Construction of All-in-Focus Images Assisted by Depth Sensing


Abstract
:1. Introduction
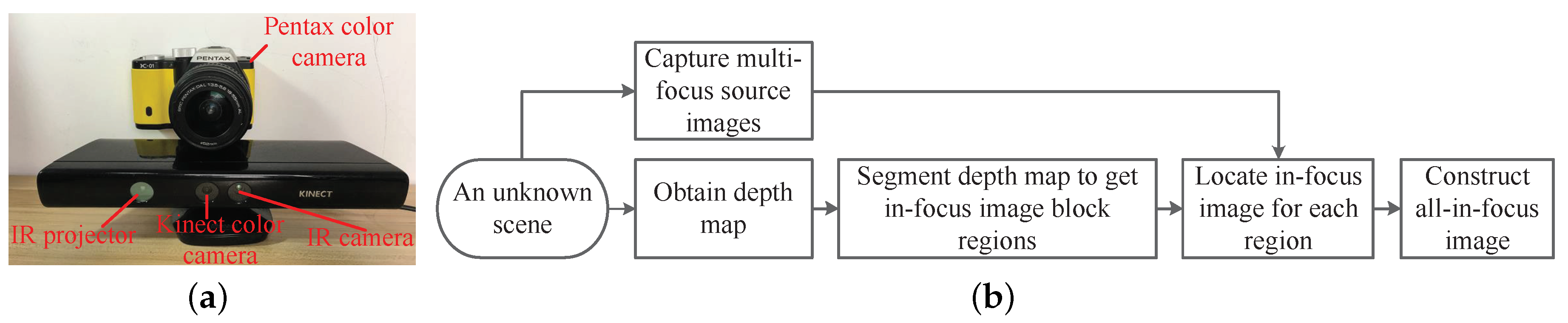
2. Multi-Focus Image Fusion System
3. Detailed Methods
3.1. Depth Map Preprocessing
3.1.1. Align Depth Map with Colour Image
3.1.2. Depth Map Hole Filling
3.2. Graph-Based Depth Map Segmentation
3.3. Construct All-in-Focus Image
4. Experiments
4.1. Evaluation Metrics
4.2. Source Images
4.3. Comparison Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Motta, D.; De Matos, L.; De Souza, A.C.; Marcato, R.; Paiva, A.; De Carvalho, L.A.V. All-in-focus imaging technique used to improve 3D retinal fundus image reconstruction. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015; pp. 26–31. [Google Scholar]
- Nguyen, C.N.; Ohara, K.; Avci, E.; Takubo, T.; Mae, Y.; Arai, T. Real-time precise 3D measurement of micro transparent objects using All-In-Focus imaging system. J. Micro-Bio Robot. 2012, 7, 21–31. [Google Scholar] [CrossRef]
- Liu, S.; Hua, H. Extended depth-of-field microscopic imaging with a variable focus microscope objective. Opt. Express 2011, 19, 353–362. [Google Scholar] [CrossRef] [PubMed]
- Bishop, T.E.; Favaro, P. The Light Field Camera: Extended Depth of Field, Aliasing, and Superresolution. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 972–986. [Google Scholar] [CrossRef] [PubMed]
- Gario, P. 4D Frequency Analysis of Computational Cameras for Depth of Field Extension. ACM Trans. Graph. 2009, 28, 341–352. [Google Scholar]
- Iwai, D.; Mihara, S.; Sato, K. Extended Depth-of-Field Projector by Fast Focal Sweep Projection. IEEE Trans. Vis. Comput. Graph. 2015, 21, 462–470. [Google Scholar] [CrossRef] [PubMed]
- Kuthirummal, S.; Nagahara, H.; Zhou, C.; Nayar, S.K. Flexible Depth of Field Photography. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 58–71. [Google Scholar] [CrossRef] [Green Version]
- Dowski, E.R.; Cathey, W.T. Extended depth of field through wave-front coding. Appl. Opt. 1995, 34, 1859–1866. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, L.; Sun, J. Optimized phase pupil masks for extended depth of field. Opt. Commun. 2007, 272, 56–66. [Google Scholar] [CrossRef]
- Zhao, H.; Li, Y. Optimized sinusoidal phase mask to extend the depth of field of an incoherent imaging system. Opt. Lett. 2008, 33, 1171–1173. [Google Scholar] [CrossRef]
- Cossairt, O.; Zhou, C.; Nayar, S. Diffusion coded photography for extended depth of field. ACM Trans. Graph. 2010, 29, 31. [Google Scholar] [CrossRef]
- Zhao, H.; Shang, Z.; Tang, Y.Y.; Fang, B. Multi-focus image fusion based on the neighbor distance. Pattern Recognit. 2013, 46, 1002–1011. [Google Scholar] [CrossRef]
