A Processing-in-Memory Architecture Programming Paradigm for Wireless Internet-of-Things Applications


Abstract
:1. Introduction
2. Related Works
- We propose a programming paradigm for PIM architecture. Drivers and APIs were implemented. An elaborate programming example is provided.
- We simulated a complete PIM computing system, including the host CPU and PIM cores, based on the gem5 simulator. We implemented the proposed programming paradigm using system calls.
- We built a board-to-board FPGA demo for the PIM architecture. The proposed programming paradigm was verified in this demo.
- We provide a performance comparison between the PIM computing architecture and traditional architectures.
- We show the application prospects of the PIM architecture, where our programming paradigm could also be utilized.
3. Target Architecture
4. Programming Paradigm
4.1. Task-Dividing Mechanism
4.2. Data-Transferring Mechanism
4.3. Software-Level Architecture
- Firmware download: The PIM device receives firmware sent by the user and downloads it to a specified location. Then, it frees the PIM device to run the firmware.
- Data transfer: This includes data send and receive. After firmware download is finished, data sent by a user are transferred to the PIM device and stored in a specific firmware location. After computation is finished, the specific length of the data is obtained from the specific location of the firmware, and then, the data are sent to the user.
- Algorithm configuration and execution: When the firmware is downloaded, the user can decide which algorithm the PIM device will run, and instruct the PIM device to start execution. The algorithm can be provided by the firmware or by the users.
