Efficient Classification of Motor Imagery Electroencephalography Signals Using Deep Learning Methods

Abstract
:1. Introduction
2. Related Studies
2.1. Filterbank Common Spatial Pattern
2.1.1. Filtering at the Base Frequency
2.1.2. Common Spatial Patterns for Two Classes
2.2. Multiclass Filterbank Common Spatial Pattern
2.3. Power Spectrum Density (PSD)
2.4. Riemannian Geometry
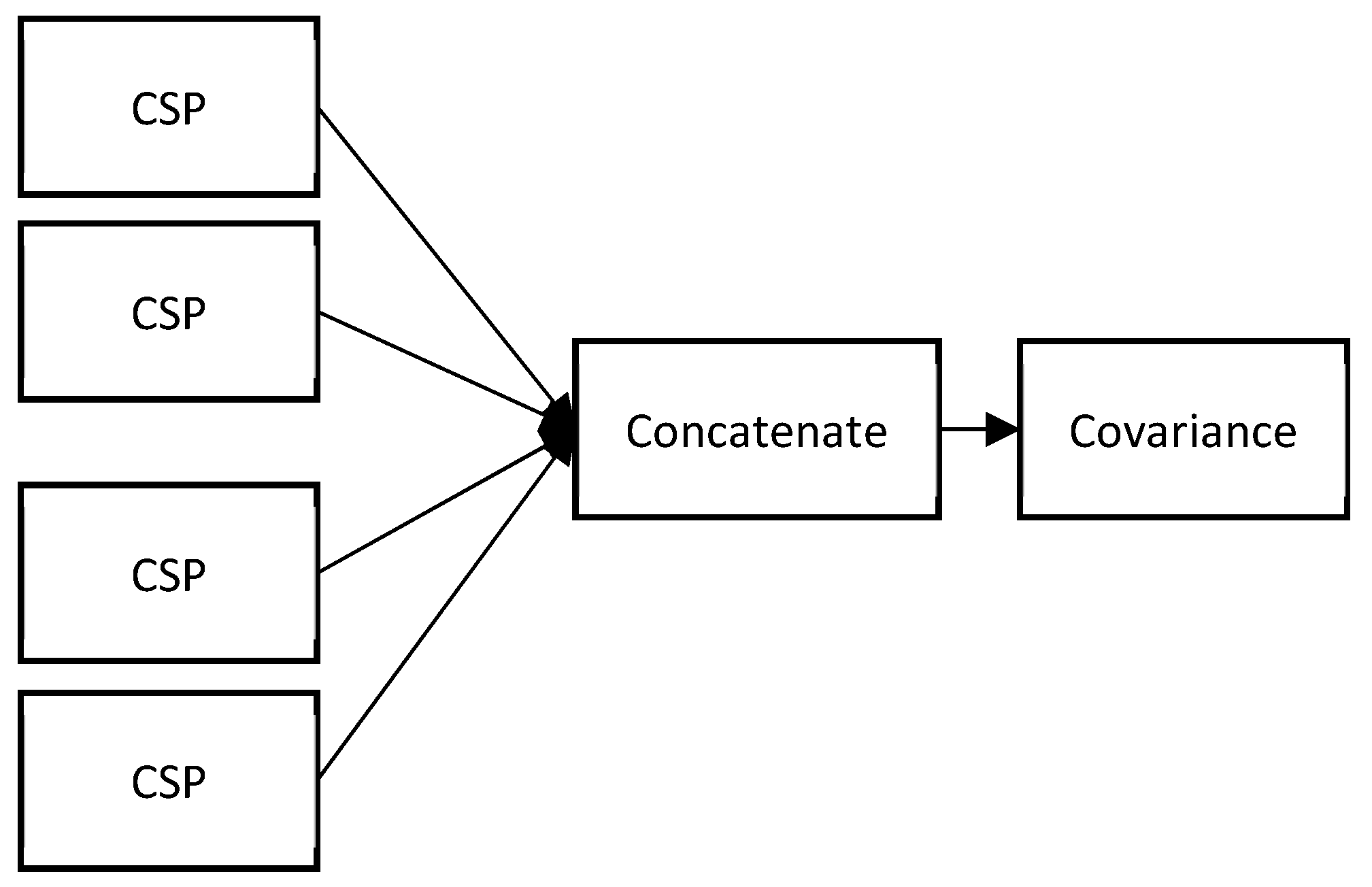
2.4.1. Spatial Covariance Matrices
2.4.2. Spatial Covariance Matrices
2.4.3. Approximation of SPD Matrices
2.4.4. Tangent Space Mapping
2.5. Particle Swarm Optimization
| Algorithm 1. Simple particle swarm optimization (PSO) pseudocode. |
| 1. begin 2. initialize 3. for i in n_iterations = k 4. for each position p of particle compute fitness 5. if fitness (p) > fitness (pbest) 6. pbest = p 7. set best of pbest as gbest 8. update particles velocity and position 9. gbest is our result |
3. Proposed Method
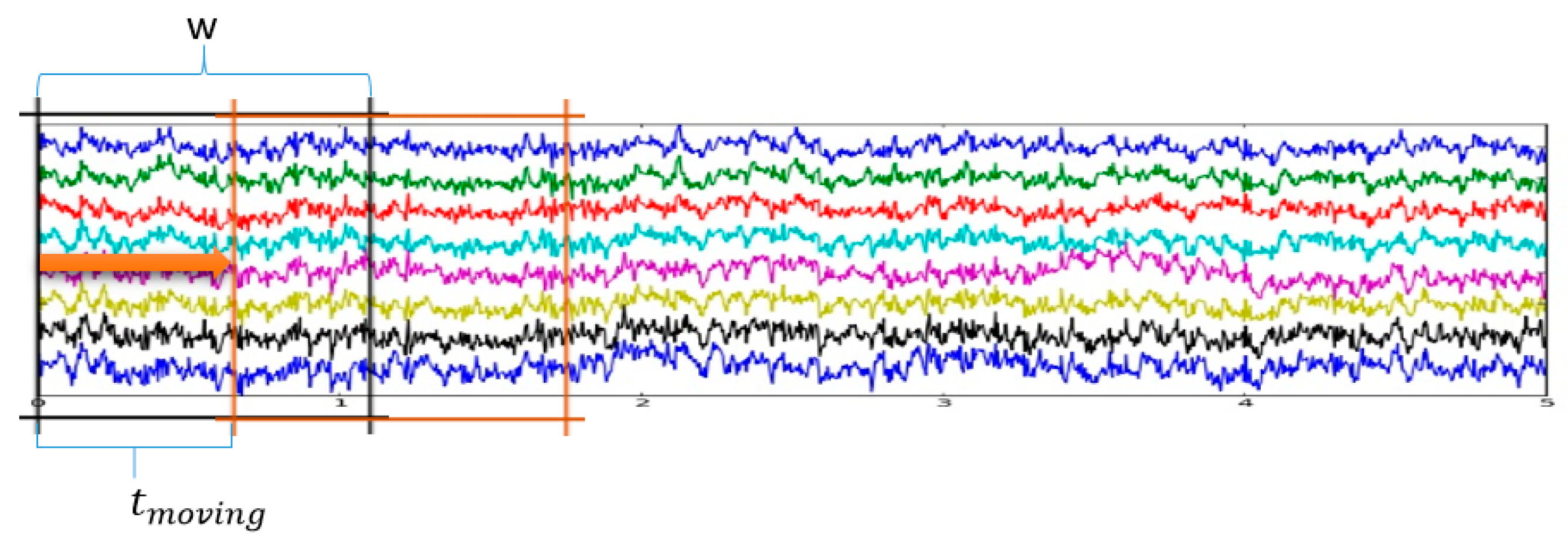
3.1. Data Augmentation
3.2. FBCSP Algorithm
3.3. PSD Algorithm
3.4. Tangent Space Mapping
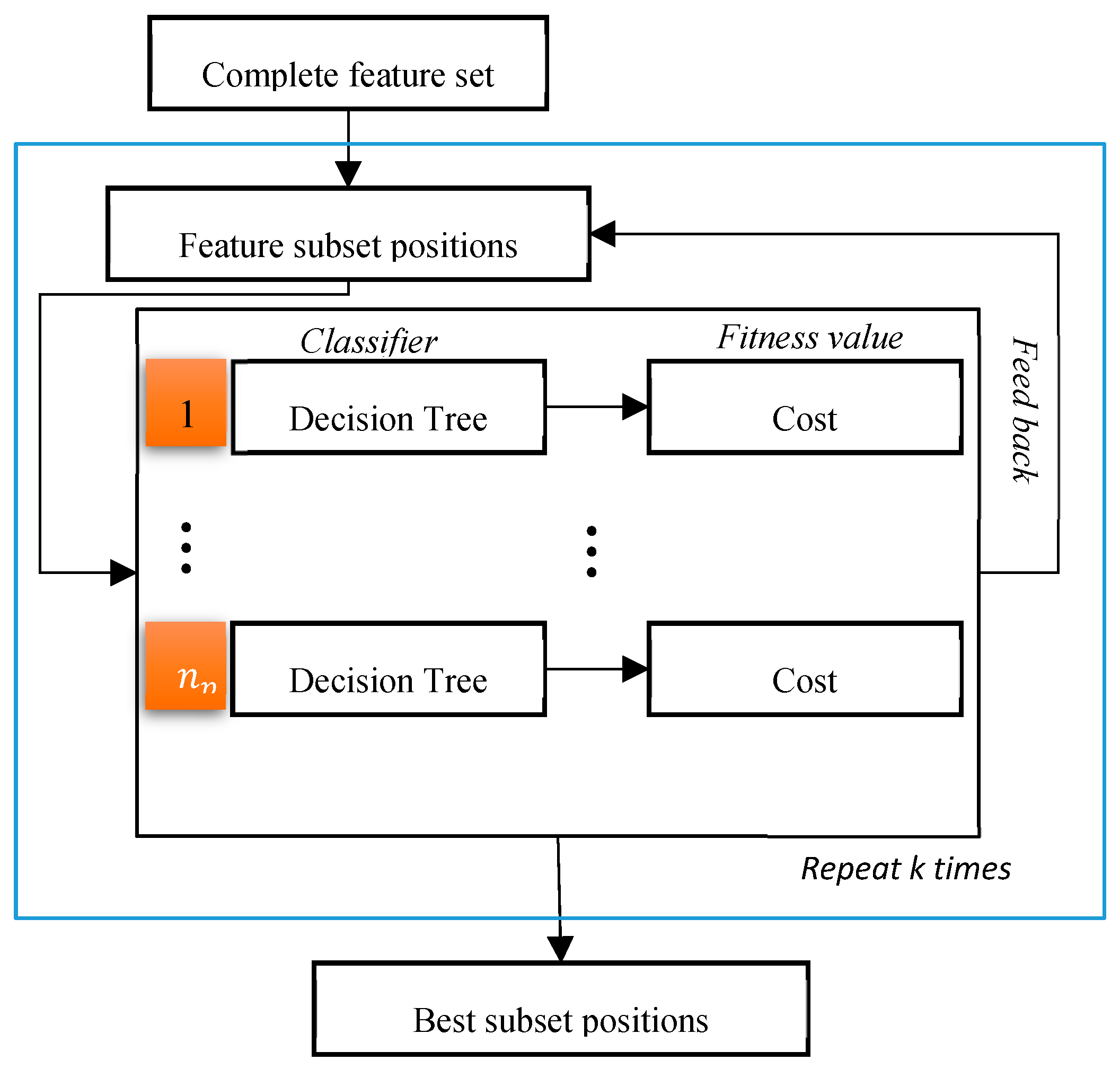
3.5. FSBPSO Algorithm
3.6. Architecture
4. Experiments and Results
4.1. Datasets
4.2. Results
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vaughan, T.M.; Heetderks, W.J.; Trejo, L.J.; Rymer, W.Z.; Weinrich, M.; Moore, M.M.; Kübler, A.; Dobkin, B.H.; Birbaumer, N.; Donchin, E.; et al. Brain-computer interface technology: A review of the Second International Meeting. IEEE Trans. Neural Syst. Rehabil. Eng. 2003, 11, 94–109. [Google Scholar] [CrossRef] [PubMed]
