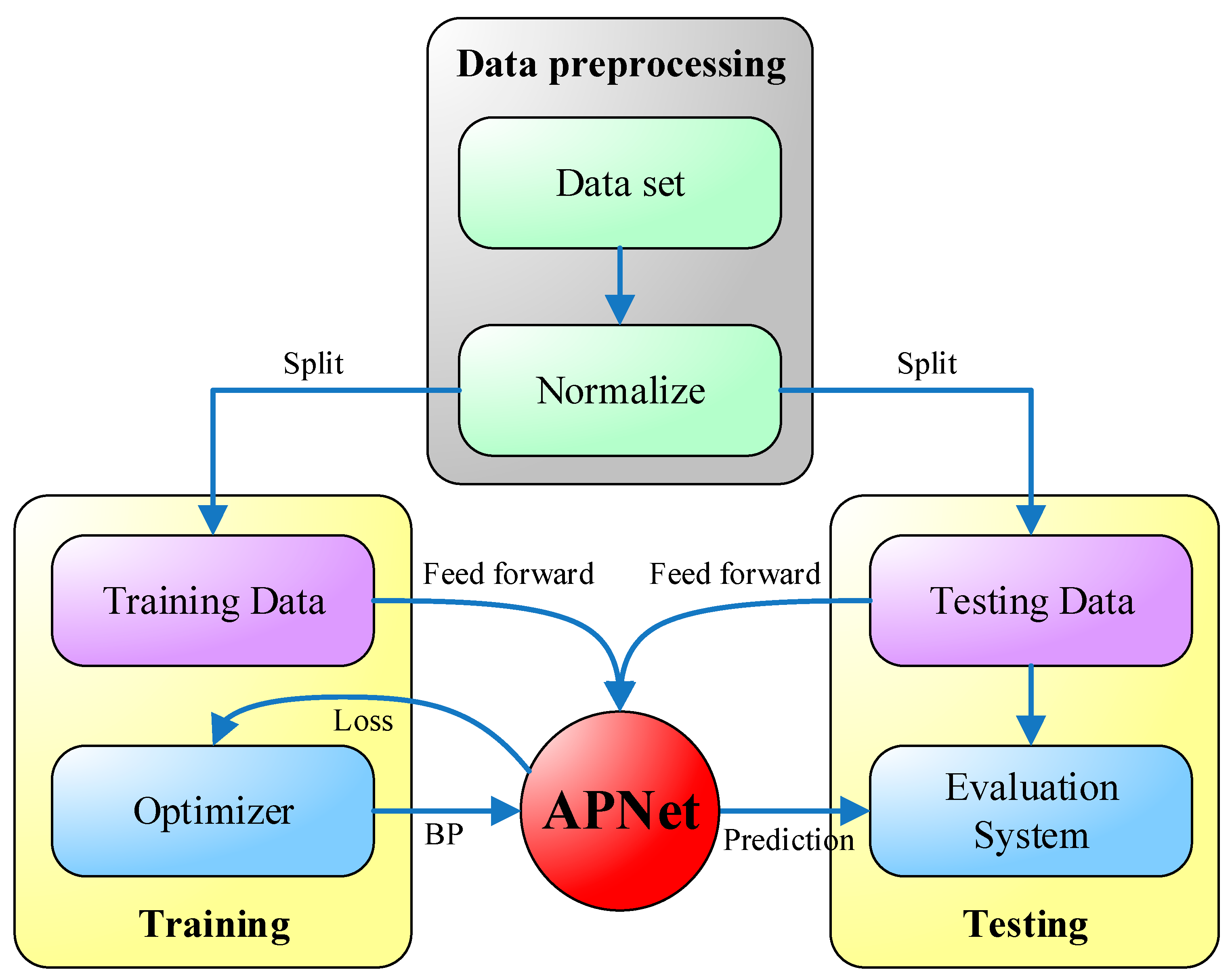
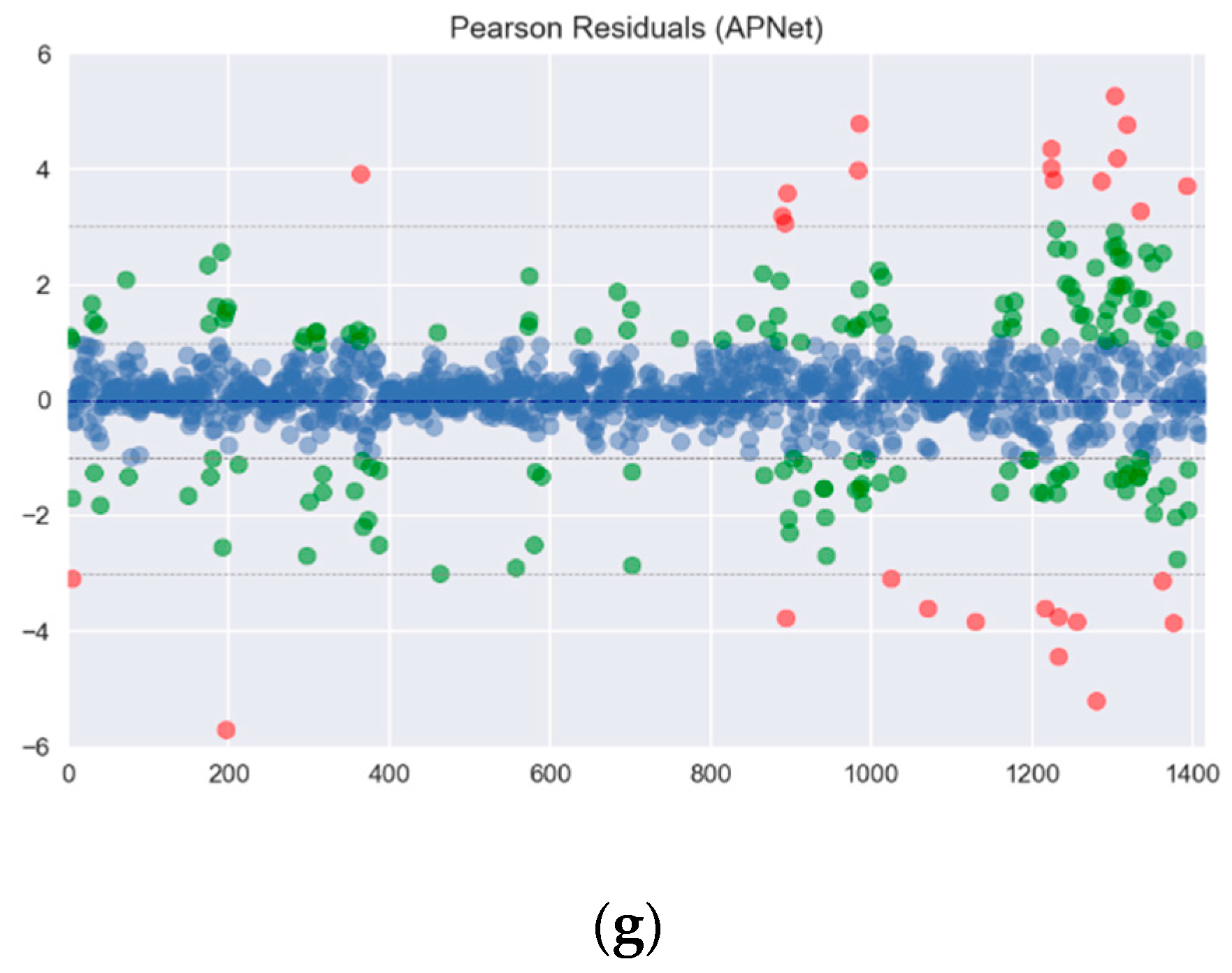
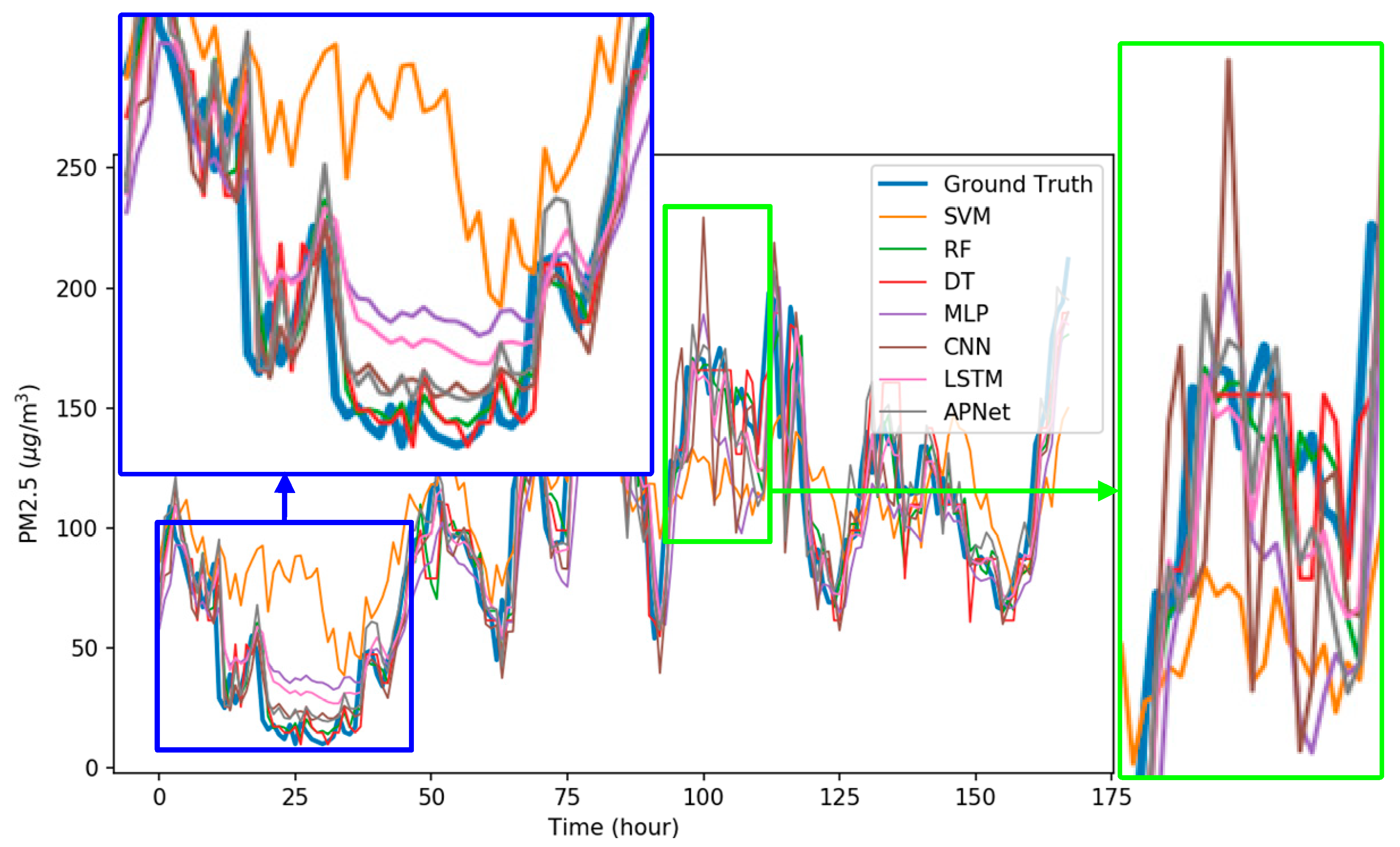
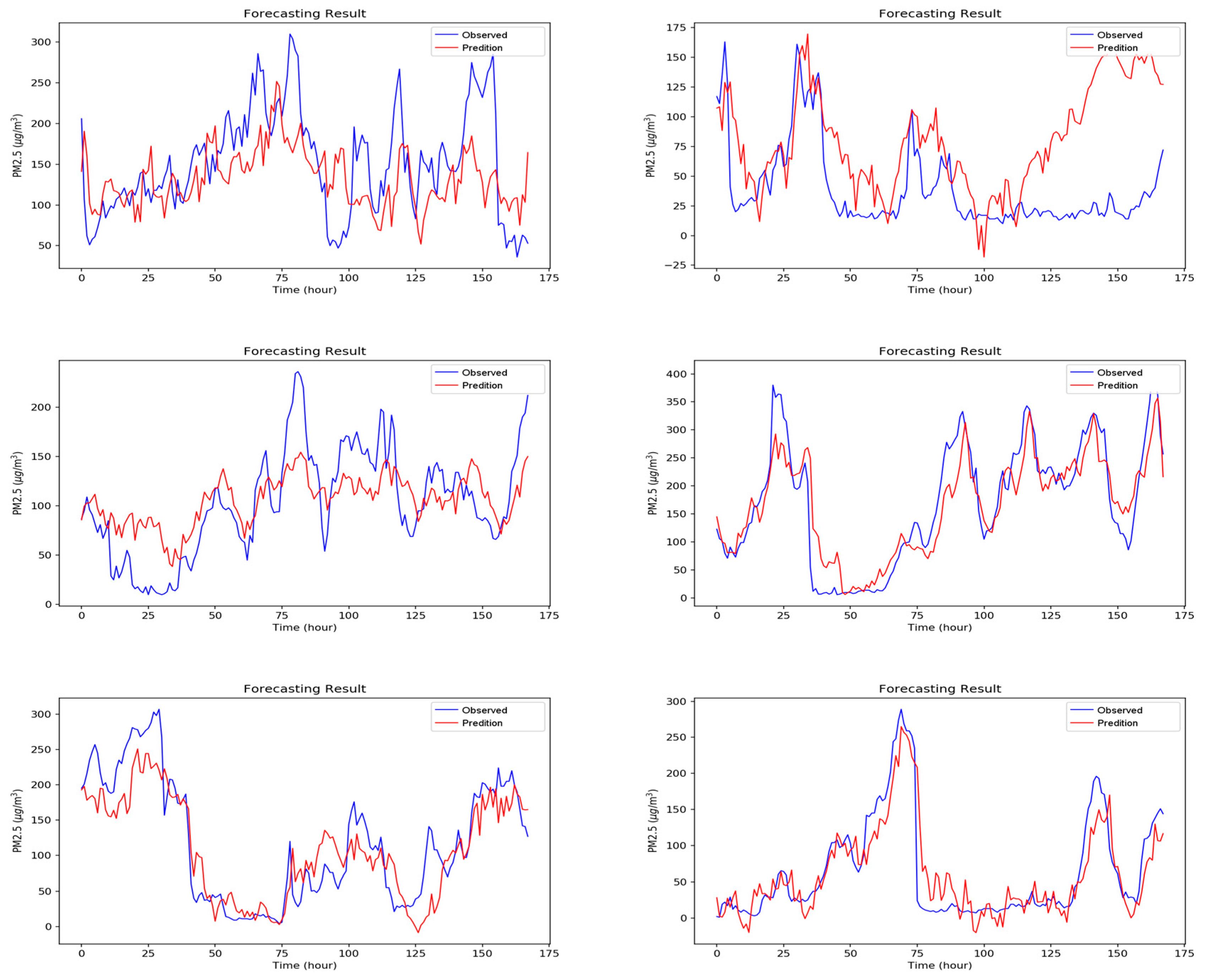