- Status check: The user can check the status of the PIM device during execution. Only the PIM device itself can update its status. PIM device status includes PIM_start, PIM_wait_data, PIM_check_alg, PIM_running, and PIM_finish.
- File operation : to obtain file size, and read file to buffer.get_file_size(A file)read_file(A buffer, A file)
- Function transfer : CPU transfer user functions to PIM device. This realizes input and output buffer management for the PIM device. Since the CPU may transfer multiple functions to the PIM device, we should specify the main function running on the PIM device by the entry pointer.build_buf(A Obuf, A entry, A Ibuf, len)free_buf(A buffer)
- Driver interaction : The CPU obtains the PIM device information, and updates the firmware on the PIM device.find_device(A PIM_device)update_firmware(PIM_device, A buffer, len)
- Operational configuration : The CPU configures the PIM device to conduct computation. It chooses the algorithm on the PIM device firmware, sends and collects computation data, obtains the computation status of the PIM device, and waits for the PIM device computation to finish.set_algorithm(PIM_device, alg)get_data(PIM_device, A buffer, len)put_data(PIM_device, A recv_buffer, len)check_status(PIM_device)wait(PIM_device)
4.4. Programming Instructions
5. Evaluation Platform Design
5.1. Simulator Based on Gem5
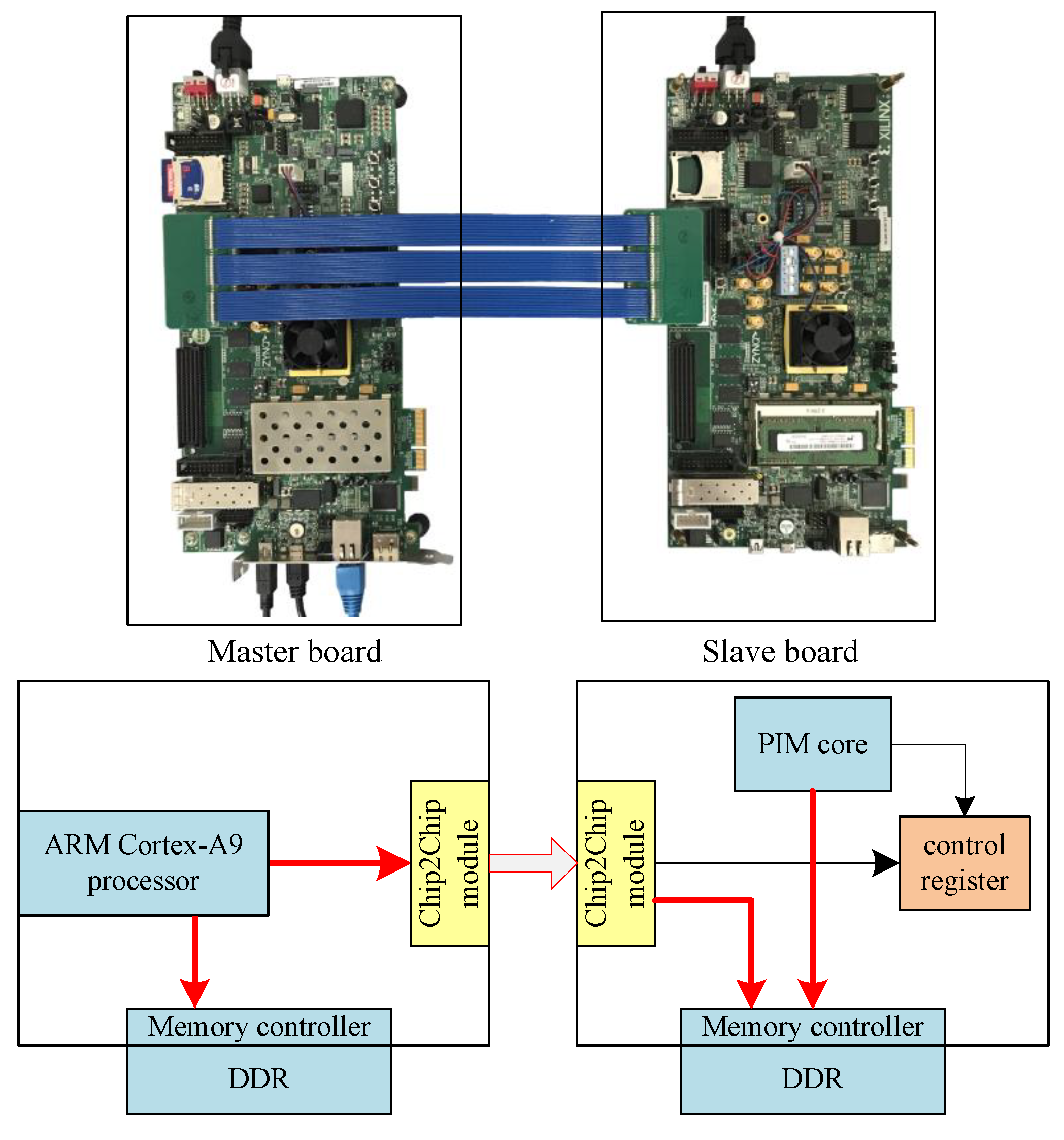
5.2. Board-to-Board FPGA Demo
6. Experiments
6.1. Experimental Framework
6.2. Results
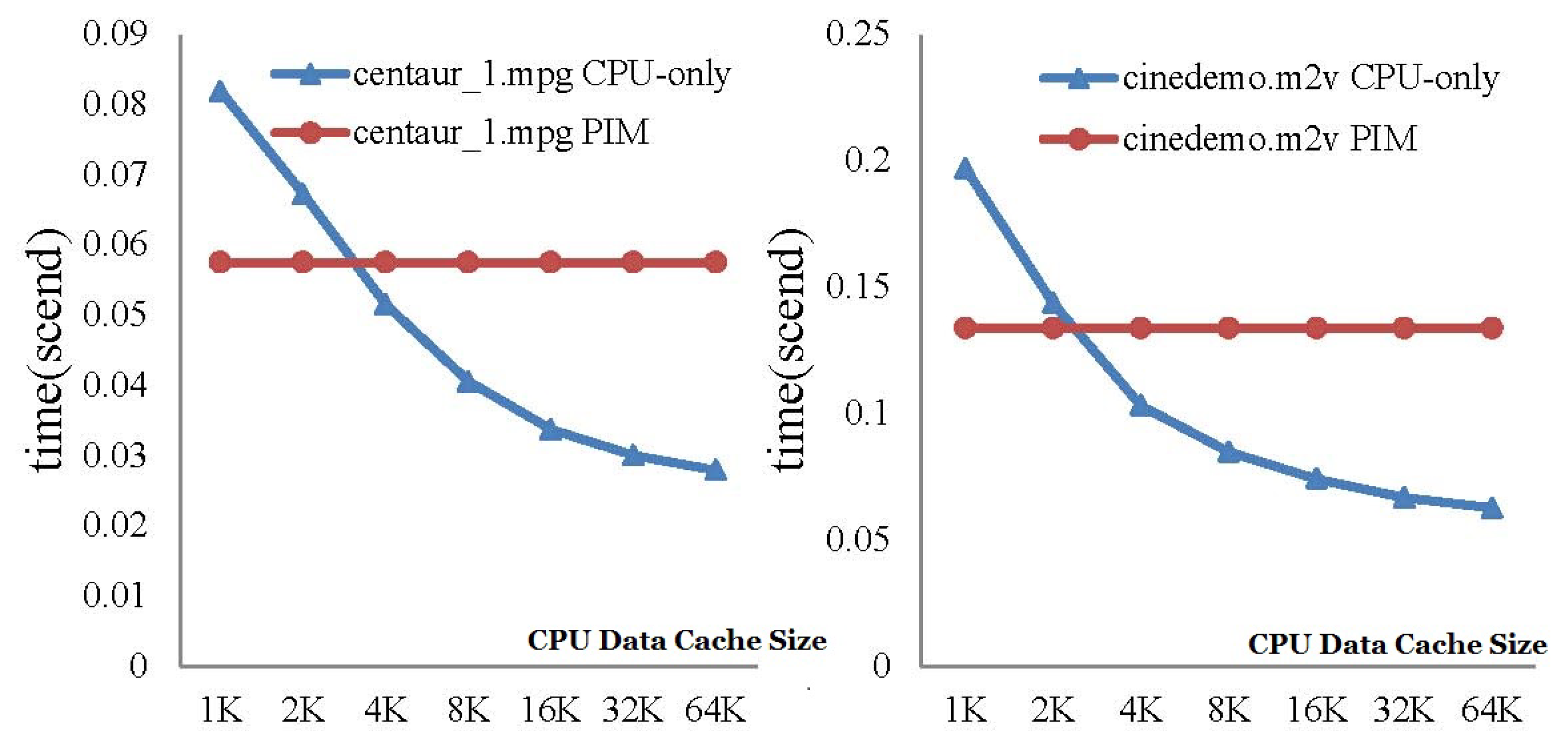
6.2.1. Mpeg2decode Programs—CPU-Only vs. PIM
6.2.2. MapReduce Programs—CPU-Only vs. PIM
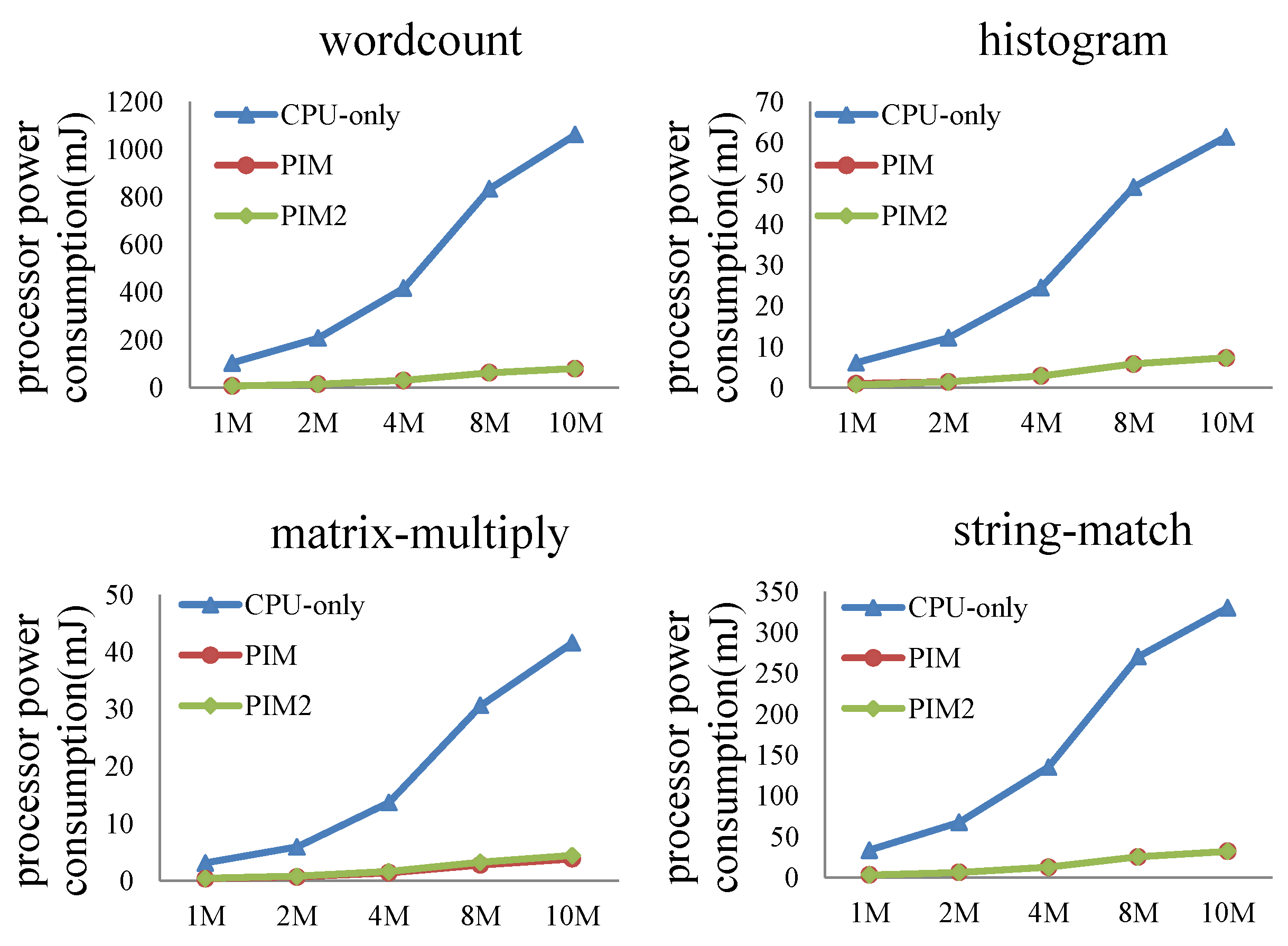
6.2.3. MapReduce Programs—CPU-Only vs. PIM vs. PIM2
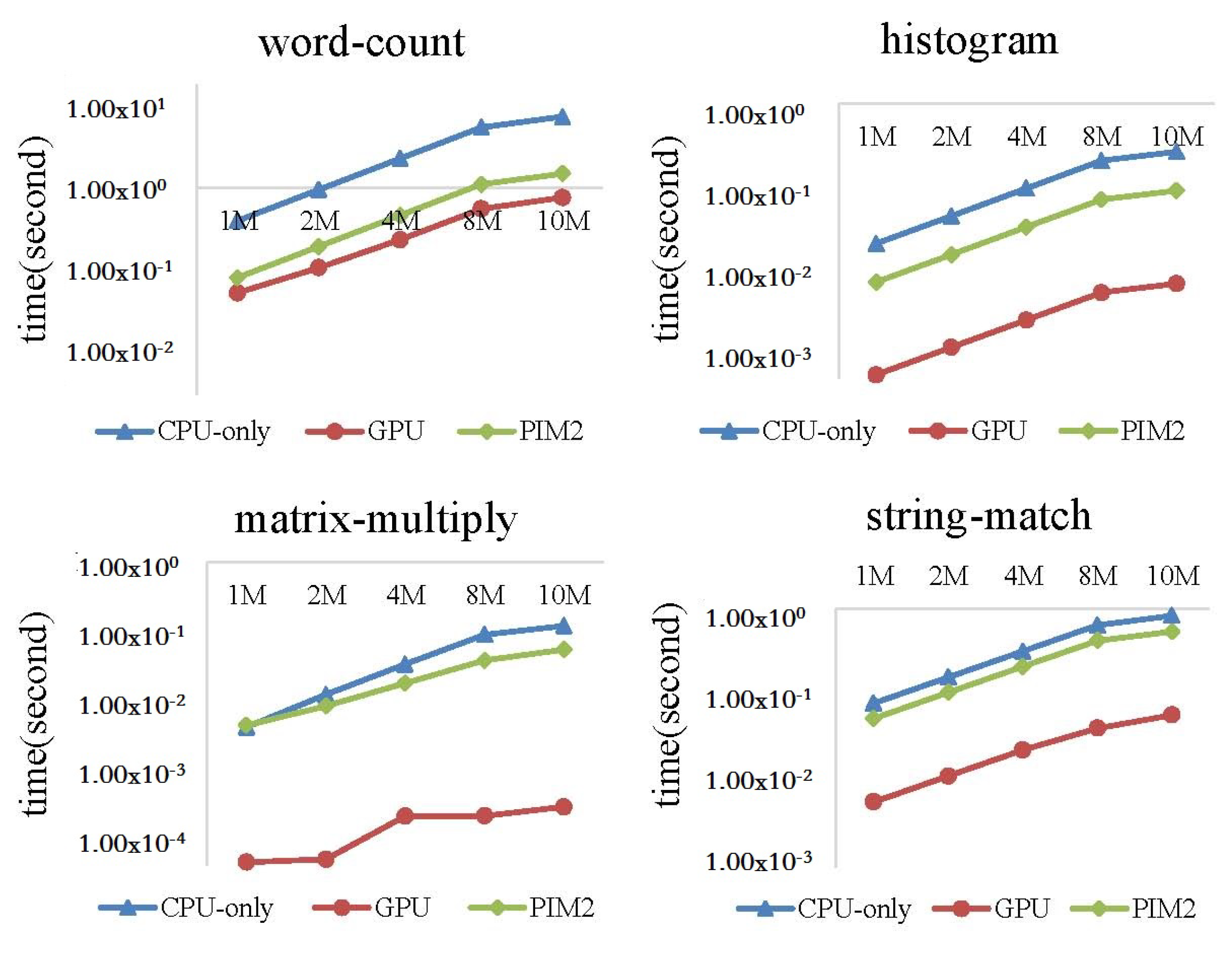