- Vidal, J.J. Toward direct brain-computer communication. Annu. Rev. Biophys. Bioeng. 1973, 2, 157–180. [Google Scholar] [CrossRef]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Grosse-Wentrup, M.; Buss, M. Multiclass common spatial patterns and information theoretic feature extraction. IEEE Trans. Biomed. Eng. 2008, 55, 1991–2000. [Google Scholar] [CrossRef]
- Zavaglia, M.; Astolfi, L.; Babiloni, F.; Ursino, M. The effect of connectivity on EEG rhythms, power spectral density and coherence among coupled neural populations: Analysis with a neural mass model. IEEE Trans. Biomed. Eng. 2008, 55, 69–77. [Google Scholar] [CrossRef] [PubMed]
- Koles, Z.J. The quantitative extraction and topographic mapping of the abnormal components in the clinical EEG. Electroencephalogr. Clin. Neurophysiol. 1991, 79, 440–447. [Google Scholar] [CrossRef]
- Ramoser, H.; Muller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [Green Version]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain computer interfaces, a review. Sensors 2012, 12, 1211–1279. [Google Scholar] [CrossRef]
- Comon, P. Independent component analysis, a new concept? Signal Process. 1994, 36, 287–314. [Google Scholar] [CrossRef]
- Barachant, A.; Bonnet, S.; Congedo, M.; Jutten, C. Multiclass brain–computer interface classification by Riemannian geometry. IEEE Trans. Biomed. Eng. 2012, 59, 920–928. [Google Scholar] [CrossRef] [PubMed]
- Forney, E. Learning Deep Representations of EEG Signals in Mental-Task Brain-Computer Interfaces Using Convolutional and Recurrent Networks; Colorado State University: Fort Collins, CO, USA, 2017. [Google Scholar]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2016, 14, 016003. [Google Scholar] [CrossRef]
