3.1. FCN Working Mechanism
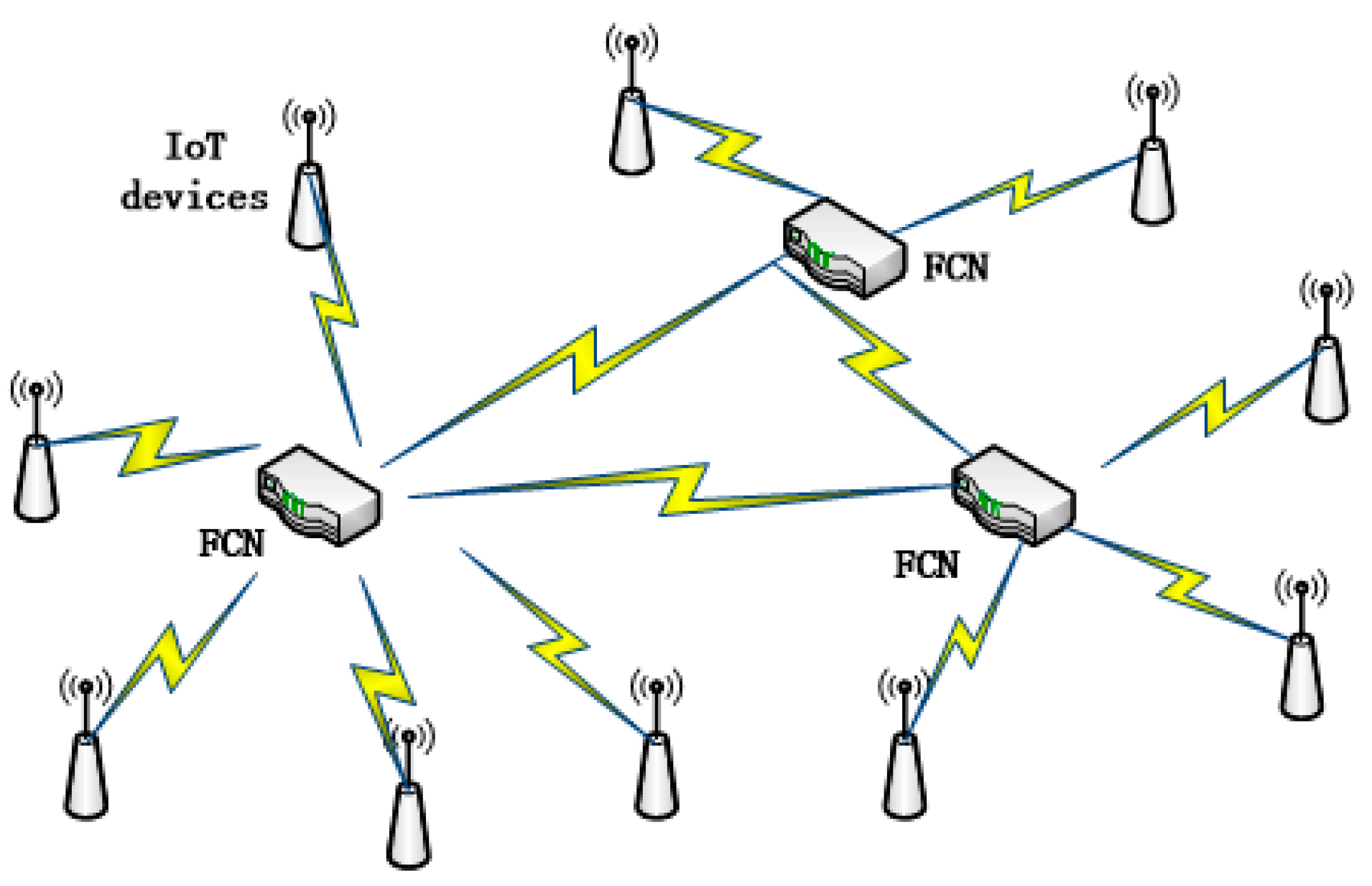
Fog computing is a virtual service for IoT applications. FCNs can be routers, switchers and other network devices that support fog computing service. FCNs serve other IoT devices nearby by helping to process the tasks that arrive from them as
Figure 2 shows.
Since the tasks’ sources are various and arrival intervals are random, the arrival process can be modeled as a Possion process. We assume the arrival rate as λ. For task processing, we do not assume the service time as an exponential distribution as [
3,
4,
5], as that is not reasonable. We discuss the general distribution below. The system is shown in
Figure 3. The task is stored in one deque, which is a variety of queues that permit in-out operations from both ends [
14].
