Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death


Abstract
:1. Introduction
2. Risks Associated with the Spreading of COVID-19
3. Methodology
3.1. Data Collection
3.2. Data Processing
- Data preprocessing includes-data integration, removal of noisy data that are incomplete and inconsistent, data normalization and feature scaling, encoding of categorical data, feature selection after correlation analysis, and split data for training and testing an LSTM model.
- Training of a LSTM model and test its accuracy with loss functions as described in Section 3.5.
- Data postprocessing includes-pattern evaluation, pattern selection, pattern interpretation, and pattern visualization.
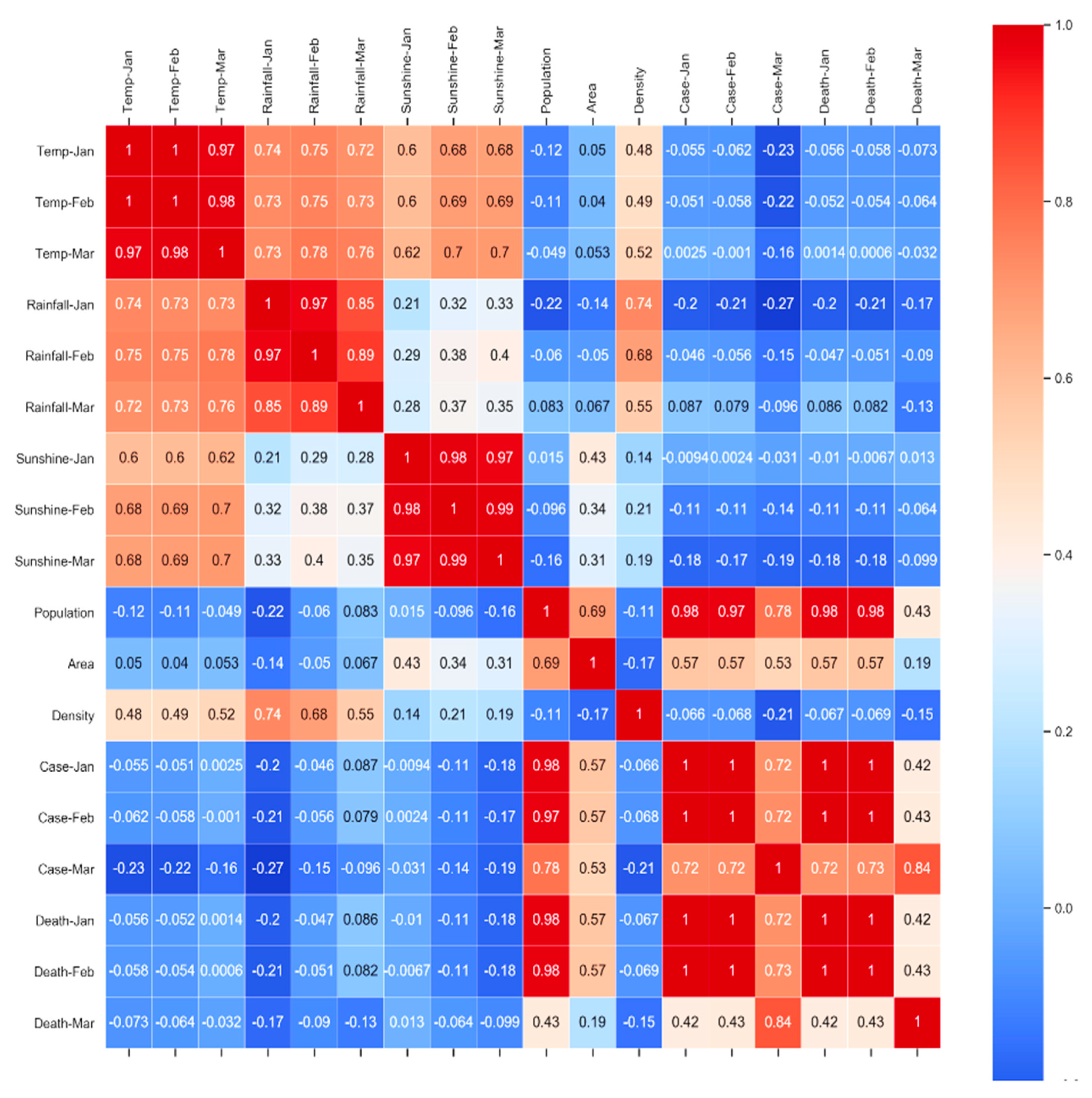
3.3. Statistical Analysis
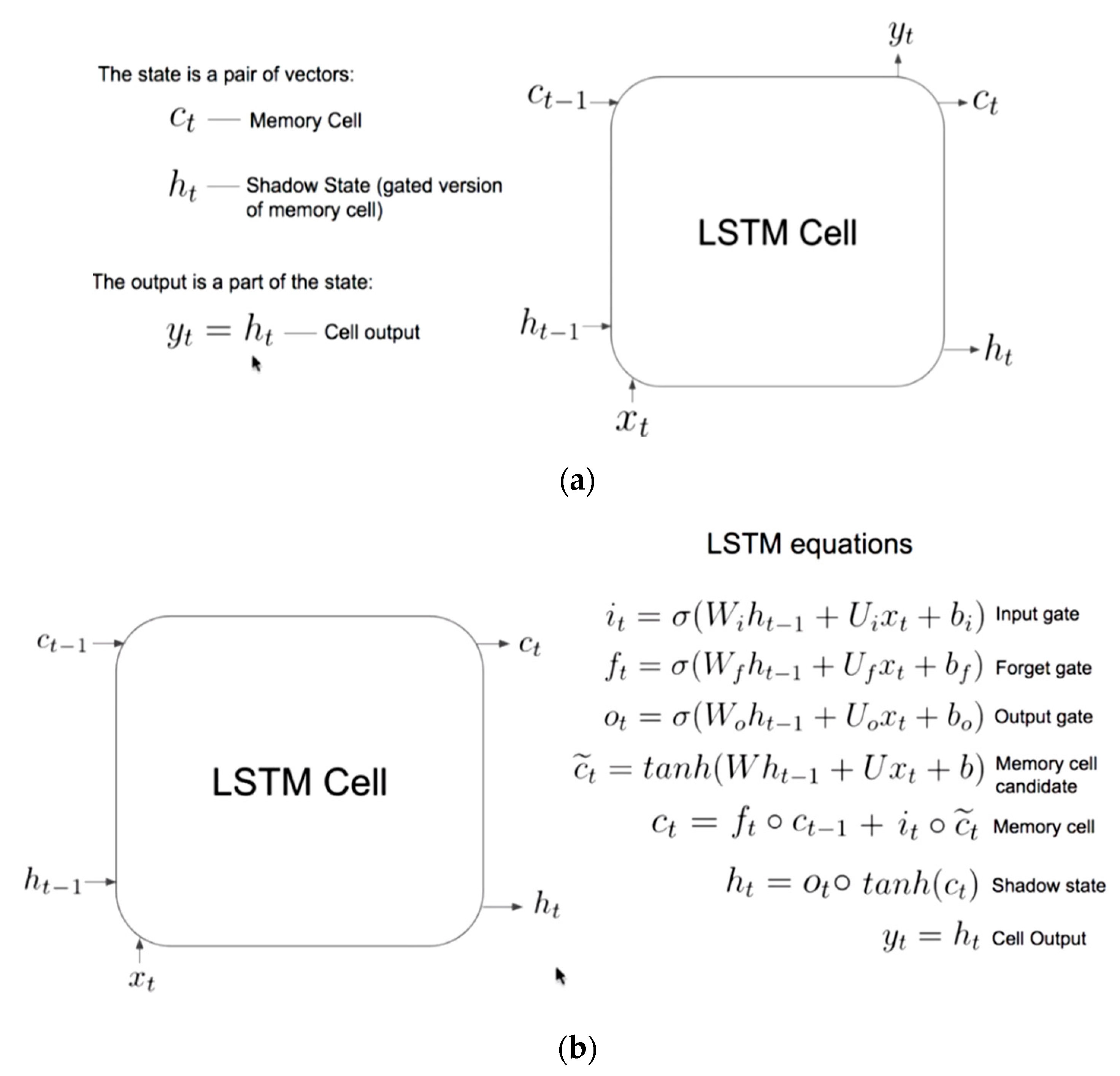
3.4. LSTM Modelling
- a.
- Vanilla LSTM Modelling in Keras:
- model = Sequential ()
- model.add (LSTM (50, activation =‘relu’, input_shape = (3, 1)))
- model.add (Dense (1))
- b.
