1. Introduction
In recent decades, autonomous underwater vehicles (AUVs) have played an increasingly crucial role in marine exploration and development, such as resource detection, military technologies, and underwater structure inspections [
1]. To facilitate the flexibility of their movement, the power capacity of AUVs is limited by their compact outfit. In addition, upon completion of undersea assignments, AUVs have to return to the bank to obtain a new mission. Docking technology makes it possible for the vehicles to upload data, download new assignments and recharge their batteries underwater [
2,
3]. This greatly extends the duration of their operation. To achieve this expected manipulation, AUVs must be guided to the docking station during the first step. The guiding process is divided into two stages: the homing stage and the docking stage [
4]. AUVs are guided to the neighbourhood of the docking station during the homing stage and then enter into it during the docking stage. Compared with the homing stage, the docking stage requires higher localisation precision and directly determines whether AUVs can get back to the docking station successfully or not. As such, the docking technology for the docking stage is of vital importance.
In previous works, several types of docking technologies based on the use of different sensors have been introduced.
A combination navigation system including an ultra-short baseline (USBL) acoustic array and a Doppler velocity log (DVL) was proposed by Allen et al. [
5] for REMUS AUV docking. McEwen et al. [
4] developed a docking system for a 54-centimetre diameter AUV using USBL guidance technology near the docking station. Vallicrosa et al. [
6] also used USBL technology to guide Girona500 I-AUV (Intervention AUV) to a docking station.
An electromagnetic (EM) docking system was first proposed by Feezor et al. [
7] for the Odyssey AUV. In recent years, Vandavasi et al. [
8] from the India National Institute of Ocean Technology described the concept and test of an electromagnetic homing guidance system (EMHGS). Peng, S. et al. [
9] from Hangzhou Dianzi University and Zhejiang Provincial Key Lab of Equipment Electronics also developed a low-cost electromagnetic docking guidance (EMDG) system for micro AUVs.
Acoustic signals are easily disturbed by reflecting surfaces such as the seabed and target structures, which makes it hard to achieve high accuracy in a short operating range [
10]. Electromagnetic signals have a high attenuation velocity underwater and can only be valid within a relatively short range [
8,
9]. In recent years, with the gradual improvement in computational capacity, vision guidance technology has been developed as a commonly used approach for AUV terminal docking due to its simplicity and effectiveness. It has excellent performance in clear water and can be effective within a range of 0–15 m [
11].
Park et al. [
12] proposed a vision docking system for ISIMI AUV with lights equipped at the entrance of the docking station and cameras equipped at the head of the AUV. By averaging the mass centres of the lights, AUV can obtain the relative two-dimensional position to the docking station and move towards its target. Their experiment was conducted in an ocean engineering basin (OEB) of the Korea Ocean Research and Development Institute (KORDI).
Y. Li et al. [
13] built a vision docking algorithm that was a combination of monocular and binocular positioning methods. The algorithm switches between the two operating modes depending on the number of lights in the images captured by the two cameras and can obtain the six-dimensional pose of the AUV. However, the computational burden of this vision-based navigation is heavy, corresponding to approximately 1.5–2.5 s, and a dead reckoning algorithm is used for aided navigation. The experiment was conducted in the water pool lab at Harbin Engineering University.
D. Li et al. [
11] presented a vision docking method using one camera and one light. The four stages taken to enable the AUV to obtain its relative distance to the docking station and navigate to the target can be outlined as: image acquisition, binarisation of the captured images, elimination of noisy luminaries, and estimation of the relative position. This system was tested in the swimming pool of Yuquan Campus of Zhejiang University.
N. Palomeras et al. [
14] proposed a range-only localisation algorithm to approach the docking station and developed an associated estimation algorithm using active beacons and augmented reality (AR) markers to complete the docking manoeuvre at short ranges. When the camera on the AUV can capture all the lights at the docking station, the six-dimensional pose of the AUV can be estimated using a non-linear least squares minimisation method. Otherwise, AR markers are used to guide the AUV.
Park et al. [
12] and D. Li et al. [
11] were able to obtain the relative two-dimensional position in pixel units of dock to AUV and control the heading direction of the AUV to the dock. Y. Li et al. [
13] and N. Palomeras et al. [
14] were able to obtain the six-dimensional pose of the AUV, but the computational burden of the former was heavy while the equipment required for the docking station was too complicated for application in turbid water in the case of the latter.
This article focuses on the docking stage, assuming that the AUV has been guided to the lamp field near the docking station using remote guidance technologies. In this study, a fast binocular localisation method is proposed. The proposed scheme uses two packaged CMOS cameras installed below a ship model and three navigation lamps equipped on a testbed docking station. An adaptively weighted OTSU method is presented to extract the lamps more accurately and efficiently, which is described specifically in
Section 3. By choosing the mass centres of the extracted lamp objects as the matching feature, the six-dimensional pose of the AUV can be computed with a binocular localisation method at an operation frequency greater than 10 Hz. To address situations in which two cameras cannot capture all the lamps, an efficacious estimation method (D. Li et al. [
11]) is applied to obtain the relative two-dimensional position to control the heading direction only.
In the remaining part of this article,
Section 2 presents the configuration for the proposed vision guidance system.
Section 3 describes the realisation of the proposed system, which includes the processing of the raw images, the binocular vision algorithm, and the control strategy for the ship model.
Section 4 presents the experiment results. The final section is a summary of the main conclusions of this study.
2. System Configuration
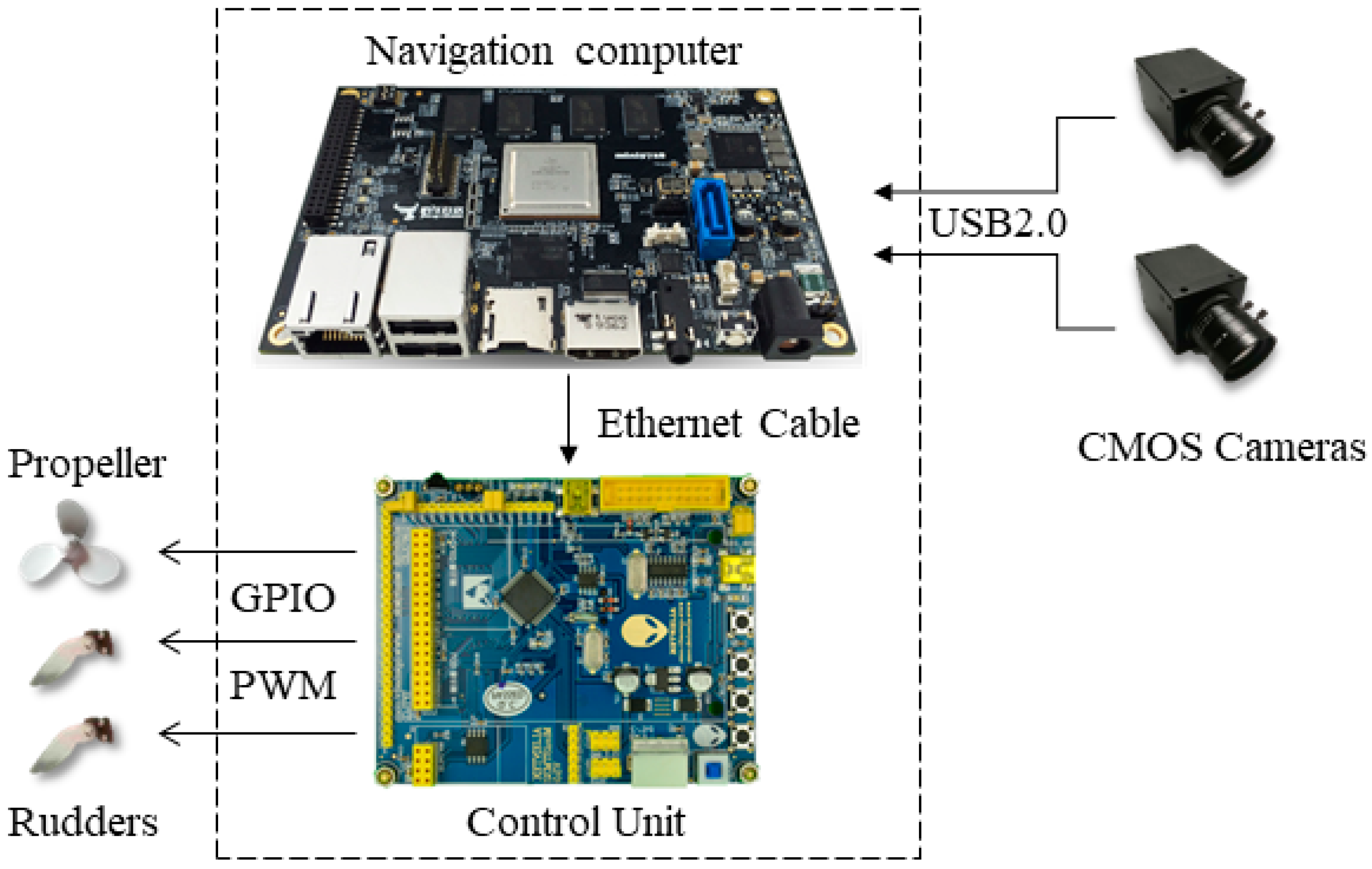
The platform applied in this article was a ship model. As shown in
Figure 1, it contains five main components: two monochromatic Complementary Metal Oxide Semiconductor (CMOS) cameras, two rudders, one propeller, one control unit and one navigation computer.