- Li, S.; Yang, B.; Hu, J. Performance comparison of different multi-resolution transforms for image fusion. Inf. Fusion 2011, 12, 74–84. [Google Scholar] [CrossRef]
- Wan, T.; Zhu, C.; Qin, Z. Multifocus image fusion based on robust principal component analysis. Pattern Recognit. Lett. 2013, 34, 1001–1008. [Google Scholar] [CrossRef]
- Liang, J.; He, Y.; Liu, D.; Zeng, X. Image fusion using higher order singular value decomposition. Image Process. IEEE Trans. 2012, 21, 2898–2909. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar] [PubMed]
- Li, S.; Kang, X.; Hu, J.; Yang, B. Image matting for fusion of multi-focus images in dynamic scenes. Inf. Fusion 2013, 14, 147–162. [Google Scholar] [CrossRef]
- Mckee, G.T. Everywhere-in-focus image fusion using controlablle cameras. Proc. SPIE Int. Soc. Opt. Eng. 1996, 2905, 227–234. [Google Scholar]
- Ohba, K.; Ortega, J.C.P.; Tanie, K.; Tsuji, M.; Yamada, S. Microscopic vision system with all-in-focus and depth images. Mach. Vis. Appl. 2003, 15, 55–62. [Google Scholar] [CrossRef]
- Huang, W.; Jing, Z. Multi-focus image fusion using pulse coupled neural network. Pattern Recognit. Lett. 2007, 28, 1123–1132. [Google Scholar] [CrossRef]
- Xiao-Bo, Q.U.; Yan, J.W.; Xiao, H.Z.; Zhu, Z.Q. Image Fusion Algorithm Based on Spatial Frequency-Motivated Pulse Coupled Neural Networks in Nonsubsampled Contourlet Transform Domain. Acta Autom. Sin. 2008, 34, 1508–1514. [Google Scholar]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. Multi-focus image fusion with dense SIFT. Inf. Fusion 2015, 23, 139–155. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.; Zhao, J.; Laganière, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94. [Google Scholar] [CrossRef]
- Liu, Y.; Jing, X.Y.; Nie, J.; Gao, H.; Liu, J.; Jiang, G.P. Context-Aware Three-Dimensional Mean-Shift With Occlusion Handling for Robust Object Tracking in RGB-D Videos. IEEE Trans. Multimed. 2019, 21, 664–677. [Google Scholar] [CrossRef]
- Zhao, L.; Bai, H.; Liang, J.; Zeng, B.; Wang, A.; Zhao, Y. Simultaneous color-depth super-resolution with conditional generative adversarial networks. Pattern Recognit. 2019, 88, 356–369. [Google Scholar] [CrossRef]
- Yu, Q.; Liang, J.; Xiao, J.; Lu, H.; Zheng, Z. A Novel perspective invariant feature transform for RGB-D images. Comput. Vis. Image Underst. 2018, 167, 109–120. [Google Scholar] [CrossRef]
- Eichhardt, I.; Chetverikov, D.; Jankó, Z. Image-guided ToF depth upsampling: A survey. Mach. Vis. Appl. 2017, 28, 267–282. [Google Scholar] [CrossRef]