- Stacked LSTM Modelling in Keras:
- model = Sequential ()
- model.add (LSTM (100, activation =‘relu’, return_sequences =True, input_shape = (3, 1)))
- model.add (LSTM (100, activation =‘relu’))
- model.add (Dense (1))
- c.
- Bidirectional LSTM Modelling in Keras:
- model = Sequential ()
- model.add (Bidirectional (LSTM (100, activation =‘relu’), input_shape = (3, 1)))
- model.add (Dense (1))
- d.
- Multilayer LSTM 1 Modelling in Keras:
- model = Sequential ()
- model.add (LSTM (units = 92, return_sequences = True, input_shape = (3, 1)))
- model.add (Dropout (0.2))
- model.add (LSTM (units = 92, return_sequences = True))
- model.add (Dropout (0.2))
- model.add (LSTM (units = 92, return_sequences = True))
- model.add (Dropout (0.2))
- model.add (LSTM (units = 92, return_sequences = False))
- model.add (Dropout (0.2))
- model.add (Dense (units = 1))
- e.
- Multilayer LSTM 2 Modelling in Keras:
- model = Sequential()
- model.add(LSTM(units = 100, return_sequences = True, input_shape = (3, 1)))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 100, return_sequences = True))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 100, return_sequences = True))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 100, return_sequences = True))
- model.add(Dropout(0.2))
- model.add(Dense(units = 1))
- f.
- Multilayer LSTM 3 Modelling in Keras:
- model = Sequential()
- model.add(LSTM(units = 50, return_sequences = True, input_shape = (3, 1)))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 50, return_sequences = True))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 50, return_sequences = True))
- model.add(Dropout(0.2))
- model.add(LSTM(units = 50, return_sequences = False))
- model.add(Dropout(0.2))
- model.add(Dense(units = 1))
- The “Dropout layer” refers to dropping out units (both hidden and visible neuron) in a neural network.
- There are three deep learning model optimizers for hyperparameter tuning and cross validation– a. Adaptive gradient (ADAGARD), b. RMSProp (adds exponential decay), and c. ADAM. In this study, we used “ADAM” optimizer.
- Mean square error (MSE), mean absolute error (MAE), “categorical_crossentropy”, “binary_crossentropy”, residual forecast error/forecast error, forecast bias/mean forecast error, root mean square error (RMSE), and “R2-score” are different determining methods for model loss, but we used “MSE”, “MAE”, “RMSE”, forecast bias, and “R2-score”.
- “Dense layer” is the regular deeply connected neural network layer.
- “ReLU” stands for rectified linear unit. It is a type of activation function. Mathematically, it can be defined as y = max (0, x), where x > 0. Its convergence is faster. It is fast to compute. It is sparsely activated.
- LSTM units can be trained in a supervised fashion, on a set of training sequences, using an optimization algorithm, such as gradient descent, combined with backpropagation through time to compute the gradients needed during the optimization process, to change every weight of the LSTM network in proportion to the derivative of the error (at the output layer of the LSTM network) with respect to corresponding weight.
3.5. Model Training and Testing
- Importing of python libraries
- Load data from repository
- Data pre-processing:
- ○
- remove missing value from the loaded data
- ○
- encode categorical features
- ○
- check distribution of data and features
- ○
- correlation analysis among features and feature scaling if required
- Feature scaling with “MinMaxScaler (feature_range = (0, 1))”
- Split the univariate sequence into samples
- Split data for training (97%) and testing (3%)
- Create LSTM models as described in Section 3.4.
- Compile the model with optimizer = “adam”, loss =“mse”, metrics = [“acc”]
- Train the model with epochs = 100, batch_size = 10, validation_split = 0.05
- Use “ADAM” optimizer for model tuning
- Evaluate model performance with accuracy and loss function after inverse transformation of the predicted feature.
- Execute the model for five times and then calculate the average of performance metrics as described in Section 3.5, and predicted value. It helps prove the testing rate and increase the validity of timeseries analysis.
- Univariate sequences are timeseries data of total cases, and total death for the world or individual countries. In this study, we have considered univariate timeseries data of the world for both training and testing of LSTM models, but the same model can be extended to use for individual countries.
- The “acc” refers to accuracy in metrics = [“acc”] of the corresponding LSTM model.
