2.1. Learning Techniques for Human Activity Recognition
Human activity recognition is a field of study which has gained significant attention in recent years due to the pervasiveness of sensors, which are now available in smartphones and wearable devices (such as smart watches or smart wristbands).
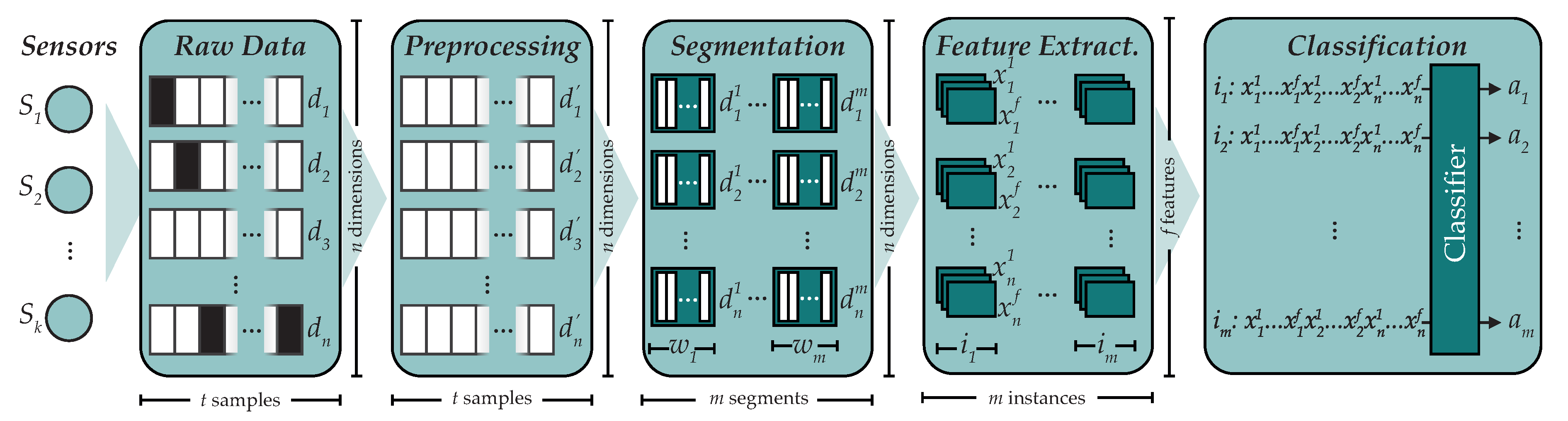
Activity recognition can be seen as a classification problem, a common type of problem found in supervised learning. In 2014, Bulling et al. [
1] studied this problem and proposed the
activity recognition chain (ARC), a sequence of steps in order to build human activity recognition systems (see
Figure 1), to which we will adhere in this paper. Bulling et al. also taxonomized these kinds of systems according to different criteria:
According to its execution mode, the system can be offline or online. In the latter case, the system is able to perform activity recognition in real time.
According to its generalization ability, the system can be user-independent or user-specific. In the former case, the system should be able to recognize the activity even for those users who are using the system for the first time.
According to the type of recognition, the system can process continuous streams of data or isolated data where the offset of each activity is previously known.
According to the type of activities, they can be periodic, sporadic or static.
According to the system model, it can be stateless or stateful. In the latter case, the system not only is aware of the sensors data but also considers a model of the environment.
In this work, we will consider a user-independent, continuous, stateless system. It could work either offline or online, and will mostly recognize periodic and static activities.
We must note there are limitations to the generalization ability of the selected approach. Due to the characteristics of the available data, we cannot be certain of how the results would differ if tested on a different group of users. However, we are not so interested in actual success percentages but in the comparison on different techniques in equal conditions.
Another important matter, raised in Ref. [
3], is the assumption regarding environmental conditions during the construction of the system. In our case, limitations on available data suggested the use of a trained approach, that is, we are training all systems assuming the same conditions both for training data and test data. This may or may not be the applicable case to a given real case. A stateful system would be more adequate in order to take into account environmental changes. However, information on the data acquisition environment was not available to us. We are thus, working on the assumption that personal sensors are designed to reduce environmental influences, and that may limit the significance of this element in this particular case.
Human activity recognition is a field which can be closely related to mHealth (mobile health), since in most cases, the activities to be recognized have a significant impact in the subject’s health. For example, in this work we will focus, among others, on certain physical activities (such as running, walking or jogging) and undesirable activities such as smoking. A system able to track the amount of physical exercise performed by the user could raise self-awareness and give proper credit for this task, an essential requirement to promote physical activity [
4]. Also, when the user carries out an undesirable activity, such as smoking, the system could raise an alert. The relationship between mHealth and activity recognition has been studied by Dobkin and Dorsch [
5].
We will use sensors located in smartphones and wearables instead of ad-hoc sensing devices placed across the subjects’ bodies. This is essential to transfer this technology to the society, since most users are already equipped with this type of device, and would not be required to hold additional hardware. Some applications of mobile activity recognition have been addressed and proposed by Lockhart et al. [
6], including some closely related to mHealth, such as fitness tracking or health monitoring.
As we stated before, an important aspect of human activity recognition applied to mHealth is recognizing physical activities (exercising). One of the most relevant datasets for physical activity is PAMAP (Physical Activity Monitoring in the Ageing Population), which was introduced by Reiss and Stricker [
7,
8]. This dataset was used by Saez et al. [
2] in order to compare the performance of different machine learning and deep learning classifiers for cross-person classification, and later Baldominos et al. [
9] used it for optimizing the feature extraction stage of the activity recognition chain.
In 2015, Shoaib et al. published a survey of online activity recognition systems using data from mobile phones [
10]. Since then, different machine learning techniques have been applied to the recognition of activities using mobile and wearable devices, such as naive Bayes,
k-NN and decision trees [
11], or the Ameva algorithm, the latter also supporting fall detection in the aging population [
12].
In the last couple of years, deep learning has started to become a standard for human activity recognition. An example of an early application is that by Ordoñez and Roggen [
13], where they used a combination of CNNs along with Long short-term memory (LSTM) layers in order to carry out activity recognition using the OPPORTUNITY dataset, which uses opportunistically discovered sensors along the subjects’ bodies and the environment [
14]. Later, some applications have arisen of deep and convolutional neural networks for mobile activity recognition. For example, Ordoñez and Roggen [
15] studied the effect of transfer learning between different domains, modalities and location. Inoue et al. [
16] used deep recurrent neural networks to improve the recognition accuracy in 20–30 percentage points when compared to classical approaches, increasing the recognition throughput. Finally, Münzner et al. [
17] have explored the use of CNNs for multimodal activity recognition using sensor fusion techniques.
2.1.1. Classical Machine Learning Techniques
In this paper, we will test the performance of different classical machine learning techniques for human activity recognition.
In this section, we will briefly describe the different techniques that will be used. These techniques will be taxonomized according to the following categories: linear models, probabilistic models, geometric models, neural networks and ensembles.
In this paper, we have used the implementation of the following algorithms provided in the
scikit-learn [
18] library for Python. We have chosen to adhere to this library because it enables fast prototyping of machine learning programs, eases the comparison of different techniques and allows the replication of the experiments.
2.1.2. Linear Models
Linear models are those that make a decision on the output based on a linear combination of the input. In this paper, we will use logistic regression, which is a widely used classification technique.
Given an input vector
, the logistic regression parameters will comprise vector of weights
and a bias value
. The output of the logistic regression for such input will be computed as:
where
is the logistic (or sigmoid) function:
Because will be a real number in the range , binary classification can be achieved by considering that the model will output the class 0 if and the class 1 otherwise.
In this paper, we will use a one-vs-rest approach for multinomial classification, using the LIBLINEAR optimizer [
19] for learning the model parameters and applying L2 regularization.
2.1.3. Probabilistic Models
Probabilistic models perform supervised learning by inferring an underlying probability distribution of data. The best well-known method is naive Bayes, which works by applying the Bayes theorem assuming strong independence among features. With this assumption, the conditional probability of
y given the input vector
is:
Given the previous formula, we can estimate the most likely class as follows:
In this paper, we will use Gaussian naive Bayes, where the likelihood of the features is assumed to be Gaussian:
where
and
are estimated using maximum likelihood [
20].
