1. Introduction
Estimating the directions of arrival (DOAs) of a number of far-field narrow-band source signals is an important problem in signal processing. Many DOA estimation methods were proposed early on, such as multiple signal classification (MUSIC) [
1], estimation of signal parameters via rotation invariance techniques (ESPRIT) [
2] and their variants [
3,
4]. Many of them work well when having accurate estimates of the array output covariance matrix and source number. In scenarios with sufficient array snapshots and a moderately high signal-to-noise (SNR), the array output covariance matrix and source number can be accurately estimated.
Recently, some sparse DOA estimation methods are popularly proposed based on sparse constructions of the array output model. They are applicable if the number of sources is unknown and many of them are effective when with a limited number of data snapshots. In [
5], the sparse DOA estimation methods are categorized into three groups: the on-grid, the off-grid and the grid-less. The on-grid method, which is widely studied and straightforward to implement, assumes that the true DOAs are on a predefined grid [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22]. The off-grid method also uses a prior grid but does not constrain the DOA estimates to be on this grid, while it introduces more unknown parameters to be estimated and complicates the algorithm [
23,
24,
25,
26,
27,
28]. The grid-less method directly operates in the entire direction domain without a pre-specified grid but, currently, is developed mainly for linear array and encounters rather large computational burden [
29,
30,
31]. Although the on-grid methods may induce the grid mismatch, it is still attractive due to its easy accessibility in a wide range of applications (see, e.g., [
28,
32,
33]). To alleviate the grid mismatch, methods for selecting an appropriate prior grid are proposed in [
9,
34].
During the past two decades, various on-grid sparse techniques, such as linear least-square, covariance-based and maximum-likelihood (ML) type methods, were researched. The linear least-square methods [
6,
9,
11,
12], minimizing the
-norm of the noise residual of the deterministic model, enforce the sparsity by constraining the
-norm of the signal vector for
(note that
-norm for
is defined as the same form as the one for
but is not truly a norm in mathematics). The covariance-based methods, such as the sparse iterative covariance-based estimation (SPICE) method [
13,
14] and its variants [
15,
16], and those proposed in [
17,
18,
19,
20,
21,
22], are derived from different covariance-fitting criteria and use the
-norm penalty to enforce the sparsity. The ML type methods, including the sparse Bayesian learning (SBL) methods [
7,
8,
10] and the likelihood-based estimation of sparse parameters (LIKES) method [
15,
16], are deduced under the assumption that the array output signal is multivariate Gaussian distributed. The SBL methods use different prior distributions to model the sparsity. The LIKES method appears to be not explicitly utilizing the sparsity, but provides sparse estimates.
The ML principle is generally believed to be statistically more sound than the covariance-fitting principle [
15]. The existing on-grid ML methods are developed on the Gaussian distribution assumption that are not satisfied in many signal processing practical applications. The complex elliptically symmetric (CES) distributions, containing the
t-distribution, the
K-distribution, the Gaussian distribution and so on, can be used to characterise the Gaussian and non-Gaussian random variables. Particularly, the heavy-tailed data, which usually appear in the field of radar and array signal processing [
35,
36], can be modeled by some CES distributions.
The
-norm penalty with
is well-known for its contributions in deriving sparse solutions [
37]. In particular, the convex
-norm penalty, also known as the least absolute shrinkage and selection operator (LASSO) penalty, is easy to handle and widely used in various applications. Generally, a sparse and accurate estimate of the unknown sparse parameter can be expected when minimizing the negative likelihood plus an
-norm penalty.
For estimating the DOAs from the CES distributed array outputs, we provide an -norm penalized ML method based on a sparse reconstruction of the array output covariance matrix. The characteristics and advantages of our method are explained as follows:
Our method is a sparse on-grid method based on the penalized ML principle, and is designed especially for the CES random output signals. The Gaussian distribution and many heavy-tailed and light-tailed distributions are included in the class of the CES distributions, and it is worth mentioning that the heavy-tailed output signals that are non-Gaussian are common in the field of signal processing [
35,
36].
The sparsity of the unknown sparse vector is enforced by penalizing its -norm. When the penalty parameter becomes zero, the proposed method is actually the general ML DOA estimation method that is applicable to the scenarios with CES random output signals.
Two penalized ML optimization problems are formulated for spatially uniform and non-uniform white sensor noise, respectively. Since it is difficult to solve the two non-convex penalized ML optimizations globally, two majorization-minimization (MM) algorithms having different iterative procedures are developed for seeking the optimal solutions locally for each of them. Some discussions on the computational complexities of the above two algorithms are provided. In addition, the optimal penalty parameter is suggested.
The proposed methods are evaluated numerically in scenarios with Gaussian and non-Gaussian output signals. Particularly, the performance gains originated from the added -norm penalty are numerically demonstrated.
The remainder of this paper is organized as follows.
Section 2 introduces a sparse CES data model of the array output. In
Section 3, a sparse penalized ML method is developed to estimate the DOAs. For solving the proposed
-penalized ML optimizations that are non-convex, algorithms in the MM framework are developed in
Section 4.
Section 5 numerically shows the performance of our method in Gaussian and non-Gaussian scenarios. Finally, some conclusions are given in
Section 6.
Notations
The notation denotes the set of all m-dimensional complex- (real-) valued vectors, and denotes the set of all complex- (real-) valued matrices. and are the p-dimensional vectors with all elements equal to 1 and 0, respectively. is the identity matrix. and denote the -norm and -norm of a vector, respectively. The superscripts and , respectively, denote the transpose and the conjugate transpose of a vector or matrix. The imaginary unit is denoted as ı defined by .
For a vector , define element-wise square root function and element-wise division operation for a vector with non-zero elements. , for , means for , denotes the stacked vector of the column vectors and . denotes a square diagonal matrix with the elements of vector on the main diagonal, and denotes the diagonal matrix with main diagonal elements by taking .
For a square matrix , denotes the th entry of , means that is Hermitian and positive definite (semidefinite), denotes the trace of , and denotes a column vector of the main diagonal elements of .
2. Problem Formulation
Consider the problem of estimating the DOAs of narrow-band signals impinging on an array of m sensors.
Given a set of grid points
we assume that the true
(
) DOAs, respectively, denoted as
, take values in it. The array output measurement at the instant
t, denoted as
, can be modeled as
where
,
is the known array manifold matrix with being the steering vector corresponding to , ;
is the source signal vector at the time instant t, in which is the unknown random signal from a possible source at and then is zero if is not in the true DOA set , ;
is the noise vector impinging on the sensor array at the time instant t.
Some necessary statistical assumptions are made as follows:
The possible source signals are uncorrelated and zero-mean at any time instant t.
The noise components are uncorrelated, zero-mean, and independent of for any time instant t.
The snapshots of sensor array signals are independent and identically distributed from a CES distribution.
Note that the zero-mean assumptions above are common in the signal processing literature [
5,
35]. The CES distribution setting of the array output
enables us to effectively process the Gaussian, heavy-tailed or light-tailed array snapshots, because the class of CES distributions [
38] includes the Gaussian distribution, the
t-distribution, the
K-distribution and so on.
For the simplicity of the notations, we denote
as
and
as
for
in the following. Under the above assumptions, we can find that the array output
in Equation (
2) at any time instant
t has mean zero and covariance matrix
where
is the (unknown) source signal covariance matrix with signal power vector
, and
is the (unknown) noise covariance matrix with the noise power vector
. The matrix
can be rewritten as
For any , the signal power if is not in the set of the true DOAs. Therefore, the true DOAs can be identified by the locations of nonzero elements of the power vector . In the following, the DOA estimation problem is formulated as a problem of estimating the locations of nonzero elements of the power vector .
