1. Introduction
Industrial mobile platforms have been in use since the industrial revolution. There are many variants of these machines such as forklifts, electric buggies, boom and scissor lifts and construction cranes. These machines generally weigh in the order of tonnes and have a high potential to inflict severe injuries or even death. For example, counterbalanced rider lift trucks (more commonly known as forklifts) are universally used in manufacturing plants, warehouses, freight terminals and trade environments because of their ability to shift heavy loads efficiently. A typical counterbalanced forklift weighs about 3 tonnes and has a 2.5 tonne lifting capacity, totaling a staggering combined weight of up to 5.5 tonnes. The above example can be extended to all other types of mobile industrial platforms.
Safety is of paramount importance and a critical element to be considered and catered for during the operation of mobile industrial platforms. During 1997–2013, in the state of Victoria, Australia, there were approximately 2500 incidence reports involving forklifts that led to injuries, near misses and material damage [
1]. To improve safety, various procedural changes and standards have been gradually introduced to isolate the forklifts from workers. For example, distinct predefined paths for forklifts and pedestrians were introduced at the cost of a productive work environment and an optimized floor plan [
2]. Such attempts have been shown to lead to only slight improvements in the rate of collision accidents.
Smart solutions that provide intelligent safety warning systems can significantly reduce the rate of incidences and improve safety in industrial environments where heavy mobile platforms operate. One of the first attempts was to use Radio Frequency Identification (RFID) technology [
3]. Despite being low-cost, RFID-based solutions tend to generate fairly high numbers of false alarms. For example, when someone is walking away from a forklift but is within the detectable range, an RFID system can generate a false alarm. A proposed alternative smart solution is the utilization of wireless sensor networks [
4]. In such solutions, a number of reference nodes are placed throughout the industrial plant and all the workers and the mobile platforms are tagged with mobile sensor nodes. In a centralized algorithm, the distances between workers and forklifts are calculated from sensor data, and used for collision avoidance [
5]. This approach is costly and not universally applicable. The batteries of the active sensor nodes used to tag the pedestrians need to be charged on a regular basis, and workers need to wear those at all times. A task that can easily be overlooked.
This paper presents a novel solution based on visual tracking via video signal processing. In practice, such a technology is not costly (owing to abundance of cheap vision systems) and can be used with any industrial mobile platform. Visual multi-target tracking methods can be broadly divided into three categories. The first includes the methods that rely only on detection of targets based on appearance models. At each time step, these models are matched with sections of the image to detect the targets, and detected targets across the time steps are connected using a labeling procedure [
6,
7,
8,
9,
10]. These methods only use the information embedded in each frame of the video sequence, separately, for tracking in that frame.
The methods in second category combine filtering (or tracking) with the detection process. These methods utilize both the image data and the
temporal information that can be acquired from the image sequence. Such methods include Multiple Hypothesis Tracker [
11] and Bayesian multiple-blob tracker [
12]. The final category of methods only use a filtering (or tracking) module to exploit all the image-based and temporal information. This family of tracking methods are called
track-before-detect (TBD) methods in the multi-target tracking literature. Examples of TBD solutions devised for visual tracking include a TBD particle filter [
13], TBD Multi-Bernoulli filters for visual tracking [
14,
15] and Hidden Markov model filtering [
16].
Recently, random set filtering methods have been adopted and extensively used to solve various multi-target tracking problems. Examples of such filters include the Probability Hypothesis Density (PHD) filter [
17], Cardinalized PHD (CPHD) filter [
18], multi-Bernoulli filter [
19,
20], labeled multi-Bernoulli (LMB) filter [
21] and the Vo–Vo filter [
22,
23]. In particular, the multi-Bernoulli filter and its labeled version, the LMB filter, have also been used to devise TBD solutions for visual multi-target tracking [
14,
15,
24]. Many theoretical and algorithmic improvements for these algorithms are proposed in the literature. Such methods include: a GM-PHD filter with false alarm detection using an irregular window [
25], a variable structure multiple model GMCPHD filter [
26], multiple modal PHD filters for tracking maneuvering targets [
27,
28,
29], joint underwater target detection and tracking using the Bernoulli filter [
30] and a generalized CPHD filter with a model for spawning targets [
31].
