1. Introduction
Fugitive emissions and the dispersion of pollutants in the atmosphere are significant concerns affecting public health as well as climate change. The accidental release of hazardous gases from both urban and industrial sources is responsible for a variety of respiratory illnesses and environmental concerns [
1,
2]. Many sensors are currently fabricated and deployed both indoors and outdoors for air quality data collection and communication. However, obtaining a spatial representation of a gas distribution is a challenging problem because existing mapping and fusion algorithms do not scale to networks of potentially hundreds of mobile and stationary sensors. The decentralized mapping and path-planning methods presented in this paper are applicable to very large-scale sensor systems, and as such can potentially be used to assess air quality, classify safe and hazardous areas based on the concentration of the harmful gases, and even localize fugitive emissions [
3].
Due to the fundamental mechanisms of atmospheric gas dispersion, auxiliary tools are required to ensure early detection and to respond with appropriate counter measures by planning future measurements efficiently in both space and time. Methods for obtaining gas distribution maps (GDM) have recently been developed along two lines of research [
4]. In the first line of research, a stationary sensor network is used to collect and fuse measurements to estimate the position of a source, typically requiring expensive and time-consuming calibration and data-recovery operations [
5]. The use of stationary sensors, however, is not typically effective or sufficiently expedient for gas sensing in response to high source rates of critical emissions. The second line of research, pursued in this paper, involves the use of mobile sensors, such as terrestrial robots equipped with gas sensors that can be controlled to rapidly and efficiently collect and fuse measurements over time. The latter approach provides for flexible sensor configurations that can respond to measurements online and thus can be applied to mapping gas distributions in unknown and complex environments.
Mobile gas sensing can be performed by a single robot [
2,
3,
6,
7,
8,
9] or by networks of robots also referred to as multi-agent systems (MAS) [
10,
11,
12,
13,
14]. Compared to single robots, MAS present several advantages, including increased probability of success and improved overall operational efficiency [
14], but also present additional technical challenges. In addition to requiring solving the GDM problem as a dynamical optimization problem, multi-agent path planning, coordination, communication, and fusion can become intractable as the number of robots increases [
4,
15,
16,
17,
18,
19,
20].
MAS path planning and coordination can be achieved via centralized or decentralized methods, depending on the underlying communication infrastructure [
21]. Centralized methods require persistent communication between a central station and every agent in the network, such that the central station can process and fuse all sensor measurements and use them to plan, or re-plan, the robot paths in a coordinated and collaborative fashion. Decentralized methods allow each robot to process its own measurements individually and then to communicate and fuse it with the measurements of a subset of collaborative robots, such as its nearest neighbors, with established connectivity. As a result, the performance of centralized methods depends entirely on the reliability of communication protocols under the operating conditions. Because fragile communication links are common in many hazardous scenarios, reliance on persistent communications with the central station and the associated power consumption can hinder or even prevent the applicability of MAS over large regions of interest that require repeated long-distance data transmission. Nevertheless, most of the existing GDM methods to date rely on centralized methods and algorithms [
10,
12,
13].
One of the main challenges in developing decentralized GDM methods lies in solving the data fusion problem for neighboring robots such that each robot can build its own representation of the GDM based on local measurements, but also update it incrementally as new information is obtained from neighboring robots. Considering the limited communication bandwidth and computing resources of most autonomous robots, it is also impractical to expect each sensor to share all the raw measurement data with its neighbors. Therefore, the decentralized approach to gas source localization presented in [
11] shares only the largest gas concentration and corresponding source position with its neighbors. However, this decentralized approach cannot be extended to high-performance GDM representations, such as Gaussian process (GP) mixture models [
8] or kernel-based models [
3,
22], and fusing GDMs obtained by different robots would result in redundant and expensive computations that potentially operate on the same raw data repeatedly.
