Multi-Sensor Data Fusion Algorithm Based on Trust Degree and Improved Genetics


Abstract
:1. Introduction
- Fuzzy mathematics, which replaces classical sets with fuzzy sets, thus extending the concepts in classical mathematics;
- Fuzzy logic and artificial intelligence, which introduces approximate reasoning in classical logic, and develops expert systems based on fuzzy information and approximate reasoning;
- Fuzzy system, which contains fuzzy control and fuzzy methods in signal processing and communication;
- Uncertainty and information, which is used to analyze various uncertainties;
- Fuzzy decision, which uses soft constraints to consider optimization problems.
- Using the cubic exponential smoothing method, data preprocessing is performed on the raw data collected by the sensor nodes, and the abnormal data generated by various factors are eliminated, and the authenticity and reliability of the data are improved;
- For the processed data, the data fusion algorithm proposed in this paper is used for data-level fusion. On the one hand, setting the trust function to exponential form avoids the absolute degree of mutual trust between data and makes the fusion result more accurate. On the other hand, the crossover and mutation operations in the traditional genetic algorithm are improved, the implementation efficiency of the algorithm is improved, and the data fusion accuracy is further improved, and can meet the requirements of high precision, low power consumption, and real-time performance of information collection in a greenhouse environment based on wireless sensor networks.