- Ang, K.K.; Chin, Z.Y.; Zhang, H.; Guan, C. Filter bank common spatial pattern (FBCSP) in brain-computer interface. In Proceedings of the IEEE International Conference on Neural Networks (IJCNN 2008), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Müller-Gerking, J.; Pfurtscheller, G.; Flyvbjerg, H. Designing optimal spatial filters for single-trial EEG classification in a movement task. Clin. Neurophysiol. 1999, 110, 787–798. [Google Scholar] [CrossRef] [Green Version]
- Parra, L.C.; Spence, C.D.; Gerson, A.D.; Sajda, P. Recipes for the linear analysis of EEG. Neuroimage 2005, 28, 326–341. [Google Scholar] [CrossRef] [Green Version]
- Ziehe, A.; Laskov, P.; Nolte, G.; MÞller, K.-R. A fast algorithm for joint diagonalization with non-orthogonal transformations and its application to blind source separation. J. Mach. Learn. Res. 2004, 5, 777–800. [Google Scholar]
- Islam, M.R.; Tanaka, T.; Molla, M.K.I. Multiband tangent space mapping and feature selection for classification of EEG during motor imagery. J. Neural Eng. 2018, 15, 046021. [Google Scholar] [CrossRef] [Green Version]
- Boeringer, D.W.; Werner, D.H. Particle swarm optimization versus genetic algorithms for phased array synthesis. IEEE Trans. Antennas Propag. 2004, 52, 771–779. [Google Scholar] [CrossRef]
- Blackwell, T.M.; Kennedy, J.; Poli, R. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Zhang, Y.; Wang, S.; Phillips, P.; Ji, G. Binary PSO with mutation operator for feature selection using decision tree applied to spam detection. Knowl. Based Syst. 2014, 64, 22–31. [Google Scholar] [CrossRef]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv, 2015; arXiv:151106448. [Google Scholar]
- Raza, H.; Cecotti, H.; Li, Y.; Prasad, G. Adaptive learning with covariate shift-detection for motor imagery-based brain–computer interface. Soft Comput. 2016, 20, 3085–3096. [Google Scholar] [CrossRef]