6.2.4. MapReduce Programs —CPU-Only vs. PIM2 vs. GPU
7. Application Prospect
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Scrbak, M.; Islam, M.; Kavi, K.M.; Ignatowski, M.; Jayasena, N. Processing-in-memory: Exploring the design space. In Proceedings of the 28th International Conference on Architecture of Computing Systems (ARCS 2015); Springer International Publishing: Cham, Switzerland, 2015; pp. 43–54. [Google Scholar]
- Ferdman, M.; Adileh, A.; Kocberber, O.; Volos, S.; Alisafaee, M.; Jevdjic, D.; Kaynak, C.; Popescu, A.D.; Ailamaki, A.; Falsafi, B. A case for specialized processors for scale-out workloads. IEEE Micro 2014, 34, 31–42. [Google Scholar] [CrossRef]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Zhang, D.; Jayasena, N.; Lyashevsky, A.; Greathouse, J.L.; Xu, L.; Ignatowski, M. Top-pim: Throughput-oriented programmable processing in memory. In Proceedings of the International Symposium on High-performance Parallel and Distributed Computing, Vancouver, BC, Canada, 23–27 June 2014; pp. 85–98. [Google Scholar]
- Torrellas, J. Flexram: Toward an advanced intelligent memory system: A retrospective paper. In Proceedings of the 2012 IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 3–4. [Google Scholar]
- Zhang, D.; Jayasena, N.; Lyashevsky, A.; Greathouse, J.; Meswani, M.; Nutter, M.; Ignatowski, M. A new perspective on processing-in-memory architecture design. In Proceedings of the ACM SIGPLAN Workshop on Memory Systems Performance and Correctness, Seattle, WA, USA, 16–19 June 2013; pp. 1–3. [Google Scholar]
- Balasubramonian, R.; Chang, J.; Manning, T.; Moreno, J.H.; Murphy, R.; Nair, R.; Swanson, S. Near-data processing: Insights from a micro-46 workshop. IEEE Micro 2014, 34, 36–42. [Google Scholar] [CrossRef]
