Detection of Talking in Respiratory Signals: A Feasibility Study Using Machine Learning and Wearable Textile-Based Sensors



Abstract
:1. Introduction
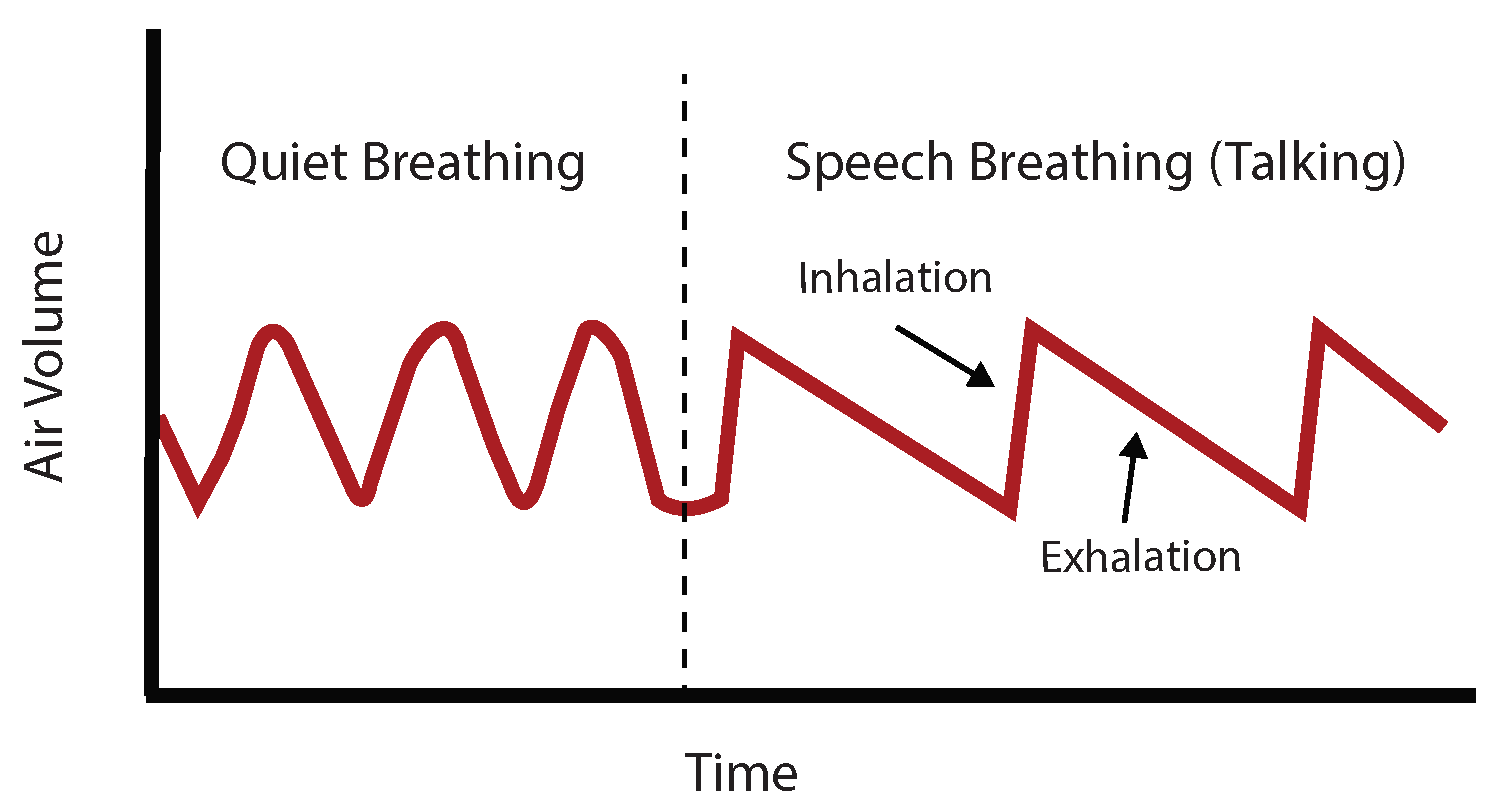
1.1. Detection of Talking (Speech Breathing)
1.2. Textile-Based Sensors
2. Materials and Methods
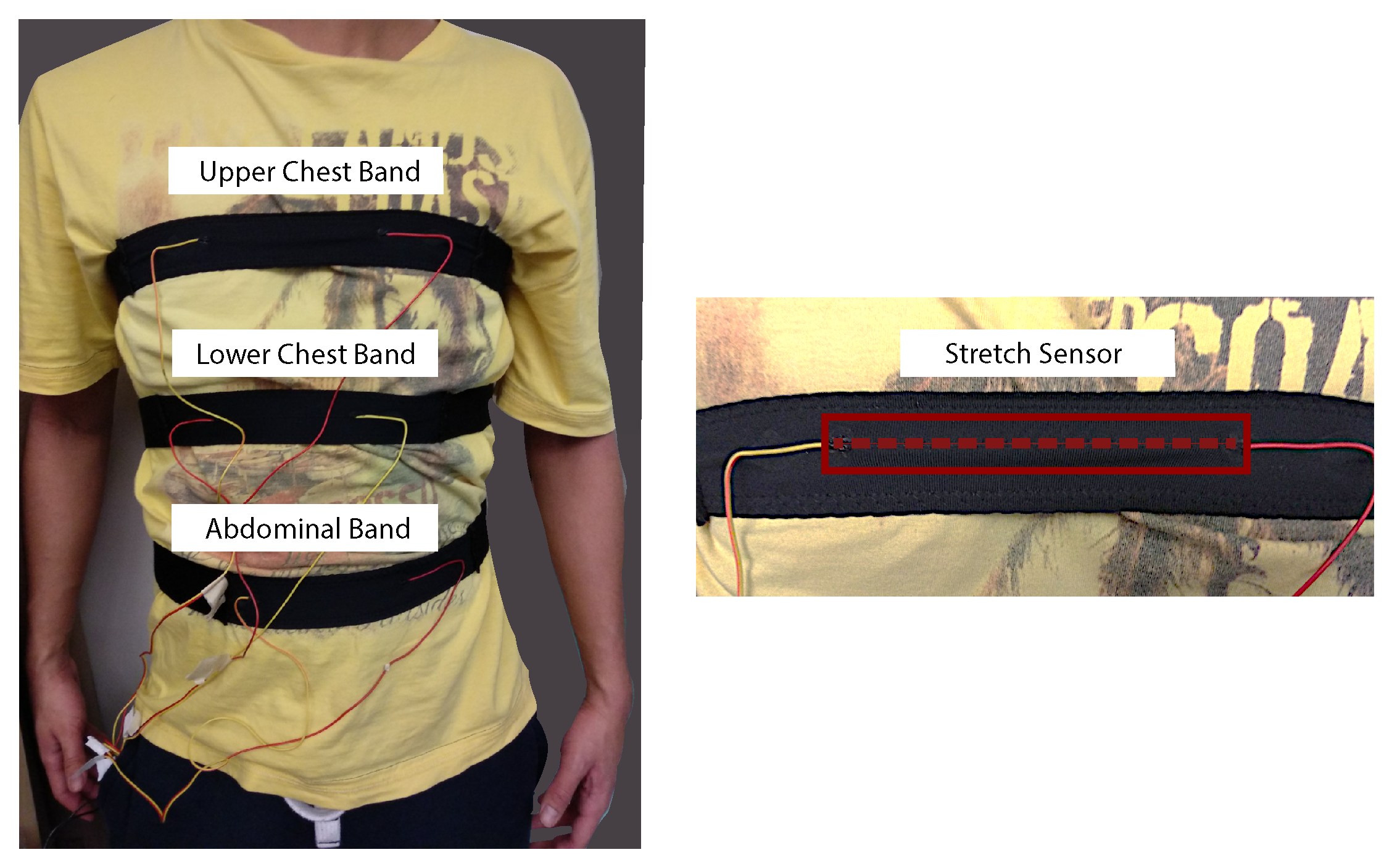
2.1. Stretch Sensor
2.2. Chest and Abdominal Bands
2.3. Data Acquisition Hardware
2.4. Study Protocol
2.5. Participants
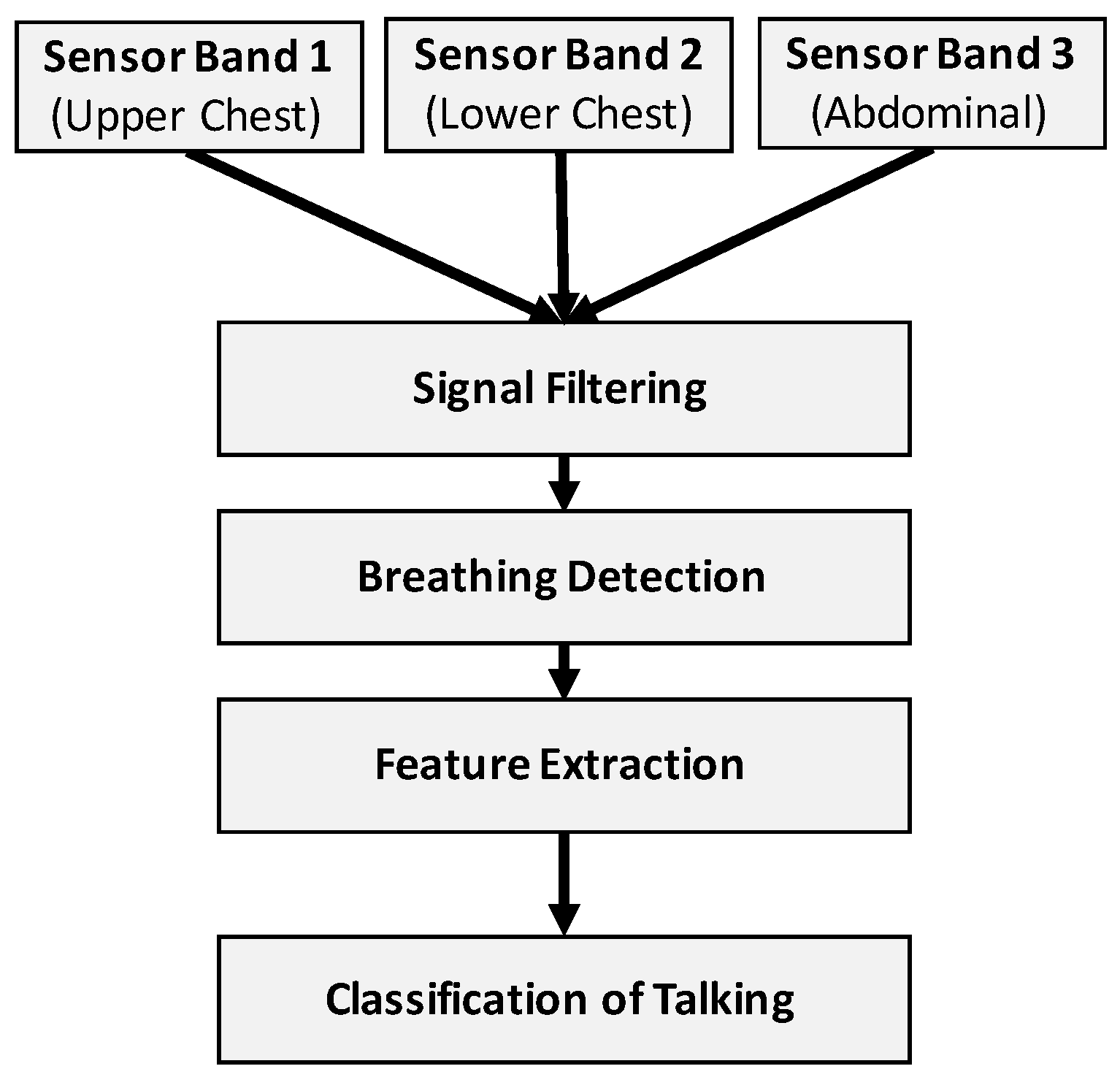
2.6. Talking Detection Algorithm
- Data input: The input data to our algorithm were the raw sensor signals (sampled with 100 Hz) of the three bands, which we converted from voltage to resistance values.
- Signal filtering: A healthy adult usually breathes between 12 and 18 times per minute at rest. For older adults, the breathing can vary between 12 and 30 times per minute [27]. We filtered the sensor signals accordingly with a bandpass filter (4th order Butterworth, lower cut-off frequency of 0.1 Hz and higher cut-off of 1.5 Hz) to account for possible drift and reduce the overall level of noise in the sensor signals.
- Breathing detection: Any inhalation of air and consequent expansion of the torso results in a peak of the stretch sensor signal. Our algorithm detects these peaks using MATLAB’s peak detection algorithm with an empirically-defined parameter of 5 for the minimum peak prominence setting. The prominence of a peak measures how much the peak stands out due to its intrinsic height and its location relative to other peaks.
- Feature extraction: The detection of a peak triggers the feature extraction process. The algorithm centres a window with an empirically-found length of 3 s on each detected peak. From this time window, a set of predefined features get extracted and used as the input to a machine learning classifier.
- Classification of talking: A machine learning classifier has been trained to detect speech breathing (i.e., talking) based on the extracted features.