3.6. Model Performance Evaluation
- Regression metrices: mean absolute error (MAE), mean squared error (MSE), root mean square error (RMSE), forecast bias, and R2 regression metric.
forecast_bias = mean (forecast_error)
3.7. Model Store and Reuse
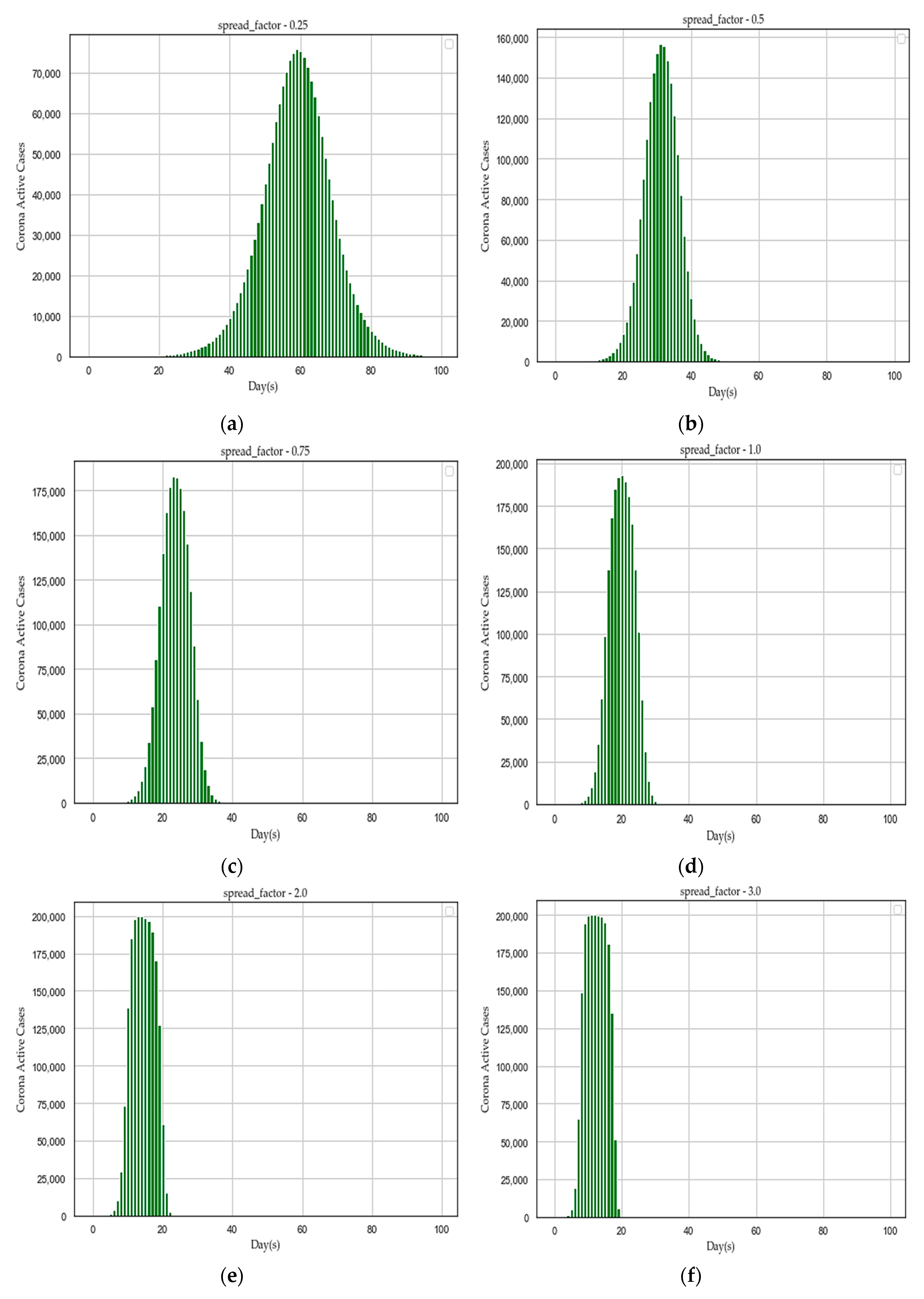
3.8. Algorithm Design to Find the Importance of Social Distancing
| Algorithm 1. Importance of social distancing by flattening the curve of afflicted population over specific days | |
| Step 1: Initialize necessary parameters as follows to create a simulated town infected with COVID-19 – | |
| days = 100/*lockdown days*/ | |
| population = 200,000/*population of the town*/ | |
| spread_factor = 0.25/*COVID-19 transmission rate (0 < f ≤ 5) */ | |
| days_to_recover = 10/*maximum recovery days from COVID-19*/ | |
| inital_afflicted_people = 5/*initial infected people of the town with COVID-19*/ | |
| Step 2: Initialize a data frame (“town”) for the simulated town with the following four features – | |
| id = range(population)/* id € (0- population) */ | |
| infected = false | |
| recovery_day = none | |
| recovered = false | |
| Step 3: Initialize the initial cases (“initialCases”) with inital_afflicted_people variable, | |
| update corresponding infected feature as true, and | |
| update recovery_day feature with days_to_recover variable | |