4. DOA Estimation Algorithms
In this section, we provide methods to solve the optimization problems in Equations (
15) and (
21) with
fixed. As Equations (
15) and (
21) are non-convex, it is generally hard to give their globally optimal solutions. Based on the MM framework [
39,
40], we develop algorithms to find the locally optimal solutions of Equations (
15) and (
21).
A function is said to be majorized by a function at , if for all x and . In the MM framework, the problem can be solved through iteratively solving .
When solving the problems in Equations (
15) and (
21) in the MM framework, majorizing functions can be constructed based on the following two inequalities. For any positive definite matrices
and
[
40],
and
where both equalities are achieved at
.
4.1. Algorithms for Spatially Non-Uniform White Noise
In this subsection, using two different majorizing functions of the objection function in Equation (
15), we develop two different MM algorithms named MM1 and MM2 to solve Equation (
15).
4.1.1. MM1 Algorithm
Denote
where
. Replacing the
and
in Equations (
22) and (
23) by
and
, respectively, we have for any
,
where
is a constant, the equality in Equation (
25) is achieved at
, and
Denote the sum of the first two terms on the right side of Equation (
26) and the
-norm penalty term in Equation (
15) as
, and then due to Equation (
12),
can be rewritten as
with
From Equation (
25),
is found to be a majorizing convex function of the objective function in Equation (
15). Based on the MM framework, the problem in Equation (
15) can be solved by iteratively solving the convex optimization problem
Proposition 1 (The MM1 algorithm for Equation (
15)).
The sequence generated bywith any initial value converges to a locally optimal solution of the optimization problem in Equation (15). Proof. Since
tends to
as
goes to the boundary of the positive semidefinite cone, the optimization problems in Equations (
30) and (
31) are equivalent.
This proposition follows by the convergence property of the MM algorithm [
40] and the fact that
with probability 1 as
tends to the boundary of the positive semidefinite cone [
41]. □
Due to Equation (
11),
required in the iteration in Equation (
31) can be the one obtained by inserting the initial estimate of
presented in [
13]. Specifically,
where
is the
ith column of the matrix
and
To solve the optimization problem in Equation (
31) globally, we develop two available solvers: the coordinate descent (CD) and SPICE-like solvers. Denote
in the following.
Proposition 2 (The CD solver for Equation (
31)).
The sequence of generated by iteratingwith any initial value converges to the globally optimal solution of the problem in Equation (31), where is the indicator function of the interval ,with being the ith element of the vector , and Proof. By the general analysis of the CD method in [
42], it is easy to find that the convex problem in Equation (
31) can be globally solved by iterating
until convergence.
Due to
and
the iteration in Equation (
39) can be reformulated as
In addition,
for
. Solving the convex optimization problems in Equation (
42) by the gradient method, we conclude that the equations in Equation (
42) are equivalent to those in Equation (
34). □
As the solver in Proposition 2 is derived by the CD method, we call it the CD solver. The MM1 algorithm in Proposition 1 with the CD solver is specially named the MM1-CD algorithm.
For clarity, detailed steps of the MM1-CD algorithm for Equation (
15) are presented in Algorithm 1.
Note that, in the CD solver, for
, we have
where
with
being the
ith column of the matrix
. The
can be interpreted as the correlation between the signal from a possible source at the grid
and the array responses
. From the indicator function
in Equation (
34), we find that it is more likely to force to zeros the powers of the assumed signals that are less correlated with the array responses.
Proposition 3 (The SPICE-like solver for Equation (
31)).
The sequence of generated by iteratingwith any initial value converges to the globally optimal solution of problem in Equation (31). | Algorithm 1 The MM1-CD algorithm for spatially non-uniform white noise. |
- 1:
Give and , - 2:
, - 3:
repeat - 4:
, - 5:
Calculate and , - 6:
, - 7:
, , - 8:
repeat - 9:
for do - 10:
, - 11:
Calculate , and , - 12:
if then - 13:
, - 14:
else - 15:
, - 16:
end if - 17:
end for - 18:
, - 19:
, - 20:
until , - 21:
, - 22:
, - 23:
until.
|
Proof. It is obvious that Equation (
31) and the SPICE criterion in [
15] are with similar forms. By the same way as the SPICE criterion is analyzed in [
15], we find that the globally optimal solution of the problem in Equation (
31) is identical to the minimizer
of the optimization problem
where
with
For a fixed
, the matrix
minimizing Equation (
46) can be verified to be [
15]
and for a fixed
, the vector
minimizing Equation (
46) can be readily given by
The sequences of
and
, generated by alternately iterating Equations (
48) and (
49) from
, converge to the globally optimal solution of the convex problem in Equation (
46) [
14,
15].
Due to
, iterating Equation (
49) is just iterating Equation (
45). Thus, the sequence of
generated by Equation (
45) converges to the minimizer
of Equation (
46). □
The solver in Proposition 3 is named the SPICE-like solver, and the MM1 algorithm in Proposition 1 with it is called the MM1-SPICE algorithm. Algorithm 2 summarily illustrates the MM1-SPICE algorithm for Equation (
15).
| Algorithm 2 The MM1-SPICE algorithm for spatially non-uniform white noise. |
- 1:
Give and , - 2:
, - 3:
repeat - 4:
, - 5:
Calculate and , - 6:
, - 7:
, - 8:
repeat - 9:
, - 10:
, - 11:
, - 12:
until , - 13:
, - 14:
, - 15:
until.
|
From Propositions 1–3, it is found that the proposed MM1 algorithm is by an inner–outer iteration loop. The MM1-CD and the MM1-SPICE algorithms are with the identical outer loop but different nested inner loops. In addition, relationship and difference between the MM1-CD and the MM1-SPICE are discussed in
Section 4.3.
4.1.2. MM2 Algorithm
When
, it is found from [
36] that, for any
,
where
From Equation (
50), we have
with the equality achieved at
. The inequality in Equation (
53) is also valid for any
due to
.
It is clear from Equation (
53) that, when
, for any
,
where the equality is achieved at
. Therefore, at any
,
majorizes the objective function in Equation (
15) for
.
Proposition 4 (The MM2 algorithm for Equation (
15)).
The sequence generated bywith any initial value converges to a locally optimal solution of the problem in Equation (15). Proof. Through the convergence analysis in [
36], we have that, although Equation (
55) is valid only when
, the sequence
generated
with any initial value
converges to a locally optimal solution of the problem in Equation (
15). It is worth mentioning that the elements of the coefficient vector
in Equation (
54) are positive. By solving the optimization problem in Equation (
57) using the gradient method, the iteration procedure in Equation (
57) is found to be exactly Equation (
56). □
The
involved in the iteration procedure in Equation (
56) can be the one given in Equation (
32). Summarily, Algorithm 3 gives the detailed steps of the MM2 algorithm for the problem in Equation (
15).
| Algorithm 3 The MM2 algorithm for spatially non-uniform white noise. |
- 1:
Give and , - 2:
, - 3:
repeat - 4:
, - 5:
Calculate and , - 6:
, - 7:
, - 8:
until.
|
4.2. DOA Estimation for Spatially Uniform White Noise
The DOA estimation in the case of spatially uniform white noise amounts to solving the optimization problem in Equation (
21). Problems in Equations (
21) and (
15) are with similar forms, but Equation (
21) involves a smaller number of unknown parameters. By the same way as the problem in Equation (
15) is analyzed in
Section 4.1, we can naturally derive the algorithms to solve Equation (
21). The algorithms for Equation (
21) are still named MM1 (including MM1-CD and MM1-SPICE) and MM2.
4.2.1. MM1 Algorithm
Proposition 5 (The MM1 algorithm for Equation (
21)).