The Hilbert map is an alternate GDM that represents a probability map learned from local concentration measurements [
7,
23]. The novel GDM representation developed in this paper uses kernel logistic regression (KLR) to express the probability that the gas concentration at a certain position belongs to a predefined range as a Hilbert map function. By this approach, new decentralized fusion algorithms can be developed that present several advantages, including decentralized fusion, agent-level complete GDM representation, and update for decentralized decision making. Additionally, information fusion operations are implemented via simple summations and only the local Hilbert map needs to be shared among neighboring robots at every measurement update. As a result, at the end time of the task, information about the gas concentration distribution over the entire region of interest can be delivered to the client or operator even if only a few robots complete the mission. Two GDM-based path-planning methods, the entropy-based artificial potential field (EAPF) and the entropy-based particle swarm optimization (EPSO) algorithms, are presented in this paper, and the simulation results show that they significantly outperform existing algorithms.
2. Problem Formulation
Consider the problem of optimally planning the trajectory of a distributed sensing system comprised of N cooperative robots engaged in GDM through a large region of interest (ROI), denoted by . In general, the gas concentration at a position , at time t, is modeled as a random variable , thus the whole gas concentration is a random field. The gas distribution is considered constant over a time interval for simplicity and thus is modeled as a spatial function defined over . The approach can be extended to time-varying concentrations by augmenting the dimensionality of the GDM.
Let
denote the space of admissible actions or controls. The dynamics of each robot are governed by stochastic differential equations (SDEs),
where
denotes the
nth robot’s position and the velocity at time
t,
denotes the
nth robot action or control, and
denotes the robot initial conditions at initial time
. The robot dynamics in (1) are characterized by additive Gaussian white noise, denoted by
, and
is a known constant matrix. In this paper, we assume that the position of the
nth robot is obtained by an on-board GPS and is denoted by
, where
denotes the estimated variable’s value.
All N robots are equipped with identical metal oxide sensors in order to cooperatively map a time-constant gas distribution, where the quantity and position of gas plumes are unknown a priori. Because the reaction surface of a single gas sensor is very small (≈1 cm), a single measurement from a gas sensor can only provide information about a very small area. Therefore, to increase the resolution of the GDM, a small metal oxide sensor array is used instead of a single oxide sensor for each robot. The area that is covered by this small metal oxide sensor array is called the field of view (FOV) of the robot, denoted by . Because the structure of the metal oxide sensor array is fixed, the positions of each metal oxide sensor can be approximated by the robot position measurements, denoted by , , where M is the number of oxide sensors on-board the nth robot. For example, for a metal oxide sensor array, the number of sensors is .
The gas concentration measurement obtained by the
mth sensor can be modeled as the sum of the actual concentration and measurement noise,
where
is a realization of the random measurement noise,
. Furthermore, the concentration measurement,
, can be treated as a sample of the random variable
, defined as
Then, the concentration measurement can be considered as an observation of the random field at position .
Because the actual gas concentration,
, and the distribution of the measurement noise,
, are unknown, our objective is to approximate the random field
, and then use this approximated random field to estimate the gas concentration map. The cost function of the
nth robot over a fixed time interval
can then be expressed as an integral of the future measurement values, conditioned on past measurements, and the robot control usage, i.e.,
where
is the entropy of the random variable
approximated by the
nth robot given all past measurements,
.
is a positive definite matrix that weighs the importance of the elements of the control input
, and the superscript “
” denotes the matrix transpose. The optimal planning problem is to find the optimal time history of the robot state
and control
, for all
, so that the cost function
in (4) is minimized over
, and subject to (1).
Let the time interval
be discretized into
equal time steps
and let
denote the discrete-time index with
. Then the objective function,
, can be rewritten as,
where the subscript
k indicates the
kth time step and the superscript “
” indicates the time until the
th step. The term,
, indicates the measurement history until the
th step and
denotes all the measurements obtained by the
nth robot up to the
kth time step.
3. Representation of GDM
To approximate the probability distribution of the continuous random variable
, there are several methods, including kernel density estimation (KDE) [
24,
25] and Gaussian process regression (GPR) [
26]. In the KDE method, the learned probability density function (PDF) is assumed to be a weighted summation of many parameterized kernel functions, where the weight coefficients and the kernel parameters are critical and learned from the raw measurement data set. In the GPR method, the approximated PDF is assumed to be a Gaussian distribution, where a large matrix, the Gram matrix, is very critical and learned from the raw measurement data. For both of methods, the data fusion of two different measurement data sets and update of the approximated PDF are computationally demanding, because all computations must be implemented from a massive amount of raw data. It is difficult to obtain the updated parameters and coefficients from the previous parameters and coefficients directly.