- Gaur, P.; Pachori, R.B.; Wang, H.; Prasad, G. A multi-class EEG-based BCI classification using multivariate empirical mode decomposition based filtering and Riemannian geometry. Expert Syst. Appl. 2018, 95, 201–211. [Google Scholar] [CrossRef]
- Singh, A.; Lal, S.; Guesgen, H.W. Reduce Calibration Time in Motor Imagery Using Spatially Regularized Symmetric Positives-Definite Matrices Based Classification. Sensors 2019, 19, 379. [Google Scholar] [CrossRef]
- Belwafi, K.; Romain, O.; Gannouni, S.; Ghaffari, F.; Djemal, R.; Ouni, B. An embedded implementation based on adaptive filter bank for brain–computer interface systems. J. Neurosci. Methods 2018, 305, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Tangermann, M.; Müller, K.-R.; Aertsen, A.; Birbaumer, N.; Braun, C.; Brunner, C.; Leeb, R.; Mehring, C.; Miller, K.J.; Mueller-Putz, G. Review of the BCI competition IV. Front. Neurosci. 2012, 6, 55. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subject | Proposed Method | Raza et al. [23] | Gramound Gaur. [24] | SR-MDRM [25] | WOLA-CSP [26] |
|---|---|---|---|---|---|
| A1 | 90.14% | 90.28% | 91.49% | 90.21% | 86.81% |
| A2 | 62.35% | 57.64% | 61.27% | 63.28% | 63.89% |
| A3 | 89.17% | 95.14% | 94.89% | 96.55% | 94.44% |
| A4 | 79.23% | 65.97% | 76.72% | 76.38% | 68.75% |
| A5 | 76.45% | 61.11% | 58.52% | 65.49% | 56.25% |
| A6 | 69.35% | 65.28% | 68.52% | 69.01% | 69.44% |
| A7 | 84.08% | 61.11% | 78.57% | 81.94% | 78.47% |
| A8 | 86.10% | 91.67% | 97.01% | 95.14% | 97.91% |
| A9 | 87.06% | 86.11% | 93.85% | 93.01% | 93.75% |
| Average | 80.44% | 74.92% | 79.93% | 81.22% | 78.86% |
| 0.9 | 0.8 | 0.7 | 8 | 200 |
| Subject | Proposed Method | LDA | SVM | Yousef and Ugur [13] |
|---|---|---|---|---|
| 1 | 78.81% | 64.58% | 74.65% | 76.00% |