Denotewithand then the sequence generated bywith any initial value converges to a locally optimal solution of the problem in Equation (21). To solve the optimization problem in Equation (
62), using the same method as Equation (
31) is solved, we offer two different iterative solvers for Equation (
62).
Proposition 6 (The CD solver for Equation (
62)).
The sequence of generated by iteratingwith any initial value converges to the globally optimal solution of the problem in Equation (62), wherewith being the jth element of the vector , being the jth column of the matrix and Proposition 6 introduces the nested CD inner loop of the MM1 algorithm for the problem in Equation (
21), and can be proven similar to Proposition 2.
Proposition 7 (The SPICE-like solver for Equation (
62)).
The sequence of generated by iteratingwith any initial value converges to the globally optimal solution of the problem in Equation (62). The iterative procedure in Proposition 7 above is the nested SPICE-like inner loop of the MM1 algorithm for Equation (
21), and can be proven similar to Proposition 3.
The MM procedure in Proposition 5 with the CD nested loop in Proposition 6 is the MM1-CD algorithm for Equation (
21). The MM1-SPICE algorithm for Equation (
21) is the MM procedure in Proposition 5 with the SPICE-like nested loop in Proposition 7.
4.2.2. MM2 Algorithm
Proposition 8 (The MM2 algorithm for Equation (
21)).
The sequence generated bywith any initial value converges to a locally optimal solution of the problem in Equation (21). Due to Equation (
19), by means of inserting in
the initial estimates of
and
given in [
13],
required by the iterations in Equations (
62) and (
69) can be
where
is given by Equation (
33) and
is the mean of the first
m smallest values of the set
4.3. Discussions on the MM1 and MM2 Algorithms
The following arguments are focused on the case of spatially non-uniform noise, which are also applicable to the case of spatially uniform noise.
Both the MM1 and MM2 algorithms decrease the objective function in Equation (
15) at each MM iteration and converge locally, in which the different majorizing functions are adopted. Compared to the MM2 algorithm, the MM1 algorithm has a majorizing function closer to the objective function in Equation (
15) due to Equation (
55). The computational burdens of the two algorithms are mainly caused by the matrix inversion operations.
Although the MM1-CD and MM1-SPICE algorithms have different nested inner iteration procedures, they converge to the same local solution theoretically because their outer MM iteration procedures are both Equation (
31). Each nested inner iteration of the MM1-CD algorithm, detailed by Steps 9–17 in Algorithm 1, requires
matrix inverse operations. In each nested inner iteration of the MM1-SPICE algorithm, presented by Steps 9–10 in Algorithm 2, only one matrix inverse operation is entailed.
It is somewhat interesting to find that the iteration of the MM2 algorithm (see Equation (
56)) and the nested inner iteration of the MM1-SPICE algorithm (see Equation (
45)) have similar forms. In each iteration of the MM2 algorithm, only one matrix inverse operation is needed.
4.4. Selection of Penalty Parameter
The penalty parameter
in Equations (
15) and (
21) affects the sparsity levels of the estimates of
and
. A modified Bayesian information criterion (BIC) method [
37], which is common and statistically sound, is provided here to choose an appropriate
. Let
and
be the solutions of the problems in Equations (
15) and (
21) with a fixed
, respectively, and denote
and
. The appropriate
for spatially non-uniform noise and uniform noise are
and
respectively, where
and
are the numbers of nonzero elements of the vectors
and
, respectively.
Note that the elements of and can be treated as 0 if they are smaller than some certain values respectively, e.g., and with a very small .
Notice that the
and
in Equations (
72) and (
73) are substitutes for the marginal likelihood also called as Bayesian evidence required in the BIC criterion [
43]. By the way, when modeling in the Bayesian framework, the marginal likelihood usually cannot be analytically calculated, but can be approximated by several computational methods in [
44,
45,
46].
5. Numerical Experiments
In this section, we numerically show the performance of the proposed methods. Consider a uniform linear array (ULA), and, for each
, the steering vector corresponding to the DOA
is
The array output data
are generated from the model
and both the source signals
and the observation noise
are temporally independent. The SNR is defined as
where
,
is the covariance matrix of
, and
is the covariance matrix of
. The root mean-square error (RMSE) of the DOA estimate is employed to evaluate the estimation performance, which is approximated by
Monte Carlo runs as
where
is the estimate of
in the
ith Monte Carlo run. In the following experiments, we applied the proposed methods and the SPICE [
13,
15] and LIKES methods [
15] to estimate the DOAs. Set the grid points
, and the tolerance
for convergence. All methods were coded in MATLAB and executed on a workstation with two 2.10 GHz Intel Xeon CPUs.
5.1. Experimental Settings
5.1.1. Experiment 1
Consider a scenario with Gaussian source signals and noise:
The number of sensors in the array is , and the number of snapshots is .
There are sources locating at , respectively.
The signal is zero-mean circular complex Gaussian with covariance matrix .
The noise is zero-mean circular complex Gaussian with covariance matrix .
5.1.2. Experiment 2
Consider the scenario where both the source signals and the observation noise are non-Gaussian. Let . We used the experimental settings:
The
source signals from
are, respectively, as
, where
is the angle separation between
and
, and
are independent and respectively, distributed as
where
denotes the Gamma distribution with the shape parameter
a and scale parameter
b, and
denotes the uniform distribution on the interval
. Note that the source signals
,
,
and
have constant modulus, which is common in communication applications [
13].
The observation noise
is distributed as
where
and
is zero-mean Gaussian with covariance matrix
.
5.1.3. Experiment 3
Consider a scenario with non-Gaussian source signals and non-Gaussian spatially non-uniform white noise. Let
and
. The
source signals locating at
are
,
and
with
being given by Equation (
78). The observation noise is distributed as
where
and
is zero-mean Gaussian with covariance matrix
.
5.2. Experimental Results
In Experiment 1, the MM1-CD, MM1-SPICE and MM2 algorithms with
were firstly applied.
Table 1 reports the iteration numbers
, the computational time
(in seconds), and the DOA estimation RMSEs (in degrees). Specifically,
is the number of total iterations,
is the number of iterations in the outer loop, amd
is the average of the iterations in a nested inner loop. Besides the RMSEs, each value in
Table 1 is the average of the results of 500 Monte Carlo runs. Note that, even though
in a Monte Carlo run,
is not exactly equal to
in
Table 1 because they are the average of 500 Monte Carlo runs.
As shown in
Table 1, the MM1-CD and MM1-SPICE algorithms had similar RMSEs and the MM1-CD algorithm took much more time than the MM1-SPICE algorithm. Considering that the MM1-CD and MM1-SPICE algorithms theoretically converge to the identical local solution, we believe that they will always have similar RMSEs. Moreover, the MM2 algorithm had the smallest iteration numbers, the least computational time and satisfactory RMSEs. In the following, we present the DOA estimation performance only of the MM1-SPICE and MM2 algorithms. Note that the MM1-SPICE and MM2 algorithms may converge to different local solutions, and then they are referred to as two different estimation methods hereinafter. Specifically, we compared the following six methods:
It is worth presenting that in, Experiments 1–3, the standard MUSIC algorithm was found to be almost ineffective, thus we do not illustrate it.