In one of our previous works [
24], we proved that LMB multi-target distribution is a
conjugate prior for a
separable likelihood function. Conjugacy means that with the particular likelihood function, if the prior multi-target distribution is LMB, then the updated multi-target distribution is also LMB. In light of this finding, we formulate our proposed LMB TBD tracking algorithm and propose two methods to fuse the color and the edge information embedded in an image sequence in the Bayesian update step. In the application focused in this study, we have the prior knowledge that (i) the targets are humans and normally in upright walking position; and (ii) they wear a mandatory safety vest. The human-shaped contour of the targets constrains the edges and the vest color constraints the color contents of the target areas in the image.
The multi-target visual tracking algorithm presented in this paper effectively uses both color and geometric information embedded in the image sequence. In a recent work [
32], we presented a novel model to exploit the geometric shape-related information using a double-ellipse structure. We proposed to use a single-target state that is comprised of the location and size parameters of two ellipses and the target velocity, and formulated a separable geometric shape likelihood function. We utilized the geometric shape likelihood and a well-established separable color likelihood to recursively propagate the prior multi-target LMB density in a Bayesian filtering framework.
In this paper, we significantly extend our initial findings reported in [
32] by proposing two different approaches to fuse the color-related and shape-related information. Note that the experimental results presented in [
32] are also substantially extended in this paper and a comprehensive set of visual tracking metrics are computed and compared. In the first method, a two-step sequential update is proposed, in which the predicted multi-target distribution is sequentially updated using the color likelihood followed by the newly formulated shape likelihood, assuming conditional independence of the shape and color measurements. Due to post-processing operations on the multi-Bernoulli distribution, such as pruning and merging, this assumption is not entirely accurate. Hence, in an alternative information theoretic approach for the update step of the multi-target filter, we propose to separately update the multi-target density twice, once using the geometric shape and once with the color measurements. The two posteriors are then fused in such a way that the resulting posterior density has the shortest combined distance (measured using weighted Kullback–Leibler average—KLA) from the initial densities, and thus incorporates the information contents of the updated posteriors based on their consensus.
The key contributions of this work are (i) devising an information theoretic method (based on minimizing the weighted Kullback–Leibler average) for fusion of color and shape measurements in a multi-Bernoulli visual tracking framework, and comparing it with the common fusion method based on sequential update as well as with a state-of-the-art method; and (ii) a comprehensive overall labeled multi-Bernoulli visual tracking solution that is particularly tailored for people tracking in industrial environments.
Experimental results involving visual tracking of industry workers show that our proposed methods outperform the state of the art in terms of false negatives and tracking performance in presence of occlusions. This is while our methods perform similar to the compared techniques in terms of false positives. It is important to note that, in safety critical applications, the rate of false negatives is significantly more important than false positives, as the occurrence of overlooking a human target can lead to catastrophic outcomes.
The outline of this paper is as follows. In
Section 2, we briefly review the necessary mathematical tools to describe random finite sets (RFSs) and the Labeled multi-Bernoulli (LMB) filter.
Section 3 describes how an LMB filter can be devised for accurate visual tracking of workers, detailing the derivation of the separable likelihood functions that capture color and shape information contents of image data separately. Then, the two-step sequential update for fusing color and shape information is presented, followed by the minimum KLA distance-based fusion of color and shape information. In
Section 4, sequential Monte Carlo (SMC) implementation of the proposed visual tracking algorithms is presented. In
Section 5, the performance of the proposed algorithm is compared with the state-of-the-art in challenging scenarios involving detection and tracking of multiple moving, mixing and overlapping industry workers in a video dataset created by the authors.
Section 6 is dedicated to conclusive remarks.
3. TBD-LMB Filter for Human Tracking
This section outlines the target appearance model used to exploit the geometric shape information embedded in the image measurements. We derive the geometric shape and color likelihood functions based on the new appearance model, in order to be utilized in the LMB update step of our multi-target tracking solutions.
