1. Introduction
Rolling element bearings have wide applications in industrial machines and are one of the most critical components. If faults occur in bearings, equipment could be damaged and disasters might happen consequently. Therefore, it is essential to monitor the health conditions of bearings. The analysis of vibration signals has been a hot research pot and used to detect faults of bearings. It is crucial to recognize faults occurring in bearings and avoid fatal breakdowns as early as possible. For decades, many researchers have conducted extensive research on fault diagnosis. At present, the fault diagnosis methods are divided into model-based methods and data-driven methods. The model-based methods generally build on the physics of the process, generating the residuals between the measure process variables and estimates [
1], such as Hidden Markov Modeling (HMM) which is successfully applied to bearing fault detection and diagnosis [
2]. Autoregressive modelling [
3] also has had excellent performance in bearing fault diagnosis. The accelerated degradation testing (ADT) [
4] method is useful in fault diagnosis and lifespan prediction, and reference [
5] presents a new approach using observer-based residual generation with no complicated design constraints to establish the relationship between the state estimation error and the fault signal. For the data-driven method, which is based on the historical data and does not need accurate mathematic and priori knowledge, it has wide applications in fault diagnosis. For example, Bayesian network is an excellent data-driven diagnosis method [
6,
7,
8]. Machine learning algorithms, such as K-nearest Neighbor (KNN), Deep Convolutional Neural Networks (DCNN), and auto-encoders are effective in the fault diagnosis of various bearings [
9,
10,
11,
12]. There is also decision tree [
13], Support Vector Machine (SVM) [
14], and wavelet transform [
15]. Artificial neural network (ANN) and Trace Ratio Linear Discriminant Analysis are other methods of diagnosing the bearings fault [
16,
17]. In addition, the vibration signal under the various operating conditions (especially in low rotational speed) is non-stationary and non-linear, the characteristic defect frequencies move continuously with the change of rotating speed, and is the same as the bearing that is going to break down. If the bearing progresses toward failure, the nonlinear features also start to be dominated by stochastic signal. With the vibration signal measured for diagnosing the bearing fault under variable condition, it will be difficult to diagnose the fault of bearing by using the traditional methods. Reference [
18] proposed a signal selection scheme based upon two order tracking techniques from complicated non-stationary operational measured vibrations. Reference [
19] reviewed features extraction methods and its application on bearing vibration signal and presents an empirical study of feature extraction methods in low rotational speed. Reference [
20] proposes the estimation of instantaneous speed relative fluctuation (ISRF) in a vibration speed. Reference [
21] proposes Stacked Convolutional Autoencoders (SCAE) together with DCNN in stationary and non-stationary speed operation. Graph-based rebalance semi-supervised learning (GRSSL) [
22], weighted self-adaptive evolutionary extreme learning machine (WSaE-ELM) [
23] and Singular Spectrum Analysis [
24] are effective in diagnosing the fault under variable conditions.
However, although the aforementioned methods are effective for bearing faults diagnosis, the feature selection part is often non-adaptive or unexplainable. The conventional methods mainly extract and select features manually, which relies heavily on the experts’ knowledge and experience. Since the signals acquired in the real world might be various in many different aspects, the features selected manually might be sensitive in the variations of operation conditions and import inevitable errors for fault diagnosis. The deep learning algorithms can extract features automatically and overcome this drawback. However, deep learnings are data-hungry and require plenty of training data which are hardly acquired in practice, especially the faulty data under different conditions. Besides, the features acquired by deep learnings are unexplainable. Therefore, the aforementioned methods can hardly diagnose the faults under various operation conditions in practice. In contrast, the Mahalanobis Taguchi System (MTS) is more robust than the other methods in various operating conditions [
25].
MTS offers a tool to determine important features and optimize the system. It is a different form compared with the other classification methods, because this classification model of measurement scale is constructed by using the class samples. It is useful to diagnose bearing faults under various conditions because the different pattern could be identified by using the Mahalanobis distance (MD) and Taguchi method. In this paper, MD is used to calculate the distance of the correlations between the benchmark and others, and the distance could be measured without the volatility of data. The advantage of MD is that it takes into consideration the correlations between the features and this consideration is very important in pattern analysis, which is why MTS is suitable for bearing fault diagnosis under various conditions [
26]. On the other hand, the Taguchi method is used to select features without manual intervention, which could improve the robustness of the algorithm. MTS also offers an effective tool for multivariate analysis [
27], considering that the bearing faults can be classified according to locations, such as inner race, outer race and rolling element [
28]. However, when the conventional MTS is used for bearing fault diagnosis, misclassifications might occur due to less adaptivity of the threshold configuration for signal-to-noise gain. During the feature selection, the threshold is normally set as a constant, which might result in the overfitting problem. If the threshold value is too large, some critical features might be eliminated. On the contrary, if the threshold value is too low, some useless or harmful feature might be selected. Therefore, if the threshold value does not march the training data sufficiently, misclassifications emerge.