- Yang, Q.; Yang, R.; Davis, J.; Nistér, D. Spatial-Depth Super Resolution for Range Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Zhang, S.; Wang, C.; Chan, S.C. A New High Resolution Depth Map Estimation System Using Stereo Vision and Kinect Depth Sensing. J. Signal Process. Syst. 2015, 79, 19–31. [Google Scholar] [CrossRef]
- Khoshelham, K.; Elberink, S.O. Accuracy and resolution of kinect depth data for indoor mapping applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with microsoft kinect sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Vijayanagar, K.R.; Loghman, M.; Kim, J. Real-Time Refinement of Kinect Depth Maps Using Multi-Resolution Anisotropic Diffusion. Mob. Netw. Appl. 2014, 19, 414–425. [Google Scholar] [CrossRef]
- Perona, P. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Duthaler, S.; Nelson, B.J. Autofocusing in computer microscopy: selecting the optimal focus algorithm. Microsc. Res. Tech. 2004, 65, 139. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor Image Fusion Using the Wavelet Transform. In Proceedings of the 1994 International Conference on Image Processing, ICIP-94, Austin, TX, USA, 13–16 November 2002; pp. 235–245. [Google Scholar]
- Zhang, Q.; Guo, B.L. Multifocus image fusion using the nonsubsampled contourlet transform. Signal Process. 2009, 89, 1334–1346. [Google Scholar] [CrossRef]
- Hossny, M.; Nahavandi, S.; Creighton, D. Comments on ‘Information measure for performance of image fusion’. Electron. Lett. 2008, 44, 1066–1067. [Google Scholar] [CrossRef]
- Wang, Q.; Shen, Y.; Zhang, J.Q. A nonlinear correlation measure for multivariable data set. Phys. Nonlinear Phenom. 2005, 200, 287–295. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Mil. Tech. Cour. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, J.Q.; Wang, X.R.; Liu, X. A novel similarity based quality metric for image fusion. Inf. Fusion 2008, 9, 156–160. [Google Scholar] [CrossRef]
- Chen, Y.; Blum, R.S. A New Automated Quality Assessment Algorithm for Image Fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]









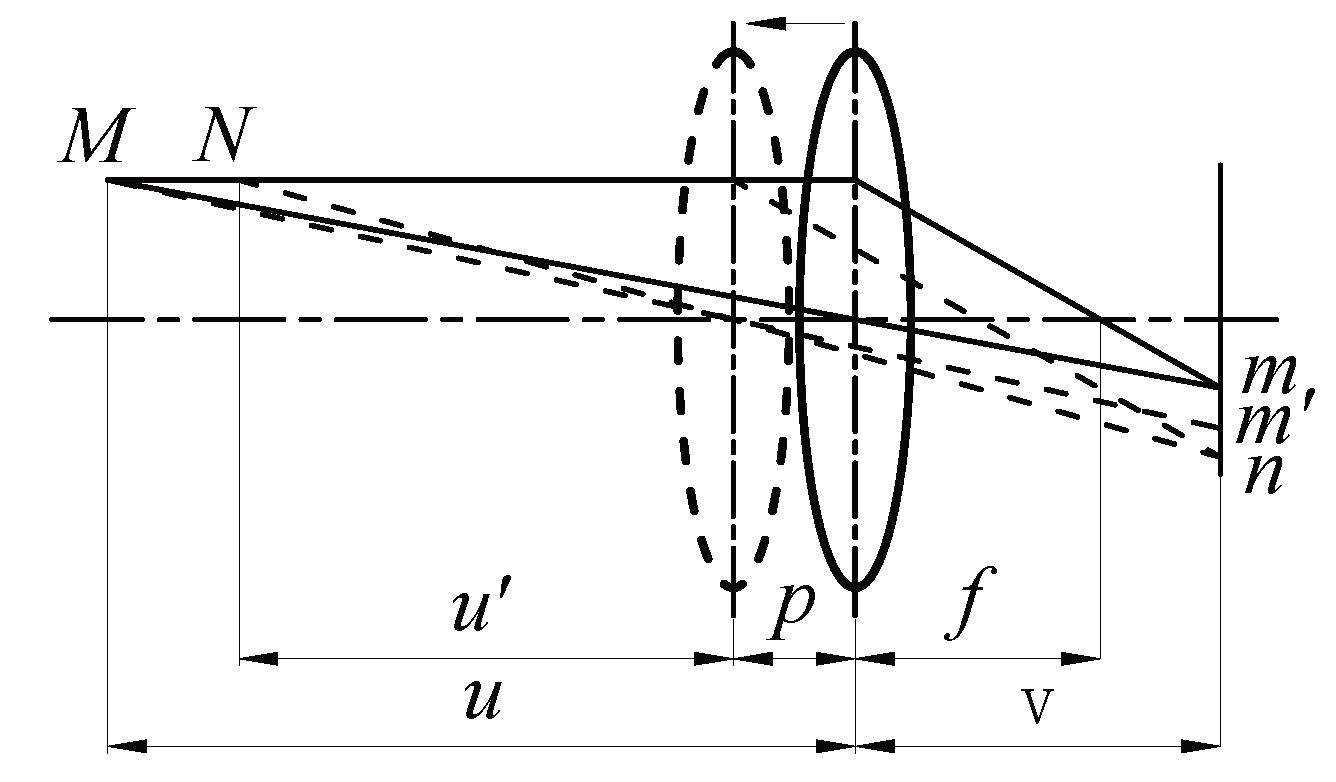{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | |||||
|---|---|---|---|---|---|
| 1 | 2722 | 3115 | 393 | 1526 | Yes |
| 2 | 2417 | 2639 | 222 | 1132 | Yes |
| 3 | 832 | 1360 | 528 | 207 | No |
| Region | |||||
|---|---|---|---|---|---|
| 1 | 2463 | 3140 | 677 | 1186 | Yes |
| 2 | 855 | 962 | 107 | 109 | Yes |
| 3 | 950 | 1085 | 135 | 136 | Yes |
| 4 | 1088 | 1269 | 181 | 182 | Yes |
| 5 | 1273 | 1412 | 139 | 257 | Yes |
| Scenes | Metrics | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|
