1. Introduction
Simultaneous Localization and mapping (SLAM) is considered to be a fundamental process required by many mobile robotic applications. The SLAM process involves building a map of a prior unknown, unstructured environment using data from noisy exteroceptive and proprioceptive sensors mounted on a robot and estimating its position with respect to this map.
Over the years, many improvements to the estimation theoretic SLAM problem have been proposed since its inception in the seminal work of Smith, et al. [
1]. An extended Kalman Filter-based SLAM (EKF-SLAM) solution was proposed by Dissanayake, et al. [
2]. In [
3], the FastSLAM algorithm was proposed as a factored solution to the SLAM problem, where the concept of Rao–Blackwellized particle filter (RBPF) was adopted. To reduce the computational cost of EKF-SLAM, an extended information filter-based SLAM algorithm, EIF-SLAM, was proposed in [
4]. The SLAM problem has been solved as a maximum a posteriori (MAP) estimation problem by modeling it as a factor graph in recent years [
5]. Graph SLAM [
6] and Square Root Smoothing and Mapping (SAM) [
7] are prime examples of MAP-based estimation. Although these methods generally produce superior results, their performance can be severely degraded due to the heuristic-based data association phase [
8]. In addition, such solutions assume that the environment is static, which may produce inconsistent results in dynamic environments.
This article proposes that a map state estimation approach based on the random finite set (RFS) filtering framework can efficiently solve the data association problem in a principled manner within a Bayesian filtering framework while relaxing the static environment assumption. Traditionally, the robot position, the landmark map, and the measurements are represented as random vectors in both MAP-based optimization and Bayesian estimation theoretic approaches. In its random vector form, this representation requires the solution of additional sub-problems such as the determination of observation to feature associations, measurement clutter (false alarms) removal, and map management before the application of nonlinear optimization or Bayesian recursion. Parallel to the developments in SLAM, in multi-target tracking, Mahler [
9] suggested the random finite set (RFS) representation of the multi-target state as opposed to random vector representation. He showed that, in contrast to the random vector representation, the RFS representation of a multi-object state offers a mathematically consistent notion of estimation error [
9]. Furthermore, the uncertainties present in practical multi-target tracking applications, such as target detection and data association uncertainties as well as random clutter, are taken into account in the RFS representation of the multi-target state. As tractable approximations to the optimal Bayesian multi-target tracking solution, Mahler devised the Probability Hypothesis Density (PHD) filter, Cardinalized PHD (CPHD) filter and the multi-Bernoulli filter [
9,
10,
11]. More recently, the
-Generalized Labeled multi-Bernoulli (
-GLMB) filter was proposed by Vo et al. as an analytical solution to the optimal multi-target Bayes filter [
12,
13]. In [
14], the Labeled Multi-Bernoulli (LMB) filter was proposed by Reuter et al. as an efficient approximation to the computationally expensive
-GLMB filter. Further, by combining the prediction and update steps and introducing a truncation approach using a Gibbs sampler, Vo et al. introduced an efficient implementation of the
-GLMB filter in [
15].
Due to the similarity between estimation theoretic SLAM problem and multi-target tracking, an RFS representation was adopted in SLAM by modeling the landmark map and observations as RFSs. The first RFS based SLAM solution was proposed by Mullane et al. [
16] and later they proposed PHD-SLAM, an improved SLAM solution using PHD filter-based mapping and Rao–Blackwellized particle filter-based trajectory estimation [
17,
18]. Lee et al. also demonstrated a PHD-SLAM algorithm by modeling the SLAM problem as a single cluster multi-object model [
19]. Despite modeling the landmark map as a Poisson distributed RFS, the PHD-SLAM algorithm produces robust results against noisy sensory information and measurement clutter. In [
20], Deusch et al. proposed LMB-SLAM as an improved solution to the SLAM problem, by representing a landmark not only by its kinematic state but also by a label and propagating the landmark map using an LMB filter. Filter-based SLAM solutions with semantic features may benefit from such a representation for associating the features to physical objects in the environment. Furthermore, SLAM solutions with multiple feature types may benefit from a labeled representation due to convenience in identification and classification (see [
21] for an example SLAM algorithm that may benefit from labeled feature models).
LMB-SLAM, which makes no assumptions about the map, in general, produces superior results compared to PHD-SLAM, which models the landmark map as a Poisson distributed RFS. However, during the measurement update, the LMB filter first converts its LMB distribution into a
-GLMB distribution, performs the measurement update, and then converts the
-GLMB distribution back to an LMB distribution. In general, this process yields a loss of information and degrades performance (see [
22] for comparisons). Moreover, the performance of the LMB-SLAM filter depends on the underlying LMB filter’s ability to partition the landmark measurements and estimated landmark tracks in the sensor Field Of View (FOV) into spatially independent clusters and update them in parallel during the measurement update step [
22]. If the measurements and tracks are easily separable into such independent groups (clusters), the LMB filter performs efficiently. However, if this is not possible, the computational cost is equivalent to the
-GLMB filter. Although closely spaced targets are uncommon in multi-target tracking applications, in SLAM, it is common to encounter clustered and unevenly distributed landmarks which appear in the sensor FOV. Depending on the type of sensor, resolution, and the algorithms used, some feature extraction methods may also produce multiple closely spaced features, which may degrade performance in LMB-SLAM. Furthermore, practical implementations of RBPF-based SLAM algorithms rely on the parallelization of the particle filter, which permits an increased number of particles. Therefore, unlike in multi-target tracking, the LMB filter may lose its ability to perform efficient map updates within a parallelized RBPF implementation of the LMB-SLAM algorithm.
