Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery †

 ,
,  ,
,
Abstract
:1. Introduction
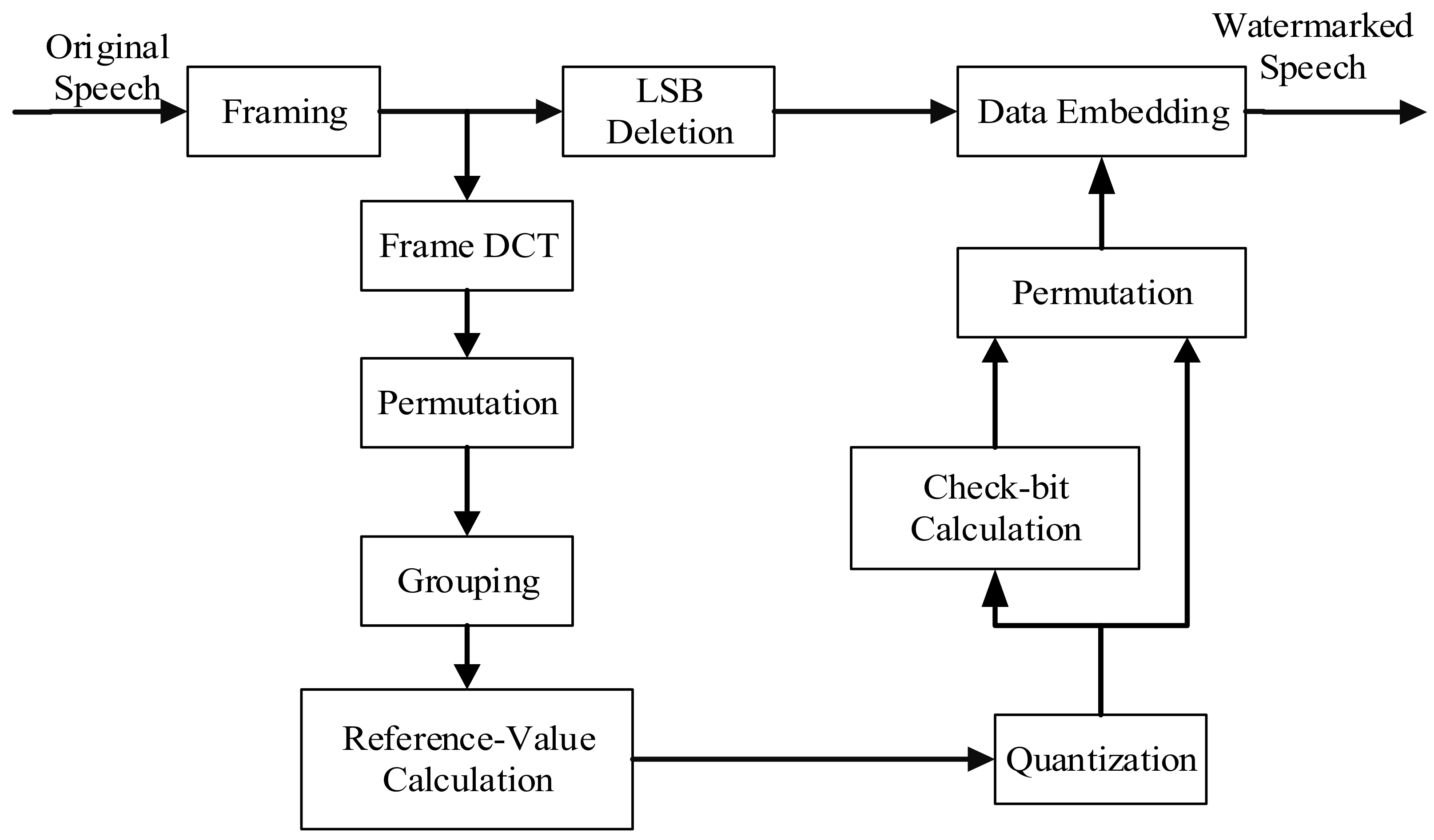
2. Watermarking Embedding Procedure
3. Signal Recovery Procedure
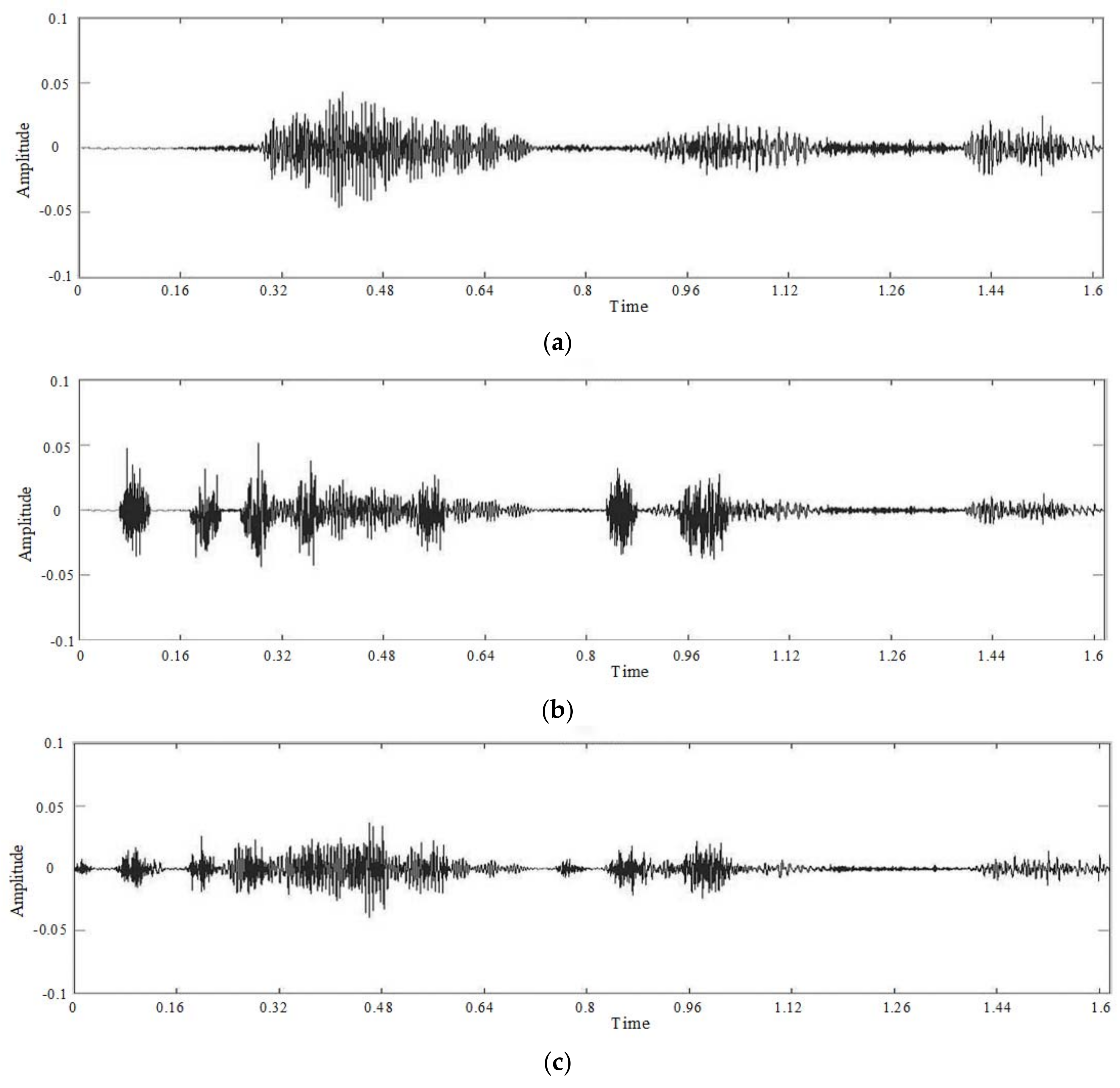
3.1. Tampered Area Localization
3.2. Data Recovery
3.3. Content Recovery by Compressive Sensing
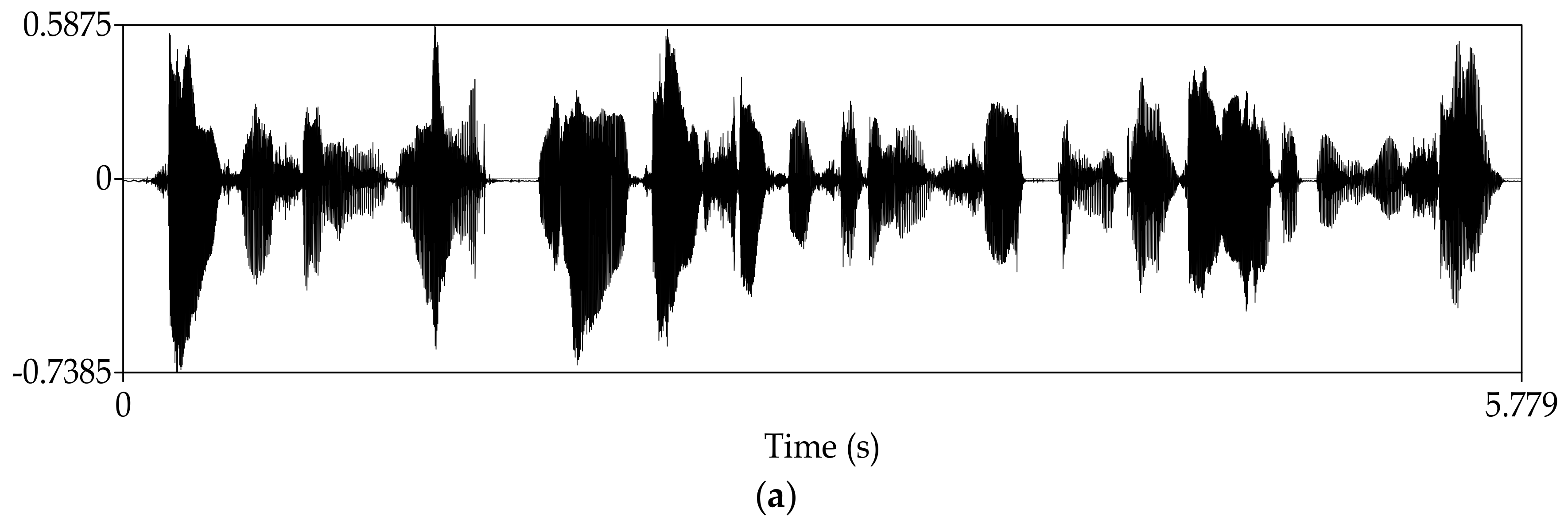
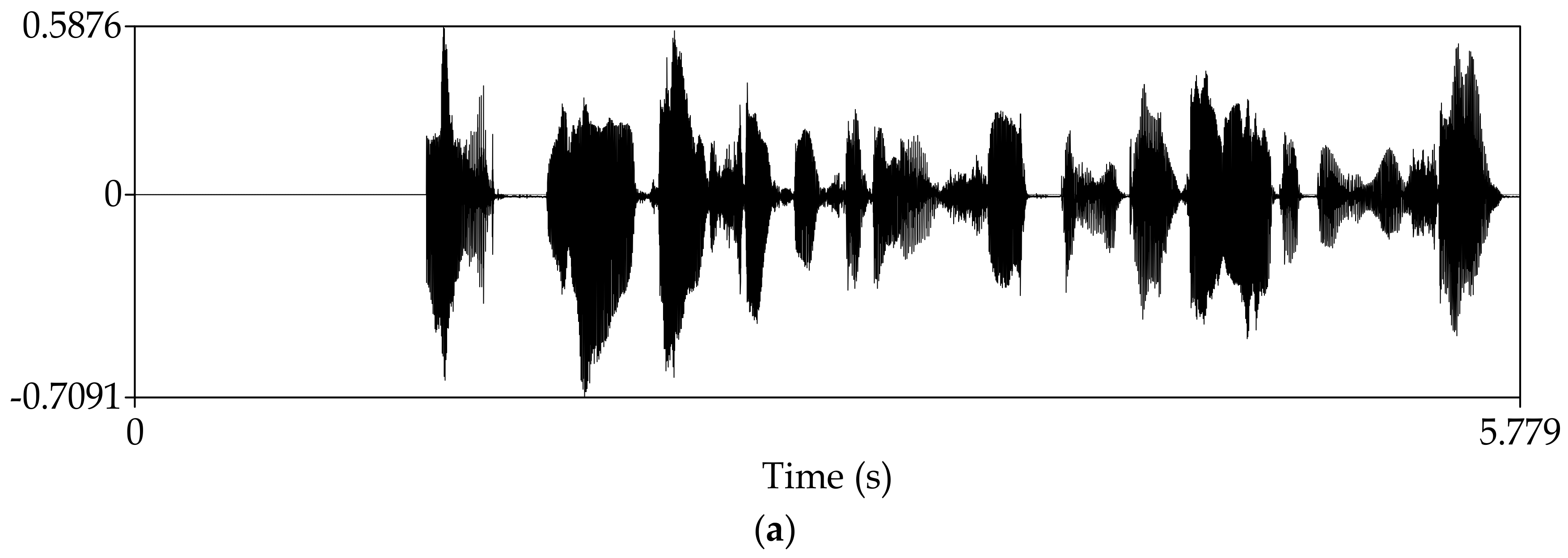
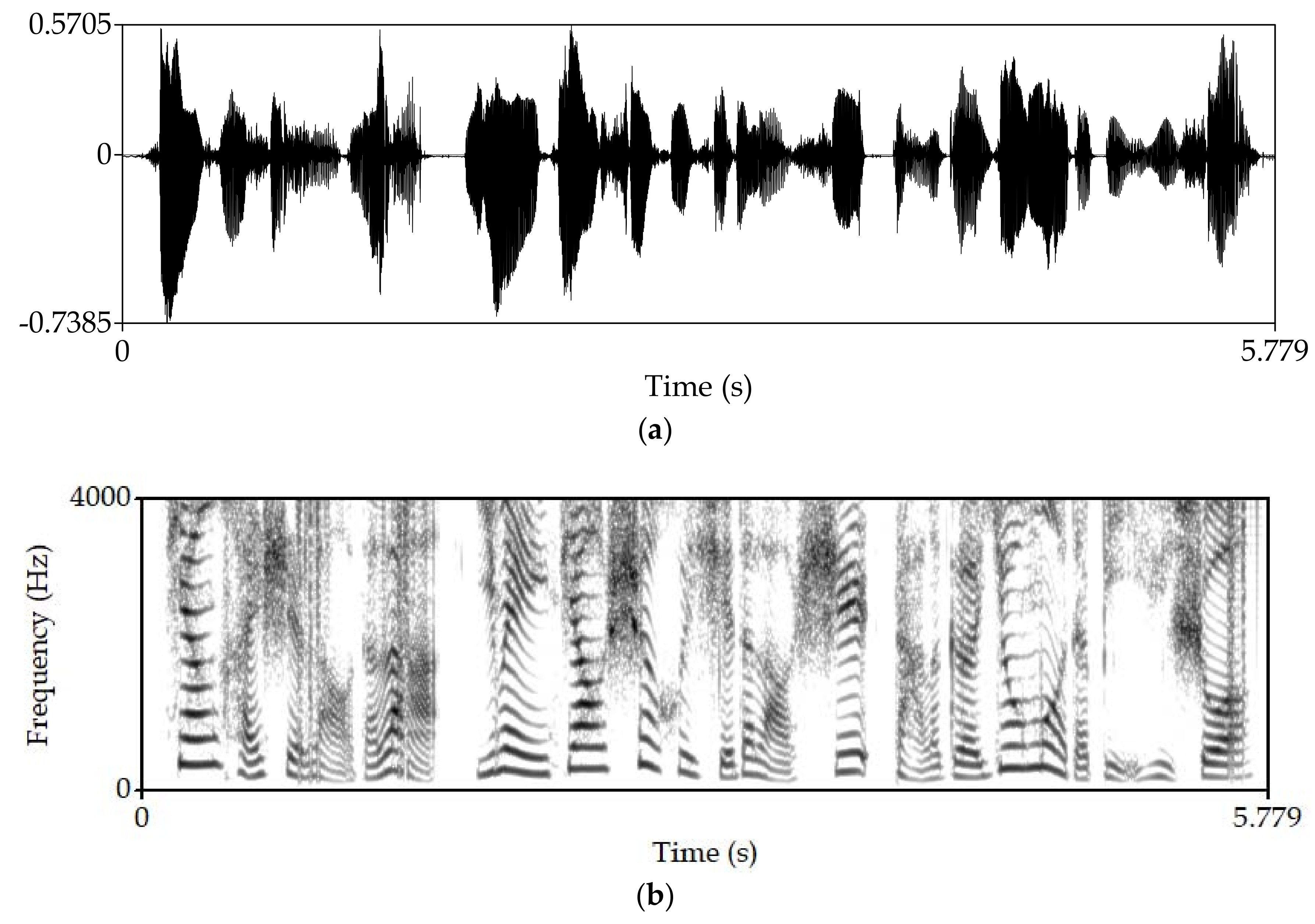
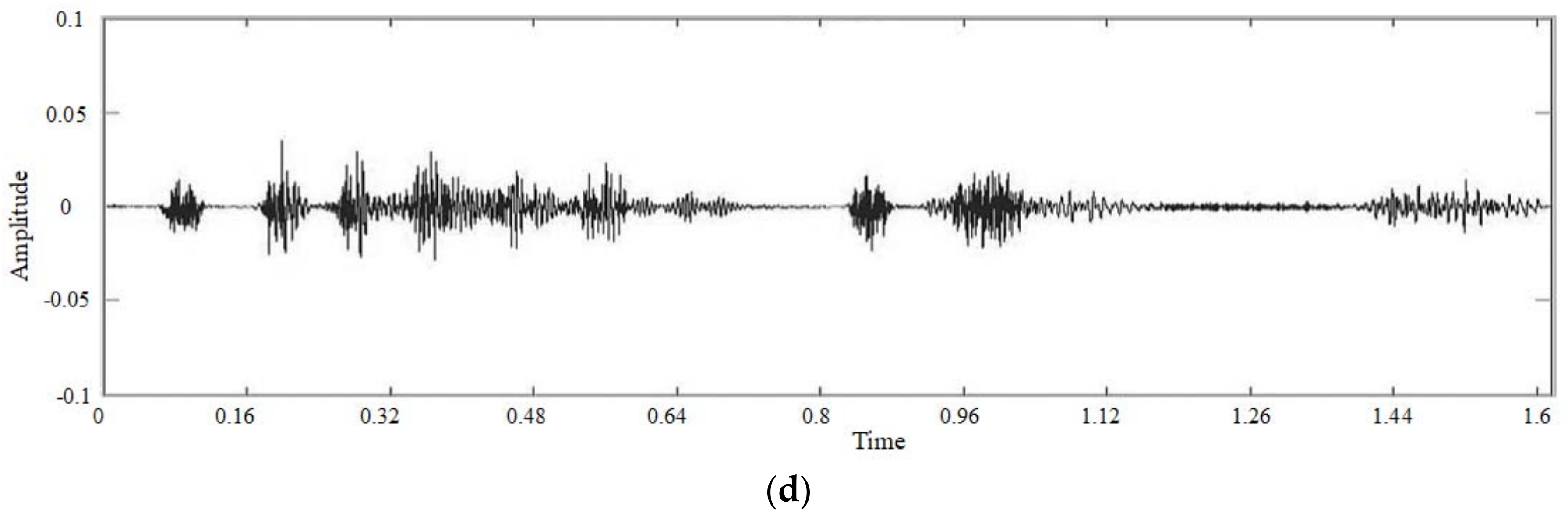
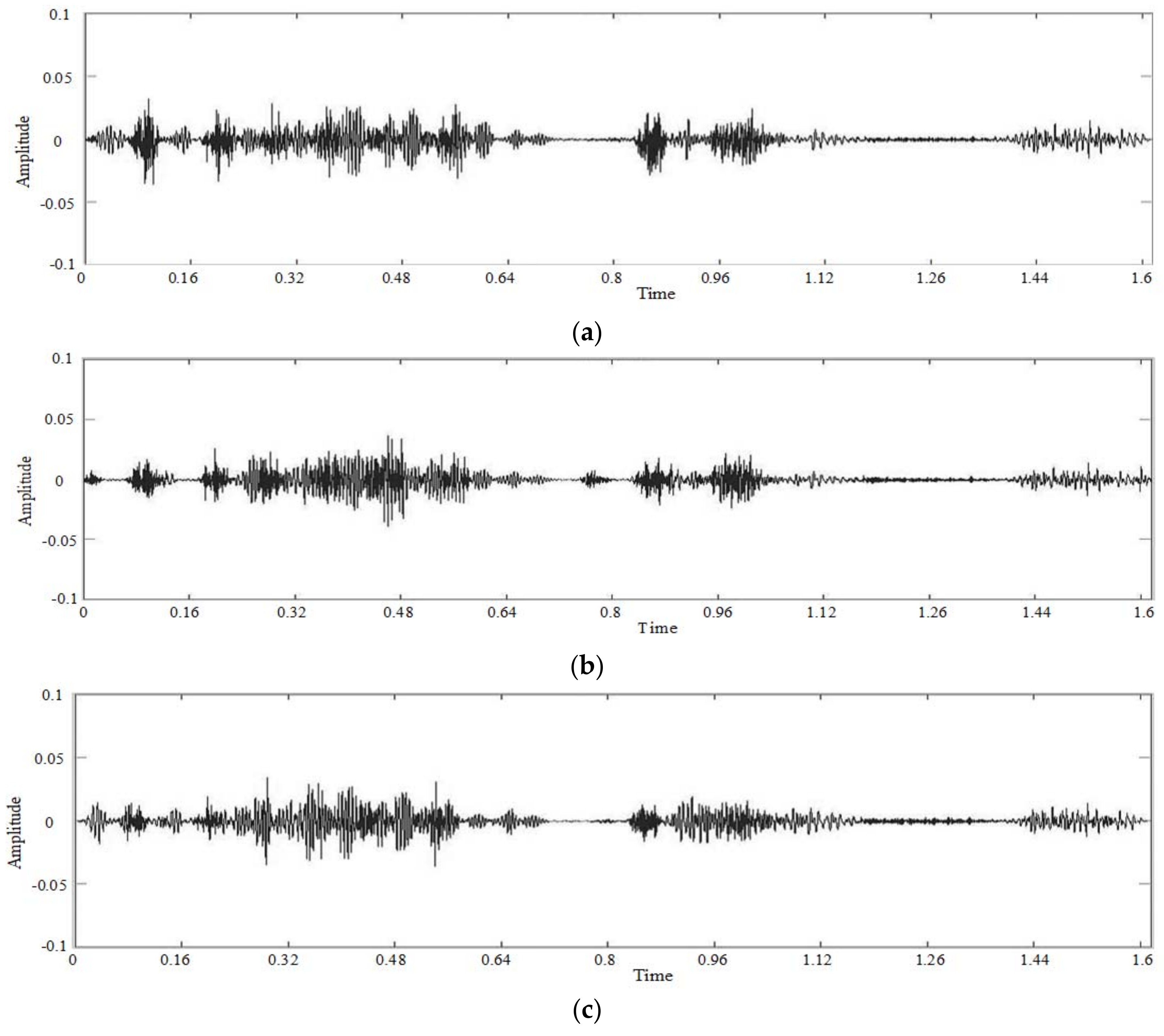
4. Experimental Results
4.1. Subjective Experiment
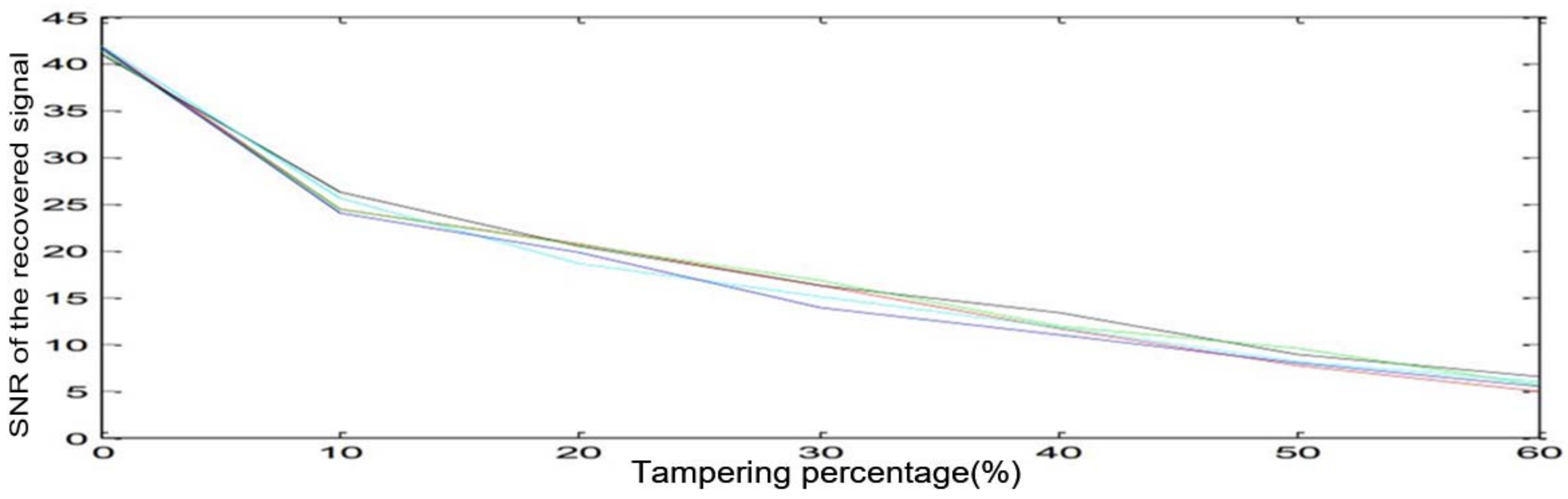
4.2. Objective Experiment
5. Speech Enhancement
5.1. Comparison of the Number of Hidden Layer Nodes
5.2. Comparison of the Number of Hidden Layers
5.3. Comparison of Iterations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Piva, A.; Barni, M.; Bartolini, F.; Cappellini, C. DCT-based watermark recovering without resorting to the uncorrupted original image. In Proceedings of the International Conference on Image Processing, Santa Barbara, CA, USA, 26–29 October 1997; Volume 1, pp. 520–523. [Google Scholar]
- Patra, B.; Patra, J.C. CRT-based self-recovery watermarking technique for multimedia applications. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 1761–1764. [Google Scholar]
