Motion Estimation-Assisted Denoising for an Efficient Combination with an HEVC Encoder


Abstract
:1. Introduction
2. Proposed Video Denoising through the Combination with HEVC
2.1. Overview
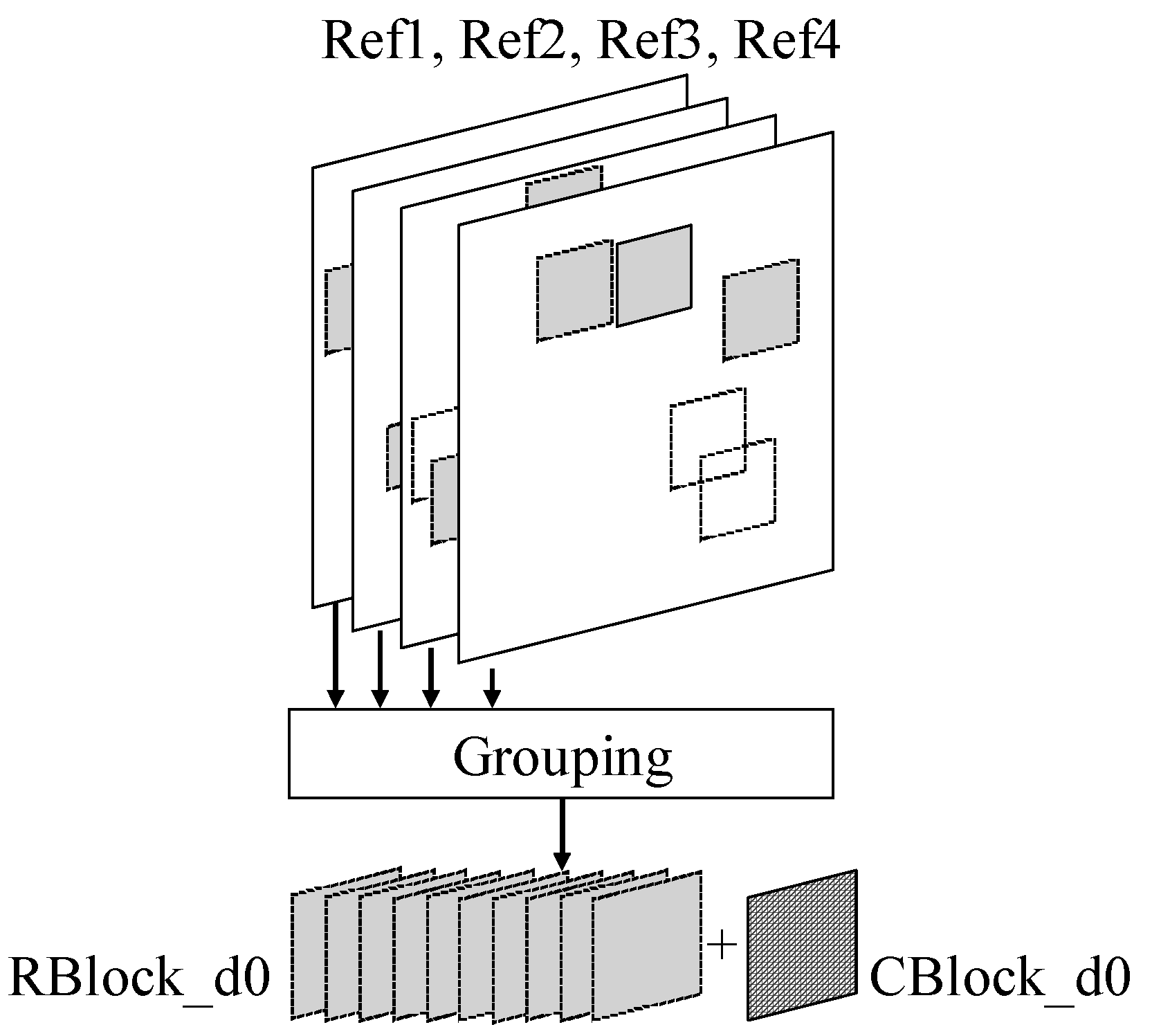
2.2. Integer Motion Estimation-Based Grouping
2.3. Depth Hierarchy-Based Aggregation
2.4. Early Denoising Termination
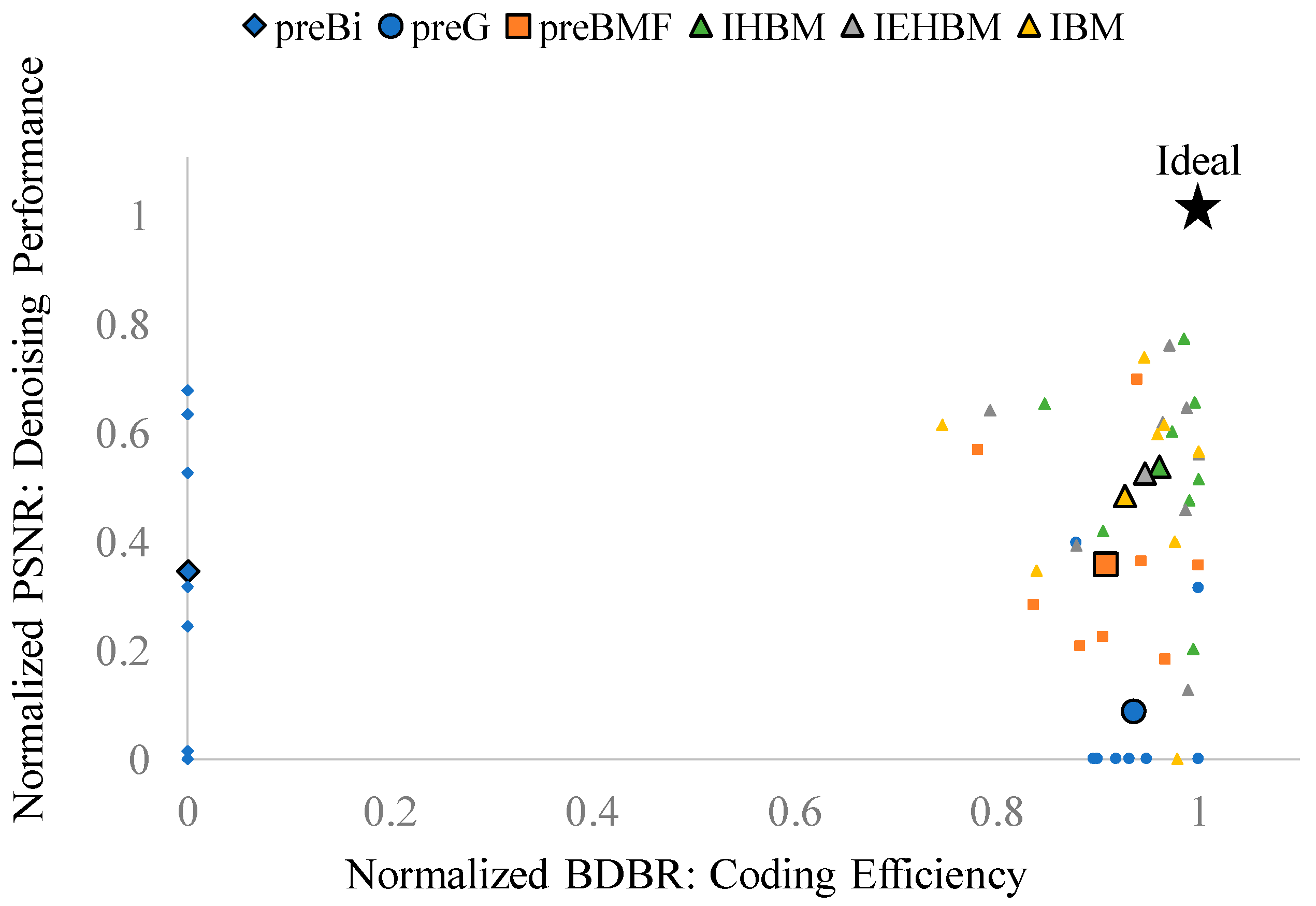
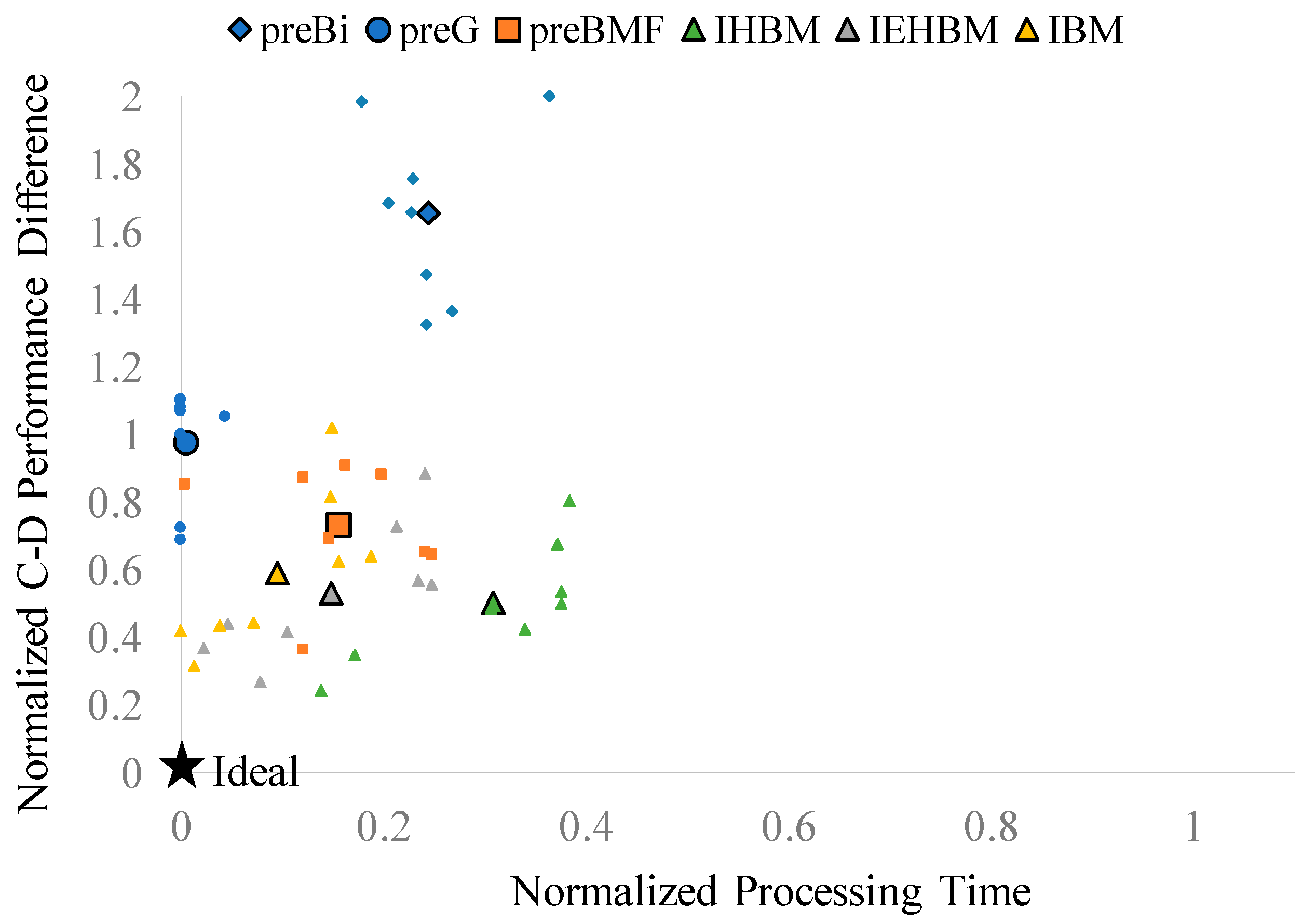
3. Performance Evaluation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Sullivan, G.J.; Ohm, J.-R.; Han, W.-J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bossen, F.; Bross, B.; Suhring, K.; Flynn, D. HEVC Complexity and Implementation Analysis. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1685–1696. [Google Scholar] [CrossRef] [Green Version]
- Shen, L.; Liu, Z.; Zhang, X.; Zhao, W.; Zhang, Z. An Effective CU Size Decision Method for HEVC Encoders. IEEE Trans. Multimedia 2013, 15, 465–470. [Google Scholar] [CrossRef]
- Ohm, J.-R.; Sullivan, G.J.; Schwarz, H.; Tan, T.K.; Wiegand, T. Comparison of the Coding Efficiency of Video Coding Standards—Including High Efficiency Video Coding (HEVC). IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1669–1684. [Google Scholar] [CrossRef]
- Faraji, H.; MacLean, W.J. CCD Noise Removal in Digital Images. IEEE Trans. Image Process. 2006, 15, 2676–2685. [Google Scholar] [CrossRef] [PubMed]
- Tian, H.; Fowler, B.; Gamal, A.E. Analysis of Temporal Noise in CMOS Photodiode Active Pixel Sensor. IEEE J. Solid-State Circuits 2001, 36, 92–101. [Google Scholar] [CrossRef]
- Gow, R.D.; Renshaw, D.; Findlater, K.; Grant, L.; McLeod, S.J.; Hart, J.; Nicol, R.L. A Comprehensive Tool for Modeling CMOS Image-Sensor-Noise Performance. IEEE Trans. Electron Devices 2007, 54, 1321–1329. [Google Scholar] [CrossRef]