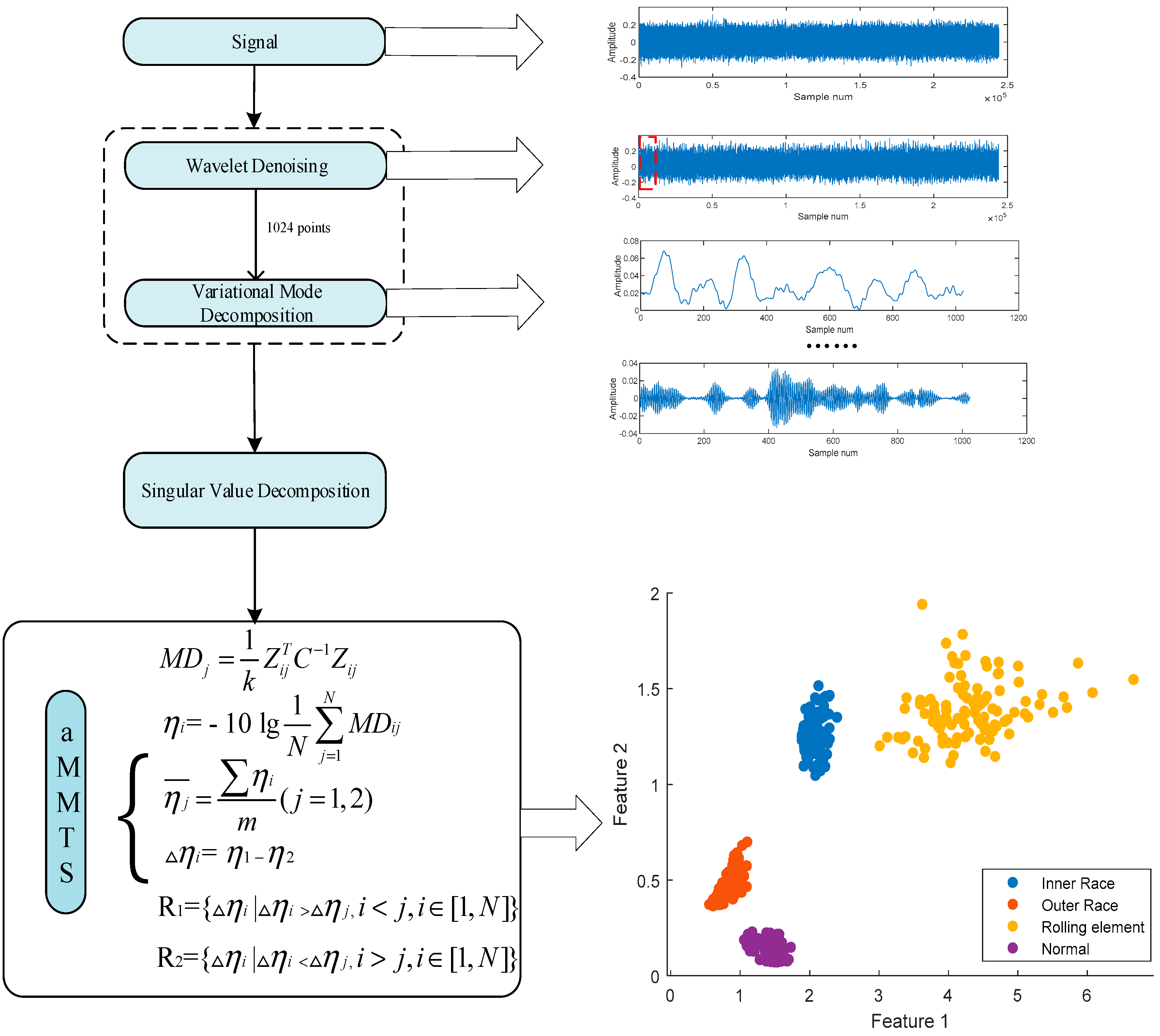
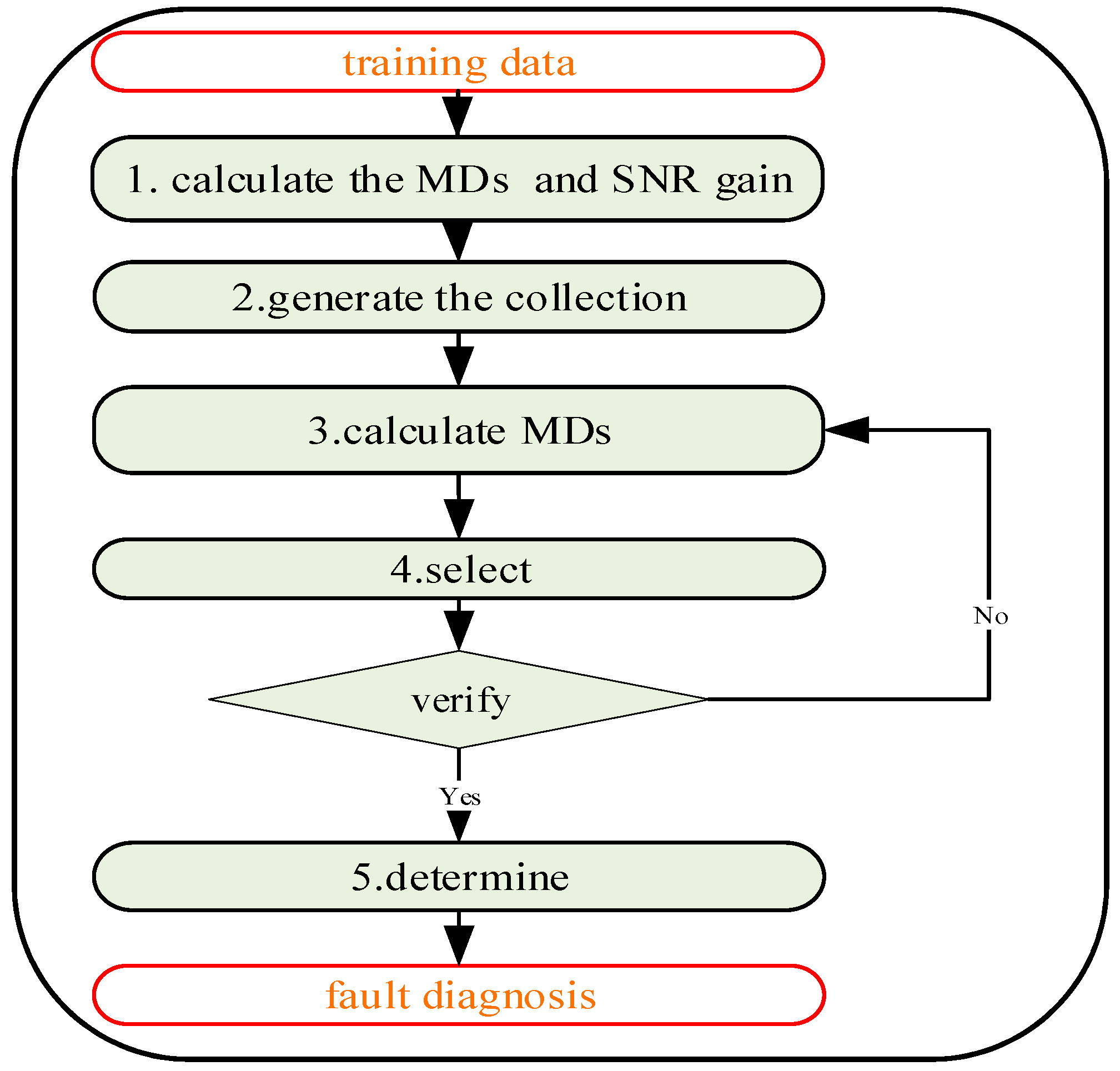
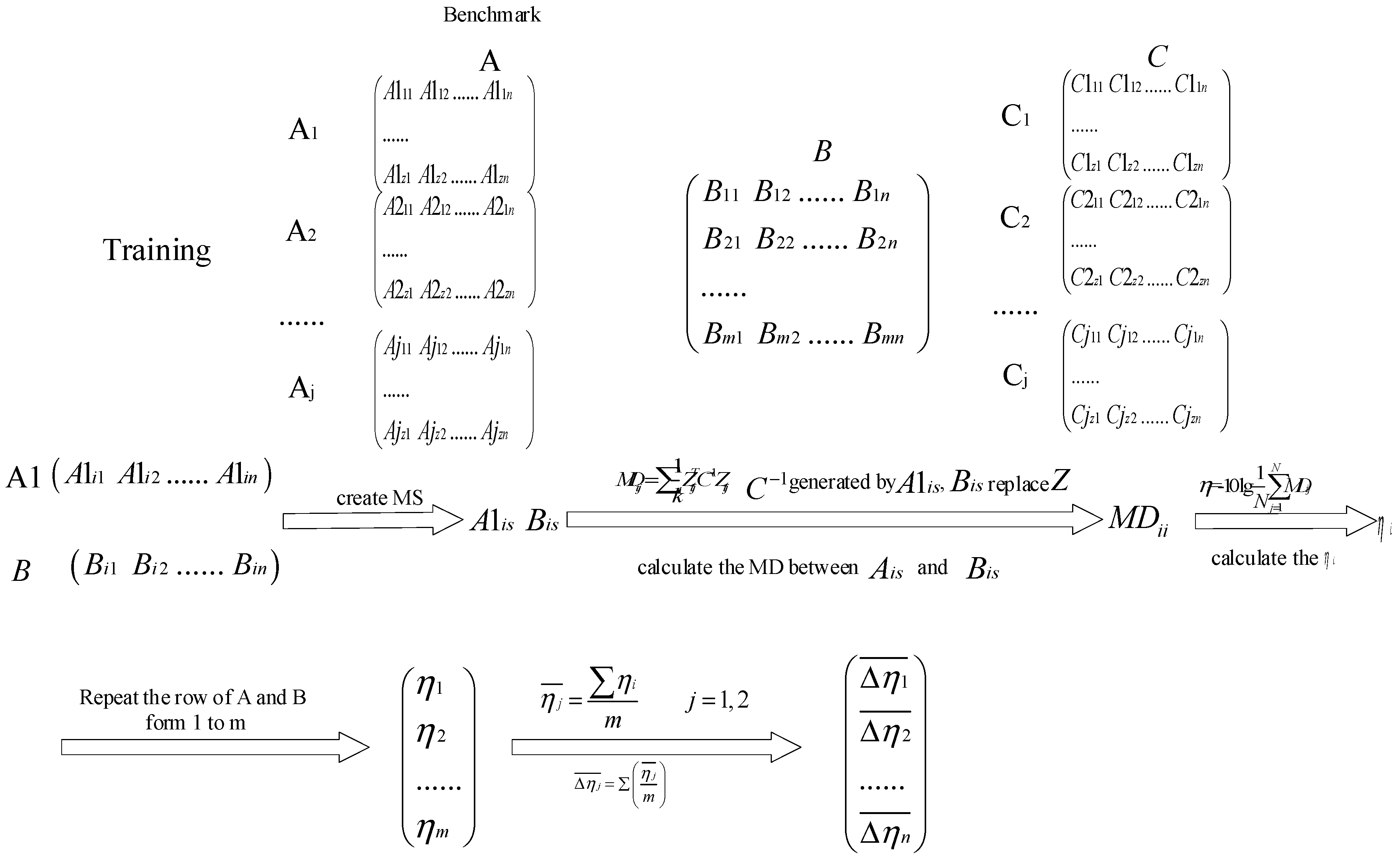
To overcome this drawback, this paper presents a novel method named adaptive Multiclass Mahalanobis Taguchi system (aMMTS) for bearing fault diagnosis. This method employs the MTS for multi-classification by considering different conditions as different benchmarks respectively. The results are based on the minimum MDs between the data and each benchmark data, and the label of the data is determined to be consistent with the label of the benchmark data whose MD is minimum. The method can be described briefly as follows: Firstly, after the Mahalanobis space (MS) is constructed by the two-level orthogonal array of the Taguchi method, aMMTS calculates the MDs from the data to the benchmark data and obtains features’ signal-to-noise ratios (SNRs) and gain values by using two-level orthogonal array. Secondly, the features are selected adaptively by recalculating the MDs via rearranging the order of features’ gain values by ascending and descending. Therefore, the proposed method is able to select the best classification result according to the adaptive chosen sequence of features’ SNRs instead of a hard threshold. Here, the sequence of SNR is determined by a function, which selects several maximum or minimum