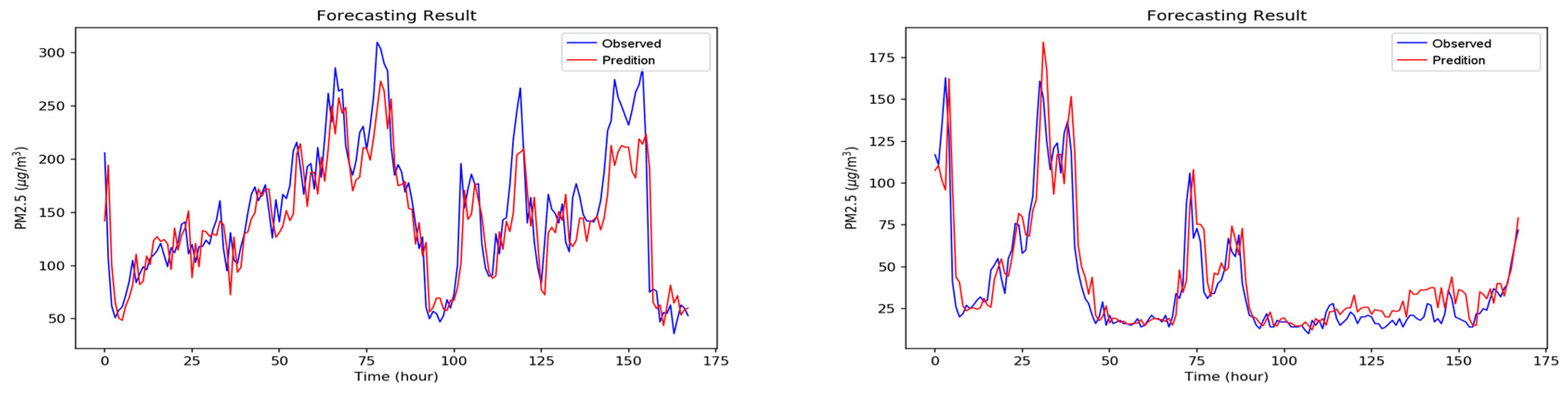
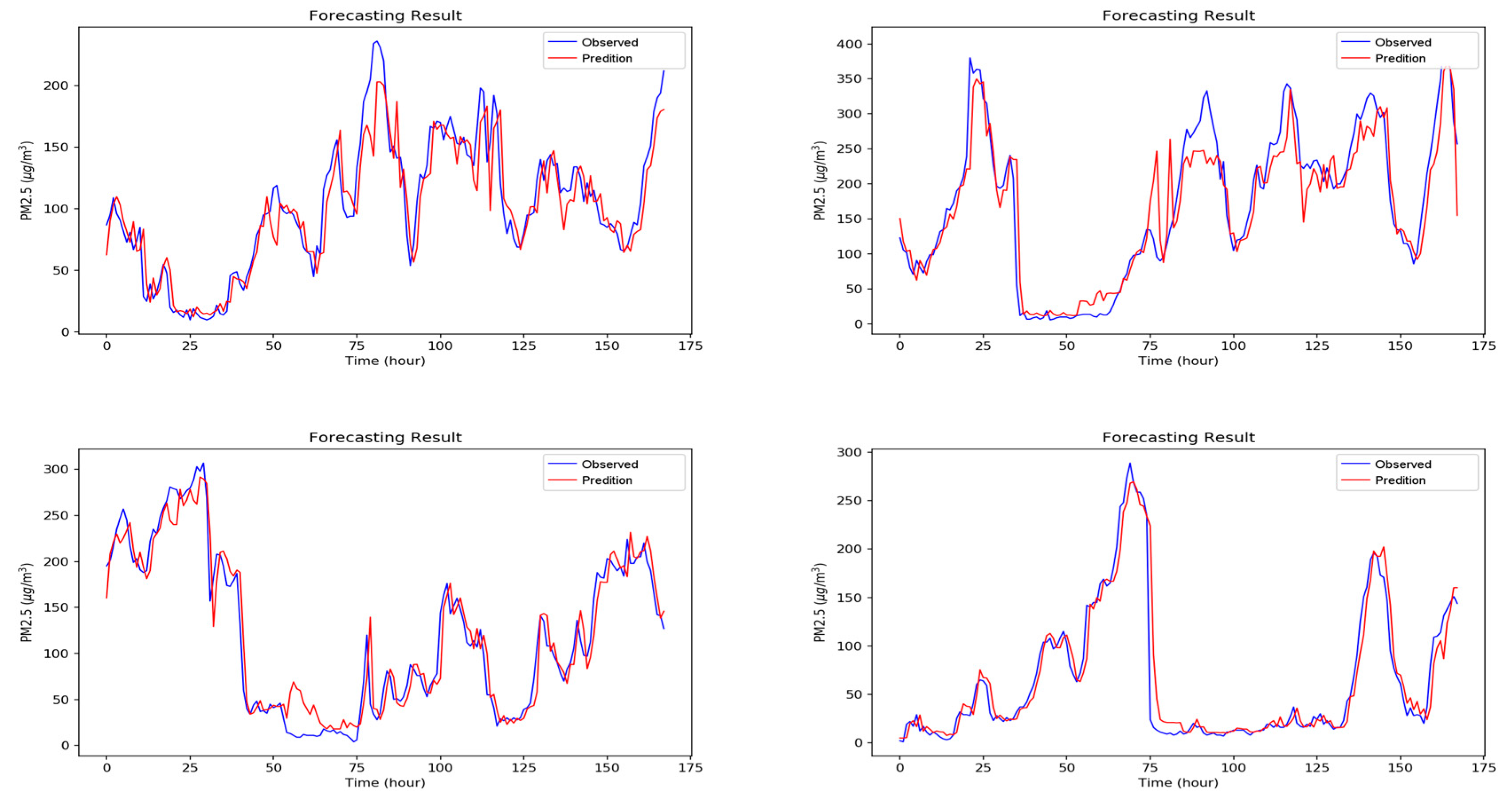
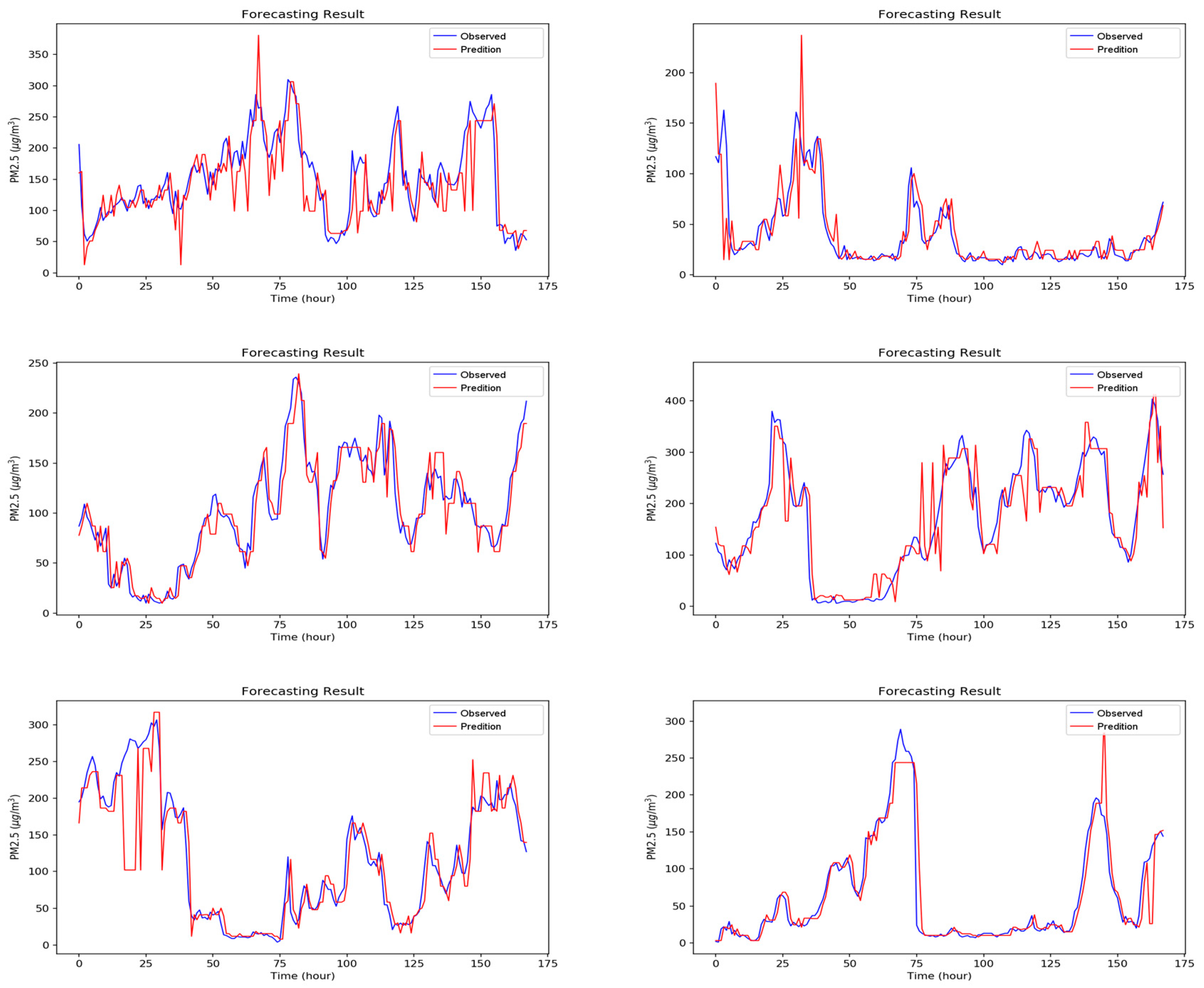