- Jeddeloh, J.; Keeth, B. Hybrid memory cube new dram architecture increases density and performance. In Proceedings of the Symposium on VLSI Technology, Honolulu, HI, USA, 12–14 June 2012; pp. 87–88. [Google Scholar]
- Lee, D.U.; Kim, K.W.; Kim, K.W.; Lee, K.S.; Byeon, S.J.; Kim, J.H.; Cho, J.H.; Lee, J.; Chun, J.H. A 1.2v 8 gb 8-channel 128 gb/s high-bandwidth memory (hbm) stacked dram with effective i/o test circuits. IEEE J. Solid-State Circ. 2015, 50, 191–203. [Google Scholar] [CrossRef]
- Jun, H.; Cho, J.; Lee, K.; Son, H.Y.; Kim, K.; Jin, H.; Kim, K. Hbm (high bandwidth memory) dram technology and architecture. In Proceedings of the Memory Workshop (IMW), Monterey, CA, USA, 14–17 May 2017; pp. 1–4. [Google Scholar]
- Molka, D.; Hackenberg, D.; Schone, R.; Muller, M.S. Characterizing the energy consumption of data transfers and arithmetic operations on x86-64 processors. In Proceedings of the International Conference on Green Computing, Hangzhou, China, 30 October–1 November 2010; pp. 123–133. [Google Scholar]
- Kogge, P.M. Execube—A new architecture for scaleable mpps. In Proceedings of the International Conference on Parallel Processing, Raleigh, NC, USA, 15–19 August 1994; pp. 77–84. [Google Scholar]
- Patterson, D.; Anderson, T.; Cardwell, N.; Fromm, R.; Keeton, K.; Kozyrakis, C.; Thomas, R.; Yelick, K. Intelligent RAM (IRAM): Chips that remember and compute. In Proceedings of the IEEE International Solid-State Circuits Conference (43rd ISSCC), San Francisco, CA, USA, 8 February 1997; pp. 224–225. [Google Scholar]
- Patterson, D.; Anderson, T.; Cardwell, N.; Fromm, R.; Keeton, K.; Kozyrakis, C.; Thomas, R.; Yelick, K. A case for intelligent RAM: IRAM. IEEE Micro 1997, 17, 34–44. [Google Scholar] [CrossRef]
