Surveillance for security and monitoring serves the purpose of human or object intrusion detection/trespassers within the protected environment. Traditional approach involves camera based human supported monitoring, which is a challenge to monitor several camera screens at the same time by one or multiple guards specifically within a factory, smart city, research laboratory, university campuses and various commercial and private sectors [
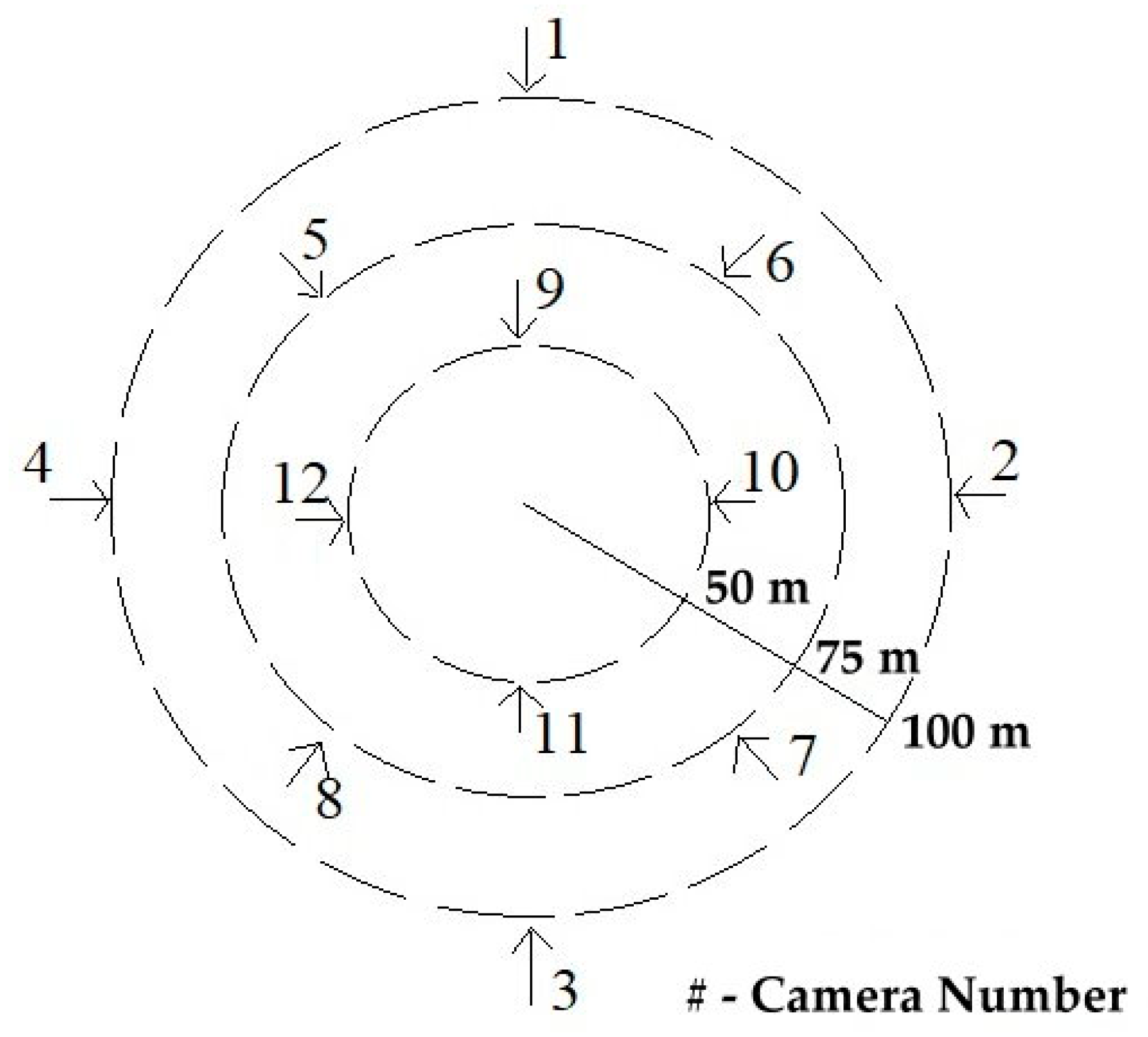
1]. There are usually many stationary cameras on the streets or specific areas of a factory. For real cases in Taiwan, there are at least 1000 cameras in a physical crystal optical factory to ensure the safety of dock workers, and detect intrusions. For the same case, twelve dedicated employees of the environmental safety department spent four hours per day to check whether dock workers following the working procedures or not. For another example, it takes average of 1–2 days by uncountable police officers to find out the escaping path of critical crimes such as bank robbing by manually image tracking from cameras standing on the main cross streets.
