Have I Seen This Place Before? A Fast and Robust Loop Detection and Correction Method for 3D Lidar SLAM



Abstract
:1. Introduction
2. Related Work
3. Contributions
- We accelerated the computation of a global 3D descriptor to detect strong loop candidates in lidar data. Compared to many other 3D descriptors, ours does not depend on the estimation of surface normals in the point cloud. The main motivation for this is the high difficulty of estimating these normals accurately given the sparse and inhomogeneous point density of lidar point clouds. Our 3D descriptor thus leads to more robust loop detections. A compiled version of our algorithm has been made available to the community through a GitHub repository, allowing future use (https://github.com/Shaws/m2dp-gpu).
- We propose a global registration technique based on four-point congruent sets, inspired by the work of Mellado et al. [26]. We improved the efficiency significantly by omitting its randomized component, which leads to faster execution times. Moreover, our improvements make the registration technique more robust for sparse and inhomogeneous 3D data.
- We propose and evaluate a loop correction algorithm that omits the iteration between the SLAM front- and back-end, leading to very fast computations of the solution.
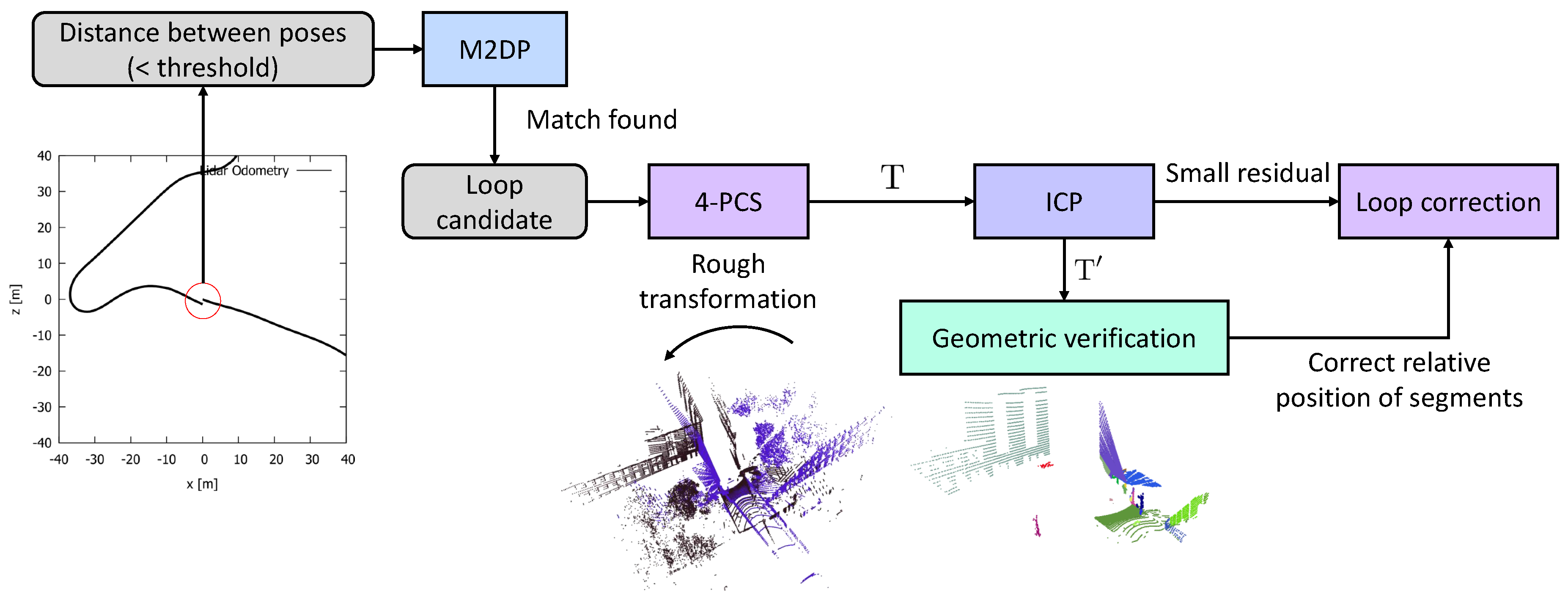
4. Approach
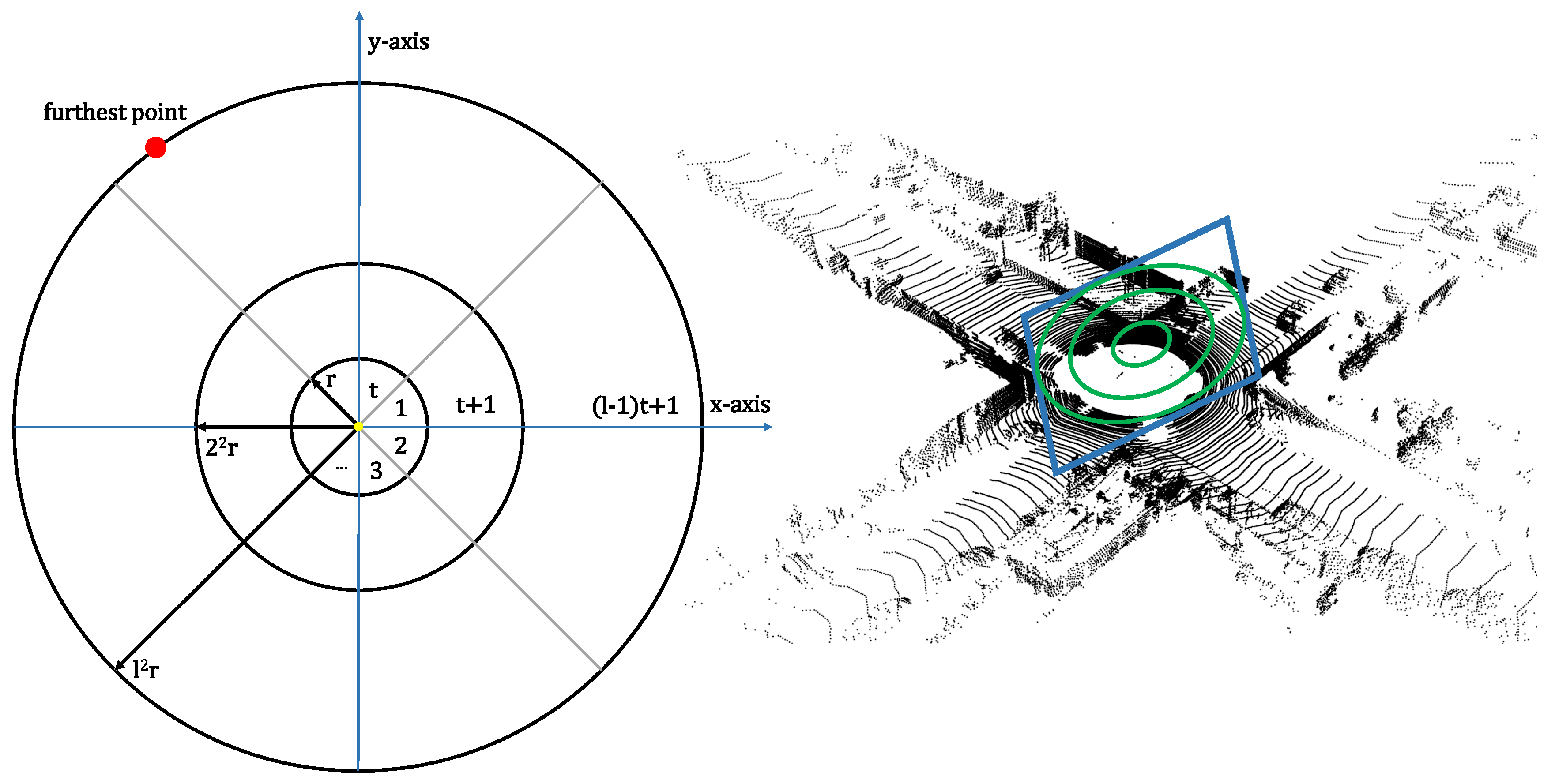
4.1. Multiview 2D-Projection
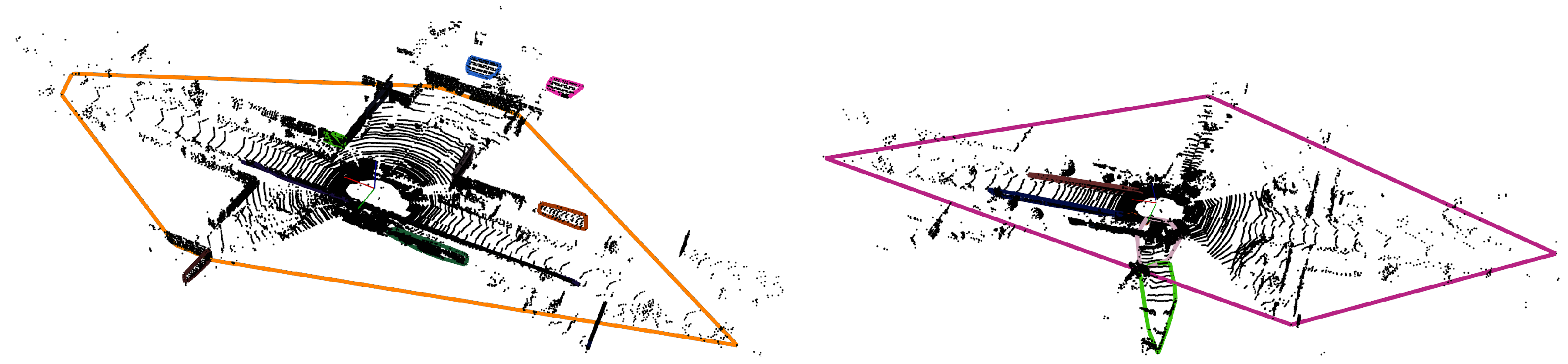
4.2. Four-Point Congruent Sets
4.2.1. Selecting a Coplanar Base
4.2.2. Finding Congruent Sets
4.2.3. Test Rigid Transformation
4.3. Verification through ICP and Geometrical Consistency
4.4. Loop Correction
5. Evaluation
5.1. Speed Analysis Global Descriptor Computation
5.2. Speed Analysis Global Registration
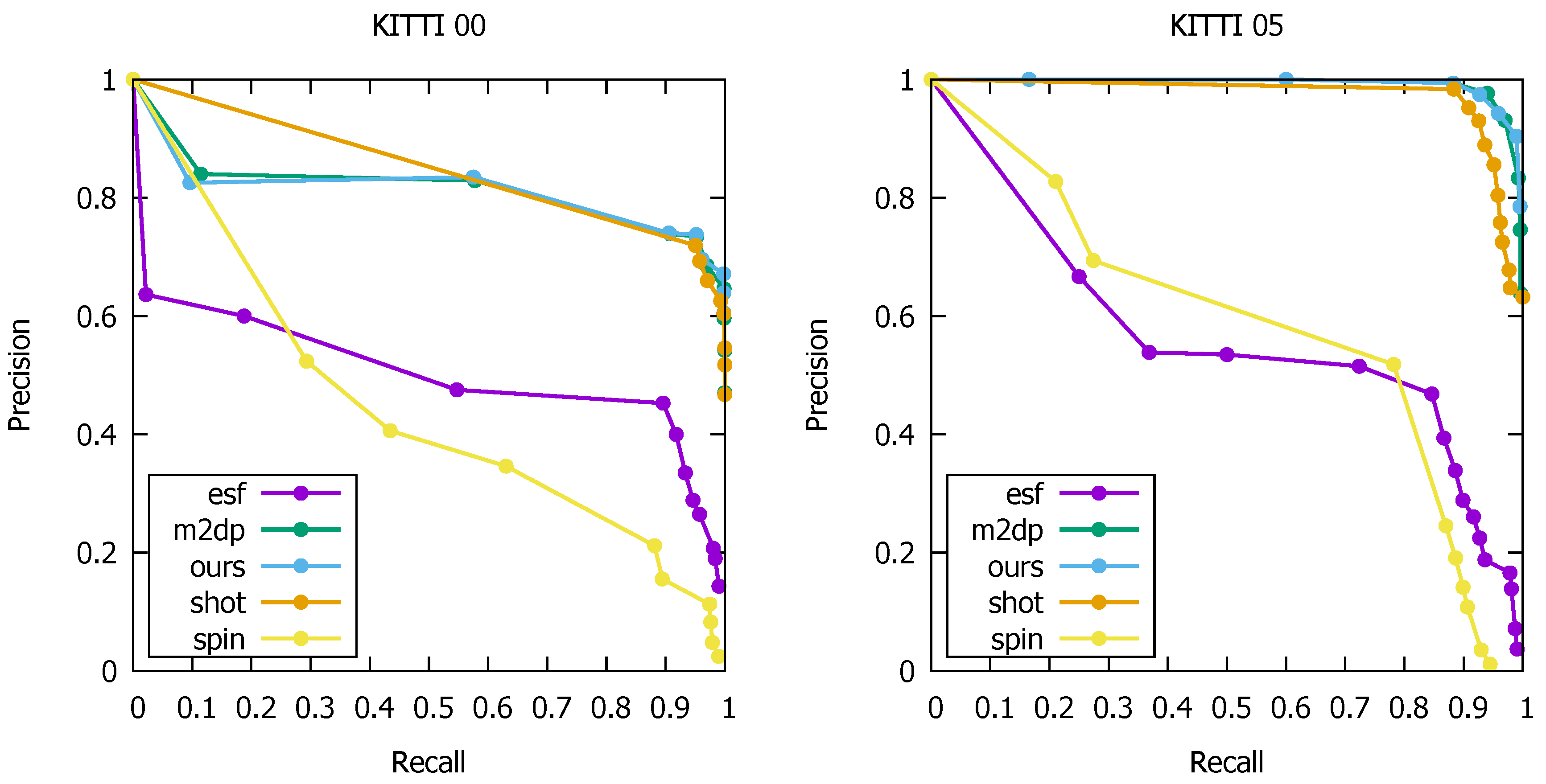
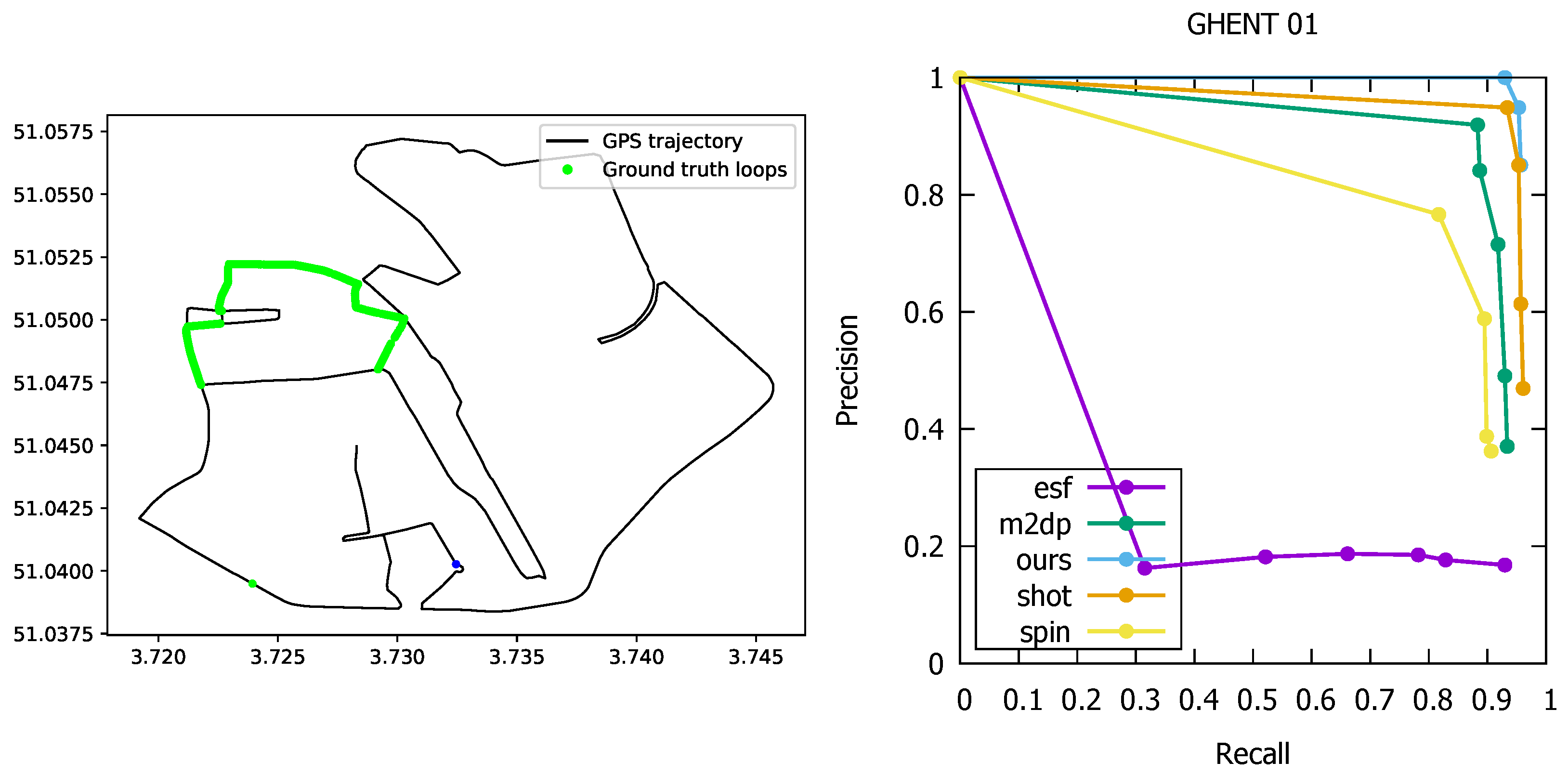
5.3. Loop Detection Accuracy
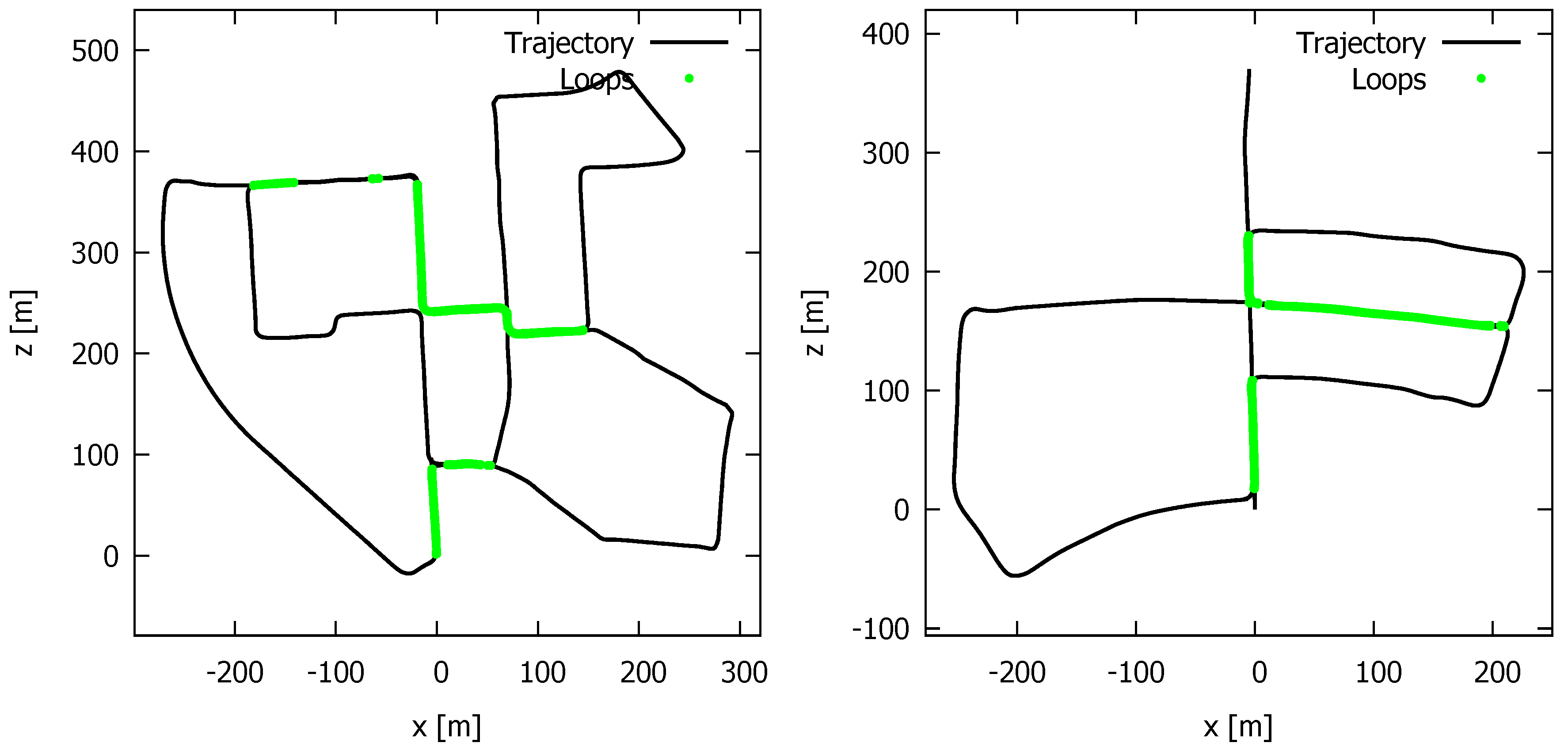
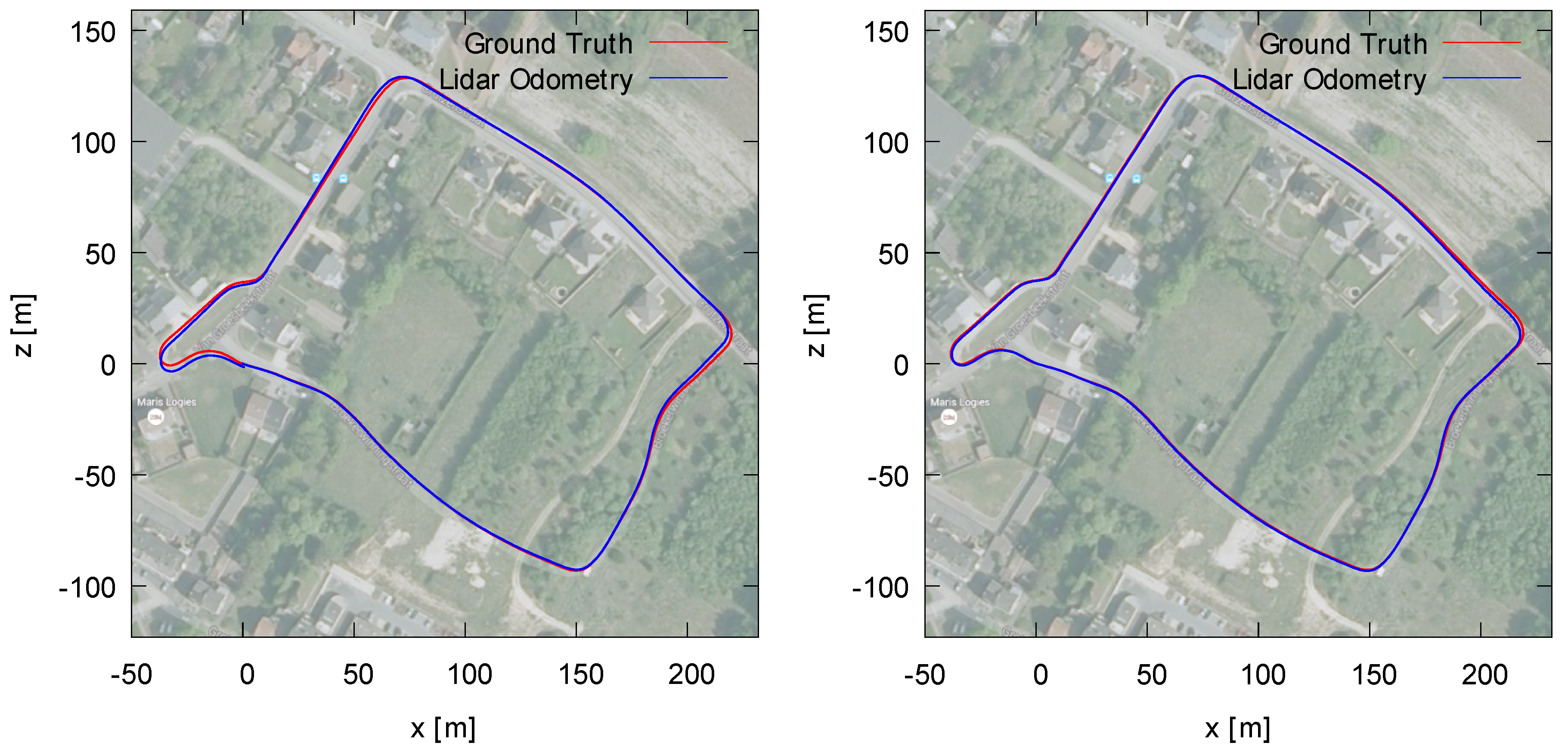
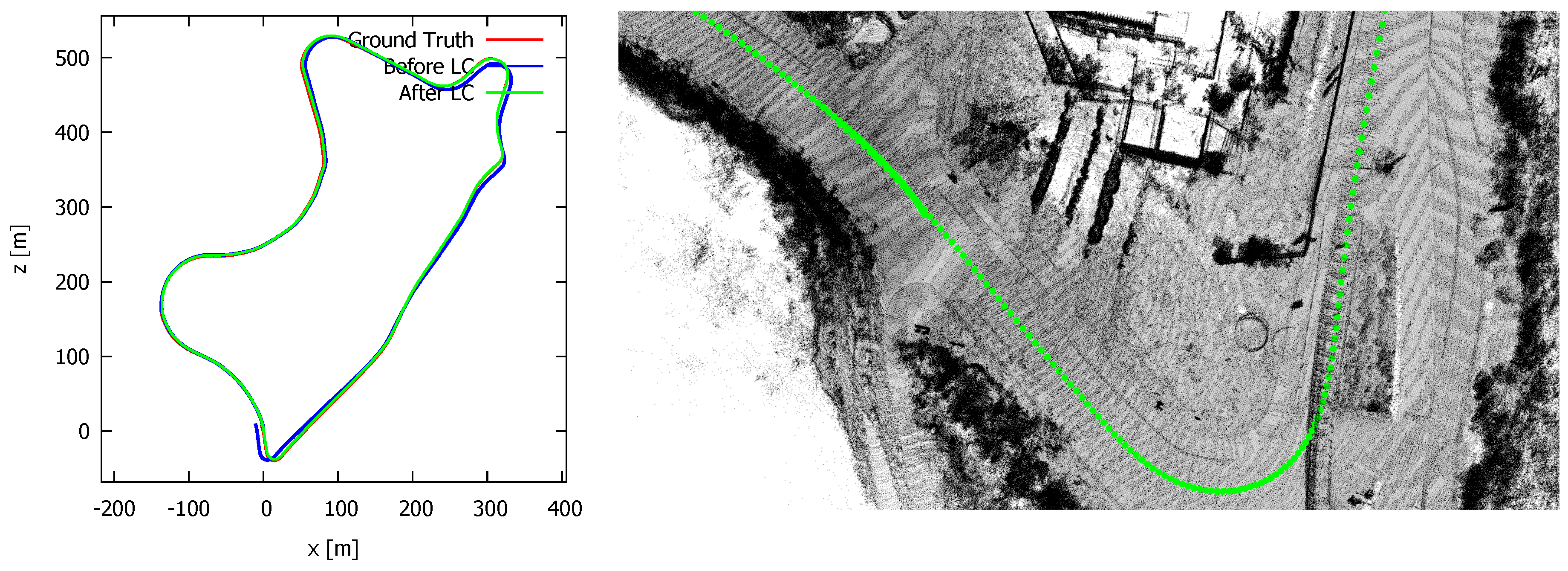
5.4. Quality and Speed of the Loop Correction
5.5. Speed Analysis Entire Loop Closure Process
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Steder, B.; Ruhnke, M.; Grzonka, S.; Burgard, W. Place recognition in 3D scans using a combination of bag of words and point feature based relative pose estimation. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1249–1255. [Google Scholar]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3D object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar] [CrossRef]