- Dey, N.; Roy, A.B.; Das, A.; Chaudhuri, S.S. Stationary Wavelet Transformation Based Self-recovery of Blind-Watermark from Electrocardiogram Signal in Wireless Telecardiology. In Recent Trends in Computer Networks and Distributed Systems Security; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Chen, F.; He, H.; Huo, Y.; Wang, H. Self-recovery fragile watermarking scheme with variable watermark payload. In Digital Forensics and Watermarking; Springer: Berlin/Heidelberg, Germany, 2012; pp. 142–155. [Google Scholar]
- Zhang, X.; Wang, S. Fragile watermarking with error-free restoration capability. IEEE Trans. Multimedia 2008, 10, 1490–1499. [Google Scholar] [CrossRef]
- Fridrich, J.; Goljan, M. Images with self-correcting capabilities. In Proceedings of the International Conference on Image Processing, Kobe, Japan, 24–28 October 1999; pp. 792–796. [Google Scholar]
- He, H.; Zhang, J.; Chen, F. Adjacent-block based statistical detection method for self-embedding watermarking techniques. Signal Process. 2009, 89, 1557–1566. [Google Scholar] [CrossRef]
- Wu, C.M.; Shih, Y.S. A Simple Image Tamper Detection and Recovery Based on Fragile Watermark with One Parity Section and Two Restoration Sections. Opt. Photonics J. 2013, 3, 103–107. [Google Scholar] [CrossRef]