The method in this paper overcomes this hurdle through an efficient fusion approach developed by approximating the continuous probability distribution by a discrete probability distribution. Denote the range of the concentration in the whole ROI by
, and then divide the range into
L concentration intervals denoted by
, where
for
, and
and
. The cutoff coefficients,
, specify the concentration intervals of interest. Instead of approximating the PDF, this paper models the probabilities that the gas concentration at every position
belongs to the concentration interval
, or,
where
denotes the probability operator. Let
denote the PDF of the concentration
and
denote the length of the
lth concentration interval. The relationship between
and
can be expressed as,
where
Therefore, the discrete distribution
can be used to describe the probability distribution of the continuous random variable
as
. More importantly, it can be used for decision making, where the concentration intervals correspond to different levels of hazardous gas concentration. The Hilbert map method, developed by Fabio Ramos and Lionel Ott in [
27] to model obstacle occupancy, is modified here to approximate the discrete distribution
over the entire ROI.
3.1. Mapping with KLR
A Hilbert map is a continuous probability map developed by formulating the mapping problem as a binary classification task. Let
be any point in
and
be defined as a categorical random variable such that
where the realization is denoted by
y. The Hilbert map describes the probabilities
and
at the position
.
Consider the training measurement data set,
, where
indicates the measurement position, the Boolean variable
indicates whether the concentration measurement,
, belongs to the range,
(where
and
), and
M is the number of measurements. The probability
is defined as,
where,
and
is a Hilbert function defined on
.
is a reproducing kernel Hilbert space (RKHS) associated with a kernel
. The kernel mapping is denoted by
, and is an injective map from
to
[
28,
29,
30,
31,
32]. According to the kernel trick [
28,
29,
30,
31,
32], the evaluation of the Hilbert function can be expressed in the form of inner product,
where
indicates the inner product in the RKHS. To learn the Hilbert map, the loss function
is defined as,
where
is the negative log-likelihood (NLL) of the data
. Here, the term
is the regularization term, which is a small user-defined positive scalar,
. Then the gradient of the loss function with respective to
f is expressed as,
where
,
, and
. In addition, the Hessian operator is expressed as,
where
is an identity operator (or matrix) defined in the domain of
, so that for any function
, and
. Here,
is an
diagonal matrix defined as,
and
is an
vector with all elements equal to one.
Using the Newton-Raphson method, the Hilbert function, is updated iteratively,
where
,
is an
identity matrix, and the subscript “
i” indicates the
ith iteration for learning function
f. The Hilbert function,
, is evaluated iteratively as follows,
where
.
It can be seen from (18) that the evaluation of
only depends on the evaluations of
and
,
. Therefore, the evaluation
for each iteration is not needed if
. Instead,
can be calculated at the last iteration directly from the evaluations of
, such that
where
is the initial function evaluation at
, prior to learning the function from
. The following matrix
only depends on the measurement data,
, and can be updated iteratively.
Furthermore, consider
Q collocation points,
, in the ROI, characterized by the same spatial interval, labeled by the superscript “c”. Let
denote the feature matrix of the collocation points. The evaluations of function
at all collocation points can be updated by,
where
. According to (19), the evaluations,
, can be updated directly by,
where
comprises the initial function evaluations at the collocation points prior to learning the function from the measurement data
.
In summary, instead of learning the function
f or its coefficients as in traditional KLR or GPR [
26], we update the evaluations of
at the collocation points,
. Given the Hilbert function
f, the evaluations at the collocation points provide the Hilbert map,
, defined as
3.2. Temporal Update of Hilbert Map
The previous subsection develops a method for learning the Hilbert map from the measurement data set
, obtained by the sensors during one time interval. This subsection considers a Hilbert map updated according to the next data set,
, obtained during the
kth time interval. Here,
is the number of measurements in the
kth time interval, and
and
are the measurement positions and the corresponding classification estimates, respectively. To learn the next Hilbert map, the loss function over a period
T can be expressed as,
where
is the regularization term as in (13),
is the “forgetting factor”, and
is the NLL of the data
. Similarly to (14), the gradient is expressed as,
where
,
,
for
, and
. Furthermore,
is a diagonal matrix obtained by placing the vector,
on the diagonal of a zero matrix. In addition, as with (15), the Hessian operator can be expressed as,
where,
and
.