- Sipiran, I.; Bustos, B. A Robust 3D Interest Points Detector Based on Harris Operator; Eurographics Workshop on 3D Object Retrieval; Daoudi, M., Schreck, T., Eds.; The Eurographics Association: Norrköping, Sweden, 2010; pp. 7–14. [Google Scholar] [CrossRef]
- Scovanner, P.; Ali, S.; Shah, M. A 3-Dimensional Sift Descriptor and Its Application to Action Recognition. In Proceedings of the MULTIMEDIA ’07 15th International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; ACM: New York, NY, USA, 2007; pp. 357–360. [Google Scholar] [CrossRef]
- Steder, B.; Rusu, R.B.; Konolige, K.; Burgard, W. NARF: 3D Range Image Features for Object Recognition. In Proceedings of the Workshop on Defining and Solving Realistic Perception Problems in Personal Robotics at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 8 October 2010. [Google Scholar]
- Johnson, A. Spin-Images: A Representation for 3-D Surface Matching. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 1997. [Google Scholar]
- Salti, S.; Tombari, F.; di Stefano, L. SHOT: Unique signatures of histograms for surface and texture description. Comput. Vis. Image Understand. 2014, 125, 251–264. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D Registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; IEEE Press: Piscataway, NJ, USA, 2009; pp. 1848–1853. [Google Scholar]
- Rusu, R.B.; Bradski, G.R.; Thibaux, R.; Hsu, J.M. Fast 3D recognition and pose using the Viewpoint Feature Histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- He, L.; Wang, X.; Zhang, H. M2DP: A novel 3D point cloud descriptor and its application in loop closure detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 231–237. [Google Scholar]
- Dewan, A.; Caselitz, T.; Burgard, W. Learning a Local Feature Descriptor for 3D LiDAR Scans. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yin, H.; Ding, X.; Tang, L.; Wang, Y.; Xiong, R. Efficient 3D LIDAR based loop closing using deep neural network. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics (ROBIO), Macau, China, 5–8 December 2017; pp. 481–486. [Google Scholar] [CrossRef]
