Object Tracking Based on Vector Convolutional Network and Discriminant Correlation Filters


Abstract
:1. Introduction
- We introduce the VCNN to reduce the parameter set of appearance representation.
- A coarse-to-fine search strategy is proposed to solve drift problems under fast motion.
- A robust online update strategy is introduced to ignore the low confidence disturbance.
2. Materials and Methods
2.1. Overview
2.2. Network Architecture
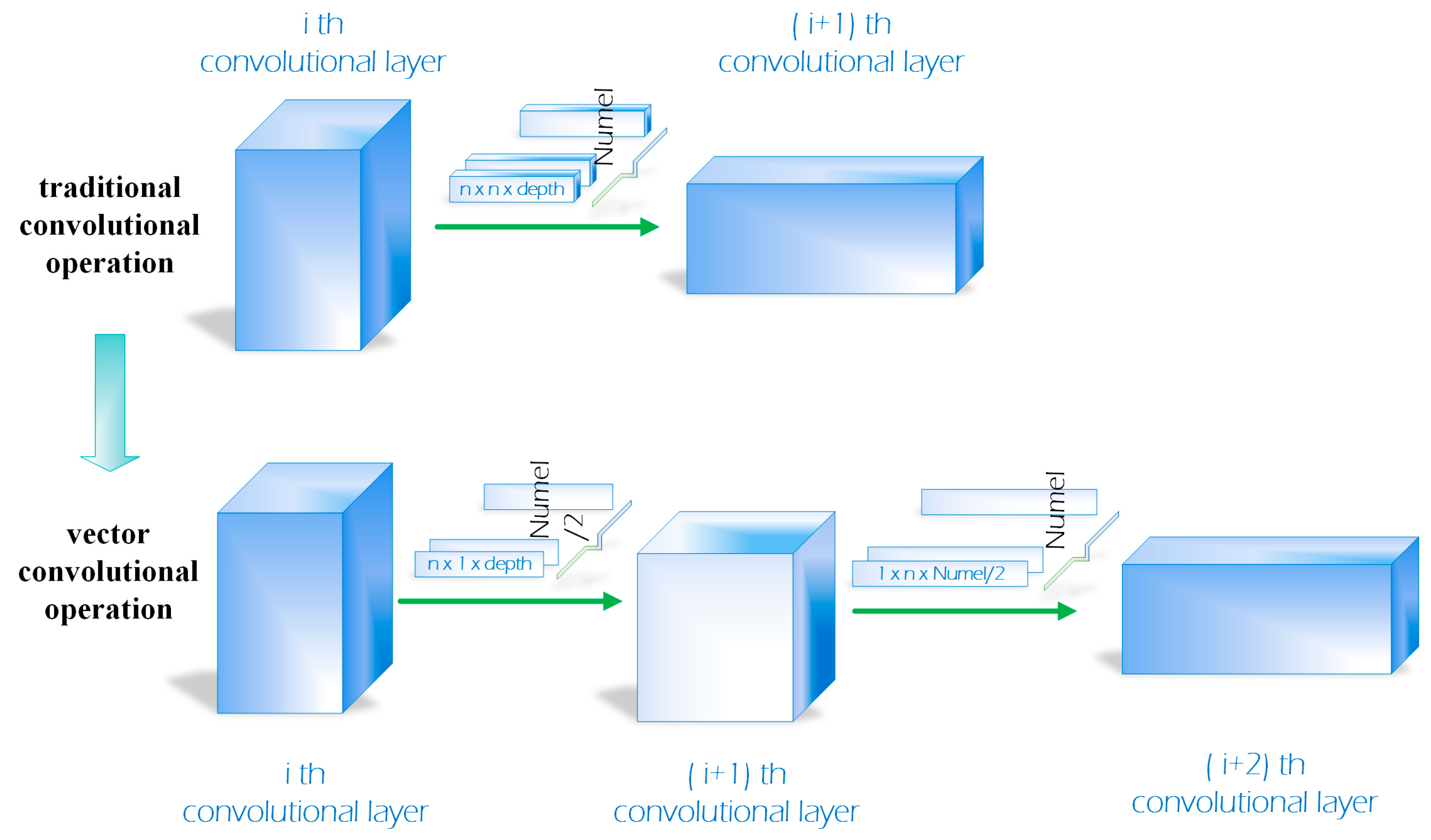
2.2.1. Vector Convolution Operator
2.2.2. Siamese Network
2.2.3. DCF Layer
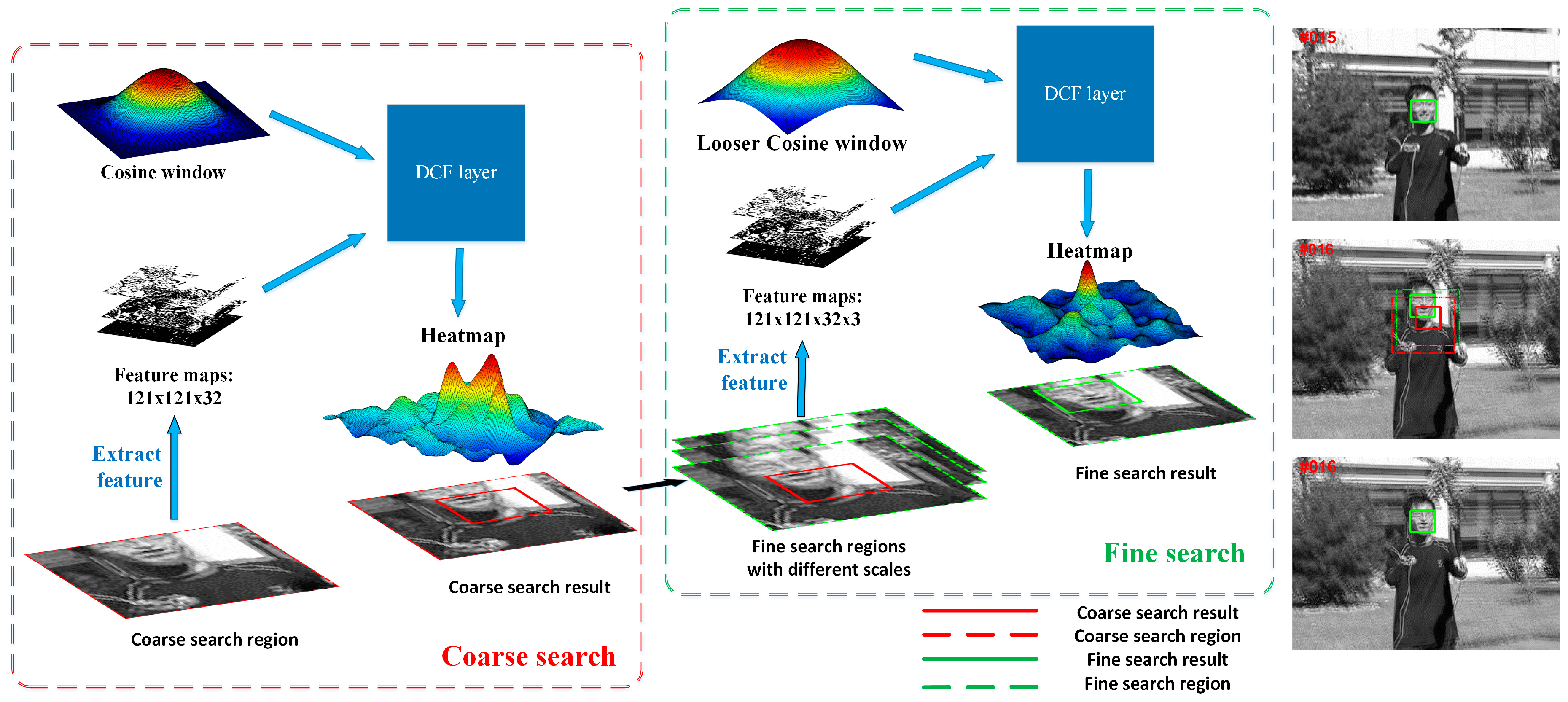
2.2.4. Coarse-to-Fine Search
2.2.5. Online Model Update
3. Results and Discussion
3.1. Implementation Details
3.2. Experiment Analysis
3.2.1. Dataset
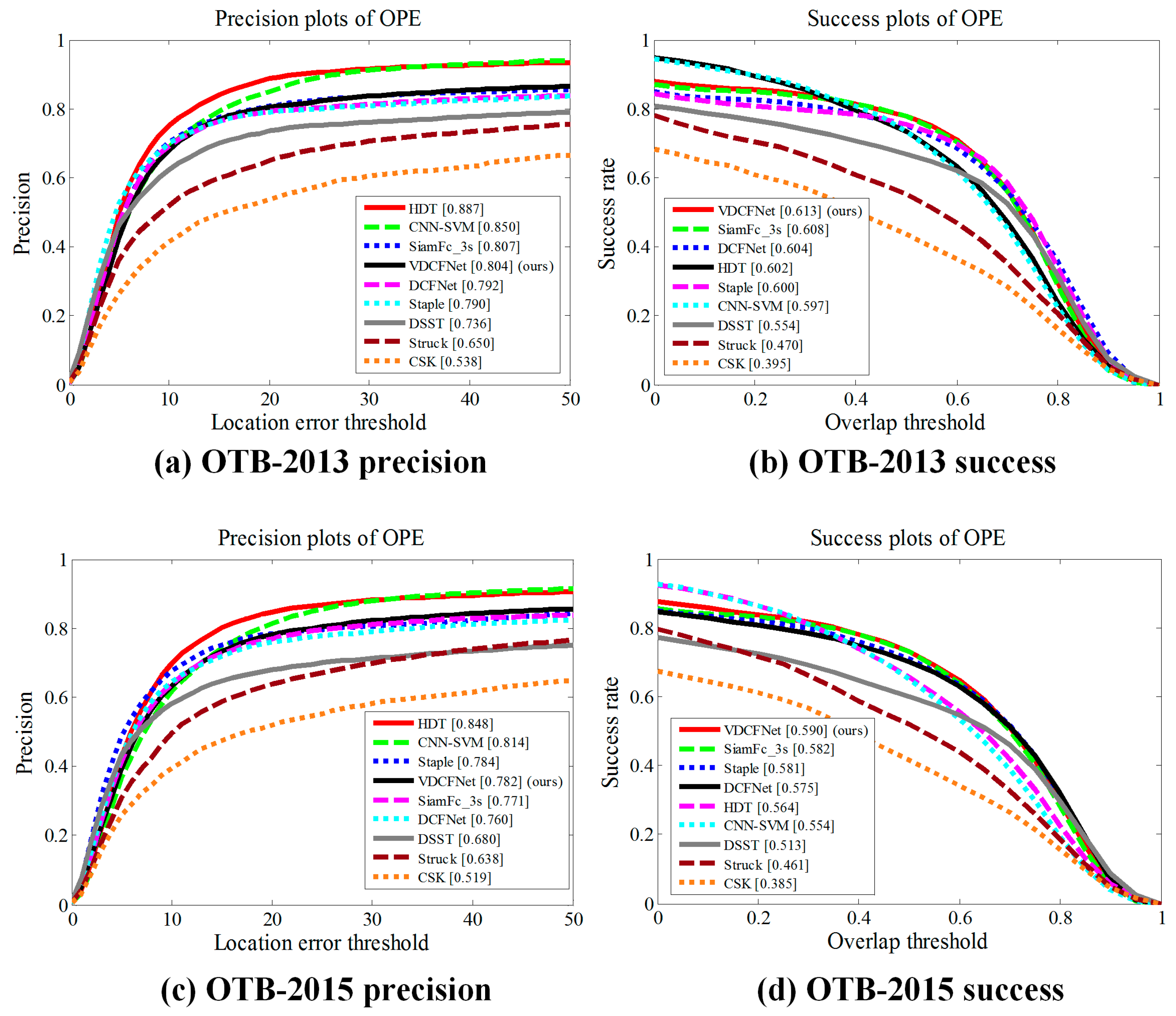
3.2.2. Comparison on OTB
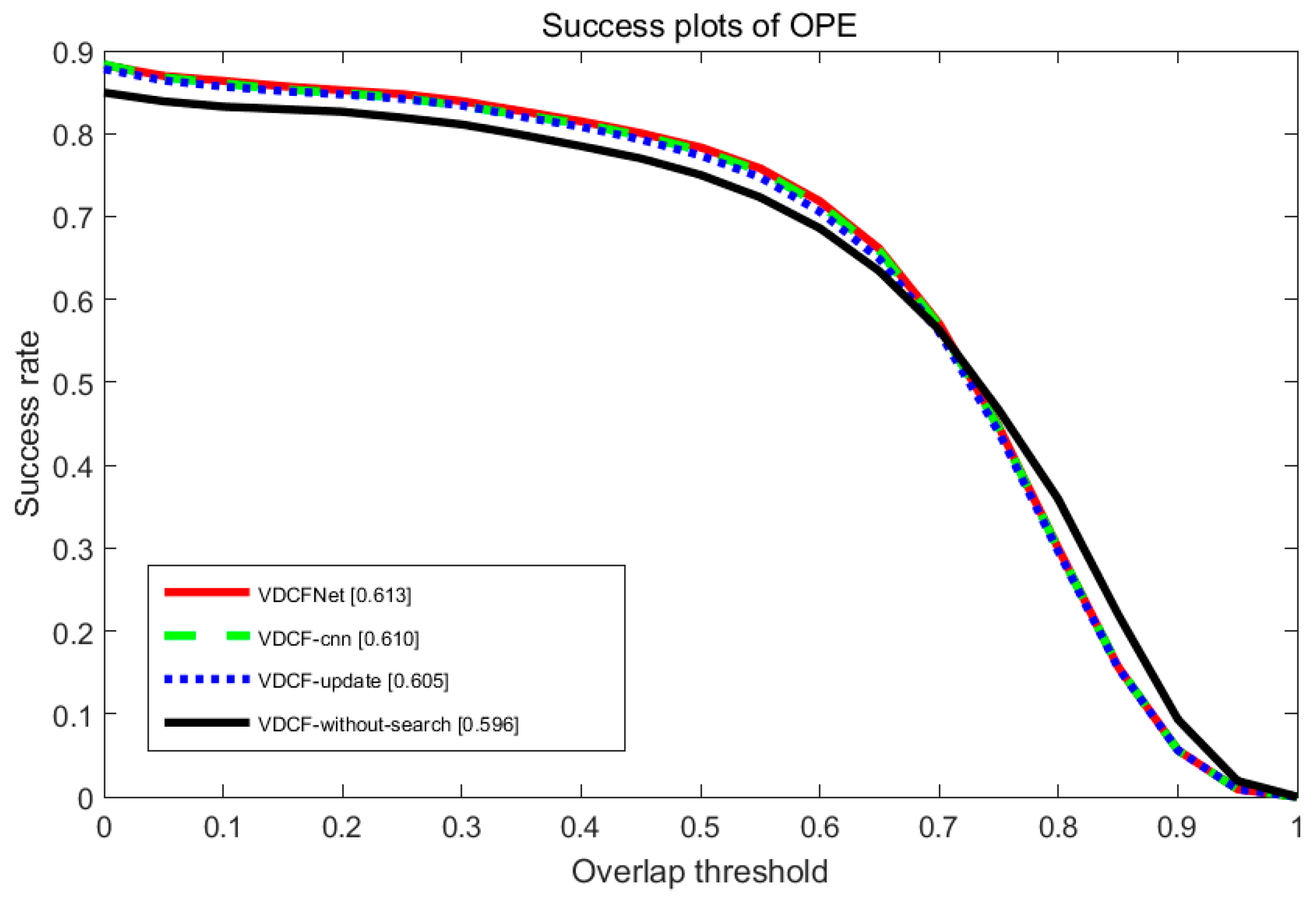
3.2.3. Ablative Analysis