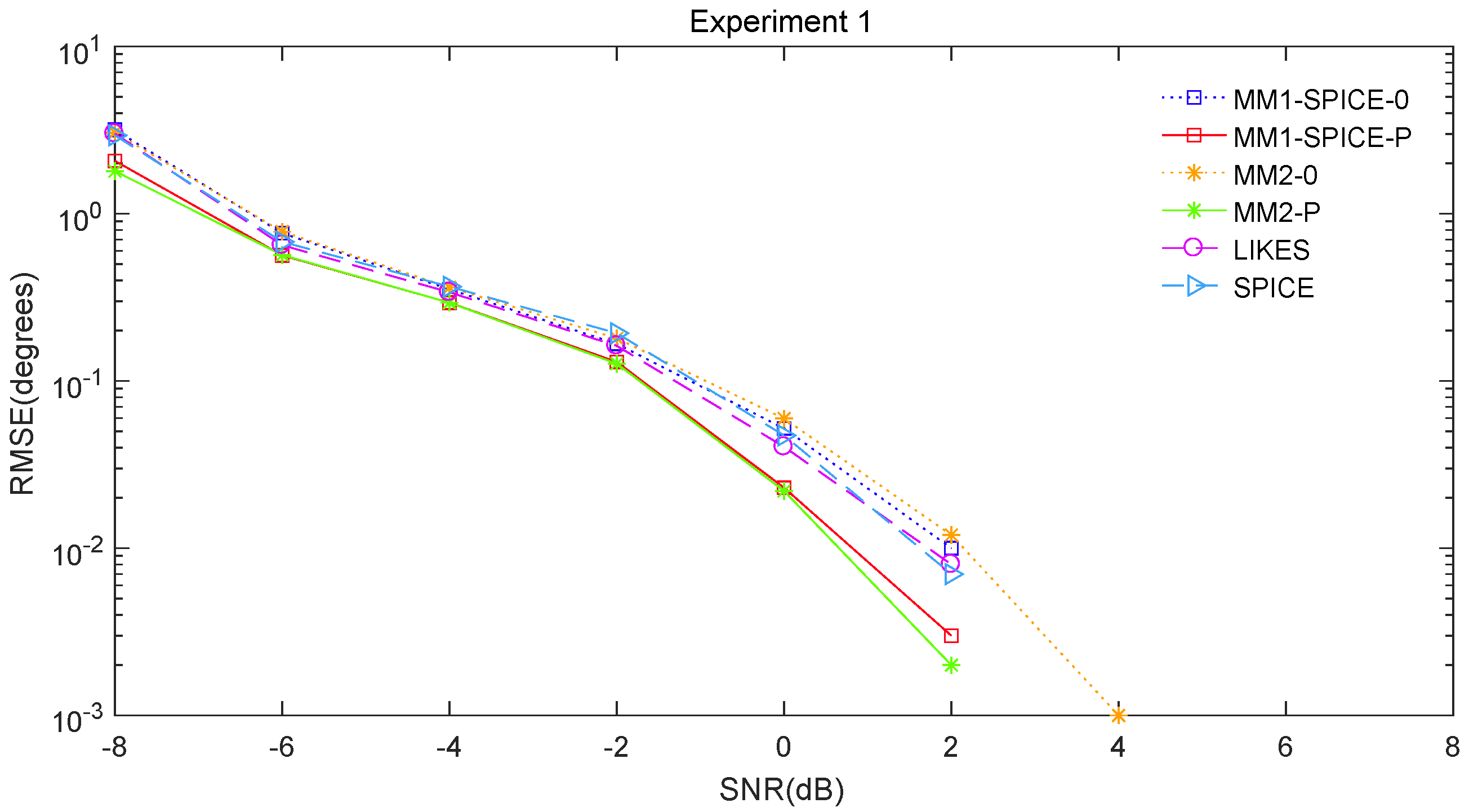
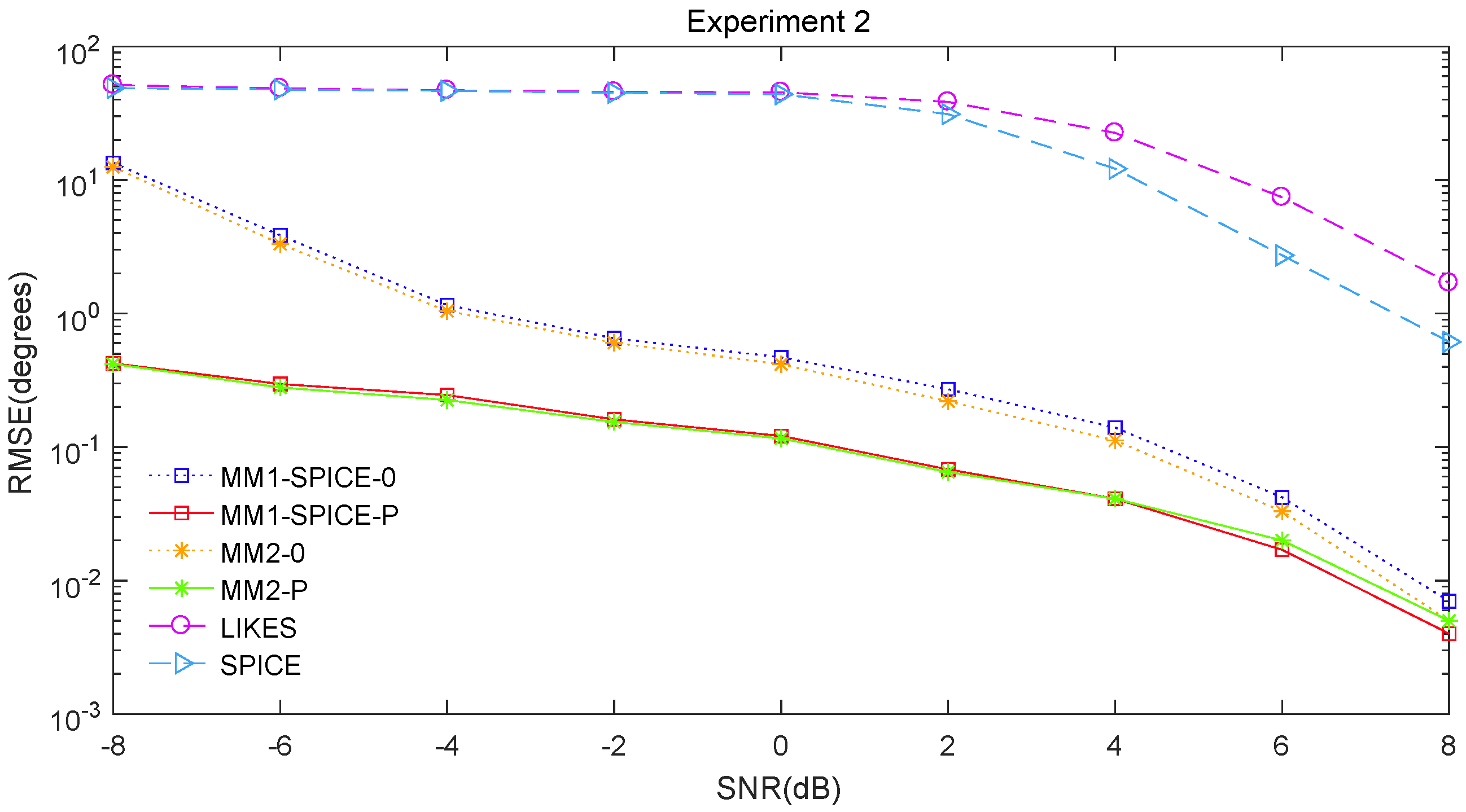
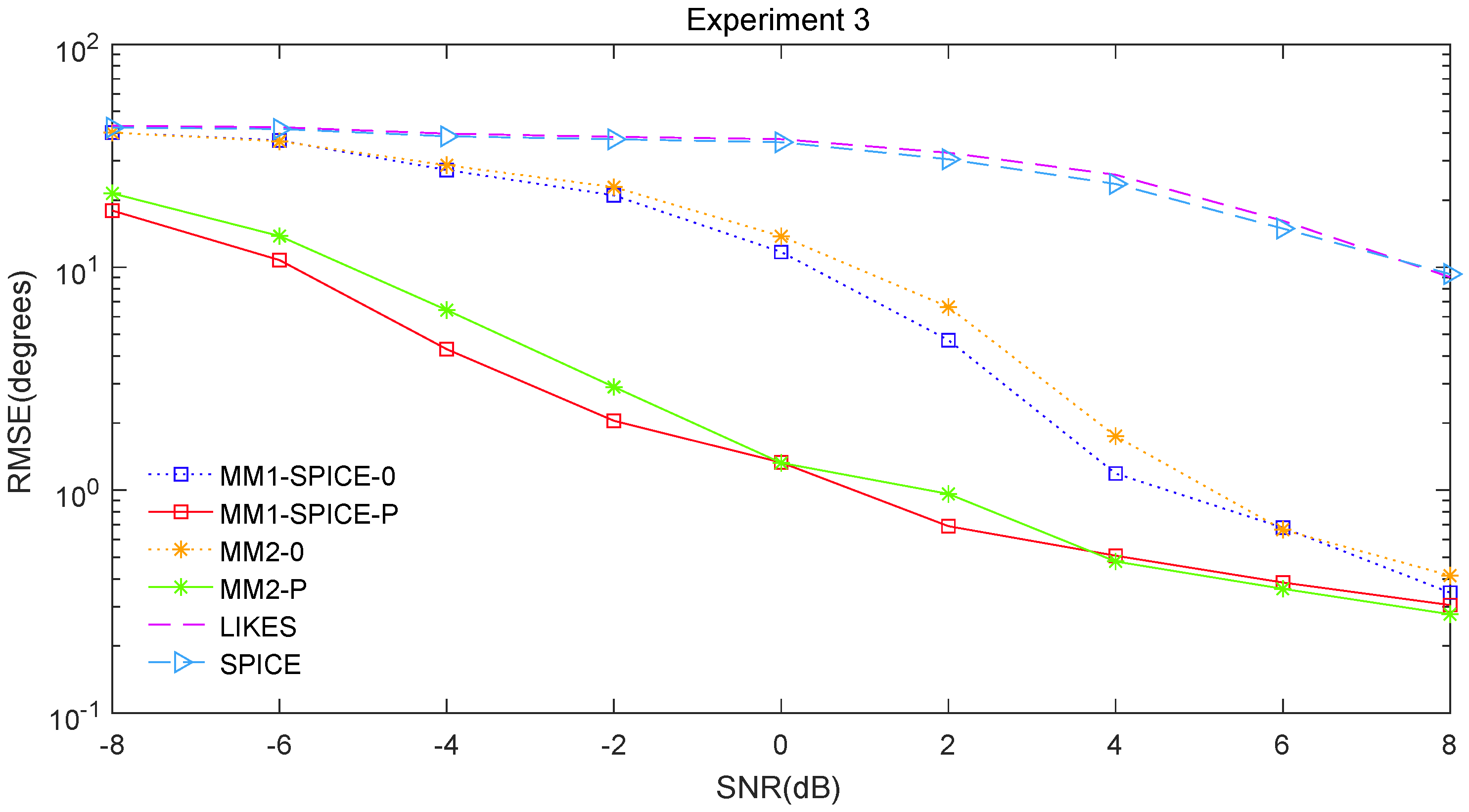
The RMSE comparisons of the above