- Nyasulu, P.M. System Design for a Computational-RAM Logic-In-Memory Parallel-Processing Machine. Ph.D. Thesis, Carleton University, Ottawa, ON, Canada, 1999. [Google Scholar]
- Murakami, K.; Inoue, K.; Miyajima, H. Parallel processing ram (ppram). Comp. Biochem. Physiol. Part A Physiol. 1997, 94, 347–349. [Google Scholar] [CrossRef]
- Draper, J.; Chame, J.; Hall, M.; Steele, C.; Barrett, T.; LaCoss, J.; Granacki, J.; Shin, J.; Chen, C.; Kang, C.W.; et al. The architecture of the diva processing-in-memory chip. In Proceedings of the International Conference on Supercomputing, New York, NY, USA, 22–26 June 2002; pp. 26–37. [Google Scholar]
- Mai, K.; Paaske, T.; Jayasena, N.; Ho, R.; Dally, W.J.; Horowitz, M. Smart memories: A modular reconfigurable architecture. In Proceedings of the 27th International Symposium on Computer Architecture, Vancouver, BC, Canada, 10–14 June 2000; pp. 161–171. [Google Scholar]
- Rezaei, M.; Kavi, K.M. Intelligent memory manager: Reducing cache pollution due to memory management functions. J. Syst. Archit. 2006, 52, 41–55. [Google Scholar] [CrossRef] [Green Version]
- Tseng, H.W.; Tullsen, D.M. Data-triggered multithreading for near-data processing. In Proceedings of the Workshop on Near-Data Processing, Waikiki, HI, USA, 5 December 2003. [Google Scholar]
- Chu, M.L.; Jayasena, N.; Zhang, D.P.; Ignatowski, M. High-level programming model abstractions for processing in memory. In Proceedings of the Workshop on Near-Data Processing, Waikiki, HI, USA, 5 December 2003. [Google Scholar]