Then, the update rule for learning the Hilbert function,
f, at the
ith iteration is given by,
where
and
. According to the above equation, the function,
f, is expressed by using the set of all the measurement positions,
, and the corresponding coefficients.
To reduce the computational load, the forgetting factor,
, is modeled by,
such that each robot stores only the measurements obtained during the past
time steps. By setting
, the update rule (28) for learning the function
f at the
ith iteration is expressed as,
where
.
3.3. Approximation of GDM
The previous subsections present a method for learning the Hilbert function,
f, from the available measurement data, comprising the measurement position data set
and corresponding classification estimates
for
that indicate whether the concentration measurement at the measurement position belongs to the range,
, defined in (9). If
L classification estimates are obtained from the same concentration measurements, indicating that the concentration measurement belongs to the
L concentration ranges, such as
, respectively, using the learning method described in
Section 3.2, one can approximate
L Hilbert functions,
. Furthermore, the probabilities in (6) can be evaluated at all the collocation points,
, such that
Now, consider Hilbert functions,
, approximated locally by each robot. Although all the concentration intervals are mutually exclusive and complete, i.e.,
it is not guaranteed that the sum of all the learned probabilities,
, is equal to one, or
. Therefore, the learned probabilities must be normalized to obtain the discrete distribution,
. Each component of the discrete distribution is calculated by,
where
is a normalization term. Let
denote the medians of these intervals, where
. Then, the expectation of the random variable
can be expressed as,
where
is the expectation operator.
5. Path-Planning Algorithms
In the previous sections, the Hilbert maps
,
,
and
, are approximated and updated by the robots. The corresponding binary probabilities
can be calculated efficiently as follows
and the entropy at each collocation point
,
, is obtained by
Then, an entropy map,
is obtained from the vector,
where
denotes the sum of the entropy at the collocation point
.
According to the cost function in (5), the objective of the nth robot is to minimize the uncertainty of the concentration distribution, which can be implemented by minimizing the entropy at all the collocation points, such that
Therefore, can be treated as an approximation of the term in (5). In the rest of paper, is applied as the approximation of the final cost function in (5) unless otherwise stated. In other words, the nth robot should visit the area around the collocation point , which has the higher value of at the kth time step. Based on this idea, two entropy-based path-planning algorithms are proposed in the following section to control the robots such that the value of the concentration measurements obtained by the robots in the ROI can be optimized over time.
5.1. Entropy-Based Artificial Potential Field
An information-driven approach is developed by planning the path of the robots such that they move towards collocation points with higher entropy. The collocation points are treated as goal positions characterized by attractive artificial potential fields defined as,
where the superscript “att” indicates the attractive field. The corresponding attractive gradient is expressed as
Similarly to classic artificial potential field methods, the repulsive potential functions
generated from the other robots are also considered, such that
where
is the distance threshold to create a repulsion effect on the robot. The repulsive gradient is expressed as
Using (52) and (54), the total potential gradient for the
nth robot is expressed as,
where
and
are user-defined coefficients.
Based on the total gradient, , the nth robot can be controlled to visit the collocation points with higher uncertainty and avoid collisions with other robots. The algorithm is developed based on the entropy attraction, which is named as EAPF algorithm.
5.2. Entropy-Based Particle Swarm Optimization
The particle swarm optimization (PSO) algorithm proposed by Clerc and Kennedy in [
33] and its variants use a “constriction coefficient” to prevent the “explosion behavior” of the particles, and have been successfully applied to GDM and gas source localization problems [
12,
13]. In the original PSO algorithm and its variants, the concentration measurements are used to update the robot controls. Considering the different objective function in (5), an entropy-based PSO (EPSO) is proposed.