- JCT-VC HEVC reference software version HM 16.10. Available online: https://hevc.hhi.fraunhofer.de/svn/svn_HEVCSoftware/tags/HM-16.10 (accessed on 10 November 2018).
- Motwani, M.C.; Gadiya, M.C.; Rakhi, C.; Motwani, R.C.; Harris, F.C. Survey of Image Denoising Techniques. In Proceedings of the International Global Signal Processing Conference, Santa Clara, CA, USA, 12–15 September 2004; pp. 27–30. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising with Block-matching and 3D Filtering. In Proceedings of the Image Denoising with Block-matching and 3D Filtering, San Jose, CA, USA, 15–19 January 2006. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buades, A.; Coll, B.; Morel, J.M. A Non-local Algorithm for Image Denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Foi, A.; Katkovnik, V.; Egiazarian, K. Pointwise Shape Adaptive DCT for High-Quality Denoising and Deblocking of Grayscale and Color Images. IEEE Trans. Image Process. 2007, 16, 1395–1411. [Google Scholar] [CrossRef] [PubMed]
- Bennett, E.P.; McMillan, L. Video Enhancement using per Pixel Virtual Exposures. In Proceedings of the ACM SIGGRAPH 2005 Courses, Los Angeles, CA, USA, 31 July–4 August 2005; pp. 845–852. [Google Scholar]
- Chen, J.; Tang, C.-K. Spatio-Temporal Markov Random Field for Video Denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Dabov, K.; Foi, A.; Egiazarian, K. Video Denoising by Sparse 3D Transform-Domain Collaborative Filtering. In Proceedings of the 15th European Signal Processing Conference, Poznan, Poland, 3–7 September 2007. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A Review of Image Denoising Algorithms, with a New One. Multiscale Model. Simul. 2005, 4, 490–530. [Google Scholar] [CrossRef] [Green Version]