Thus the FCN is a M/G/1 queuing system with the following properties: the arrival rate is λ, the process time is
,
denotes the average service time per task, and
denotes the second moment of
. According to [
15], the M/G/1 queuing system holds the following two equations:
In the above equations
denotes load intensity,
denotes the waiting time in the queue and
denotes response time which equals a task’s entire time in the FCN. As the FCN abides by the FCFS mechanism, arriving tasks first wait in the ready queue then receive service until the processor is idle, so the
consists of
and
. Here we propose a new important measure factor
which denotes the conditional expectation of
while
is set to
. Since how long one task waits is independent of its service time, we obtain the following equation:
Equations (3) and (4) can be simplified as:
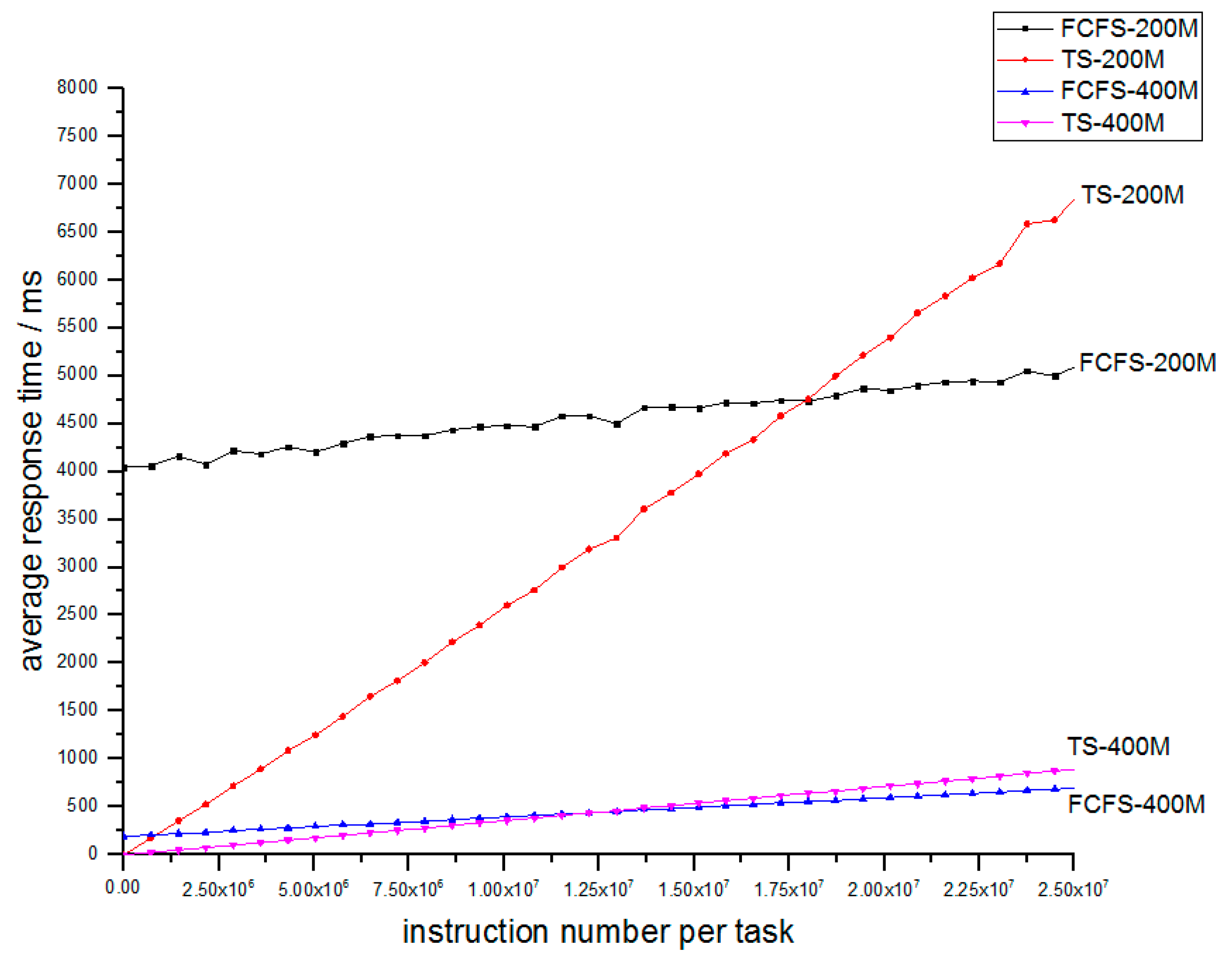
According to Equation (5), we find that no matter how small a task is, the response time can be no shorter than
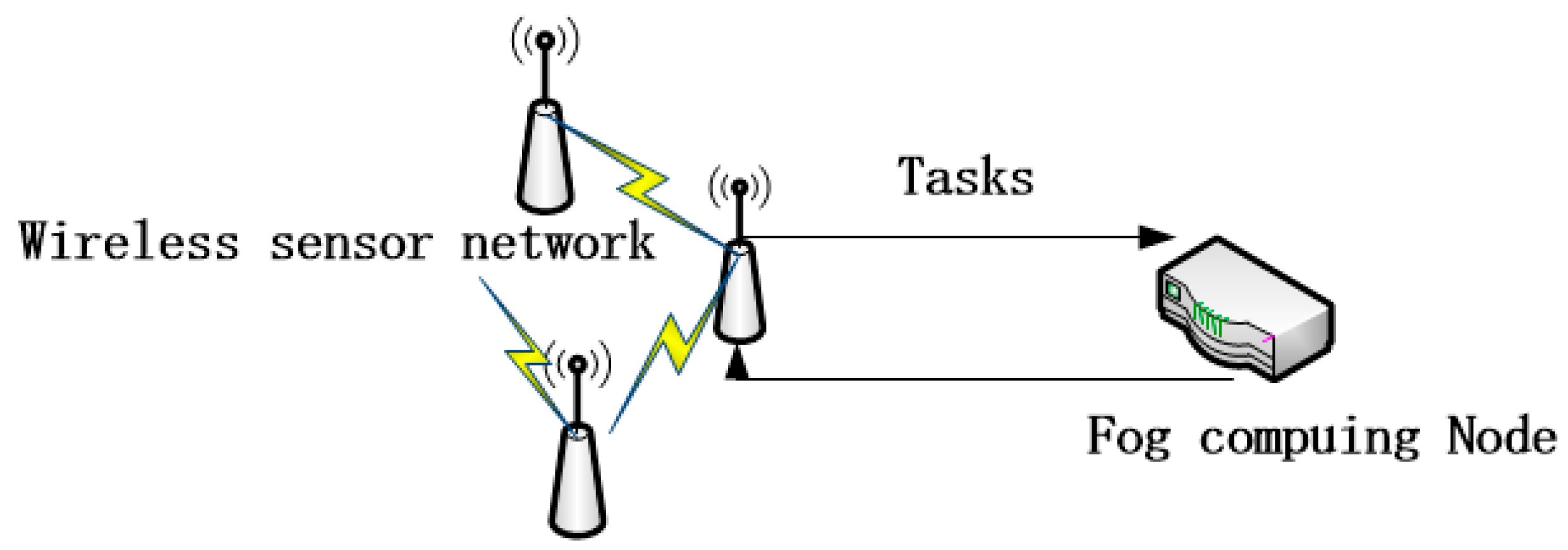
, which is the lower bound limit of time; however, some sense-and-actuate-loop IoT applications like a wireless sensor and actuator network, which generate a large number of light tasks and demand quick response time, will obtain terrible QoS due to the unavoidable lower-bound time limit, so the FCFS system is not appropriate for the FCN. We propose a classical mechanism that can cut off the lower-bound time limit–time-sharing (TS) mechanism. A TS mechanism is efficient for concurrency, which has been applied to computer systems successfully. As
Figure 4 shows, the wireless sensor shunts its tasks to the FCN for service, and the time-sharing FCN can respond quickly and provide high QoS.
