Generally, establishing a PSF under a specific motion is the key to star image recovery. In this section, first, we analyze the PSF model of the blurred star image caused by the rotation of the star sensor around the optical axis and non-optical axis and calculate the PSF in the corresponding motion condition through the angular velocity information of the gyroscope. Then, we introduce an improved RL algorithm to recover the blurred star image.
3.1. Motion Blur Model of the Star Image
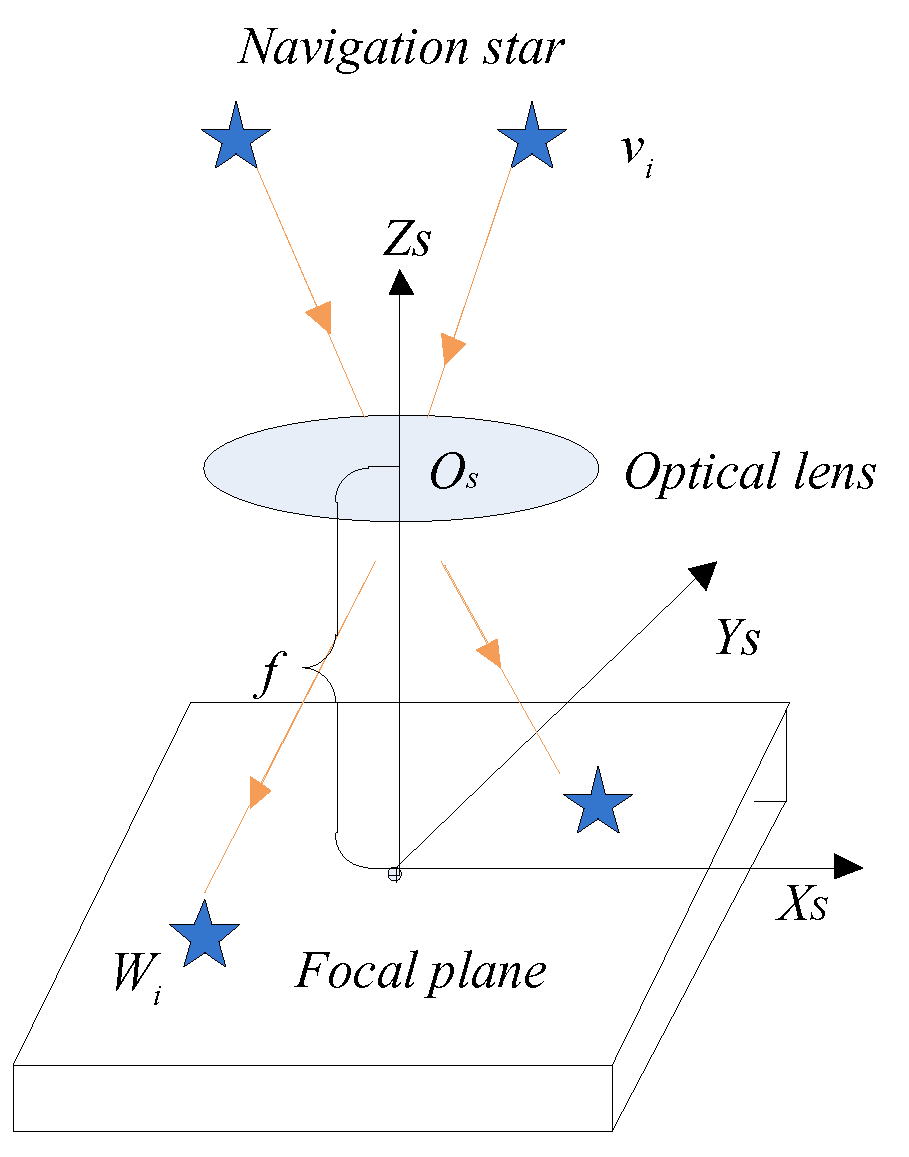
To better recover the blurred star image, the primary task is to obtain the PSF. Therefore, it is necessary to analyze the mechanism of the star image blurs. The star sensor is a navigation device that acquires the attitude by utilizing star observations. Because the star sensor needs to photograph the sky with a dark background, in order to increase the number of navigation stars in the star image, it needs to increase the exposure time appropriately. If the star sensor has a wide range of motion during the exposure time, the same star will be imaged at different locations on the star image, which will result in blurring of the star image. Mathematically, the model of star image blurring can be written as,
where
,
, and
denote the sharp star image, the blurred star image, and the PSF, respectively;
represents two-dimensional convolution operator, and
denotes the image noise.