six methods are illustrated in
Figure 1,
Figure 2 and
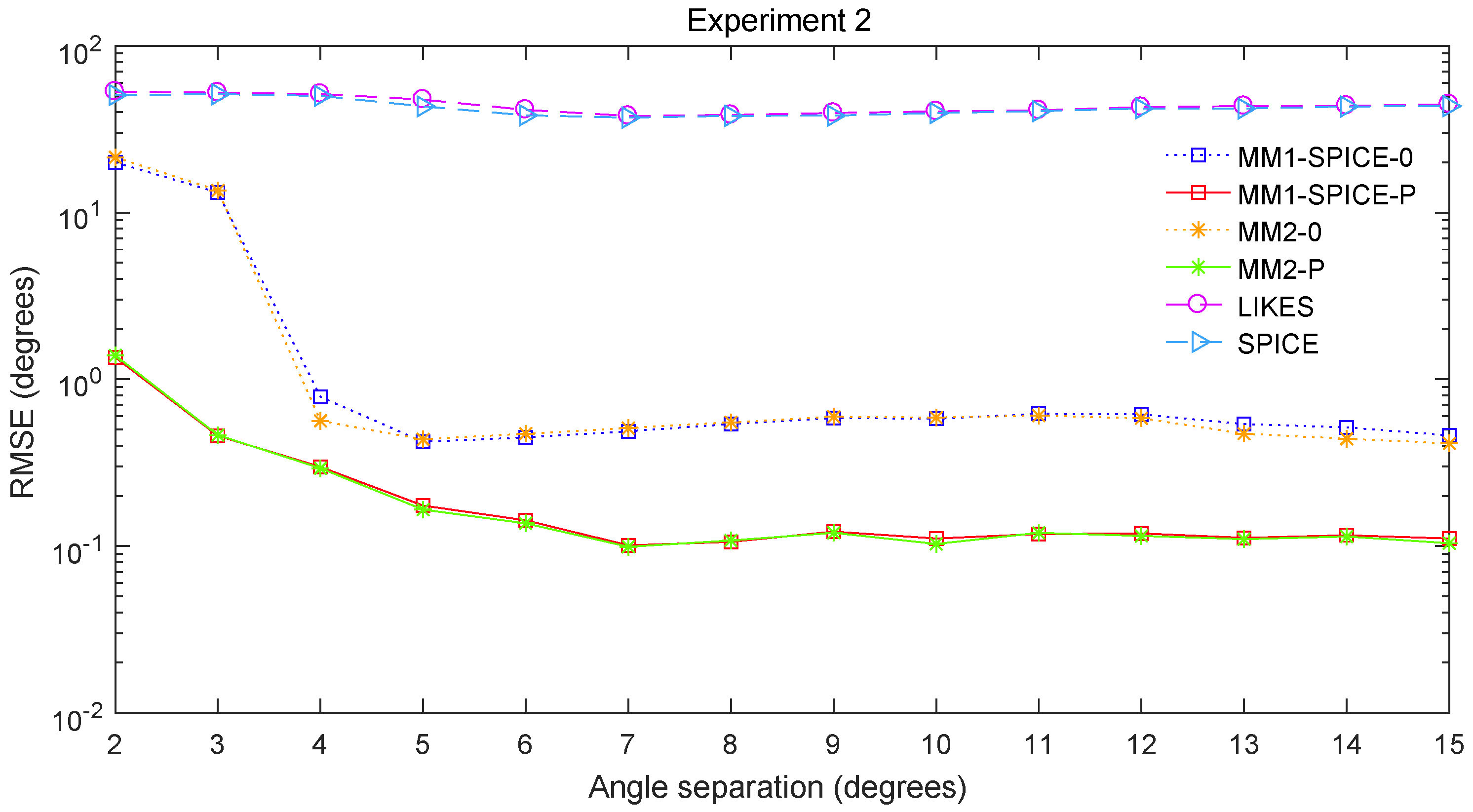
Figure 3 for Experiments 1–3 with different SNRs, respectively.