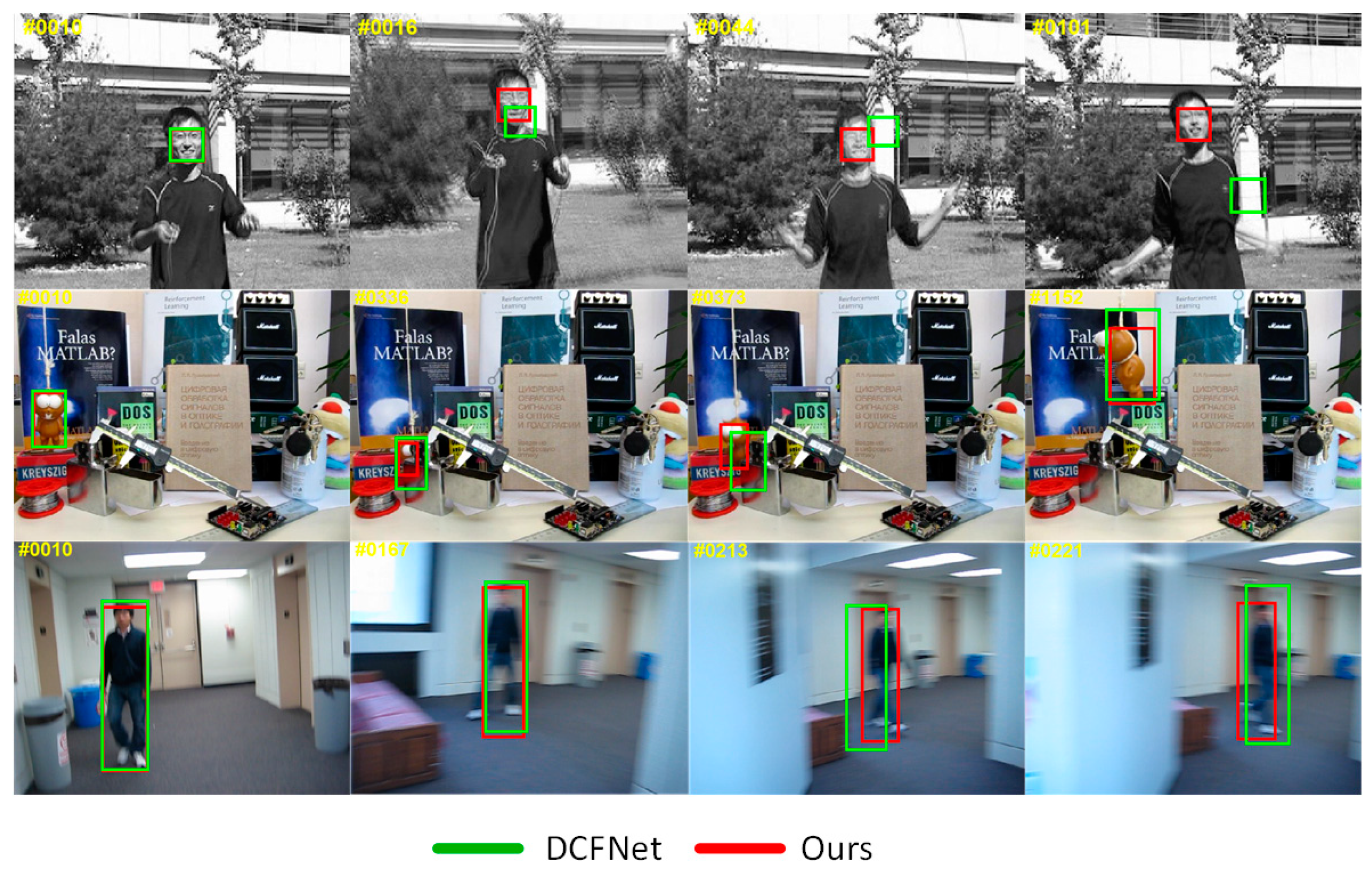
3.2.4. Qualitative Evaluation
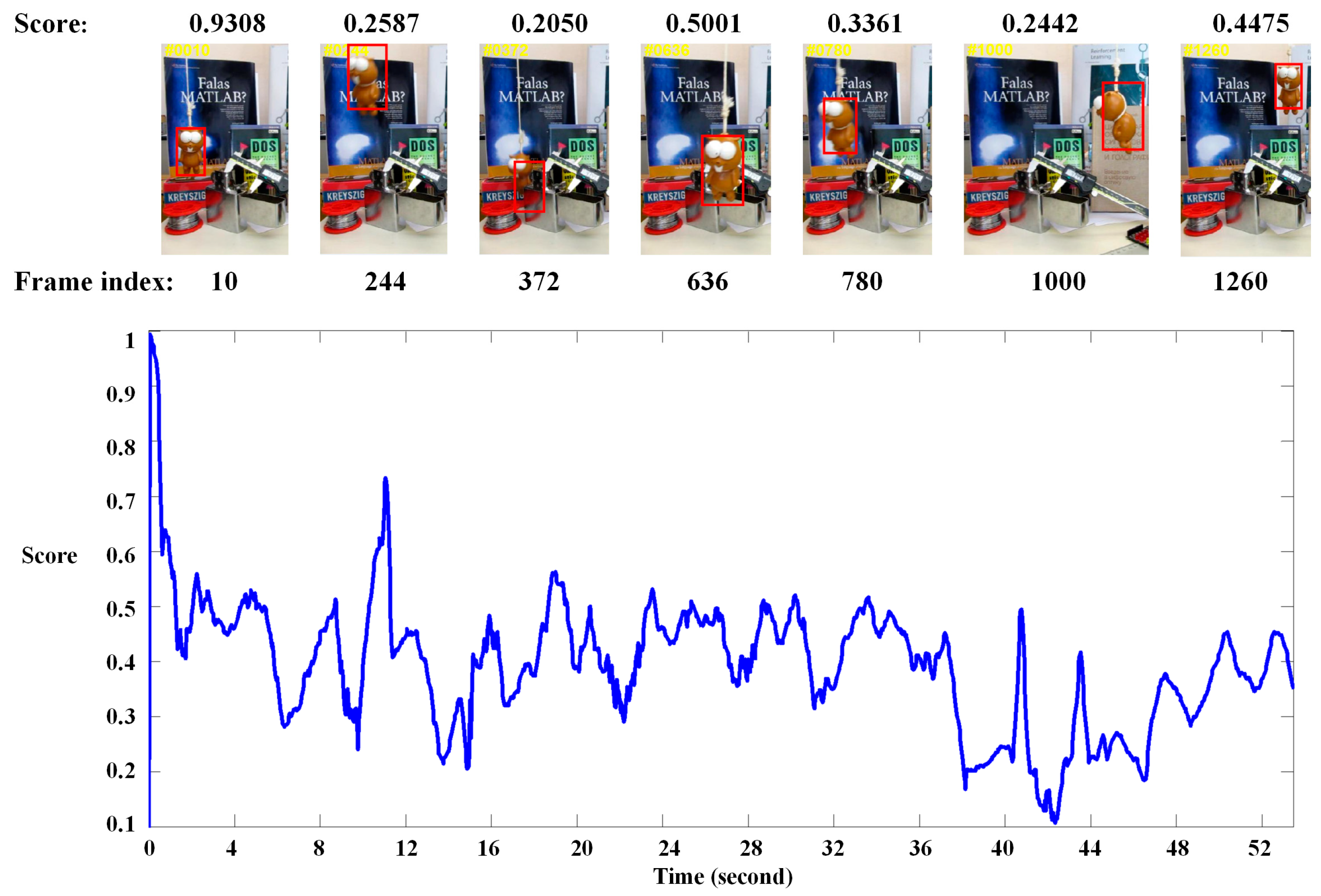
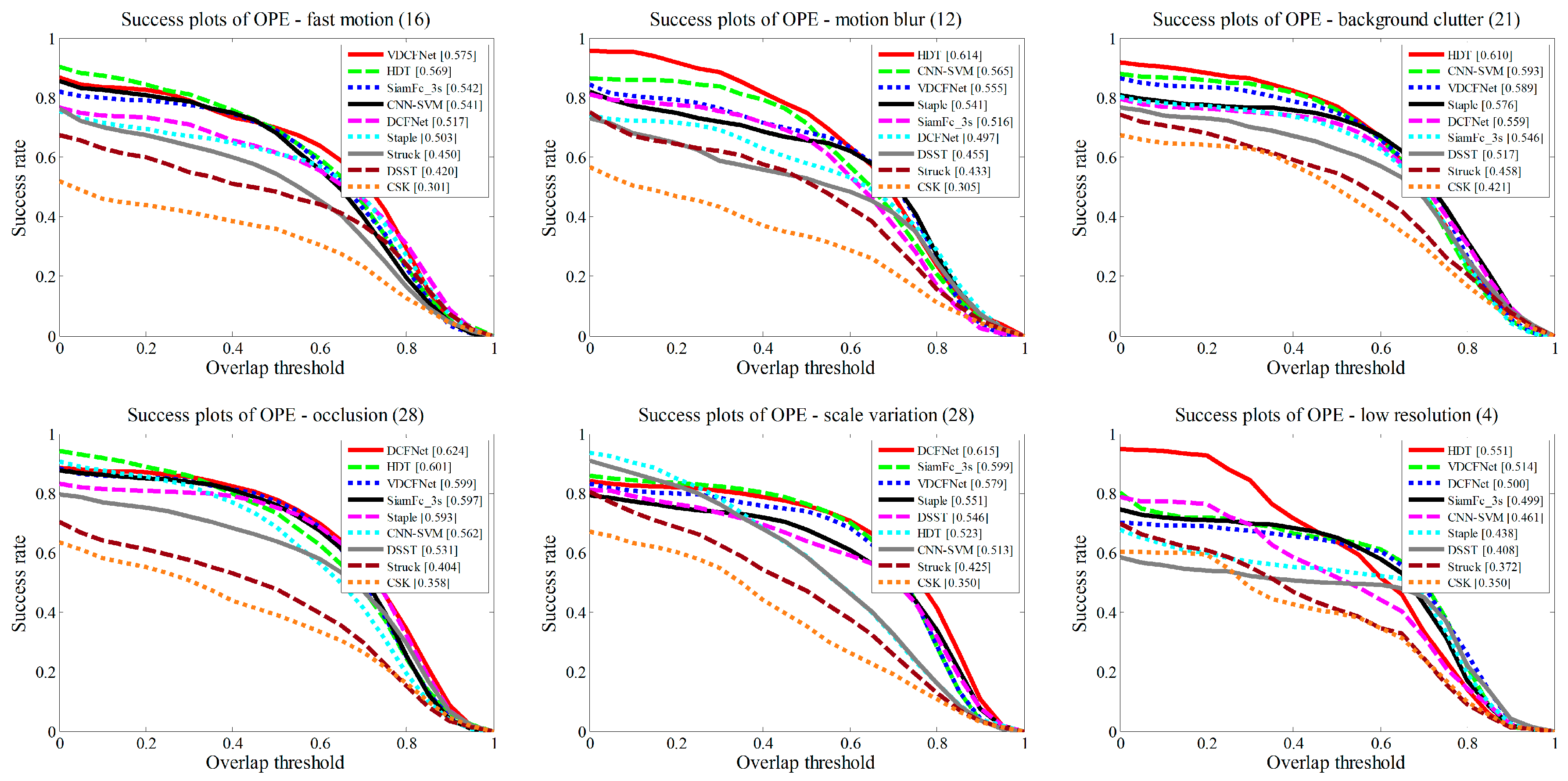
3.2.5. Failure Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed]
- Yang, H.; Shao, L.; Zheng, F.; Wang, L.; Song, Z. Recent advances and trends in visual tracking: A review. Neurocomputing 2011, 74, 3823–3831. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.-H. Online object tracking: A benchmark. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.-H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Shi, J.; Yeung, D.-Y.; Jia, J. Understanding and diagnosing visual tracking systems. In Proceedings of the Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3101–3109. [Google Scholar]
- Jin, Z.; Hou, Z.; Yu, W.; Chen, C.; Wang, X. Game theory-based visual tracking approach focusing on color and texture features. Appl. Opt. 2017, 56, 5982–5989. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Sui, X.; Pan, K.; Tao, Y. Adaptive pedestrian tracking via patch-based features and spatial–temporal similarity measurement. Pattern Recognit. 2016, 53, 163–173. [Google Scholar] [CrossRef]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online tracking by learning discriminative saliency map with convolutional neural network. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.-H. Robust visual tracking via convolutional networks without training. IEEE Trans. Image Process. 2016, 25, 1779–1792. [Google Scholar] [CrossRef] [PubMed]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Chi, Z.; Li, H.; Lu, H.; Yang, M.-H. Dual deep network for visual tracking. IEEE Trans. Image Process. 2017, 26, 2005–2015. [Google Scholar] [CrossRef] [PubMed]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 749–765. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Kang, W.; Liu, G.; Jia, M. REMOVED: Adaptive correlation filters for robust object tracking. Pattern Recognit. 2017, 72, 484–493. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Qi, Y.; Zhang, S.; Qin, L.; Yao, H.; Huang, Q.; Lim, J.; Yang, M.-H. Hedged deep tracking. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4303–4311. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. arXiv, 2017; arXiv:1704.04057. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2016; arXiv:1602.07261v2. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <1 mb model size. arXiv, 2016; arXiv:1602.07360. [Google Scholar]
- Boeddeker, C.; Hanebrink, P.; Drude, L.; Heymann, J.; Haeb-Umbach, R. On the computation of complex-valued gradients with application to statistically optimum beamforming. arXiv, 2017; arXiv:1701.00392. [Google Scholar]