Due to the different motion types of the star, sensors produce different PSFs, so PSF is important for describing the model of the blurred star image. Since the distance from the navigation star to the earth is much larger than the distance from the star sensor to the earth, the linear motion has less effect on the star image blur, and this effect can be ignored. Therefore, we mainly analyze the model of the blurred star image generated by the angular motion.
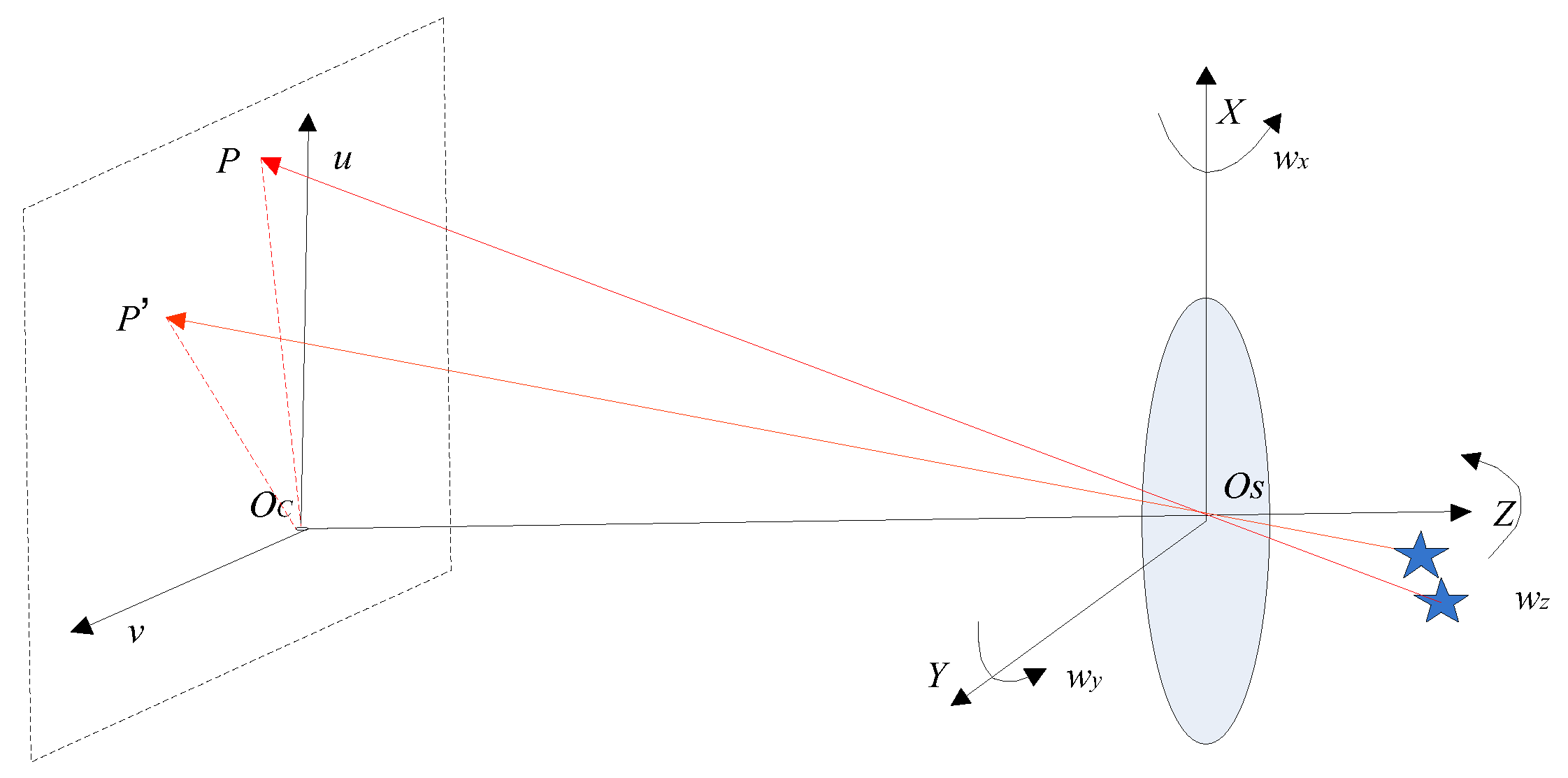
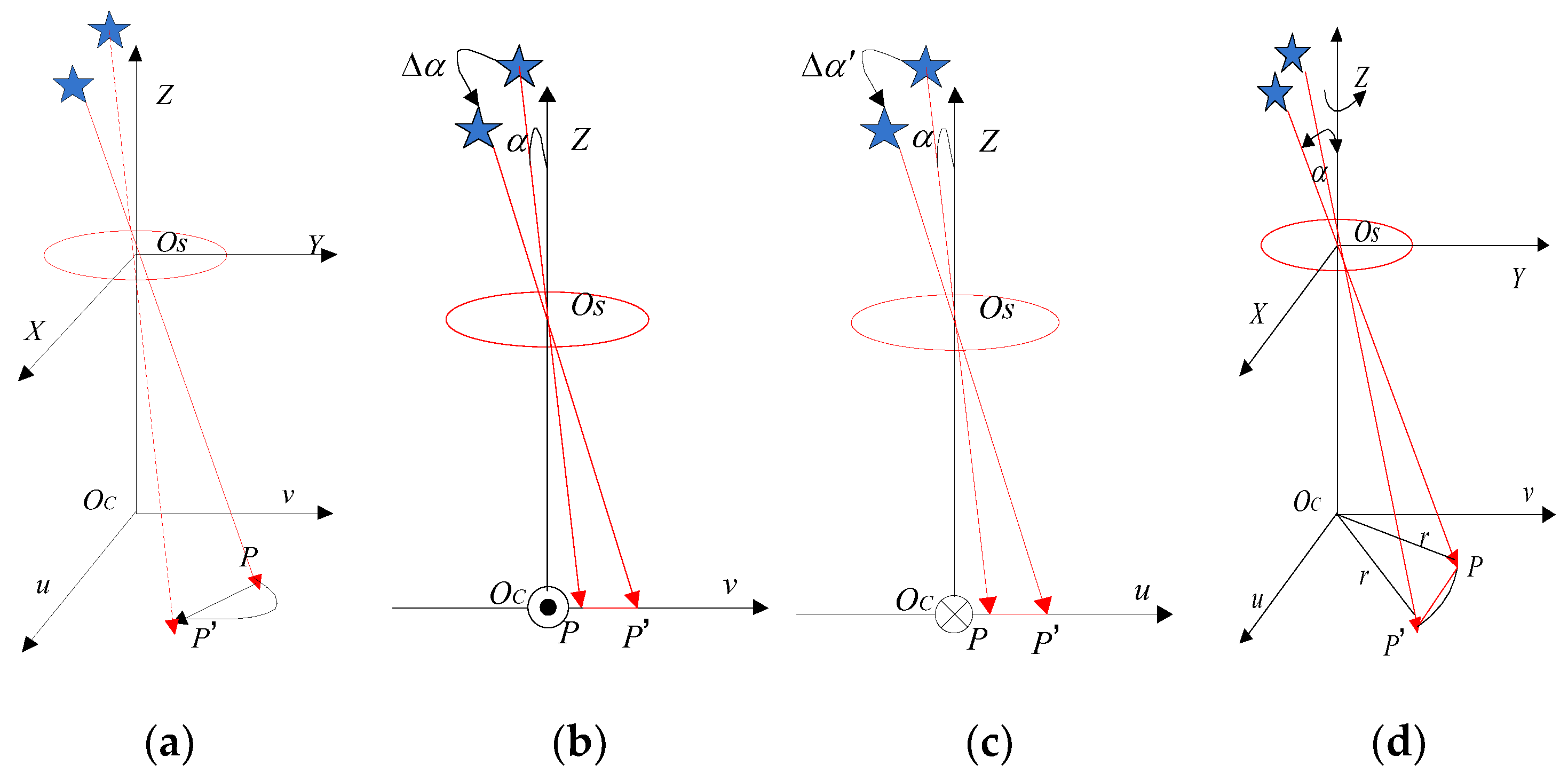
In
Figure 3a, the star image blur caused by the angular motion is shown. Since the exposure time of the star sensor is short, the angular velocity of the star sensor can be considered to be constant during the exposure time. Moreover, the star sensor coordinate system is coincident with the body-fixed frame. In
Figure 3b, the model of the blurred star image generated by the star sensor rotating around the X-axis is shown, the initial angle between the starlight direction and the principal optical axis of the star sensor is
, and the projection of the navigation star is
in the star image. When the star sensor rotates clockwise around the X-axis at an angular velocity
, and during the exposure time
, the rotational angle is
, and the star spot moves from
to
in the image plane. The geometric relationship between
and
is,
where
represents the distance from
to
quantized by pixels,
denotes the pixel size, and
is the focal length of the star sensor.