All SLAM algorithms that adopt standard RBPF-based robot trajectory estimation methods (including PHD-SLAM and LMB-SLAM) suffer from particle degeneration due to resampling and mismatch between the proposal and target distributions. This happens when proposal distributions designed to use only robot controls (which are often less certain and modeled with a large covariance), sample particles in a large area of the state space. As a result, after the measurement update, only those particles, which have maps that closely match the measurements, receive high weights. Therefore, the vast majority of particles receive negligible weights. During resampling, the higher weighted particles are duplicated, thus eliminating the particles with lower weights resulting in loss of particle diversity. This reduces the filter’s ability to revise the path of the robot and results in divergence over time. To address this issue, Montemerlo et al. proposed the FastSLAM 2.0 algorithm, which incorporates the current observations and the existing map to further improve the proposal distribution to closely match the robot trajectory posterior [
23,
24].
In this article, an RFS-based SLAM algorithm called
-GLMB-SLAM2.0 is proposed using the optimal kernel-based RBPF approach [
25] for robot trajectory estimation, and the recently developed efficient
-GLMB filter [
15] for landmark map estimation. Preliminary results of the proposed algorithm hence referred to as
-GLMB-SLAM1.0, were published in [
26]. An improved version is presented here, referred to as
-GLMB-SLAM2.0, where the RBPF used in the trajectory estimation adopts a modified proposal distribution similar to FastSLAM 2.0, which results in superior performance. Furthermore,
-GLMB-SLAM2.0 benefits from substantial computational savings in landmark map estimation due to inheriting the Gibbs sampler-based joint prediction/update method of the efficient
-GLMB filter [
15]. It is demonstrated that the proposed
-GLMB-SLAM2.0 algorithm outperforms the original
-GLMB-SLAM1.0 [
26] and LMB-SLAM algorithms in terms of pose estimation error and quality of the map, and yields superior, robust performance under feature detection uncertainty and varying clutter rates, while only slightly compromising the computational cost.
2. Problem Formulation
Let denote the time sequence of control commands applied to the robot up to time k, where denotes the control command applied at time k. In addition, let the time sequence of the pose history of the robot be denoted by , where denotes the pose of the robot with respect to the global frame of reference at time k. Further, let the time sequence of sets of measurements be denoted by , where denotes the measurement set received at time k, and denotes the number of detections. These measurements result from detections collected from an exteroceptive sensor mounted on the robot, such as a camera, lidar or a sonar, using a feature extraction algorithm.
2.1. Labeled RFS Representation of the Map
Let the landmark map be represented as a labeled RFS
where
denotes the number of landmarks present in the environment at time
k. Each realization of a landmark
is of the form
, where
is the kinematic state and
is a distinct label of the point
m. Distinct labels provide a method to distinguish between landmarks [
12,
13].
Let the kinematic state space of a landmark be denoted by and the discrete label space be denoted by . Further, let be the projection from labeled RFSs to labels defined by . Let the Kronecker delta function for arbitrary arguments (such as vectors, sets or integers) be denoted by , which takes the value of 1 only if and 0 otherwise. The indicator function takes the value of 1 if and 0 otherwise. Let denote the distinct label indicator, which takes the value of 1 if and only if the labeled set has the same cardinality as its labels and 0 otherwise. Let represent all finite subsets of a set . The inner product of two continuous functions and is denoted by and for a real valued function , the multi-object exponential is defined as .
2.2. Rao–Blackwellization of the SLAM Problem
In the SLAM problem, it is necessary to evaluate the posterior probability distribution,
for all times
k, where
denotes the initial pose of the vehicle. In other words, it is necessary to evaluate the joint posterior density consisting of the map and the robot pose history at all times
k, given the time sequences of sets of observations, and control commands up to and including time
k and the initial robot pose.
The joint posterior density consisting of the landmark map
and robot trajectory
at time
k, is evaluated using the existing map
, history of robot poses
evaluated at time
, the time sequence of sets of observations
and the applied control commands
up to and including time
k. In a manner similar to Montemerlo’s approach in FastSLAM [
3], the SLAM posterior is factorized into a product of the robot trajectory posterior and the map posterior conditioned on the robot trajectory as follows,
This decouples the SLAM problem into two separate (conditionally independent) estimation problems. The key advantage of this factorization is two-fold: Firstly it can benefit from Monte Carlo methods (particle filtering) for joint robot trajectory estimation, making it possible to adopt non-linear motion models. Secondly, it can benefit from using an RFS representation and Finite Set Statistic (FISST) techniques for landmark map posterior estimation. By representing the map and measurements as RFSs and appropriately modeling the map transition model, it is possible to estimate the number and locations of multiple landmarks in the presence of measurement noise and clutter within a single joint estimation framework. This automatically considers all data association hypotheses and takes landmark detection and survival uncertainties into account.