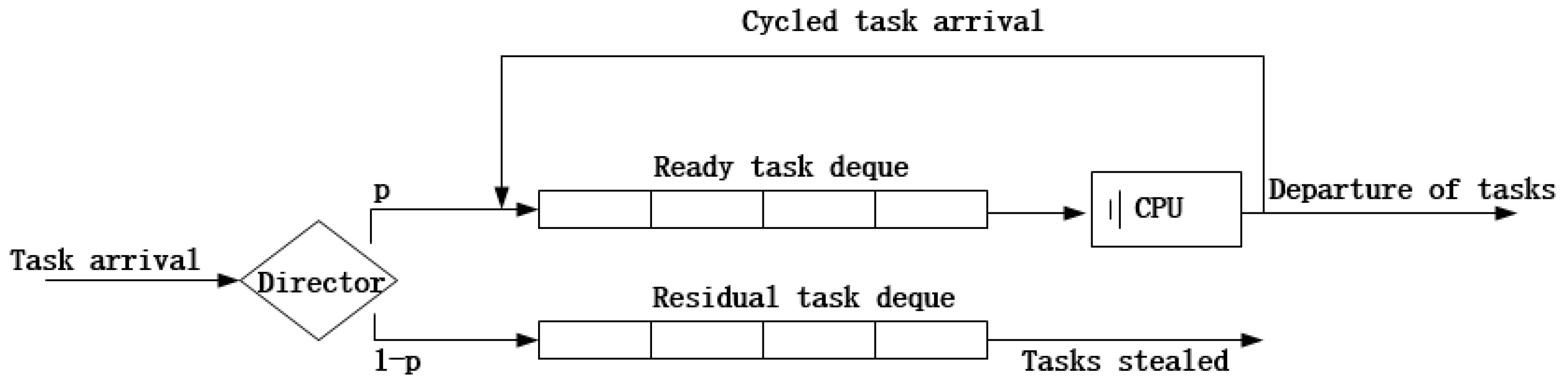
Next, we elaborate the TS system. As
Figure 5 shows, once a task arrives, it is pushed into the task deque from the back. The CPU obtains a task from the front of the task deque and gives it a little quantum of service. When the task is completed, it leaves the FCN; otherwise, it is pushed into the task deque from the back, which is called ‘cycled arrival’. Through time-sharing, each task receives service in turn. The service quantum is so little that every task seems to be served at the same time. The scheduling mechanism is also called Round-Robin (RR) time-sharing. According to [
16], we obtain a key equation:
so if FCN adopts the RR algorithm, the expectation of
is proportional to
. Some IoT applications, like wireless sensor and actuator networks which are comprised of small tasks, can obtain a quick response in contrast to waiting for a fixed time in the FCFS system. in
Section 4, we compare the two scheduling algorithms through simulations.
We compare Equations (5) and (6), and we find that although the TS system removes the lower- bound time limit, its coefficient for service time is larger than that of FCFS system: . So the TS system decreases the response time for light tasks at the expense of increasing the response time for heavy tasks. But to be reasonable, the light tasks always demand more than heavy tasks. So we believe that the expense is reasonable.
We also found that the TS system has a potential advantage, as Equation (7) shows:
The ratio between the expected and is constant, which just relates to ; however is decided by λ and , so the TS scheduler is completely fair to all tasks, whether small or large. This feature is necessary and helpful. As if the ratio is smaller for small tasks, users and developers tend to split a large task into smaller tasks. Or if the ratio is larger for small tasks, then users and developers tend to merge small tasks into larger ones for a quicker response. Such unfairness will cause malicious competition and add the burden of users and developers. So we insist that fairness is necessary in fog computing, which means that is the same for any task processed in any FCN.