2.1.4. Geometric Models
Geometric models assume that data with similar features can be grouped together, and does so based on the geometric properties of the data. One of the simplest yet most widely used geometric models for classification is
k-nearest neighbors (
k-NN) [
21]. Interestingly, this algorithm does not build an explicit model, but rather perform
instance-based learning: new instances are classified by comparing them with the whole training set.
In this paper, we have used
k-NN with an Euclidean metric, where the distance between two instances
and
is computed as follows:
To classify an instance, the k closest instances are chosen and the class is decided via majority voting. As a result, k-NN determines Voronoi regions in the multidimensional hyperspace in order to classify new instances. After a preliminary analysis, we have determined to set , letting features uniformly weighted.
2.1.5. Neural Networks
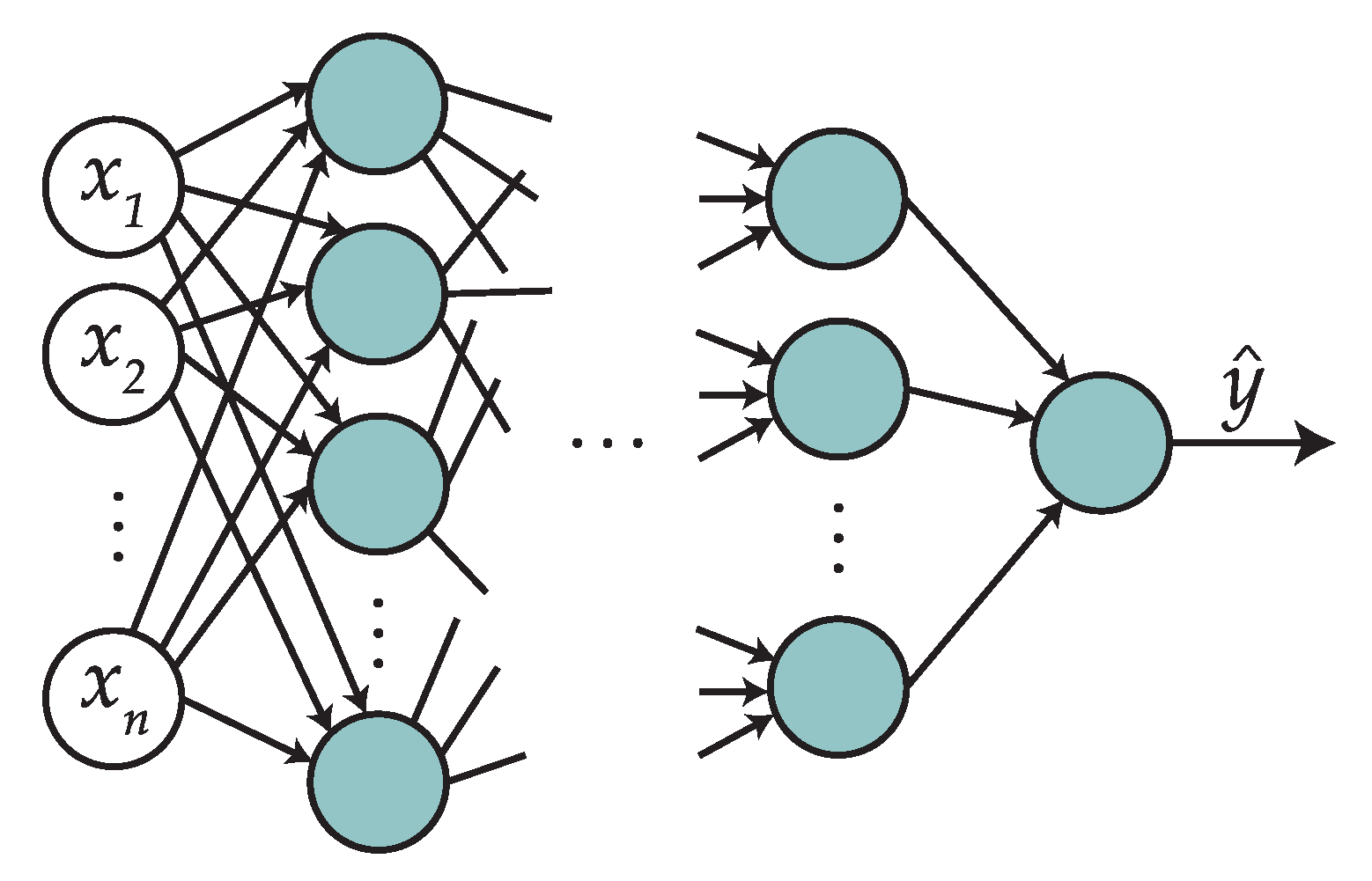
Neural networks are techniques that in a sense try to mimic the behavior of the human brain. In this paper, we will use the multi-layer perceptron (MLP), which is a very commonly used implementation of a feed-forward network that works as a universal function approximator. The basic topology of an MLP is shown in
Figure 2.
The first layer (in white) is known as an input layer, and will store the values of the vector , the feature vector for a given instance. The following layers, except for the last one, are known as hidden layers. We consider the MLP to have L layers ( hidden layers and one output layer), where the l-th hidden layer has units (or neurons).
During classification, data is going forward through the different layers. A layer l is characterized by two sets of parameters: a matrix of weights and a vector of biases .
The activation vector of neurons in layer
l is computed as follows:
where
is the activation function of neurons in layer
l. In this paper, we will use the ReLU (Rectified Linear Unit) activation function for the hidden layers, which is a non-linear function defined by the next equation:
ReLU has been proved a useful activation function since it prevents the effect of vanishing gradient, thus, accelerating the learning of the parameters during backpropagation [
22].
The last layer is known as the output layer. In the case of binary classification, the output layer has one output unit, and computes the output as follows:
In this case, we will not use the ReLU function, but a logistic function (see Equation (2)) so that the values are normalized in the range. In the case of multinomial classification, the MLP will have more than one output layer.
In this paper, we have used a MLP with two hidden layers, with 200 and 50 units respectively. The network will be trained using the Adam optimizer [
23] with the suggested values for
,
and
, and a learning rate of
. The network will be trained for 2000 epochs.
2.1.6. Ensembles
Ensembles combine different machine learning classifiers in order to obtain an overall improved model. The idea behind ensembles is that each model is specialized in a certain set of instances, and when working together they often perform majority voting in order to decide which class should be assigned to a certain instance.
While ensembles can be built out of any machine learning model, the most common approaches involve ensembles of decision trees. A decision tree is a structure that makes questions about the instance features in each level of the tree, descending through the branches until reaching a leaf, which contains the preferred class for that instance. A commonly used implementation of a decision tree is Quinlan’s C4.5 [
24].
In this paper, we will compare two different implementations for building ensembles of decision trees: random forests [
25] and extremely randomized trees (ET) [
26]. In both cases, each of the trees is trained using a random sample of the training data. We have configured both ensembles to train 20 decision trees using Gini impurity.
2.1.7. Convolutional Neural Networks
Convolutional neural networks [
27,
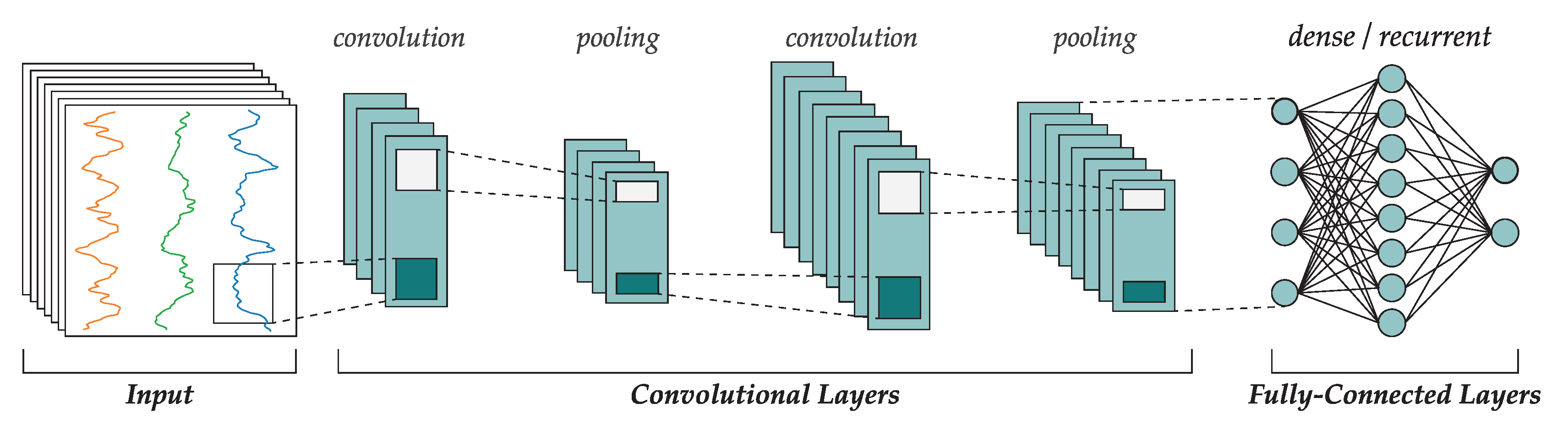
28] are a specific type of deep learning networks that are being applied to many complex problems with significant success. A convolutional network is composed of two differentiated parts: a feature learner and a classifier. The feature learner is made of a convolutional layer, most often placed sequentially, where each layer can process the output of the previous one in order to generate feature maps, which after learning, will turn into useful features extracted directly from the data without the need of manual feature engineering. Between these convolutional layers, pooling layers can be optionally found to decrease the feature maps size using downsampling. Finally, the classifier is often implemented as a MLP or conversely, a recurrent neural network.
