CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems



Abstract
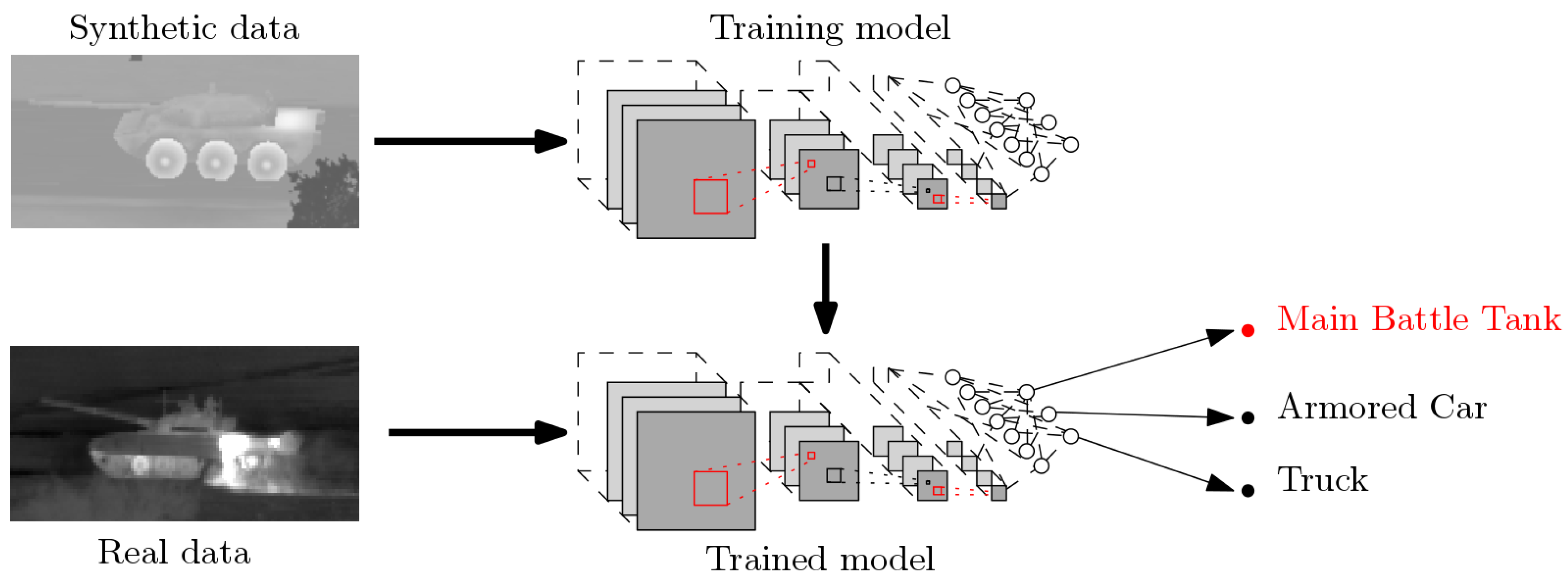
:1. Introduction
2. Related Work and Problem Statement
2.1. Infrared Imaging for Object Detection, Recognition, and Tracking
2.2. Deep Learning for Recognition and Identification in Infrared Images
2.3. Learning Strategies with Simulated Datasets
2.4. Viewpoint Invariance
3. Considered Datasets
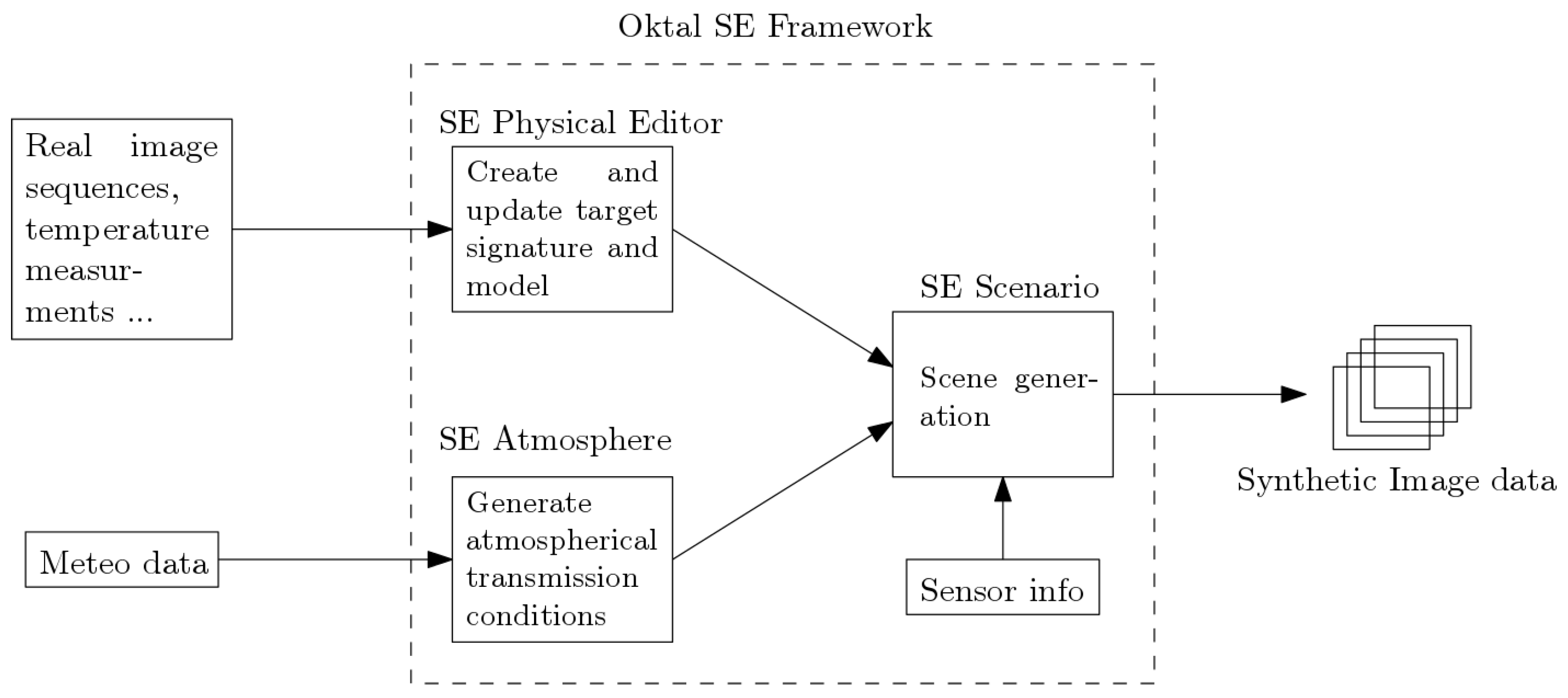
3.1. Simulated and Real Infrared Data
- DS1
- is composed of 17,280 images, each one containing a target. Six targets are available: two battle tanks (referenced as m1 and m2), three armoured cars (referenced as c1, c2, and c3), and one truck (t1). Thus, we have 2880 images for each target. The simulated data in DS1 were obtained using basic 3-D models of the targets and a basic model for generating the infrared signatures in the images. The resulting MIWR signatures may not be very accurate: heat transfer and diffusion are not taken into account, resulting in flat and uniform hot spots on the vehicles.