- Yin, H.; Wang, Y.; Tang, L.; Ding, X.; Xiong, R. LocNet: Global localization in 3D point clouds for mobile robots. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Fernández-Moral, E.; Mayol-Cuevas, W.W.; Arévalo, V.; Jiménez, J.G. Fast place recognition with plane-based maps. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2719–2724. [Google Scholar]
- Dubé, R.; Dugas, D.; Stumm, E.; Nieto, J.I.; Siegwart, R.; Cadena, C. SegMatch: Segment based loop-closure for 3D point clouds. arXiv, 2016; arXiv:1609.07720. [Google Scholar]
- Zhu, Z.; Yang, S.; Dai, H.; Li, F. Loop Detection and Correction of 3D Laser-Based SLAM with Visual Information. In Proceedings of the CASA 2018 31st International Conference on Computer Animation and Social Agents, Beijing, China, 21–23 May 2018; ACM: New York, NY, USA; pp. 53–58. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Non-linear Constraint Network Optimization for Efficient Map Learning. IEEE Tran. Intell. Transp. Syst. 2009, 10, 428–439. [Google Scholar] [CrossRef]
- Lu, F.; Milios, E. Globally Consistent Range Scan Alignment for Environment Mapping. Auton. Robots 1997, 4, 333–349. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-Time Loop Closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Sprickerhof, J.; Nüchter, P.A.; Lingemann, K.; Hertzberg, P.J. A Heuristic