2.3. -GLMB-SLAM Observation Model
The measurement set received from the sensor at time
k contains both landmark generated measurements and false alarms (measurement clutter). Let the RFS
denote the measurement clutter. Then, the measurements received at time
k can be modeled by the RFS,
where
is a Bernoulli RFS representing the measurement corresponding to the observation of landmark
. Due to the limited field of view (FOV) of the sensor,
can have a value of the form
with probability of detection
or
∅ with probability of
. Note that the probability of detection is a function of the landmark state and robot position. The measurement likelihood function, conditioned on the detection of the landmark with state
, is given by
. Assuming that the measurements are conditionally independent and the measurement clutter is an independent process, the measurement likelihood function corresponding to the observations can be written using Equations (12.139) and (12.140) of Chapter 12 in [
9] as,
where
denotes the intensity of Poisson distributed measurement clutter, and
where
is an association map of the form,
such that each and every distinct estimated feature is associated to a distinct measurement (i.e.,
implies
). The set
of all such association maps is called the association map space and a subset of association maps with domain
is denoted by
. Note that unlike multi-target tracking, in SLAM, previously estimated landmarks that exit the current sensor FOV are retained in the map with probability of detection
during the measurement update step and therefore in general contribute to the robot trajectory posterior estimate.
2.4. -GLMB-SLAM Map Transition Model
As the robot continues to explore the unknown environment, new observations are collected in the limited FOV of the sensor and fused into the landmark map. These new landmarks are modeled as labeled RFS
with the birth label space
, and the corresponding birth density is assumed to be a labeled multi-Bernoulli density and can be modeled in a similar manner to Equation (
2) from [
15] as,
where a realization of
is of the form
for any label
and denotes the birth probability of the landmark with label
l and
denotes its spatial distribution.
Furthermore, a portion of the already existing landmarks in the map appears in the current sensor FOV. Given the state of the current landmark map,
, a landmark
may appear in the sensor FOV in the next time step with survival probability
and changes its state to
with probability density
, or leave the sensor FOV with probability
. It is also important to note that, unlike multi-target tracking, in SLAM, landmarks are usually assumed stationary and hence the motion of a landmark is modeled as a Kronecker delta function,
. In addition, the label of a landmark is preserved during the state transition. Assuming that the state of the landmark map is represented by
, the set of surviving landmarks in the next time step is modeled as a labeled multi-Bernoulli (LMB) RFS
with parameter set
. Then, the state transition of the map can be modeled using a LMB distribution similar to Equation (
25) from [
12] as,
where
The first part in Equation (
8) corresponds to the surviving landmarks and the second corresponds to dying (disappearing) landmarks. The newly appearing (birth) landmarks are independent of the already existing landmarks in the map. Therefore, the probability density of the predicted state of the map
, conditioned on the current map
, can be written as a product of birth density and the transition density of the surviving landmarks similar to Equation (
31) from [
12] as follows,
Note that the estimated landmarks that exit the current sensor FOV should remain in the map and be modeled with probability of survival during the prediction step and contribute to the robot trajectory posterior estimate.
2.5. -GLMB-SLAM Map Estimation
To propagate the landmark map in time, we adopt the recently proposed efficient
-GLMB filter [
15]. This approach avoids the traditional prediction/update steps of a Bayesian filter and directly updates the posterior at time
k to time
, achieving significant computational savings compared to its original implementation [
12,
13]. Let the map posterior
at time
k be abbreviated as
; let the measurement updated landmark map posterior at time
be abbreviated as
; and let the robot pose at time
be denoted by
. Assume that
at time
k is given by the
-GLMB distribution of the following form [
12],
where
represents a set of landmark labels and
represents a history of association maps up to time
k and denoted by
. The pair
represents the hypothesis that the set of landmarks with labels
has history
of association maps. The weight
represents the probability of the hypothesis
, and
represents the probability density of the kinematic state of the feature with label
l and the association map history
.
Assume that the birth landmarks (newly appearing landmarks) and the surviving landmarks in the FOV follow LMB distributions as in Equations (
6) and (
7). Let
denote the label space of newly appearing features in the FOV at time
. Then, adopting the joint prediction/update approach proposed in [
15], the measurement updated map posterior
can be written as,
where
and
,
and
denotes the association map space at time
, and
where
(see Equation (
5)), and
where the notation + has been used to abbreviate the symbols at time
and
denotes the probability of birth of the landmark with label
. Note that the resultant map update in Equation (
11) is a
-GLMB distribution, which is equivalent in its form to the prior distribution in Equation (
10). Each prior map hypothesis
generates a set of new hypotheses
using the robot position, prior spatial distributions, birth spatial distributions, probability of detection and probability of survival values of landmarks, probability of births and the set of received measurements at time
. Equations (
12)–(
14) contribute to the hypotheses weights and result in scalar values. Equation (
15) is the spatial distribution of a predicted landmark, where the first part corresponds to a survival and the second to a birth. Equation (
16) corresponds to the spatial distribution after measurement update. Note that the measurement update step takes measurement to track associations into account to generate the resultant spatial distribution.