At the
kth time step, the update of the
nth robot position,
, can be described as
where
represents the velocity of the
nth robot at the
kth time step,
and
are the best neighboring and global collocation points, respectively. The best neighboring collocation point,
, is determined by,
where
is a coefficient which specifies the neighbor area from
. The best global collocation point,
, is determined by
The learning coefficients,
and
, are two uniform random variables. The constant parameter
prevents the explosion behavior. For efficient performance and prevention of the explosion behavior in (56), the parameter settings of the learning coefficients proposed in [
12,
13,
33] is applied. The constriction parameter
is calculated by (refer to [
33]),
where
and
.










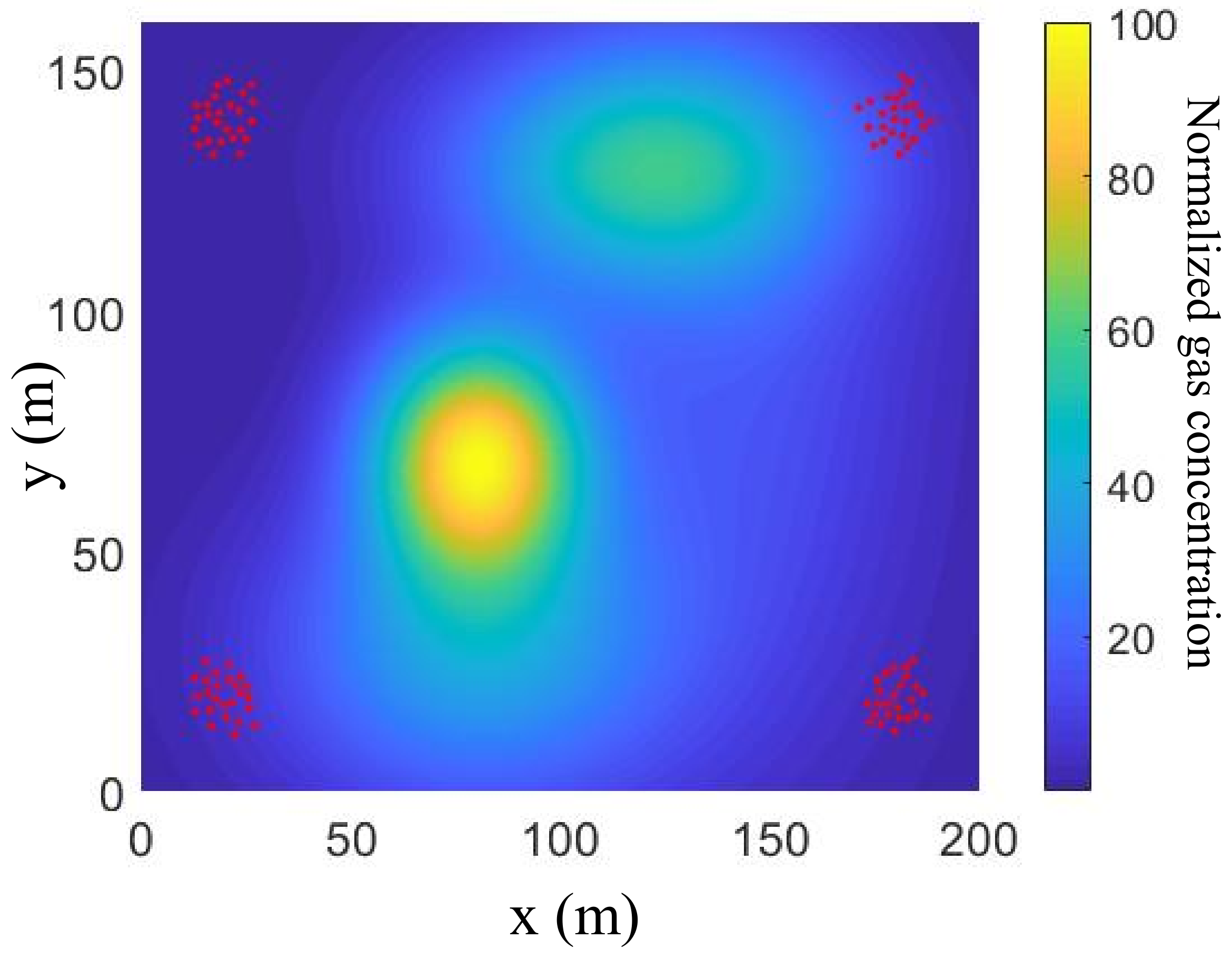{kind=link}
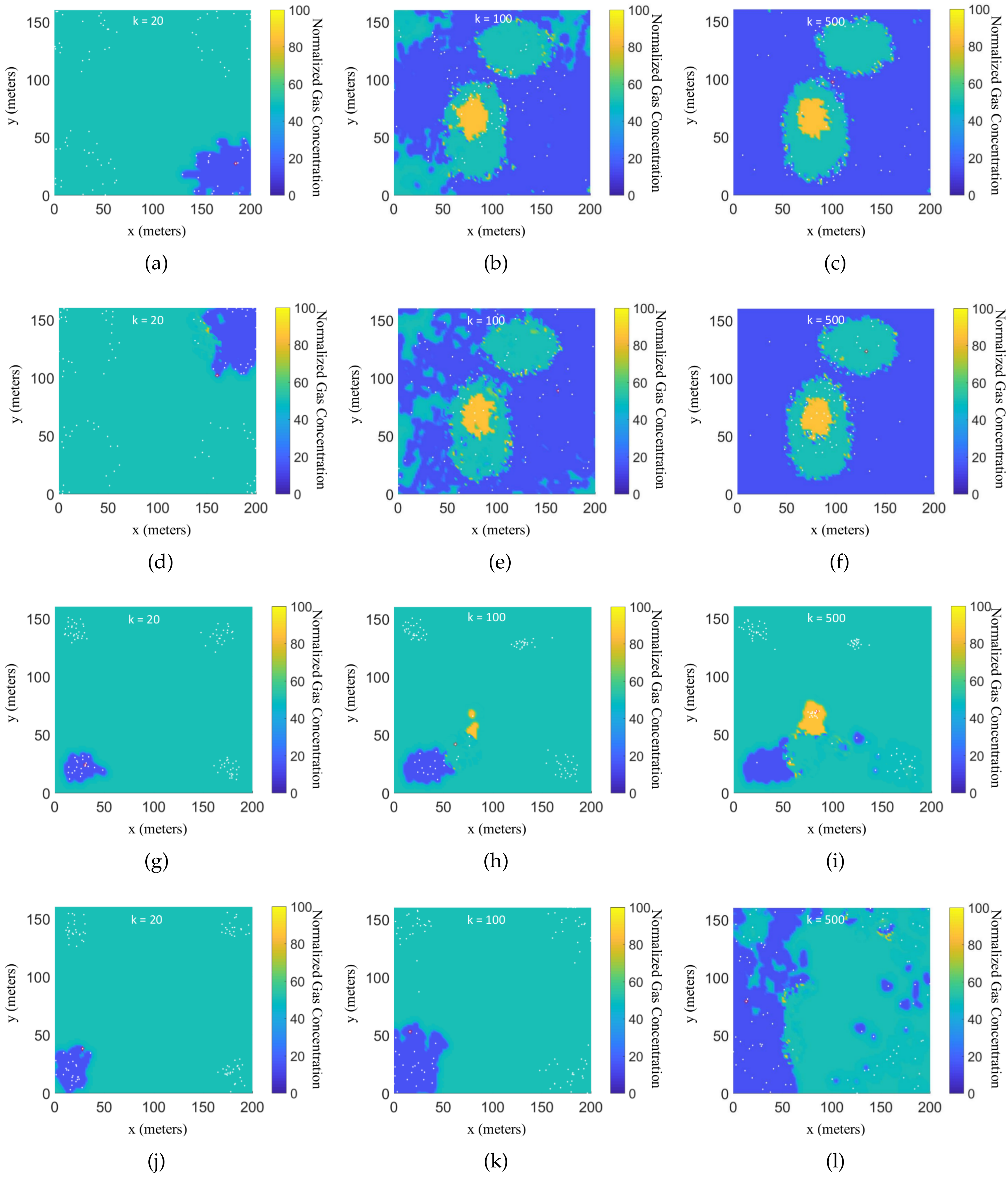
{kind=link}
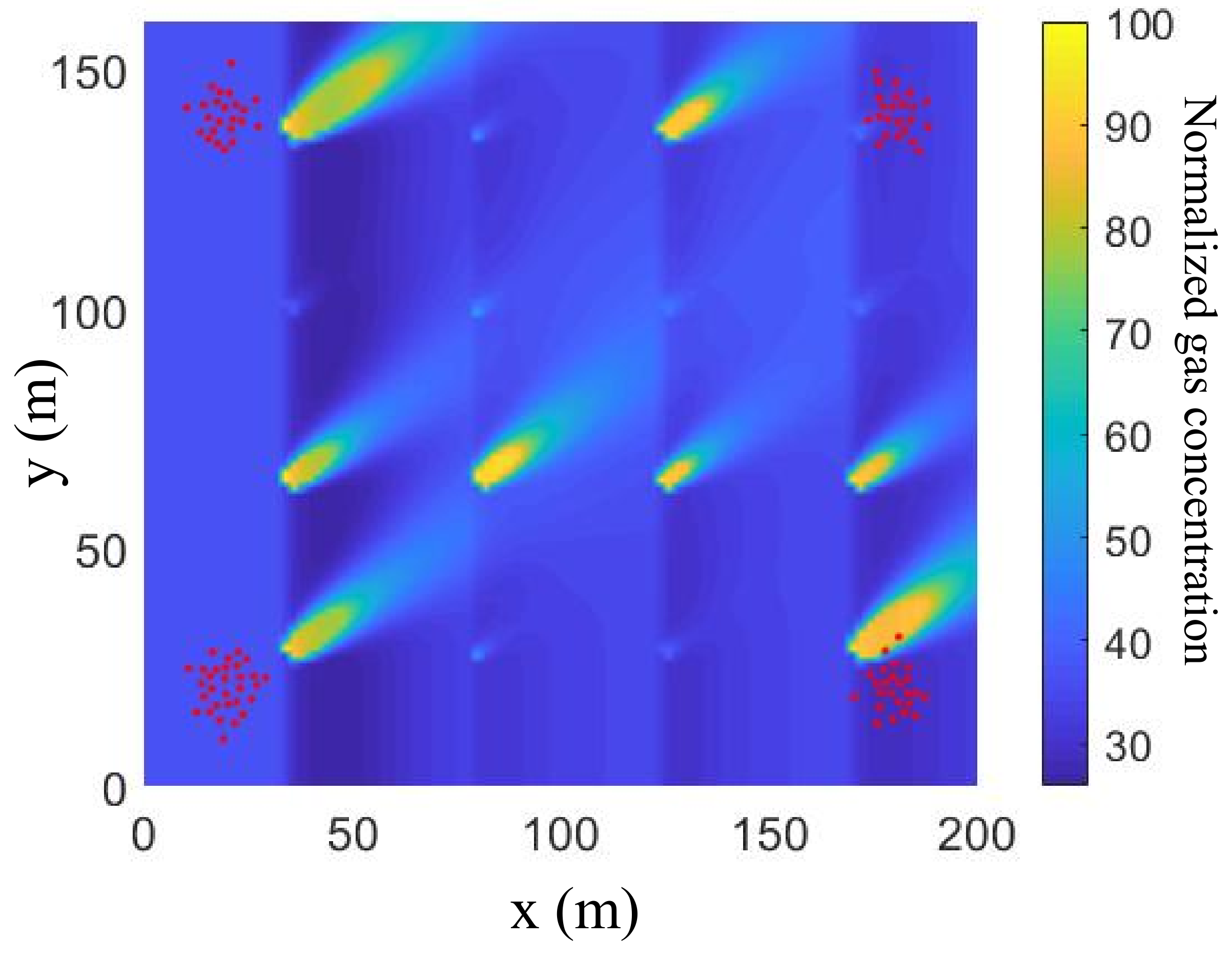
{kind=link}
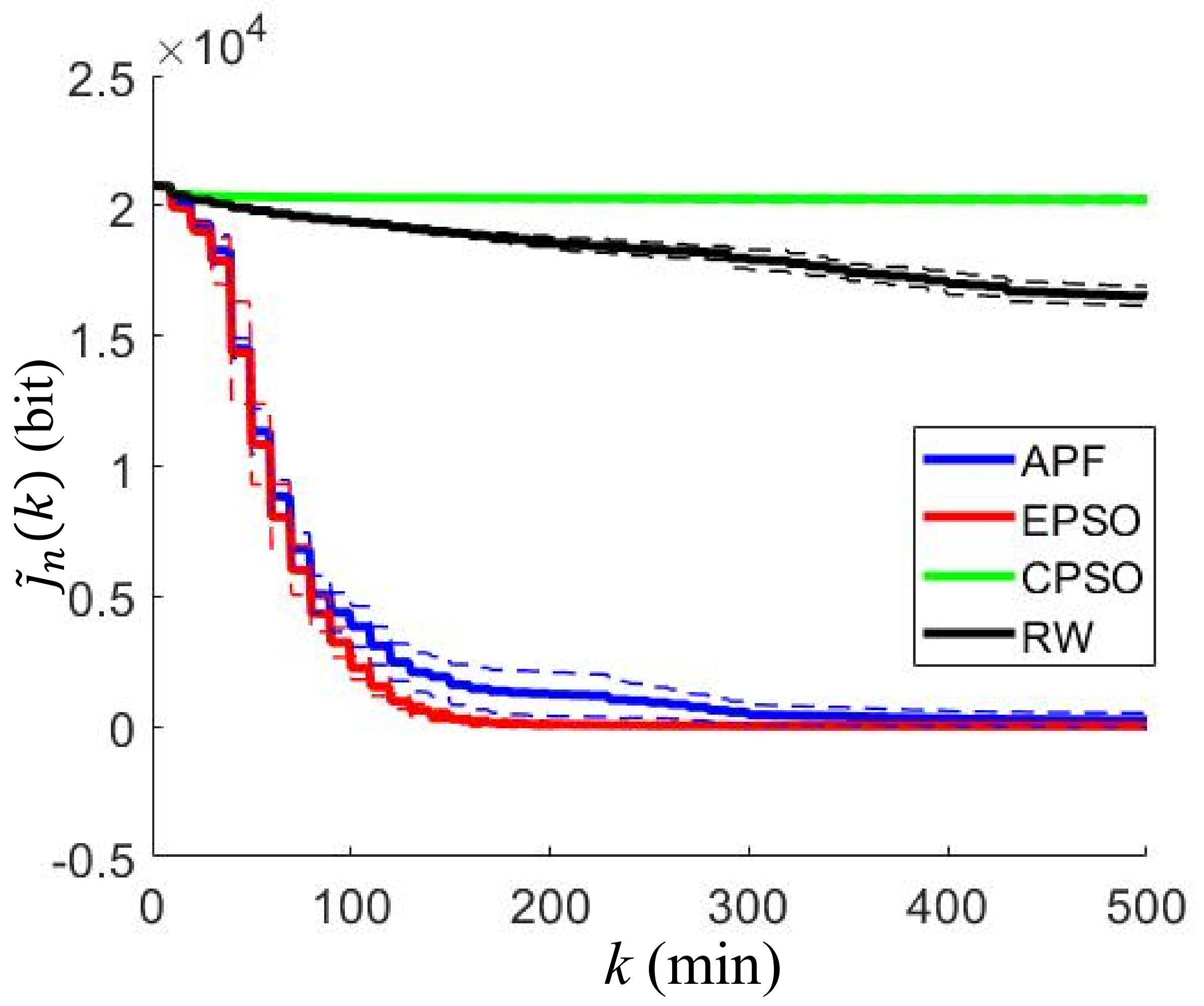
{kind=link}
{kind=link}
{kind=link}