| DWT | NSCT | IM | GF | NSCT-PCNN | DSIFT | DCNN | Ours | ||
| 1 | 1.1478(2) | 1.0451(1) | 1.3869(5) | 1.3402(4) | 1.3372(3) | 1.4235(8) | 1.3903(6) | 1.4201(7) | |
| 0.8463(2) | 0.8408(1) | 0.8629(4) | 0.8597(3) | 0.8646(6) | 0.8681(8) | 0.8635(5) | 0.8653(7) | ||
| 0.6694(3) | 0.4408(1) | 0.6998(5) | 0.6946(4) | 0.6421(2) | 0.7079(6) | 0.7094(7) | 0.7153(8) | ||
| 0.8344(2) | 0.7255(1) | 0.9129(8) | 0.9023(4) | 0.8516(3) | 0.9049(5) | 0.9112(7) | 0.9099(6) | ||
| 0.8992(2) | 0.7262(1) | 0.9548(5) | 0.9412(4) | 0.9275(3) | 0.9710(6) | 0.9721(7) | 0.9766(8) | ||
| 0.7372(2) | 0.6935(1) | 0.7688(5) | 0.7634(4) | 0.7977(8) | 0.7575(3) | 0.7708(6) | 0.7742(7) | ||
| 2 | 0.9504(2) | 0.8125(1) | 1.2323(7) | 1.1674(4) | 1.0457(3) | 1.2308(6) | 1.2250(5) | 1.2504(8) | |
| 0.8308(2) | 0.8250(1) | 0.8480(7) | 0.8426(4) | 0.8374(3) | 0.8468(6) | 0.8465(5) | 0.8489(8) | ||
| 0.6387(3) | 0.3889(1) | 0.6855(6) | 0.6747(4) | 0.5777(2) | 0.6834(5) | 0.6879(7) | 0.6954(8) | ||
| 0.8273(3) | 0.6922(1) | 0.9159(5) | 0.9175(6) | 0.8269(2) | 0.9141(4) | 0.9206(8) | 0.9191(7) | ||
| 0.9012(3) | 0.6908(1) | 0.9655(6) | 0.9431(4) | 0.8976(2) | 0.9627(5) | 0.9716(7) | 0.9832(8) | ||
| 0.7231(2) | 0.6681(1) | 0.7856(6) | 0.7627(3) | 0.7744(4) | 0.7832(5) | 0.7887(7) | 0.7977(8) | ||
| 3 | 0.9101(2) | 0.8422(1) | 1.1820(5) | 1.1500(4) | 1.0052(3) | 1.2015(7) | 1.1927(6) | 1.2089(8) | |
| 0.8284(2) | 0.8255(1) | 0.8437(5) | 0.8414(4) | 0.8344(3) | 0.8448(7) | 0.8442(6) | 0.8454(8) | ||
| 0.6608(3) | 0.4649(1) | 0.7039(5) | 0.6998(4) | 0.5672(2) | 0.7079(6) | 0.7099(7) | 0.7143(8) | ||
| 0.8266(3) | 0.7660(1) | 0.9070(5) | 0.9115(7) | 0.8053(2) | 0.9112(6) | 0.9127(8) | 0.9033(4) | ||
| 0.9151(3) | 0.7796(1) | 0.9742(5) | 0.9602(4) | 0.8834(2) | 0.9759(6) | 0.97997 | 0.9825(8) | ||
| 0.7059(2) | 0.6699(1) | 0.7816(5) | 0.7681(4) | 0.7169(3) | 0.7903(6) | 0.7949(7) | 0.7954(8) | ||
| 4 | 0.8384(2) | 0.7653(1) | 1.1384(5) | 1.0978(4) | 0.9426(3) | 1.1727(7) | 1.1520(6) | 1.1828(8) | |
| 0.8249(2) | 0.8220(1) | 0.8408(5) | 0.8382(4) | 0.8310(3) | 0.8430(7) | 0.8415(6) | 0.8439(8) | ||
| 0.6269(3) | 0.4355(1) | 0.6738(5) | 0.6642(4) | 0.5434(2) | 0.6786(6) | 0.6822(7) | 0.6886(8) | ||
| 0.7967(3) | 0.7586(2) | 0.8972(4) | 0.9039(6) | 0.7443(1) | 0.9020(5) | 0.9048(7) | 0.9067(8) | ||
| 0.9047(3) | 0.7491(1) | 0.9692(5) | 0.9500(4) | 0.8729(2) | 0.9777(6) | 0.9837(7) | 0.9890(8) | ||
| 0.6908(2) | 0.6486(1) | 0.7713(5) | 0.7527(4) | 0.7075(3) | 0.7828(6) | 0.7852(8) | 0.7834(7) | ||
| 5 (Figure 7) | 0.9352(2) | 0.8659(1) | 1.1746(5) | 1.1420(4) | 0.9868(3) | 1.2248(7) | 1.1968(6) | 1.2311(8) | |