In a FCN, one task may gain different
in different FCNs. The service time of one task depends on its programming architecture and the processors of the serving FCN. For convenience we propose on absolute value π that denotes the number of instructions of one task to represent the working load of tasks and an absolute value
that denotes the number of instructions processed by the FCN per unit time. We obtained modified equations as follows:
Here, C denotes the FCN’s performance which is called the ‘concurrency coefficient’. As we can see, the smaller C means quicker response and better performance of FCNs. So we aim to reduce C. And C is dependent on the processing rate of the FCN, the arrival rate, and the average service time of tasks. The next section will elaborate a new scheduler that aims to minimize concurrency coefficients of FCNs based on game theory.
3.2. Game-Theory Based Work-Stealing Scheduler
Work-stealing as a scheduling algorithm is imposed on a multi-processor system to balance the load between processors. Compared to a multi-processor system, a fog computing network features a much more complex topology, more significant communication delay and dispersive memory. Stealing between FCNs is much more expensive than between processors. A normal work-stealing scheduler adopts a strategy where an idle processor steals from a randomly chosen processor. If the victim processor has more than one task, it transfers the extra task to the stealer; otherwise, it responds with a refusal command and then the stealer attempts another randomly chosen processor. In conclusion, if the scheduler is applied to a fog computing network, it suffers from the following defects:
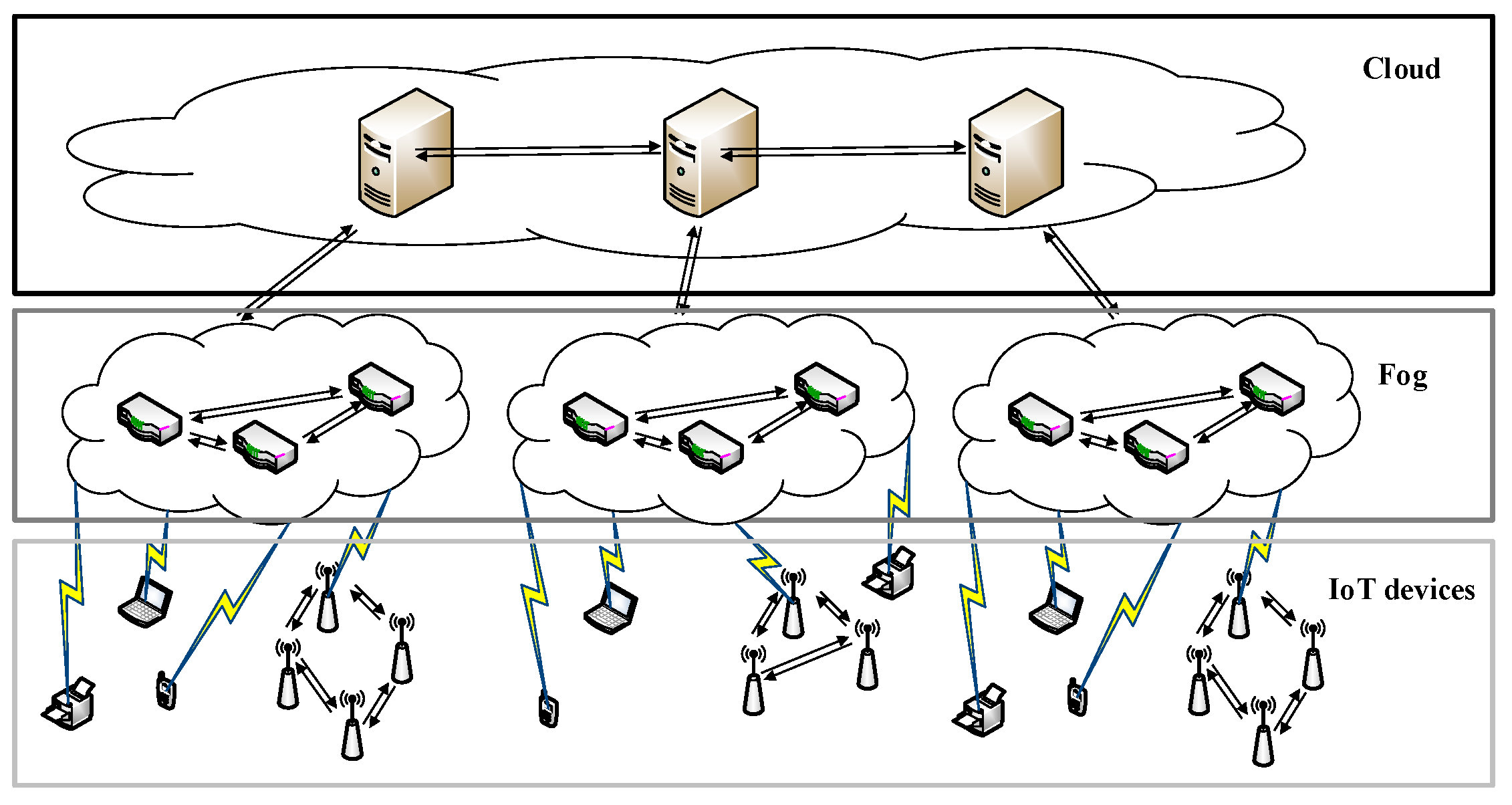
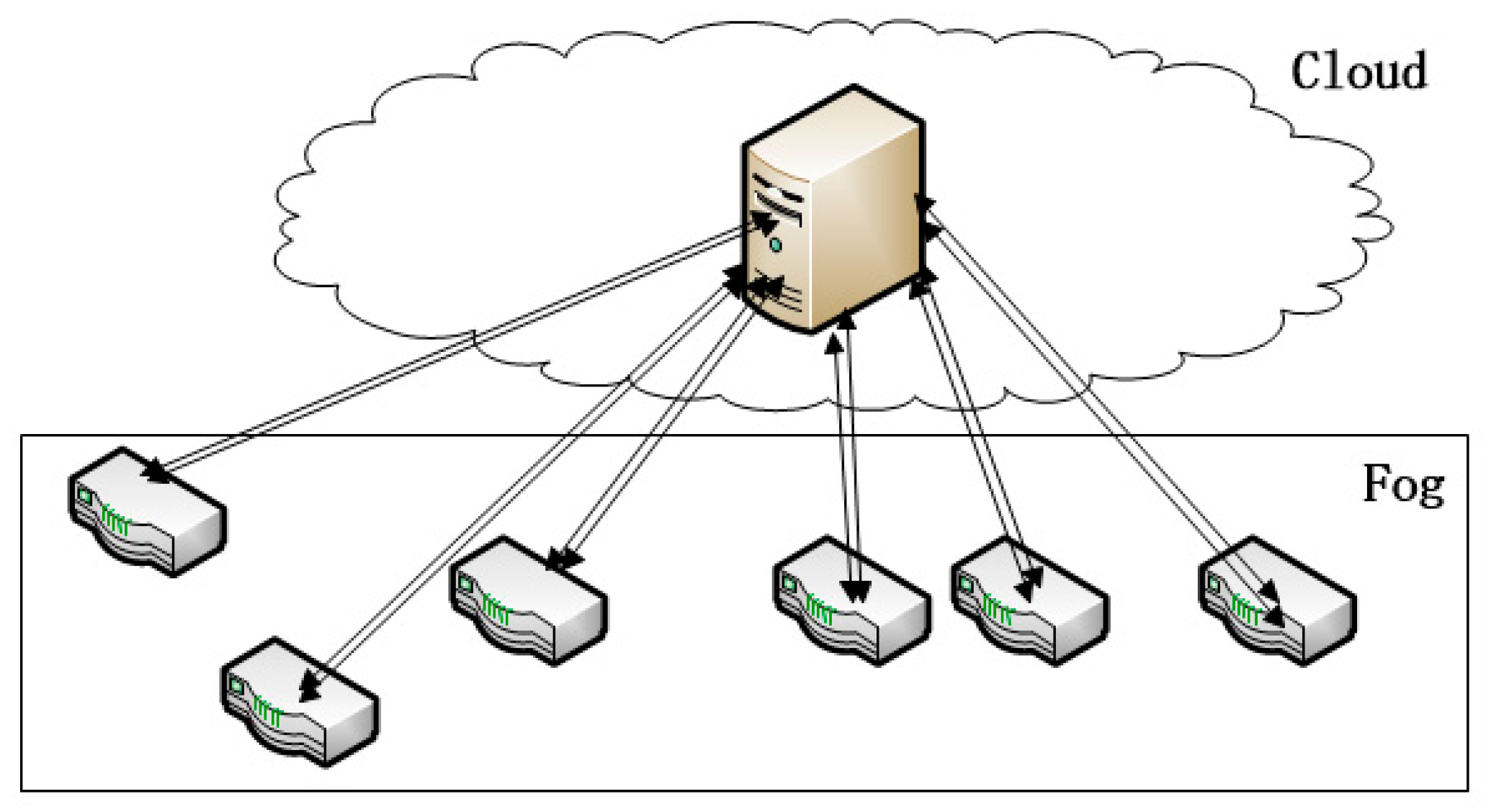
We have to adjust the normal work-stealing scheduler for fog computing. Fog computing is the complement to cloud computing (as
Figure 1 shows), as every FCN is connected to the cloud. So we can utilize the cloud to help with work-stealing. A cloud manages a cluster of FCNs and orchestrates their cooperation. The parameters of the cluster of FCNs are listed in
Table 1.