| Step 4: Initialize the initial active cases (“active_cases”) with initally_afflicted variable and | |
| initial recovered cases (“recovery”) with 0. | |
| Step 5: | |
| for day = 1 to days do | |
| Step 5.1: Mark the people of town data frame, who have recovered on current day | |
| - update the feature recovery_day as True and infected feature as False | |
| if they have crossed days_to_recover else ignore. | |
| Step 5.2: Calculate the number of people who are afflicted today with spread_factor | |
| - calculate number of people infected in the town data frame based on | |
| feature infected = True | |
| -multiply the count of total infected people with spread_factor to | |
| calculate total possible cases of infected people on current day | |
| Step 5.3: Forget people who were already infected in cases of current day | |
| Step 5.4: Mark the new cases as afflicted, and their recovery day by updating | |
| active_cases and recovery lists of the town data frame. | |
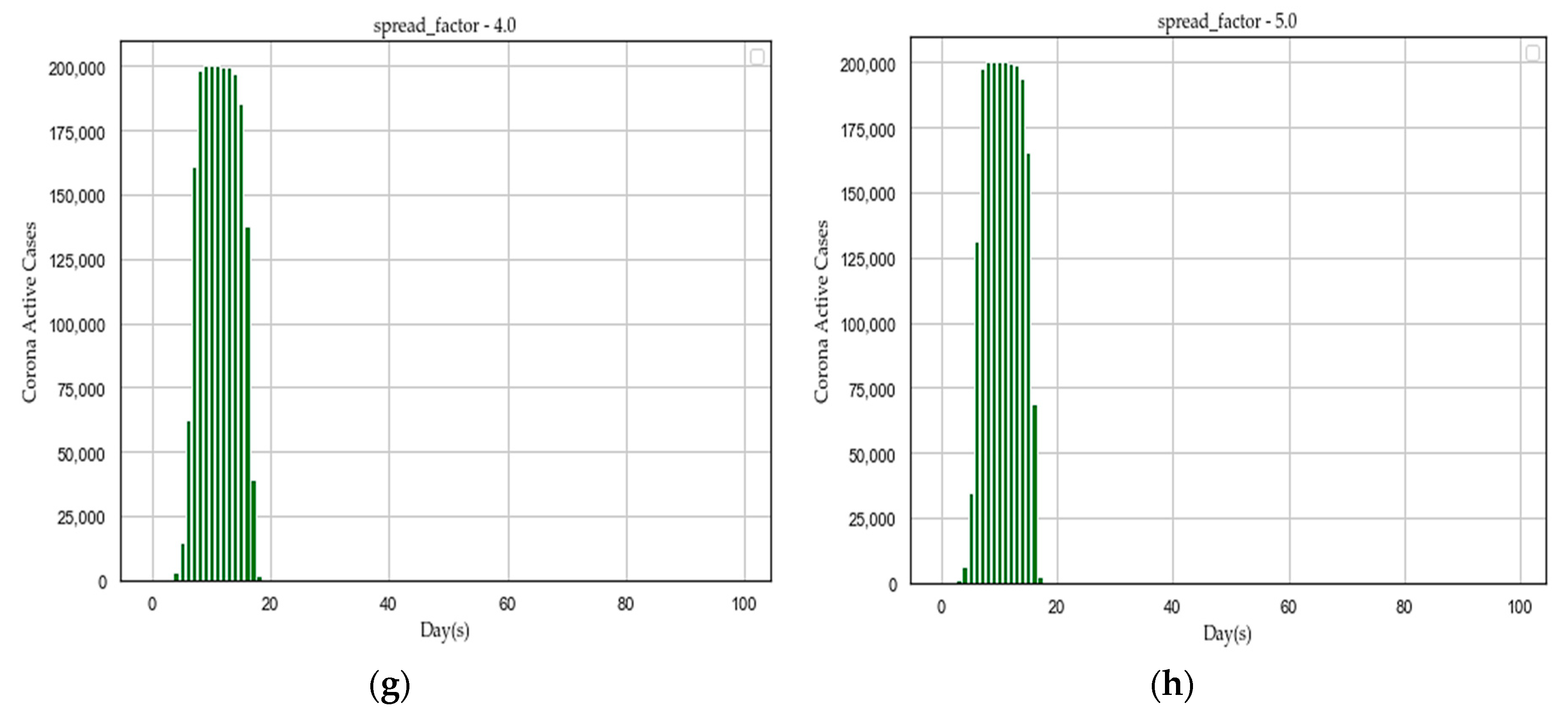
| Step 6: Repeat the step 5 for spread_factor = 0.25 to 5.0 and plot every distribution graph of active_cases over days. | |
- We plotted distribution graph of active cases over days for the following set of “f” values: [0.25, 0.5, 0.75, 1.0, 2.0, 3.0, 4.0, 5.0] with the initialized parameters at Step 1.