2.7. Machine Learning Approach
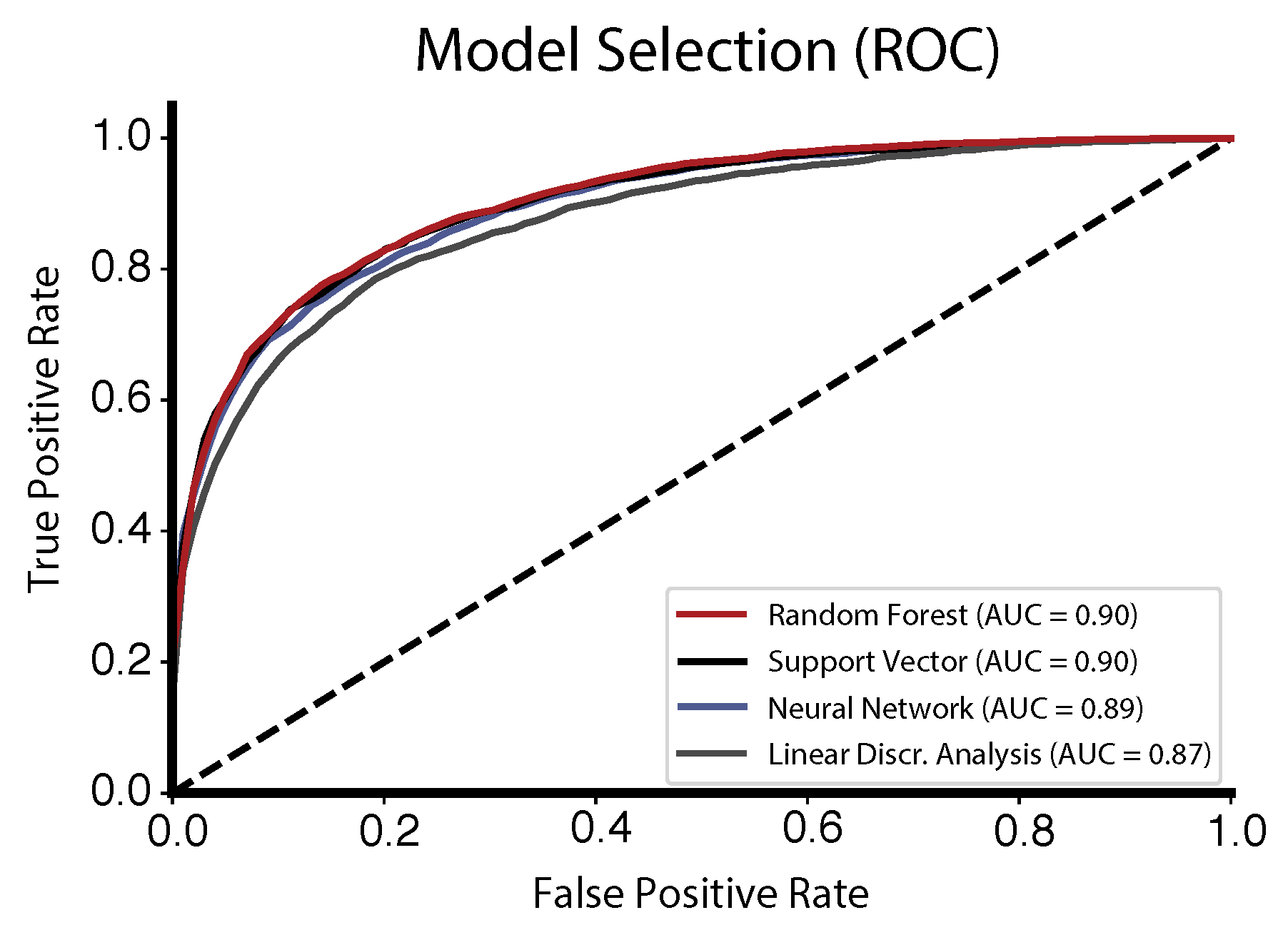
2.7.1. Model Selection
2.7.2. Feature Extraction and Selection
- Ratio beyond sigma: the ratio of values that are more than away from the mean of x (with ).
- Symmetry looking: the Boolean variable denoting if the distribution of x looks symmetric.
- Continues Wavelet Transform peaks: the number of peaks of the continuous wavelet transform using a Mexican hat wavelet [34].
- Skewness: the sample skewness of x (calculated with the adjusted Fisher–Pearson standardized moment coefficient G1).
- Energy ratio by chunks: the sum of squares of chunk i out of N chunks expressed as a ratio with the sum of squares over the whole (with ).
- Augmented Dickey–Fuller: the hypothesis test that checks whether a unit root is present in x [35].
- Count above mean: the number of values in x that are higher than the mean of x.
- Count below mean: the number of values in x that are lower than the mean of x.
- Number of crossings: the number of crossings of x on m (with ).
- Fourier coefficients: the coefficients of the one-dimensional discrete Fourier transform [36].
- Welch’s spectral density: the cross power spectral density of x [37].
- Sample entropy: the sample entropy of x.
- Autoregressive coefficients: the fit of the unconditional maximum likelihood of an autoregressive process.