The main strength of CNNs is that they are able to automatically extract relevant features that can be useful for classification, without the need of human experts deciding on which features are the most convenient. These features are automatically introduced to the classifier to generate an output. Interestingly, during the backpropagation process both the parameters of the classifier and the feature learner are trained, therefore providing a global optimization process (which contrasts the classical feature engineering process, when human intervention would be needed if the first set of features did not reach the expected quality). Another important aspect of CNNs is the introduction of pooling layers. Besides reducing dimensionality of feature maps, they avoid mapping a specific feature to an absolute “position” in the network connections, effectively providing invariance to translations. This was found to be quite useful in computer vision applications, where the network learns to recognize specific characteristics such as a given pattern of lines or colors, in any part of an image provided as a pixel matrix regardless of its position.
Figure 3 shows the topology of a typical CNN where the input raw data passes through two sets of convolutional and pooling layers. The resulting data is a set of calculated feature maps that are passed to the fully connected layers that are indeed a MLP or recurrent network that is trained in a conventional way using gradient descent. In signal processing applications such as this work, each input vector the concatenated values for the sensor measure over a window of time of length
W.
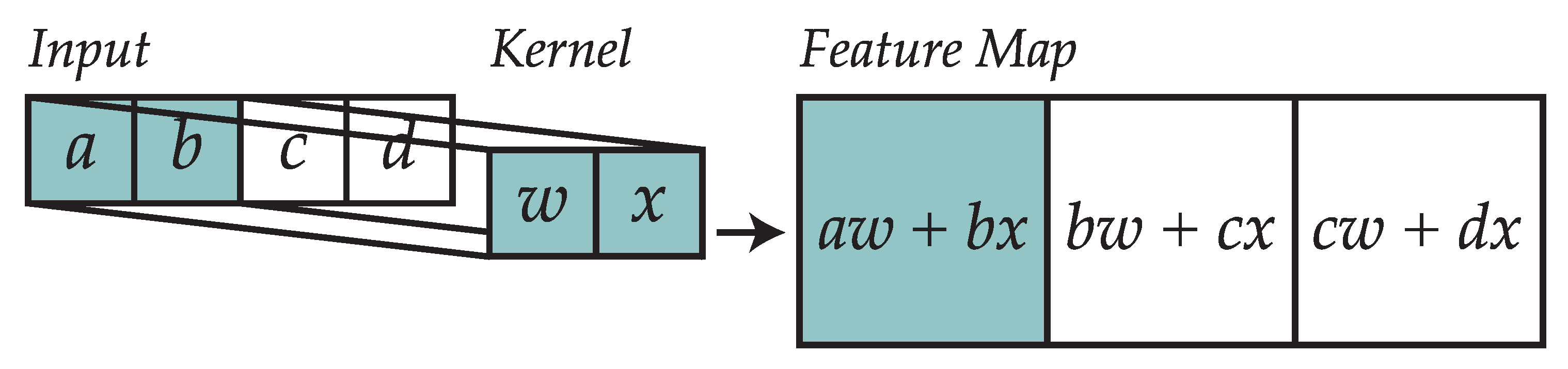
Convolutional layers are composed of a series of kernels (also known as filters) that process their inputs by performing a convolution operation. These elements work on multidimensional arrays (tensors), which in signal processing would often be one-dimensional while in computer vision they would be two-dimensional.
Convolution of the input tensor with the kernel produces the kernel output as shown in
Figure 4. The convolution operator for a one-dimensional vector is shown in Equation (10). The process of convolution, followed by pooling, enables the network to search for correlations among consecutive groups of input values that can be present in different parts of the analyzed window.
As a result, for an input and a kernel , the resulting tensor will be shaped .
After computing feature maps, an activation function can be applied to every element in the output tensor. In our case, we will apply a ReLU function in order to compute a non-linear transformation of the output.
Each pooling layer reduces the dimension of its input, typically using the technique of max-pooling. In this technique a group of input data is replaced by the maximum value of the group.
After the convolutional layers have extracted relevant features from the input data, the resulting tensor will be flattened into a vector. Then, this vector can be introduced to a trainable learning, which will often be a fully connected neural network.
Whereas a common approach could be to use a MLP, we have decided to use a recurrent neural network. However, instead of the classical recurrent approach, which is harder to train, we have preferred to introduce LSTM cells [
30].
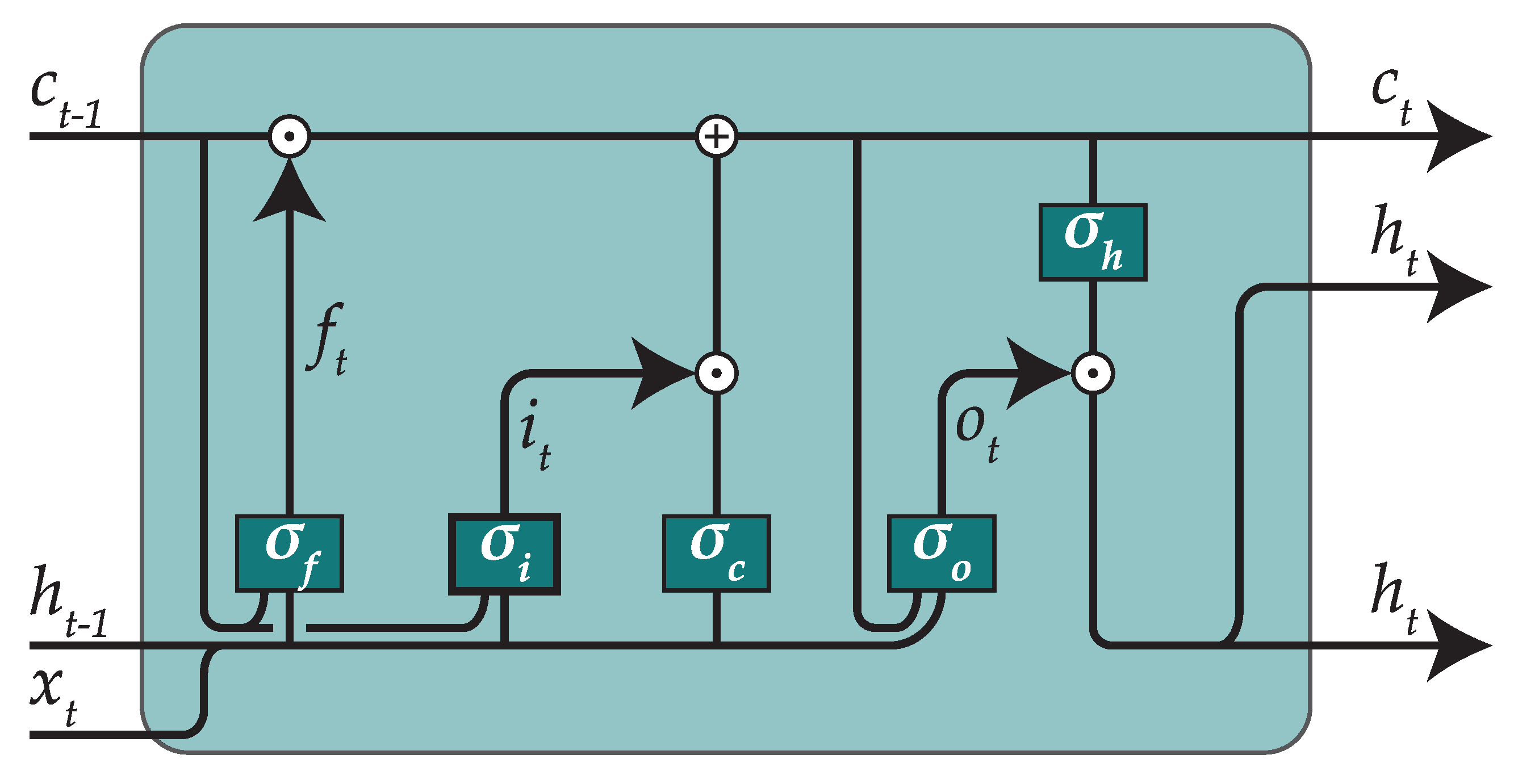
The architecture of a LSTM cell with peephole connections is shown in
Figure 5. In LSTM cells,
is called the “cell state”. A cell contains three gates that control the cell state by adding or removing information. The first gate is the “forget gate” and decides which information will be forgotten from
, the second gate is the “input gate” and decides which new information will be included into
, and the last gate is the “output gate” and decides which information will constitute the output. The math behind a LSTM cell is shown in the next equations, where ⊙ stands for an element-wise product operator:
The first of these gates, is the “forget gate” which will look at the input and decide which information will be forgotten from . In particular, will be a vector of real values in the interval , that will be multiplied element-wise by . A 0 means that the corresponding information in will be ignored, whereas a 1 would leave that information unaltered.