- The algorithm was implemented with “simulated_data_2”.
- The worst-case time complexity of the algorithm is O(N2), where N = problem size.
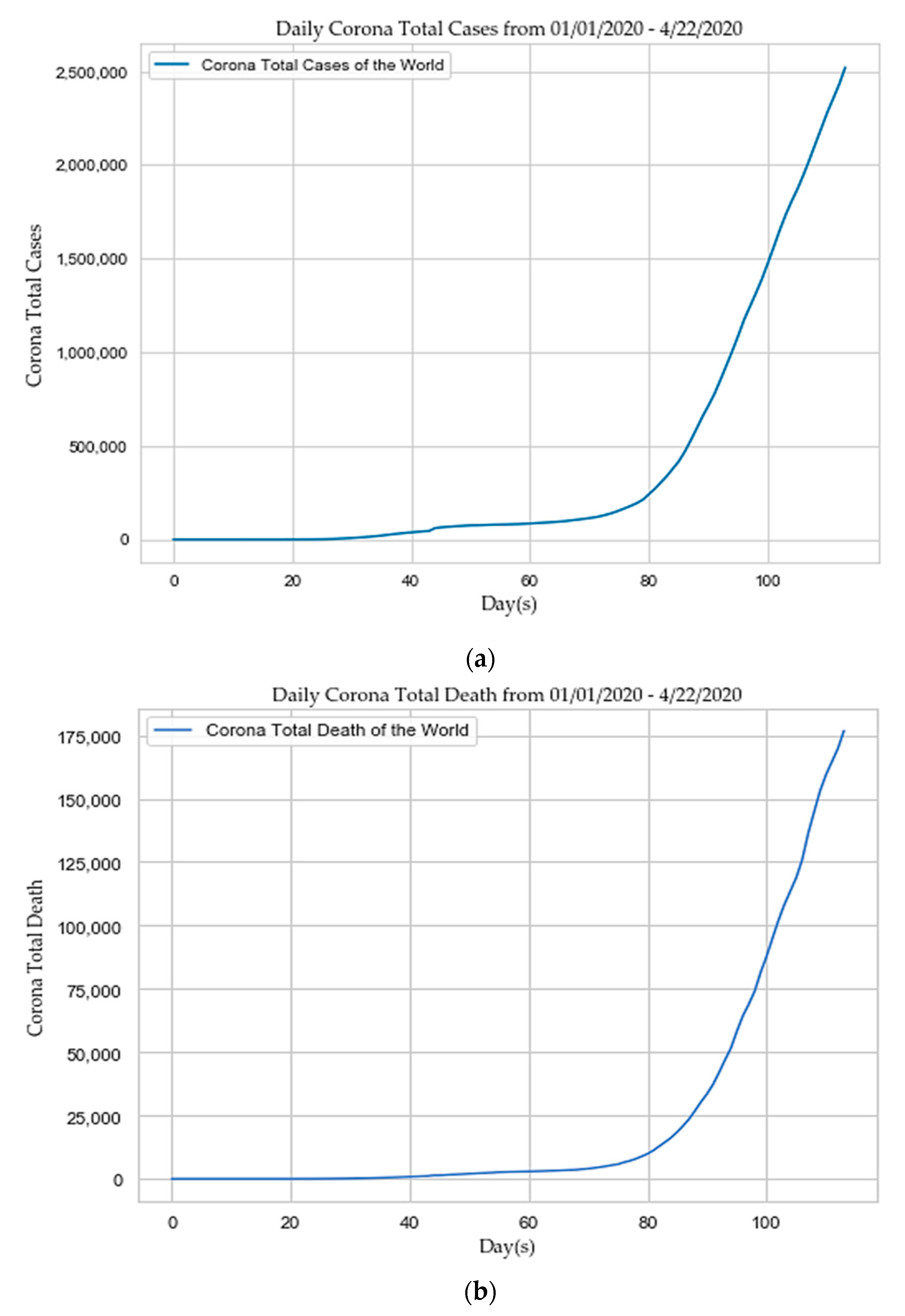