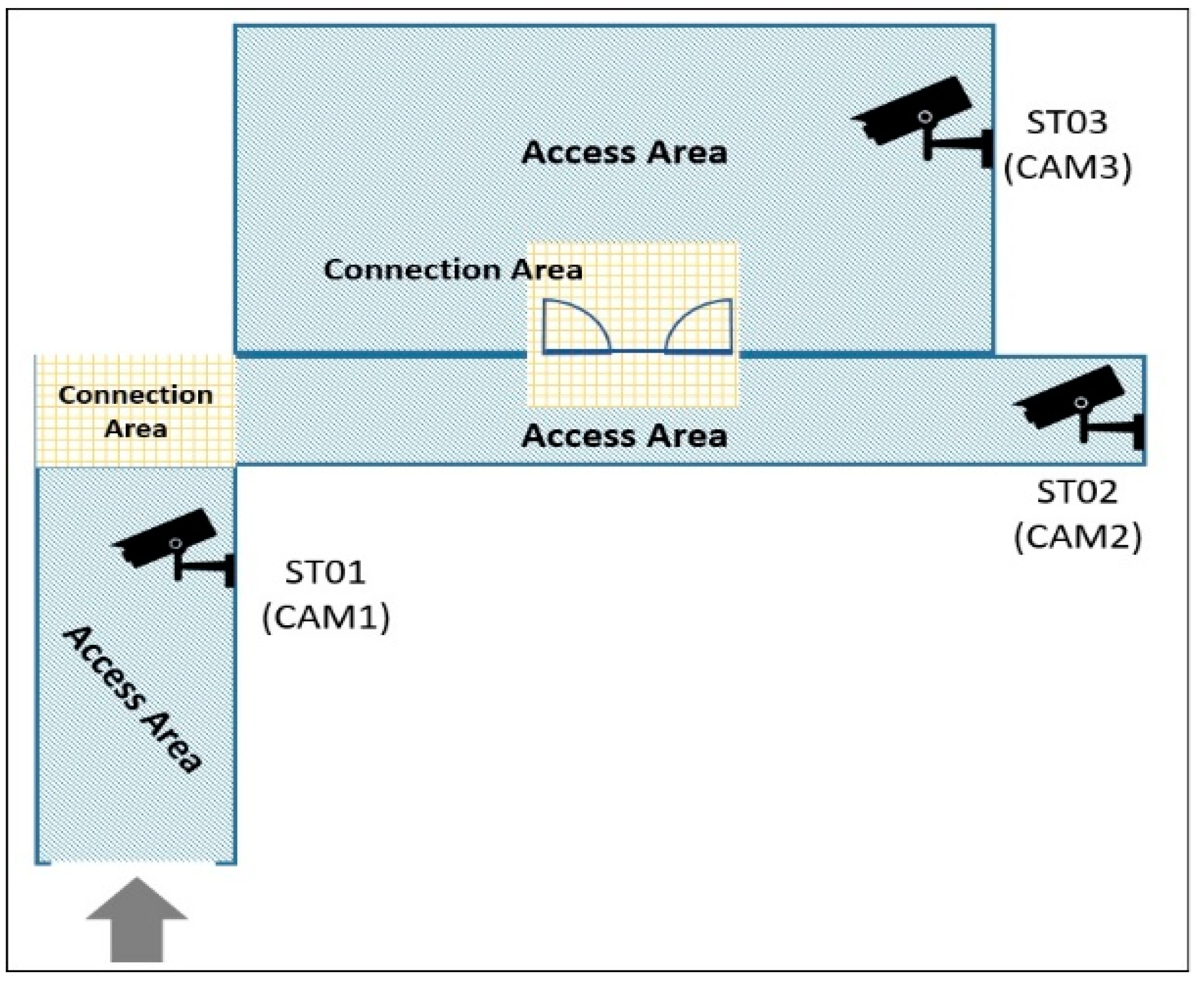
There are several scenarios are taken into consideration for the development and implementation of suspicious tracking across multiple cameras based on correlation filters (STAM-CCF). For universities, it is usually an open and large area and almost everyone can get into campus without identification checking. For the safety of students, once an intruder gets into the campus and is being identified as a suspicious person, the video surveillance system should automatically track and show the path of the movements of the intruder to the related administrators and security guards. For the use cases of factories, usually the areas and spaces are designed for specific fabrication processes with high-cost equipment. Only authorized persons can get into such working areas. Once a suspicious person breaks in, an alarm will be triggered, and the security system would send the images, movements and location of the intruder to management. The STAM-CCF will play the role of event trigger and information provider in factory scenarios. For future applications such as smart city, a smart city consists of several aspects for its smooth functioning. Traffic management is one of the crucial parts, which needs to be managed. If over speeding is detected of any kind of vehicle, then several accidents can be avoided before time. Route congestion can be notified in advance before heading towards it. Accident cases can be detected on highways, thus alerting nearby hospitals to provide emergency help services. Disaster management is a state emergency that can detect public rush in a particular area affected by flooding, tornado, earthquake, etc., to get rescue help. A disease outburst can also be avoided if suspicious patterns are captured in an area, where multiple people are getting sick and hence can be helpful to be controlled on time. Also, if a suspicious object is kept in a public area such as market, airports, railway stations, parks, it can be a cautious step towards safety. STAM-CCM will play an important role for security surveillance in the future.
1.2. Literature Survey:
Previous within-camera tracking related studies majorly focus on one-camera application scenarios and aggregate all video streams in a grid screen monitored by a human. Due to the inconvenience of usage, time-consuming and human support cost, the research on multi-camera tracking came out with some results recently. Several intelligent video surveillance functions were also recently introduced to the market, and can be divided into two kinds of methods, which are learning-based and non-learning based. The idea of STAM-CCF mainly comes from previous multiple camera related studies, especially for the combination usage of different features-based methods, and the usage of a two-stage mechanism. In addition, for the implementation purpose, several image pre-processing techniques were also introduced in the following.