2. Related Work
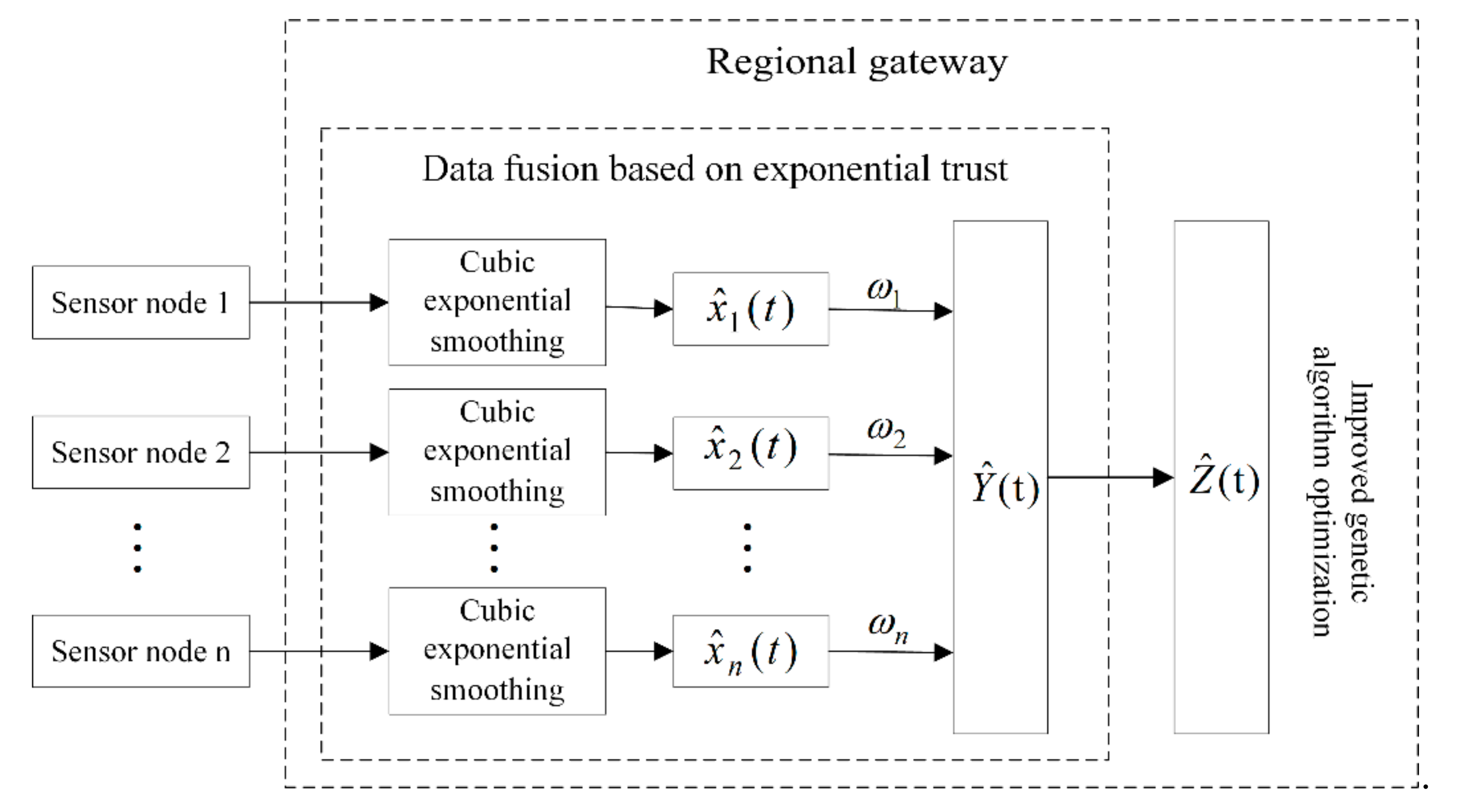
3. Multi-Sensor Data Fusion Structure Model
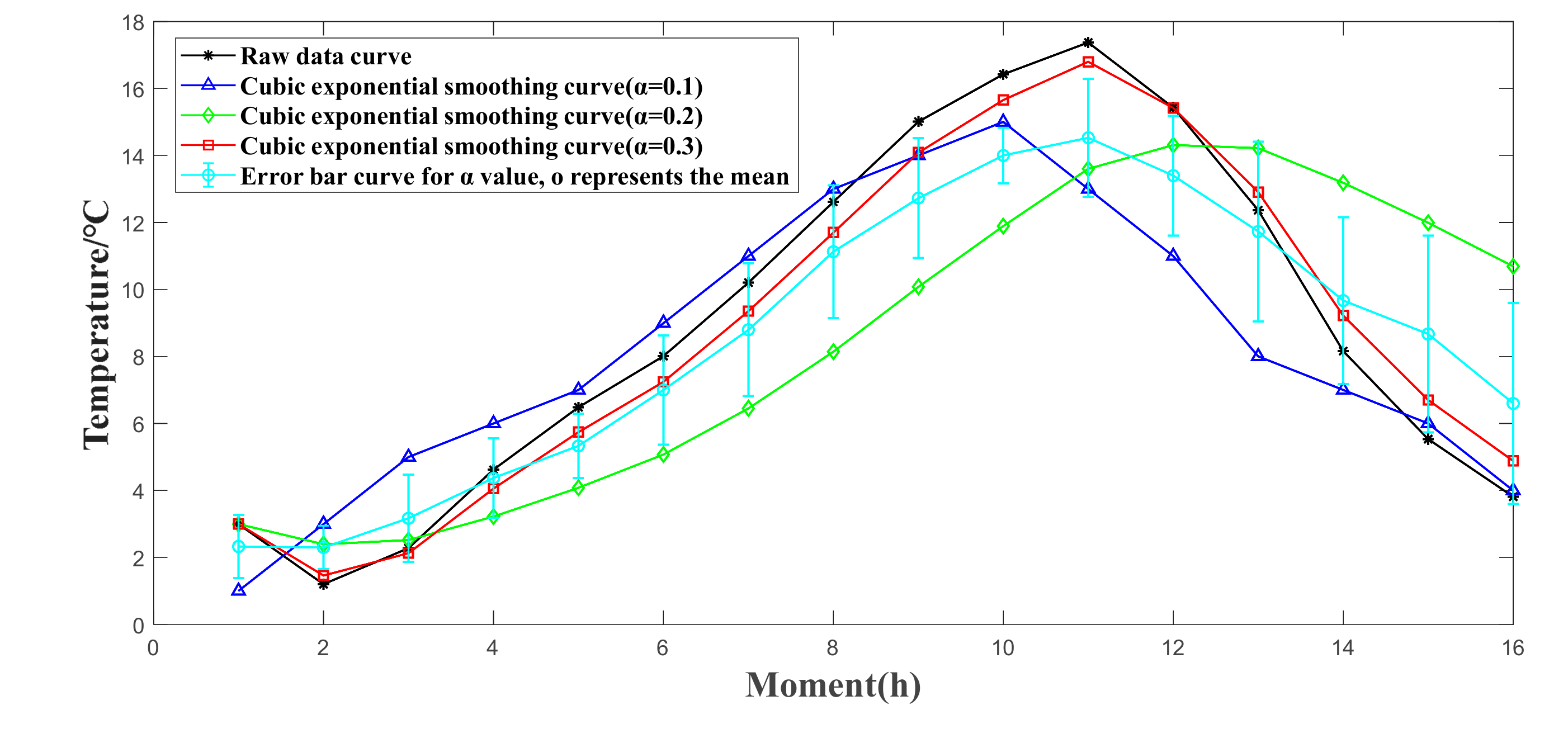
4. Data Preprocessing Based on Cubic Exponential Smoothing
5. Greenhouse WSNs Data Fusion Algorithm Based on Trust Degree and Improved Genetics
5.1. Trust Degree Function
5.2. Trust Degree based Data Fusion Model
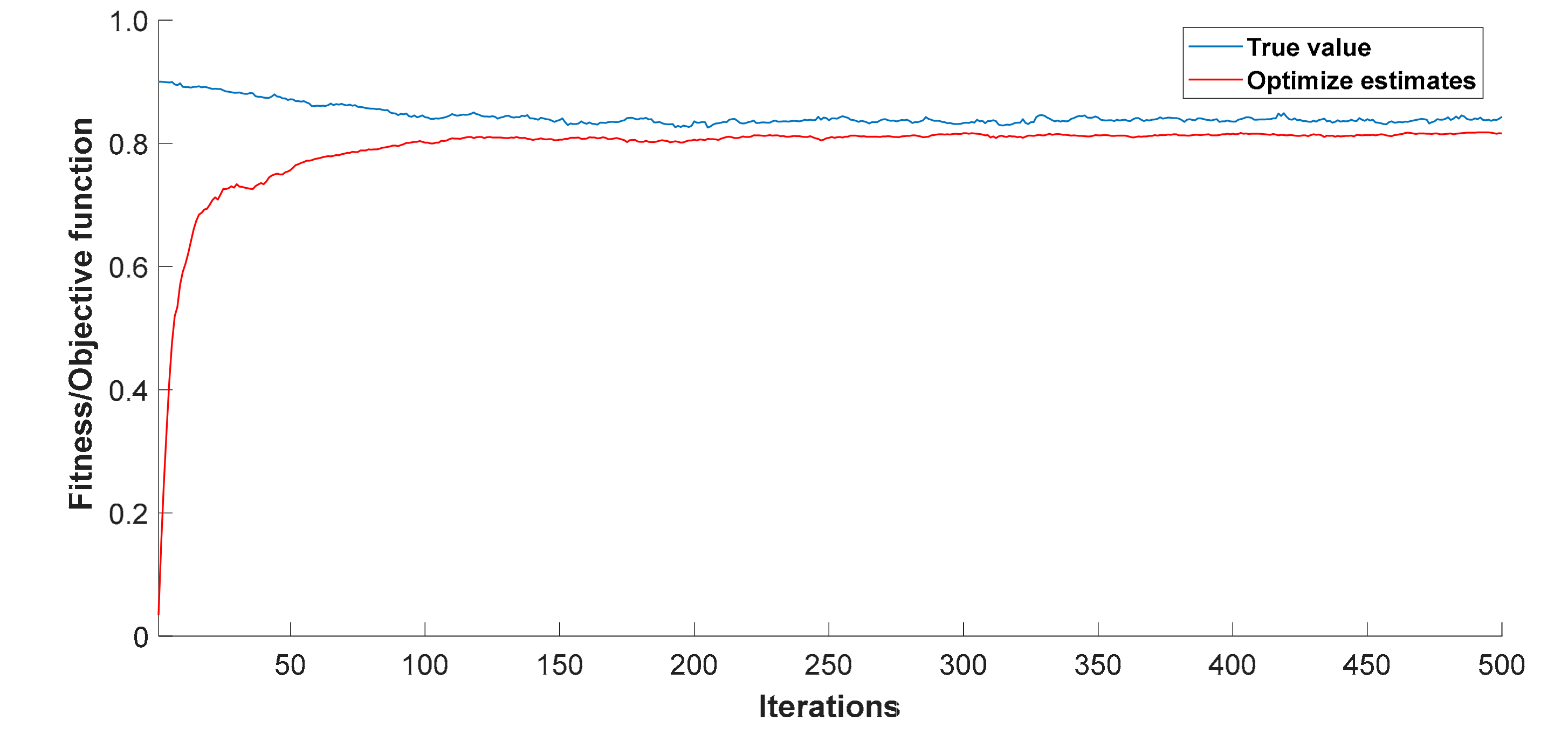
5.3. Optimize Fusion Results with Improved Genetic Algorithms
| Algorithm 1 Improved genetic algorithm. |
| 1. Initialization: using a decimal coding strategy, using the random number sequence composed of weights as the chromosome, the number of iterations G = 500; |
| 2. Set the initial population size using the improved circle algorithm; |
| 3. Initial circle |
| while do |
| if New pathOld path do |
| Exchange the order between u and v to get a new path: |
| else |
| Original path |
| end if |
| end while; |
| 4. The objective function is used as a fitness function; |
| 5. fordo; |
| 6. Adopt improved crossover: |
| sort Objective function ; |
| The crossover operator is determined by using Logistic chaotic sequence |
| According to the set mutation rate, the chaotic sequence is used to obtain the new gene value after mutation, thereby obtaining a new chromosome. |
| 7. Use the "Roulette Wheel Selection" to choose; |
| 8. end for. |
6. Tentative and Analysis
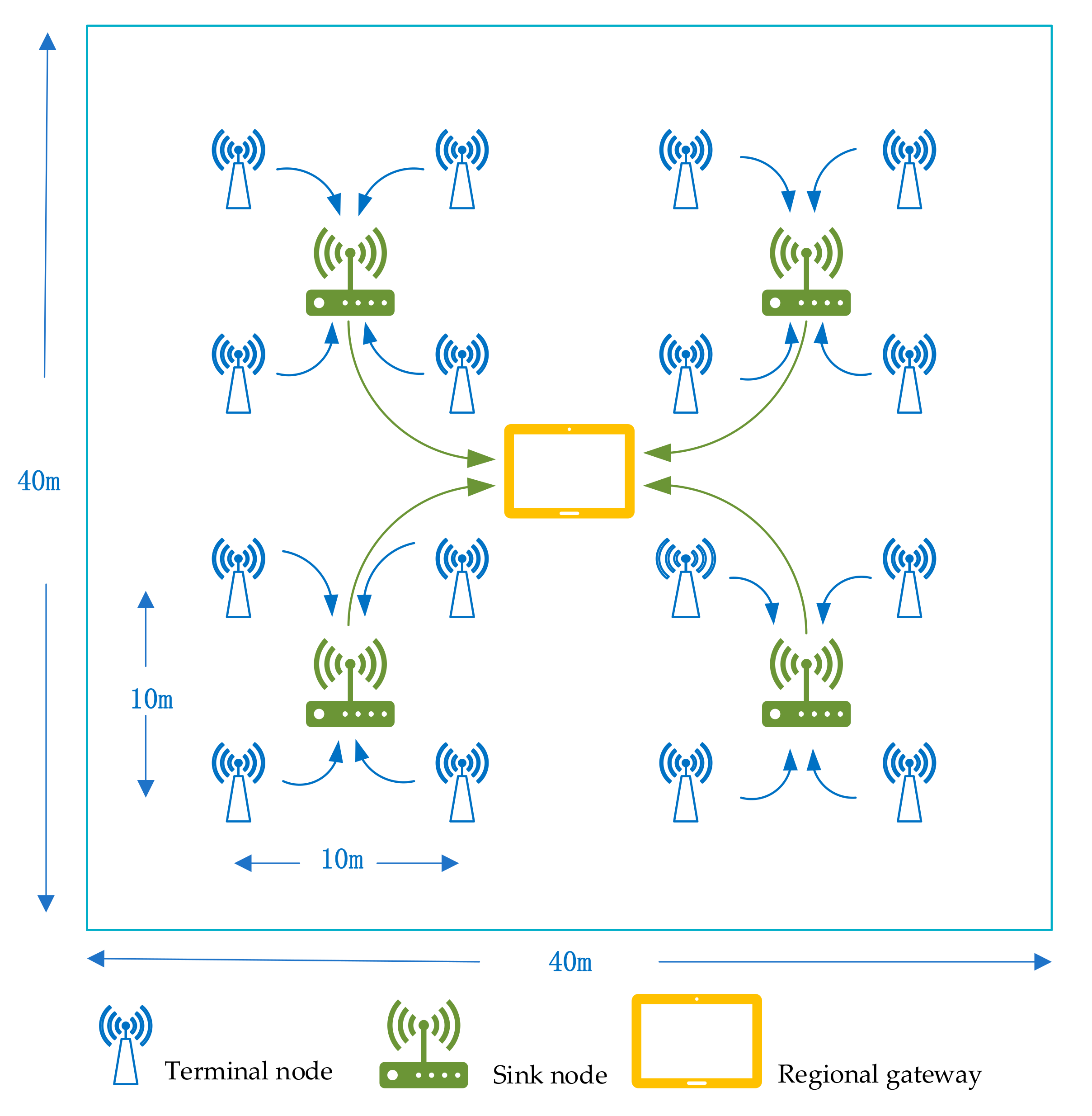
6.1. Tentative Method
6.2. Data Preprocessing Effect