- Ji, H.; Huang, S.; Shen, Z.; Xu, Y. Robust video restoration by joint sparse and low rank matrix approximation. SIAM J. Imag. Sci. 2011, 4, 1122–1142. [Google Scholar] [CrossRef]
- Guo, H.; Vaswani, N. Video denoising via online sparse and low rank matrix decomposition. In Proceedings of the 2016 IEEE Statistical Signal Processing Workshop (SSP), Palma de Mallorca, Spain, 26–29 June 2016. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Wen, B.; Ravishankar, S.; Bresler, Y. VIDOSAT: High-Dimensional Sparsifying Transform Learning for Online Video Denoising. IEEE Trans. Image Process. 2019, 28, 1691–1704. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Giladi, A.; Pancorbo, F.G. Noise Reduction Prefiltering for Video Compression; Stanford Univ. Press: Stanford, CA, USA, 2008. [Google Scholar]
- Tang, M.; Han, Y.; Wen, J.; Yang, S. HEVC-based Motion Compensated Joint Temporal-Spatial Video Denoising. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1797–1801. [Google Scholar]
- Zhang, X.; Xiong, R.; Lin, W.; Ma, S.; Liu, J.; Gao, W. Video Compression Artifact Reduction via Spatio-Temporal Multi-Hypothesis Prediction. IEEE Trans. Image Process. 2015, 24, 6048–6061. [Google Scholar] [CrossRef] [PubMed]
- Dar, Y.; Bruckstein, A.M.; Elad, M.; Giryes, R. Postprocessing of Compressed Images via Sequential Denoising. IEEE Trans. Image Process. 2016, 25, 3044–3058. [Google Scholar] [CrossRef] [PubMed]
- Recommendation ITU-T H.265, MPEG H-Part 2: High Efficiency Video Coding, ISO/IEC 23008-2, 2013. Available online: https://www.itu.int/rec/T-REC-H.265-201304-S/en (accessed on 10 November 2018).