Figure 4 and
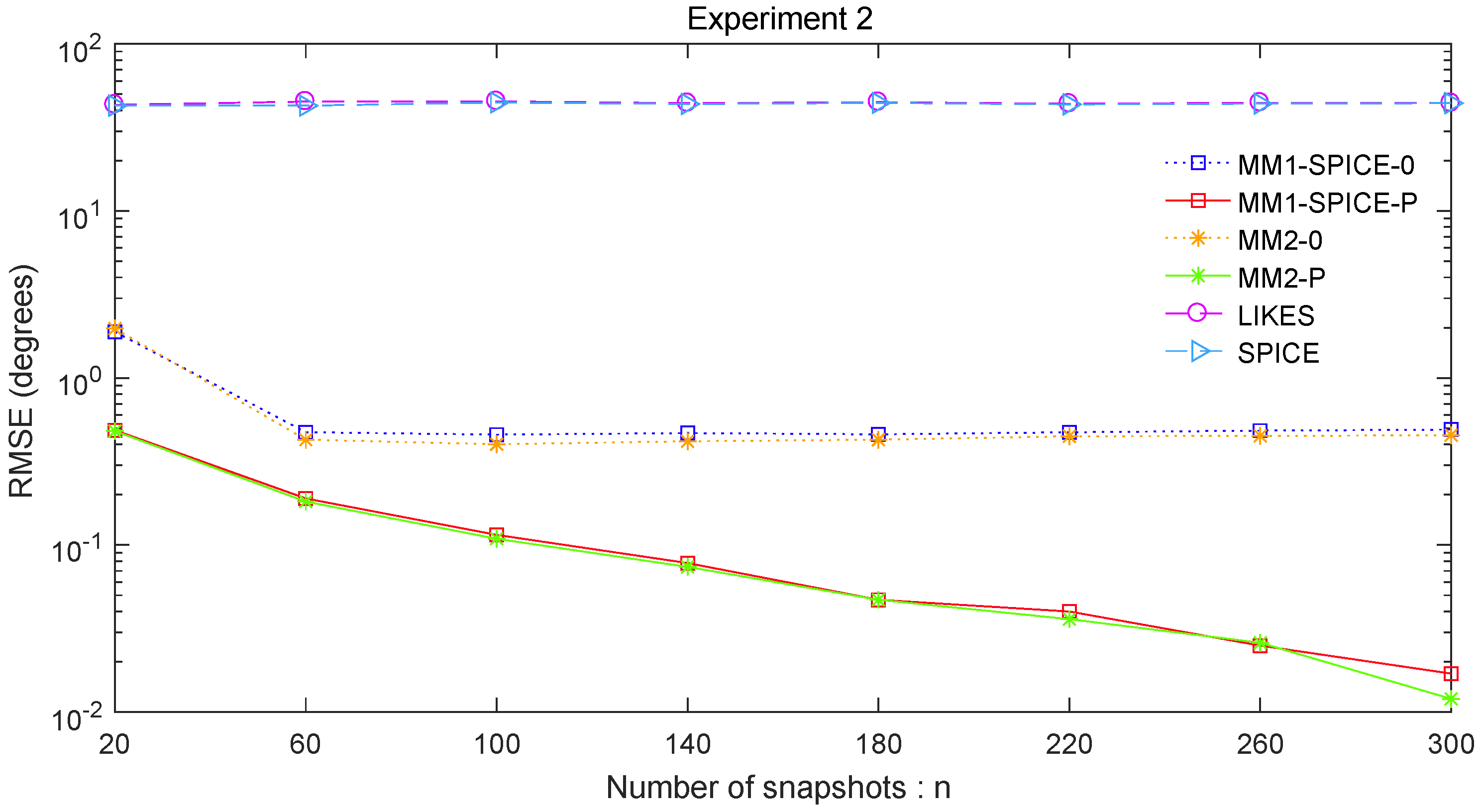
Figure 5 for Experiment 2 show the DOA estimation RMSEs of the above six methods versus the number of snapshots and the angle separation, respectively.
In
Figure 1, we can see that the MM1-SPICE-0 and MM2-0 methods were comparable to the LIKES and SPICE methods in the Gaussian cases. As shown in
Figure 2,
Figure 3,
Figure 4 and
Figure 5, the scenarios of non-Gaussian random source signals and heavy-tailed random noise, the MM1-SPICE-0 and MM2-0 methods performed much better than the LIKES and SPICE methods. In other words, the ML methods designed for the CES outputs were effective in the simulation scenarios of Gaussian and non-Gaussian distributions.
As shown in
Figure 1,
Figure 2,
Figure 3,
Figure 4 and
Figure 5, we found that the penalized ML methods, i.e., the MM1-SPICE-P and MM2-P methods, had smaller RMSEs than the other four methods. As shown in
Figure 4, with the increase of the number of snapshots, the performance of the MM1-SPICE-P and MM2-P methods improved but the performance of the MM1-SPICE-0 and MM2-0 methods remained virtually unchanged.
Figure 5 shows that, as
increased from
to
, the performance of the MM1-SPICE-P and MM2-P methods became better, while, when
was larger than
, the performance of the MM1-SPICE-0 and MM2-0 methods no longer improved. As shown in
Figure 1,
Figure 2 and
Figure 3, unsurprisingly, as the SNR increased, the performance of all the six methods became better.
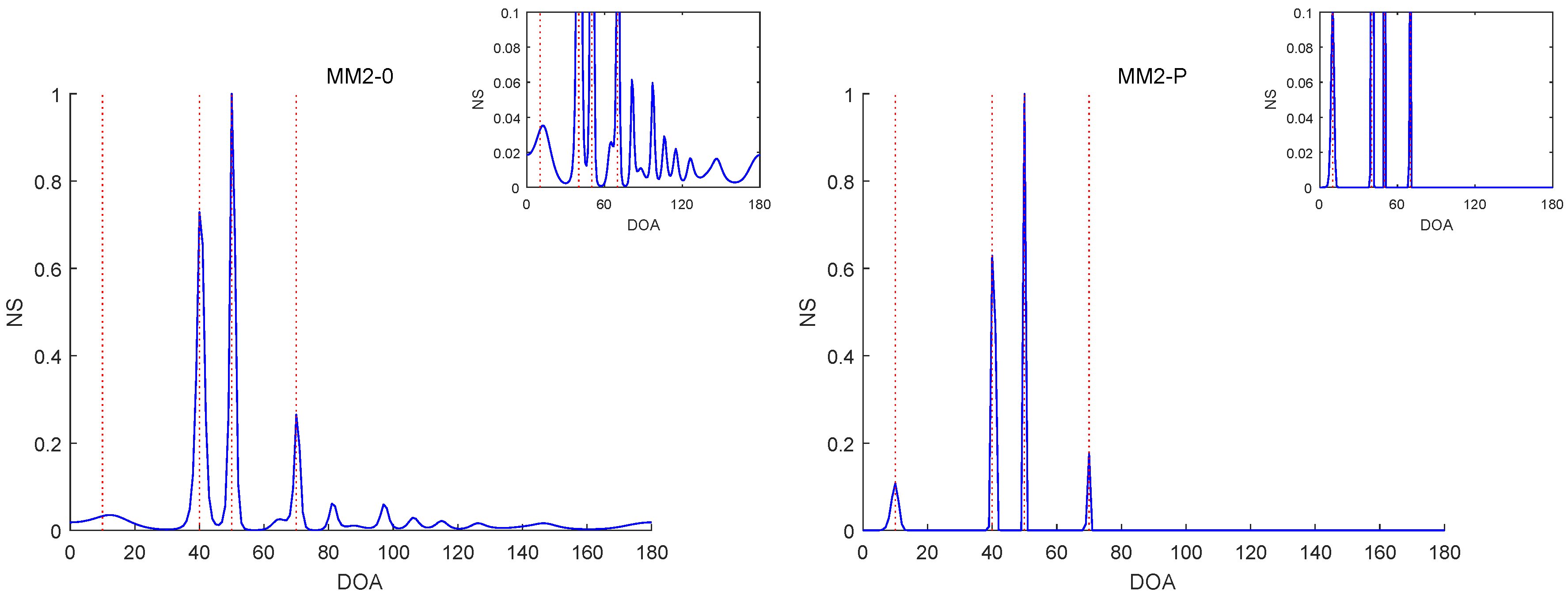
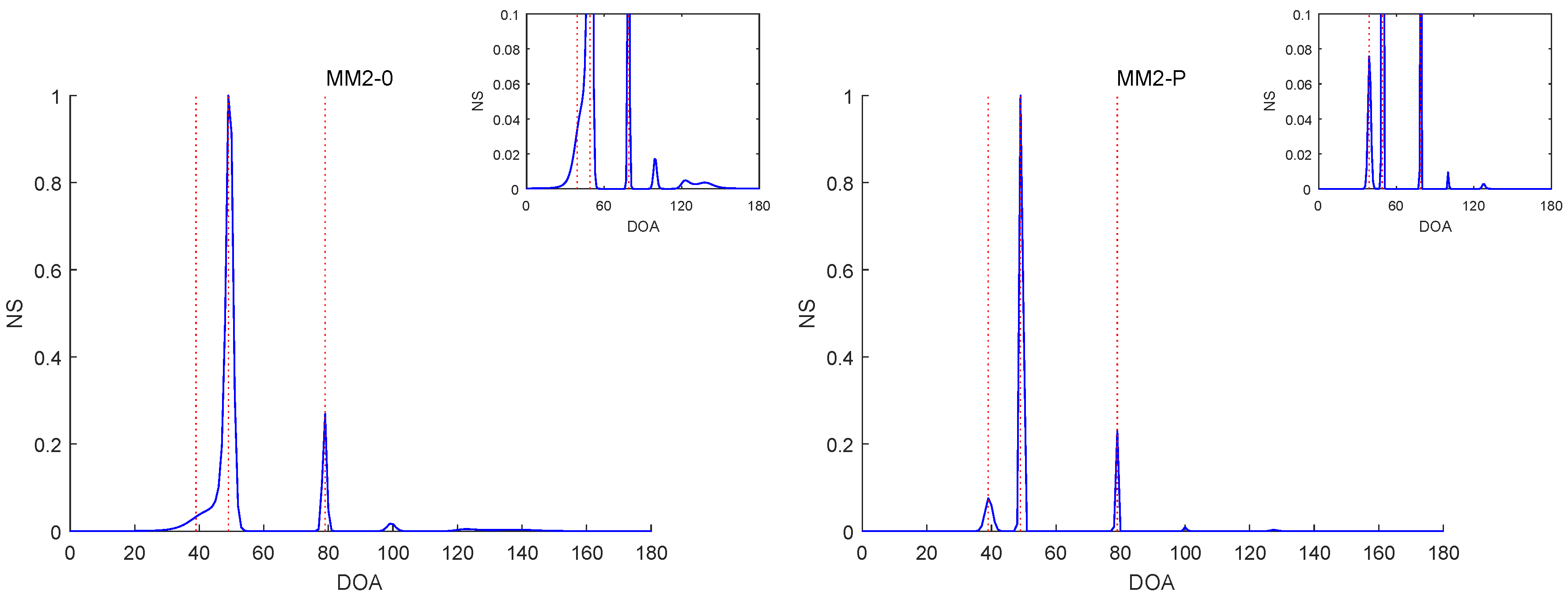
For illustrating the difference between the penalized and un-penalized ML methods, we evaluated the normalized spectrum (NS):