3.1. Appearance Model
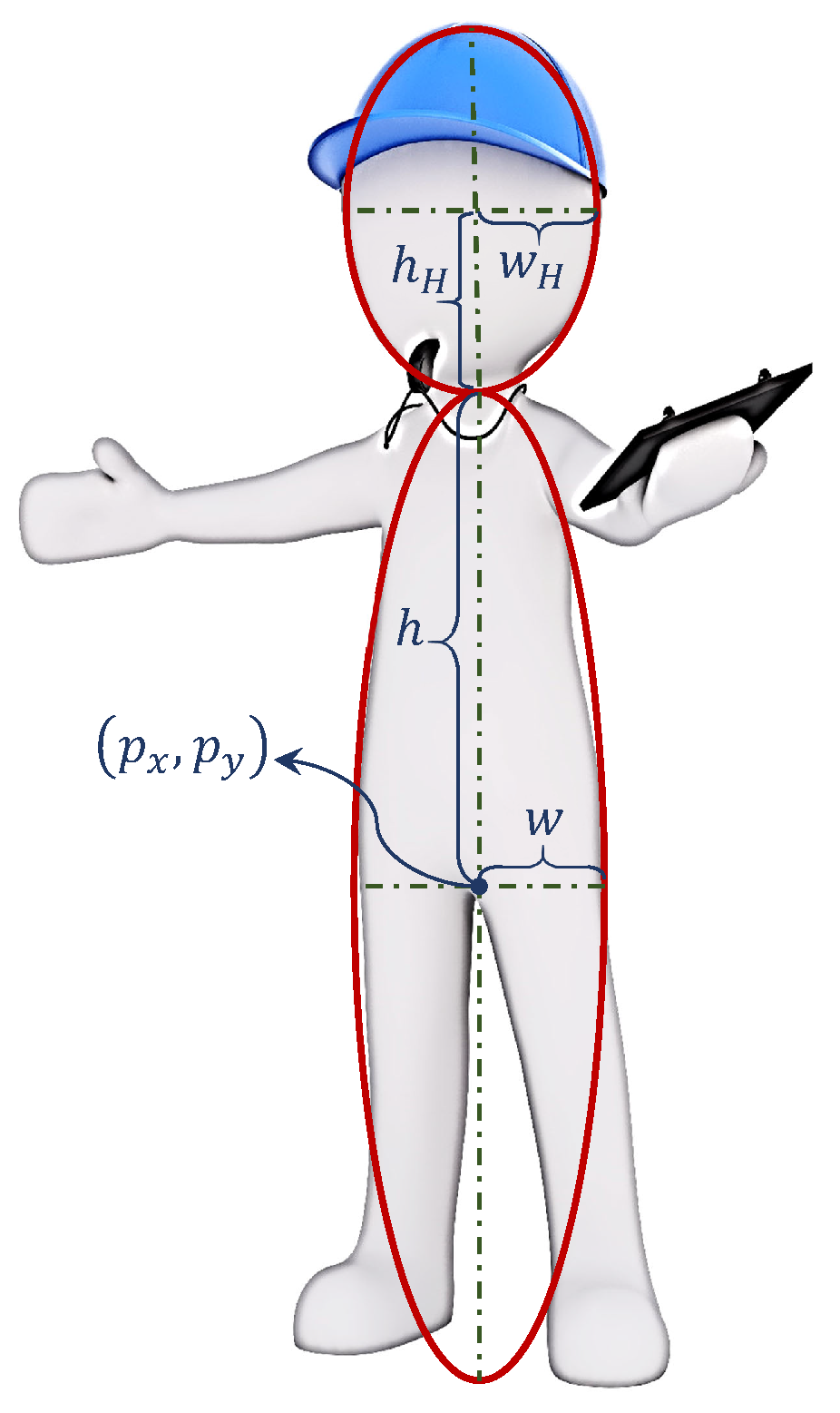
In this work, we are interested in tracking human targets who are wearing a “high visible” safety vest in an industrial environment. In such environments, it is reasonable to assume that the workers almost always move in a stand-up position. In order to capture the geometry of a human’s straight body, we model a single human target as a combination of two adjacent ellipses that share the same vertical axis, as shown in
Figure 1. The target state space
is eight-dimensional, and each unlabeled single-target state is denoted by
.
Generally, in other target tracking approaches such as [
24,
34], the target state is modeled as a rectangular blob in 2D cases (in 3D, it is generally a cube). Our formulation of the double-ellipse structure for single target state permits the formulation of separable likelihood functions for our image measurements as described in the next section. It is important to note that, as long as the likelihood function is of the separable form (
8), there is no need to formulate the term
, as it does not appear in the update Equations (
13) and (
14). We only need to formulate the single-target-dependent term
.