features to calculated MDs. Finally, a set of features with the best results is selected as the final feature vector. In this method, two different sets of training samples are employed to calculate the SNRs respectively and obtain the final feature vectors respectively. By the aforementioned improvement, the proposed aMMTS is capable to overcome the drawback of the conventional MTS and prevent the over-fitting problem. Therefore, the aMMTS is insensitive to the operation conditions and can be employed for bearing fault diagnosis.
Moreover, this method is combined with variational mode decomposition (VMD) [
29] and singular value decomposition (SVD) to diagnose the faults. VMD is an entirely non-recursive algorithm, and is used to decompose the signal. It has been proven that due to the characteristics of nonlinear vibration in the bearings, VMD is more efficient than empirical mode decomposition (EMD) and Fourier transform (FT) under variable condition. SVD is used to extract the features. Therefore, VMD and SVD are employed in this paper.
The rest of this article is organized as follows:
Section 2 introduces the algorithms involved in this paper.
Section 3 illustrates the experiments to validate the proposed method.
Section 4 is the conclusions.
3. Results
In this paper, the experimental data are from Case Western Reserve University Bearing Data Center. This experiment involved three different faults that occurred on three components: inner race, outer race and rolling element. The vibration signals were acquired under four different speeds: 1797 r/min, 1772 r/min, 1750 r/min, and 1730 r/min, and the sampling frequency was set to 12 kHz. To demonstrate the aMMTS, this study randomly selected the data in the dataset under the defect of 0.07 inches. The number of samples are shown in
Table 1.
There were 2192 samples; 548 for inner race, 548 for outer race, 548 for rolling element and 548 for normal. The data are divided into three parts: training data, validation data and test data. In order to avoid the overfitting caused by the training data, training samples were used to construct MS, generate the SNR gain and calculate MDs by using the sequences of SNR gains, and were divided into three parts, with one of the parts set as benchmark group. To avoid the over-fitting problem, group A was used to construct MS and generate the SNR gain, and group B were used to calculate the MDs with the sequences of SNR gain and identify faults.
Validation samples were used to verify the recognition result if there exists the same minimum MDs, and the sequence was selected according to the best result.
Test samples were used to validate the proposed method.