In the above list, some parameters are almost fixed, like , which denotes the processing capacity of the FCN. The other parameters should be bookkept by the FCN itself and reported to the cloud periodically.
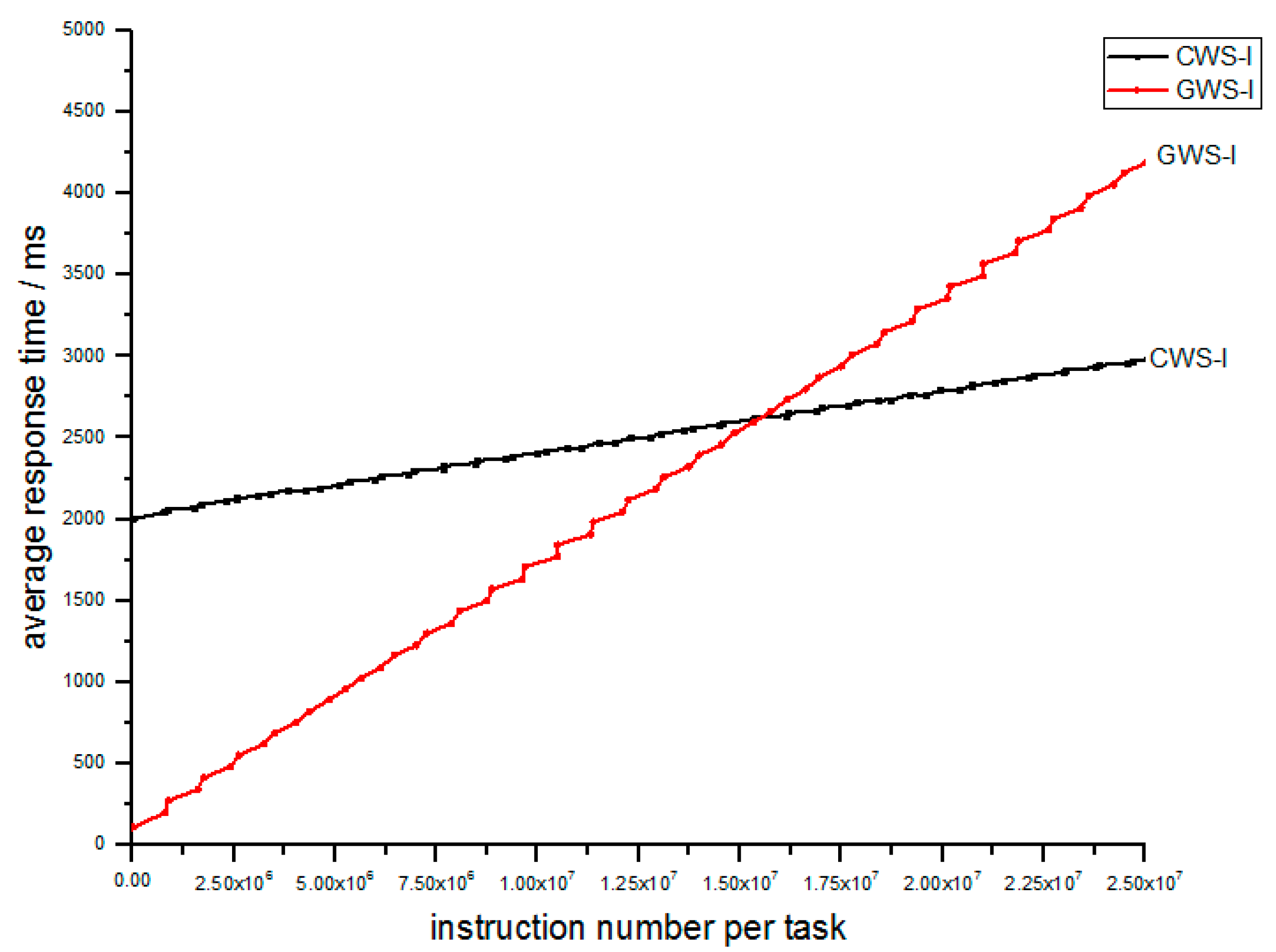
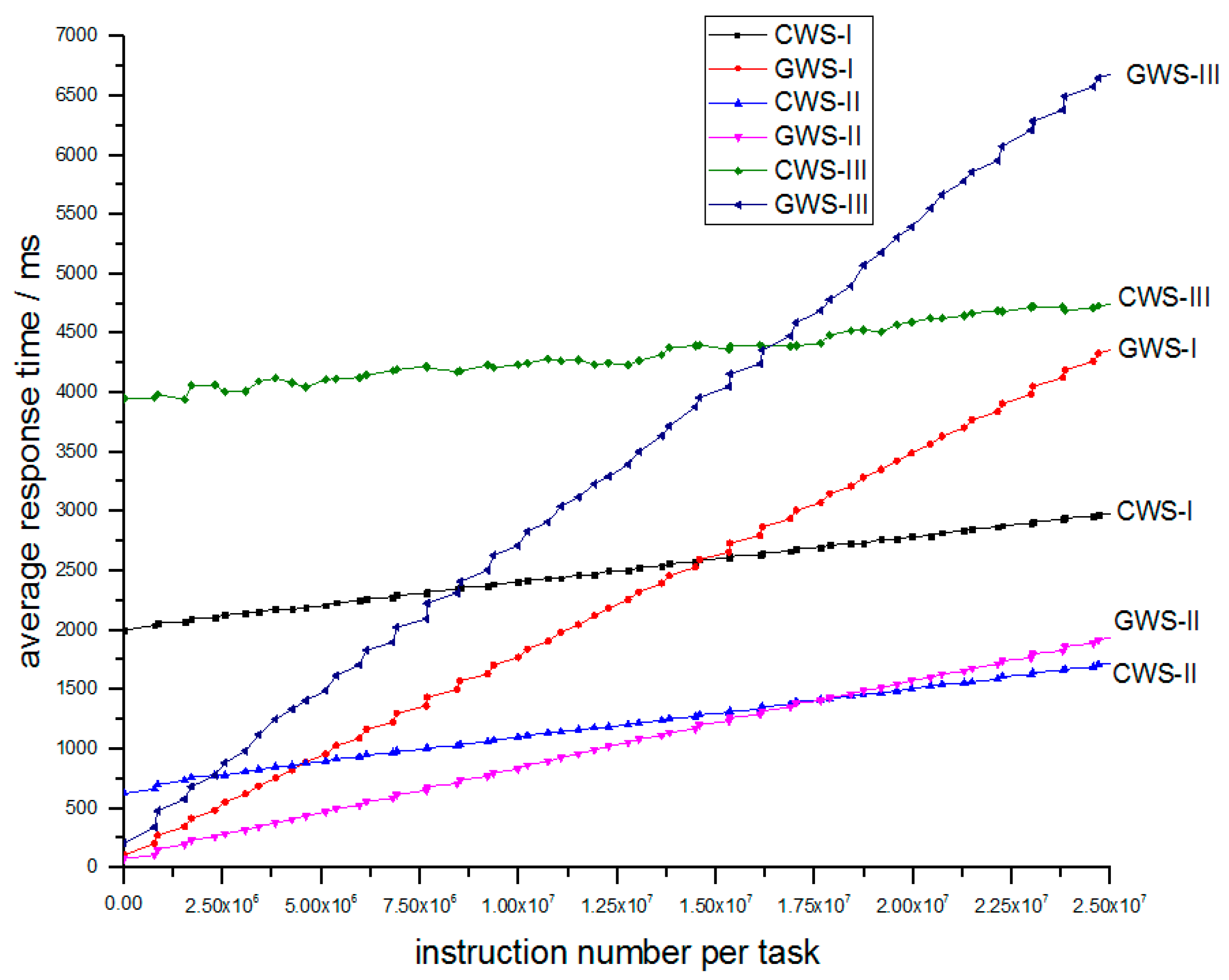
In the fog computing network above, every FCN has its own concurrency coefficient based on Equation (12). This factor is an important measure of performance which denotes the average response time of the specified task. For
the concurrency coefficient is in Equation (13):
Obviously, a different FCN may possess a different processing rate , different task arrival rate and different average instruction number per task , which may lead to different concurrency coefficient based on the Equation (13). The goal of this paper is to fairly achieve a larger for every FCN.
From the Equation (13), for an FCN like , the concurrency coefficient only depends on , and . Among these factors, , which denotes the process rate of , is almost fixed; , which denotes the task arrival rate of , just relies upon the IoT devices in this area; and denotes the average number of instructions per task of . So the only factor that can be modified is the task arrival rate . We can modify so that approximates the average value of the concurrency coefficient . The algorithm is elaborated as follows.
This adjusted work-stealing algorithm aims to adjust the task input intensity. We classify FCNs into two varieties: over-loaded FCNs with a large concurrency coefficient and under-loaded FCNs with a small concurrency coefficient. The work-stealing algorithm reduces the task arrival rate of over-loaded FCNs and raises the task arrival of under-loaded FCNs by shunting and stealing. The two varieties of FCNs are modeled in
Figure 6 and
Figure 7.
As
Figure 6 shows, an FCN contains two task deques, the ready task deque, which works with the CPU, and the residual task deque, which stores raw tasks that are ready to be stolen. Another big difference is the director, which decides whether a task goes to the ready or residual task deque on the probability of p. So what is
p? This will be discussed in
Section 3.3. For over-loaded FCNs like
, all of the arriving tasks go to the ready task deque at the probability of
, so the task arrival rate becomes
. The updated concurrency coefficient is expressed as follows:
When is less than 1, the director of this FCN will shunt arriving tasks to the ready task deque at the probability of and to the residual task deque at the probability of . Tasks in the ready task deque will receive service one by one, and tasks in the residual task deque wait for a stealing request. Once a task enters the ready deque, it cannot be shared; tasks in in the residual dequee are raw and suitable for sharing. When a stealing request comes, and the residual task deque is not empty, the FCN delivers a task from the back of the residual task deque to the stealing FCN.
When
is greater than 1, as shown in