2.7.3. Performance Evaluation
2.8. Software
3. Results
3.1. Model Selection
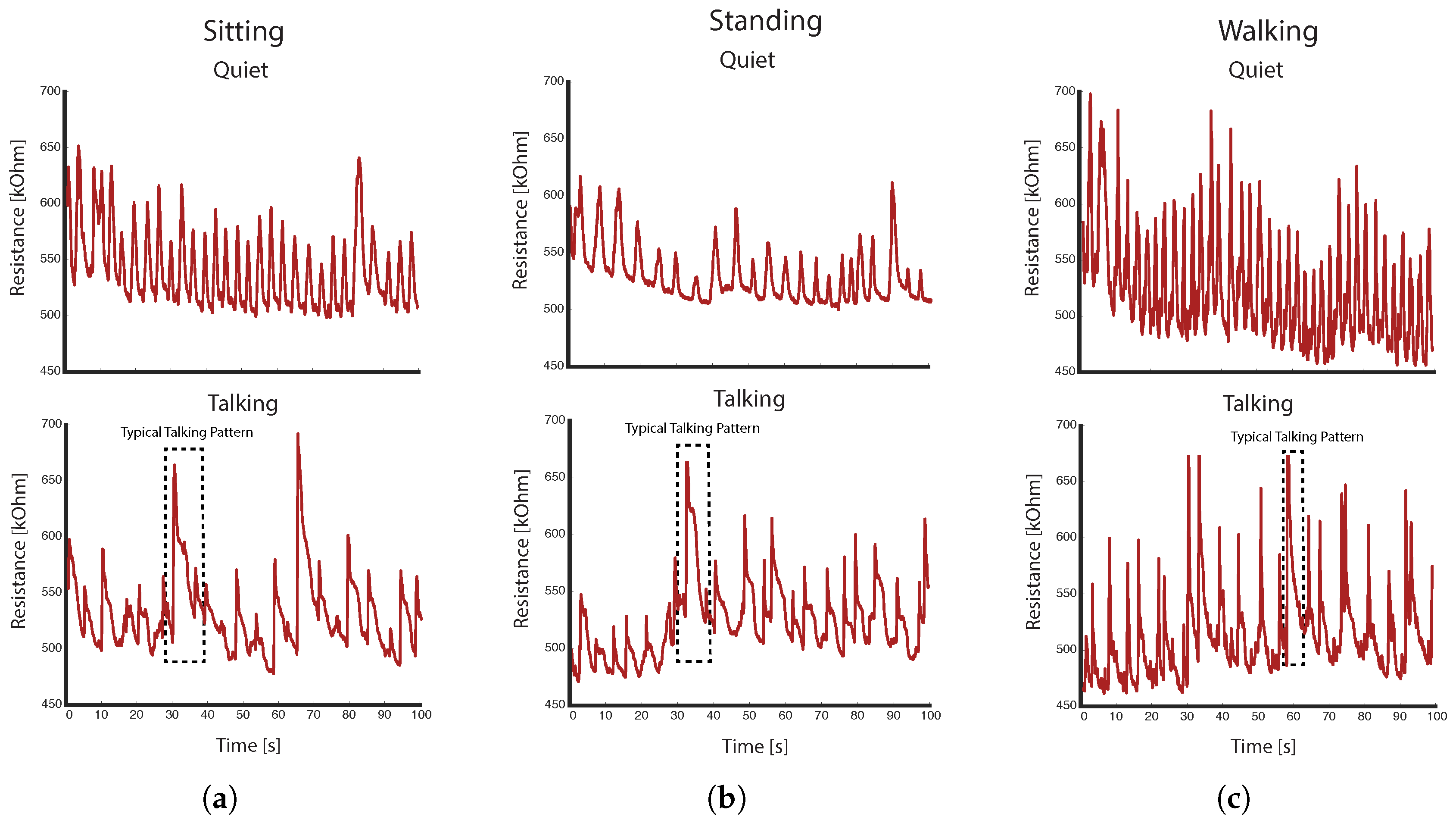
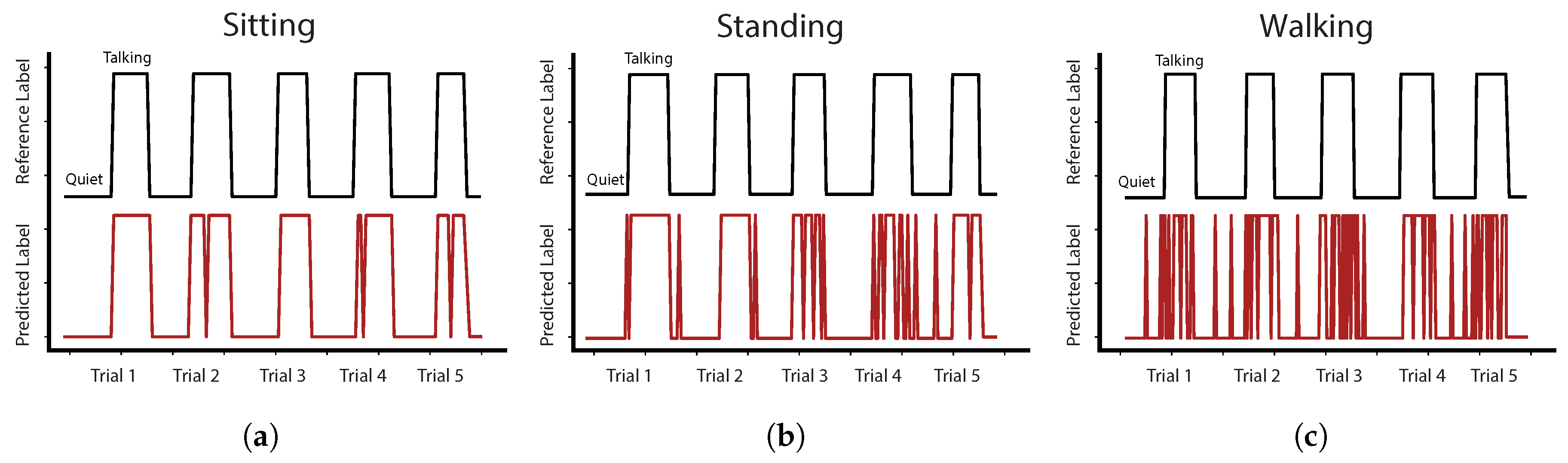
3.2. Accuracy of Talking Detection Algorithm
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Grenade, L.; Boldy, D. Social isolation and loneliness among older people: Issues and future challenges in community and residential settings. Aust. Health Rev. 2008, 32, 468–478. [Google Scholar] [CrossRef] [PubMed]
- Cattan, M.; White, M.; Bond, J.; Learmouth, A. Preventing social isolation and loneliness among older people: A systematic review of health promotion interventions. Ageing Soc. 2005, 25, 41–67. [Google Scholar] [CrossRef]
- Health Quality Ontario. Social Isolation in Community-Dwelling Seniors: An Evidence-Based Analysis; Health Quality Ontario: Toronto, ON, Canada, 2008; Volume 8, pp. 1–49.
- Coughlin, S.S. Recall bias in epidemiologic studies. J. Clin. Epidemiol. 1990, 43, 87–91. [Google Scholar] [CrossRef]
- Choudhury, T.; Pentland, A. Sensing and modeling human networks using the sociometer. In Proceedings of the Seventh IEEE International Symposium on Wearable Computers, White Plains, NY, USA, 21–23 October 2003; pp. 216–222. [Google Scholar] [Green Version]
- Wyatt, D.; Choudhury, T.; Bilmes, J.; Kitts, J.A. Inferring colocation and conversation networks from privacy-sensitive audio with implications for computational social science. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–41. [Google Scholar] [CrossRef] [Green Version]
- Cristani, M.; Pesarin, A.; Vinciarelli, A.; Crocco, M.; Murino, V. Look at who’s talking: Voice Activity Detection by Automated Gesture Analysis. In Proceedings of the European Conference on Ambient Intelligence, Amsterdam, The Netherlands, 16–18 November 2011; pp. 72–80. [Google Scholar]
- Rao, R.R. Cross-modal prediction in audio-visual communication. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing, Atlanta, GA, USA, 9 May 1996. [Google Scholar]
- Klasnja, P.; Consolvo, S.; Choudhury, T.; Beckwith, R.; Hightower, J. Exploring privacy concerns about personal sensing. Lect. Notes Comput. Sci. 2009, 5538, 176–183. [Google Scholar]