- Yang, M.; Bourbakis, N. An efficient packet loss recovery methodology for video streaming over IP networks. IEEE Trans. Broadcast. 2009, 55, 190–210. [Google Scholar] [CrossRef]
- Anbarjafari, G.; Ozcinar, C. Imperceptible non-blind watermarking and robustness against tone mapping operation attacks for high dynamic range images. Multimedia Tools Appl. 2018. [Google Scholar] [CrossRef]
- Lu, C.S.; Liao, H.M. Multipurpose watermarking for image authentication and protection. IEEE Trans. Image Process. 2001, 10, 1579–1592. [Google Scholar] [PubMed] [Green Version]
- Eswaraiah, R.; Reddy, E.S. Robust medical image watermarking technique for accurate detection of tampers inside region of interest and recovering original region of interest. IET Image Process. 2015, 9, 615–625. [Google Scholar] [CrossRef]
- Yeh, F.H.; Lee, G.C. Toral fragile watermarking for localizing and recovering tampered image. In Proceedings of the 2005 International Symposium on Intelligent Signal Processing and Communication Systems, Hong Kong, China, 13–16 December 2006; pp. 321–324. [Google Scholar]
- Lin, P.L.; Hsieh, C.K.; Huang, P.W. A hierarchical digital watermarking method for image tamper detection and recovery. Pattern Recognit. 2005, 38, 2519–2529. [Google Scholar] [CrossRef]