Loop Closing Technique for Large-Scale 6D SLAM. Automatika 2011, 52, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Droeschel, D.; Behnke, S. Efficient Continuous-Time SLAM for 3D Lidar-Based Online Mapping. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–9. [Google Scholar]
- Vlaminck, M.; Luong, H.; Goeman, W.; Philips, W. 3D Scene Reconstruction Using Omnidirectional Vision and LiDAR: A Hybrid Approach. Sensors 2016, 16, 1923. [Google Scholar] [CrossRef]
- Vlaminck, M.; Luong, H.; Philips, W. Liborg: A lidar-based robot for efficient 3D mapping. In Proceedings of the Applications of Digital Image Processing XL, San Diego, CA, USA, 19 September 2017; Volume 10396. [Google Scholar]
- Mellado, N.; Aiger, D.; Mitra, N.J. SUPER 4PCS: Fast Global Pointcloud Registration via Smart Indexing. Comput. Graph. Forum 2014, 33, 205–215. [Google Scholar] [CrossRef]
- Goossens, B.; De Vylder, J.; Philips, W. Quasar: A new heterogeneous programming framework for image and video processing algorithms on CPU and GPU. In Proceedings of the IEEE International Conference on Image Processing ICIP, Paris, France, 27–30 October 2014; pp. 2183–2185. [Google