The second gate, is called the “input gate”, and decides which new information will be included into the cell state. In particular, will be a real vector with the same format than , and a function will transform the input data. Later, the transformed data and will be multiplied element-wise, and the result will be summed up with , resulting in .
The final gate, , is called the “output gate” and will decide which information will constitute the output. Here, will be a vector similar to . However, it will not be used to modify the cell state; instead, it will be applied over a transformed version of the cell state in order to be returned as output.
By using LSTM cells, we will be able to learn temporal components of the data, which can be useful since we will be dealing with time series.
Again, we have chosen to apply ReLU as the activation function for the fully connected layers. Also, we will introduce
dropout, a technique that removes a random set of connections during training which has been proven successful [
31] as a form of regularization to avoid overfitting.
In order to implement the convolutional neural network, we have used the Theano framework [
32] along with the Lasagne library. We have chosen to use these tools since they simplify the construction of the CNN topology and speeds up the training process. Also, we can share the code with the scientific community to enable them to replicate the experiments.
For designing the CNN topology, we have performed a prior analysis to determine suitable hyperparameters. In the end, we have decided to include three convolutional layers with 64 kernels each, with a filter size of 10 and a ReLU activation function. A max-pooling layer of size 2 was included after each convolutional layer. Also, we have included two LSTM layers with 128 units each and ReLU activation function, and dropout of 50%. The output layer would implement a softmax function: by doing so, all the output values sum up to 1, and they can be seen as the probability distribution of the instance belonging to any of the classes.
For training the network we have used the RMSProp optimizer [
33] with a learning rate of
and the suggested hyperparameters:
and
.
2.2. Methodology
A sequence of steps for working on human activity recognition problems, namely the
activity recognition chain (ARC) was introduced by Bulling et al. [
1]. The steps involved in the ARC were previously shown in
Figure 1 and include: data acquisition, data preprocessing, segmentation, feature extraction and classification.
In this paper, we will adhere to the activity recognition chain when working on classification using classical machine learning techniques. When using CNNs instead, we will use a slightly different approach as a part of an end-to-end deep learning solution, which does not require the feature extraction stage.
In the current section, we will thoroughly describe how each of these stages are applied in this work.
2.2.1. Data
For this paper, we have decided not to perform data acquisition on our own, but rather use a publicly available dataset. In particular, we have chosen to use the data provided by Shoaib et al. [
11,
34]. This dataset contains labeled instances for activity gathered using two mobile devices and is quite recent, as it has been released in 2017. By using a public dataset, we enable reproducibility of the results of this paper. Data can be downloaded from the Pervasive Systems group page of University of Twente [
11].
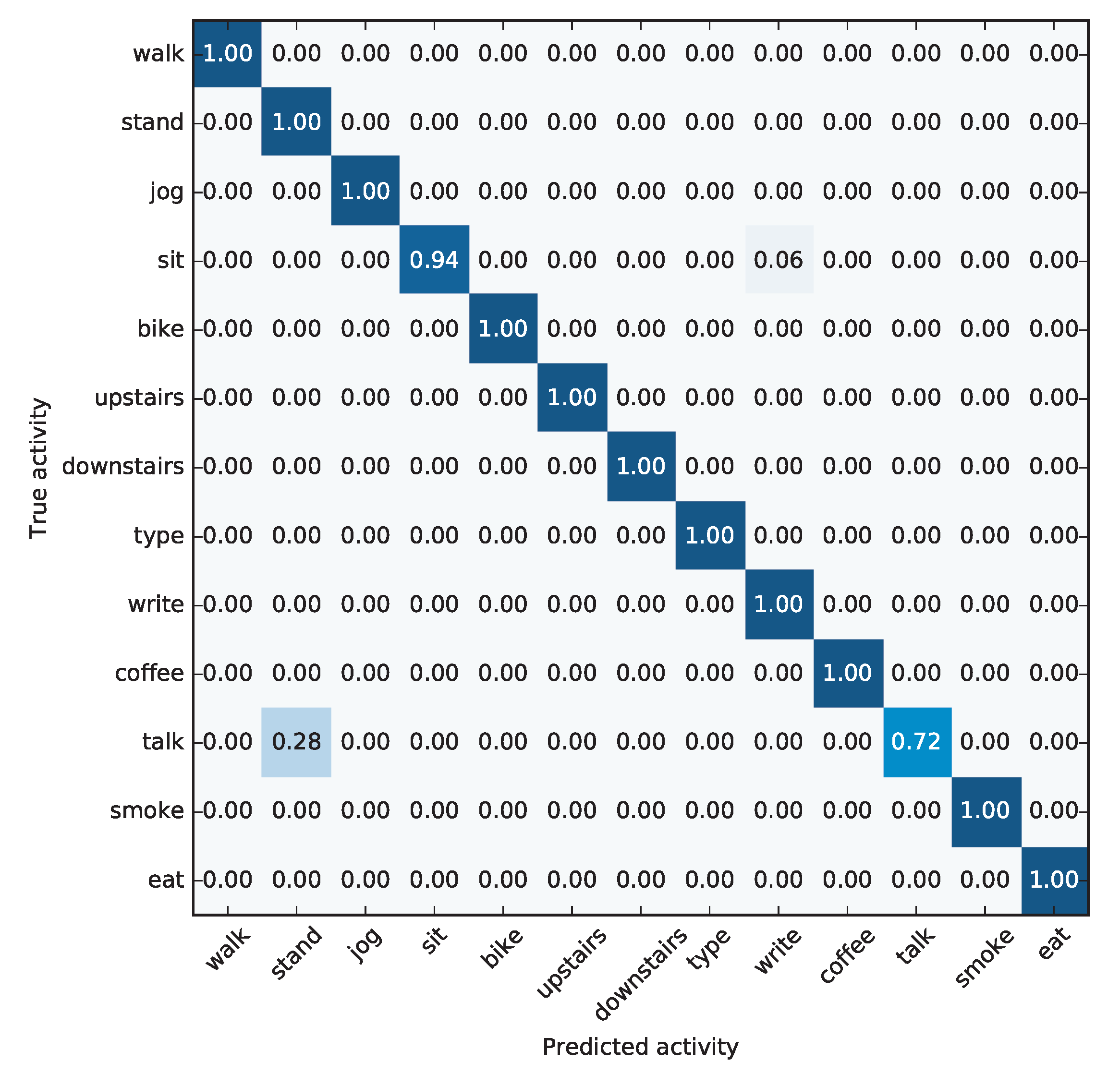
This dataset contains data for thirteen different human activities, including physical activities (walking, jogging, biking, going upstairs and going downstairs), common postures (standing, sitting), working activities (typing, writing), and leisure activities (talking, eating, drinking coffee and smoking).