3.2. Measurement Likelihood—Shape
The intuition behind our formulation of the shape likelihood is that, if the target state is accurately hypothesized (during the prediction step), there should be a substantial number of edges (in the corresponding edge-detected image measurement) around the boundary of the hypothesized target state. These edges can be approximated using the above described double-ellipse structure. Our geometric shape likelihood is built upon this intuition and it is described in the following.
The well known Canny edge detector is used on each image measurement
y. After the prediction step at each time instance, a set of predicted targets are produced. Each target state is eight-dimensional as mentioned before and, for each hypothesized predicted target, we compute the shortest distance from every edge pixel to the particular hypothesized double-ellipse structure. As per our intuition, for a valid hypothesis (hypothesized target is close to the actual target), we expect some of the edge pixels (
inlier pixels) to be very close to the boundary of the double-ellipse structure. These pixels can be separated from the rest (
outlier pixels) using the Modified Selective Statistical Estimator (MSSE) [
35] algorithm as described below.
Consider the i-th hypothesized target with unlabeled state . Let us denote the shortest distance from the j-th edge pixel in the image to the double-ellipse boundary that represents , by . Assuming that is a valid hypothesis corresponding to the correct state of an existing target, we expect that, for some edge pixels (the inliers), the distances are small and for the rest of edge pixels (the outliers) they are large. MSSE is an effective algorithm that addresses the questions of “how small” and “how large” the distances need to be for a pixel to be labeled an inlier or outlier.
In MSSE, all the distances for the same hypothesis are first sorted in ascending order. Let us denote the sorted distance from edge pixel
j to the boundary of hypothesis
i by
. Naturally, the smaller distances are expected to correspond to inliers and the larger ones to outliers. Assuming that the first
sorted distances correspond to inliers, the standard deviation of those pixels from the target boundary is given by:
The next distance, which is the smallest outlier distance, is expected to be larger than
where
T is a user-defined parameter in the order of a single figure (we chose
in our experiments). Thus, in the algorithm, the above standard deviations are iteratively computed for increasing values of
, and in each iteration it checks whether
is correct. If so, the algorithm stops and outputs the standard deviation of inlier distances denoted by
.
When all the standard deviations of inlier distances for all hypotheses are small, the likelihood of image measurement
y for the given multi-target state
should be large. We can use exponential functions to denote this mathematically as follows:
where
is a user-defined application dependent constant. It is important to note that the proportionality factor is independent of the target states and thus the above formulated shape likelihood function follows the separable form of interest presented in Equation (
8) with
.
3.3. Measurement Likelihood—Color
Kernel density estimation over a set of histograms is one of the well known techniques to formulate color likelihoods. Following [
15,
36,
37,
38], we use kernel density estimation over a set of
training HSV histograms denoted by
. In our experiments,
training histograms proved to be sufficiently comprehensive. It was shown in [
15] that this approach leads to the desired separable likelihood of the form (
8). Indeed, the multi-target likelihood function for color contents of the image measurement, for a hypothesized multi-target state
is given by:
where
is the normalization factor,
is the HSV histogram of color contents of the image within the area of the hypothesized target
,
is the kernel function,
b is the kernel bandwidth,
is the number of bins in each histogram and
is the Bhattacharyya distance between the histograms [
36,
39,
40].
Again, we note that the proportionality factor is independent of the target states and thus the above formulated color likelihood function follows the separable form of interest presented in Equation (
8) with
. Gaussian kernels are used in our experiments. Since most of the prominent color features of an image measurement are present in the luminous high visible vest, we only use the color histograms of the contents of the upper half of the lower ellipse associated with each target state.
3.4. Sequential Update
Instead of using a combined color-shape likelihood function in a single update step, we compute the LMB update in two steps. This way, we not only exploit both the color and shape information but also reduce the required computation as explained in the following. We note that, according to Vo et al. [
41], if the measurement contents are conditionally independent, such a two-step update is theoretically equivalent to a single update step with a combined likelihood function.
