1. Introduction
Handshapes are the basis of so-called finger alphabets that are used by deaf people to express words for which there are no separate signs in sign languages. The same handshapes, shown for various positions and orientations of the hand, are also important components of dynamic signs occurring in sign languages. Moreover, in the case of the so-called minimal pairs, the shape of the hand is the only distinguishing feature. Therefore, building a complete system for automatic recognition of the manual part of sign language is not possible without solving the problem of recognizing static handshapes.
The problem is challenging. Handshapes occurring in finger alphabets are complicated. A projection, that takes place during the image formation in a camera, results in significant loss of information. Individual fingers overlap each other or remain completely covered. In addition, some handshapes are very similar. Moreover, a movement trajectory is not available and therefore a detailed analysis of the shape is required. In the case of typical cameras, including stereo cameras, a big challenge is a dependence on variable backgrounds and lighting conditions. Individual differences in showing particular shapes by different users need to be considered as well. Therefore, systems developed in a controlled and sterile laboratory environment do not always work in demanding real-world conditions.
Currently, there are imaging devices on the market which operate both in the visible and near-infrared and provide accurate and reliable 3D information in the form of point clouds. These clouds can be further processed to extract skeletal information. An example of such a device is the popular Kinect controller, which, along with the included software, provides the skeletal data for the entire body of the observed person. There are similar solutions, with smaller observation area and higher resolution, for obtaining skeletal data for the observed hand. Examples of such devices are some time-of-flight cameras or a Leap Motion controller (LMC). These are in early stages of development but technological progress in this area is fast. For example, the first version of the Leap Motion Software Development Kit (SDK) was able to track only visible parts of the hand, but the version 2 uses some prediction algorithms, and the individual joints of each finger are tracked even when the controller cannot see them. It is expected that sooner or later, newer solutions will emerge. Therefore, it is reasonable to undertake research on the handshape recognition based on skeletal data.
Despite a number of works in this field, the problem remains unresolved. Current works are either dedicated to one device only or deal with a few simple static shapes or dynamic gestures, for which the great support is the distinctive role of the motion trajectory.
In this paper, a method of handshapes recognition, based on skeletal data is described. The proposed feature vector encodes the relative differences between vectors associated with the pointing directions of the fingers and the palm normal. Different classifiers are tested on the demanding dataset, containing 48 handshapes performed by five users. Each shape is repeated 500 times by each user. Two different sensor configurations and significant variation in the hand rotation are considered. The late fusion at the decision level of individual models, as well as comparative study carried out on a publicly available dataset, are also included.
The remainder of this paper is organized as follows. The recent works are characterized in
Section 2,
Section 3 describes the method,
Section 4 discusses the experiment results, and
Section 5 summarizes the paper.
Appendix A contains the full versions of the tables with the results of leave-one-person-out cross-validation.
2. Recent Works
The suitability of the skeletal data, obtained from the LMC, for Australian Sign Language (Auslan) recognition has been explored in [
1]. Testing showed that despite the problems with accurate tracking of fingers, especially when the hand is perpendicular to the controller, there is a potential for the use of the skeletal data, after some further improvement of the provided API.
An extensive evaluation of the quality of skeletal data, obtained from the LMC, was also tested in [
2]. Static and dynamic measurements were performed using a high-precision motion tracking system. For static objects, the 3D position estimation with the standard deviation less than 0.5 mm was reported. A spatial dependency of the controller’s precision was also tested. In [
1,
2] the early version of the provided software was used. Recently, the stability of tracking has been significantly improved.
In [
3], the skeletal data was used to recognize a subset of 10 letters from American Manual Alphabet. Handshapes were presented 10 times by 14 users. The feature vector was based on the positions and orientations of the fingers measured by the LMC. The multi-class support vector machine (SVM) classifier was used. The recognition accuracy was 80.86%. When the feature vector was augmented by features calculated from the depth map obtained with the Kinect sensor, the recognition accuracy increased to 91.28%.