- Pan, Z.; Lei, J.; Zhang, Y.; Wang, F.L. Adaptive Fractional-Pixel Motion Estimation Skipped Algorithm for Efficient HEVC Motion Estimation. ACM Trans. Multimedia Comput. Commun. Appl. 2018, 14, 1. [Google Scholar] [CrossRef]
- Pan, Z.; Yi, X.; Chen, L. Motion and Disparity Vectors Early Determination for Texture Video in 3D-HEVC. Multimedia Tools Appl. 2018, 1–18. [Google Scholar] [CrossRef]
- Pan, Z.; Chen, L.; Sun, X. Low Complexity HEVC Encoder for Visual Sensor Networks. Sensors 2015, 15, 30115–30125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lebrun, M. An Analysis and Implementation of the BM3D Image Denoising Method. Image Process. Line 2012. [Google Scholar] [CrossRef]
- Jehng, Y.S.; Chen, L.G.; Chiueh, T.D. An Efficient and Simple VLSI Tree Architecture for Motion Estimation Algorithms. IEEE Trans. Signal Process. 1993, 41, 2. [Google Scholar]
- Shafique, M.; Bauer, L.; Henkel, J. 3-Tier Dynamically Adaptive Power-Aware Motion Estimator for H.264/AVC Video Encoding. In Proceedings of the 13th international symposium on Low power electronics and design (ISLPED ’08), Bangalore, India, 11–13 August 2008. [Google Scholar]
- Shafique, M.; Bauer, L.; Henkel, J. enBudget: A Run-Time Adaptive Predictive Energy-Budgeting Scheme for Energy-Aware Motion Estimation in H.264/MPEG-4 AVC Video Encoder. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE 2010), Dresden, Germany, 8–12 March 2010. [Google Scholar]
- Khan, M.U.K.; Shafique, M.; Henkel, J. Software Architecture of High Efficiency Video Coding for Many-core Systems with Power Efficient Workload Balancing. In Proceedings of the conference on Design, Automation & Test in Europe, Dresden, Germany, 24–28 March 2014. [Google Scholar]