The two step LMB update is as follows: we compute the color likelihood for each target using Equation (
17) and the weights of particles of each hypothesized target are updated accordingly. The process of generation, prediction and update of particles is detailed as part of SMC implementation explained in
Section 4. Then, in a particle pruning step, we discard the particles with weights less than a small threshold that is adaptively determined as one and half times the smallest particle weight. The remaining particles are then normalized and used in the second update step using edge likelihood given in (
16).
Note that computing the edge likelihood is computationally expensive. This is because, for each target hypothesis (particle), the distances from all the numerous edge pixels to the hypothesized double-ellipse outline of the target need to be computed, then sorted, and then processed with the MSSE algorithm, and these present a much higher level of computation compared to direct calculation of color histograms and Bhattacharyya distances in the color likelihood formula. Inclusion of the pruning operation between the two update steps heavily reduces the number of particles for which the edge likelihood needs to be computed, hence substantially reducing the required computation. Indeed, our experiments showed that direct calculation of the combined likelihood is intractable in real-time applications.
3.5. Weighted Kla Based LMB Fusion
We propose to use Kullback–Leibler divergence which has been used in various signal processing and computer vision applications, to fuse the color related and geometric shape related information. Instances where Kullback–Leibler divergence is used in the literature include a partitioned update of a Kalman filter [
42] and anomaly detection [
43].
Both the double-ellipse appearance model and the formulation of the two likelihood functions are approximates. Hence, conditional independence of color and edge measurements can be inaccurate. Furthermore, in the sequential update approach, the particle pruning step contributes to the estimation error. An alternative information theoretic approach is to separately update the predicted LMB density, once using the shape and once using the color measurements, then combine the two posteriors into a fused distribution that has minimum divergence from them (and therefore encapsulates the best of information content, in terms of shape and color relevance of the hypothesized targets).
Let us denote the two LMB posteriors by
and
respectively. The fused LMB density, denoted by
should have the smallest divergence from the above two posteriors, which is defined as the following weighted average of its Kullback–Leibler divergence from the two posteriors:
where
is the weight of emphasis on shape versus color information, and Kullback–Leibler divergence between two labeled RFS densities is given by:
Based on the derivations presented in (Equations (51) and (52)) [
44], it is straightforward to show that the LMB density which minimizes the KLA distance (
18) is parametrized as follows:
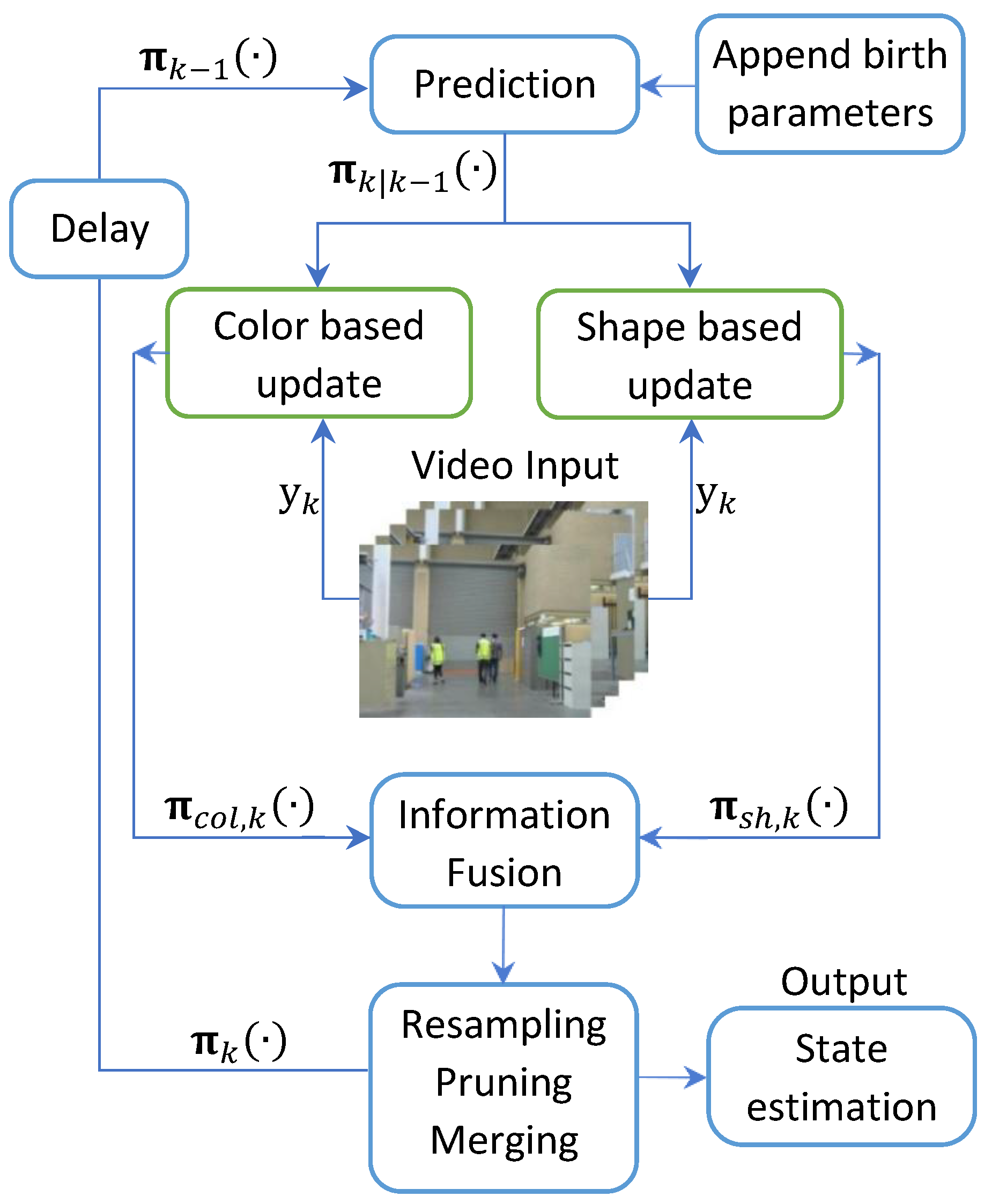
For the sake of clarity, the overall structure of the proposed algorithm is depicted in
Figure 2.
5. Experimental Results
We implemented our tracking algorithm in MATLAB Version R2016b, using the target state models described in