- DS2
- is composed of 23,040 images, each one comprising a single target. In addition to the six classes represented in dataset DS1, two other truck classes have been appended (referenced as t2 and t3). Simulated target MIWR signatures and 3-D models of the targets have been refined to provide a more realistic simulation dataset. More clearly, we took into account 2-dimensional heat transfers for each surface based on its composition. This results in smoother temperature gradients.
- DS3
- is composed of the same simulated scenes and targets as in dataset DS2, using target MWIR signatures recalibrated using real MIWR images. Temperature measurements on real vehicles were also used to validate or rectify physical models used in dataset DS2. As such, this dataset is the most realistic one among the three simulation datasets.
- DR
- contains 40,000 images extracted from infrared videos sequences. Each images has a size of pixels. The targets available in DR are m1, m2, c1, c3, t1, and t3, meaning that no test examples will be available for classes c2 and t2.
3.2. Training Datasets
3.3. Test Datasets
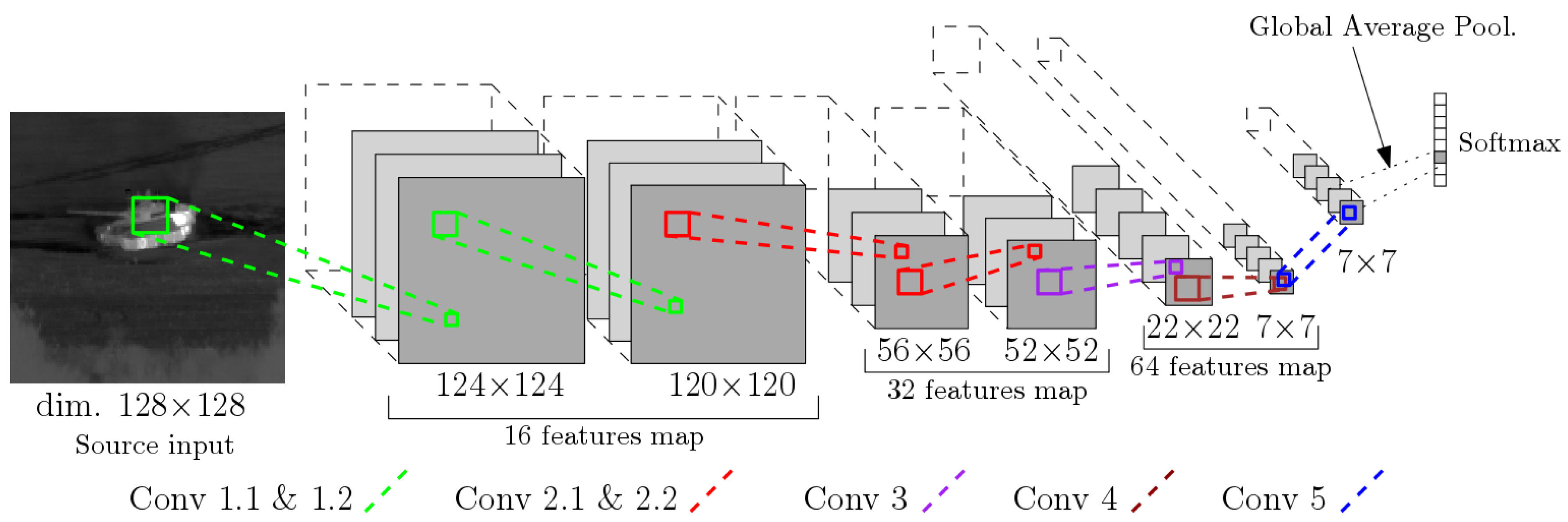
4. Proposed cfCNN
4.1. Description of the cfCNN
4.2. Training Consideration
- The optimization algorithm used for training is Adam. We will use the sames configuration parameters as in Reference [45], i.e., and .
- We use the Xavier initialization scheme [46] to prepare the network before training it during 150 epochs. To avoid over-fitting we use an early-stopping criterion to stop the learning process if the testing error starts to increase before reaching the last epoch.
5. Results
5.1. CNN Performance on Real Data for Identification and Recognition
- the CNN from Rodgers et al. [30], with 310 thousand parameters.
- an Inception v3 [50], with 23 millions parameters.
- cfCNN(fc), a modified version of the cfCNN, where the convolution layers from Conv 1.1 to Conv 4 are kept. A fully connected layer with 256 units replaces Conv 5 and the GAP layer. Thus, this architecture has 540 thousand parameters.
- Rodgers et al. [30] with batch size 256: on average, 59 s per batch.
- BCNN [48] with batch size 96: on average, 251 s per batch.
- Inception v3 [50] with batch size 256: on average, 85 s per batch.
- cfCNN with batch size 256: on average, 55 s per batch.
- cfCNN(fc) with batch size 256: on average, 58 s per batch.