Table 1 presents the details of the equipment specification of the proposed system. We chose a monochromatic camera due to its higher sensitivity to light compared to colour cameras, whose colour filters result in a loss of more than half of the incident light energy [
15]. The field angle of the camera is 60 degrees. The CMOS cameras are connected to the navigation computer by Universal Serial Bus (USB) port. The navigation computer is embedded in a Linux operating system and is utilised in processing the images captured by the cameras and then transmitting the visual computation results to the control unit by ethernet. The control unit implements the control strategy (described in
Section 3.3) to control the direction and speed of the ship model. To be more specific, it can transmit Pulse Width Modulation (PWM) instructions to the rudders and propeller through General-Purpose Input/Output (GPIO) ports.
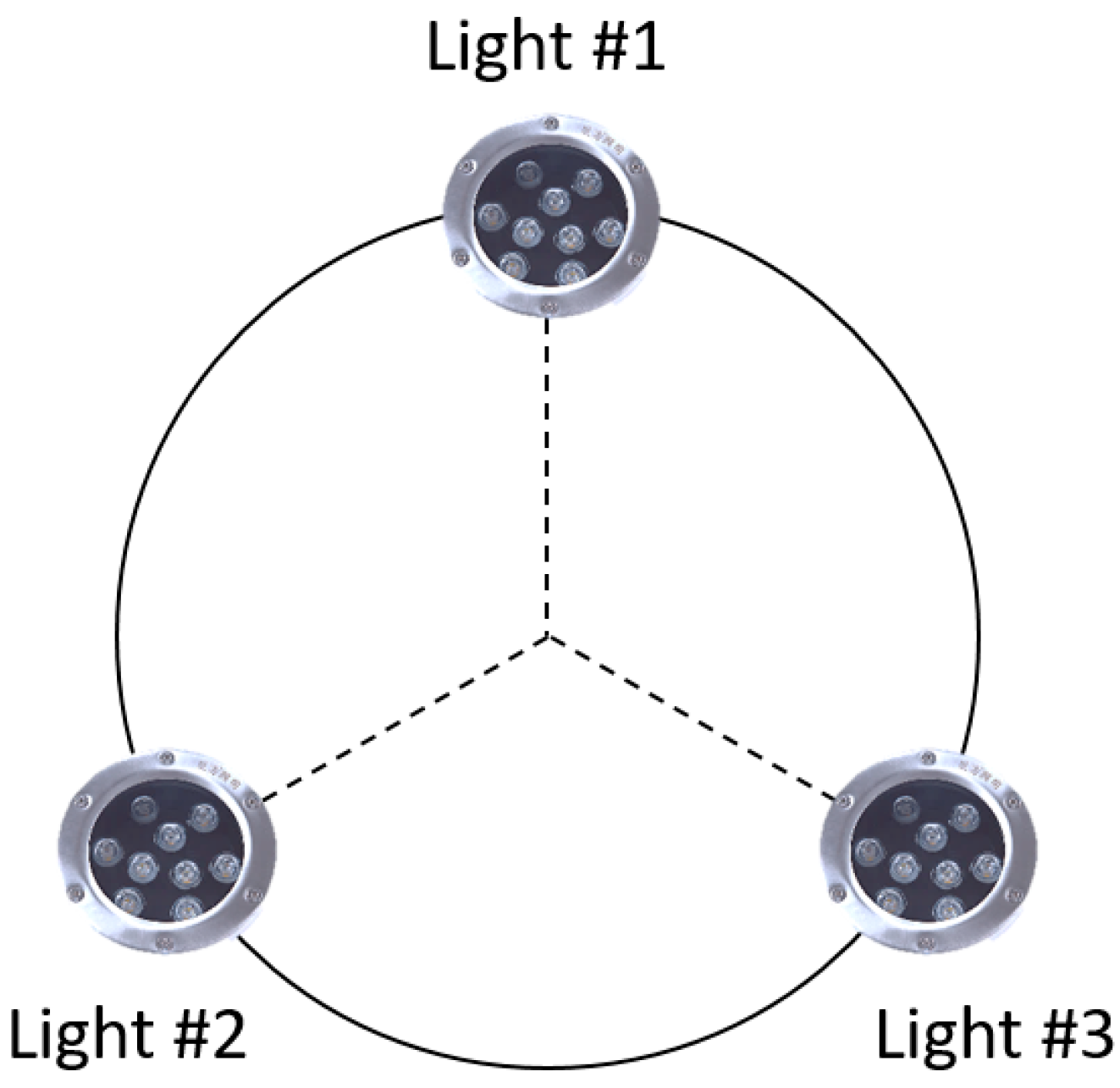
Most of the vision guidance systems mount the navigation lamps at the entrance of the docking station as active beacons. In this paper, we also adopt this method. However, instead of a real docking station, we used an aluminium profile model with lamps equipped on it, which operated similarly to the docking station in terms of the terminal docking process. Three common underwater green lamps were symmetrically positioned on the aluminium profile model around the centre of the three lamps, namely, the centre of the docking station (
Figure 2). Green lamps were chosen because of the wavelengths at which it is relatively difficult for seawater to either absorb or scatter the light [
16].