- Zhu, X.; Ho, A.; Marziliano, P. A new semi-fragile image watermarking with robust tampering restoration using irregular sampling. Signal Process. Image Commun. 2008, 23, 298–312. [Google Scholar] [CrossRef]
- Gur, G.; Altug, Y.; Anarim, E.; Alagoz, F. Image error concealment using watermarking with subbands for wireless channels. IEEE Commun. Lett. 2008, 11, 298–312. [Google Scholar]
- Chamlawi, R.; Khan, A.; Usman, I. Authentication and recovery of images using multiple watermarks. Comput. Electr. Eng. 2010, 36, 578–584. [Google Scholar] [CrossRef]
- Inoue, H.; Miyazaki, A.; Yamamoto, A.; Katsura, T. A digital watermark based on the wavelet transform and its robustness on image compression. In Proceedings of the 1998 International Conference on Image Processing (ICIP98), Chicago, IL, USA, 7 October 1998; Volume 2, pp. 391–395. [Google Scholar]
- Zhang, X.P.; Qian, Z.X.; Ren, Y.L.; Feng, G.R. Watermarking with flexible self-recovery quality based on compressive sensing and compositive reconstruction. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1223–1232. [Google Scholar] [CrossRef]
- Lee, T.Y.; Lin, S.D. Dual watermark for image tamper detection and recovery. Pattern Recognit. 2008, 89, 675–679. [Google Scholar] [CrossRef]
- Van Schyndel, R.G.; Tirkel, A.Z.; Osborne, C.E. A digital watermark. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; pp. 86–90. [Google Scholar]