As a result of the short exposure time of the star sensor,
is quite small, the first order Taylor-expansion for
can be obtained.
Substituting Equation (10) into (9), we have
In general, the rotational motion characteristics of the star sensor in the
and
directions are the same. As shown in
Figure 3c, during the exposure time
, the star sensor rotates clockwise around the Y-axis at an angular velocity
, the rotational angle is
, the star spot shifts along the
axis in the image plane, and its translation vector can be obtained.
When the star sensor rotates around the X-axis and Y-axis with angular rates
and
, respectively, and after the exposure time
, the rotation angle of the star sensor is
, and the translation vector of the star spot is
In general, when the star sensor rotates around the cross bore-sight direction (
and
OSY directions), the blur kernel angle
of the star image can be given by
Then, the PSF of the blurred star image is expressed as [
37,
38],
In
Figure 3d, the star sensor rotates clockwise around the Z-axis at an angular rate
, point
does a circular motion with
as the center and
as the radius. The rotation angle of the star sensor is
during the exposure time
. Since the exposure time of the star sensor is short, the arc length
can be approximated as the chord length
. Inspired by reference [
39], the motion of the star spot can be regarded as a uniform linear motion on the focal plane. The displacement of the star spot in the direction of the X- and Y-axis can be expressed as,
The star image blur kernel angle
and the
are given by
According to the geometric relation in
Figure 3d,
Substituting Equation (19) into Equation (18), Equation (18) can be rewritten as
Therefore, when the star sensor rotates around the Z-axis, the PSF of the blurred star image is expressed as,
In summary, according to Equations (15) and (21), the model of the multiple-blurred star image is given by
where the
and
need to be calculated based on the angular velocity
,
and
of the star sensor. In this paper, we use a gyroscope to provide the angular velocity
of the spacecraft. Therefore, the angular velocity
of the star sensor is expressed as,
where
denotes the rotation matrix from the body coordinate system to the star sensor coordinate system. Because the star sensor is fixed on the spacecraft,
can be calibrated in advance.
After obtaining the PSF, the NBID algorithm is used to recover the blurred star image.
3.2. Richardson-Lucy (RL) Algorithm
The NBID algorithm includes both linear and nonlinear algorithms. The most common linear NBID algorithms include the inverse filtering algorithm, Wiener filtering algorithm, and least squares algorithm [
3]. Compared with the linear NBID algorithm, nonlinear NBID algorithm has a better effect in suppressing noise and preserving image edge information. Currently, the RL algorithm [
40] is the most widely used non-linear iterative restoration algorithm. The RL algorithm is a blurred image deconvolution algorithm that extends from the maximum a posteriori probability estimate. This method assumes that the noise in the image follows a Poisson distribution, and the likelihood probability of the image is
where,
denotes the pixel coordinate,
represents the blurred image,
denotes the PSF, and
denotes the two-dimensional convolution operator.
To get the maximum likelihood solution of the sharp image
, we minimize the energy function.
By deriving the
and normalizing the blur kernel
, the RL algorithm iteratively updates the image by
where
represents the iteration number.
The RL algorithm has two important properties [
40]: Non-negativity and energy preserving. It constrains the non-negative of estimated values of the sharp image and preserves the total energy of the image in the iteration so that the RL algorithm has excellent performance in the star image deblurring. However, the iterative convergence criterion is not given in the RL algorithm, and the optimal number of iterations need to be obtained through constant-trying with large time-consumption. This shortcoming of the RL algorithm cannot be ignored if we are dealing with a large number of the blurred star image. Therefore, it is necessary to study an improved RL algorithm which automatically sets the number of iterations.