Section 3.1. The targets have variable major and minor axis lengths to represent their movements towards and away from the camera. Furthermore, upper and lower bounds are defined for the axes’ lengths as well. The upper bound ensures that multiple targets are not represented by a single double-ellipse structure, and the lower bound is to make sure that the double-ellipse structure is large enough to represent a single target.
The targets are set to have a constant survival probability of . We use a nearly constant velocity model for evolution of target state. The rationale behind this selection is that, in an indoor industrial environment, workers can only walk through designated paths and therefore, their direction of movement and speed are likely to remain constant throughout the motion. Furthermore, the randomness in nearly constant model permits the hypothesized targets to change their velocities. This allows us to track targets when there are changes in the velocities of the mobile platform and/or workers.
In RFS approaches, the birth process in a tracking algorithm should be designed in such a way that it captures the newly entering targets as well as those missed. Thus, our birth process is composed of five labeled Bernoulli components, which cover the entire image. Four labeled Bernoulli components are initiated in four sides of the image to detect the newly born targets, since most of the newly born targets appear in the four sides of an image. Another labeled Bernoulli component is initiated in the middle of the image in order to detect the missed targets. This component will enable the detection of targets after occlusion or after reappearing from behind non-target objects (such as walls).
All the birth labeled Bernoulli components have a constant probability of existence of , and are uniformly distributed within an image. Using additional information, if available, such as positions of the gate entrances, elevator access points, etc., we can incorporate other complex birth models with different probability densities, at the expense of higher computational load. To strike the right balance between accuracy of particle approximation and computation, the number of particles per target are constrained between and .
In the KLA based LMB fusion, the weight
is set to
. That is, we rely more on the color than the shape features. This enables us to track the targets in partial occlusion—see the results presented in
Table 1,
Table 2 and
Table 3.
At the RMIT University manufacturing workshops, we created a dataset of three video sequences with 346, 835 and 451 frames, respectively. This environment is specifically chosen because it closely resembles an indoor industrial environment; it is rich in visual features such as edges and corners and includes large areas of yellow color close to the color of safety vests worn by industry workers. Each sequence was recorded with a camera attached to a mobile platform which was moved at varying speeds. There are four human targets in each of the sequences and three of them are wearing the safety vest. One person wearing a vest moves randomly, specifically across the camera field of view. The other two wearing safety vests move very close to each other as a group. In two of the sequences, these two persons split after some time and, in the other, they stay together until the end. The person who is not wearing the safety vest also moves randomly. These scenarios are designed to depict the real world scenarios and to test the ability of the proposed trackers to track targets with varying speeds, varying camera ego motion, partial and full occlusions, size variations and different motions within the same sequence.