- El-Harouni, W.; Rehman, S.; Prabakaran, B.S.; Kumar, A.; Hafiz, R.; Shafique, M. Embracing Approximate Computing for Energy-Efficient Motion Estimation in High Efficiency Video Coding. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017. [Google Scholar]
- Shafique, M.; Khan, M.U.K.; Henkel, J. Power Efficient and Workload Balanced Tiling for Parallelized High Efficiency Video Coding. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014. [Google Scholar]
- Shafique, M.; Henkel, J. Low Power Design of the Next-Generation High Efficiency Video Coding. In Proceedings of the 19th Asia and South Pacific Design Automation Conference (ASP-DAC), Singapore, 20–23 January 2014. [Google Scholar]
- Bjontegaard, G. Calculation of average PSNR differences between RD curves. In Proceedings of the 13th VCEG-M33 Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video Sequence | Bitrate (Mbps) | ||
|---|---|---|---|
| Clean | Noisy | ||
| video | video | ||
| ClassB | Kimono | 3.89 | 78.28 |
| BasketballDrive | 7.34 | 163.54 | |
| ClassC | BasketballDrill | 2.17 | 33.07 |
| BQMall | 3.05 | 40.64 | |
| ClassD | BasketballPass | 0.61 | 8.37 |
| BQSquare | 1.63 | 10.48 | |
| ClassE | FourPeople | 2.39 | 87.72 |
| Johnny | 1.76 | 85.98 | |
| Average | 3.18 | 30.98 | |
| VideoSequence | BDBR (%) | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | ||||||||||||||||||||||
| σ = 15 LD | σ = 15 RA | σ = 25 LD | ||||||||||||||||||||
| preBi | preG | preBM | preBMF | IBM | IHBM | IEHBM | preBi | preG | preBM | preBMF | IBM | IHBM | IEHBM | preBi | preG | preBM | preBMF | IBM | IHBM | IEHBM | ||