Scholar]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4pointss Congruent Sets for Robust Pairwise Surface Registration. In Proceedings of the SIGGRAPH ’08 ACM SIGGRAPH 2008 Papers, Los Angeles, CA, USA, 11–15 August 2018; ACM: New York, NY, USA; pp. 85:1–85:10. [Google Scholar] [CrossRef]
- Shoemake, K. Animating Rotation with Quaternion Curves. SIGGRAPH Comput. Graph. 1985, 19, 245–254. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 3354–3361. [Google Scholar]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3D object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Phuket, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | avg. | Matlab ([10]) in ms | GPU (ours) in ms |
|---|---|---|---|
| VLP-16 | 25,446 | 250 | 110 |
| HDL-32E | 51,687 | 273 | 121 |
| HDL-64E | 62,594 | 476 | 127 |
| Dataset | Sensor | Time (ms) Ours | Time (ms) [26] | Num. Samples in [26] | |
|---|---|---|---|---|---|
| Kitti | Velodyne HDL-64E | 0.5 | 184 | 875 | 2000 |
| Ghent | Velodyne VLP-16 | 0.5 | 159 | 415 | 2000 |
| Sequence | Spin Image | SHOT | ESF | M2DP | Ours |
|---|---|---|---|---|---|
| KITTI00 | 0.025 | 0.575 | 0.143 | 0.597 | 0.605 |
| KITTI05 | <0.01 | 0.632 | 0.037 | 0.833 | 0.904 |