The idea behind the joint prediction/update approach is to generate a smaller number of highly probable map hypotheses using existing hypotheses at time
k, by simulating most likely data association decisions, detection/miss-detection decisions and survival/death possibilities using a Gibbs sampler. This prevents the generation of insignificant and contradicting hypotheses and drastically reduces the computational complexity compared to the traditional prediction/update based
-GLMB filter implementation [
13]. It also yields a computationally efficient alternative for real-time implementations.
We assume that the probability of detection , and probability of survival have constant values depending on whether a landmark is within the sensor FOV or not, and the measurement likelihood is modeled as a Gaussian probability density function. Furthermore, the spatial distribution of each birth landmark, , is modeled as a Gaussian (or mixture of Gaussians) probability density function. Hence, the -GLMB filter follows a Gaussian mixture representation, where the spatial distribution of each landmark in the map with label l, and an association map history in each hypothesis, results in a Gaussian (or a mixture of Gaussians) probability density function.
2.6. Trajectory Estimation
In a manner similar to PHD-SLAM [
18] (and LMB-SLAM [
20]), the robot trajectory posterior is factorized and further simplified using the Markov property as follows,
and to cater for non-linear and non-Gaussian motion models, a Rao–Blackwellized particle filter [
27] is adopted, with an improved sampling distribution motivated by the FastSLAM 2.0 algorithm [
23]. Similar to FastSLAM 2.0, the proposal distribution is chosen to include the current observation set so that sampling not only takes robot controls into account, but also the current measurement set. Let the proposal distribution be
, which can be factorized and simplified using the Markov property as,
where the sampling function can be written as,
where
is a normalization constant.
Note that although Equations (
17) and (
18) appear to be similar, the proposed distribution in Equation (
18) is chosen to have a form which can be efficiently sampled, while the target distribution in Equation (
17) is, in general, more difficult to sample.
Note that the denominator of the target distribution,
, is a normalization constant. The state transition function of the robot trajectory distribution is known and the state transition function of the proposal distribution is chosen to be equivalent to that of the robot trajectory posterior such that,
Then, sampling a robot pose
from the proposal distribution is equivalent to sampling from the transition density given by,
and the weighting function can be evaluated as follows,
It is important to note that, to sample a robot pose
in Equation (
21), the map posterior at time
is used during the sampling step and the same integral is evaluated again at the weight update step in Equation (
22) with the sampled robot pose.
3. Implementation
This section presents the implementation details of the proposed
-GLMB-SLAM algorithm. The robot trajectory is propagated using a Rao–Blackwellized particle filter to cater for non-linear and possibly multi-modal motion models in both 2D and 3D environments. The trajectory dependant landmark map is modeled as a labeled RFS and propagated using a
-GLMB filter [
15].
The
-GLMB distribution of the landmark map posterior at time
k can be approximated using a set of
H highest probable hypotheses in the following form,
where the right hand side of the above equation can also be represented as a parameter set of the form
, where, for each hypothesis
h,
represents a set of landmark labels,
represents the probability of the hypothesis and
consists of the spatial distribution
of each landmark within this hypothesis.
Suppose that the robot trajectory posterior,
can be represented by a set of weighted particles of the form
, where
represents the weight of the particle
i. Then, the SLAM posterior (Equation (
1) can be represented as,
since the
-GLMB distribution of the landmark map is conditioned on the robot trajectory. The details of the implementation of the particle filter and the Gaussian mixture (GM) implementation of the
-GLMB filter is given in the following subsections.
3.1. Map Estimation
In this section, we briefly summarize the details of the Gaussian mixture implementation of the
-GLMB filter used in the estimation of the landmark map. Let
denote a Gaussian probability density function with mean
and covariance
, and assume that the probability of detection of a landmark within the sensor FOV is of the form
. Let the observation model be a non-linear function of the form,
where
represents a zero-mean Gaussian measurement noise source with covariance
and
is the robot pose according to particle
i at time
k. Then, assuming that the spatial distribution of
is of the form
, the measurement likelihood can be approximated as a Gaussian distribution by linearizing as follows:
where
is the Jacobian of
with respect to
at
(
is the zero vector) and
denotes the Jacobian of
with respect to
at
.