3. Vision Guidance Algorithm
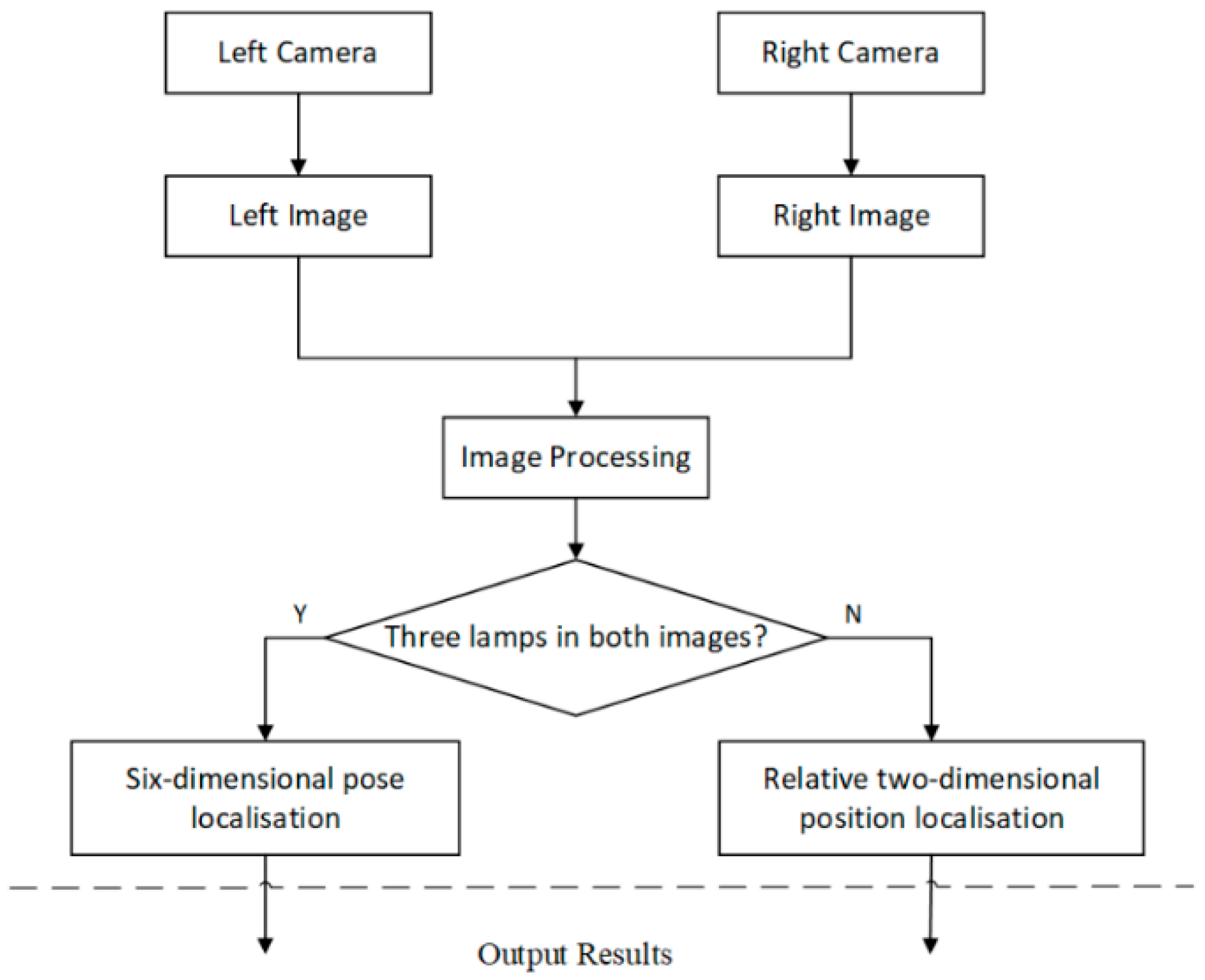
As previously indicated, the vision guidance system primarily contains two cameras installed below the ship model and three active lamps equipped on the simple docking station. This article presents a fast binocular localisation algorithm to determine the relative position and attitude between the AUV and the docking station. A relative localisation algorithm is applied when two cameras cannot capture all three lamps.
When all three lamps are captured by both cameras, the fast binocular localisation algorithm is able to compute the six-dimensional pose (including three-dimensional position and three-dimensional attitude) of the AUV via a mass-centre matching method. Moreover, a relative localisation method proposed by D. Li et al. [
11] is applied when the two cameras cannot capture all the lamps. The combination of these algorithms can improve the reliability of the system without a significant increase in the computational burden. The flow chart of the visual localisation algorithm is shown in
Figure 3.
3.1. Image Processing
Light is attenuated and scattered during underwater propagation, and hence, images captured in this environment may contain noise and artefacts. In this section, we utilise a median filter to remove image noise and propose a weighted OTSU method to binarise the image and to extract the mass centres of the captured lamps in the binary image.
3.1.1. Image Filtering
An underwater lamp consists of several small LEDs. As such, the captured image of an individual lamp may be identified as several lamps instead of one. A median filter with a 5 × 5 pixel mask was thus adopted to smooth the image and to remove salt-and-pepper noise while still retaining the edge information of the object.
Figure 4 shows the raw image and the image acquired after processing using the median filter.
3.1.2. Adaptively Weighted OTSU Method
Before feature matching, the object needs to be extracted from the processed image. It is feasible to segment the foreground object and the background scene through thresholding. In this article, we propose an adaptively weighted OTSU method to obtain the global optimal threshold for the captured image. The traditional OTSU method defines the segmentation threshold as the solution that maximises the between-class variance, which is established as follows:
where
ω0 and
ω1 denote the probability that a pixel is divided into the object and the background under the global threshold T, respectively. The variables
μ0 and
μ1 denote the average grey value of the object zone and the background zone and
μT is the average greyscale value of the entire image. The number of pixels divided into the object and the background is denoted as
N0 and
N1, respectively. Assuming
m and
n are the width and height of the image in pixel units, respectively, it can be induced from the definition that
ω0 =
N0/(
m ×
n) and
ω1 =
N1/(
m ×
n) as well as
N0 +
N1 =
m ×
n. Therefore, it is obvious to induce that
ω0μ0 +
ω1μ1 =
μT and
ω0 +
ω1 = 1.
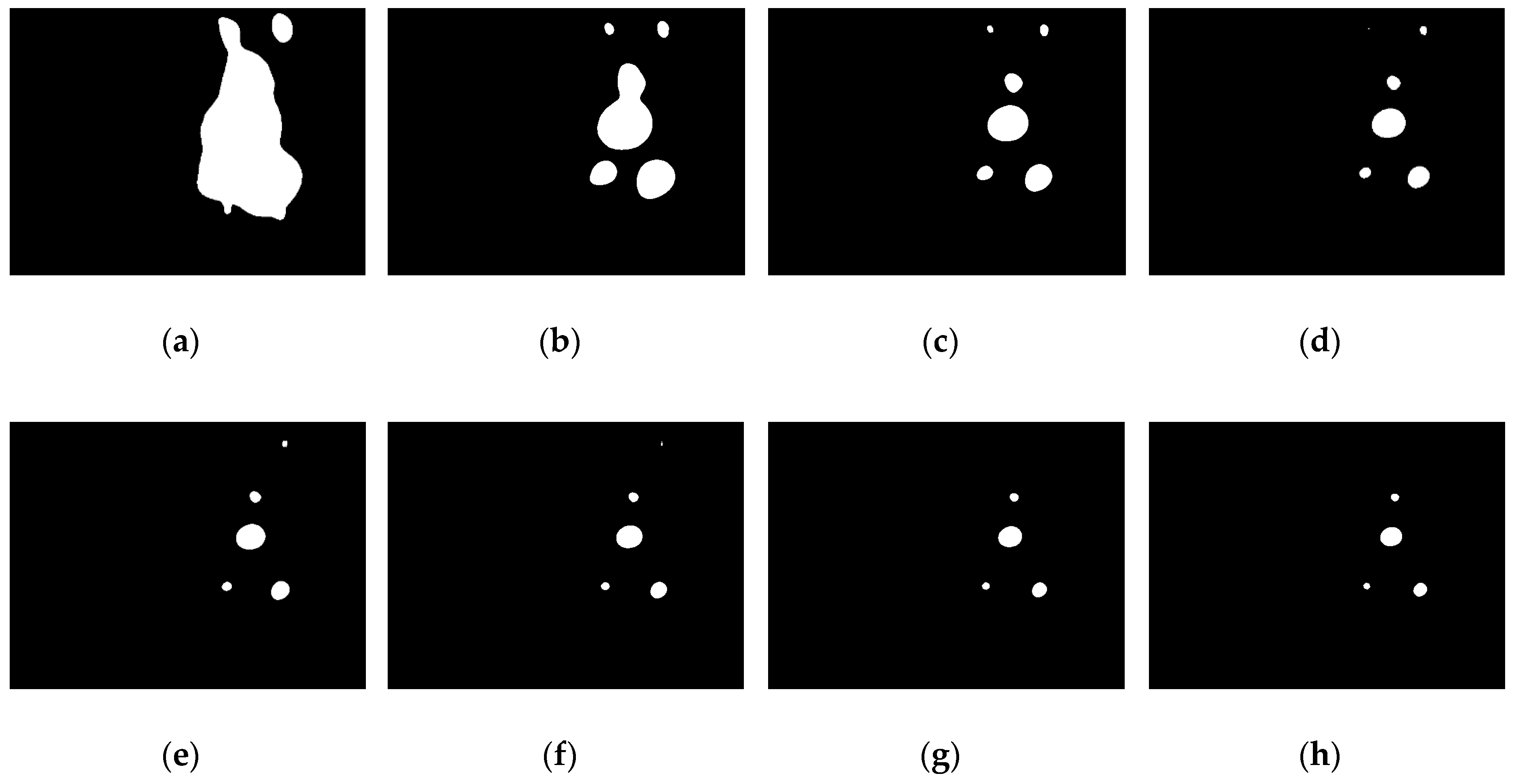
After applying the traditional OTSU method, the image shown in
Figure 4b becomes the binary image as shown in
Figure 5a. The result appears to be non-ideal. The reason for this is that most regions of the image captured underwater are background scene. In other words, the proportion of the pixels with a small grey value (i.e., the background) is much larger than the proportion of the pixels with a large grey value (i.e., the object) in the captured image. Therefore, in order to maximise the between-class variance, the optimal global threshold T calculated by the traditional OTSU method is more likely to be smaller, that is, biases towards the grey value of the background. In this way, some background pixels are segmented as the foreground object, so that the segmented object area is much larger than the real object area and several lamps are mixed together as shown in
Figure 5a. This method works well in the study by D. Li et al. [
11], because only one light is used for guidance, thereby avoiding the mixing problem. However, in this work, each lamp needs to be extracted individually for the subsequent feature matching process.