- Identification score: this score refers to the ability of the network to correctly predict the vehicle class, i.e., if its Top1- prediction is the correct label. It is the default global classification score.
- Recognition score: this score measures the ability of the network to correctly retrieve as the top-1 result a vehicle category similar to the one of the true label. For example if the result is c1 instead of being classified as c3, this contributes to the recognition score as it is from the same “category” as the expected result. This recognition score is more relevant than classically considered Top-3 or Top-5 scores for the targeted operational context.
5.1.1. Performance Gains Using Improved Simulation
5.1.2. CNN Performance Comparison
5.1.3. Gains Using Leaky ReLU as the Main Nonlinearity
5.1.4. Dataset Size and Batch Size
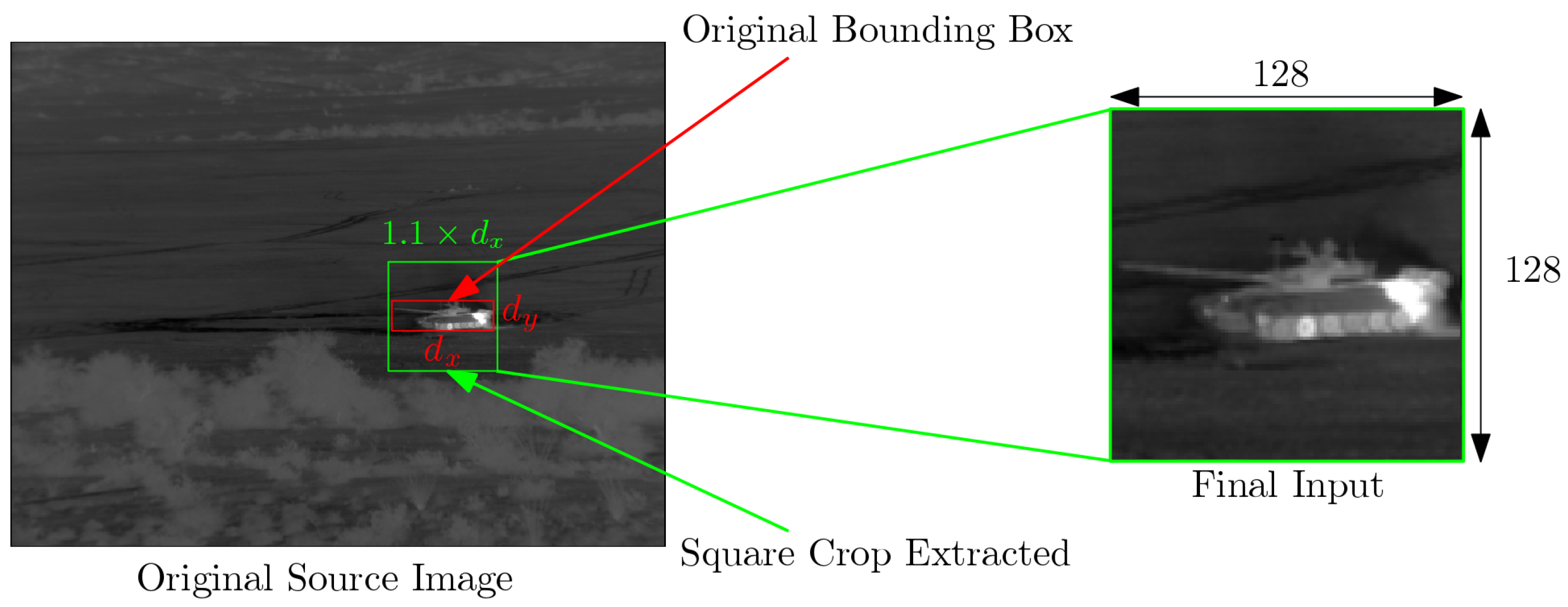
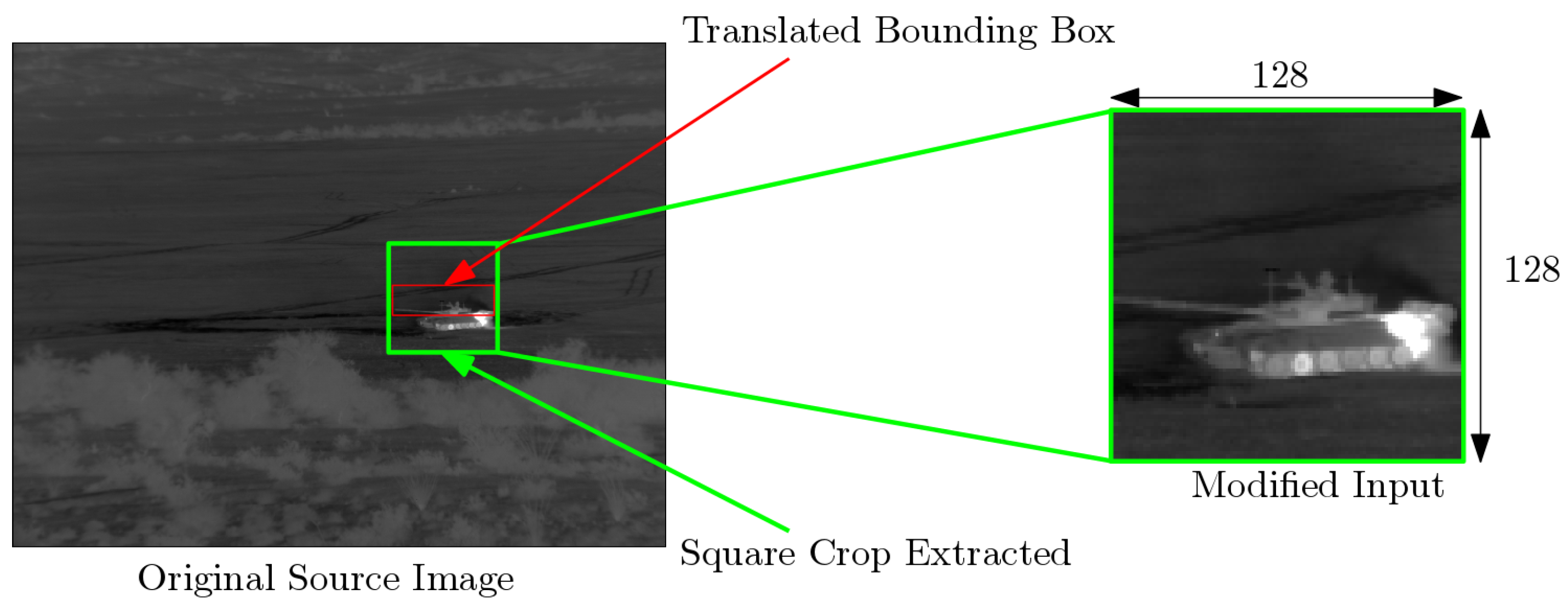
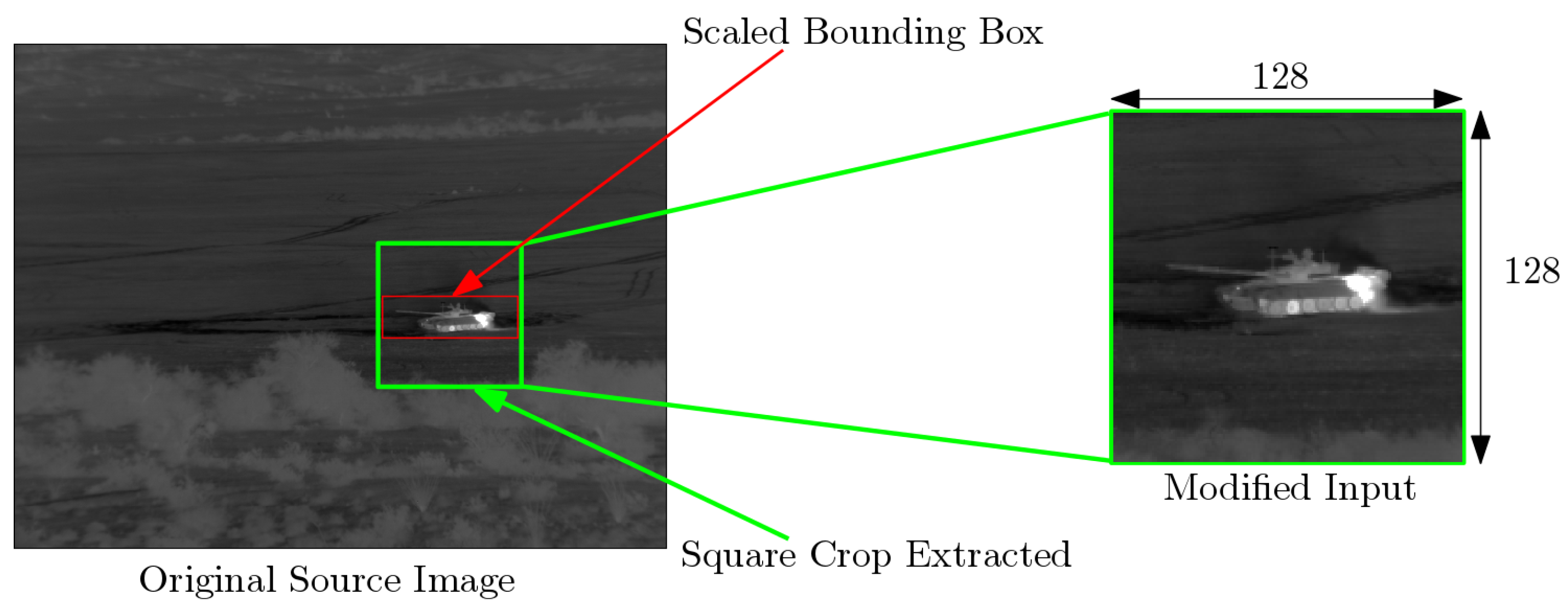
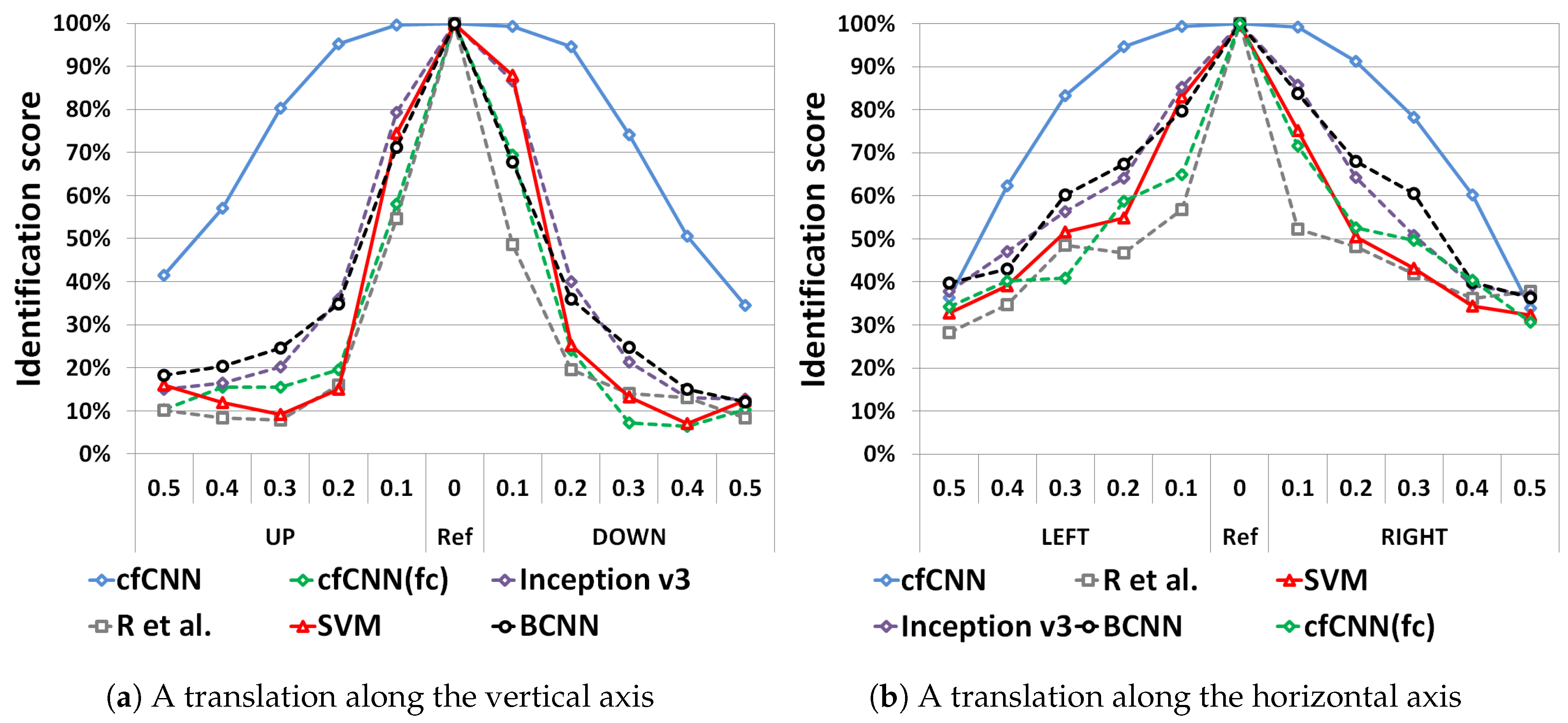
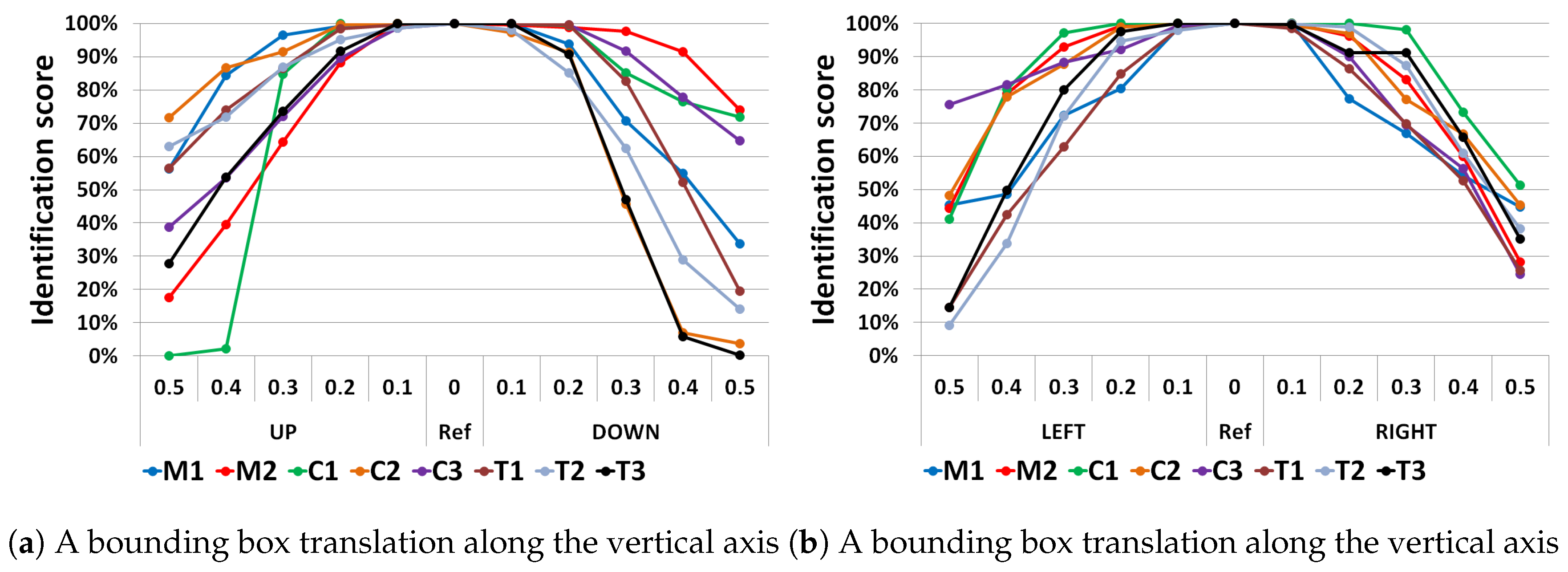
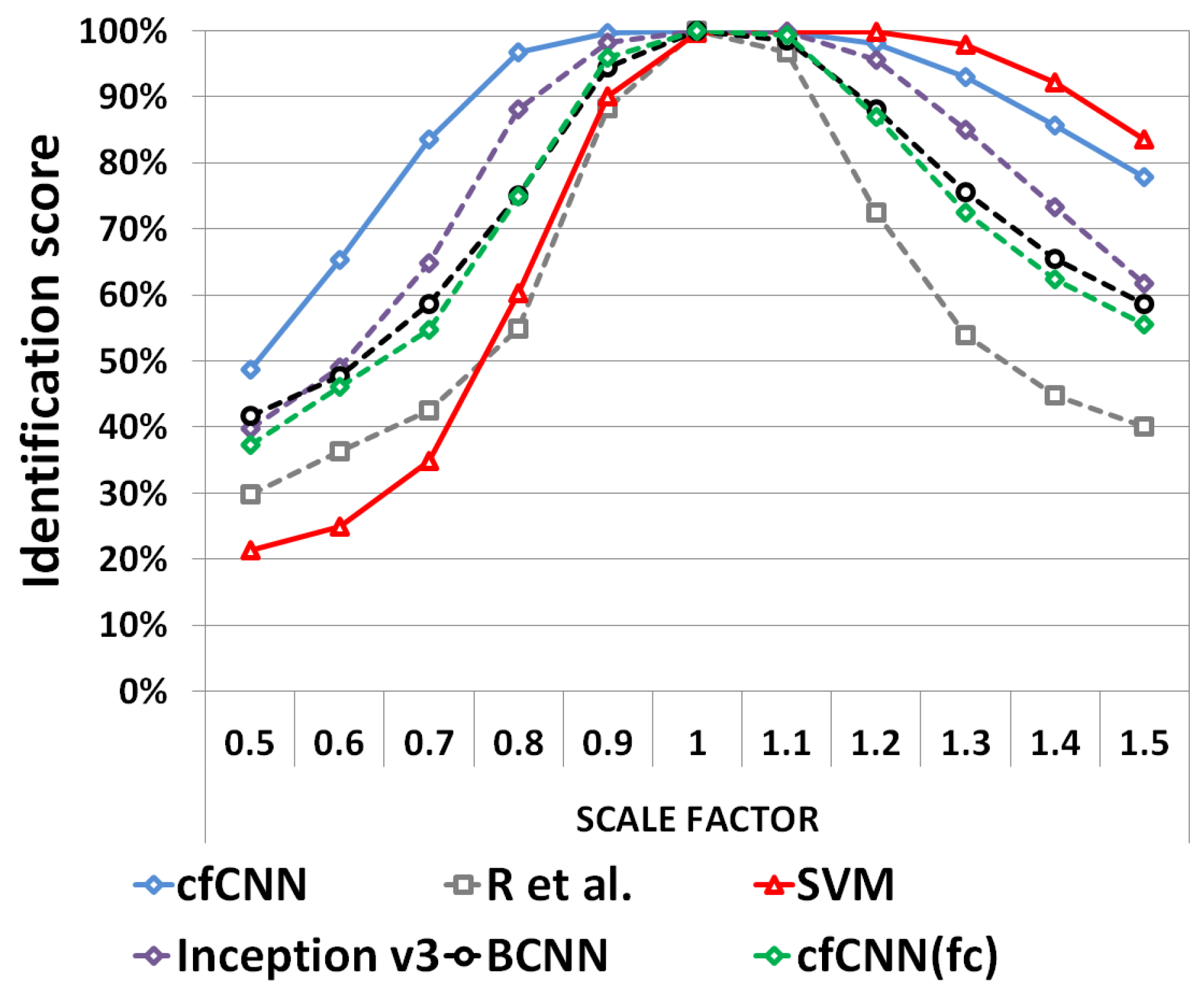
5.2. Evaluation of the Robustness to Localization and Scaling Errors
- TTS to evaluate the robustness against localization errors. The results are presented in Section 5.2.1.
- TSS to evaluate the robustness against scaling errors. Test results is presented in Section 5.2.2.
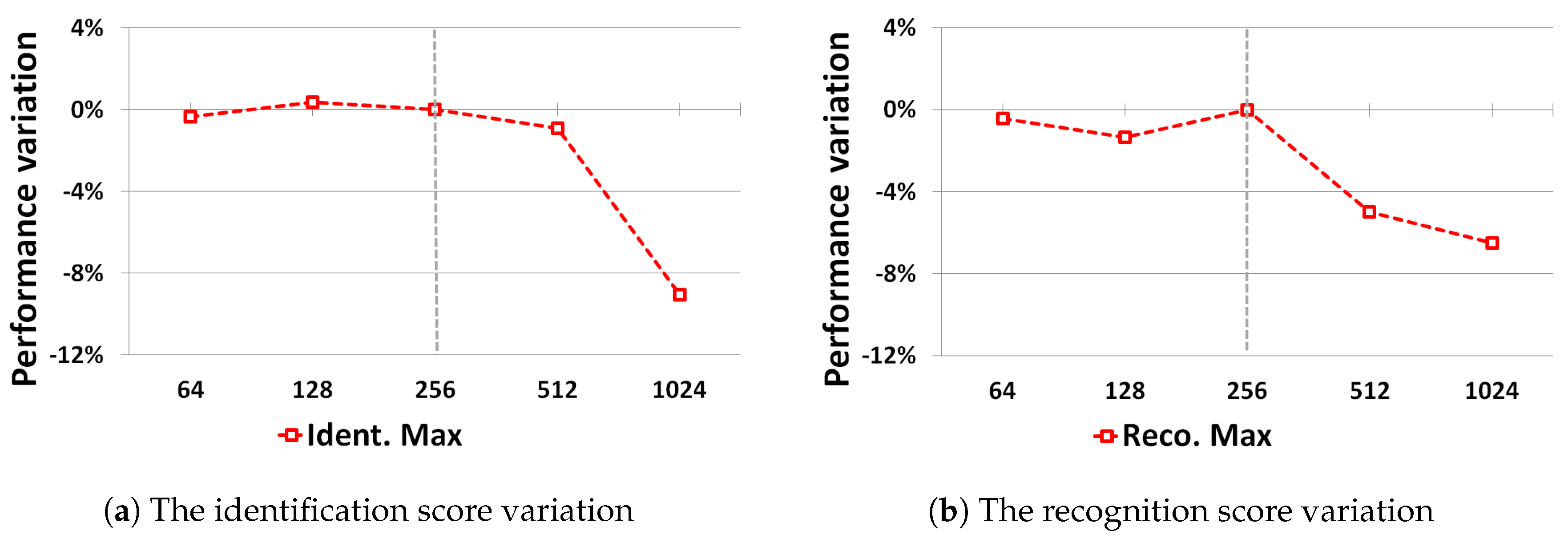
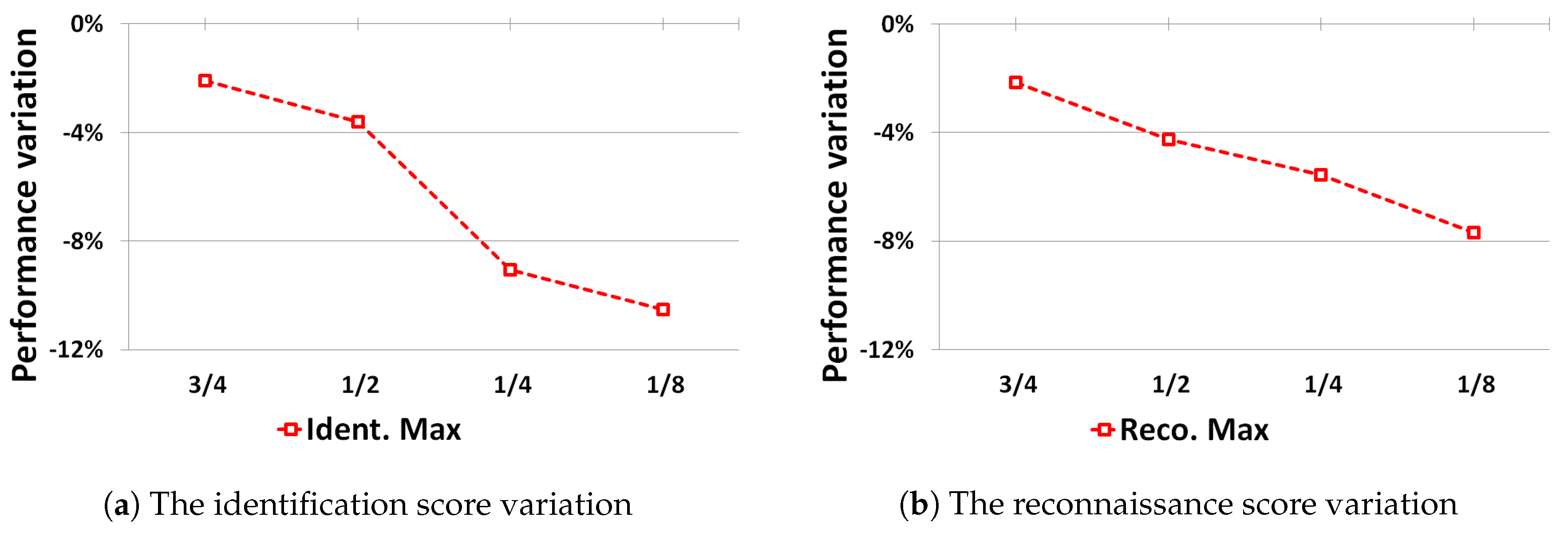
5.2.1. Impact of Localization Errors on Identification Performance
5.2.2. Robustness against Scale Modification
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| GAP | Global Average Pooling |
| IR | Infrared |
| MWIR | Middle Wavelength Infrared |
| ATR | Automatic Target Recognition |
| ATD | Automatic Target Detection |