- Li, A.; Lin, M.; Wu, Y.; Yang, M.-H.; Yan, S. Nus-pro: A new visual tracking challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 335–349. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.; Blasch, E.; Ling, H. Encoding color information for visual tracking: Algorithms and benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 24, 5630–5644. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 445–461. [Google Scholar]
- Vedaldi, A.; Lenc, K. Matconvnet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.-M.; Hicks, S.L.; Torr, P.H. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2096–2109. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Convolutional Filter | Stride | Exemplar Branch | Searching Branch |
|---|---|---|---|---|
| Input | 3 @ 125 × 125 | 3 @ 125 × 125 | ||
| vconv1 | 32 @ 3 × 1 × 3 | 1 | 32 @ 123 × 125 | 32 @ 123 × 125 |
| vconv2 | 64 @ 1 × 3 × 32 | 1 | 64 @ 123 × 123 | 64 @ 123 × 123 |
| Relu | ||||
| vconv3 | 32 @ 3 × 1 × 64 | 1 | 32 @ 121 × 123 | 32 @ 121 × 123 |
| vconv4 | 32 @ 1 × 3 × 32 | 1 | 32 @ 121 × 121 | 32 @ 121 × 121 |
| Name | IV | SV | OCC | DEF | MB | FM | IPR | OPR | OV | BC | LR | Overall Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours | 0.558 | 0.579 | 0.595 | 0.573 | 0.555 | 0.575 | 0.557 | 0.573 | 0.578 | 0.574 | 0.514 | 0.613 |
| SiamFc_3s | 0.532 | 0.599 | 0.597 | 0.541 | 0.516 | 0.542 | 0.570 | 0.589 | 0.635 | 0.546 | 0.499 | 0.608 |
| DCFNet | 0.574 | 0.615 | 0.624 | 0.558 | 0.497 | 0.517 | 0.569 | 0.589 | 0.668 | 0.559 | 0.500 | 0.604 |
| HDT | 0.553 | 0.523 | 0.601 | 0.627 | 0.614 | 0.569 | 0.578 | 0.583 | 0.569 | 0.610 | 0.551 | 0.602 |
| CNN-SVM | 0.555 | 0.513 | 0.562 | 0.640 | 0.565 | 0.541 | 0.570 | 0.581 | 0.571 | 0.593 | 0.461 | 0.574 |