In [
4], the 26 letters of the English alphabet in American Sign Language (ASL) performed by two users were recognized using the features derived from the skeletal data. The recognition rate was 72.78% for the k-nearest neighbor (kNN) classifier and 79.83% for SVM.
Twenty-eight signs corresponding to the Arabic alphabet, performed 100 times by one person were recognized using 12 selected attributes of the hand skeletal data [
5]. For the Naive Bayes (NB) classifier, the recognition rate was 98.3% and for the Multilayer Perceptron (MP) 99.1%.
In [
6], the 50 dynamic gestures from Arabic Sign Language (ArSL), performed by two persons, were recognized using the feature vector composed of positions of fingers and distances between them and multi-layer perceptron neural network. The recognition accuracy was 88%.
A real-time multi-sensor system for ASL recognition was presented in [
7]. The skeletal data, collected from Leap Motion sensors, was fused using multiple sensors data fusion and the classification was performed using hidden Markov models (HMM). The 10 gestures, corresponding to the digits from 0 to 9, were performed by eight subjects. The recognition accuracy was 93.14%.
In [
8], the 24 letters from ASL were recognized using the feature vector that consists of the normal vector of the palm, coordinates of fingertips and finger bones, the arm direction vector, and the fingertip direction vector. These features were derived from the skeletal data provided by LMC. The decision tree (DT) and genetic algorithm (GA) were used as the classifier. The recognition accuracy was 82.71%.
Five simple handshapes were used to control a robotic wheelchair in [
9]. Skeletal data was acquired by LMC. Feature vector consisted of the palm roll, pitch and yaw angles, and the palm normal direction vector. Block Sparse Representation (BSR) based classification was applied. According to the authors, the method yields accurate results but no detailed information about experiments and obtained recognition accuracy are given.
In [
10], 10 handshapes corresponding to the digits in Indian Sign Language were recognized. The feature vector consisted of the distances between the consecutive fingertips and palm center and the distances between the fingertips. The features were derived from skeletal data acquired by LMC. Multi-Layer Perceptron (MP) neural network with back propagation algorithm was used. Each shape was presented by four subjects. The recognition accuracy of 100% is reported in the paper.
In [
11], 28 letters of the Arabic Sign Language were recognized using the body and hand skeletal data acquired by Kinect sensor and LMC. One thousand four hundred samples were recorded by 20 subjects. One hundred and three features for each letter were reduced to 36 using the Principal Component Analysis algorithm. For the SVM classifier, the recognition accuracy of 86% is reported.
In [
12], 25 dynamic gestures from Indian Sign Language were recognized using a multi-sensor fusion framework. Data was acquired using jointly calibrated Kinect sensor and LMC. Each word was repeated eight times by 10 subjects. Different data fusion schemes were tested and the best recognition accuracy of 90.80% was reported for the Coupled Hidden Markov Models (CHMM).
Twenty-eight handshapes corresponding to the letters of the Arabic alphabet were recognized using skeletal data from LMC and RGB image from Kinect sensor [
13]. Gestures were performed at least two times by four users. Twenty-two of 28 letters were recognized with 100% accuracy.
In [
14], Rule Based-Backpropagation Genetic Algorithm Neural Network (RB-BGANN) was used to recognize 26 handshapes corresponding to the alphabet in Sign System of Indonesian Language. Thirty-four features, related to the fingertips positions and orientations, taken from the hand skeletal data acquired by LMC, were used. Each gesture was performed five times. The recognition accuracy was 93.8%.
The skeletal data provided by the hand tracking devices LMC and Intel RealSense was used for recognizing 20 of the 26 letters from ASL [
15]. The SVM classifier was used. The developed system was evaluated with over 50 individuals, and the recognition accuracy for particular letters was in the range of 60–100%.