To fix the above problem, a weight coefficient is added to increase the proportion of the object in the between-class variance formula. The modified between-class variance is established as follows:
where K is the added weight coefficient. Assuming
ω0 and
ω1 are constant coefficients between 0 and 1, the smaller the value of K is, the larger the value of
and the smaller the value of
will be. This means that the proportion of the object in the between-class variance will be greater and the extracted objective region will be smaller. Then, in order to maximise the between-class variance, the output threshold of this modified method will bias toward the grey value of the objective region, i.e., the output threshold of this method will be higher than that of the original method. This conclusion is proven in
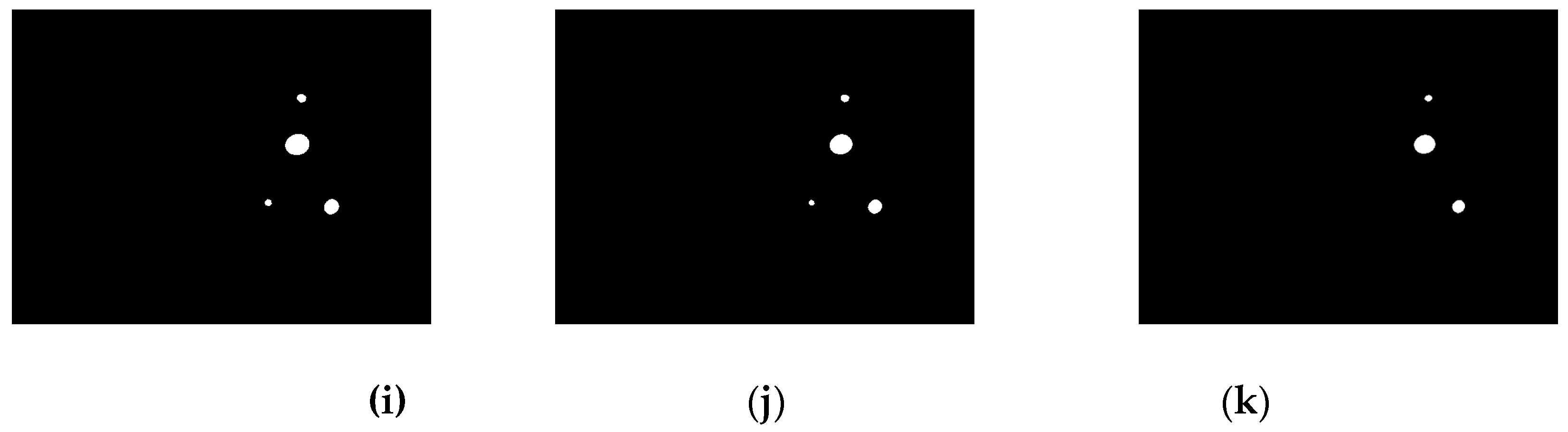
Figure 5.
The traditional OTSU algorithm is a particular case of the weighted OTSU algorithm when K is equal to 1, as shown in
Figure 5a.
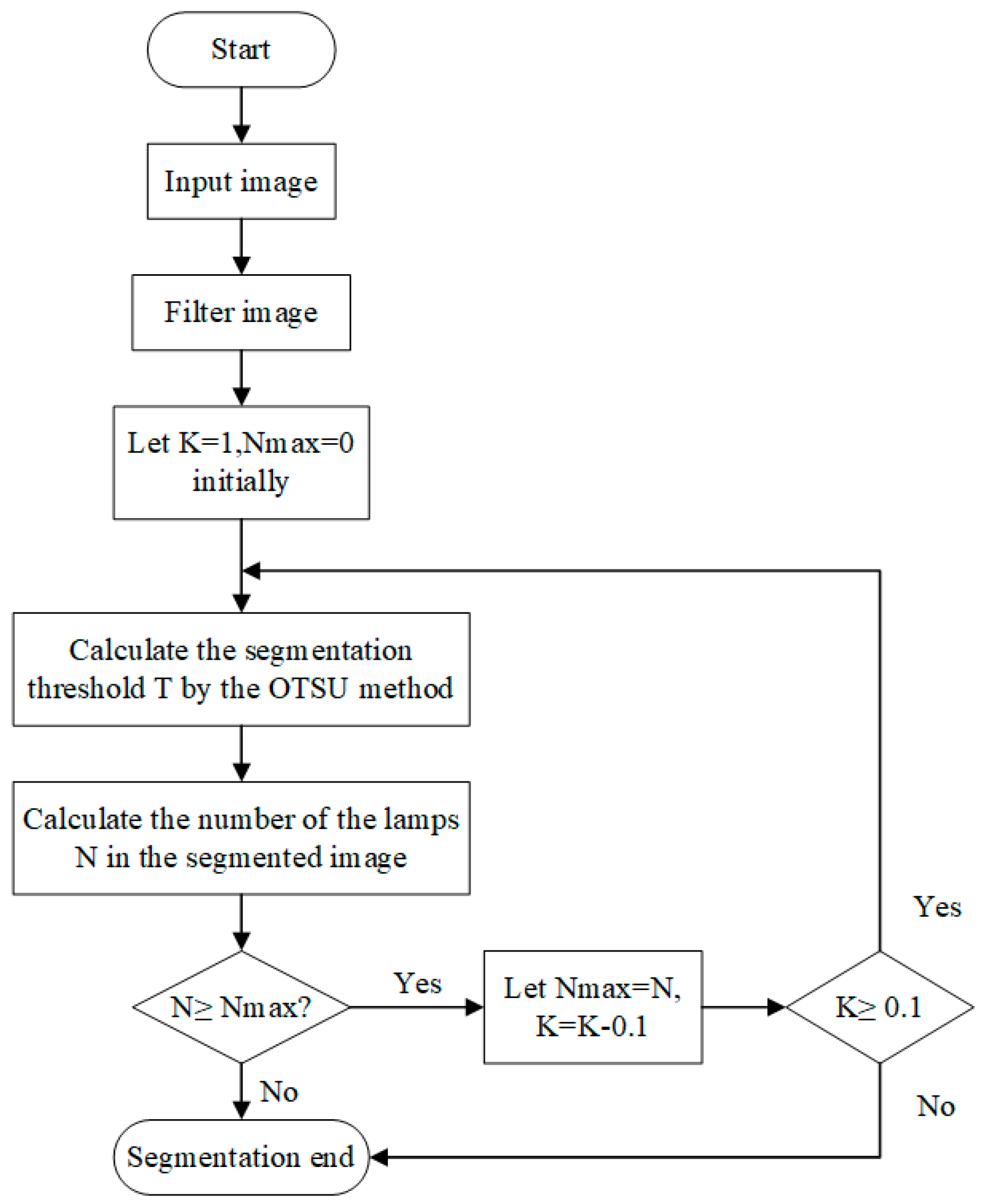
Figure 5b–k shows the binary images obtained through the weighted OTSU method with different weight coefficients. It can be observed that the smaller the weight coefficient K is, the larger the output global threshold T will be. When K is too small, the output threshold will extremely bias towards the grey value of the objective region. Therefore, the lamps with relatively low grey values cannot be extracted. Taking this condition into consideration, we would like to let K be adaptive according to the number of lamps in the segmented image. The procedures involved in the implementation of the adaptively weighted OTSU method is illustrated in
Figure 6. The final weight coefficient K* is selected by maximising the number of lamps in the segmented image N:
In this method, the extracted lamps are neither mixed nor missed, irrespective of the distance of the AUV from the station.