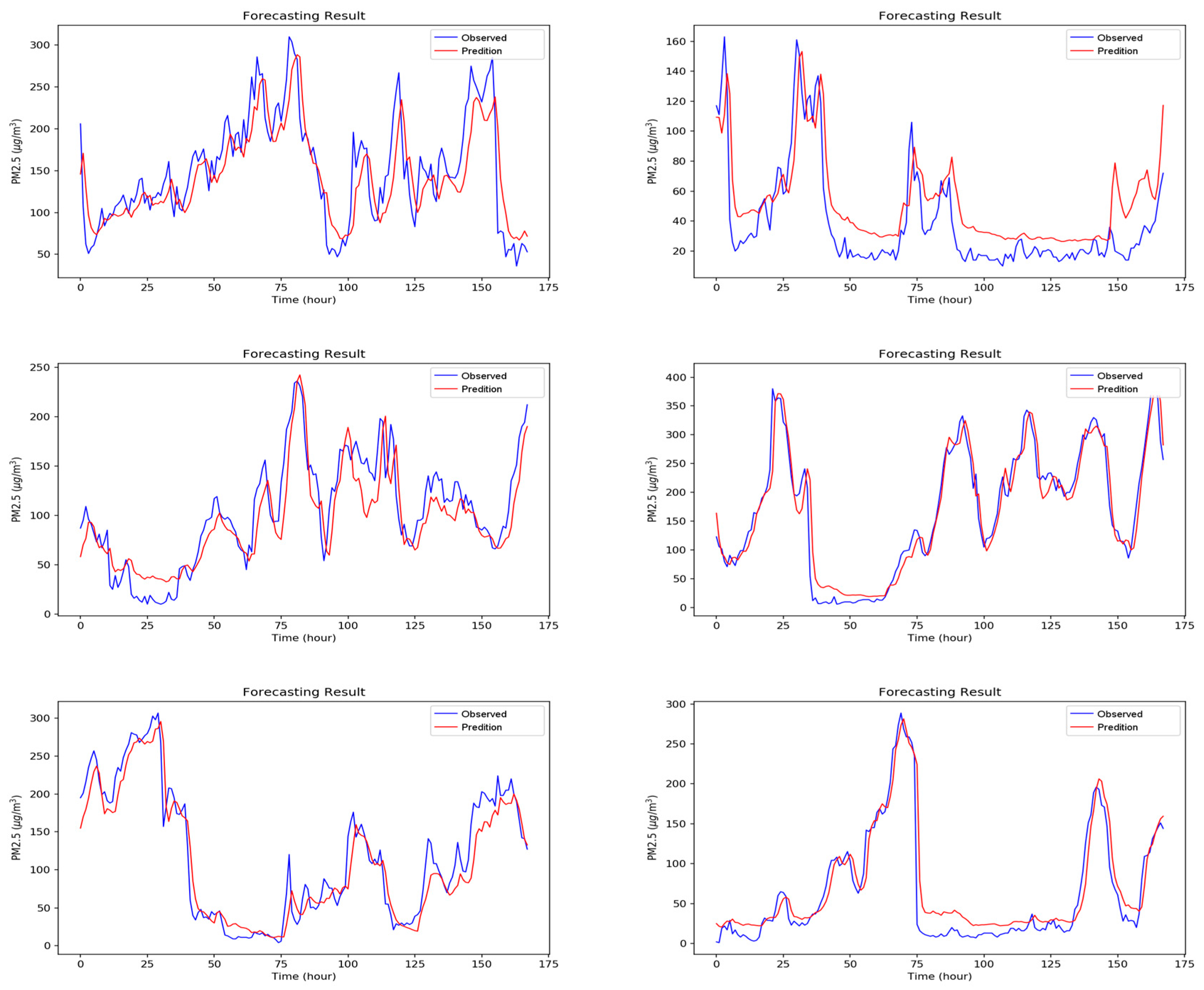
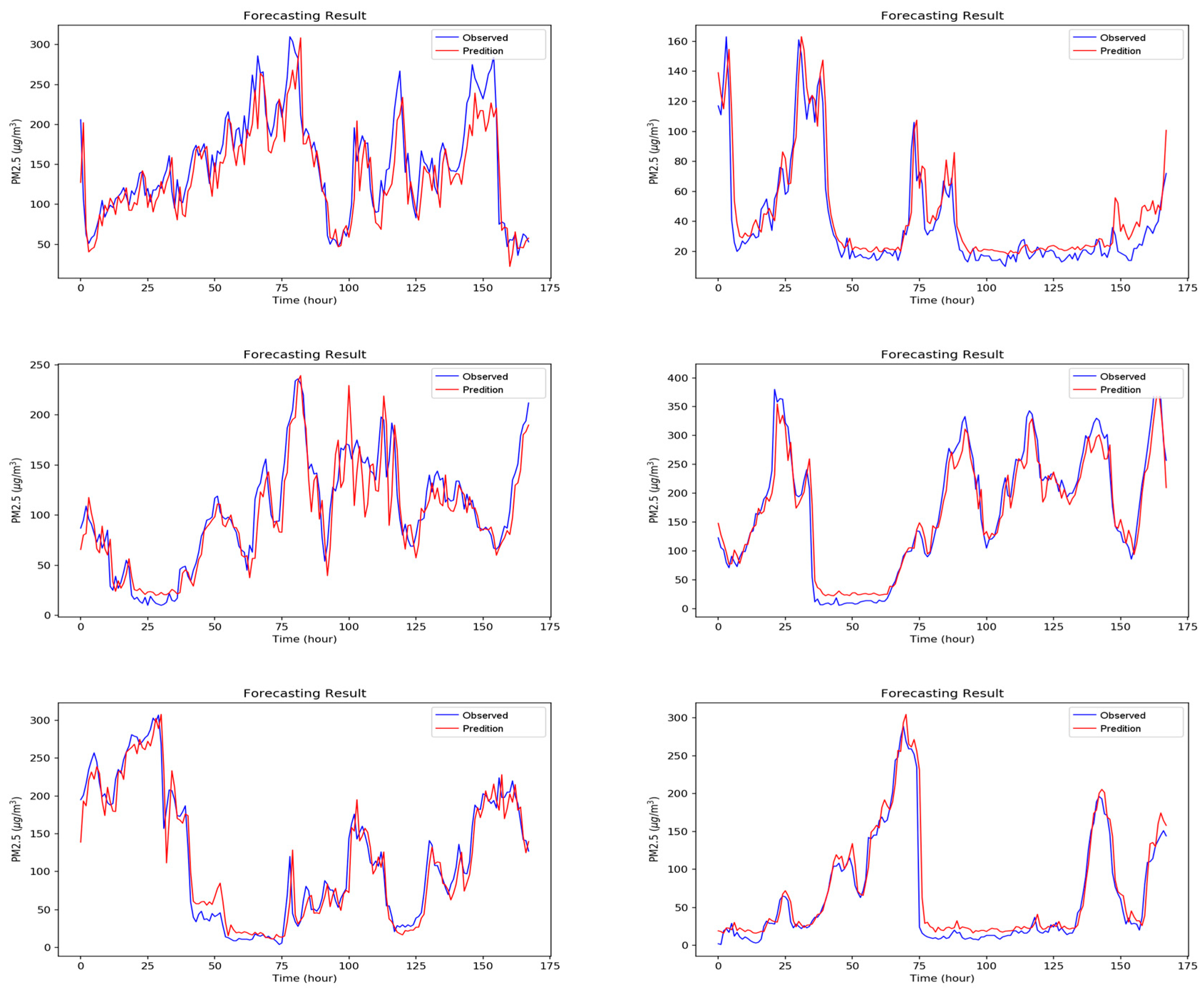
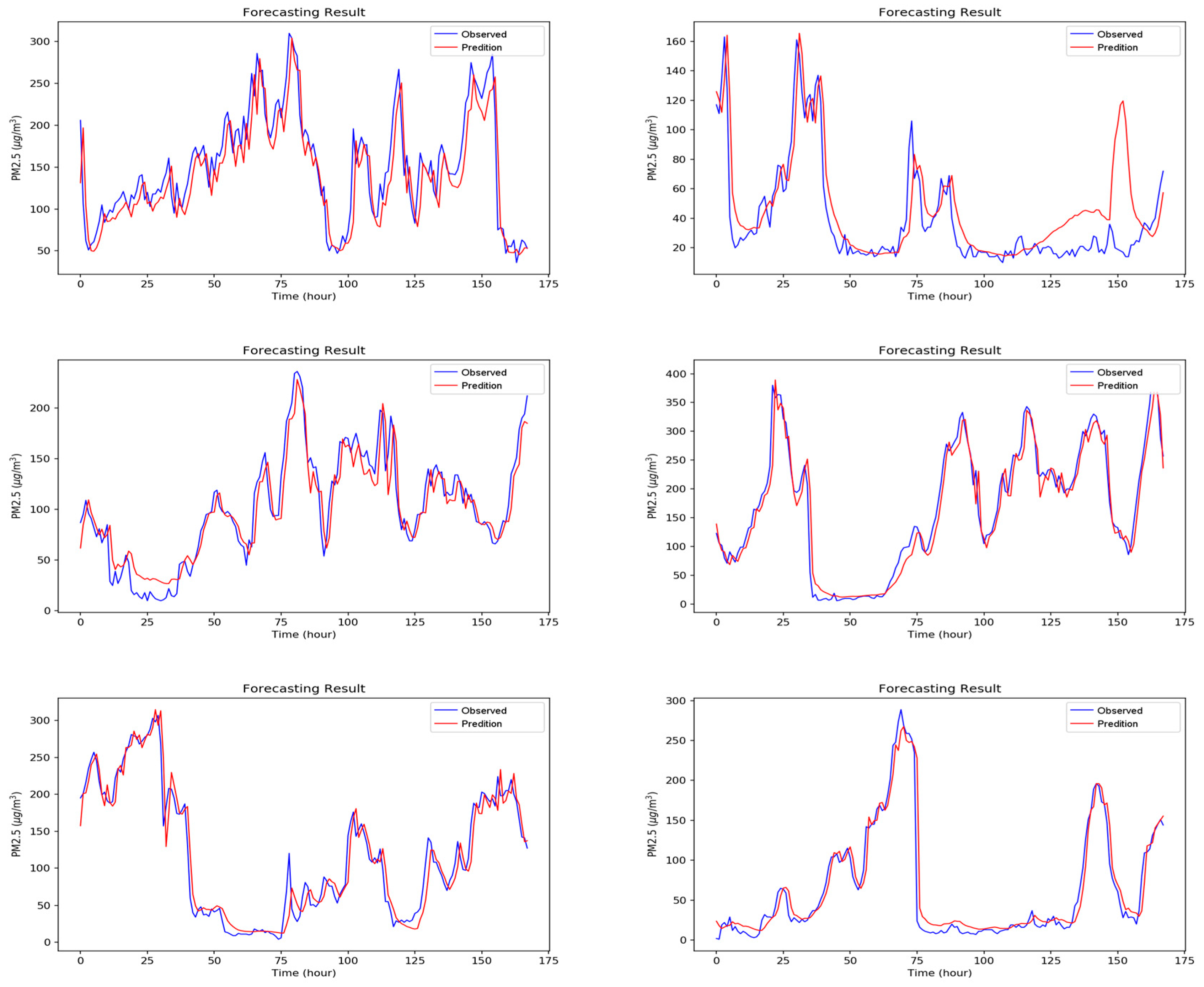
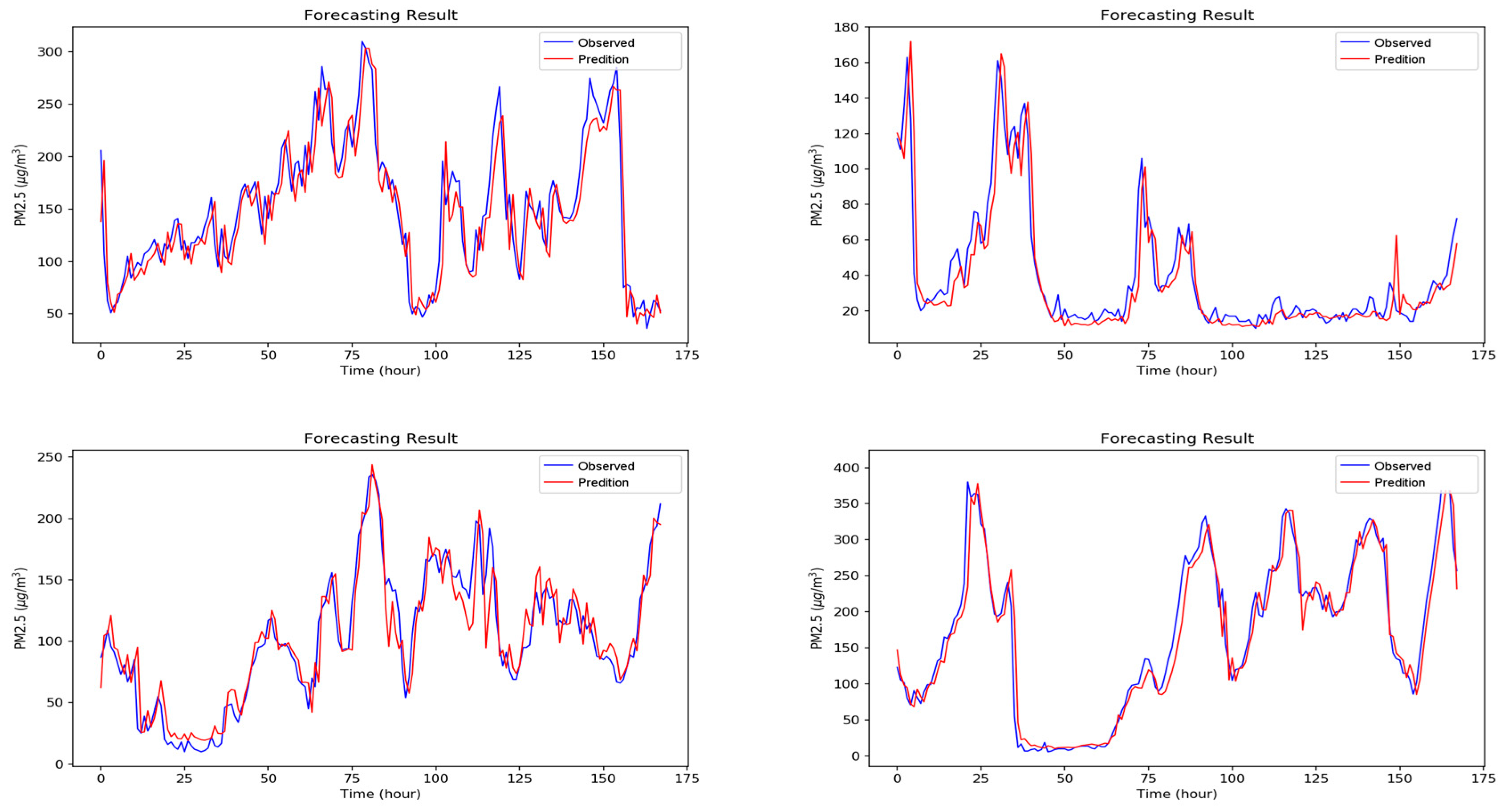