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Moosavi-Dezfooli, S.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 86–94. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Military Sensing Information Analysis Center (SENSIAC): Dataset for Automatic Target Recognition in Infrared Imagery. 2008. Available online: www.dsiac.org/services/store/atr-algorithm-development-image-database (accessed on 30 April 2019).
- Deng, H.; Sun, X.; Liu, M.; Ye, C.; Zhou, X. Infrared small-target detection using multiscale gray difference weighted image entropy. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 60–72. [Google Scholar] [CrossRef]
- Tzannes, A.P.; Mooney, J.M. Point Target Detection in IR Image Sequences Using Spatio-Temporal Hypotheses Testing; Air Force Research Laboratory Technical Report; Air Force Research Laboratory: Dayton, OH, USA, 1999. [Google Scholar]
- Khan, J.F.; Alam, M.S.; Bhuiyan, S.M. Automatic target detection in forward-looking infrared imagery via probabilistic neural networks. Appl. Opt. 2009, 48, 464–476. [Google Scholar] [CrossRef]
- Khan, J.F.; Alam, M.S. Target detection in cluttered forward-looking infrared imagery. SPIE Opt. Eng. 2005, 44, 076404. [Google Scholar] [CrossRef]
- Venkataraman, V.; Fan, G.; Yu, L.; Zhang, X.; Liu, W.; Havlicek, J.P. Automated target tracking and recognition using coupled view and identity manifolds for shape representation. EURASIP J. Adv. Signal Process. 2011, 2011, 124. [Google Scholar] [CrossRef]
- Yoon, S.P.; Song, T.L.; Kim, T.H. Automatic target recognition and tracking in forward-looking infrared image sequences with a complex background. Int. J. Control. Autom. Syst. 2013, 11, 21–32. [Google Scholar] [CrossRef]
- Bharadwaj, P.; Runkle, P.; Carin, L. Infrared-image classification using expansion matching filters and hidden Markov trees. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 1553–1556. [Google Scholar]