| ClassB | Kimono | −80.9 | −96.8 | −99.0 | −97.9 | −98.6 | −98.8 | −98.9 | −83.6 | −97.5 | −99.3 | −98.5 | −98.8 | −99.1 | −99.0 | −76.4 | −94.0 | −98.9 | −98.9 | −99.0 | −99.1 | −99.0 |
| 34.4 | 35.4 | 37.0 | 36.2 | 34.4 | 34.9 | 34.7 | 35.4 | 36.2 | 37.7 | 37.0 | 35.7 | 36.1 | 36.0 | 29.9 | 32.3 | 34.9 | 35.0 | 31.9 | 32.5 | 32.3 | ||
| BasketballDrive | −78.0 | −97.0 | −99.2 | −98.0 | −98.7 | −98.9 | −99.0 | −81.2 | −97.9 | −99.5 | −98.9 | −99.2 | −99.3 | −99.3 | −54.1 | −93.9 | −99.0 | −99.0 | −98.8 | −99.0 | −99.0 | |
| 34.2 | 32.7 | 37.3 | 34.4 | 34.6 | 34.9 | 34.8 | 35.4 | 33.3 | 38.3 | 34.8 | 35.0 | 35.5 | 35.4 | 29.4 | 30.8 | 35.3 | 35.3 | 31.6 | 32.5 | 32.0 | ||
| ClassC | BasketballDrill | −74.7 | −96.2 | −97.8 | −95.1 | −94.1 | −95.0 | −95.6 | −78.0 | −97.1 | −98.4 | −96.3 | −94.6 | −95.8 | −95.5 | −50.7 | −93.9 | −97.4 | −96.6 | −96.5 | −97.4 | −97.0 |
| 32.3 | 30.2 | 34.2 | 31.1 | 31.6 | 31.9 | 31.8 | 33.1 | 30.4 | 34.5 | 31.2 | 32.4 | 32.6 | 32.5 | 27.8 | 28.9 | 32.2 | 32.1 | 29.7 | 29.7 | 29.7 | ||
| BQMall | −70.4 | −96.0 | −96.0 | −90.4 | −89.5 | −90.7 | −92.1 | −74.2 | −97.1 | −97.2 | −92.1 | −89.2 | −91.0 | −90.3 | −47.3 | −92.7 | −95.8 | −95.6 | −94.5 | −96.1 | −95.3 | |
| 30.7 | 27.3 | 32.3 | 30.1 | 30.4 | 30.6 | 30.5 | 31.5 | 27.5 | 32.7 | 30.5 | 31.1 | 31.3 | 31.3 | 26.5 | 26.6 | 30.1 | 29.9 | 28.1 | 28.1 | 28.1 | ||
| ClassD | BasketballPass | −74.3 | −96.4 | −97.6 | −93.8 | −96.8 | −97.3 | −97.5 | −77.1 | −97.1 | −98.1 | −94.8 | −96.7 | −97.3 | −97.2 | −50.5 | −93.1 | −97.3 | −97.1 | −98.0 | −98.5 | −98.3 |
| 31.7 | 28.9 | 33.4 | 30.1 | 31.6 | 31.8 | 31.8 | 32.4 | 29.2 | 33.6 | 30.5 | 32.4 | 32.5 | 32.5 | 26.4 | 27.9 | 31.2 | 31.0 | 29.5 | 29.5 | 29.5 | ||