The data was collected from ten healthy male participants aged 23–35 years. The physical activities and common postures were performed by all subjects. Working activities and leisure activities were performed by seven out of the ten subjects, with the sole exception of smoking, which was performed by six participants (only six of them were smokers, and non-smokers were not required to smoke for the data collection stage). A total of 30 min of data is available for each activity, with an equal amount of data from each participant. Thus, the dataset involves 390 min of data.
The participants were asked to carry two mobile phones Samsung Galaxy S2, one in their right pocket and the other in the right wrist. An exception was made since one subject was left-handed: in that case, he was allowed to carry the device in his left wrist, and data was post-processed accordingly to make it consistent with the remaining data. The orientation of mobile phones was portrait with their screen pointing towards the body. The wrist-worn smartphone is used as a proxy for an actual smartwatch device, having equivalent sensors. Data is sampled from the accelerometer, the gyroscope and the magnetometer at a frequency of 50 Hz using an Android app specifically designed for that purpose [
34]. Additionally, data from a virtual linear accelerometer is also included in the dataset, by removing acceleration due to gravity from the accelerometer data. We performed no additional data calibration besides the one already in the raw data provided in the publicly available dataset. The resulting raw data sample vector has 12 components, detailed in
Table 1.
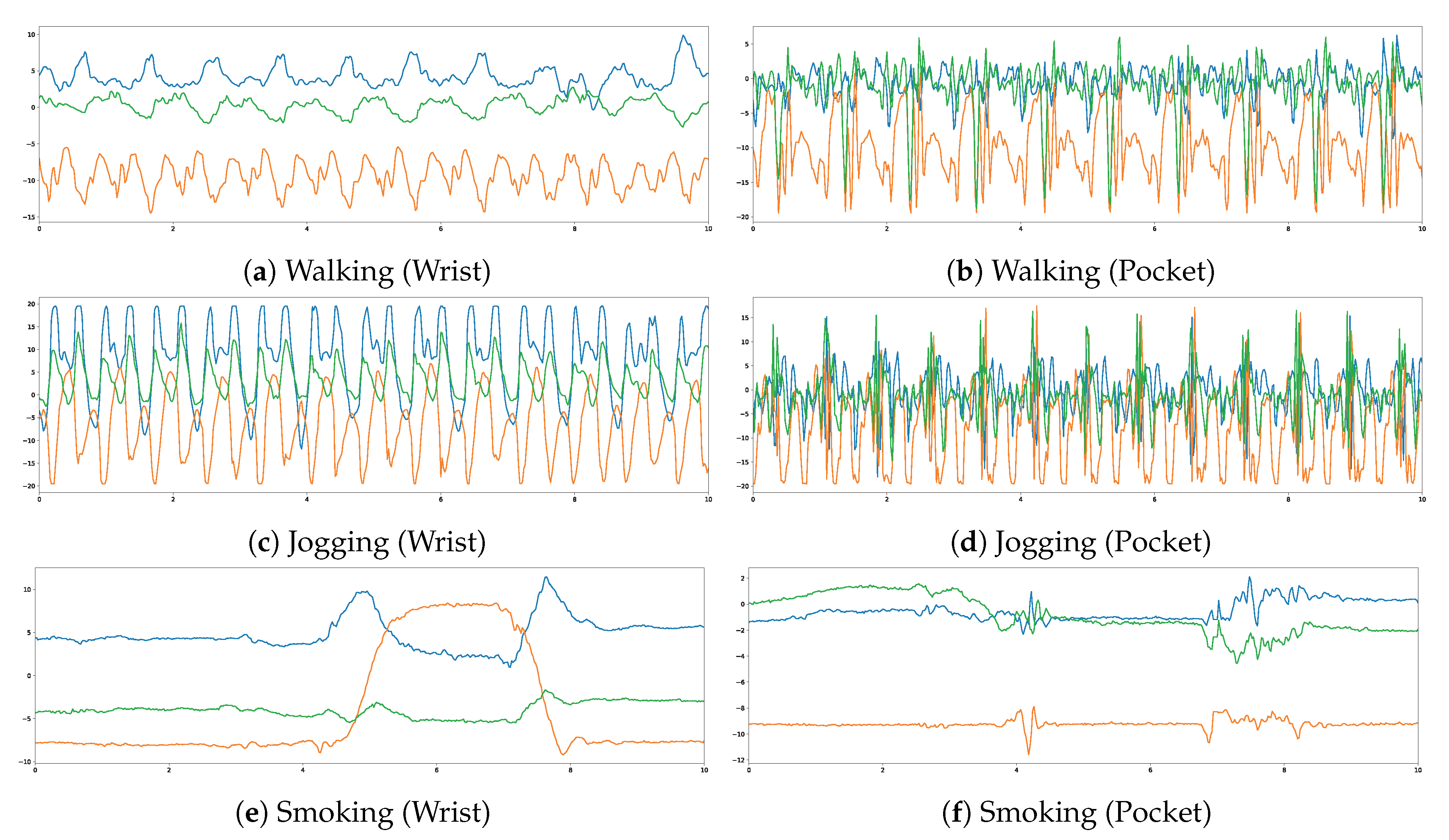
Some examples of the data available in the dataset are shown in
Figure 6. Each plot shows the value of the three dimensions of the accelerometer (blue is
x, orange is
y, green is
z) for a certain activity. Plots in the left side belong to the accelerometer located in the wrist, while those in the right refer to the accelerometer located in the pocket. Interesting trends can be seen with just these few examples, and we will now mention a few. Walking and jogging have a very similar effect in the accelerometer in the pocket, the main difference being that when jogging, both the magnitude and frequency of the motion are larger. However, walking and jogging are quite different when the motion is captured in the wrist: walking barely has any motion, but jogging does. The activity of smoking is rather interesting: most of the time, the plot shows barely any movement. However, we can see how between seconds 4 and 8 the
y dimension of the accelerometer located in the wrist experiences a large motion, which would reflect the fact that the subject carries the hand to the mouth in order to aspire smoke. This action takes about four seconds, and then the subject comes back to the original position. Interestingly, about the 4th and the 8th second, there is a small impact on the accelerometer in the pocket, which could happen if the subject be moving the hand holding the cigarette near the smartphone located in the right pocket.
2.2.2. Preprocessing
The data has been used as provided by Shoaib et al., and has not been submitted to further preprocessing. Original data is already synchronized and cleaned, and we have used it out-of-the-box. However, we have omitted the timestamp, since it is not a really useful feature for learning the activity performed.
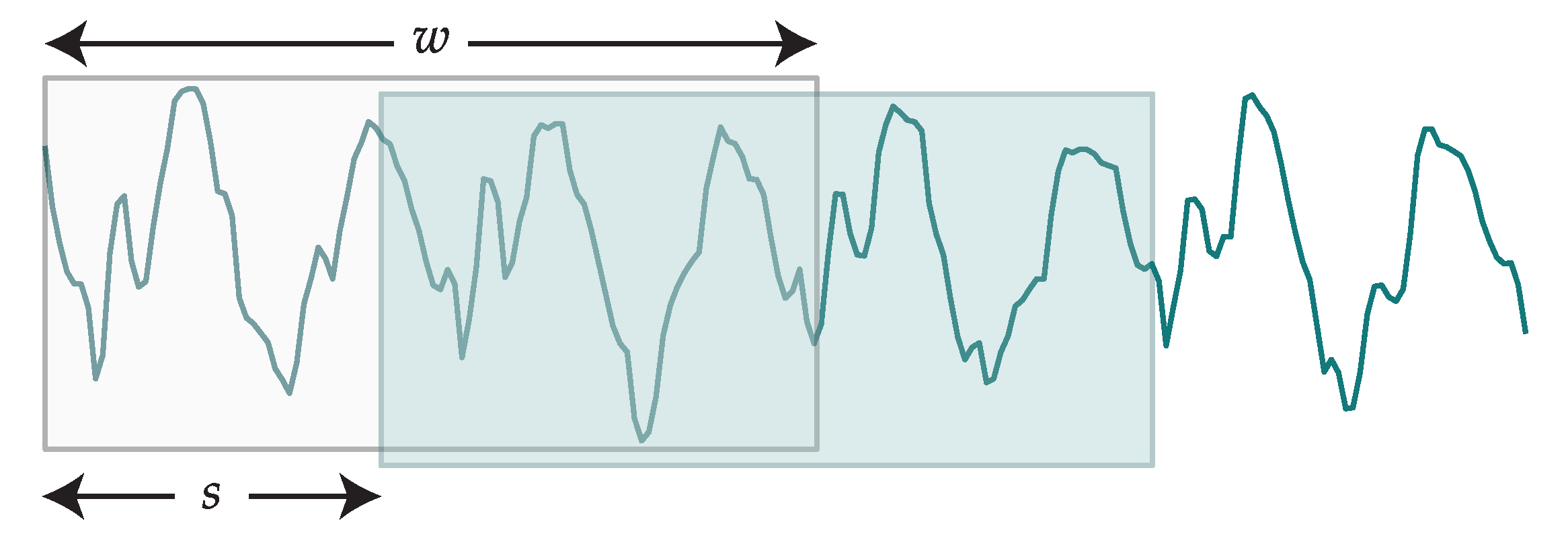
2.2.3. Segmentation
For the segmentation stage, we have created segments by moving a sliding window across each dimension of the data. The process is conceptually depicted in
Figure 7. The sliding window will have a fixed size of
w samples and a step of
s samples. Every time the window slides over the data, a new segment is created with the samples contained in the window. The larger the step, the less data we will have after feature extraction; on the other hand, very small steps can lead to unmanageable volumes of data. Windows are guaranteed to comprise only instances belonging to the same activity.