3.1.3. Image Segmentation
As mentioned in the previous section, threshold segmentation methods (TSMs) are usually used to segment the image into two classes: the objective zone and the background zone. When the boundary threshold T is given, the segmented image can be obtained as follows:
where f(i,j) and g(i,j) are the grey values of pixel point in the location (i,j) on the processed image and on the binary image, respectively. The pixel point with a grey value greater than or equal to T(i,j) becomes the bright group (grey value equal to 255) while the pixel point with a grey value smaller than T(i,j) becomes the dark group (grey value equal to 0). As such, the greyscale image is divided into the objective zone and the background zone.
Depending on whether the threshold T varies with the location of the pixel point, TSMs can be divided into local TSMs and global TSMs. The threshold of the former method is determined adaptively by the neighbourhood window that is centred on each pixel [
17]. In the latter method, the determination of the global threshold is of the most importance. Several studies on vision guidance technology have adopted diverse methods for determining the global threshold. Park et al. [
12] adopted a pre-specified threshold value to segment the greyscale image. D. Li et al. [
11] applied a traditional OTSU method to obtain the global optimal threshold, which has been commonly used for image segmentation due to its excellent performance. Y. Li et al. [
13] used a Mean-Shift algorithm to extract the light source zone. This algorithm is an iterative optimisation approach, which is computationally intensive. The computational burdens of the four aforementioned segmentation methods and the proposed adaptively weighted OTSU approach are illustrated in
Table 2. It is evident that the Mean-Shift algorithm takes more than ten times as long as the TSMs and is unsuitable for the real-time processing of images.
The threshold segmentation results of the four TSMs for the image shown in
Figure 4b are illustrated in
Figure 7, and the threshold segmentation results for the image captured near the station are shown in
Figure 8. It can be concluded that the adaptive local TSM is unsuitable for underwater lamp images due to its high sensitivity to the noise in the image. The pre-specified TSM is the fastest algorithm, but it is inflexible, owing to the brightness of the captured lamps varying with the distance between the AUV and the docking station. For example, when setting the pre-defined threshold as 125, this method appears to be suitable for images captured far from the station (
Figure 4b), but it fails to precisely extract the object when the image is captured near the station (
Figure 8c). With the traditional OTSU TSM, it is likely to mix up the lamps when the AUV is far from the station, in which cases most regions in the underwater captured images are background (
Figure 7c). Moreover, the adaptively weighted OTSU TSM can extract the object precisely without incurring a heavy computational burden, irrespective of the distance between the AUV and the station. Therefore, it outperforms the other four methods.
3.1.4. Feature Extraction
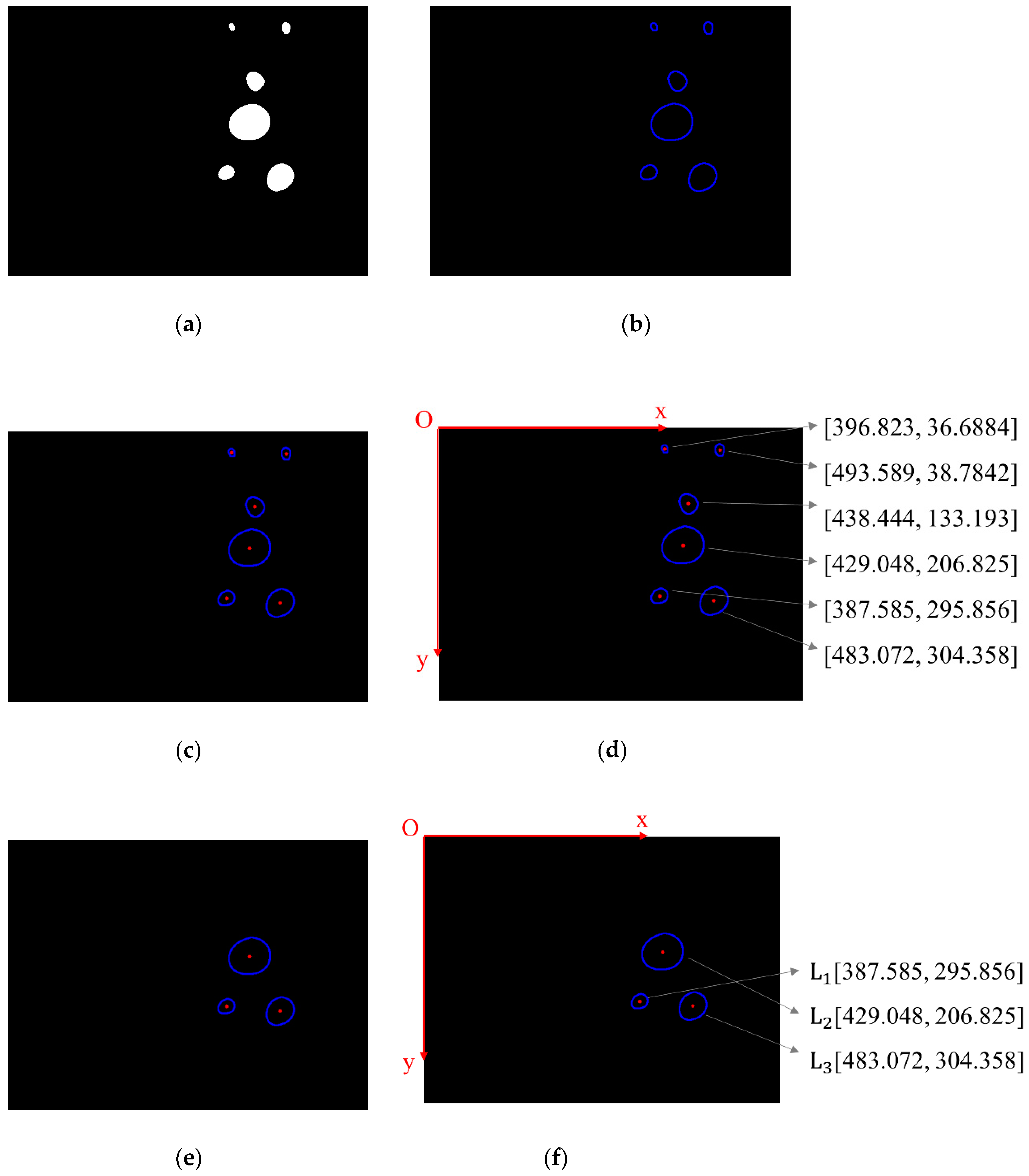
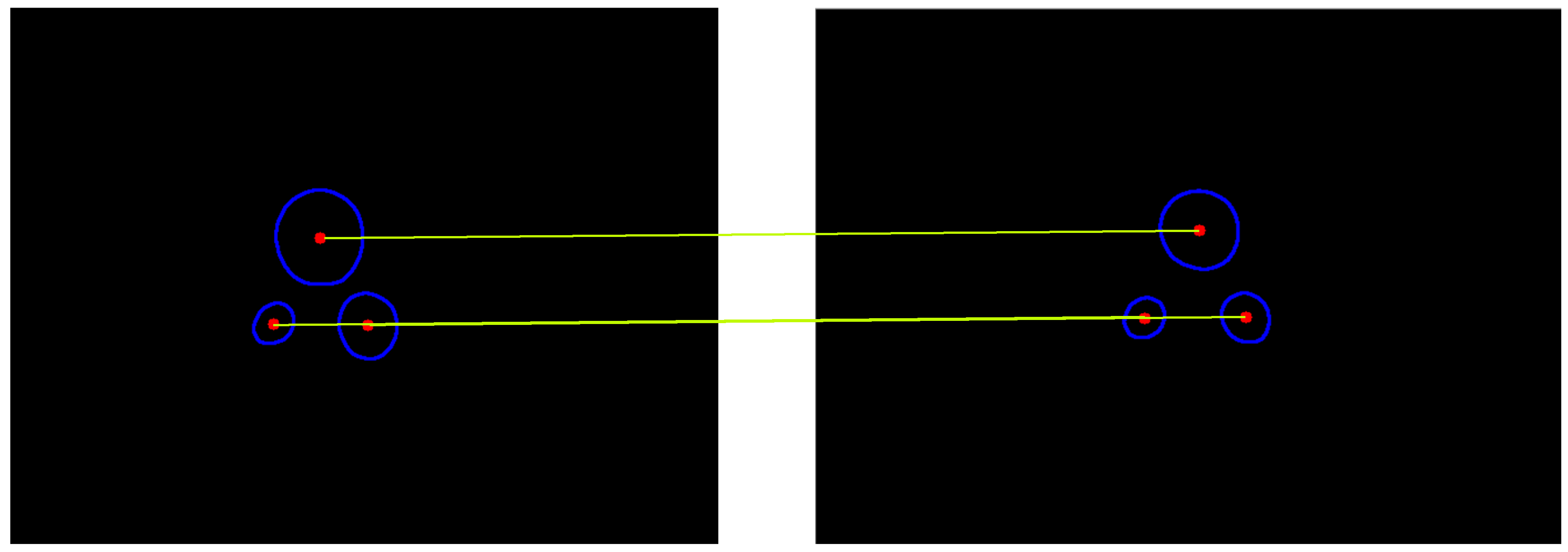
In this study, we chose the mass centres of the captured lamps as the matching feature of the binocular algorithm. We extracted all the contours of the lamps from the binary image as shown in
Figure 9b. Then the coordinates of pixels on each contour were averaged to obtain the coordinate of the mass centre of each contour, i.e., the mass centre of each lamp (
Figure 9c). The origin of the pixel coordinate frame is at the top left corner of the image while the positive directions of the x and y axis are respectively point to the left and upper side of the image as shown in
Figure 9d.