Suspicious tracking and detection surveys presented by Tripathi et al. [
2], have been studied extensively to detect various kinds of abnormal behaviors for images from a single camera. Non-learning-based methods are used to compare fine-grained characteristics to classify user behaviors. For example, feature extraction is performed on an image to capture features either by way of feature based or by tracking based of a particular person. Users can capture feature-based tracking by using several ways of detection by a change in head positions, change in boundary box by a particular height, and width, etc. The classification methods applied include various aspects of person based on posture, shape of the body and motion captured in the video. Several classifiers are included within its experiment and they are k-Nearest Neighbor, Support Vector Mechanism, Hidden Markov Model, Multi-Class Support Vector Mechanism, Haar-feature based cascade classifiers (HAAR), Four-layered Multilayer Perceptron (Four-layered MLP), Fuzzy Logic, etc.
Another widely used one-camera application scenario is the static camera. Such kind of applications are quite progressed through research, regarding theft detection in day-to-day life events in public/private zones. Banks and airports have daily customers and travelers, so human activities are recognized based on single-threaded ontology to avoid robbery and attacks respectively, as presented by Akdemir et al. [
3]. Unusual activities/suspicious activities are also detected by a fuzzy c-means algorithm using a ratio histogram suggested by Chuang et al. [
4]. Robbery cases are also detected using a forward-backward ratio histogram and a finite state machine (FSM) which proved to have better accuracy and efficiency than that proposed by Chuang et al. [
5]. Assaulting and theft/stealing is also detected by using a stochastic representation scheme and a hierarchical algorithm for probabilistic recognition. Automated learning of group activities can be used to overcome the limitation of a system that faces struggles amongst group interactions as presented by Ryoo and Aggarwal [
6]. Snatch theft is also one of the growing issues that is overcome by using extracting information from optical flow to detect suspicious activities using surveillance video. In the next stage, to confirm whether the theft actual occurrence is done by using flow pattern statistics is being presented by Ibrahim et al. [
7]. Automated teller machines (ATM) crimes are also considered to detect human unusual activities by using multiple object detection and noticing suspicious activities. A classifier is used as utilizing features within the surveillance video. Here, the system may face a limitation of partial occlusion as presented by Sujith [
8].