- Rahman, M.; Ahsan, A.; Plarre, K.; al’Absi, M.; Ertin, E.; Kumar, S. mConverse: Inferring Conversation Episodes from Respiratory Measurements Collected in the Field. In Proceedings of the 2nd Conference on Wireless Health, San Diego, CA, USA, 10–13 October 2011. [Google Scholar]
- Fuchs, S.; Reichel, U.D.; Rochet-Capellan, A. Changes in speech and breathing rate while speaking and biking. In Proceedings of the 18th International Congress of Phonetic Sciences (ICPhS 2015), Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Wilhelm, F.H.; Handke, E.; Roth, W. Detection of speaking with a new respiratory inductive plethysmography system. Biomed. Sci. Instrum. 2003, 39, 136–141. [Google Scholar] [PubMed]
- Haugh, M. Conversational Interaction. In The Cambridge Handbook of Pragmatics; Cambridge University Press: Cambridge, UK, 2012; pp. 251–274. [Google Scholar]
- Ramos-Garcia, R.I.; Tiffany, S.; Sazonov, E. Using respiratory signals for the recognition of human activities. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 173–176. [Google Scholar]
- Tognetti, A.; Bartalesi, R.; Lorussi, F.; De Rossi, D. Body segment position reconstruction and posture classification by smart textiles. Trans. Inst. Meas. Control 2007, 29, 215–253. [Google Scholar] [CrossRef]
- Mattmann, C.; Amft, O.; Harms, H.; Troester, G.; Clemens, F. Recognizing upper body postures using textile strain sensors. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers (ISWC), Boston, MA, USA, 11–13 October 2007; pp. 29–36. [Google Scholar]
- Papi, E.; Spulber, I.; Kotti, M.; Georgiou, P.; McGregor, A.H. Smart sensing system for combined activity classification and estimation of knee range of motion. IEEE Sens. J. 2015, 15, 5535–5544. [Google Scholar] [CrossRef]
- Ferrone, A.; Maita, F.; Maiolo, L.; Arquilla, M.; Castiello, A.; Pecora, A.; Jiang, X.; Menon, C.; Ferrone, A.; Colace, L.; et al. Wearable band for hand gesture recognition based on strain sensors. In Proceedings of the IEEE RAA/EMBS International Conference on Biomedical Robotics and Biomechatronics, Singapore, 26–29 June 2016; pp. 4–7. [Google Scholar]
- Adafruit. Available online: https://www.adafruit.com/ (accessed on 10 June 2018).