Furthermore, assume that the RFS
of newly appearing features in the sensor FOV can be modeled by a labeled multi-Bernoulli (LMB) distribution given by,
where
denotes the probability of birth of landmark
, and its spatial distribution
is modeled as a Gaussian distribution (or a mixture of Gaussian distributions) using the adaptive birth approach proposed in [
14]. Assume that each hypothesis of the landmark map distribution
(Equation (
10)) at time
k is represented by the hypothesis weight
. In addition, assume that the set of spatial distributions of each landmark in the set
with label
l is given by a mixture of weighted Gaussian distributions as,
where
denotes the weight of
jth Gaussian component. Then, using Equations (
14)–(
16) it can be shown that the measurement updated spatial density for a given association map
in the measurement updated
-GLMB distribution (Equation (
11)) also results in a mixture of weighted Gaussian distributions of the form,
where
,
and
denote the weight, mean and covariance of the measurement updated
jth Gaussian distribution component using the association map
, respectively. The weight
of each hypothesis can be obtained using Equations (
12)–(
15). Note that the sum of the hypothesis weights, is equivalent to the normalization constant of the
-GLMB update posterior (Equation (
11)), and is used in the trajectory update step in
Section 3.2.
To extract the landmark map, the cardinality distribution component of the
-GLMB distribution of the landmark map of the highest weighted particle is obtained using its hypothesis weights. The highest weighted hypothesis component with the cardinality equivalent to the maximum a posteriori (MAP) cardinality estimate (see [
13]) is assumed to contain the labels and the mean locations of the landmarks in the map.
3.2. Robot Trajectory Estimation
Assume that the weighted set of particles
represents the robot trajectory posterior at time
. Then, at time
k, a new robot pose is sampled from each particle using controls, measurements and the map posterior at time
as follows,
where the robot pose transition due to a control input alone is modeled using a non-linear function given by,
where
denotes Gaussian white control noise with covariance
. The robot pose transition function (due to control inputs) is modeled as a Gaussian probability density function given by,
In Equation (
32),
denotes the Jacobian of the robot motion model (Equation (
31)) with respect to the control noise when the control noise
. Further,
denotes the Jacobian of Equation (
31) with respect to robot pose at
, and
denotes the pose covariance. Note that we adopt the Gaussian mixture implementation of the
-GLMB filter, thus the right hand side of Equation (
30) results in a single Gaussian probability density function, which is a summation of a set of weighted Gaussian probability density functions, from which sample
is drawn.
The new robot pose,
, is then added to the set of particles
, creating a temporary set of particles, all of which have been drawn from the proposal distribution. Now, each particle in the temporary set is assigned an importance weight given by,