Figure 7, the FCN is under-loaded. There is no need to maintain the residual deque as the director. The FCN has to steal another FCN so that the overall task arrival rate can increase. We set the successful stealing interval as an exponential distribution with the average value of
. A successful stealing interval means the interval between two stealing from FCS which contains extra tasks. If the FCN fails to steal, it continues without waiting.
An exceptional situation occurs when is equal to 1, then FCN is just the same as an isolated TS system that does not steal or shunt any tasks to the residual task deque. This special case rarely happens, so we don’t discuss this in the following sections.
As the cloud periodically updates the FCN cluster, the role of each FCN may change. Some over-loaded FCNs may become under-loaded and vice versa, so the algorithm is dynamic to the real IoT environment and evolves periodically. In next section, we will discuss how to calculate the probability set . This is the key factor for our algorithm.
3.3. Nash Bargaining Solution for the Probability Set
Section 3.2 proposes an efficient scheduling algorithm of work-stealing for a TS system, but how to set the important factor
has not be solved. The main goal of the paper is to minimize the concurrency coefficient
of each FCN. The problem can be modeled as a NBS rather than a Nash equilibrium for cooperative FCNs. This is a cooperative game, which is different from its non-cooperative counterpart [
17]. Through cooperation of players (FCNs), a better profit can be achieved. The game is depicted in
Figure 8.
As
Figure 8 shows, FCNs gain common knowledge through the cloud. FCNs can communicate with each other to gain common knowledge, but this communication process is of time complexity
. So why not draw support from the cloud? As all FCNs are linked to the cloud, so FCNs can gain all information needed for the game by means of the central cloud with the time complexity
. Although the cloud may be far from edge, I believe a decrease in time complexity by one order of magnitude can offset it even more. Let’s analyze the game to find the optimal balancing points. The mathematical problem is as follows:
Inequation (16) guarantees the probability
is not negative and Inequation (17) is the stability condition of the M/G/1 queuing system. We replace
according to Equation (14), so objective (14) can be simplified as:
By maximizing
,
minimizes
at the same time. Every FCN cooperates by means of the cloud center to gain better performance. This problem can be viewed as a Nash bargaining game for cooperative players. According to [
18], the NBS can realize Pareto optimal operation point; that is, NBS guarantees optimality and fairness for every FCN. According to [
17], the above objective (19) is equivalent to the following objective:
where
indicates the initial agreement point which denotes that
must not be less than
. We set
based on Inequation (17) and we set
In conclusion, the above problem can be elaborated as follows:
Then we use the Lagrange multiplier method to find the set
for the maximum objective. But first we ignore the condition
and apply it later. The Lagrange function is as follows, and
and
are multipliers for Equation (18) and Inequation (17).