- Pugsley, S.H.; Jestes, J.; Zhang, H.; Balasubramonian, R.; Srinivasan, V.; Buyuktosunoglu, A.; Davis, A.; Li, F. NDC: Analyzing the impact of 3d-stacked memory+logic devices on mapreduce workloads. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Monterey, CA, USA, 23–25 March 2014; pp. 190–200. [Google Scholar]
- Islam, M.; Scrbak, M.; Kavi, K.M.; Ignatowski, M.; Jayasena, N. Improving Node-Level MapReduce Performance Using Processing-in-Memory Technologies; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S. The gem5 simulator. ACM SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Li, S.; Ahn, J.H.; Strong, R.D.; Brockman, J.B.; Tullsen, D.M.; Jouppi, N.P. Mcpat: An integrated power, area, and timing modeling framework for multicore and manycore architectures. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, NY, USA, 12–16 December 2009; pp. 469–480. [Google Scholar]
- Ahn, J.; Hong, S.; Yoo, S.; Mutlu, O.; Choi, K. A scalable processing-in-memory accelerator for parallel graph processing. In Proceedings of the ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; pp. 105–117. [Google Scholar]
- Morad, A.; Yavits, L.; Ginosar, R. GP-SIMD processing-in-memory. ACM Trans. Archit. Code Optim. 2015, 11, 53. [Google Scholar] [CrossRef]
- The gem5 Simulator. Available online: http://gem5.org/Main_Page (accessed on 30 December 2018).
- Binkert, N.L.; Dreslinski, R.G.; Hsu, L.R.; Lim, K.T.; Saidi, A.G.; Reinhardt, S.K. The M5 Simulator: Modeling Networked Systems. IEEE Micro 2006, 26, 52–60. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Parameters | |
|---|---|---|
| CPU-only | Out-of-Order | |
| L1-cache | 64 KB | |
| (64 KB Icache and 64 KB Dcache) | ||
| L2-cache | 1 MB | |
| block size | 64 B | |
| memory capacity | 2 GB | |
| Clock rate | 1 GHz | |
| PIM core | in-order | |
| L1-cache | 64 KB | |