Each input vector
is obtained from the sequence of training data for an activity
using Equation (11), where we address the elements in
T using the slice notation typical in arrays.
2.2.4. Feature Extraction
In order to introduce the data to a classifier, we first need to extract features from the raw data. This step will only be performed when classification is done via classical machine learning techniques. When using convolutional neural networks, this step is ignored and the segments obtained in the previous stage are introduced directly to the first convolutional layer.
In this stage, we will manually engineer features that enable the classifiers to learn the class from the data. First, it should be noted that the data can be seen as a time series. When dealing with classification of temporal series, it is often interesting to transform the series into the frequency domain by computing the discrete Fourier transform (DFT) of the input. In our case, we have computed the fast Fourier transform (FFT) for each dimension in each segment:
Then, we have considered only the real coefficients, ignoring the imaginary part of the transformed values. Finally, we have computed the next features for each segment and dimension:
The mean value of the raw vector.
The standard deviation of the raw vector.
The median of the transformed vector.
The lower quartile of the transformed vector.
The upper quartile of the transformed vector.
The skewnwss of the transformed vector.
The kurtosis of the transformed vector.
We have selected the mean and standard deviation of the non-transformed values because they have been proved useful for activity recognition [
35,
36]. The statistical values obtained from the transformed input have been chosen because they have been proved useful in previous works [
2,
35], and have resulted as well of a prior manual stage of sensitivity analysis.
2.2.5. Classification
In order to perform classification, we have divided the data into a training set and a test set. To do so, we have considered the first 70% of the data for each activity as the training set, and the remaining 30% of the data as the test set. Data is not previously shuffled; therefore, the test set contains “future data” with respect to the training set.
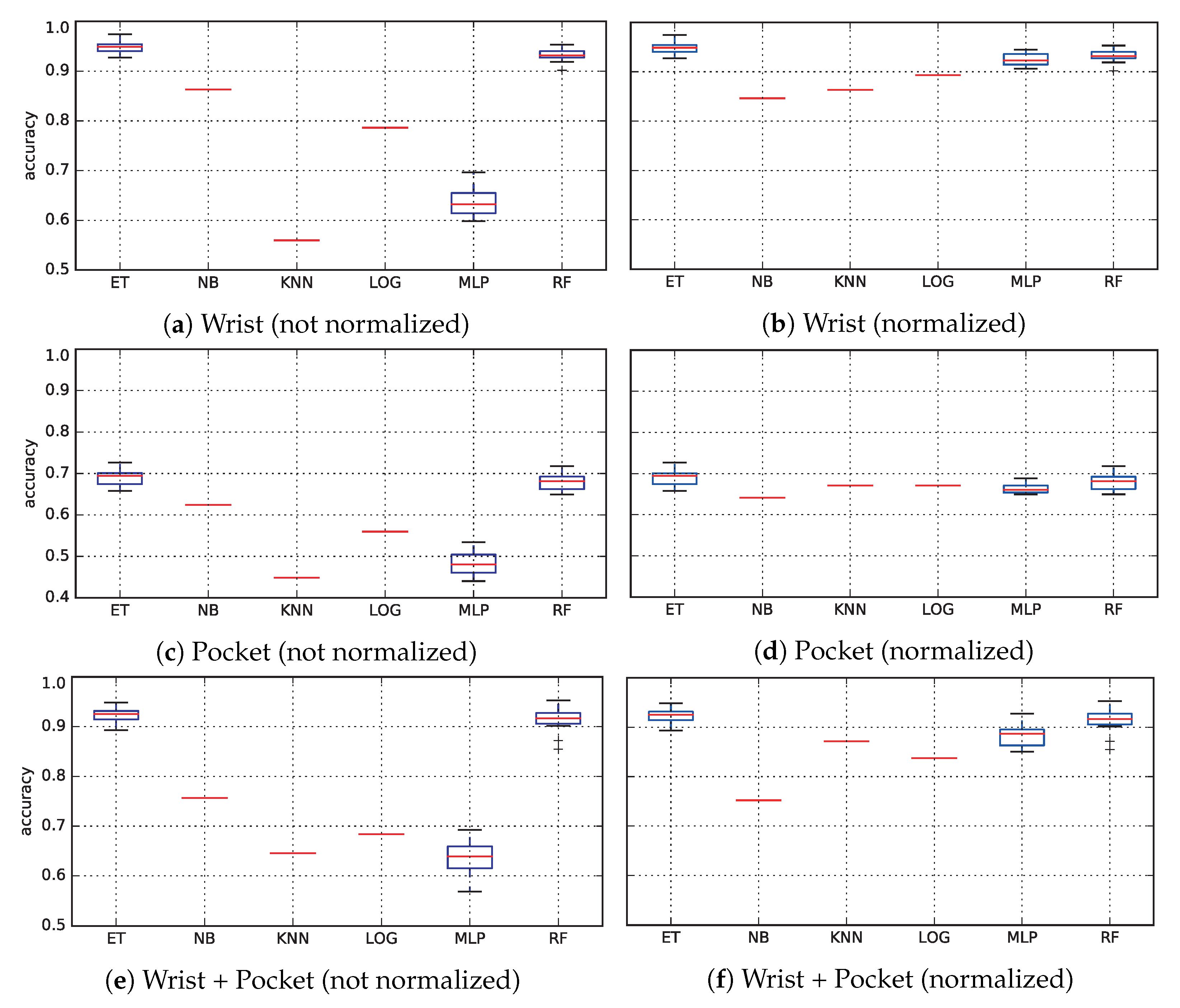
The classification is performed with three different datasets: data obtained from the wrist device, data obtained from the pocket device, and both. In the former two cases, the dataset has features (12 dimensions and 7 features per dimension). In the latter case, the dataset comprises twice the number of features (168), as this dataset results from stacking the other two horizontally.
The classifiers used for learning the activity recognition models have been presented in
Section 2.1.1, along with their configuration. Their parameters have been estimated after a prior manual sensitivity analysis. Also, convolutional neural networks will be used for classification, following the description provided in
Section 2.1.7. In this case; however, the previous features will not be used, and instead inputs will be one-dimensional vectors formed by the concatenation of the 12 dimensions for the full window: that is,
for the wrist and pocket datasets, and
in the dataset that uses both sensors (wrist and pocket).
2.3. Experimental Setup
2.3.1. Classical Machine Learning Methods
The experiments have been executed in a MacBook Pro laptop with an Intel Core i7 processor running at 3 GHz and 16 GB of DDR3 RAM memory. As for the software, we have used the implementations of machine learning algorithms provided by scikit-learn 0.18.1, using numpy 1.13.1 and scipy 0.19.0 for processing the data in order to extract features.