- Gray, G.J.; Aouf, N.; Richardson, M.A.; Butters, B.; Walmsley, R.; Nicholls, E. Feature-based target recognition in infrared images for future unmanned aerial vehicles. J. Battlef. Technol. 2011, 14, 27–36. [Google Scholar]
- Cao, Z.; Zhang, X.; Wang, W. Forward-looking infrared target recognition based on histograms of oriented gradients. In Proceedings of the MIPPR 2011: Automatic Target Recognition and Image Analysis, Guilin, China, 4–6 November 2011. [Google Scholar]
- Zhang, F.; Liu, S.Q.; Wang, D.B.; Guan, W. Aircraft recognition in infrared image using wavelet moment invariants. Image Vis. Comput. 2009, 27, 313–318. [Google Scholar] [CrossRef]
- Makantasis, K.; Nikitakis, A.; Doulamis, A.D.; Doulamis, N.D.; Papaefstathiou, I. Data-Driven Background Subtraction Algorithm for In-Camera Acceleration in Thermal Imagery. IEEE Trans. Circuits Syst. Video Technol. 2018, 54, 2090–2104. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, A. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Lew, M. Deep learning for visual understanding: A review. Intell. Neurosci. 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tank, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmmentation with Deep Convolutional Nets and Fully Connected CRFs? In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 December 2015. [Google Scholar]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Williams, D.P. Underwater target classification in synthetic aperture sonar imagery using deep convolutional neural networks. In Proceedings of the IEEE International Conference on Pattern Recognition, Cancún, Mexico, 4–8 December 2016; pp. 2497–2502. [Google Scholar]