In [
16], a method to recognize static sign language gestures, corresponding to 26 American alphabet letters and 10 digits, performed by 10 users, was presented. The skeletal data acquired by LMC was used. Two variants of the feature vector were considered: (i) the distances between fingertips and the center of the palm, and (ii) the distances between the adjacent fingertips. The nearest neighbor classifier with four different similarity measures (Euclidean, Cosine, Jaccard, and Dice) was used. The obtained recognition accuracy varied from 70–100% for letters and 95–100% for digits.
Forty-four letters of Thai Sign Language were recognized using the skeletal data acquired by LMC and the decision trees [
17]. The recognition accuracy of 72.83% was reported, but the authors do not indicate how many people performed gestures.
In [
18], the skeletal data, acquired from two Leap Motion controllers, was used to recognize 28 letters from Arabic Sign Language. Handshapes were presented 10 times by one user. For the data fusion at features level and Linear Discriminant Analysis (LDA) classifier, the average accuracy was about 97.7%, while for classifier level fusion using Dempster-Shafer theory of evidence—97.1%.
Ten static gestures performed 20 times by 13 individuals were recognized using the new feature called Fingertips Tip Distance, derived from LMC skeletal data, and Histogram of Oriented Gradients (HOG), calculated from undistorted, raw sensor images [
19]. After dimension reduction, based on Principal Component Analysis (PCA), and feature weighted fusion, the multiclass SVM classifier was used. Several variants of feature fusion were explored. The best recognition accuracy was 99.42%.
In [
20], 28 isolated manual signs and 28 finger-spelling words, performed four times by 10 users, were recognized. The proposed feature vector consisted of fingertip positions and orientations derived from the skeletal data obtained with LMC. The SVM classifier was used to differentiate between manual and finger spelling sequences and the Bidirectional Long Short-Term Memory (BLSTM) recurrent neural networks were used for manual sign and fingerspelled letters recognition. The obtained recognition accuracy was 63.57%.
Eight handshapes, that can be used to make orders in a bar, were recognized in [
21]. Each shape was presented three times by 20 participants. The feature vector consisted of normalized distances between the tips of the fingers and the center of the palm and was calculated from row skeletal data provided by LMC. Three classification methods: kNN, MP and Multinomial Logistic Regression (MLR) were considered. The best recognition accuracy of 95% was obtained for kNN classifier.
In [
22], fingertip distances, fingertip inter-distances, and hand direction, derived from skeletal data acquired by LMC as well as the RGB-D data provided by Kinect sensor were used for sign language recognition in a multimodal system. Ten handshapes, performed 10 times by 14 users were recognized using data-level, feature-level, and decision-level multimodal fusion techniques. The best recognition accuracy of 97.00% was achieved for the proposed decision level fusion scheme.
The current works are summarized in
Table 1.
4. Experiments
4.1. Datasets
Two datasets were considered.
4.1.1. Dataset 1: Authors’ Own Dataset
Forty-eight static handshapes, occurring in Polish Finger Alphabet (PFA) and Polish Sign Language (PSL) were considered (
Figure 3) [
25].
The gestures were recorded in two configurations: (i) LMC lies horizontally on the table (configuration user-sensor); (ii) the sensor is attached to the monitor and directed towards the signer (configuration user-user). In the configuration (i), two variants were additionally considered: (a) gestures are made with fixed hand orientation (like in PFA); (b) spatial hand orientation changes in a wide range (like in PSL). In the configuration (i) variant (a) five people, designated hereinafter A, B, C, D, and E, participated in the recordings. In other cases, the gestures of person A were recorded. Gestures were shown by each person 500 times. During the data collection, visual feedback was provided, and when an abnormal or incomplete skeleton was observed, the process was repeated to ensure that 500 correct shapes were registered for each class. Incorrect data was observed for approximately 5% of frames. It was also noticed that the device works better when the whole hand with very visible fingers is presented first and then slowly changes to the desired shape.
4.1.2. Dataset 2: Microsoft Kinect and Leap Motion Dataset
In order to evaluate the method for more users and to make a comparative analysis, the database provided in the work [
3] was used. The database contains the recordings of 10 letters from ASL, performed 10 times by 14 people and acquired by jointly calibrated LMC and depth sensor.