The machine learning techniques have been described in
Section 2.1.1, where some of their configuration was already discussed. For determining the best parameters, we have performed a preliminary sensibility analysis, and concluded that in most cases default parameters work fine, or there are not a significant differences when changing the values. All the relevant parameters of the machine learning algorithms are shown in
Table 2.
For the segmentation phase, we have used a sliding window size of , which is equivalent to 1 min of activity, and a step of . Reducing the step would provide more training and test data, at the cost of increasing memory requirements and execution time.
Because some techniques may benefit from data normalization, we have decided to normalize the input features by substracting the mean and dividing by the variance. As we will see later, this will have a positive effect in techniques based on numerical computations (MLP, Logistic Regression) and distances (k-NN).
Finally, some techniques are stochastic, specifically random forests, extremely randomized trees and the multi-layer perceptron. For this reason, we have executed each classifier 20 times using different random seeds in order to avoid biases and check the robustness of the technique.
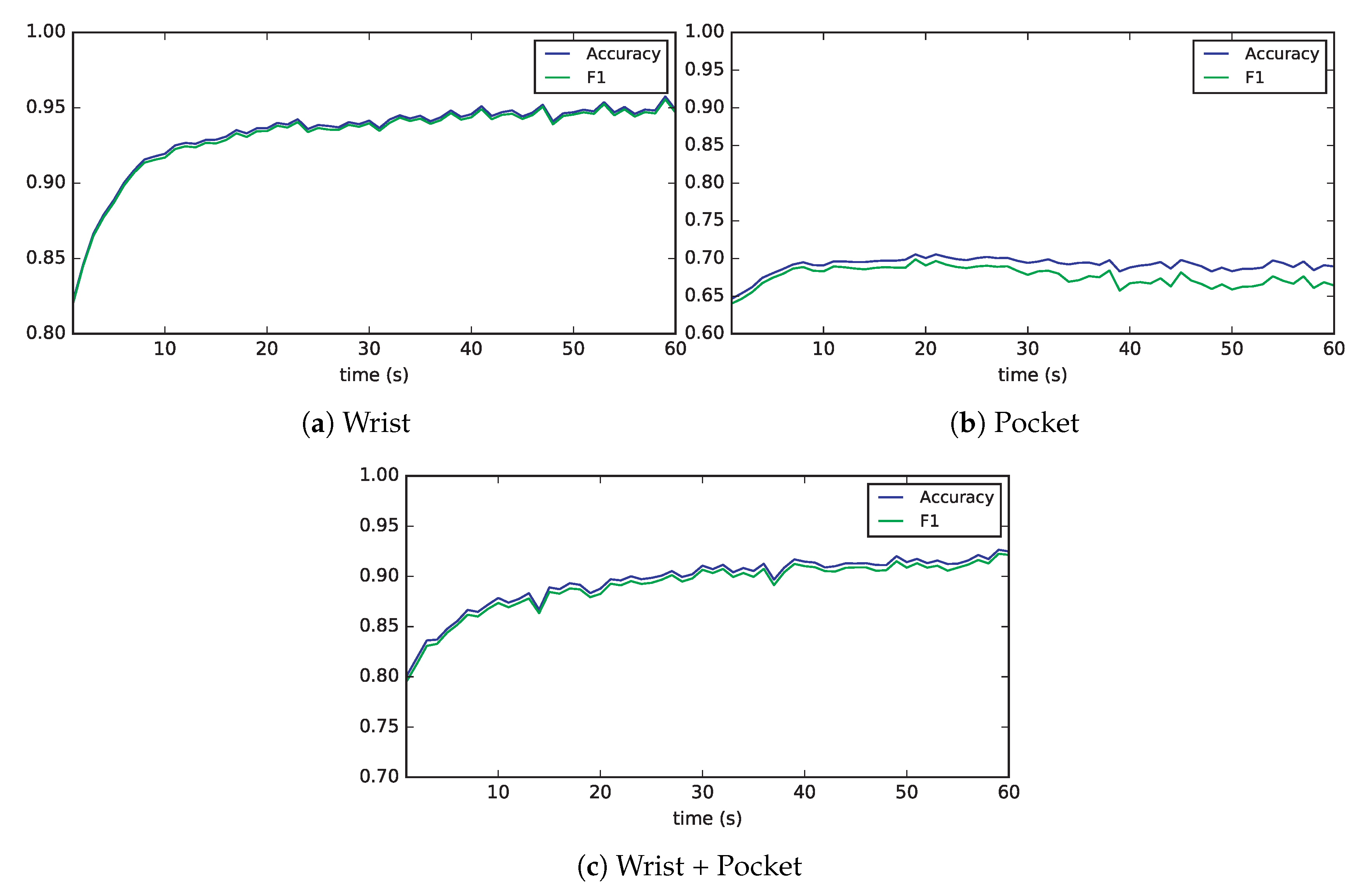
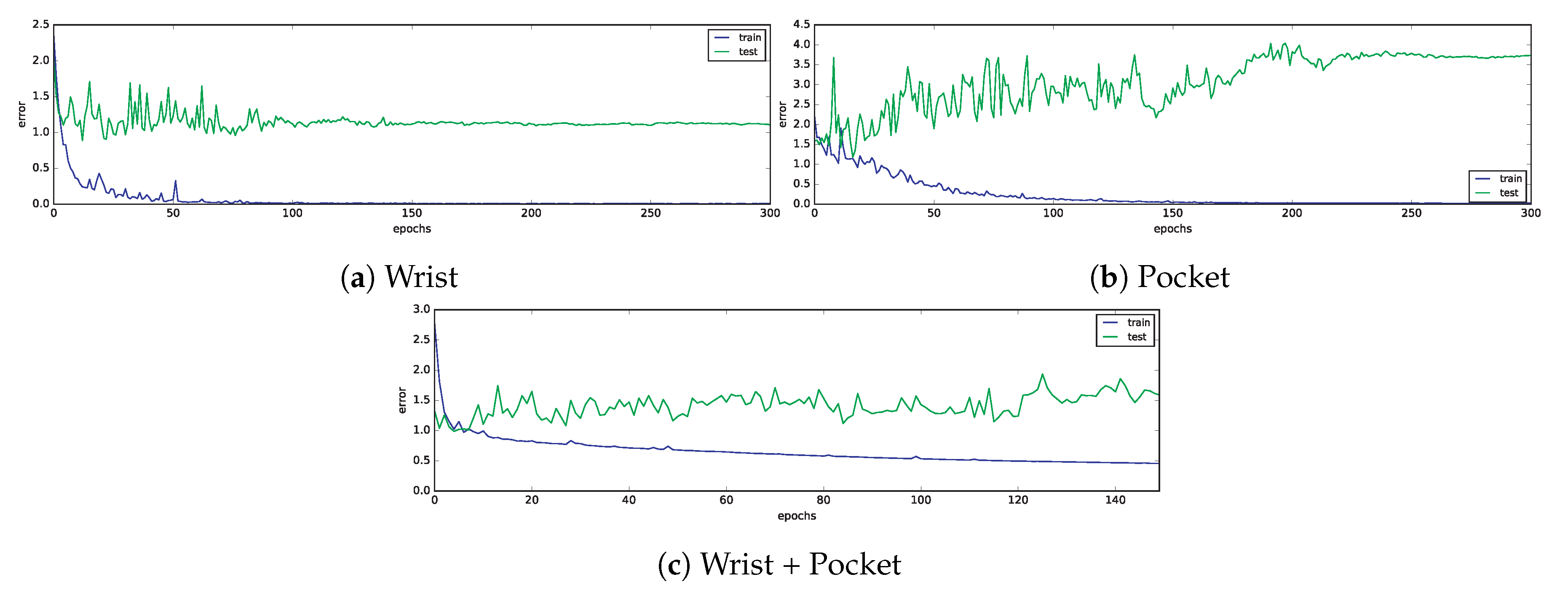
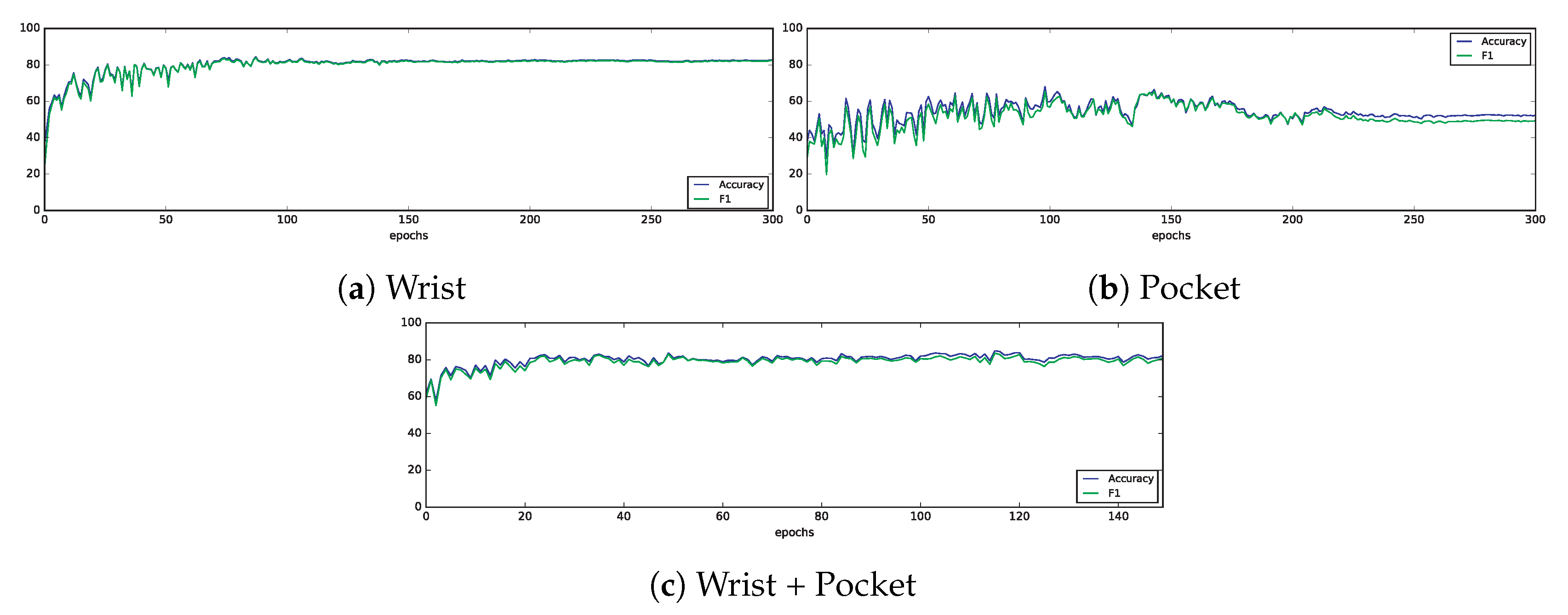
2.3.2. Deep Learning Methods
The experiments performed with convolutional neural networks were executed in a workstation comprising 2 Intel Xeon E5-2667 CPUs running at 3.20 GHz, 128 GB of RAM memory, and four NVIDIA TESLA P100 GPUs, plus one Titan Xp GPU.
This workstation has been equipped with the following software packages:
numpy 1.13.1,
scipy 0.19.0 and
scikit-learn 0.18.1. For deep learning we have decided to use the Theano framework [
32] in its version
theano 0.9.0, as well as