where
and
are, respectively, the estimates of
and
.
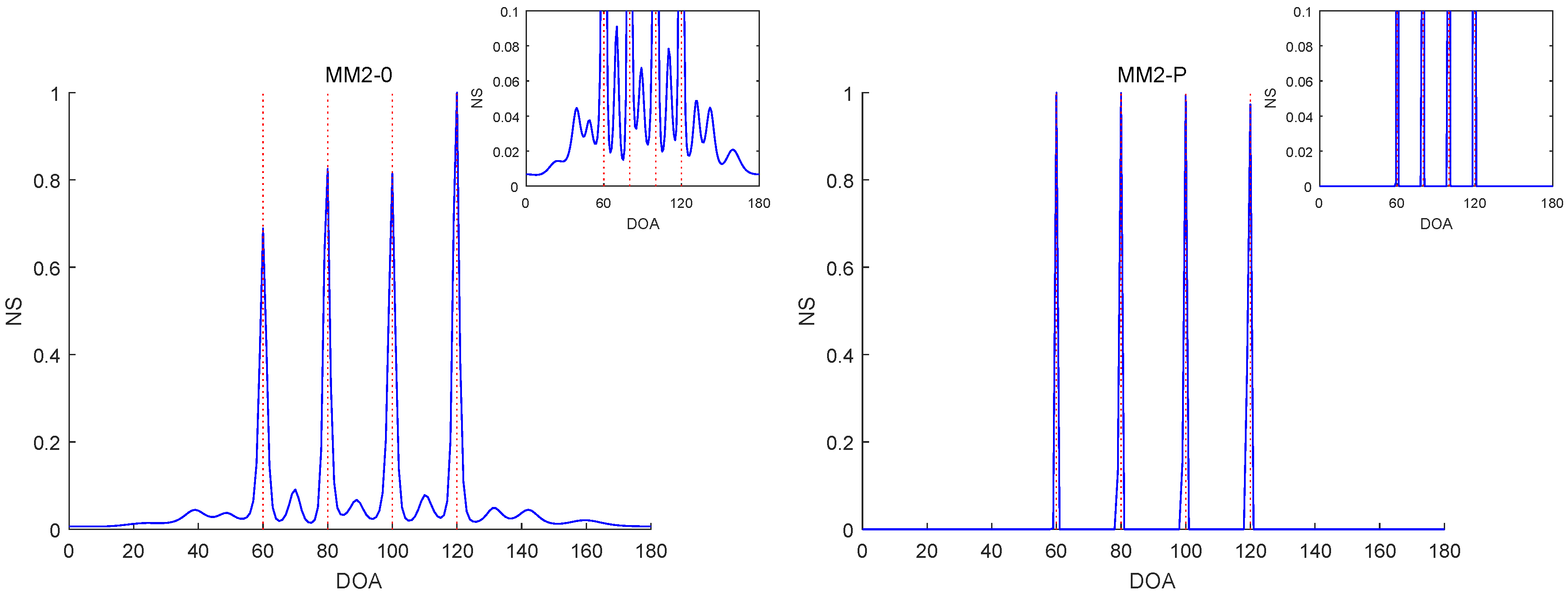
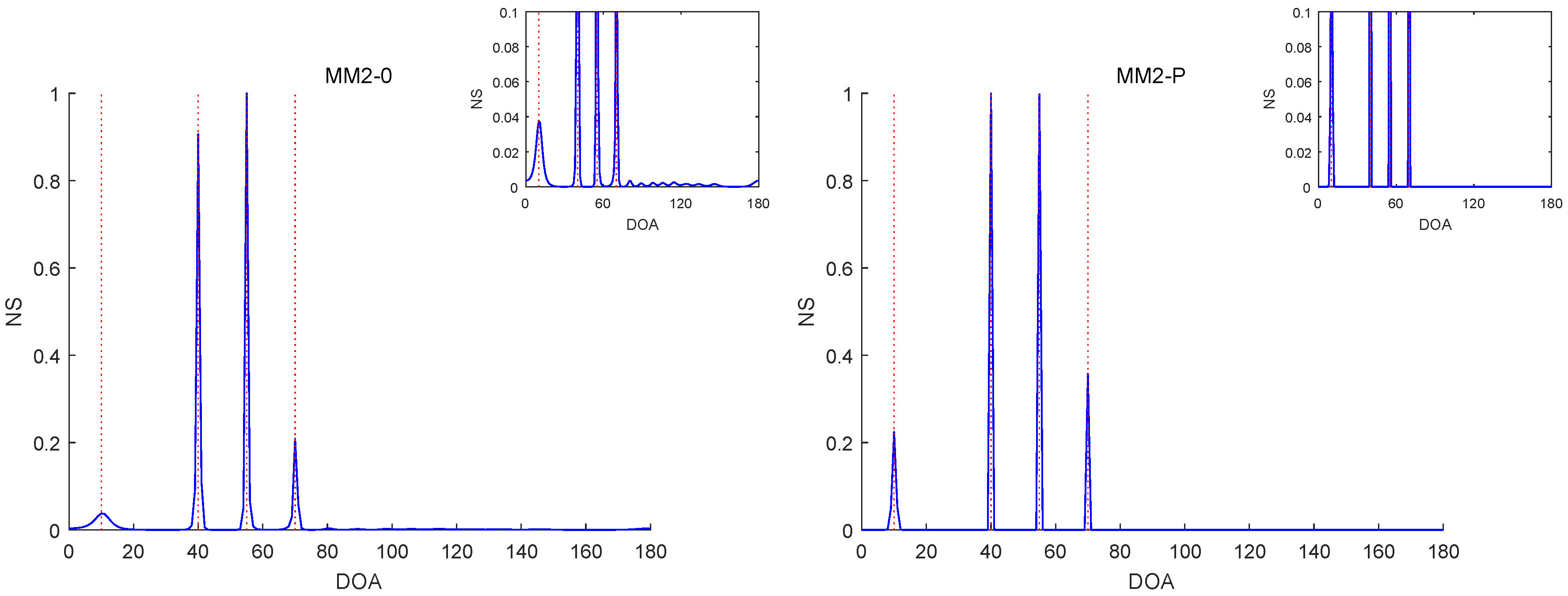
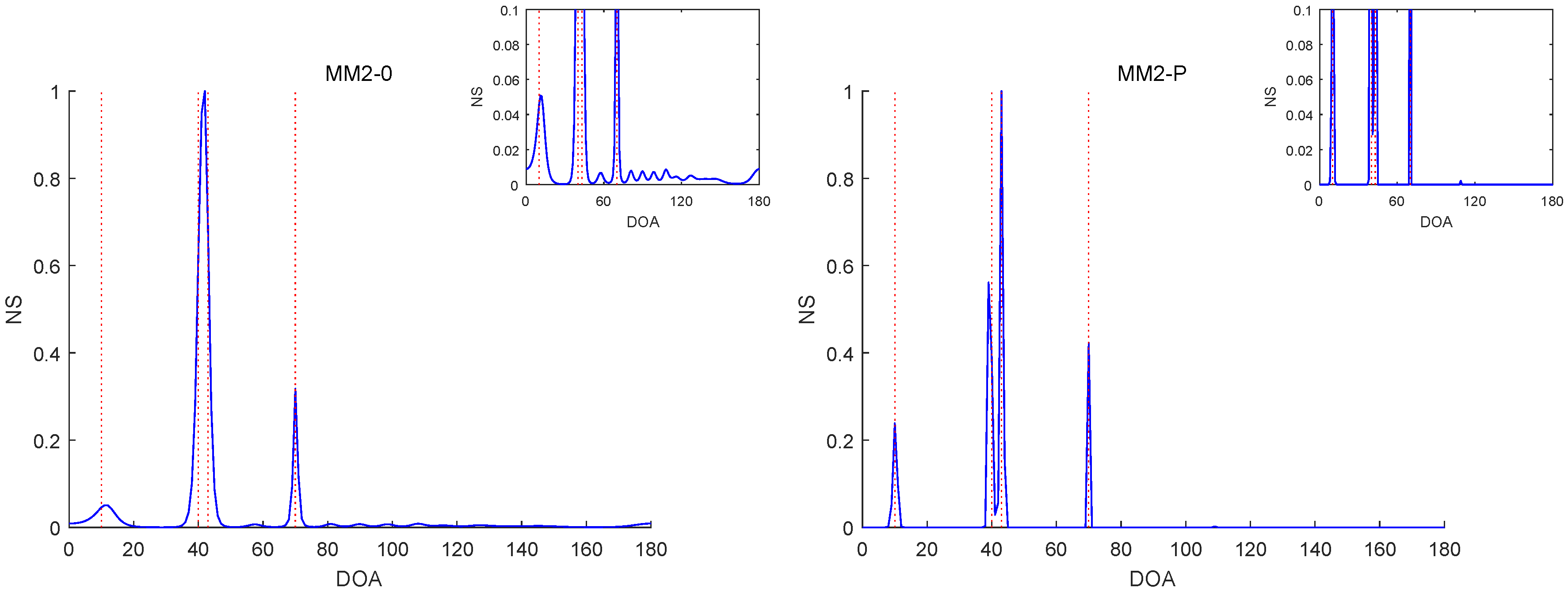
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 report the NSs of Experiments 1–3 by the MM2-0 and MM2-P methods (the curves of the NSs of the MM-SPICE-0 and MM2-SPICE-P methods are similar to those of the MM2-0 and MM2-P methods, respectively).
Figure 6 and
Figure 10 are for Experiments 1 and 3 with
, respectively.
Figure 7 and
Figure 8 are both for Experiment 2 with
and
, but they involve two scenarios with different angle separations. Particularly,
Figure 8 is for the very small
, as opposed to
Figure 7 for
.
Figure 9 is also for Experiment 2, but it is about the scenario with small snapshot size
, small
and moderate angle separation
. Note that the red dashed lines mark the true DOAs and the NS curves in each figure are the results of a randomly selected realization. We can clearly see in
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 that the MM2-P method having the
-norm penalty added yielded a higher angular resolution.
6. Conclusions
This paper provides a penalized ML method for DOA estimation under the assumption that the array output has a CES distribution. Two MM algorithms, named MM1 and MM2, are developed for solving the non-convex penalized ML optimization problem for spatially uniform or non-uniform noise. They converge locally with different rates. The numerical experiments showed that the MM2 ran faster and performed as well as the MM1 when estimating the DOAs. Their rates of convergence will be further explored theoretically in future.