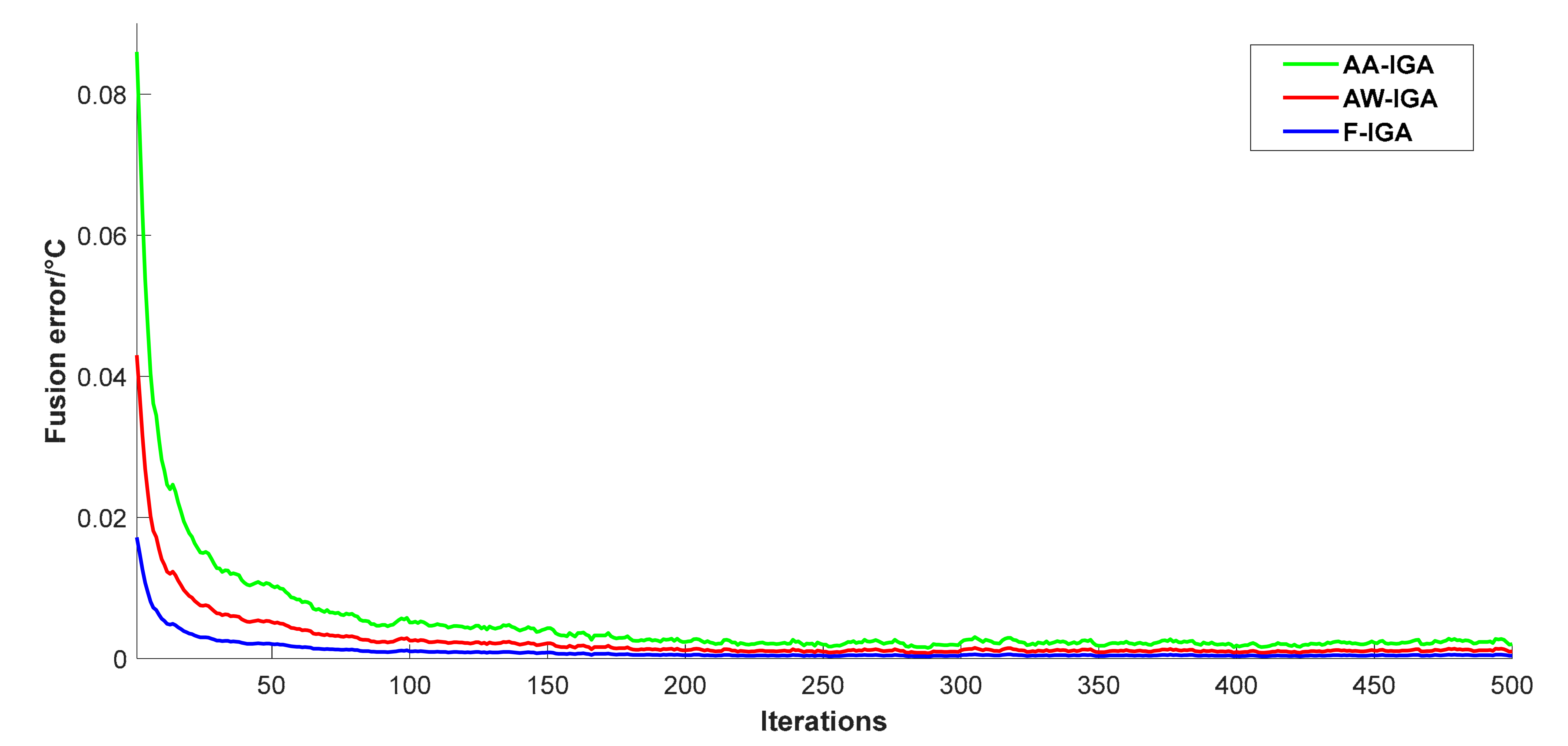
6.3. Data Fusion and Optimization Results
6.4. Performance Comparison
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Xingzhen, B.; Mengbai, M.; Zhijing, Z.; Zhengzhong, G. A Greenhouse Monitoring Data Fusion Algorithm Based on Data Preprocessing and Kalman Filter. J. Transduc. Technol. 2017, 30, 1525–1530. [Google Scholar]
- Wang, J.; Tawose, O.T.; Jiang, L.; Zhao, D. A New Data Fusion Algorithm for Wireless Sensor Networks Inspired by Hesitant Fuzzy Entropy. Sensors (Basel) 2019, 19, 784. [Google Scholar] [CrossRef]
- Srbinovska, M.; Gavrovski, C.; Dimcev, V.; Krkoleva, A.; Borozan, V. Environmental parameters monitoring in precision agriculture using wireless sensor networks. J. Clean. Produc. 2015, 88, 297–307. [Google Scholar] [CrossRef]
- Yinghui, L.; Genqing, D. Study on Data Fusion of Wireless Monitoring System for Greenhouse. In Proceedings of the 8th International Conference on Intelligent Computation Technology and Automation (ICICTA), Nanchang, China, 14–15 June 2015; pp. 864–866. [Google Scholar]
- Jiang, H.; Hallstrom, J.O. Fast, Accurate Event Classification on Resource-Lean Embedded Sensors. ACM Trans. Auton. Adapt. Syst. 2013, 8, 65–80. [Google Scholar] [CrossRef]
- Huang, L.; Xiao, J. Application Research of Intelligent Greenhouse’s Control System Based on Multi-Sensor Data Fusion. In Proceedings of the Second International Conference on Computer Modeling and Simulation, Hainan, China, 20–24 January 2010; pp. 211–214. [Google Scholar]