lasagne 0.2.dev1 library for simplifying the creation of the network architecture.
In order to train and evaluate the convolutional neural network using the GPUs, we have installed CUDA Toolkit 8.0, cuDNN 6.0 primitives and pygpu 0.6.9.
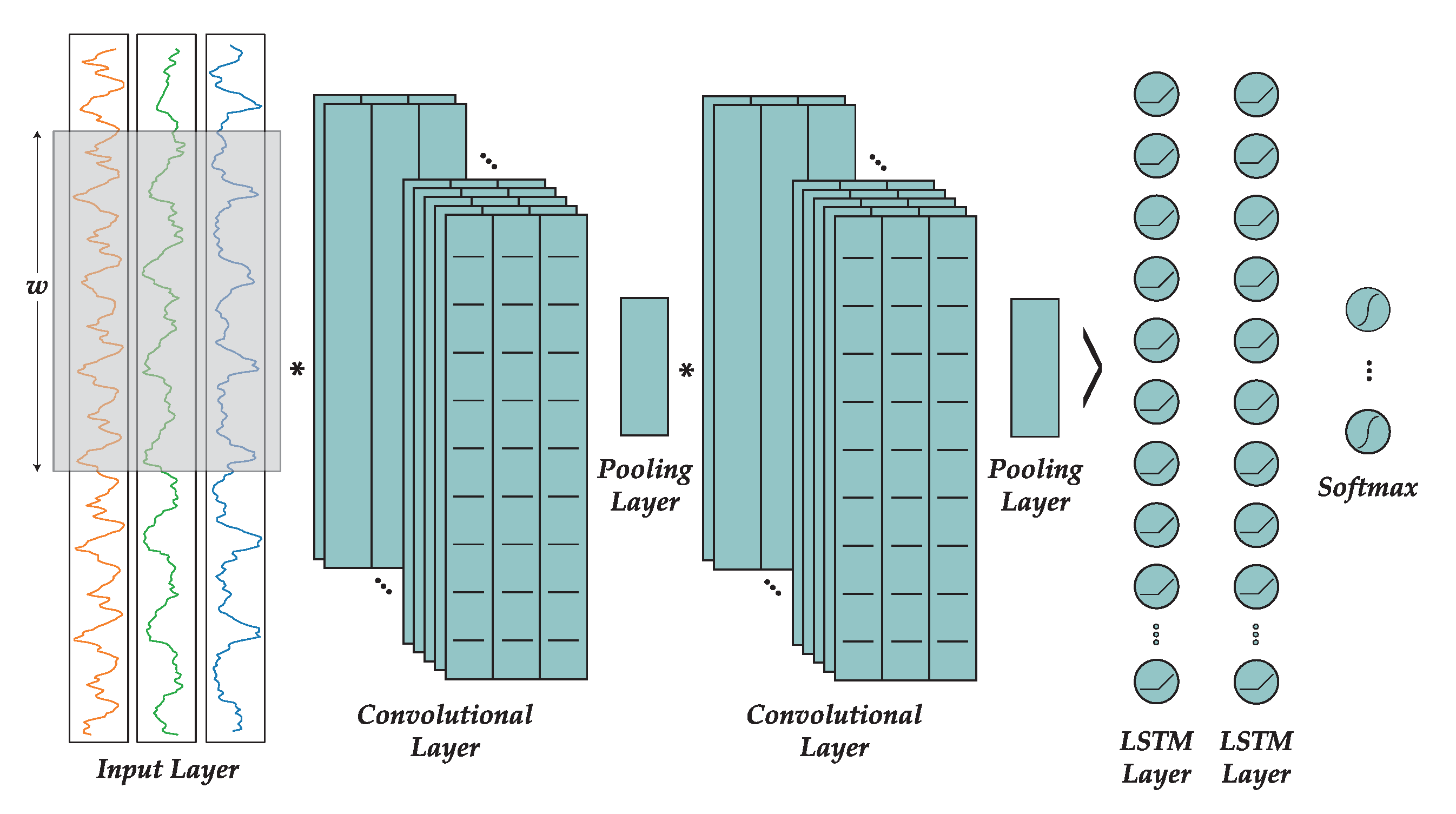
In
Section 2.1.7 we already described the topology of the CNN, decided after manually trying different architectures. This architecture is shown in
Figure 8. The network comprises three convolutional layers, each of them with 64 kernels of size 10 and ReLU activation function. After every convolutional layer there is a pooling layer of size 2 in order to halve the size of the feature maps. Later, the output feature maps are flattened and introduced into a recurrent network consisting on two layers with 128 LSTM cells each, and ReLU activation function, with a 50% of dropout regularization. Finally, the output is passed through a softmax function to normalize the values between 0 and 1 in order to complete the classification process.
We have chosen a window length of , as it was the value tested with classical machine learning techniques. However, in this case we used a step of , since deep learning techniques benefit from the availability of large quantities of data. For the wrist and pocket datasets, minibatches of windows were introduced to the network, whereas for the combined dataset the batch size was of . These values were as large as possible to avoid too much stochasticity during training, while allowing the data to fit in memory.
For the learning rate, we established an initial value of , which was adjusted over time in order to reduce it by 0.95 every time the train error increased from one epoch to the next. By doing so, we can achieve a fast optimization at the beginning, providing a fine tuning of the network parameters in the end and avoiding the algorithm from diverging.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}