| Staple | 0.568 | 0.551 | 0.593 | 0.618 | 0.541 | 0.503 | 0.580 | 0.575 | 0.547 | 0.576 | 0.438 | 0.600 |
| DSST | 0.561 | 0.546 | 0.531 | 0.506 | 0.455 | 0.420 | 0.563 | 0.535 | 0.462 | 0.517 | 0.408 | 0.554 |
| Struck | 0.418 | 0.425 | 0.404 | 0.393 | 0.433 | 0.450 | 0.436 | 0.425 | 0.459 | 0.458 | 0.372 | 0.470 |
| CSK | 0.361 | 0.350 | 0.358 | 0.343 | 0.305 | 0.301 | 0.394 | 0.381 | 0.349 | 0.421 | 0.350 | 0.395 |
| Tracker | OP | DP | CLE | FPS | Parameters |
|---|---|---|---|---|---|
| vconv1-dcf | 0.88 | 0.84 | 11.56 | 65.04 | 1728 |
| conv1-dcf | 0.89 | 0.84 | 11.52 | 65.94 | 896 |
| vconv2-dcf | 0.86 | 0.80 | 13.06 | 53.62 | 4848 |
| conv2-dcf | 0.87 | 0.79 | 12.98 | 54.46 | 10144 |
| vconv3-dcf | 0.81 | 0.72 | 14.02 | 41.04 | 7968 |
| conv3-dcf | 0.82 | 0.76 | 14.38 | 43.26 | 19392 |
| vconv5-dcf | 0.57 | 0.51 | 17.68 | 33.12 | 14208 |
| conv5-dcf | 0.60 | 0.57 | 16.76 | 30.84 | 37888 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Sui, X.; Kuang, X.; Liu, C.; Gu, G.; Chen, Q. Object Tracking Based on Vector Convolutional Network and Discriminant Correlation Filters. Sensors 2019, 19, 1818. https://doi.org/10.3390/s19081818
Liu Y, Sui X, Kuang X, Liu C, Gu G, Chen Q. Object Tracking Based on Vector Convolutional Network and Discriminant Correlation Filters. Sensors. 2019; 19(8):1818. https://doi.org/10.3390/s19081818
Chicago/Turabian StyleLiu, Yuan, Xiubao Sui, Xiaodong Kuang, Chengwei Liu, Guohua Gu, and Qian Chen. 2019. "Object Tracking Based on Vector Convolutional Network and Discriminant Correlation Filters" Sensors 19, no. 8: 1818. https://doi.org/10.3390/s19081818
APA StyleLiu, Y., Sui, X., Kuang, X., Liu, C., Gu, G., & Chen, Q. (2019). Object Tracking Based on Vector Convolutional Network and Discriminant Correlation Filters. Sensors, 19(8), 1818. https://doi.org/10.3390/s19081818