| Sequence | Total Length (m) | Average Error (m) | Median Error (m) | ||||
|---|---|---|---|---|---|---|---|
| before LC | after LC | gain | before LC | after LC | gain | ||
| HASSELT | 715 | 5.65 | 3.13 | ×1.81 | 3.98 | 2.13 | ×1.87 |
| KITTI09 | 1705 | 9.89 | 4.80 | ×2.06 | 7.85 | 3.53 | ×2.22 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlaminck, M.; Luong, H.; Philips, W. Have I Seen This Place Before? A Fast and Robust Loop Detection and Correction Method for 3D Lidar SLAM. Sensors 2019, 19, 23. https://doi.org/10.3390/s19010023
Vlaminck M, Luong H, Philips W. Have I Seen This Place Before? A Fast and Robust Loop Detection and Correction Method for 3D Lidar SLAM. Sensors. 2019; 19(1):23. https://doi.org/10.3390/s19010023
Chicago/Turabian StyleVlaminck, Michiel, Hiep Luong, and Wilfried Philips. 2019. "Have I Seen This Place Before? A Fast and Robust Loop Detection and Correction Method for 3D Lidar SLAM" Sensors 19, no. 1: 23. https://doi.org/10.3390/s19010023
APA StyleVlaminck, M., Luong, H., & Philips, W. (2019). Have I Seen This Place Before? A Fast and Robust Loop Detection and Correction Method for 3D Lidar SLAM. Sensors, 19(1), 23. https://doi.org/10.3390/s19010023