- Zhang, X.P.; Wang, S.Z.; Feng, G.R. Fragile Watermarking Scheme with Extensive Content Restoration Capability. In Digital Watermarking; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5703, pp. 268–278. [Google Scholar]
- Zhang, X.P.; Wang, S.Z.; Qian, Z.X.; Feng, G.R. Reference Sharing Mechanism for Watermark Self-Embedding. IEEE Trans. Image Process. 2011, 20, 485–495. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Lin, T.; Feng, G. Technique of characteristic-based self-embedded watermark using in audio. Comput. Eng. Appl. 2007, 43, 192–194. [Google Scholar]
- Chen, F.; He, H.; Wang, H. A fragile watermarking scheme for audio detection and recovery. Congr. Image Signal Process. 2008, 5, 135–138. [Google Scholar]
- Vleeschouwer, C.; Delaigle, J.-F.; Macq, B. Invisibility and application functionalities in perceptual watermarking—An overview. Proc. IEEE 2002, 90, 64–77. [Google Scholar] [CrossRef]
- Li, S.; Song, Z.; Lu, W.; Sun, D.; Wei, J. Parameterization of LSB in Self-Recovery Speech Watermarking Framework in Big Data Mining. Secur. Commun. Netw. 2017, 2017, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient Projection for Sparse Reconstruction: Application to Compressed Sensing and Other Inverse Problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery from Random Measurements via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Bhat, V.K.; Sengupta, I.; Das, A. An adaptive audio watermarking based on the singular value decomposition in the wavelet domain. Digit. Signal Process. 2010, 20, 1547–1558. [Google Scholar] [CrossRef]
- Cox, I.; Kilian, J.; Leighton, F.T.; Shamoon, T. Secure spread spectrum watermarking for multimedia. IEEE Trans. Image Process. 1997, 6, 1673–1687. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ozer, H.; Sankur, B.; Memon, N. An SVD-based audio watermarking technique. In Proceedings of the 7th ACM Workshop Multimedia Security, New York, NY, USA, 1–2 August 2005; pp. 51–56. [Google Scholar]
- El-Samie, F.E.A. An efficient singular value decomposition algorithm for digital audio watermarking. Int. J. Speech Technol. 2009, 12, 27–45. [Google Scholar] [CrossRef]
- Swanson, M.D.; Zhu, B.; Tewfik, A.H.; Boney, L. Robust audio watermarking using perceptual masking. Signal Process. 1998, 66, 337–355. [Google Scholar] [CrossRef]
- Erfani, Y.; Siahpoush, S. Robust audio watermarking using improved TS echo hiding. Digit. Signal Process. 2009, 19, 809–814. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Description | SDG |
|---|---|---|
| 5.0 | Imperceptible | 0 |