Then we apply the Karush Kuhn Tucker (KKT) constraints as follows:
According to (17) and (19), we know
, so we deduce
, and Equations (24)–(26) can be concluded as:
The result set
can be resolved from Equations (25) and (26).
Until now the result set
} has not been solved because the constraint (16)
has not been applied. If
, Equation (16) infers that
is too little. But based on (21), if
is too small, then weak processing capacity is too weak and task arrival too frequent—both of which lead to FCN failure. So we just abandon FCNs with negative
According to [
7], we can remove the
for which
by using the following algorithm in the time complexity of
.
In the above algorithm, the sorting accounts for the time complexity of . The Pareto optimal point is calculated out as }. In the fog computing network, we adopt the result set } to implement the work-stealing scheduler, and the Pareto optimal maximum for the concurrency coefficient will be achieved. ‘Pareto optimality’ means there is no way to improve performance of one FCN without decreasing the performance of others.
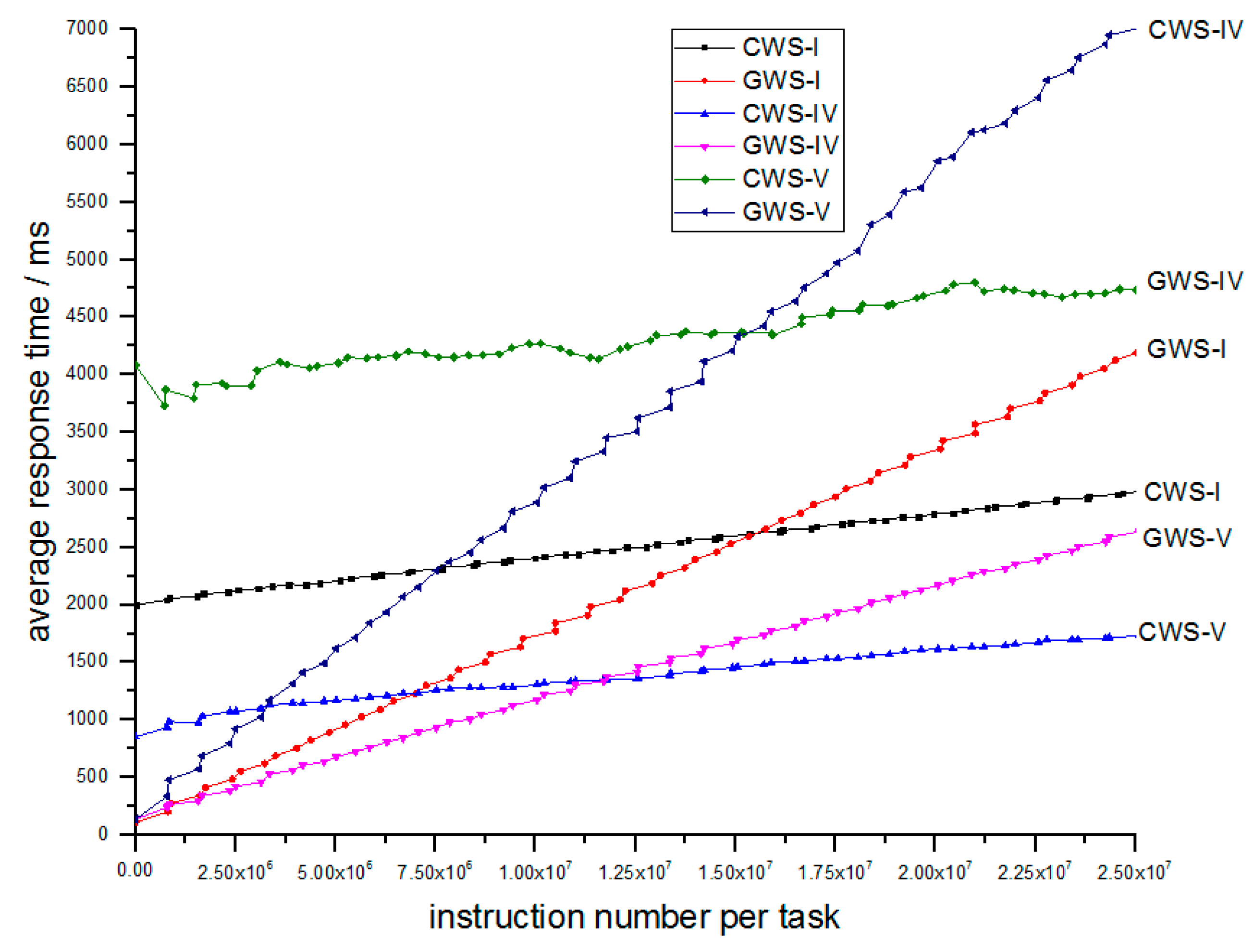
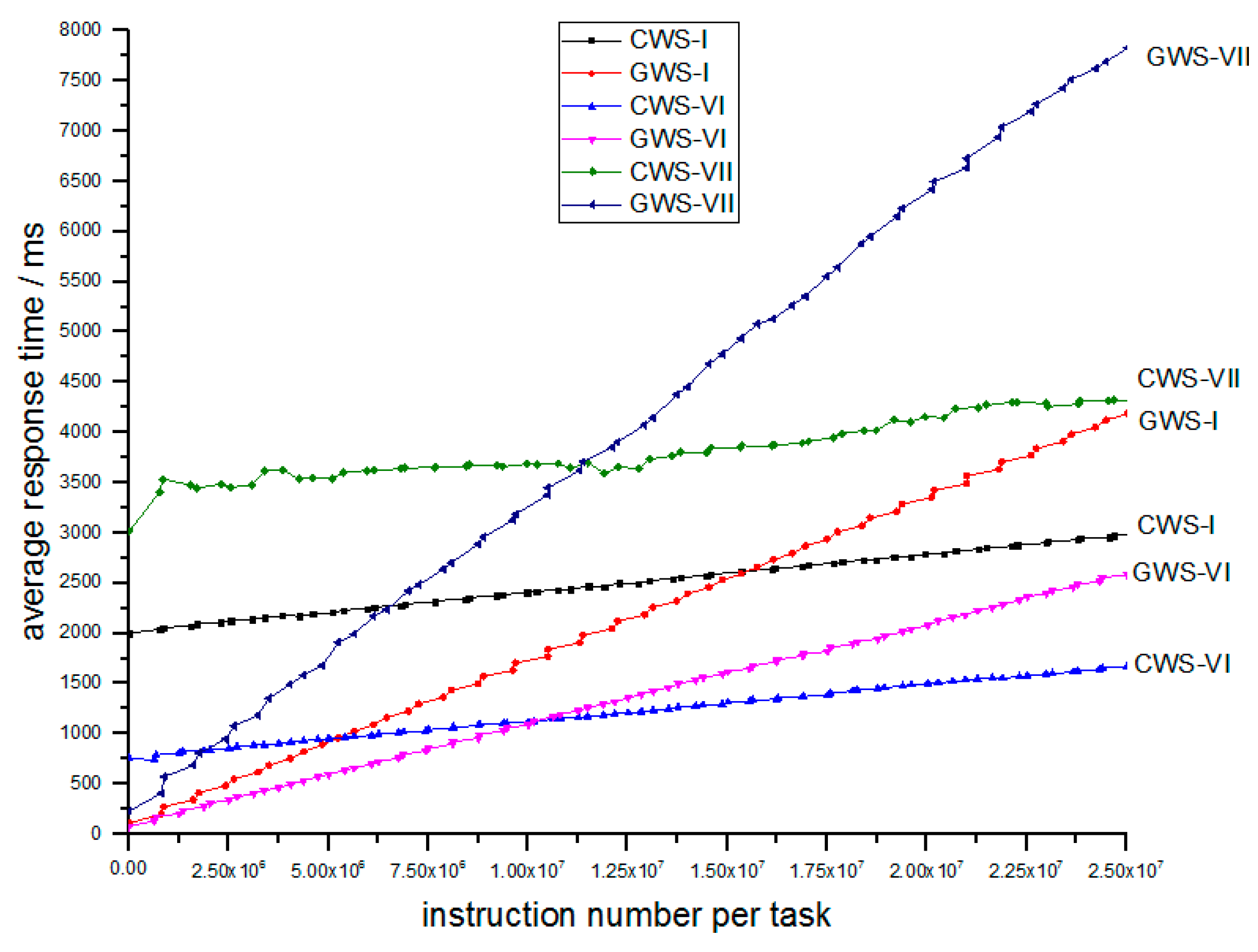
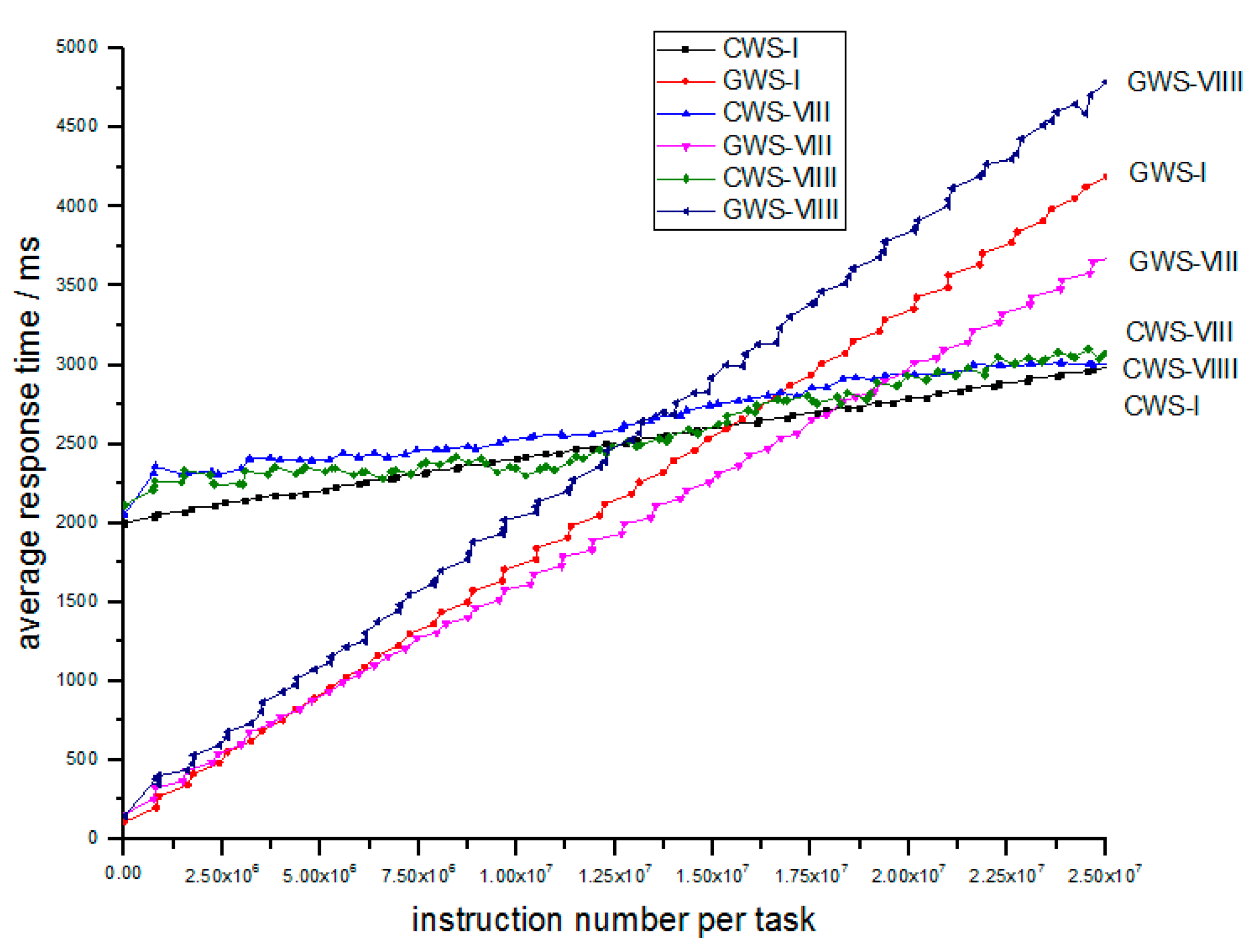
The next section elaborates the simulations that prove the efficiency of the Algorithm 1 below.
| Algorithm 1: post-processing algorithm for eliminating the negative |
Input: task arrival rate , the overall task arrival rate λ, the parameter and the FCN number .
Output: probability set .
Sort all FCNs in decreasing order of , While , end while for end for.
|

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}