The main reason for evaluating the performance of the proposed method on our own dataset is that there are no publicly available datasets which contain the human targets who are wearing a high visible vest.
We use various standard tracking and detection metrics to quantify the performance of our proposed methods. We use the set of metrics proposed by Li et al. [
46], which have been widely used in the visual tracking literature [
47,
48,
49,
50,
51]. The metrics include:
- –
recall (REC - ↑): correctly tracked objects over total ground truth;
- –
precision (PRE - ↑): correctly tracked objects over total tracking results;
- –
false alarms per frame (FAF - ↓);
- –
percentage of objects tracked for more than 80% of their life time (MT - ↑);
- –
percentage of objects tracked for less than 20% of their life time (ML - ↓);
- –
percentage of partially tracked objects (PT ↓ = 1 - MT - ML);
- –
identity switches (IDS - ↓); and
- –
the number of fragmentations (Frag - ↓) of ground truth trajectories.
Here, the arrow symbol ↑ represents that higher scores indicate better results, and ↓ represents the reverse.
To evaluate the detection performance of our trackers, we use two widely used measures, false negative rate (FNR) and false alarm (positive) rate (FAR). These measures have widely been used in the visual tracking literature [
14,
15]. They are defined as the following rates: the total number of targets that are missed, and the total number of non-existing but detected targets, divided by the total number of true targets, over all frames. Furthermore, to quantify the tracking performance of our method, following Hoseinnezhad et al. [
14,
15], we use another two measures, label switching rate (LSR) and lost tracks ratio (LTR). The label switching rate is defined as the number of label switching events occurred during the tracking period normalized by the number of total ground truth tracks. The label switching between two targets can take place when they are moving close to each other and/or after they are separated. If the tracker can not distinguish between close targets, they may be tracked as a single target and hence will have a single label. The lost tracks ratio is defined as the number of tracks which are not detected (misdetected) for more than 50% of their lifetimes, normalized over the total number of ground truth tracks.
In terms of the above noted error measures, we compare our results with the results of the method based on Dynamic Programming and Non-Maxima Suppression (DPNMS method). This is a well-cited state-of-the-art visual tracking technique [
52]. The DPNMS method treats multi target tracking as an optimization problem which is solved using greedy algorithms in which dynamic programming and non-maxima suppression is used to omit tracklets representing the same target. Henceforward, the sequential two-step update method is called TSU, and the KLA based LMB fusion method is dubbed KLAF.
To examine the performance of DPNMS method on our datasets, we used the MATLAB code published by the authors of [
52]. It is important to note that the target states calculated by DPNMS are rectangular bounding boxes and thus, when calculating the accuracy measures, we had to convert our tracking results for compatibility. That is, we calculated the parameters of the bounding boxes which enclosed the tracked double-ellipse structures. Furthermore, to generate a fair comparison, we manually removed the tracks (generated by DPNMS) that represented the human target not wearing the safety vest.
The results for recall and precision metrics are listed in
Table 1. It can be seen that, in terms of the metrics proposed in [
47], both of our proposed methods perform better than the state-of-the-art method in comparison. In particular, our Kullback–Leibler method outperforms the other two methods in most of the metric values. It consistently records higher values’ recall and precision metrics, which means that the proposed KLAF method tracks the targets with high accuracy. Furthermore, both of our approaches have not recorded any identity switches for any of the sequences. Most importantly, in a safety critical application such as the application that we focus on in this paper, the KLAF method has not registered any mostly lost targets in any of the sequences. This fact makes the proposed KLAF method suitable for this application.
The detection results and their comparisons are given in
Table 2. The table shows that KLAF method outperforms other methods in terms of detection results as well. It should also be noted that our simple approach to sequentially update the predicted multi-target distribution also yields comparative results with respect to the state of the art. In particular, in a safety critical algorithm, the FNR is of high interest and it can be seen that our method has the lowest FNR among the three (which means that it performs better in detecting targets). Except in one particular instance, the KLAF method outperformed the state of the art and the TSU in terms of false alarm rate as well.