| 4.9~4.0 | Imperceptible but not annoying | −0.1~−1.0 |
| 3.9~3.0 | Slightly annoying | −1.1~−2.0 |
| 2.9~2.0 | Annoying | −2.1~−3.0 |
| 1.9~1.0 | Very annoying | −3.1~−4.0 |
| Audio Signal | Subjective Evaluation | Objective Evaluation | |
|---|---|---|---|
| SDG | Correct Detection (%) | SNR | |
| 1 | −0.05 | 54 | 41.80 |
| 2 | 0.0 | 52 | 40.95 |
| 3 | −0.07 | 46 | 41.32 |
| 4 | 0.0 | 48 | 41.93 |
| 5 | 0.0 | 46 | 41.68 |
| Average | −0.024 | 49.2 | 41.54 |
| Reference | Algorithm | SNR | MOS |
|---|---|---|---|
| [32] | Spread spectrum | 28.59 | 4.46 |
| [33] | STFT-SVD | 28.36 | 4.70 |
| [34] | SVD | 27.13 | 4.60 |
| [31] | DWT-SVD | 26.84 | 4.60 |
| [35] | Frequency masking | 12.87 | 2.93 |
| [36] | TS echo hiding | 22.70 | 4.70 |
| Proposed | DCT-CS | 41.54 | 4.97 |
| Audio Number | 1 | 2 | 3 | 4 | 5 | Average (%) | |
|---|---|---|---|---|---|---|---|
| Tampering Percentage (%) | |||||||
| 0 | 41.80 | 40.95 | 41.32 | 41.93 | 41.68 | 41.54 | |
| 10 | 24.47 | 26.28 | 24.38 | 25.60 | 24.03 | 24.95 | |
| 20 | 20.70 | 20.42 | 20.58 | 18.65 | 19.77 | 20.02 | |
| 30 | 16.23 | 16.20 | 16.80 | 15.02 | 13.83 | 15.62 | |
| 40 | 11.67 | 13.33 | 11.92 | 11.79 | 10.97 | 11.94 | |
| 50 | 7.76 | 8.90 | 9.53 | 8.12 | 7.91 | 8.44 | |
| 60 | 4.87 | 6.52 | 5.60 | 5.95 | 5.41 | 5.67 | |