The importance weight of each particle in the temporary set is normalized such that . Then, a new set of particles is drawn with replacement, where each particle is sampled with a probability proportional to its importance weight. The resultant particle set with its importance weights, denoted by , represents the robot trajectory posterior density at time k.
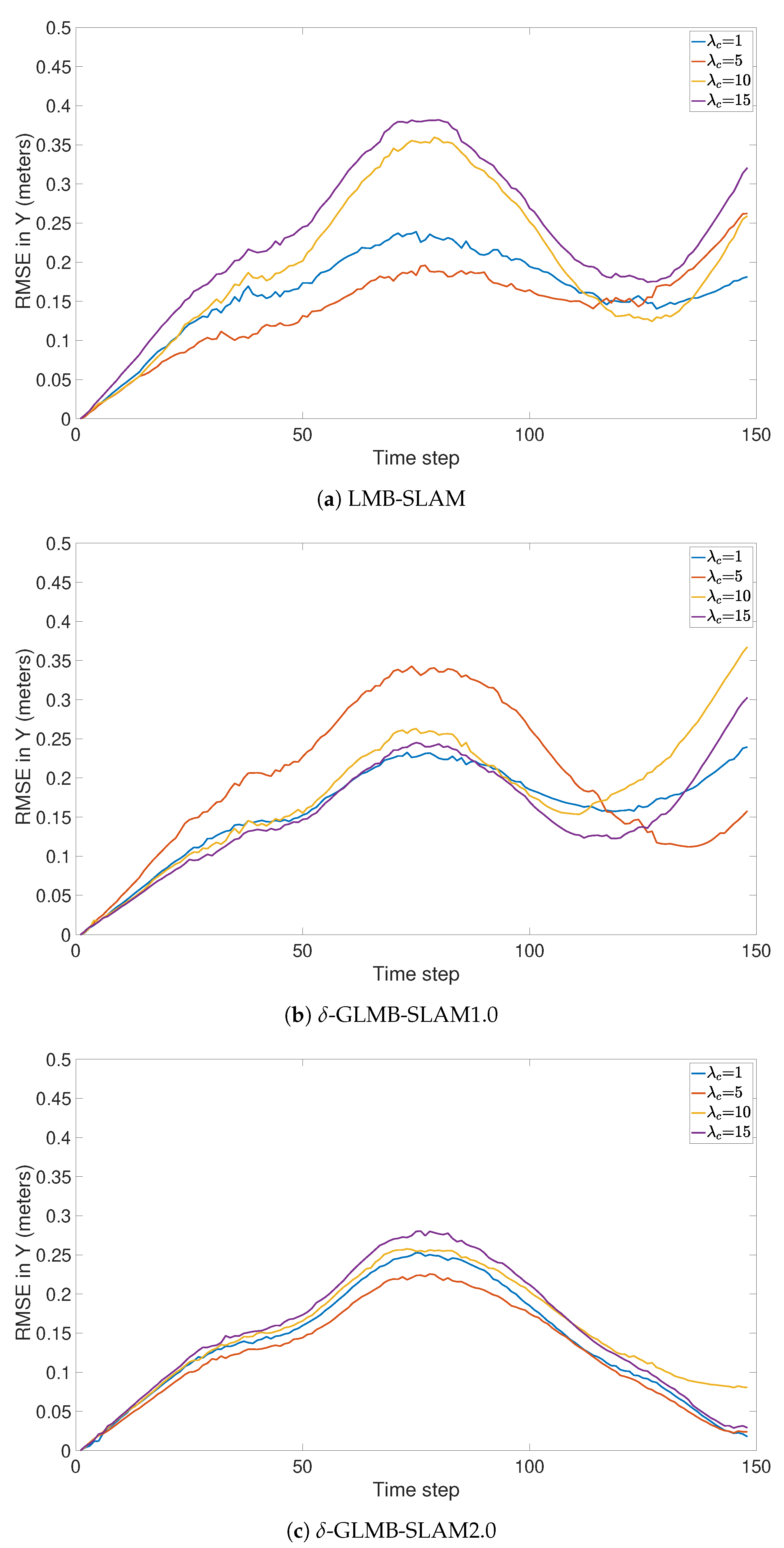
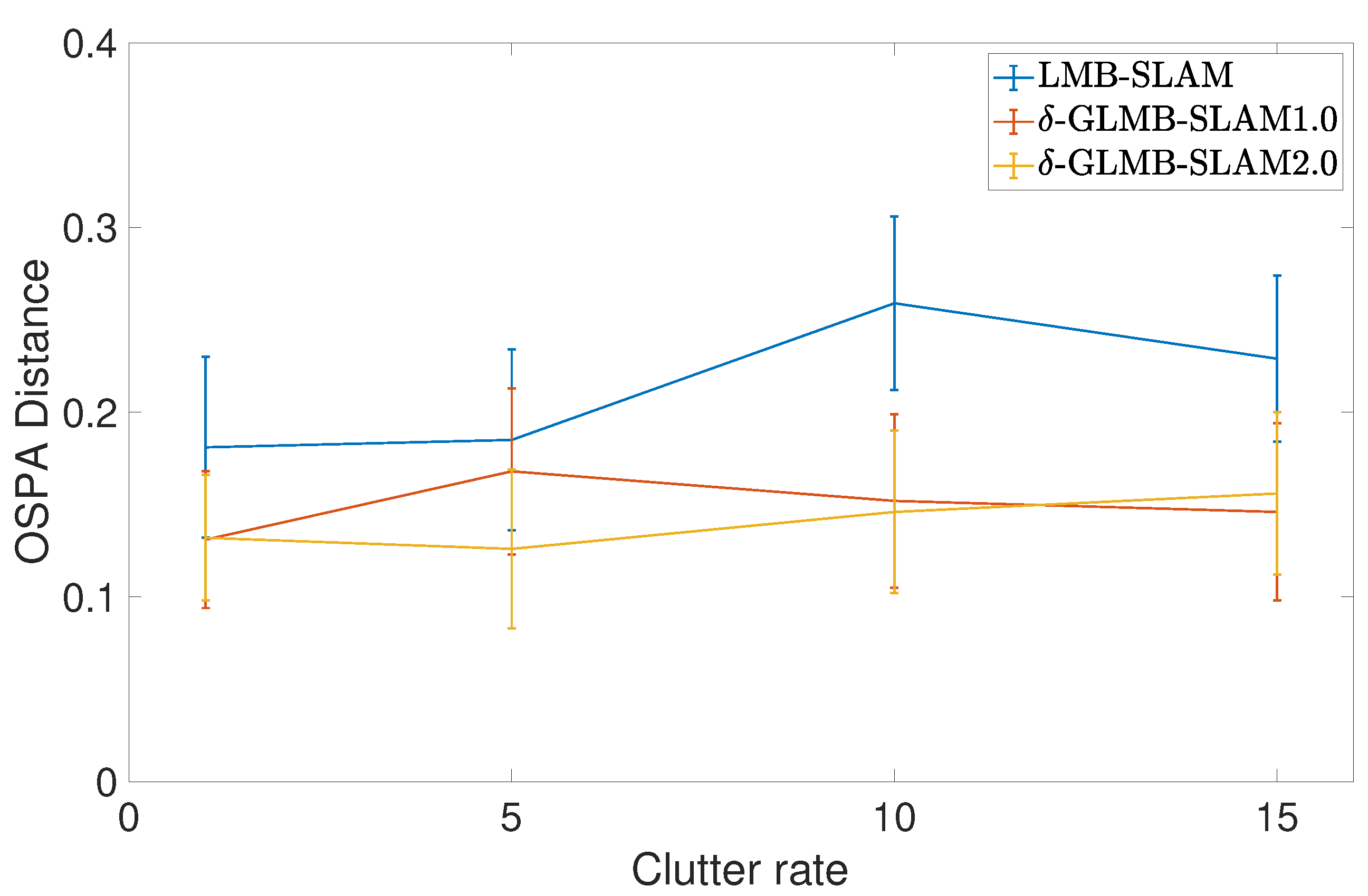
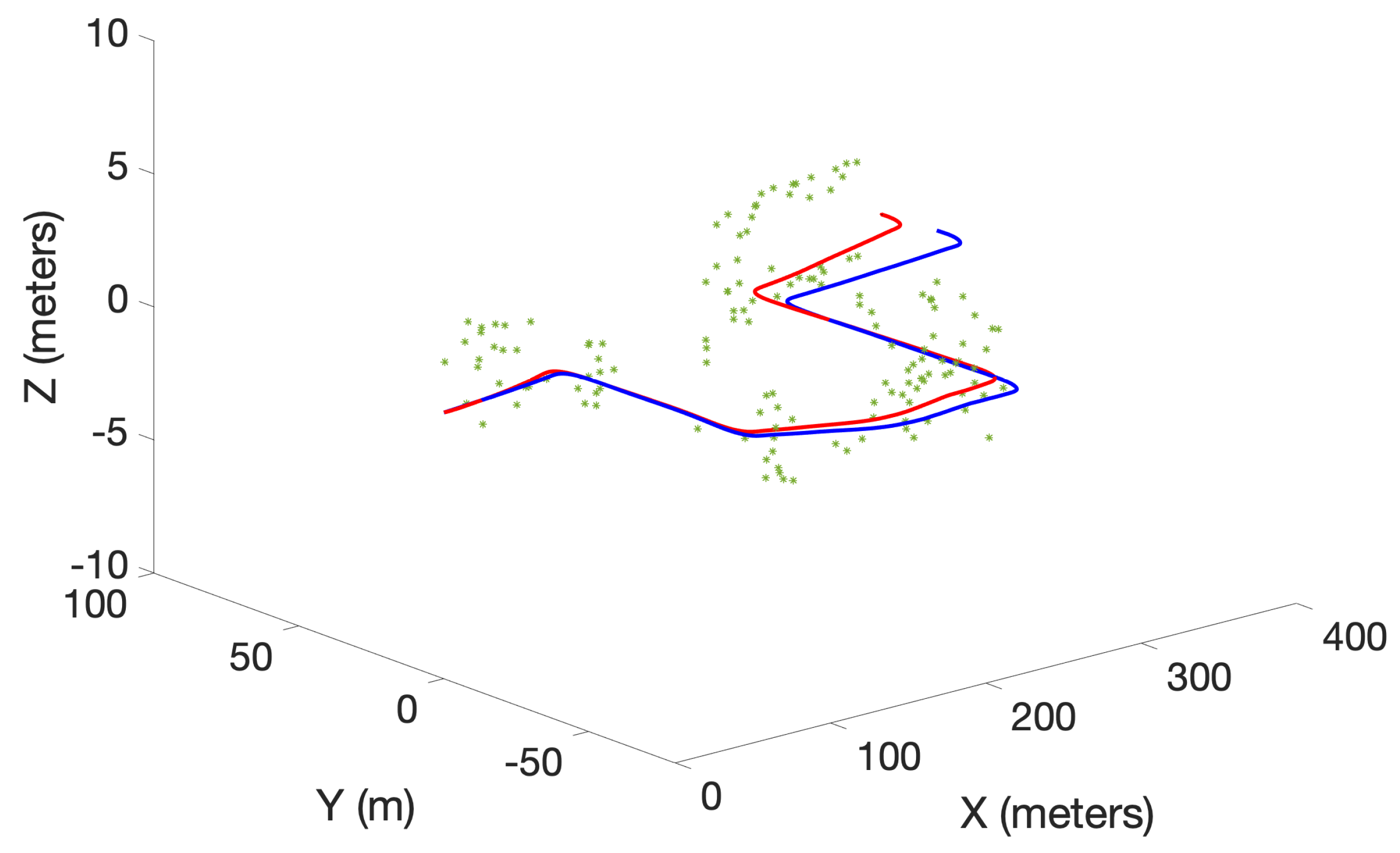
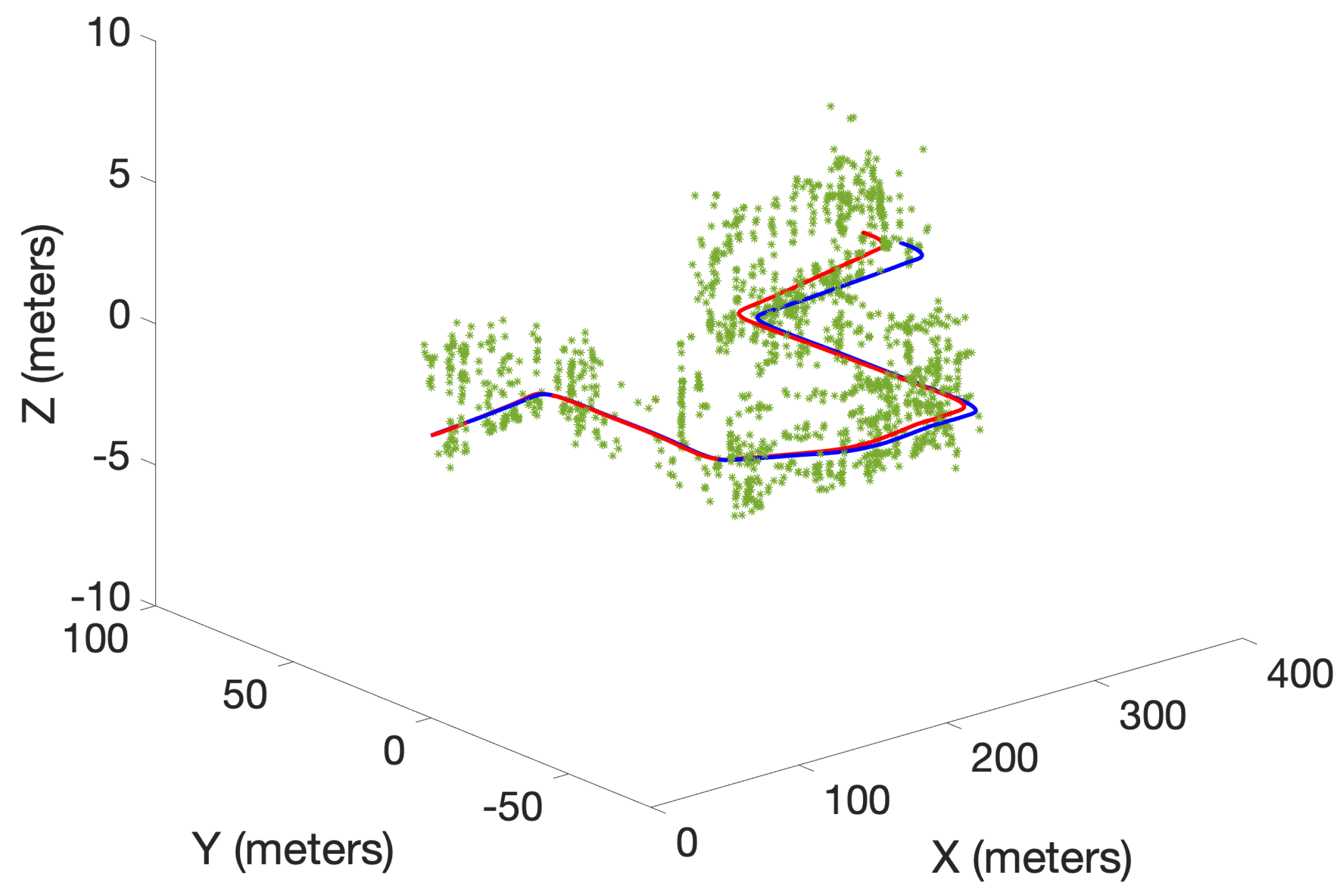
5. Conclusions
In this paper, we have presented a new RFS-based SLAM algorithm referred to as -GLMB-SLAM2.0. Similar to earlier RFS-based SLAM algorithms, -GLMB-SLAM2.0 factorizes the SLAM posterior into the landmark map posterior and robot trajectory posterior via Rao–Blackwellization. However, instead of using a standard particle filter, the robot trajectory is propagated using an optimal kernel based particle filter, and the landmark map is estimated using an efficient variant of the -GLMB filter based on a Gibbs sampler. The performance of -GLMB-SLAM2.0 was evaluated using a series of simulations and a real experiment, and compared to its predecessor -GLMB-SLAM1.0 and the LMB-SLAM algorithm with a Gibbs sampling-based joint map prediction and update approach. From the simulated and the real results, it can be seen that the proposed -GLMB-SLAM2.0 algorithm outperforms both -GLMB-SLAM1.0 and LMB-SLAM in terms of pose estimation error and the quality of the map under varying clutter conditions while requiring slightly higher computational times. The higher quality in the pose and the map estimation error can be attributed to two factors. First, the sampling of the particle filter no longer relies only on the control signals but instead uses the controls, measurements and prior map in order to produce a set of highly likely robot poses during the robot pose sampling step. Second, both -GLMB filters maintain multiple hypotheses for the landmark map state and remove insignificant hypotheses as further measurements invalidate contradicting hypotheses. Although -GLMB-SLAM1.0 also relies on the -GLMB filter for landmark map estimation, an improved particle filter results in better estimation performance in -GLMB-SLAM2.0. On the other hand, the LMB-SLAM algorithm combines multiple hypotheses during the measurement update step into a single LMB distribution with loss of information. As a result, drifts in landmark map estimates are visible during re-visits to previously mapped areas, which in turn result in drifts of the robot pose estimate. The higher computational time of -GLMB-SLAM2.0 to that of -GLMB-SLAM1.0 is due to additional computations required during the particle filter sampling step. Furthermore, it can be seen that standard measurement gating, particle level parallelization, and the Gibbs sampler-based hypothesis generation, result in a lower computational time of -GLMB-SLAM1.0 compared to LMB-SLAM, which outweighs the savings expected by combining multiple hypotheses.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}