- Images SI. Available online: https://www.imagesco.com/ (accessed on 10 June 2018).
- Ejupi, A.; Ferrone, A.; Menon, C. Quantification of textile-based stretch sensors using machine learning: An exploratory study. In Proceedings of the IEEE International Conference on Biomedical Robotics and Biomechatronics (BioRob), Twente, The Netherlands, 26–29 August 2018. [Google Scholar]
- Gholami, M.; Ejupi, A.; Rezaei, A.; Ferrone, A.; Menon, C. Estimation of Knee Joint Angle using a Fabric-based Strain Sensor and Machine Learning: A Preliminary Investigation. In Proceedings of the IEEE International Conference on Biomedical Robotics and Biomechatronics (BioRob), Twente, The Netherlands, 26–29 August 2018. [Google Scholar]
- Rezaei, A.; Ejupi, A.; Gholami, M.; Ferrone, A.; Menon, C. Preliminary Investigation of Textile-Based Strain Sensors for the Detection of Human Gait Phases Using Machine Learning. In Proceedings of the IEEE International Conference on Biomedical Robotics and Biomechatronics (BioRob), Twente, The Netherlands, 26–29 August 2018. [Google Scholar]
- Gilbert, R.; Auschincloss, J.H.; Peppi, D. Relationship of rib cage and abdomen motion to diaphragm function during quiet breathing. Chest 1981, 80, 607–612. [Google Scholar] [CrossRef] [PubMed]
- Kaneko, H.; Horie, J. Breathing movements of the chest and abdominal wall in healthy subjects. Respir. Care 2012, 57, 1442–1451. [Google Scholar] [CrossRef] [PubMed]
- Grimby, G.; Bunn, J.; Mead, J. Relative contribution of rib cage and abdomen to ventilation during exercise. J. Appl. Physiol. 1968, 24, 159–166. [Google Scholar] [CrossRef] [PubMed]
- McFadden, J.P.; Price, R.; Eastwood, H.D.; Briggs, R. Raised respiratory rate in elderly patients: A valuable physical sign. Br. Med. J. (Clin. Res. Ed.) 1982, 284, 626–627. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 1, 155–161. [Google Scholar]
- Mika, S.; Ratsch, G.; Weston, J.; Schölkopf, B.; Muller, K.R. Fisher discriminant analysis with kernels. In Proceedings of the 1999 IEEE Signal Processing Society Workshop (Cat. No. 98TH8468), Madison, WI, USA, 25 August 1999; pp. 41–48. [Google Scholar] [Green Version]
- tsfresh. Available online: http://tsfresh.readthedocs.io/ (accessed on 10 June 2018).