It is worth mentioning that, in numerical simulations, the proposed
-norm penalized likelihood method effectively estimated the DOAs, although the values of nonzero elements of
or
were not estimated very accurately. By replacing the
-norm penalty by other proper penalties (e.g., the smoothly clipped absolute deviation (SCAD) [
47], adaptive LASSO [
48], or
-norm penalty (
)), more accurate estimates of the unknown parameter may be derived in the future.
If the
-norm penalty is replaced by the adaptive LASSO penalty, then the algorithms proposed in this paper can be applied almost without modification because the adaptive LASSO penalty is a weighted
-norm penalty. When the non-convex SCAD or the
-norm penalty (
) is employed, the convex majorizing functions given in [
40,
49] can be exploited based on the MM framework, and then the algorithms in this paper with minor modifications are also applicable.
When we have some informative prior knowledge on the directions of source signals, the problem of estimating the DOAs can be formulated as maximizing a sparse posterior likelihood from the Bayesian perspective. The sparse Bayesian method of estimating DOAs from the CES array outputs is interesting and is worth studying, while how to formulate and solve a sparse posterior likelihood optimization and how to do model selection are challenges. The BIC criterion can be used for the model selection, in which the Bayesian evidence difficult to be analytically derived can be approximated by the methods in [
44,
45,
46]. More research along this line will be done in the future.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}