- Yingjun, X.; Mingxia, S.; Mingzhou, L.; Yonghua, L.; Yuwen, S.; Longshen, L. Real-time data fusion algorithm for greenhouse wireless sensor networks system. Trans. Chin. Soc. Agric. Eng. 2012, 28, 160–166. [Google Scholar]
- Tan, R.; Xing, G.; Liu, B.; Wang, J.; Jia, X. Exploiting Data Fusion to Improve the Coverage of Wireless Sensor Networks. IEEE/ACM Trans. Netw. 2012, 20, 450–462. [Google Scholar] [CrossRef]
- Li, L.; Wei-jia, L. The analysis of data fusion energy consumption in WSNS. In Proceedings of the 2011 International Conference on System Science, Engineering Design and Manufacturing Informatization, Guiyang, China, 22–23 October 2011; pp. 310–313. [Google Scholar]
- Wang, W.; Huang, T.; Liu, H.; Pang, F. Localization Algorithm Based on SVM-Data Fusion in Wireless Sensor Networks. In Proceedings of the 2009 Third International Conference on Genetic and Evolutionary Computing, Guilin, China, 14–17 October 2009; pp. 447–450. [Google Scholar]
- Rodríguez, S.; Zato, C.; Corchado, J.M.; Li, T. Fusion system based on multi-agent systems to merge data from WSNS. In Proceedings of the 17th International Conference on Information Fusion (FUSION), Salamanca, Spain, 7–10 July 2014; pp. 1–8. [Google Scholar]
- Zhang, Y.; Dingguo, J.; Baoguo, X. Application of Improved BP Algorithm in Multi-sensor Data Fusion. J. Southeast Univ. (Nat. Sci. Ed.) 2008, S1, 258–261. [Google Scholar]
- Li, L.; Bai, F. Analysis of Data Fusion in Wireless Sensor Networks. In Proceedings of the 2011 International Conference on Electronics Communications and Control (ICECC), Ningbo, China, 9–11 September 2011; pp. 2547–2549. [Google Scholar]