Multi-camera coordination and control (MC3) surveillance strategies provides survey for several state-of-art multi-camera coordination and control strategies presented by Natarajan et al. [
1]. There are several computer vision techniques for detecting an object, tracking its movements, analyzing its behavior and storing its pattern as presented by Valera et al. [
9]. Techniques developed for activity analysis that are used in surveillance by using trajectory based is presented by Morris et al. [
10]. By integrating various sensors, multi-sensors face challenges associated with how the modality is selected, i.e., how can the data fusion be achieved? Furthermore, how are the sensors planned for their implementation? These questions were presented by Abidi et al. [
11]. Multi-cameras are also used in object detection and its tracking by using several computer vision techniques as presented by Javed et al. [
12]. Hybrid techniques of computer vision, data fusion and smart camera networks explore various limitations in architecture, middleware, calibration and compression in multi cameras as shown by Aghajan et al. [
13]. Other computer vision techniques include synchronizing cameras, the communication done within them, and the target correspondence, all of which is presented by Kim et al. [
14]. Platforms for hardware and software required for wireless sensor nodes for video surveillance is presented by Seema et al. [
15]. Acquiring the highlights from wide area network-based camera technology and its analysis is presented by Chowdhury et al. [
16]. Algorithms for the purpose of image processing, vision computing, video coding and visual sensor network platforms is presented by Tavli et al. [
17]. Re-identification process used for people re-identification in practical issues and some genuine ways to overcome it is presented by Vezzani et al. [
18]. Sparse camera network for capturing target correspondence across cameras and summarizing its activities by using computer vision techniques is presented by Song et al. [
19]. A convolution neural network with the loss function similar to neighborhood components analysis (NCA-net) had been proposed to tackle challenges of multiple objects across multiple cameras. Such challenges are caused by low resolution, variation of illumination, complex backgrounds and posture change [
20]. Integration of different computer vision and pattern recognition in surveillance done by multiple camera’s using computer vision techniques is presented by Wang et al. [
21]. Security and privacy protection for privacy preserving techniques, major security threats and challenges related to visual sensor networks, which are able to perform on board processing and communication components is presented by Winkler et al. [
22]. Self-configuration of autonomous smart cameras used for discovery of task topology, calibration, allocation of task and active vision are the various challenges in smart camera network presented by Miguel et al. [
23].
There are still many image processing skills used in the STAM-CCF implementation phase to overcome the problem of low-quality images gathering from multiple cameras. These pre-processing skills are important for learning based algorithms whose learning model is built based on good image quality. Robust visual tracking overcomes the challenges faced by non-stationary image streams changing over time in the presence of significant variations of surrounding illumination. Referring to fixed appearance models ignoring shape changes or lightning conditions. Ross et al. [
24] presented a tracking method that learns incrementally low-dimensional subspace representation, which displays efficiency in adapting to changes online in the target appearance. There are two important features used of principal component analysis for improving overall tracking performance. These are methods for achieving accuracy in every update of the sample mean and a forgetting factor used for fitting older observations is provided with less modelling power. This work contributes significantly for tracking algorithm in indoor and outdoor environments, including the scaling, posing and illumination changes in the target object. One of the popular techniques, that overcomes the issues of traditional biometrics is the gait recognition by J. Luo et al. [
25]. The objectives are achieved by using gait energy image (GEI) and accumulated frame difference energy image (AFDEI), which are gait sequences static and dynamic characteristics, with time characteristics, respectively. Hence, compared to single feature, it obtains better results by combination of above two characteristics. The experimental results claim to have generated better results on the CASIA_B gait database with a high recognition rate. CASIA_B, a gait dataset, was created from the Institute of Automation, Chinese Academy of Sciences.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}