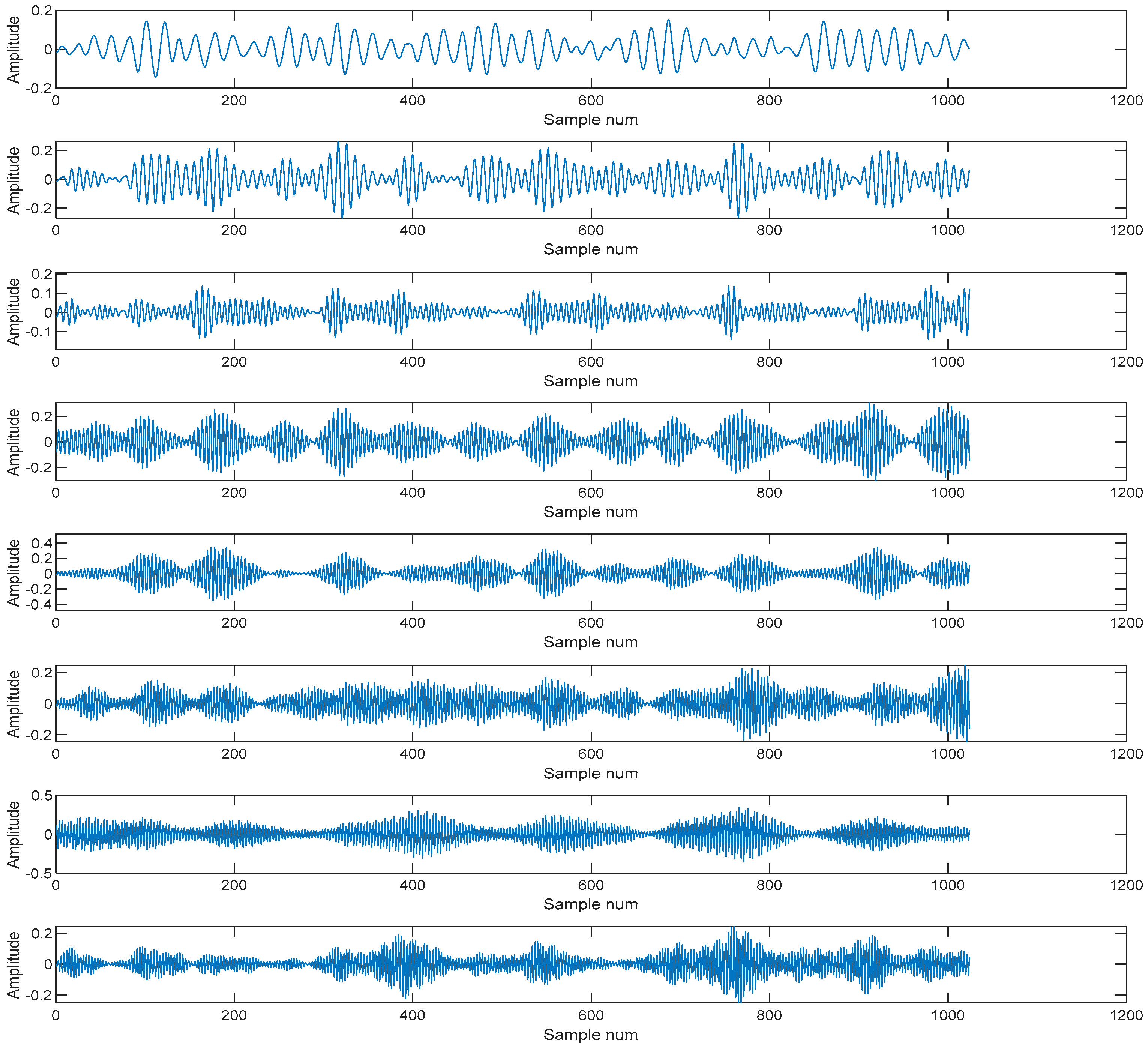
3.1. Signal Decomposition by Using VMD and Wavelet Denosing
Above all, this study employed wavelet denoising to remove the noise from the raw signals. First, the Daubechies 5 (db5) was used to decompose the signal, and obtained the wavelet decomposition vector and the bookkeeping vector. Second, thresholds wavelet coefficient was calculated by setting the detail vector which would be compressed as [
1,
2,
3] and the vector which is the corresponding percentages of lower coefficients as [100,90,80], and using the wavelet decomposition vector and the bookkeeping vector. Lastly, the thresholds, Daubechies 5 (db5) and decomposed signals were used to reconstruct the denoising signal. Then the VMD was used to decompose the signal, and was needed to give the preset IMF component number
K and penalty parameter
α which constrained the moderate bandwidth. The value of
α toke the default value 1024, the value of
K was 8. An example is shown in
Figure 7.
3.2. Feature Extraction by Using SVD
SVD was used to analyze the IMFs. After the signal decomposition, the IMF matrix was decomposed by SVD, and obtained singular value vectors. The singular value vectors were considered as features and formed the feature matrix. Then, the feature matrix was used to diagnose the fault by aMMTS. To avoid the over-fitting problem, the features were divided into training samples, validation samples and test samples. The features of the above IMFs of those were shown in
Table 2.
The features obtained by SVD are shown in
Table 3.
3.3. Fault Diagnosis Using aMMTS
After the feature extraction, the aMMTS was used to identify and diagnose fault modes. The steps of aMMTS are as follow:
Firstly, the MS of training and benchmark were constructed, the eight-factor and two-level orthogonal array is shown in
Table 4, and the MS based on
Table 2 is shown in
Table 5;
Secondly, the MD was calculated, and SNR gain was also obtained by benchmark samples and training samples. The SNR gain is shown in
Table 6;
Thirdly, the MDs between the benchmark samples and validation samples were calculated by using the ascending and descending order of SNR;
Fourthly, the validation samples were used to verify the correctness of feature selection which existed more than one smallest MD;
Fifthly, the best sequence was chosen and set as the sequence of features.
Lastly, the best sequence was used to identify the test samples. Took the benchmark is outer race as the example shown in
Figure 9.