- Haitao, W. Research on Quadratic Data Fusion Based on Trust Degree; Kunming University of Science and Technology: Kunming, China, 2015. [Google Scholar]
- Liao, Y.; Chou, J. Weighted Data Fusion Use for Ruthenium Dioxide Thin Film pH Array Electrodes. IEEE Sens. J. 2009, 9, 842–848. [Google Scholar] [CrossRef]
- Yager, R.R. The power average operator. IEEE Trans. Syst. Man Cybern. Part A 2001, 31, 724–731. [Google Scholar] [CrossRef]
- Shi, L.; Mengyao, L.; Li, X. WSNS data fusion approach based on improved BP algorithm and clustering protocol. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 1450–1454. [Google Scholar]
- Zhang, J.; Yang, Z. Research on Data Fusion in Multi-sensor Data Acquisition System. Transduc. Microsyst. 2014, 33, 52–57. [Google Scholar]
- Zhenjiang, C.; Jianyi, K.; Qing, Z.; Hong, X. Application of Data Fusion Technology in Greenhouse Temperature Detection. Transact. Chin. Soc. Agric. Mach. 2006, 10, 101–103. [Google Scholar]
- Liyong, Z.; Zhang, L.; Li, D. Multi-sensor grouping weighted fusion algorithm based on optimal grouping principle. Chin. J. Sci. Instrum. 2008, 1, 200–205. [Google Scholar]
- Gao, F.; Yu, L.; Wang, Y.; Shangqiong, L.; Zhang, W.; Lijie, Y. Development of PC software for wireless sensor networks crops moisture monitoring system. Trans. Chin. Soc. Agric. Eng. 2010, 26, 175–181. [Google Scholar]
- Hezhen, C.; Minghe, J.; Feng, J. Kalman Filtering and Multi-sensor Data Fusion Technology. Pattern Recognit. Artif. Intell. 2000, 13, 248–253. [Google Scholar]