4.2. Results
For LMC lying on the table (configuration (i)) the best recognition rates (≥99.5%) were for SVM, kNN, Ens Bag, Ens Sub kNN and FLANN, wherein the results obtained under large variation in hand’s rotation (variant (b)) were only slightly worse. For configuration (ii), the results are better. This configuration seems to be more natural for a user accustomed to showing gestures to another person.
However, the results of the leave-one-subject-out cross-validation experiment, shown in
Table 6 and
Table A1, are much worse for all considered classification methods. The best recognition rates (≥50.0%) were for: LD, SVM Lin, Ens Bag.
The performances of the individual gestures are strongly dependent on the user, and the training set consisting of four people is not sufficiently representative to correctly classify the gestures of the fifth, unknown person.
The results obtained for dataset 2, and shown in
Table 7,
Table 8 and
Table A2, confirm that when the training set consists of more users, the discrepancy between 10-fold cross-validation and leave-one-subject-out cross-validation is significantly lower. However, it should be mentioned that in this case, the number of recognized classes is much smaller.
For the dataset 2 and 10-fold CV, the best results (≥88.0%) were for SVM Gauss, kNN 1, kNN W, Ens Bag and Ens Sub kNN, whereas for leave-one-subject-out cross-validation the best results (≥88.0%) were for kNN1, kNN W, Ens Sub kNN.
Because for the most demanding case (
Table 6) the best results were obtained for SVM Lin and Ens Bag—the parameters of these two classifiers were further analyzed (see
Table 9 and
Table 10).
The SVM classifier is by nature binary. It classifies instances into one of the two classes. However, it can be turned into a multinomial classifier by two different strategies: one-vs-one and one-vs-all. In one-vs-one, a single classifier for each pair of classes is trained. The decision is made by applying all trained classifiers to an unseen sample and a voting scheme. The class that has been recognized most times is selected. In one-vs-all, a single classifier per class is trained. The samples of that class are positive samples, and all other samples are negatives. The decision is made by applying all trained classifiers to an unseen sample and selecting the one with the highest confidence score.
In SVM Lin classifier, the change of the multiclass method from one-vs-one to one-vs-all leads to decrease in the recognition accuracy. For Ens Bag classifier, the recognition accuracy increases with the number of learners, but the response time increases as well (see
Figure 4).
The experiment was stopped when the response time reached 100 ms, i.e., the value at which the typical user will notice the delay [
42].
In
Table 8 the best results were obtained for 1 NN, 10 NN W, and Ens Sub kNN. The FLANN version of the kNN classifier turned out to be the fastest one. Therefore, a further analysis of kNN classifiers has been carried out.
In
Table 11, the nearest neighbor classifier 1 NN with brute-force search in the dataset was compared with the FLANN version with a different number of the randomized trees.
As should be expected, the results obtained for the exact version are slightly better than for the classifier, which finds the approximate nearest neighbor. However, if we compare the processing times, the FLANN version is over 400 times faster. Therefore, this classifier is a particularly attractive choice in practical applications.
An experiment was also carried out to check whether the late fusion of classifiers, at the decision level of individual models, leads to improved recognition accuracy. A simple method was used, in which every classifier votes for a given class. According to [
43], simple unweighted majority voting is usually the best voting scheme. All possible combinations of classifiers were tested. The best result of leave-one-subject-out cross-validation on dataset 1, 56.7%, was obtained when the outputs of the classifiers LD, QD, SVM Lin, Ens Boost, Ens Bag were fused. The result is better than the best result obtained for a single classifier by 4.4%. However, the fusion of classifiers leads to a decrease in the individual classes recognition. The voting deteriorates the prediction in classes F, I, Xm, Yk.
4.3. Computational Efficiency
The average response times of the individual classifiers are shown in
Table 12.