The mass centres were firstly sorted in terms of their vertical coordinates. To remove the reflected lamps located at the top of the image, we only kept three mass centres that had larger vertical coordinates (
Figure 9e). Then we sorted the mass centres of three lamps in terms of their horizontal coordinates and marked the three lamps in order. In this way, we can identify the lamps. When both cameras capture all three lamps, each lamp captured by the left and right camera can be matched in order.
When the roll angle of the AUV exceeds 60°, this sorting method fails. However, this situation rarely occurs. To ensure the normal functional operation of the AUV, IMU (Inertial Measurement Unit), compass, or other sensors will be applied to maintain the variation of the roll angle on a small fluctuation [
18]. This is not discussed herein.
3.2. Binocular Vision Algorithm
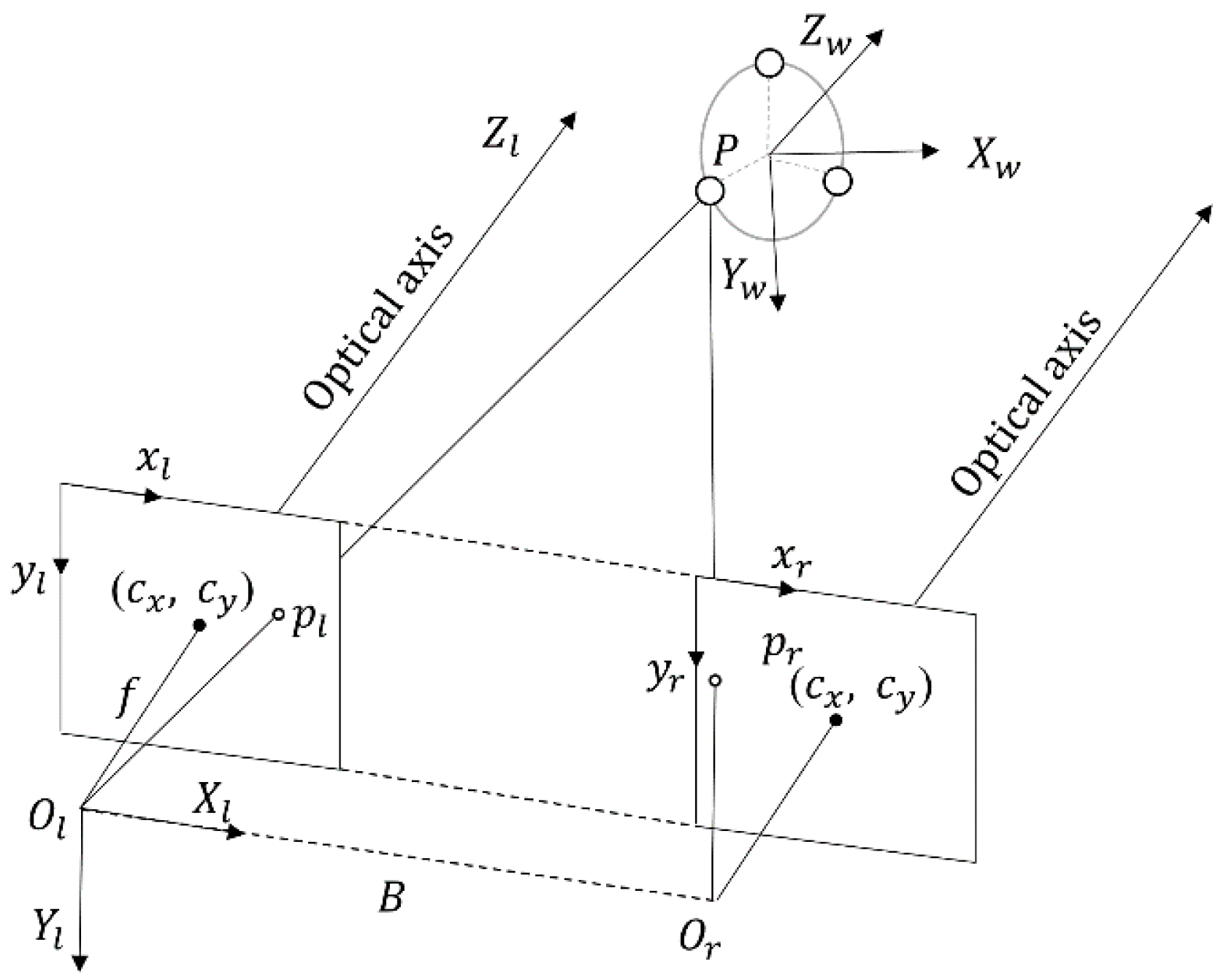
In this study, we apply a parallel binocular vision algorithm to realise the localisation. The position and attitude of the AUV relative to the docking station can be obtained using three co-planar lamps and two parallel cameras.
Firstly, we adopt the method proposed by Zhang Z. et al. [
19] to calibrate the cameras. Using the calibrated internal coefficients and the external coefficients of two cameras, we can rectify the captured images and ensure that the image planes of both cameras are ideally co-planar (
Figure 10).
Then, according to the similar triangle theorem, the position of a matching point in the left camera coordinate O
l-X
lY
lZ
l can be computed as:
where f is the focal length of the camera, B is the baseline length of the two cameras, x
l and x
r are the horizontal positions of a point in the image coordinate of the left and right camera, respectively, while y
l and y
r are the vertical positions.
cx and
cy are, respectively, the horizontal and vertical position of the optical centre in the image plane.
The coordinate frames of the vision guidance system in this study are shown in
Figure 11. In the AUV body frame, the position of the matching point can be obtained as:
The dock coordinate refers to the earth or the inertial frame. The position of the matching points in the AUV coordinate P
A can be computed from Equations (8)–(10), while the positions of the three lamps in the dock coordinate P
D are determined. Therefore, using the three matching points, the relative translation and rotation of the two coordinates, namely the position and attitude of the AUV relative to the dock, can be computed by the transverse formula:
where T is the translation vector and R is the rotation matrix. Given that the average position of the three lamps is the origin of the dock coordinate, T can be computed as the average position of the three matching points in the AUV coordinate as follows:
Then, R can be computed from Equation (11) via the positions of the three matching points in the AUV and dock coordinate. Assuming that ψ, θ and φ are the rotation angles of the AUV coordinate relative to the dock coordinate in the X, Y, and Z direction, R can be described as:
Assuming R
ij is the element of matrix R in the ith row and the jth column, the attitude of AUV can be obtained from Equation (13):
Hence, the three-dimensional position and three-dimensional attitude of AUV relative to the docking station are deduced. The matching features of the images captured by the two cameras are discussed in
Section 3.1 and are shown in
Figure 12. With this feature matching method, the operation frequency of the binocular ranging algorithm can exceed 10 Hz and the entire visual process can reach 5 Hz, which satisfies the control requirement.