| (64 KB Icache and 64 KB Dcache) | ||
| Clock rate | 1 GHz | |
| PIM | CPU-only + one PIM core | |
| PIM2 | CPU-only + two PIM cores | |
| GPU | NVIDIA GeForce GTX480 | |
| Fermi GPU architecture | ||
| 15 streaming multiprocessors | ||
| each containing 32 cores | ||
| virtual memory page size | 4 GB | |
| Clock rate | 700 MHz | |
| Centaur_1.mpg | Cinedemo.m2v | |
|---|---|---|
| CPU-only | ||
| PIM |
| Centaur_1.mpg | Cinedemo.m2v | |
|---|---|---|
| CPU-only | ||
| PIM |
| Memory Access Latency | Others | |
|---|---|---|
| wordcount | 24% | 76% |
| histogram | 59% | 41% |
| matrix-multiply | 69% | 31% |
| string-match | 10% | 90% |
| CPU-Only | PIM | |
|---|---|---|
| wordcount | 0.52 | |
| histogram | 0.16 | |
| matrix-multiply | 2.18 | |
| string-match | 0.13 |
| CPU-Only | PIM | |
|---|---|---|
| wordcount | 2.93 | |
| histogram | 0.40 | |
| matrix-multiply | 0.87 | |
| string-match | 0.18 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Hou, Y.; He, H. A Processing-in-Memory Architecture Programming Paradigm for Wireless Internet-of-Things Applications. Sensors 2019, 19, 140. https://doi.org/10.3390/s19010140
Yang X, Hou Y, He H. A Processing-in-Memory Architecture Programming Paradigm for Wireless Internet-of-Things Applications. Sensors. 2019; 19(1):140. https://doi.org/10.3390/s19010140
Chicago/Turabian StyleYang, Xu, Yumin Hou, and Hu He. 2019. "A Processing-in-Memory Architecture Programming Paradigm for Wireless Internet-of-Things Applications" Sensors 19, no. 1: 140. https://doi.org/10.3390/s19010140
APA StyleYang, X., Hou, Y., & He, H. (2019). A Processing-in-Memory Architecture Programming Paradigm for Wireless Internet-of-Things Applications. Sensors, 19(1), 140. https://doi.org/10.3390/s19010140