3.3. Improved RL Algorithm
To overcome the shortcomings of the RL algorithm, we propose an improved RL algorithm, and the flow diagram is shown in
Figure 4. First, we set the parameters of the star sensor including the field of view, focal length, star magnitude limit, resolution of the star image, etc. We use these parameters to simulate a large number of sharp star image and the corresponding blurred star image. Second, according to the angular rates of the gyroscope output, we calculate the PSF of each blurred star image and use the RL algorithm to deblur the star image and record the optimal number of iterations used. The optimal number of iterations and the sum of the Magnitude of Fourier Coefficients (SUMFC) of the PSF of the blurred star image are used for the training of the ensemble back-propagation neural network (EBPNN) [
41]. After the training is completed, the optimal iteration number prediction model of the RL algorithm can be obtained. Finally, when the navigation system is used, the PSF of the blurred star image is obtained according to the angular velocity of the gyroscope, and the SUMFC of the PSF is used as the input of the prediction model. The star image is deblurred according to the number of iterations required by the RL algorithm of the prediction model output. Especially, when predicting the number of iterations, the ensemble back-propagation neural network (EBPNN) prediction model based on the improved bagging method uses the SUMFC of the PSF of the blurred star image as the input.
We use different PSFs to blur the sharp star image (
Figure 5a). The relationship between the SUMFC of PSFs and the corresponding number of iterations required by the RL algorithm is shown in
Figure 6. We can see that there is an obvious non-linear relationship between them, which prompts us to use EBPNN to predict the optimal number of iterations of the RL algorithm.
The performance of a single back-propagation (BP) neural network is limited. It takes a long time to learn, and its objective function is easy to fall into a local minimum. Therefore, we use the integration strategy based on the improved bagging method to integrate the single neural network. The bagging method [
42] is based on the re-sampling and self-help technology. The self-help learning sample set
is retrieved from the original training set
, the size of each self-learning sample set is equivalent to the original training set, and each self-learning sample trains a single BP neural network. The bagging method increases the diversity of neural network by re-selecting the training set, thereby improving the generalization ability and prediction accuracy of the EBPNN.
In order to further improve the prediction accuracy of the ensemble neural network, we introduce a just-in-time learning algorithm to optimize the sample sets
obtained by the bagging method. Suppose two input samples
and
, where
is the currently acquired input sample and
is a training sample in
. The distance and angle between them can be calculated by the following equation.
The similarity between
and
is
where,
is the weighting factor, the larger the
value, the higher the similarity between
and
.
We select the k-group data closest to the currently acquired one sample
from the training sample set
and arrange the new sample set in descending order.
where
denotes the expected output value corresponding to
in training sets
.
Therefore, the local modeling problem is transformed into an optimization problem.
Minimize
to obtain the model parameter
at the current moment, and then obtain its local model:
In particular, we find that the computational complexity of the EBPNN model increases with the increase of the number of BPNN models, but the prediction accuracy of the EBPNN model does not always increase with it, sometimes it even decreases. Therefore, after considering the computational complexity and prediction accuracy of the EBPNN model, we decide to use three sub-BP neural network models to construct the EBPNN model. As shown in
Figure 7, three BP neural networks are trained by different sample sets
, and the integrated prediction model is obtained by aggregating the three BP neural networks. When the EBPNN is used for prediction, we use the weighted method to integrate the output of each neural network and take the integrated result as the output of EBPNN. In the process of integrating the output of each BP neural network, first, we calculate the average training errors
of three sub-models on their respective training sample set. Then, we construct a weighting vector
of
dimensions, the value of
is the same as the number of sub-BP neural network models, so
,
,
. Finally, we calculate the prediction results of three sub-models for the input data
by Equation (31) and form a
-dimensional output vector
. The final prediction result of the EBPNN is expressed as,
To verify the effectiveness of the EBPNN prediction model, we analyzed the accuracy of the iteration times estimated by the model. In the training stage of the EBPNN model, each BP neural network adopts a three-layer structure. The nodes of the input layer, hidden layer, and output layer are set to 1, 10 and 1, respectively. The sigmoid function is used as the activation function. The original training set
contains 1708 samples. In
Figure 8, we show the number of iterations predicted by the EBPNN model and compare it with the optimal number of iterations. We can see that the number of iterations estimated by the EBPNN almost coincides with the optimal number of iterations, and the error between them is small. Therefore, the performance of the EBPNN prediction model can meet our requirements.
After EBPNN predicts the number of iterations, we use the improved RL algorithm to obtain the sharp star image, and then we can accurately estimate the attitude information by the star image segmentation, star extraction, star identification, star matching, and other operations [
43].




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}