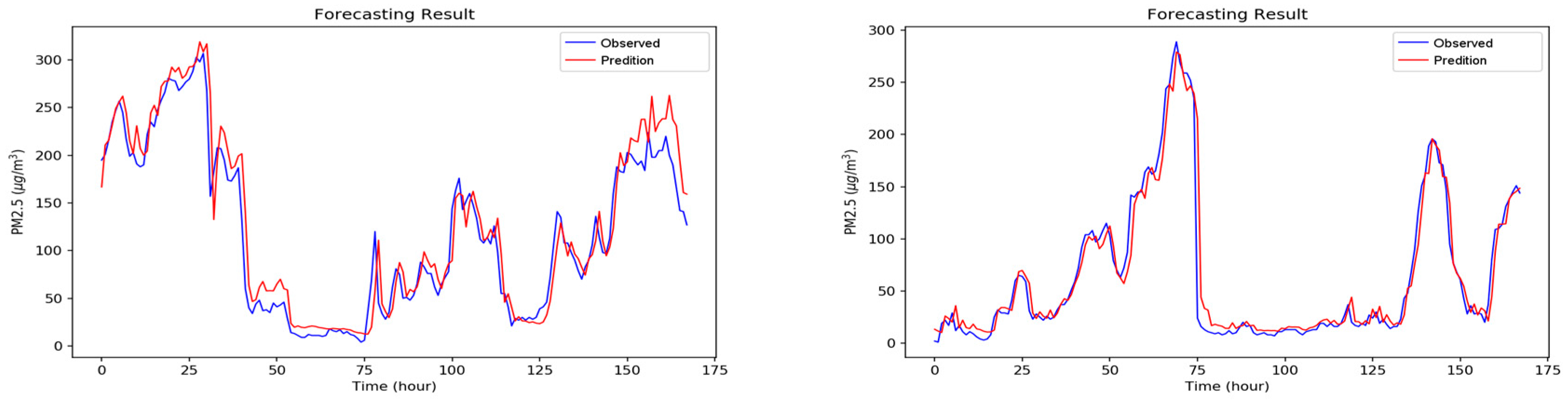
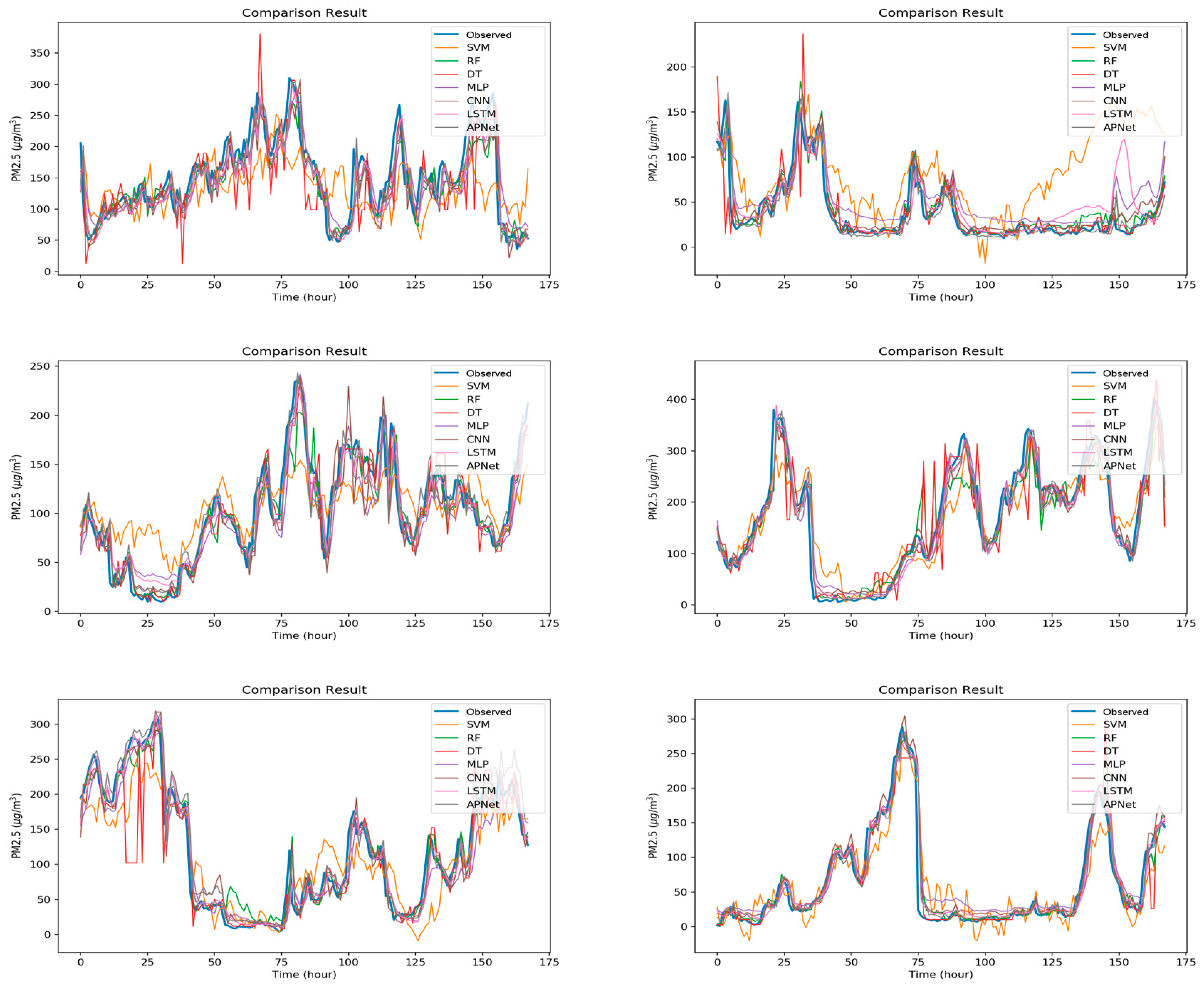
5. Experimental Results and Discussion