| 2 | 80.14% | 58.08% | 75.36% | 65.80% |
| 3 | 77.08% | 61.11% | 70.13% | 75.30% |
| 4 | 91.37% | 67.34% | 81.98% | 95.30% |
| 5 | 86.15% | 66.55% | 79.10% | 83.00% |
| 6 | 80.73% | 59.72% | 72.91% | 79.50% |
| 7 | 81.59% | 69.79% | 80.55% | 74.50% |
| 8 | 81.25% | 67.10% | 76.64% | 75.30% |
| 9 | 84.37% | 60.06% | 77.08% | 73.30% |
| Average | 82.39% | 63.81% | 76.49% | 77.56% |
| Subject | Proposed Method | TSLDA | CSP*+LDA | MDRM |
|---|---|---|---|---|
| 1 | 93.30% | 80.50% | 81.80% | 77.80% |
| 2 | 84.59% | 51.30% | 45.10% | 44.10% |
| 3 | 91.68% | 87.59% | 83.50% | 76.80% |
| 4 | 84.55% | 59.30% | 59.00% | 54.90% |
| 5 | 86.54% | 45.00% | 42.20% | 43.80% |
| 6 | 76.92% | 55.30% | 43.30% | 47.10% |
| 7 | 94.03% | 82.10% | 81.50% | 72.00% |
| 8 | 93.20% | 84.80% | 69.60% | 75.20% |
| 9 | 92.24% | 86.10% | 80.00% | 76.60% |
| Average | 87.94% | 70.20% | 65.11% | 63.20% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majidov, I.; Whangbo, T. Efficient Classification of Motor Imagery Electroencephalography Signals Using Deep Learning Methods. Sensors 2019, 19, 1736. https://doi.org/10.3390/s19071736
Majidov I, Whangbo T. Efficient Classification of Motor Imagery Electroencephalography Signals Using Deep Learning Methods. Sensors. 2019; 19(7):1736. https://doi.org/10.3390/s19071736
Chicago/Turabian StyleMajidov, Ikhtiyor, and Taegkeun Whangbo. 2019. "Efficient Classification of Motor Imagery Electroencephalography Signals Using Deep Learning Methods" Sensors 19, no. 7: 1736. https://doi.org/10.3390/s19071736
APA StyleMajidov, I., & Whangbo, T. (2019). Efficient Classification of Motor Imagery Electroencephalography Signals Using Deep Learning Methods. Sensors, 19(7), 1736. https://doi.org/10.3390/s19071736