- Akula, A.; Singh, A.; Ghosh, R.; Kumar, S.; Sardana, H.K. Target Recognition in Infrared Imagery Using Convolutional Neural Network. In Proceedings of International Conference on Computer Vision and Image Processing; Springer: New York, NY, USA, 2017; pp. 25–34. [Google Scholar]
- Gungdogu, E.; Koc, A.; Alatan, A. Object classification in infrared images using deep representations. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 1066–1070. [Google Scholar]
- Bhattacharya, P.; Riechen, J.; Zolzer, O. Infrared Image Enhancement in Maritime Environment with Convolutional Neural Networks. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Funchal, Portugal, 27–29 January 2018. [Google Scholar]
- Kim, S.; Song, W.; Kim, S. Infrared Variation Optimized Deep Convolutional Neural Network for Robust Automatic Ground Target Recognition. In Proceedings of the CVPR Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 195–202. [Google Scholar]
- Rodger, I.; Connor, B.; Robertson, N. Classifying objects in LWIR imagery via CNNs. In Proceedings of the SPIE: Electro-Optical and Infrared Systems: Technology and Applications XIII, Edinburgh, UK, 26–29 September 2016; Volume 9987, pp. 99870–99884. [Google Scholar]
- Malmgren-Hansen, D.; Kusk, A.; Dall, J.; Nielsen, A.A.; Engholm, R.; Skriver, H. Improving SAR Automatic Target Recognition Models with Transfer Learning from Simulated Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1484–1488. [Google Scholar] [CrossRef]
- Kang, M.; Ji, K.; Leng, X.; Xing, X.; Zou, H. Synthetic Aperture Radar Target Recognition with Feature Fusion Based on a Stacked Autoencoder. Sensors 2017, 17, 192. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Kang, M.; Leng, X.; Zou, H. Deep Convolutional Highway Unit Network for SAR Target Classification with Limited Labeled Training Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1091–1095. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Chen, C.; Seff, A.; Kornhauser, A.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the International Conference on Computer Vision, Araucano Park, Chile, 11–18 December 2015. [Google Scholar]