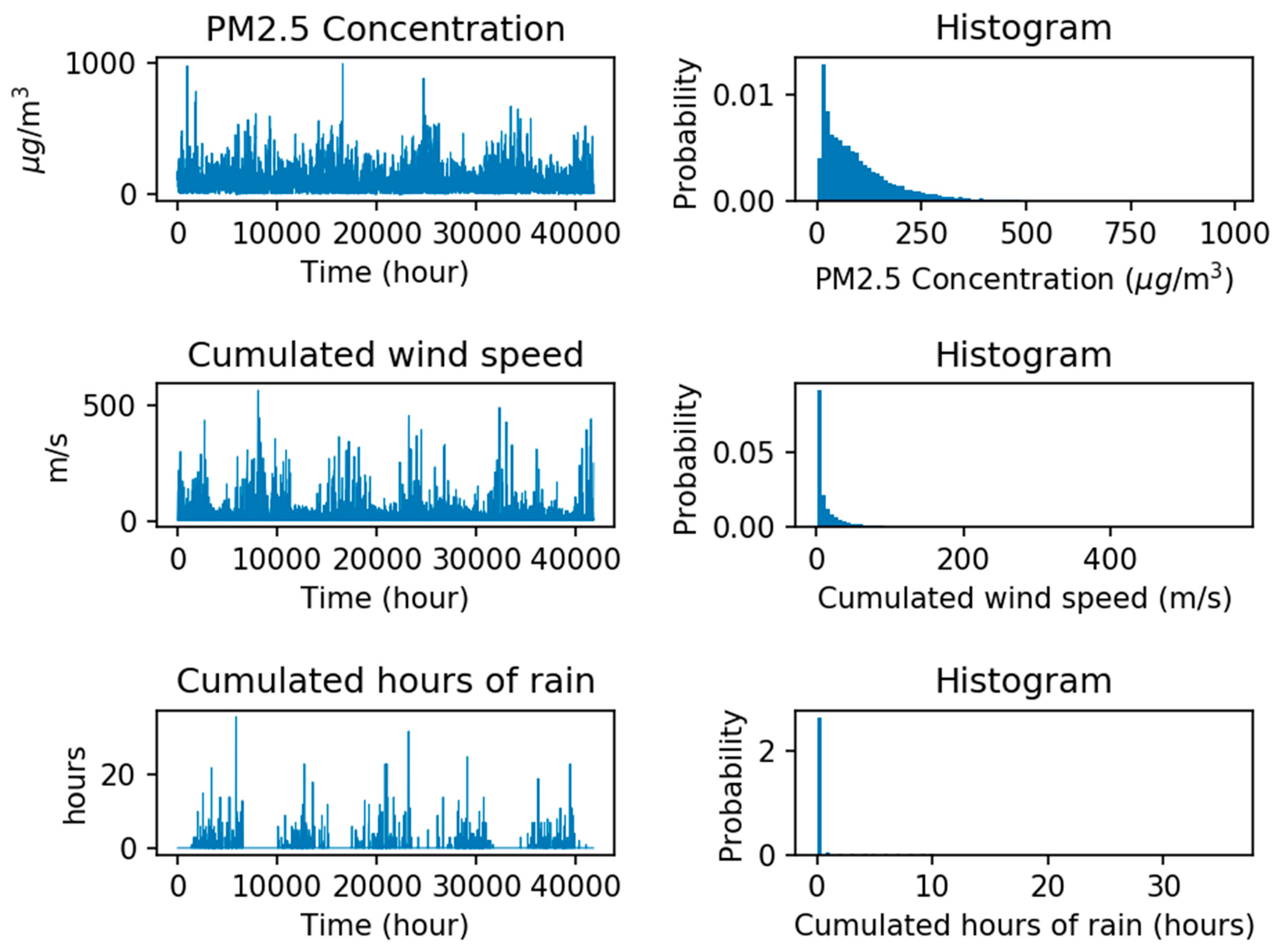
5.1. Data Descriptions
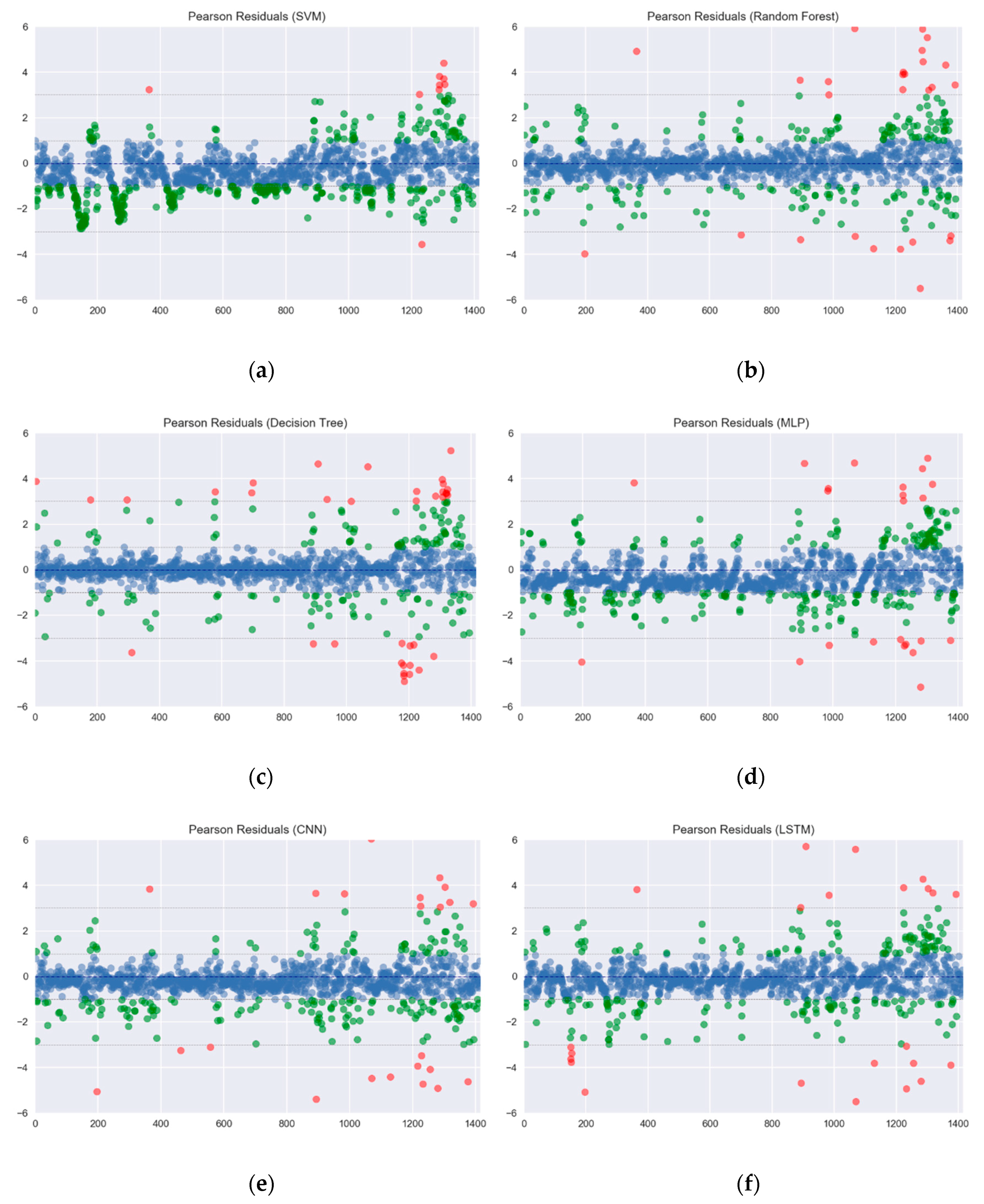
5.2. Experiment Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A










References
- International Energy Agency. Available online: https://www.iea.org/ (accessed on 22 February 2018).