Together with the average time needed for data acquisition and feature vectors calculation, which is equal to 6 ms, they do not exceed 100 ms, so the typical user will not notice the time delay between presentation of the given gesture and the predicted response of the system [
42]. However, all experiments were carried out on a fairly powerful workstation, equipped with a 2.71 GHz processor, 32 GB of RAM and a fast SSD. For less-efficient systems, e.g., mobile or embedded devices, the preferred choice is FLANN or DT. Moreover, in the case of FLANN classifier, the randomized trees can be searched in parallel.
4.4. Comparative Analysis
According to the authors’ knowledge, the only database of static hand skeletal data available on the Internet for which comparative analysis can be carried out is Dataset 2 [
3].
Table 13 compares the recognition accuracy obtained for this database.
The first row quotes the results obtained for LMC, without additional data from the Kinect sensor. The proposed feature vector allows obtaining better results even with the same classifier (SVM).
5. Conclusions
Handshape recognition based on its skeleton becomes an important research problem because there are more and more new devices on the market that enable the acquisition of such data. In this paper:
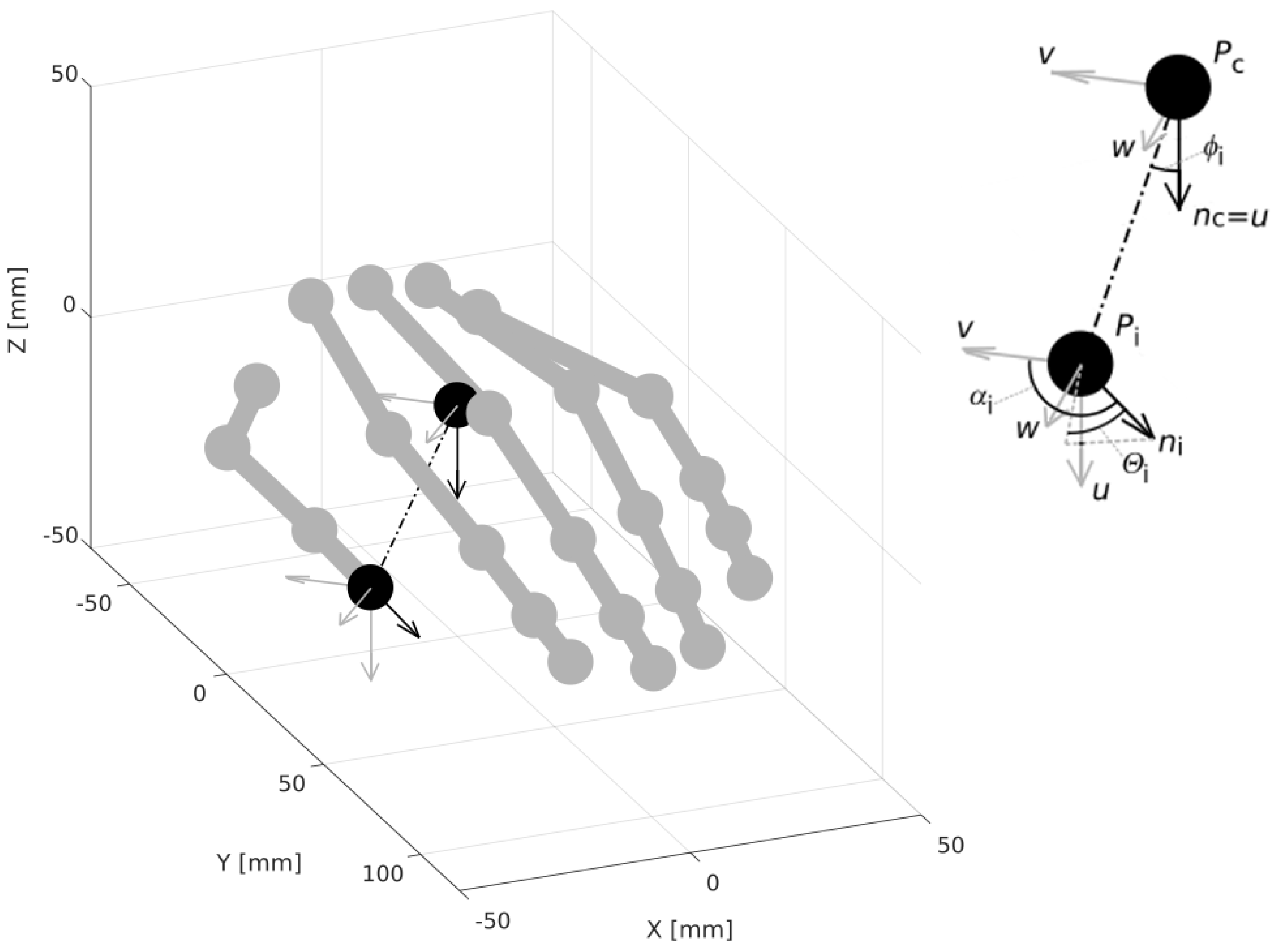
A feature vector was proposed, which describes the relative differences between the pointing directions of individual fingers and the hand normal vector.