When both cameras cannot capture all the lamps, we can only calculate the relative distance at the X and Y dimension between the docking station and the AUV. The average coordinates of the mass centres of the captured lamps in the left and right image plane can be computed from the processed image, denoted as (
,
) and (
,
), respectively, in pixel units. Then the position of the docking station relative to the AUV (
,
) in pixel units can be computed as follows:
3.3. Control Strategy
The motion control system for AUV consists of two independent parts, namely, the control strategies for the horizontal and vertical plane [
20]. The control schemes for motion in two planes are similar [
11]. To avoid redundancy, we only focus on the tracking control strategy on one plane and the other plane can be derived in a similar manner. Furthermore, during the docking stage in a real scenario, the AUV tends to sail at a setting depth and to move on the horizontal two-dimensional plane. Hence, in this study, we only discuss the two-dimensional motion control on the horizontal plane and carry out the experiment in the same way. The classical Proportion Integration Differentiation (PID) control strategy is used to control the yaw angle of the ship model on the horizontal plane.
When both cameras are able to capture all three lamps, we can obtain the three-dimensional position and attitude of the AUV relative to the docking station from the binocular vision algorithm. From the obtained three-dimensional position, the horizontal yaw angle of the ship model relative to the docking station can be obtained as follows:
where X
A and Z
A denote the position of the docking station in the X and Z direction of the AUV coordinate, respectively.
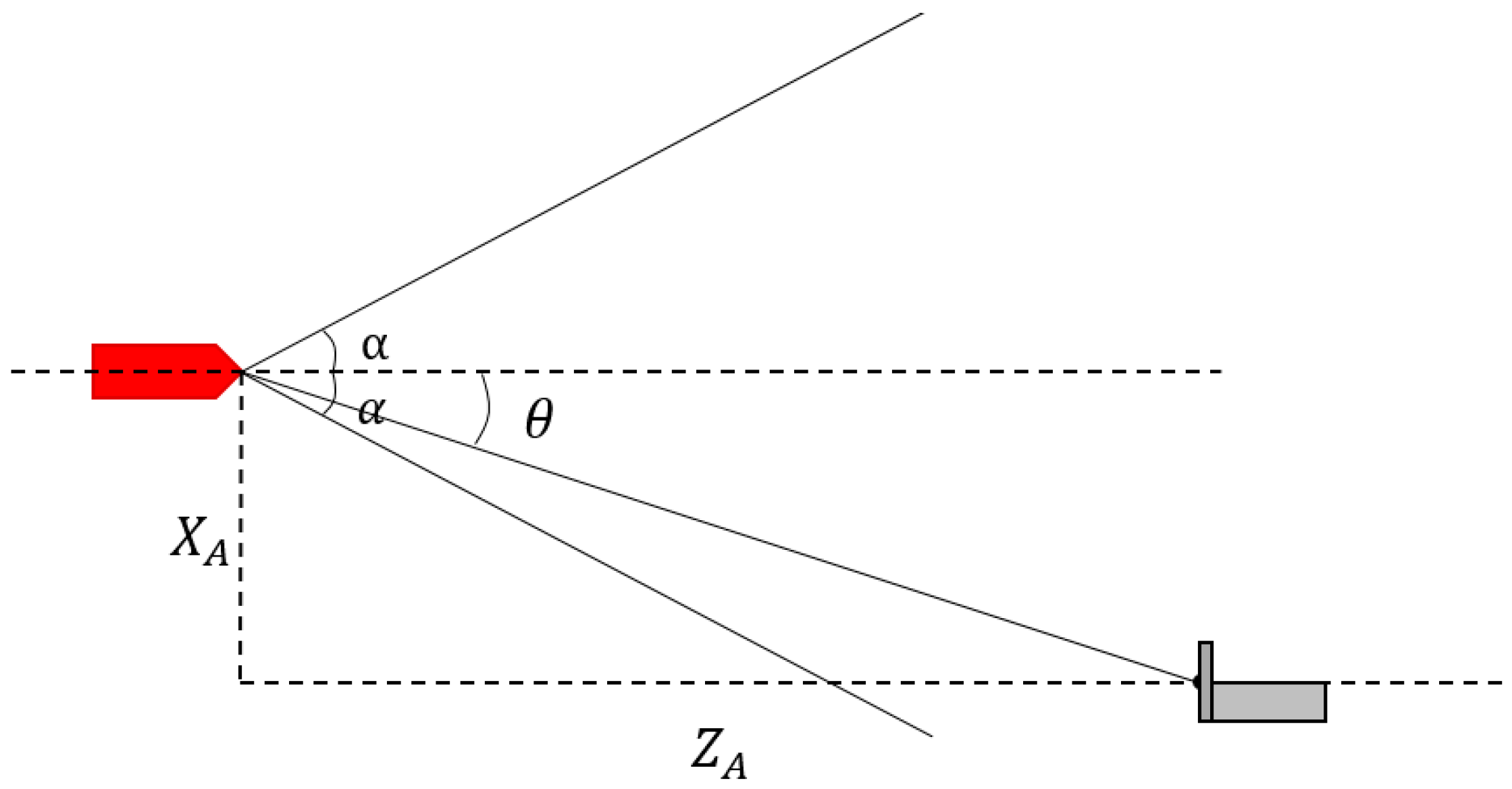
When the two cameras cannot capture all three lamps, we can only obtain the relative position of the docking station relative to the ship model in pixel units (
,
). In such cases, Equation (17) is not applicable. Assuming that the field angle of the camera is α, we can obtain the following equation via the geometric relationship and the camera model shown in
Figure 13:
where k is the proportional coefficient.
Therefore, the horizontal yaw angle of the ship model can be derived as:
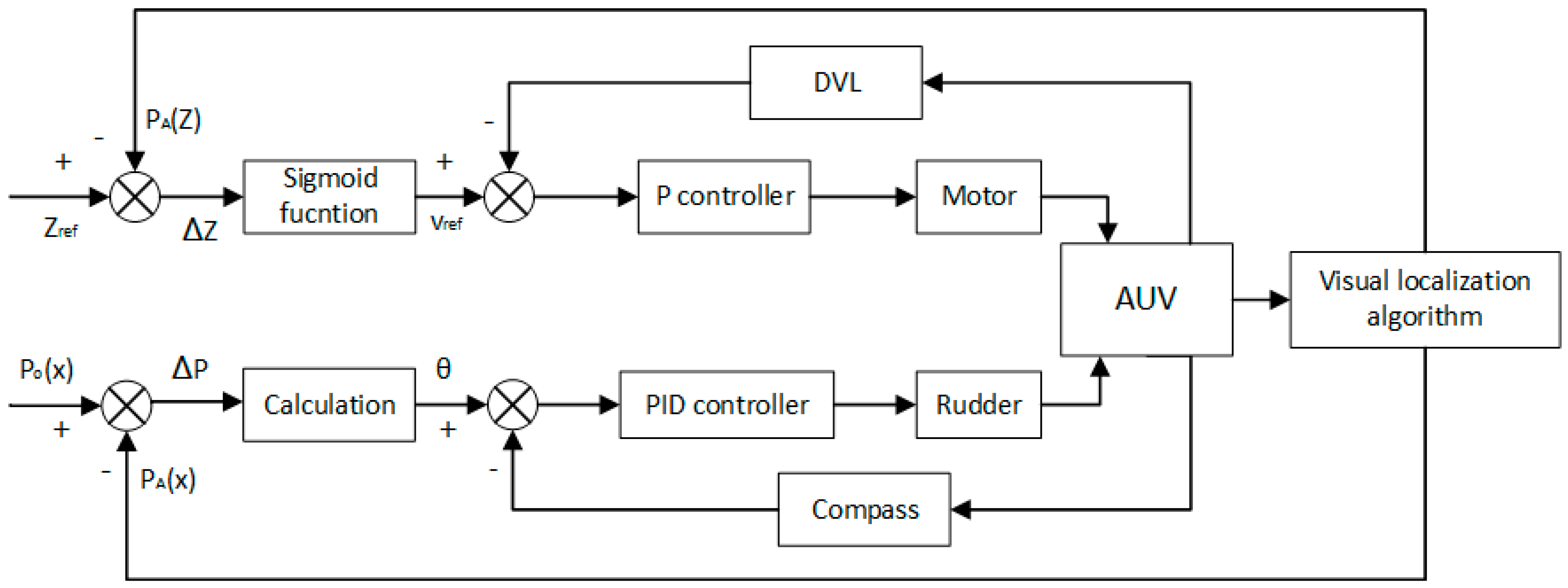
The PID control scheme is illustrated in
Figure 14. The position of the docking station in the AUV coordinate P
A can be obtained by the proposed vision localisation algorithm, while P
O denotes the origin of the AUV coordinate. The deviation between P
A and P
O, denoted as ΔP, is equal to P
A. Thereby, the yaw angle θ can be calculated by Equations (17) and (20). The compass can measure the angle of the centre line of the AUV deviated from the centre line of the docking station θ
dock. The deviation between θ and θ
dock, denoted as Δθ, serves as the input of the controller, the coefficients of which are determined by trial and error.