| BlowingBubbles | −40.6 | −94.6 | −93.6 | −94.6 | −91.7 | −93.8 | −93.0 | −45.9 | −96.2 | −95.2 | −89.2 | −91.6 | −93.5 | −92.9 | −46.2 | −91.8 | −94.5 | −94.3 | −96.3 | −97.2 | −96.7 | |
| 26.5 | 27.9 | 31.0 | 28.1 | 29.8 | 30.0 | 29.9 | 27.0 | 27.9 | 31.3 | 28.5 | 30.6 | 30.8 | 30.8 | 26.3 | 27.1 | 29.0 | 29.0 | 27.6 | 27.6 | 27.6 | ||
| ClassE | FourPeople | −77.2 | −97.5 | −99.3 | −97.2 | −98.4 | −98.5 | −98.7 | −79.8 | −98.2 | −99.5 | −98.0 | −97.7 | −98.1 | −97.9 | −52.4 | −94.0 | −98.6 | −98.6 | −99.1 | −99.2 | −99.1 |
| 33.3 | 31.9 | 36.1 | 32.8 | 34.4 | 34.4 | 34.5 | 34.2 | 32.1 | 36.6 | 33.1 | 35.0 | 35.1 | 35.1 | 28.3 | 30.2 | 33.7 | 33.7 | 32.0 | 32.0 | 32.0 | ||
| Johnny | 78.9 | 97.7 | 99.8 | 99.1 | 99.8 | 99.8 | 99.8 | −81.7 | −98.4 | −99.9 | −99.5 | −99.9 | −99.9 | −99.9 | −54.9 | −94.4 | −99.5 | −99.5 | −99.8 | −99.8 | −99.8 | |
| 34.8 | 33.6 | 38.4 | 34.5 | 36.3 | 36.1 | 36.3 | 35.9 | 34.0 | 39.0 | 34.8 | 37.4 | 37.3 | 37.4 | 29.7 | 31.4 | 36.3 | 36.2 | 34.1 | 34.1 | 34.1 | ||
| Average | −71.9 | −96.5 | −97.8 | −95.8 | −96.0 | −96.6 | −96.8 | −75.2 | −97.4 | −98.4 | −95.9 | −96.0 | −96.8 | −96.5 | −54.1 | −93.5 | −97.6 | −97.5 | −97.8 | −98.3 | −98.0 | |
| 32.2 | 31.0 | 35.0 | 32.2 | 32.9 | 33.1 | 33.0 | 33.1 | 31.3 | 35.5 | 32.5 | 33.7 | 33.9 | 33.9 | 28.0 | 29.4 | 32.8 | 32.8 | 30.5 | 30.7 | 30.7 | ||
| Video Sequence | Total Time/Frame (sec) | |||||||
|---|---|---|---|---|---|---|---|---|
| Denoising Time/Frame (sec) | ||||||||
| preBi | preG | preBM | preBMF | IBM | IHBM | IEHBM | ||
| ClassB | Kimono | 45.63 | 39.08 | 75.79 | 43.53 | 44.59 | 53.16 | 47.93 |
| 0.20 | 0.05 | 43.50 | 7.30 | 6.70 | 14.50 | 9.80 | ||
| BasketballDrive | 45.67 | 38.23 | 74.54 | 43.58 | 43.91 | 51.89 | 47.25 | |