- Li, P. Application of Kalman Filter in Information Fusion Theory; Xidian University: Xidian, China, 2008. [Google Scholar]
- Collotta, M.; Pau, G.; Bobovich, A.V. A Fuzzy Data Fusion Solution to Enhance the QoS and the Energy Consumption in Wireless Sensor Networks. Wirel. Commun. Mob. Comput. 2017, 10, 3418284. (In English) [Google Scholar] [CrossRef]
- Wen, Z.; Xie, L.; Feng, H.; Tan, Y. Robust fusion algorithm based on RBF neural network with TS fuzzy model and its application to infrared flame detection problem. Appl. Soft Comput. 2019, 76, 251–264. [Google Scholar] [CrossRef]
- Qiao, J.F.; Li, W.; Han, H. Soft computing of biochemical oxygen demand using an improved T-S fuzzy neural network. Chin. J. Chem. Eng. 2014, 22, 1254–1259. [Google Scholar] [CrossRef]
- Wang, S.X.; Zhang, N.; Wu, L. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Xu, D.; Zhao, R.; Li, S.; Chen, S.; Jiang, Q.; Zhou, L.; Shi, Z. Multi-sensor fusion for the determination of several soil properties in the Yangtze River Delta, China. Eur. J. Soil Sci. 2019, 70, 162–173. [Google Scholar] [CrossRef]
- Wu, J.; Yang, S.X. Intelligent Control of Bulk Tobacco Curing Schedule Using LS-SVM-and ANFIS-Based Multi-Sensor Data Fusion Approaches. Sensors 2019, 19, 1778. [Google Scholar] [CrossRef]
- Aiello, G.; Giovino, I.; Vallone, M.; Catania, P.; Argento, A. A decision support system based on multisensor data fusion for sustainable greenhouse management. J. Clean. Product. 2018, 172, 4057–4065. [Google Scholar] [CrossRef]