The tracking results of our methods and DPNMS methods, in terms of another set of performance metrics, are given in
Table 3. In terms of LSR, the proposed KLAF tracker mostly outperformed the other methods (i.e., it distinguished better between targets, even in scenarios where targets were moving very close to each other). Our simple approach, the TSU method is shown to have better performance than the DPNMS method. Furthermore, in one scenario (sequence 02), the DPNMS tracker was not able to track a target for more than 50% of its lifetime while ours have not missed any target for more than 50% of its lifetime. Videos of all the three cases with tracking results are provided as supplemental materials.
It can be seen in
Figure 3 that our trackers perform accurately in cases where the targets are moving close to each other. This demonstrates the efficiency of the merging step of our trackers. Furthermore, all three of the sequences depicted in
Figure 3 include a target having a different motion to the other targets, which has been successfully captured by our tracking algorithms.
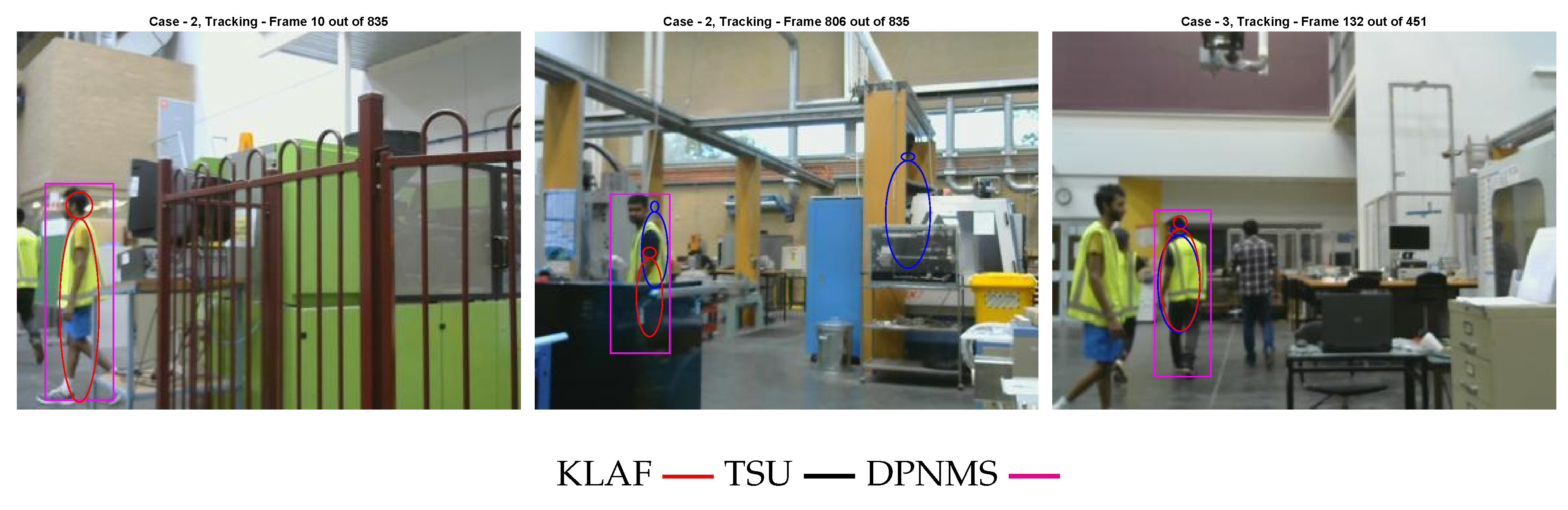
Figure 4 shows a few instances where our methods have failed. The left and right snapshots show two instances where our method has missed a target. This is due to the fact that no birth particle has been generated in those regions of the images, and thus the initialization of those target tracks are delayed. The centre snapshot shows an instance where our sequential update based method has reported a false alarm. This is due to the fact that the particles generated in that region of the image overlap with a yellow colour pole in the background, resulting in higher colour likelihood and edge likelihood (due to the shape of the pole) values for those particles. Thus, their probability of existence is higher and the corresponding hypothesised target track is detected as a valid target at the estimation phase of the filter.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}