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C. Classification and Regression Trees; Routledge: Abingdon, UK, 1984; Volume 1. [Google Scholar]
- Grossmann, A.; Morlet, J. Decomposition of hardy functions into square integrable wavelets of constant shape. J. Math. Anal. 1984, 15, 723–736. [Google Scholar] [CrossRef]
- Cheung, Y.W.; La, K.S. Lag order and critical values of the augmented dickey-fuller test. J. Bus. Econ. Stat. 1995, 13, 277–280. [Google Scholar]
- Cooley, J.W.; Lewis, P.A.W.; Welch, P.D. The fast fourier transform and its applications. IEEE Trans. Educ. 1969, 12, 27–34. [Google Scholar] [CrossRef]
- Welch, P.D. The use of fast fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Ejupi, A.; Lord, S.R.; Delbaere, K. New methods for fall risk prediction. Curr. Opin. Clin. Nutr. Metab. Care 2014, 17, 407–411. [Google Scholar] [CrossRef] [PubMed]
- Mukhopadhyay, S.C. Wearable sensors for human activity monitoring: A review. IEEE Sens. J. 2014, 15, 1321–1330. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, Y. RGB-D camera-based daily living activity recognition. J. Comput. Vis. Image Process. 2012, 2, 12. [Google Scholar]
- Bari, R.; Adams, R.J.; Rahman, M.; Parsons, M.B.; Buder, E.H.; Kumar, S. rConverse: Moment by moment conversation detection using a mobile respiration sensor. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 2:1–2:27. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Participants (n = 15) | |
|---|---|
| Age (years) | 23 (3.8) |
| Gender (F/M) | 6/9 |
| Height (cm) | 169.8 (8.9) |
| Weight (kg) | 68.5 (12.1) |
| BMI (kg/m) | 23.6 (3.1) |
| Average ACC | Average TPR | Average FPR | |
|---|---|---|---|
| Sitting | 88.0 (5.4) | 88.0 (6.1) | 12.6 (6.9) |
| Standing | 86.3 (7.3) | 84.2 (8.6) | 12.5 (7.6) |
| Walking | 80.6 (7.7) | 71.8 (12.1) | 13.3 (6.5) |
| Average | 85.0 (6.8) | 81.3 (8.9) | 12.8 (7.0) |
| P01 | P02 | P03 | P04 | P05 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | TPR | FPR | ACC | TPR | FPR | ACC | TPR | FPR | ACC | TPR | FPR | ACC | TPR | FPR | |
| Sitting | 94.3 | 92.3 | 3.9 | 94.8 | 93.5 | 4.2 | 97.5 | 94.9 | 0.9 | 84.9 | 84.9 | 15.0 | 82.9 | 81.2 | 15.6 |
| Standing | 93.9 | 92.2 | 4.4 | 90.5 | 90.0 | 9.1 | 94.2 | 91.5 | 3.7 | 76.1 | 73.1 | 21.3 | 86.0 | 79.1 | 9.9 |
| Walking | 79.6 | 76.4 | 17.6 | 85.2 | 81.0 | 11.6 | 90.2 | 82.4 | 4.4 | 68.8 | 55.3 | 20.7 | 87.2 | 83.6 | 9.8 |
| P06 | P07 | P08 | P09 | P10 | |||||||||||
| Sitting | 81.6 | 87.7 | 24.2 | 88.6 | 95.1 | 20.2 | 93.7 | 93.1 | 5.9 | 89.3 | 93.3 | 14.6 | 92.0 | 90.9 | 7.3 |
| Standing | 82.5 | 79.2 | 14.7 | 94.0 | 94.9 | 7.1 | 95.1 | 92.5 | 2.9 | 93.6 | 96.1 | 8.9 | 87.0 | 81.4 | 9.1 |
| Walking | 71.1 | 70.5 | 28.5 | 87.8 | 84.7 | 9.3 | 95.6 | 90.8 | 1.4 | 79.7 | 75.4 | 17.0 | 81.1 | 68.2 | 11.9 |
| P11 | P12 | P13 | P14 | P15 | |||||||||||
| Sitting | 82.7 | 82.0 | 16.7 | 89.8 | 87.0 | 7.9 | 83.5 | 89.3 | 22.7 | 84.3 | 79.1 | 12.6 | 79.3 | 75.0 | 16.7 |
| Standing | 73.9 | 73.8 | 26.1 | 83.3 | 70.8 | 9.0 | 78.7 | 76.2 | 18.8 | 75.8 | 79.5 | 28.2 | 89.8 | 93.2 | 13.9 |
| Walking | 68.3 | 42.5 | 14.8 | 79.4 | 69.4 | 13.5 | 73.0 | 61.3 | 18.6 | 81.7 | 68.2 | 9.9 | 80.0 | 66.9 | 9.9 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ejupi, A.; Menon, C. Detection of Talking in Respiratory Signals: A Feasibility Study Using Machine Learning and Wearable Textile-Based Sensors. Sensors 2018, 18, 2474. https://doi.org/10.3390/s18082474
Ejupi A, Menon C. Detection of Talking in Respiratory Signals: A Feasibility Study Using Machine Learning and Wearable Textile-Based Sensors. Sensors. 2018; 18(8):2474. https://doi.org/10.3390/s18082474
Chicago/Turabian StyleEjupi, Andreas, and Carlo Menon. 2018. "Detection of Talking in Respiratory Signals: A Feasibility Study Using Machine Learning and Wearable Textile-Based Sensors" Sensors 18, no. 8: 2474. https://doi.org/10.3390/s18082474
APA StyleEjupi, A., & Menon, C. (2018). Detection of Talking in Respiratory Signals: A Feasibility Study Using Machine Learning and Wearable Textile-Based Sensors. Sensors, 18(8), 2474. https://doi.org/10.3390/s18082474