- Kolomvatsos, K.; Anagnostopoulos, C.; Hadjiefthymiades, S. Data Fusion and Type-2 Fuzzy Inference in Contextual Data Stream Monitoring. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 1839–1853. [Google Scholar] [CrossRef]
- Liu, K.; Chehade, A.; Song, C. Optimize the Signal Quality of the Composite Health Index via Data Fusion for Degradation Modeling and Prognostic Analysis. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1504–1514. [Google Scholar] [CrossRef]
- Jinpei, W.; Deshan., S. Modern Data Analysis; Mechanical Industry Press: Beijing, China, 2006. [Google Scholar]
- Zhentao, H.; Xiansheng, L. A Multi-sensor Data Fusion Method Based on Relative Distance. Syst. Eng. Electron. 2006, 28, 196–198. [Google Scholar]
- Zhuqing, J.; Weili, X.; Zhang, L.; Baoguo, X. Multi-sensor data fusion based on trust and its application. J. Southeast Univ. (Nat. Sci. Ed.) 2008, S1, 253–257. [Google Scholar]
- Back, T.; Hoffimeister, F.; Schwefel, H.P. A survey of evolution strategies. In Proceedings of the 4th International Genetic Algorithms Conference, San Diego, CA, USA, 13–16 July 1991; pp. 2–9. [Google Scholar]
- Fogel, D.B. An introduction to simulated evolutionary optimization. IEEE Trans. Neural Netw. 1994, 5, 3–14. [Google Scholar] [CrossRef]
- Wei, C.J.; Yao, S.S.; He, Z.Y. A modified evolutionary programming. In Proceedings of the IEEE International Evolutionary Computation Conference, Nagoya, Japan, 20–22 May 1996; pp. 135–138. [Google Scholar]