| 0.8305(2) | 0.8276(1) | 0.8444(5) | 0.8435(4) | 0.8335(3) | 0.8481(7) | 0.8465(6) | 0.8482(8) | ||
| 0.6432(3) | 0.4472(1) | 0.6720(5) | 0.6594(4) | 0.5506(2) | 0.6751(6) | 0.6753(7) | 0.6885(8) | ||
| 0.8381(3) | 0.7649(1) | 0.9011(7) | 0.8953(4) | 0.7858(2) | 0.8973(5) | 0.8984(6) | 0.9214(8) | ||
| 0.9016(3) | 0.7483(1) | 0.9628(5) | 0.9419(4) | 0.8702(2) | 0.9698(6) | 0.9769(7) | 0.9802(8) | ||
| 0.7117(2) | 0.6785(1) | 0.7860(5) | 0.7607(4) | 0.7186(3) | 0.7966(7) | 0.7964(6) | 0.8014(8) |
| Scores | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | Total Scores | Ranking | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of Times | ||||||||||||
| Methods | ||||||||||||
| Ours | 23 | 5 | 1 | 0 | 1 | 0 | 0 | 0 | 229 | 1 | ||
| DCNN | 3 | 14 | 10 | 3 | 0 | 0 | 0 | 0 | 197 | 2 | ||
| DSIFT | 2 | 7 | 13 | 6 | 1 | 1 | 0 | 0 | 180 | 3 | ||
| IM | 1 | 3 | 3 | 21 | 2 | 0 | 0 | 0 | 160 | 4 | ||
| GF | 0 | 1 | 2 | 0 | 25 | 2 | 0 | 0 | 125 | 5 | ||
| NSCT-PCNN | 1 | 0 | 1 | 0 | 1 | 14 | 12 | 1 | 85 | 6 | ||
| DWT | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 17 | 73 | 7 | ||
| NSCT | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 29 | 31 | 8 | ||
| Scenes | Methods | |||||||
|---|---|---|---|---|---|---|---|---|
| DWT | NSCT | IM | GF | NSCT-PCNN | DSIFT | DCNN | Ours | |
| 1 | 0.2054 | 35.7285 | 3.2084 | 0.3351 | 243.2443 | 8.8385 | 132.9873 | 0.030 |
| 2 | 0.2031 | 35.5960 | 3.1097 | 0.3491 | 243.8029 | 11.4488 | 131.7024 | 0.035 |
| 3 | 0.2061 | 35.7128 | 2.9816 | 0.3473 | 243.4221 | 7.6047 | 131.6626 | 0.033 |
| 4 | 0.2039 | 35.7426 | 2.9719 | 0.3457 | 243.8831 | 7.3378 | 127.3014 | 0.032 |
| 5 (Figure 7) | 0.2050 | 35.7939 | 2.9131 | 0.3452 | 243.1754 | 9.4629 | 132.2269 | 0.035 |
| Average | 0.2047 | 35.7148 | 3.0369 | 0.3445 | 243.5056 | 8.9385 | 131.1761 | 0.033 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, H.; Luo, J.; Xie, S.; Sun, Y. Construction of All-in-Focus Images Assisted by Depth Sensing. Sensors 2019, 19, 1409. https://doi.org/10.3390/s19061409
Liu H, Li H, Luo J, Xie S, Sun Y. Construction of All-in-Focus Images Assisted by Depth Sensing. Sensors. 2019; 19(6):1409. https://doi.org/10.3390/s19061409
Chicago/Turabian StyleLiu, Hang, Hengyu Li, Jun Luo, Shaorong Xie, and Yu Sun. 2019. "Construction of All-in-Focus Images Assisted by Depth Sensing" Sensors 19, no. 6: 1409. https://doi.org/10.3390/s19061409
APA StyleLiu, H., Li, H., Luo, J., Xie, S., & Sun, Y. (2019). Construction of All-in-Focus Images Assisted by Depth Sensing. Sensors, 19(6), 1409. https://doi.org/10.3390/s19061409