- Bakry, A.; Elhoseiny, M.; El-Gaaly, T.; Elgammal, A. Digging deep into the layers of CNNs: In search of how CNNs achieve view invariance. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto-Rico, 26 April–4 May 2016. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free?—Weakly-supervised learning with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 685–694. [Google Scholar]
- Bazzani, L.; Bergamo, A.; Anguelov, D.; Torresani, L. Self-taught Object Localization with Deep Networks. arXiv 2014, arXiv:1409.3964v7. [Google Scholar]
- Azulay, A.; Weiss, Y. Why do deep convolutional networks generalize so poorly to small image transformations? arXiv 2018, arXiv:1805.12177v2. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Networks in Networks. arXiv 2013, arXiv:1312.4400v3. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Springenberg, J.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2014, arXiv:1412.6806v3. [Google Scholar]
- Maas, A.; Hannun, A.; Ng, A. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lin, T.-Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. In Proceedings of the International Conference on Computer Vision, Araucano Park, Chile, 11–18 December 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567v3. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Features Map | Kernel Size | Output Size |
|---|---|---|---|
| Conv 1.1 | 16 | 5 × 5 | 124 × 124 |
| Conv 1.2 | 16 | 5 × 5 | 120 × 120 |
| Max-pool 2 × 2 | 60 × 60 | ||
| Conv 2.1 | 32 | 5 × 5 | 56 × 56 |
| Conv 2.2 | 32 | 5 × 5 | 52 × 52 |
| Max-pool 2 × 2 | 26 × 26 | ||
| Conv 3 | 64 | 5 × 5 | 22 × 22 |