- Rudolph, G. Local convergence rates of simple evolutionary algorithms with Cauchy mutations. IEEE Trans. Evolut. Comput. 1997, 1, 249–258. [Google Scholar] [CrossRef]
- Chellapilla, K. Combining mutation operators in evolutionary programming. IEEE Trans. Evolut. Comput. 1998, 2, 91–96. [Google Scholar] [CrossRef]
- Xiangxing, W.; Chen, Z. Introduction to Chaos, Shanghai; Shanghai Science and Technology Literature Publishing House: Shanghai, China, 1996. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | F-IGA | AA-IGA | AW-IGA |
|---|---|---|---|
| Fusion error (°C) | 0.0043 | 0.0107 | 0.0076 |
| Algorithm | F-IGA | AA-IGA | AW-IGA |
|---|---|---|---|
| Average running time (s) | 21.274 | 60.155 | 46.491 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, G.; Zhang, Z.; Zheng, B.; Li, Y. Multi-Sensor Data Fusion Algorithm Based on Trust Degree and Improved Genetics. Sensors 2019, 19, 2139. https://doi.org/10.3390/s19092139
Sun G, Zhang Z, Zheng B, Li Y. Multi-Sensor Data Fusion Algorithm Based on Trust Degree and Improved Genetics. Sensors. 2019; 19(9):2139. https://doi.org/10.3390/s19092139
Chicago/Turabian StyleSun, Guiling, Ziyang Zhang, Bowen Zheng, and Yangyang Li. 2019. "Multi-Sensor Data Fusion Algorithm Based on Trust Degree and Improved Genetics" Sensors 19, no. 9: 2139. https://doi.org/10.3390/s19092139
APA StyleSun, G., Zhang, Z., Zheng, B., & Li, Y. (2019). Multi-Sensor Data Fusion Algorithm Based on Trust Degree and Improved Genetics. Sensors, 19(9), 2139. https://doi.org/10.3390/s19092139