- World Energy Outlook Special Report 2016. Available online: https://www.iea.org/publications/freepublications/publication/WorldEnergyOutlookSpecialReport2016EnergyandAirPollution.pdf (accessed on 22 February 2018).
- Chen, L.-J.; Ho, Y.-H.; Lee, H.-C.; Wu, H.-C.; Liu, H.-M.; Hsieh, H.-H.; Huang, Y.-T.; Lung, S.-C.C. An Open Framework for Participatory PM2.5 Monitoring in Smart Cities. IEEE Access 2017, 5, 14441–14454. [Google Scholar] [CrossRef]
- Han, L.; Zhou, W.; Li, W. City as a major source area of fine particulate (PM2.5) in China. Environ. Pollut. 2015, 206, 183–187. [Google Scholar] [CrossRef] [PubMed]
- Kioumourtzoglou, M.-A.; Schwartz, J.; James, P.; Dominici, F.; Zanobetti, A. PM2.5 and mortality in 207 US cities. Epidemiology 2015, 27, 221–227. [Google Scholar] [CrossRef]
- Walsh, M.P. PM2.5: Global progress in controlling the motor vehicle contribution. Front. Environ. Sci. Eng. 2014, 8, 1–17. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Chen, M.; Dong, W.; Jin, D. Software-defined internet of things for smart urban sensing. IEEE Commun. Mag. 2015, 53, 55–63. [Google Scholar] [CrossRef]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. Semantic framework of internet of things for smart cities: Case studies. Sensors 2016, 16, 1501. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Xiang, K. Adaptive Sampling for Urban Air Quality through Participatory Sensing. Sensors 2017, 17, 2531. [Google Scholar] [CrossRef] [PubMed]
- Ghaffari, S.; Caron, W.-O.; Loubier, M.; Normandeau, C.-O.; Viens, J.; Lamhamedi, M.; Gosselin, B.; Messaddeq, Y. Electrochemical Impedance Sensors for Monitoring Trace Amounts of NO3 in Selected Growing Media. Sensors 2015, 15, 17715–17727. [Google Scholar] [CrossRef] [PubMed]
- Lary, D.J.; Lary, T.; Sattler, B. Using Machine Learning to Estimate Global PM2.5 for Environmental Health Studies. Environ. Health Insights 2015, 9, 41–52. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Hu, Y.; Shao, J.; Chi, T. Deep learning architecture for air quality predictions. Environ. Sci. Pollut. Res. 2016, 23, 22408–22417. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Mathur, R.; Schere, K.; Kang, D.; Pleim, J.; Young, J.; Tong, D.; Pouliot, G.; McKeen, S.A.; Rao, S.T. Evaluation of real-time PM2.5 forecasts and process analysis for PM2.5 formation over the eastern United States using the Eta-CMAQ forecast model during the 2004 ICARTT study. J. Geophys. Res. 2008, 113, D06204. [Google Scholar] [CrossRef]
- Wang, Y.; Muth, J.F. An optical-fiber-based airborne particle sensor. Sensors 2017, 17, 2110. [Google Scholar] [CrossRef] [PubMed]
- Shao, W.; Zhang, H.; Zhou, H. Fine particle sensor based on multi-angle light scattering and data fusion. Sensors 2017, 17, 1033. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Dunea, D.; Pohoata, A.; Iordache, S. Using wavelet–feedforward neural networks to improve air pollution forecasting in urban environments. Environ. Monit. Assess. 2015, 187, 477. [Google Scholar] [CrossRef] [PubMed]
- Kuo, P.-H.; Chen, H.-C.; Huang, C.-J. Solar Radiation Estimation Algorithm and Field Verification in Taiwan. Energies 2018, 11, 1374. [Google Scholar] [CrossRef]
- Law Amendment Urged to Combat Air Pollution. Available online: http://www.china.org.cn/environment/2013-02/22/content_28031626_2.htm (accessed on 1 July 2018).
- Orbach, J. Principles of Neurodynamics. Perceptrons and the Theory of Brain Mechanisms. Arch. Gen. Psychiatry 1962, 7, 218. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Why Are Deep Neural Networks Hard to Train? Available online: http://neuralnetworksanddeeplearning.com/chap5.html (accessed on 1 July 2018).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dan Foresee, F.; Hagan, M.T. Gauss-Newton approximation to bayesian learning. In Proceedings of the IEEE International Conference on Neural Networks, Houston, TX, USA, 2 June 1997; IEEE: Piscataway, NJ, USA, 1997; Volume 3, pp. 1930–1935. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar] [CrossRef]
- Wan, L.; Zeiler, M.; Zhang, S.; LeCun, Y.; Fergus, R. Regularization of neural networks using dropconnect. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1058–1066. [Google Scholar]
- Prechelt, L. Early Stopping|but when? In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69, ISBN 978-3-642-35288-1, 978-3-642-35289-8. [Google Scholar]
- Improving the Way Neural Networks Learn. Available online: http://neuralnetworksanddeeplearning.com/chap3.html (accessed on 1 July 2018).
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Wang, S.; Hae, H.; Kim, J. Development of easily accessible electricity consumption model using open data and GA-SVR. Energies 2018, 11, 373. [Google Scholar] [CrossRef]
- Niu, D.; Li, Y.; Dai, S.; Kang, H.; Xue, Z.; Jin, X.; Song, Y. Sustainability Evaluation of Power Grid Construction Projects Using Improved TOPSIS and Least Square Support Vector Machine with Modified Fly Optimization Algorithm. Sustainability 2018, 10, 231. [Google Scholar] [CrossRef]
- Liu, J.P.; Li, C.L. The short-term power load forecasting based on sperm whale algorithm and wavelet least square support vector machine with DWT-IR for feature selection. Sustainability 2017, 9, 1188. [Google Scholar] [CrossRef]
- Das, M.; Akpinar, E. Investigation of Pear Drying Performance by Different Methods and Regression of Convective Heat Transfer Coefficient with Support Vector Machine. Appl. Sci. 2018, 8, 215. [Google Scholar] [CrossRef]
- Wang, J.; Niu, T.; Wang, R. Research and application of an air quality early warning system based on a modified least squares support vector machine and a cloud model. Int. J. Environ. Res. Public Health 2017, 14, 249. [Google Scholar] [CrossRef] [PubMed]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar] [CrossRef]
- Zhu, M.; Xia, J.; Jin, X.; Yan, M.; Cai, G.; Yan, J.; Ning, G. Class Weights Random Forest Algorithm for Processing Class Imbalanced Medical Data. IEEE Access 2018, 6, 4641–4652. [Google Scholar] [CrossRef]
- Ma, J.; Qiao, Y.; Hu, G.; Huang, Y.; Sangaiah, A.K.; Zhang, C.; Wang, Y.; Zhang, R. De-Anonymizing Social Networks With Random Forest Classifier. IEEE Access 2018, 6, 10139–10150. [Google Scholar] [CrossRef]
- Huang, N.; Lu, G.; Xu, D. A Permutation Importance-Based Feature Selection Method for Short-Term Electricity Load Forecasting Using Random Forest. Energies 2016, 9, 767. [Google Scholar] [CrossRef]
- Hassan, M.; Southworth, J. Analyzing Land Cover Change and Urban Growth Trajectories of the Mega-Urban Region of Dhaka Using Remotely Sensed Data and an Ensemble Classifier. Sustainability 2017, 10, 10. [Google Scholar] [CrossRef]
- Quintana, D.; Sáez, Y.; Isasi, P. Random Forest Prediction of IPO Underpricing. Appl. Sci. 2017, 7, 636. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man. Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Huang, N.; Peng, H.; Cai, G.; Chen, J. Power Quality Disturbances Feature Selection and Recognition Using Optimal Multi-Resolution Fast S-Transform and CART Algorithm. Energies 2016, 9, 927. [Google Scholar] [CrossRef]
- Alani, A.Y.; Osunmakinde, I.O. Short-Term Multiple Forecasting of Electric Energy Loads for Sustainable Demand Planning in Smart Grids for Smart Homes. Sustainability 2017, 9, 1972. [Google Scholar] [CrossRef]
- Rosli, N.; Rahman, M.; Balakrishnan, M.; Komeda, T.; Mazlan, S.; Zamzuri, H. Improved Gender Recognition during Stepping Activity for Rehab Application Using the Combinatorial Fusion Approach of EMG and HRV. Appl. Sci. 2017, 7, 348. [Google Scholar] [CrossRef]
- Rau, C.-S.; Wu, S.-C.; Chien, P.-C.; Kuo, P.-J.; Chen, Y.-C.; Hsieh, H.-Y.; Hsieh, C.-H.; Liu, H.-T. Identification of Pancreatic Injury in Patients with Elevated Amylase or Lipase Level Using a Decision Tree Classifier: A Cross-Sectional Retrospective Analysis in a Level I Trauma Center. Int. J. Environ. Res. Public Health 2018, 15, 277. [Google Scholar] [CrossRef] [PubMed]
- Rau, C.-S.; Wu, S.-C.; Chien, P.-C.; Kuo, P.-J.; Chen, Y.-C.; Hsieh, H.-Y.; Hsieh, C.-H. Prediction of Mortality in Patients with Isolated Traumatic Subarachnoid Hemorrhage Using a Decision Tree Classifier: A Retrospective Analysis Based on a Trauma Registry System. Int. J. Environ. Res. Public Health 2017, 14, 1420. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.-F.; Hu, M.-G.; Xu, C.-D.; Christakos, G.; Zhao, Y. Estimation of Citywide Air Pollution in Beijing. PLoS ONE 2013, 8, e53400. [Google Scholar] [CrossRef] [PubMed]
- Study on PM2.5 Pollution in Beijing Urban District from 2010 to 2014. Available online: http://www.stat-center.pku.edu.cn/Stat/Index/research_show/id/169 (accessed on 1 July 2018).