A demanding dataset containing 48 hand shapes, shown 500 times by five persons in two different sensor placement, has been prepared and made available [
44].
The registered data has been used to perform classification. Seventeen known and popular classification methods have been tested.
For classifiers SVM Lin and Ens Bag, given the best recognition accuracies, an analysis of the impact of their parameters on the obtained results was carried out.
It was found that the weaker result for leave-one-person-out validation may be caused by individual character of performances of individual gestures, a difficult dataset, containing as many as 48 classes, among which there are very similar shapes, and imperfections of the LMC, which in the case of individual fingers occlusions tries predict their position and spatial orientation. It is worth mentioning that other works on static handshape recognition, cited in the literature, concern a smaller number of simpler gestures.
The proposed feature vector allows obtaining better results.
It was determined experimentally that although late fusion improves the results, it causes the deterioration of recognition efficiency in some classes, which in some applications may be undesirable.
To recognize complicated handshapes occurring in the sign languages, a feature vector invariant to translation, rotation, and scale, which is sensitive to the subtle differences in shape, is needed. The proposed feature vector is inspired by research on local point cloud descriptors [
27]. Angular features, describing the mutual position of two vectors normal to the cloud surface, are used there to form a representation of the local geometry. Such a descriptor is sensitive to subtle differences in shape [
45]. In our proposition, the fingertips and the palm center are treated as a point cloud, and the finger directions and the palm’s normal are used instead of the surface normals. It is also worth noting that the proposed feature vector is invariant to position, orientation, and scale. This is not always the case in the literature, where the features depending on the hand size or orientation are used. This invariance is particularly important in the case of sign language, where unlike in the finger alphabet, the hand’s position and orientation are not fixed. An interesting proposition of an invariant feature vector was proposed in [
3] and enhanced in [
19]. In
Section 4.4, it was compared to our proposal.
Analysis of the confusion matrices obtained for the dataset 1 shows that the most commonly confused shapes are: B-Bm, C-100, N-Nw, S-F, T-O, Z-Xm, Tm-100, Bz-Cm and 4z-Cm. In fact, these are very similar shapes (see
Figure 3). In adverse lighting conditions, when they are viewed from some distance or from the side, they can be confused even by a person. When sequences of handshapes, corresponding to fingerspelled words, are recognized, disambiguation can be achieved by using the temporal context. However, this is not always possible because often fingerspelling is used to convey difficult names, foreign words or proper names. If the similar shapes are discarded from the dataset 1, leave-one-subject-out cross-validation gives recognition efficiencies of about 80%.
The proposed system is fast and requires no special background or specific lighting. One of the reasons for the weaker results of leave-one-person-out validation is the imperfection of a sensor, that does not cope well with fingers occlusions. Therefore, as part of further work, the processing of point clouds registered with two calibrated sensors is considered in order to obtain more accurate and reliable skeletal data. Further work will also include recognition of letter sequences and integration of the presented solution with the sign language recognition system.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