| Max-pool 2 × 2 | 11 × 11 | ||
| Conv 4 | 64 | 5 × 5 | 7 × 7 |
| Conv 5 | 8 | 1 × 1 | 7 × 7 |
| Global average pooling | 8 × 1 | ||
| Softmax | 8 × 1 | ||
| Training Set | TRS2 | TRS3 | ||
|---|---|---|---|---|
| Architecture | Ident. | Recog. | Ident. | Recog. |
| SVM | 3.2% | 10.20% | 8.8% | 16.11% |
| Rodgers et al. | 3.34% | 8.36% | 8.43% | 9.27% |
| BCNN | 3.38% | 14% | 4.48% | 12.64% |
| Inception v3 | 0.79% | 10.68% | 9% | 25.77% |
| cfCNN(fc) | 14.17% | 12.71% | 23.61% | 17.71% |
| cfCNN | 6.20% | 10.62% | 14.67% | 17.98% |
| Training Set | TRS1 | TRS2 | TRS3 | |||
|---|---|---|---|---|---|---|
| Architecture | Ident. | Recog. | Ident. | Recog. | Ident. | Recog. |
| SVM | −1.44% | −1.78% | −2.96% | 2.47% | −1.92% | 9% |
| BCNN | −0.13% | −8.91% | −0.05% | −0.40% | −6.29% | 3.38% |
| Inception v3 | −2.47% | −15.83% | −9.35% | −10.98% | −1.25% | 7.82% |
| cfCNN(fc) | −18.02% | −5.43% | 1.42% | 0.98% | 8.10% | 6.35% |
| cfCNN | 11.25% | 3.31% | 15.48% | 5.96% | 19.54% | 14.38% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
d’Acremont, A.; Fablet, R.; Baussard, A.; Quin, G. CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems. Sensors 2019, 19, 2040. https://doi.org/10.3390/s19092040
d’Acremont A, Fablet R, Baussard A, Quin G. CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems. Sensors. 2019; 19(9):2040. https://doi.org/10.3390/s19092040
Chicago/Turabian Styled’Acremont, Antoine, Ronan Fablet, Alexandre Baussard, and Guillaume Quin. 2019. "CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems" Sensors 19, no. 9: 2040. https://doi.org/10.3390/s19092040
APA Styled’Acremont, A., Fablet, R., Baussard, A., & Quin, G. (2019). CNN-Based Target Recognition and Identification for Infrared Imaging in Defense Systems. Sensors, 19(9), 2040. https://doi.org/10.3390/s19092040