- Statistical Analysis of Air Pollution in Five Cities in China. Available online: http://www.stat-center.pku.edu.cn/Stat/Index/research_show/id/215 (accessed on 1 July 2018).
- Hwang, H.J.; Yook, S.J.; Ahn, K.H. Experimental investigation of submicron and ultrafine soot particle removal by tree leaves. Atmos. Environ. 2011, 45, 6987–6994. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | SVM | RF | DT | MLP | CNN | LSTM | APNet |
|---|---|---|---|---|---|---|---|
| #1 | 42.57556 | 18.68328 | 23.90568 | 22.4221 | 18.9675 | 18.5217 | 16.7474 |
| #2 | 35.40574 | 14.92391 | 19.53063 | 22.0437 | 14.8997 | 16.2908 | 14.2053 |
| #3 | 43.37174 | 16.74816 | 17.93104 | 20.2441 | 16.9613 | 15.8297 | 14.9131 |
| #4 | 50.19538 | 31.64949 | 36.57292 | 23.1328 | 20.7791 | 18.1417 | 18.2807 |
| #5 | 40.38873 | 19.54953 | 27.66294 | 22.8951 | 17.1051 | 16.505 | 17.2492 |
| #6 | 34.57838 | 17.80561 | 21.3065 | 18.5993 | 15.1543 | 13.9768 | 14.0047 |
| #7 | 37.10853 | 12.3846 | 15.37398 | 19.9247 | 15.3203 | 13.1789 | 11.9718 |
| #8 | 21.85433 | 9.96139 | 11.07522 | 13.9672 | 11.1243 | 11.1574 | 9.85554 |
| #9 | 40.47121 | 21.13339 | 25.09194 | 26.0607 | 18.954 | 17.2029 | 18.9953 |
| #10 | 33.1085 | 12.80574 | 15.72481 | 17.213 | 12.0842 | 12.6606 | 10.1216 |
| Average | 37.90581 | 17.56451 | 21.41757 | 20.65027 | 16.13498 | 15.34655 | 14.63446 |
| Test | SVM | RF | DT | MLP | CNN | LSTM | APNet |
|---|---|---|---|---|---|---|---|
| #1 | 56.55255 | 26.59535 | 36.90484 | 29.98992 | 26.36855 | 25.2699 | 23.83181 |
| #2 | 47.07641 | 26.84212 | 38.17991 | 30.86026 | 25.24918 | 27.20435 | 25.95273 |
| #3 | 55.9933 | 25.46634 | 29.14463 | 27.68189 | 24.43146 | 23.31643 | 22.56656 |
| #4 | 66.58581 | 47.20812 | 58.96869 | 35.14076 | 31.38514 | 29.63356 | 31.08485 |
| #5 | 50.32762 | 31.14631 | 55.65785 | 31.59871 | 26.4418 | 27.15832 | 26.77069 |
| #6 | 47.23936 | 32.32307 | 43.69507 | 27.00565 | 23.87708 | 23.05538 | 24.81823 |
| #7 | 48.11796 | 22.96514 | 33.33885 | 28.78185 | 24.29253 | 23.04227 | 20.83558 |
| #8 | 27.70533 | 16.61144 | 19.44406 | 19.52802 | 16.63667 | 17.22178 | 16.44391 |
| #9 | 57.49434 | 39.29988 | 44.9455 | 38.8347 | 31.03137 | 30.14096 | 35.23974 |
| #10 | 43.12105 | 20.30241 | 34.27529 | 21.50208 | 16.24985 | 16.88207 | 14.7433 |
| Average | 50.02137 | 28.87602 | 39.45547 | 29.09238 | 24.59636 | 24.2925 | 24.22874 |
| Test | SVM | RF | DT | MLP | CNN | LSTM | APNet |
|---|---|---|---|---|---|---|---|
| #1 | 0.638786 | 0.926131 | 0.857044 | 0.907166 | 0.935633 | 0.940295 | 0.941237 |
| #2 | 0.92699 | 0.973356 | 0.945972 | 0.968823 | 0.977848 | 0.973044 | 0.975517 |
| #3 | 0.754792 | 0.944363 | 0.926856 | 0.936873 | 0.950255 | 0.953075 | 0.955411 |
| #4 | 0.872546 | 0.924315 | 0.868861 | 0.957647 | 0.970539 | 0.970023 | 0.966768 |
| #5 | 0.70376 | 0.893368 | 0.699291 | 0.89043 | 0.922092 | 0.919221 | 0.932416 |
| #6 | 0.870895 | 0.938605 | 0.879954 | 0.956404 | 0.966881 | 0.967185 | 0.964074 |
| #7 | 0.843806 | 0.966459 | 0.927678 | 0.947582 | 0.964757 | 0.966151 | 0.972383 |
| #8 | 0.887029 | 0.957205 | 0.943408 | 0.941748 | 0.95875 | 0.953544 | 0.96088 |
| #9 | 0.914454 | 0.959145 | 0.940049 | 0.961928 | 0.9731 | 0.97354 | 0.963773 |
| #10 | 0.700245 | 0.939808 | 0.8138 | 0.936971 | 0.963777 | 0.963319 | 0.967397 |
| Average | 0.81133 | 0.942276 | 0.880291 | 0.940557 | 0.958363 | 0.95794 | 0.959986 |
| Test | SVM | RF | DT | MLP | CNN | LSTM | APNet |
|---|---|---|---|---|---|---|---|
| #1 | 0.745175 | 0.958607 | 0.923722 | 0.943082 | 0.959601 | 0.963882 | 0.968546 |
| #2 | 0.952324 | 0.98613 | 0.972305 | 0.980782 | 0.988124 | 0.985715 | 0.987253 |
| #3 | 0.716799 | 0.968534 | 0.962342 | 0.964832 | 0.972961 | 0.974219 | 0.976896 |
| #4 | 0.873168 | 0.95108 | 0.92713 | 0.975282 | 0.979759 | 0.983128 | 0.981386 |
| #5 | 0.790755 | 0.940903 | 0.82489 | 0.93198 | 0.958817 | 0.957693 | 0.961527 |
| #6 | 0.897091 | 0.960562 | 0.924618 | 0.974253 | 0.982193 | 0.982024 | 0.978416 |
| #7 | 0.904886 | 0.982324 | 0.961747 | 0.970803 | 0.979047 | 0.982588 | 0.985856 |
| #8 | 0.924705 | 0.977994 | 0.97085 | 0.967449 | 0.977596 | 0.975862 | 0.979732 |
| #9 | 0.934477 | 0.973919 | 0.967458 | 0.974426 | 0.984648 | 0.985924 | 0.980962 |
| #10 | 0.784602 | 0.962931 | 0.900264 | 0.957321 | 0.976973 | 0.976935 | 0.982527 |
| Average | 0.852398 | 0.966298 | 0.933533 | 0.964021 | 0.975972 | 0.976797 | 0.97831 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.-J.; Kuo, P.-H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors 2018, 18, 2220. https://doi.org/10.3390/s18072220
Huang C-J, Kuo P-H. A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors. 2018; 18(7):2220. https://doi.org/10.3390/s18072220
Chicago/Turabian StyleHuang, Chiou-Jye, and Ping-Huan Kuo. 2018. "A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities" Sensors 18, no. 7: 2220. https://doi.org/10.3390/s18072220
APA StyleHuang, C. -J., & Kuo, P. -H. (2018). A Deep CNN-LSTM Model for Particulate Matter (PM2.5) Forecasting in Smart Cities. Sensors, 18(7), 2220. https://doi.org/10.3390/s18072220