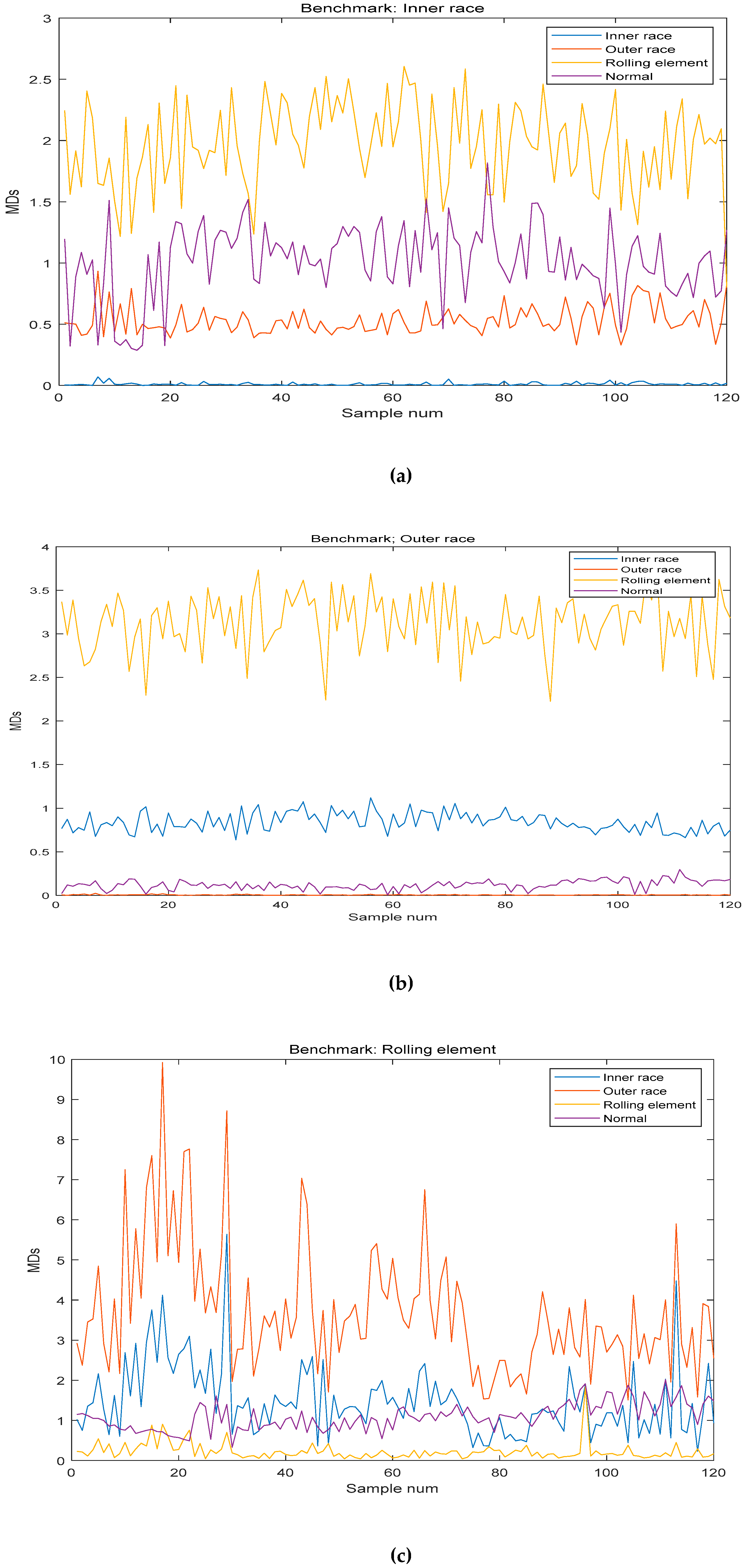
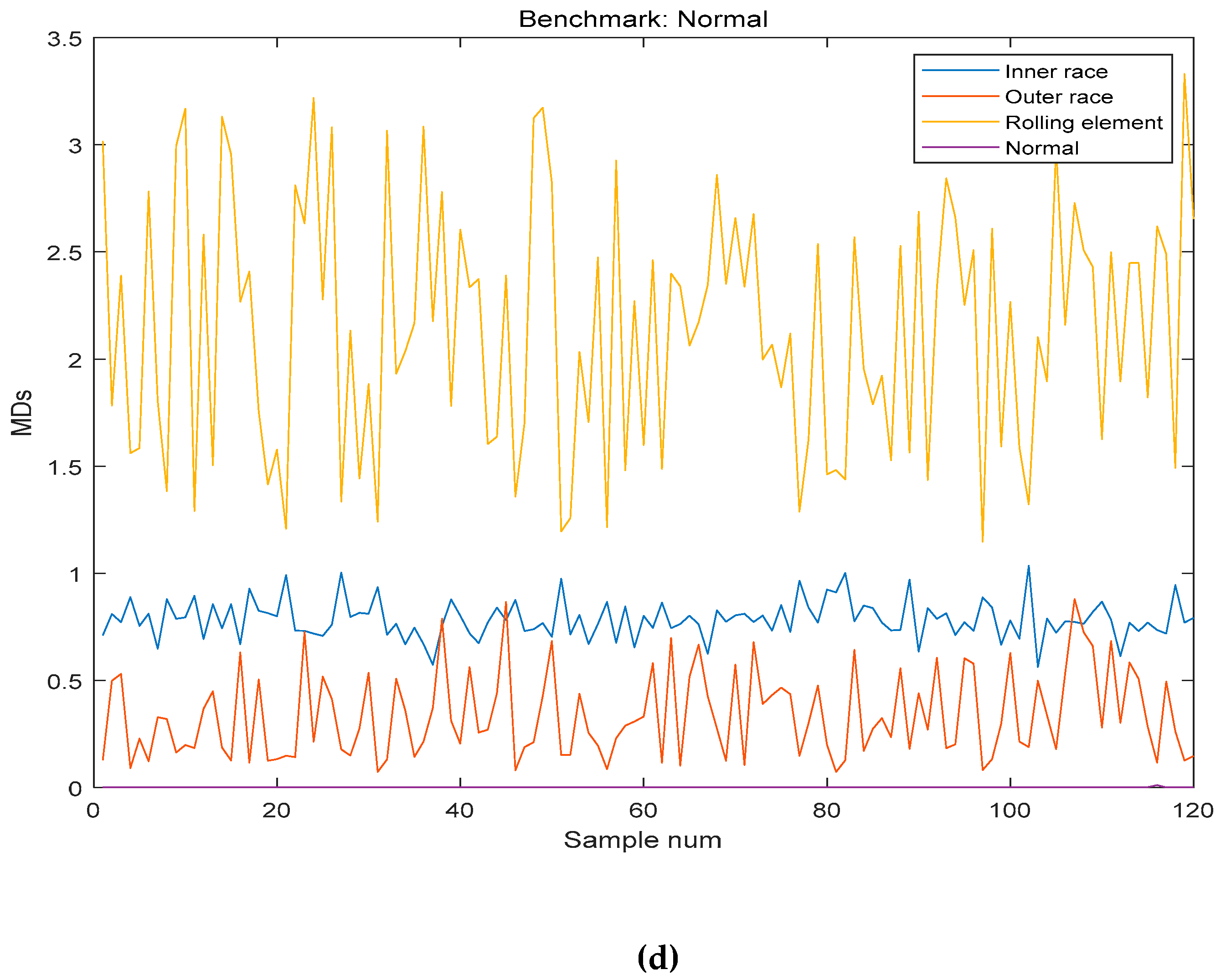
Finally, the test sample was used to test the result of the method, and the benchmarks were inner race, rolling element, outer race and normal. The results are shown in
Table 7 and the MDs between benchmark and test sample are shown in