| 0.20 | 0.05 | 42.40 | 7.30 | 8.10 | 14.10 | 9.80 | ||
| ClassC | BasketballDrill | 8.50 | 6.80 | 13.81 | 7.94 | 7.83 | 9.41 | 8.30 |
| 0.04 | 0.01 | 7.70 | 1.20 | 1.70 | 2.50 | 2.00 | ||
| BQMall | 8.38 | 6.61 | 13.88 | 8.37 | 7.97 | 9.35 | 8.32 | |
| 0.04 | 0.01 | 7.90 | 1.20 | 1.50 | 2.40 | 1.50 | ||
| ClassD | BasketballPass | 1.88 | 1.47 | 3.24 | 1.75 | 1.38 | 1.70 | 1.43 |
| 0.01 | 0.00 | 2.00 | 0.30 | 0.40 | 0.60 | 0.50 | ||
| BlowingBubbles | 2.39 | 1.70 | 3.59 | 2.17 | 1.73 | 1.96 | 1.85 | |
| 0.01 | 0.00 | 1.80 | 0.30 | 0.30 | 0.40 | 0.30 | ||
| ClassE | FourPeople | 16.86 | 13.31 | 28.89 | 15.21 | 14.44 | 18.62 | 14.95 |
| 0.10 | 0.02 | 18.30 | 2.70 | 2.90 | 5.70 | 3.50 | ||
| Johnny | 17.05 | 13.73 | 28.19 | 13.78 | 14.28 | 18.16 | 14.41 | |
| 0.10 | 0.02 | 18.60 | 2.70 | 2.90 | 6.10 | 3.10 | ||
| Average | 18.30 | 15.11 | 30.24 | 17.04 | 17.02 | 20.53 | 18.06 | |
| 0.09 | 0.02 | 17.78 | 2.88 | 3.06 | 5.79 | 3.81 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.-Y.; Rhee, C.E. Motion Estimation-Assisted Denoising for an Efficient Combination with an HEVC Encoder. Sensors 2019, 19, 895. https://doi.org/10.3390/s19040895
Lee S-Y, Rhee CE. Motion Estimation-Assisted Denoising for an Efficient Combination with an HEVC Encoder. Sensors. 2019; 19(4):895. https://doi.org/10.3390/s19040895
Chicago/Turabian StyleLee, Seung-Yong, and Chae Eun Rhee. 2019. "Motion Estimation-Assisted Denoising for an Efficient Combination with an HEVC Encoder" Sensors 19, no. 4: 895. https://doi.org/10.3390/s19040895
APA StyleLee, S. -Y., & Rhee, C. E. (2019). Motion Estimation-Assisted Denoising for an Efficient Combination with an HEVC Encoder. Sensors, 19(4), 895. https://doi.org/10.3390/s19040895