Moreover, it is possible for AUV to obtain its six-dimensional pose relative to the docking station when the binocular vision algorithm works. Therefore, except for the heading direction, the AUV can control its speed as well. When the target position in Z direction P
A(z) is larger than the reference Z-distance Z
ref, which is set as 5 m, it is suggested that the AUV moves at a relatively high velocity. When Z
A is smaller than Z
ref, it is suggested that the AUV moves at a relatively low velocity to avoid strong collision with the docking station. The relationship between the deviation ∆Z and the reference velocity v
ref is established via the sigmoid function:
where v
0 is the minimum velocity of the AUV and K
v + v
0 is the maximum velocity. K
v is set as v
0 so that the maximum velocity is twice the minimum velocity.
In conditions where the two cameras cannot capture all three lamps, the AUV is either within short range of the docking station or has a large deviation from the docking station. In this case, it is desirable that the AUV moves slowly, and hence we let Z
A be equal to 0 m. The control strategy scheme on the horizontal plane is shown in
Figure 14.
5. Conclusions
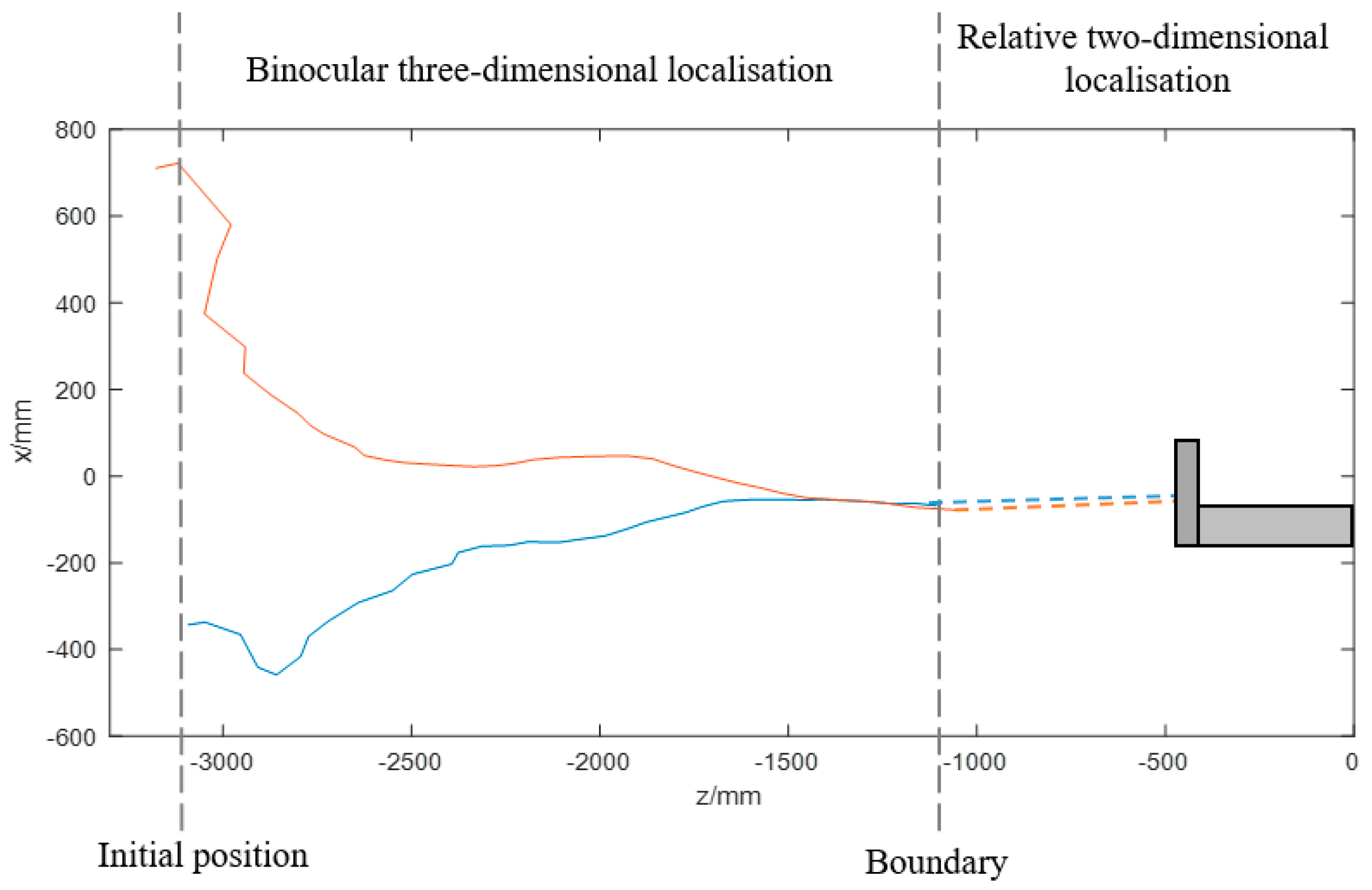
This study presents a fast binocular localisation method in combination with a relative pose estimation method for the instance when two cameras cannot capture all the lamps. A detailed description of the system configuration is proposed. Through image processing, including image filtering, image segmentation using an adaptively weighted OTSU method and feature extraction, the mass centres of the lamps are obtained as the matching features of the binocular algorithm. A control strategy based on this vision algorithm is then provided. The test at fixed points shows that the relative localisation error in the heading direction within 3.6 m is approximately 2%, which satisfies the requirements for tracking control. A verification experiment was conducted in the laboratory pool using a ship model to evaluate the feasibility of the entire system. The ship model can achieve docking no matter whether it starts at the right side or the left side of the docking station.
Compared with the other vision guidance systems mentioned in the introduction, the vision guidance system presented in this article has the following advantages. Firstly, an adaptively weighted OTSU method is proposed to segment the captured image with good performance and a relatively low cost of computation compared with other TSMs. Secondly, the frequency of the proposed binocular localisation method can reach up to 10 Hz, and the entire algorithm can achieve 5 Hz. Furthermore, the vision algorithm includes a relative pose estimation method in the case when there are one or more lamps out of the viewing field of the cameras. The vision guidance algorithm will work even if only one of the cameras captures lamps, greatly extending its working range.
However, some defects still exist in this article and can be optimised in the future. For example, the pool experiment conducted in this article uses a model ship to validate the proposed algorithm. In future work, experiments using a full-sized AUV will be conducted in a deep-water area to evaluate the effectiveness of the proposed system in an actual sea environment. The motion in the vertical plane will be taken into consideration. Moreover, to make this vision guidance algorithm more practical, a dead reckoning algorithm could be used as an assisted algorithm for circumstances when the target is lost from the sight of both cameras during the docking stage. In addition, a laser source may be considered in the future to extend the effective range of the vision guidance system.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}