| Watermarking—Recovery | Watermarking—Decrement of Nodes | Watermarking—Same Number of Nodes |
|---|---|---|
| −0.20249 | 2.0729 | 1.3375 |
| Watermarking—Recovery | Watermarking—4 Layers | Watermarking—7 Layers |
|---|---|---|
| −0.20249 | 2.0729 | −2.563 |
| Watermarking—Recovery | Watermarking—100 Iterations | Watermarking—200 Iterations | Watermarking—500 Iterations |
|---|---|---|---|
| −0.20249 | 1.6238 | 2.0729 | 1.2703 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, W.; Chen, Z.; Li, L.; Cao, X.; Wei, J.; Xiong, N.; Li, J.; Dang, J. Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery †. Sensors 2018, 18, 2390. https://doi.org/10.3390/s18072390
Lu W, Chen Z, Li L, Cao X, Wei J, Xiong N, Li J, Dang J. Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery †. Sensors. 2018; 18(7):2390. https://doi.org/10.3390/s18072390
Chicago/Turabian StyleLu, Wenhuan, Zonglei Chen, Ling Li, Xiaochun Cao, Jianguo Wei, Naixue Xiong, Jian Li, and Jianwu Dang. 2018. "Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery †" Sensors 18, no. 7: 2390. https://doi.org/10.3390/s18072390
APA StyleLu, W., Chen, Z., Li, L., Cao, X., Wei, J., Xiong, N., Li, J., & Dang, J. (2018). Watermarking Based on Compressive Sensing for Digital Speech Detection and Recovery †. Sensors, 18(7), 2390. https://doi.org/10.3390/s18072390