Figure 10.
As shown in
Table 7 and
Figure 10, this method accurately classified and diagnosed the fault of the bearing by using the different benchmarks. The recognition results of normal and outer race reached 100%. However, it is not accurate enough to diagnose the fault of inner race and rolling element. However, in the normal and the fault of inner race, it is effective in industrial application.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
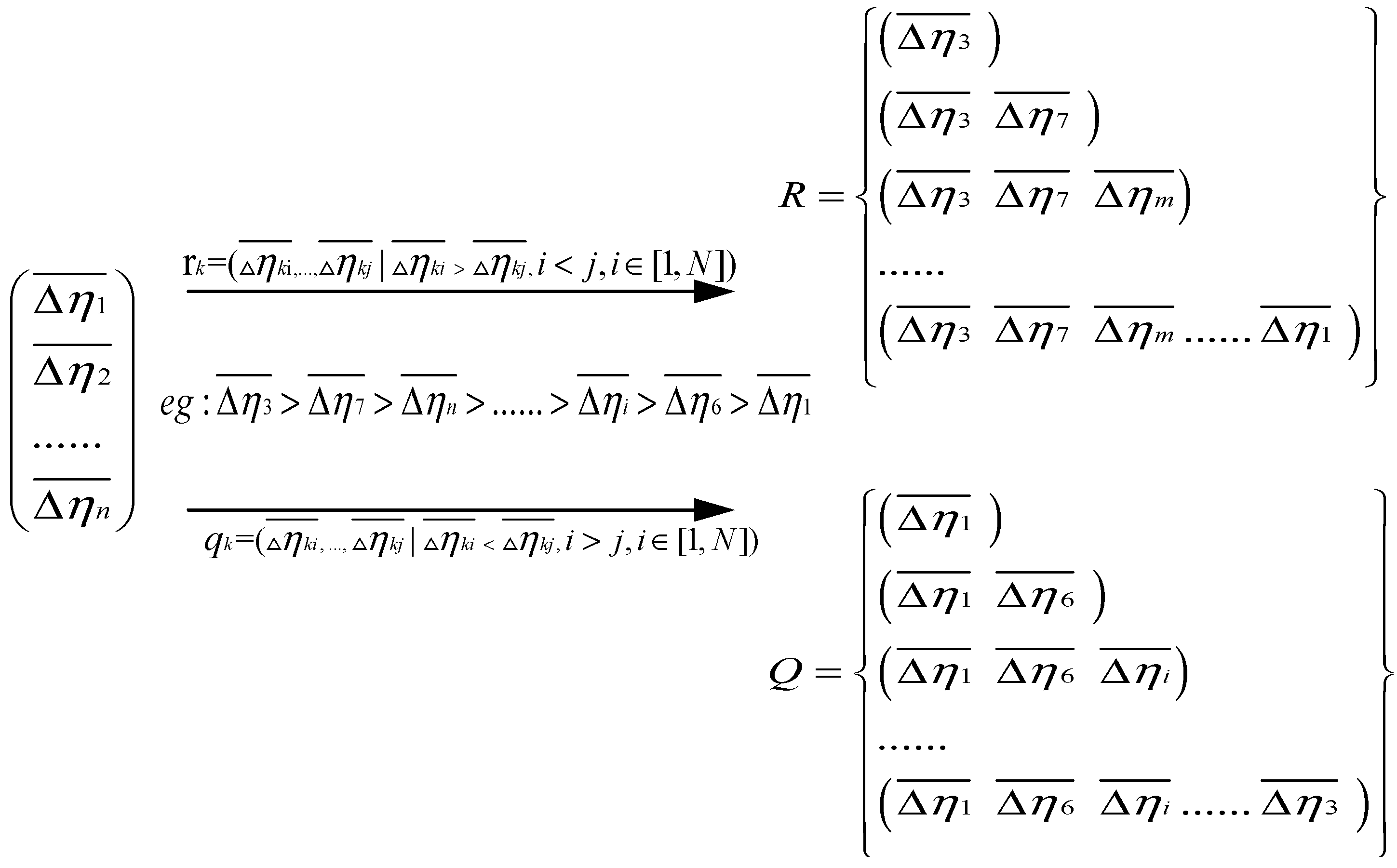{kind=link}
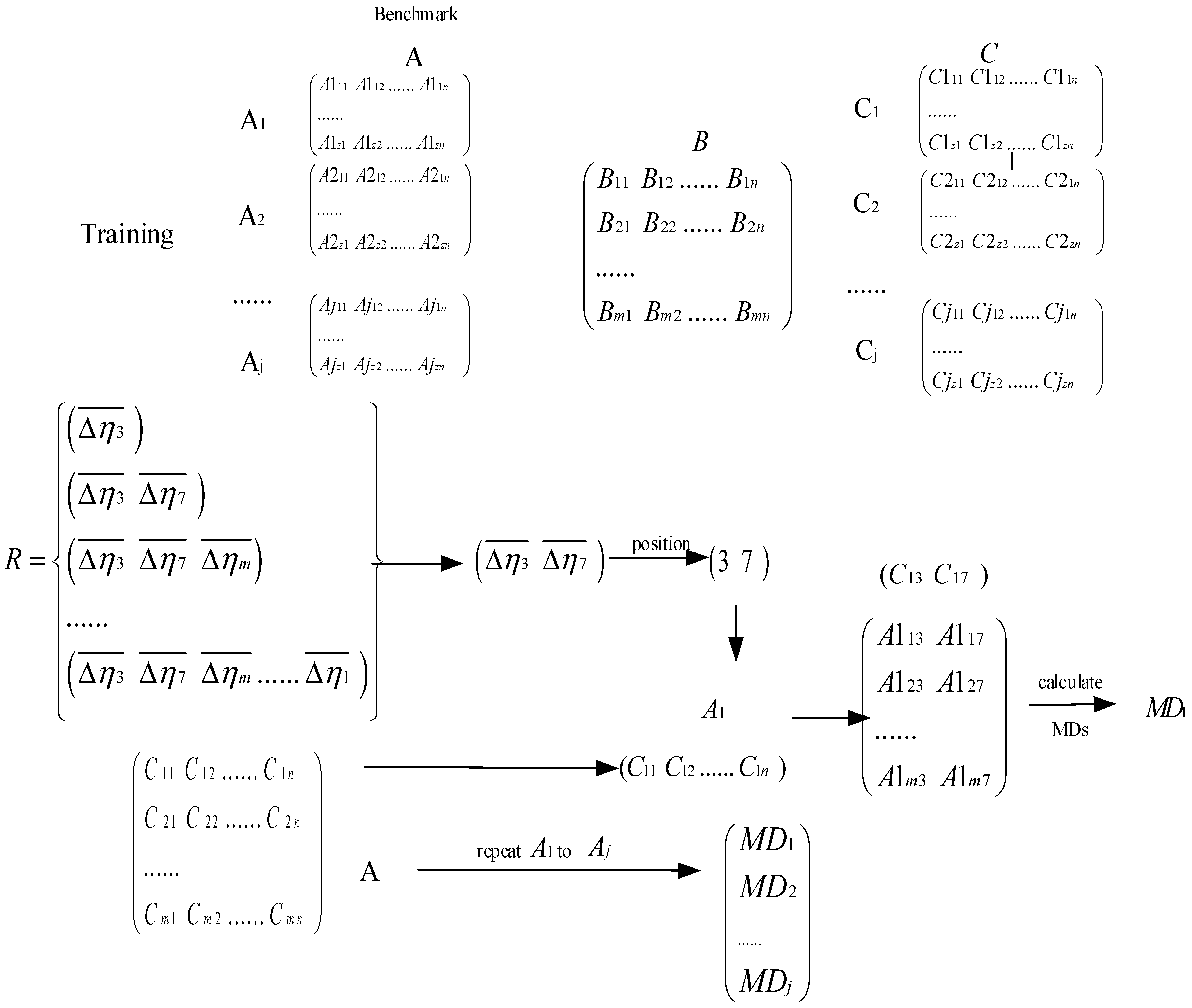{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}