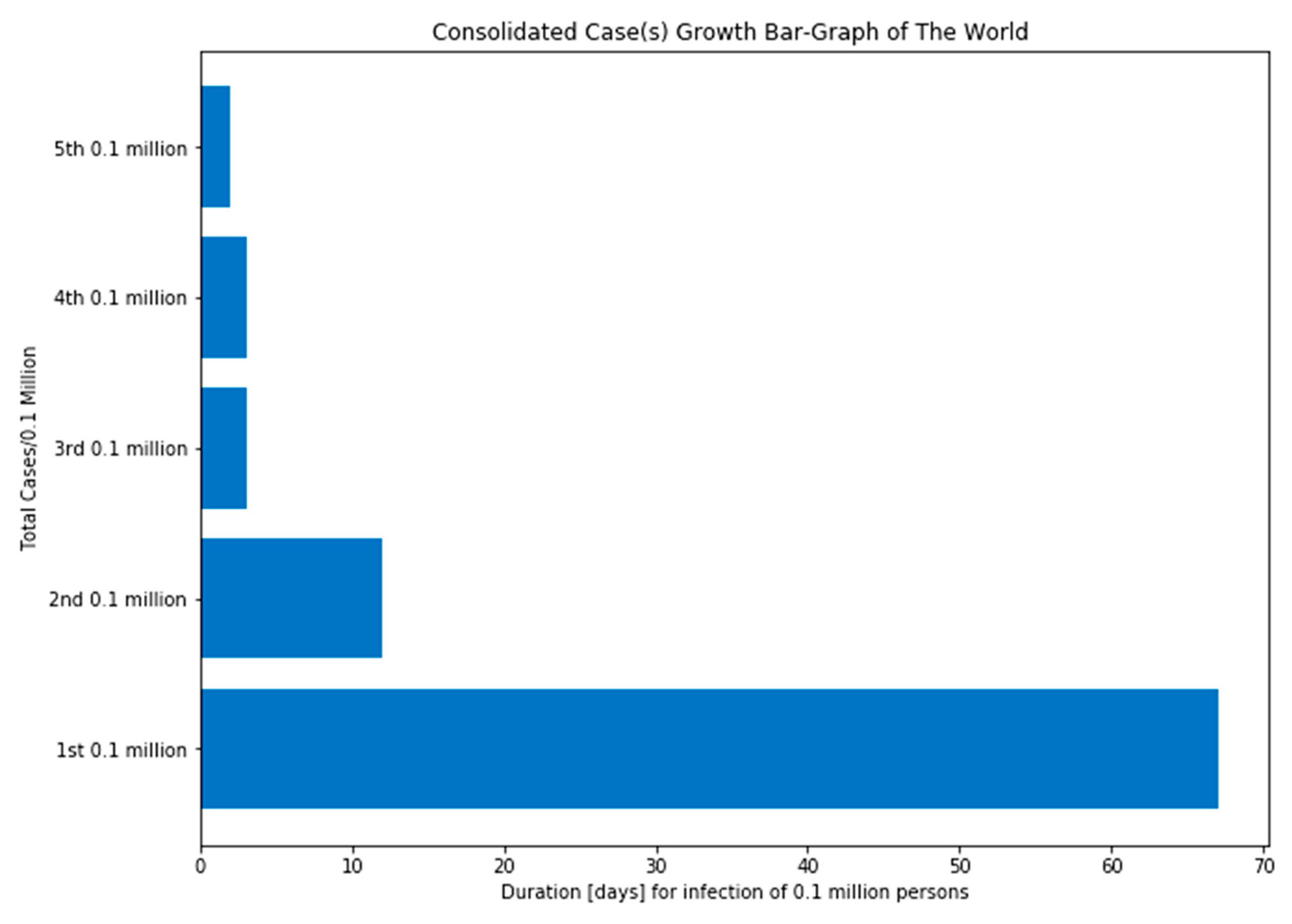
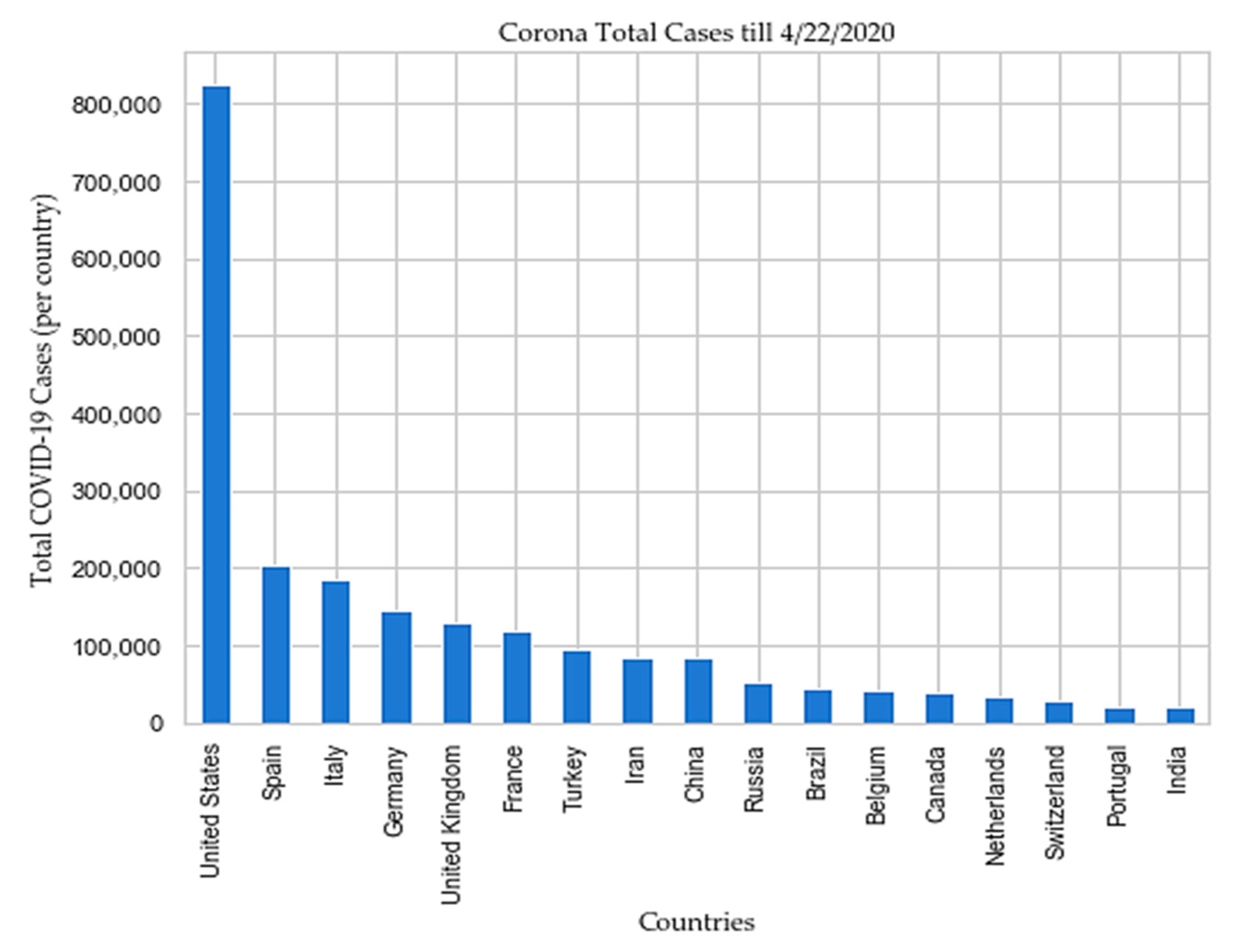
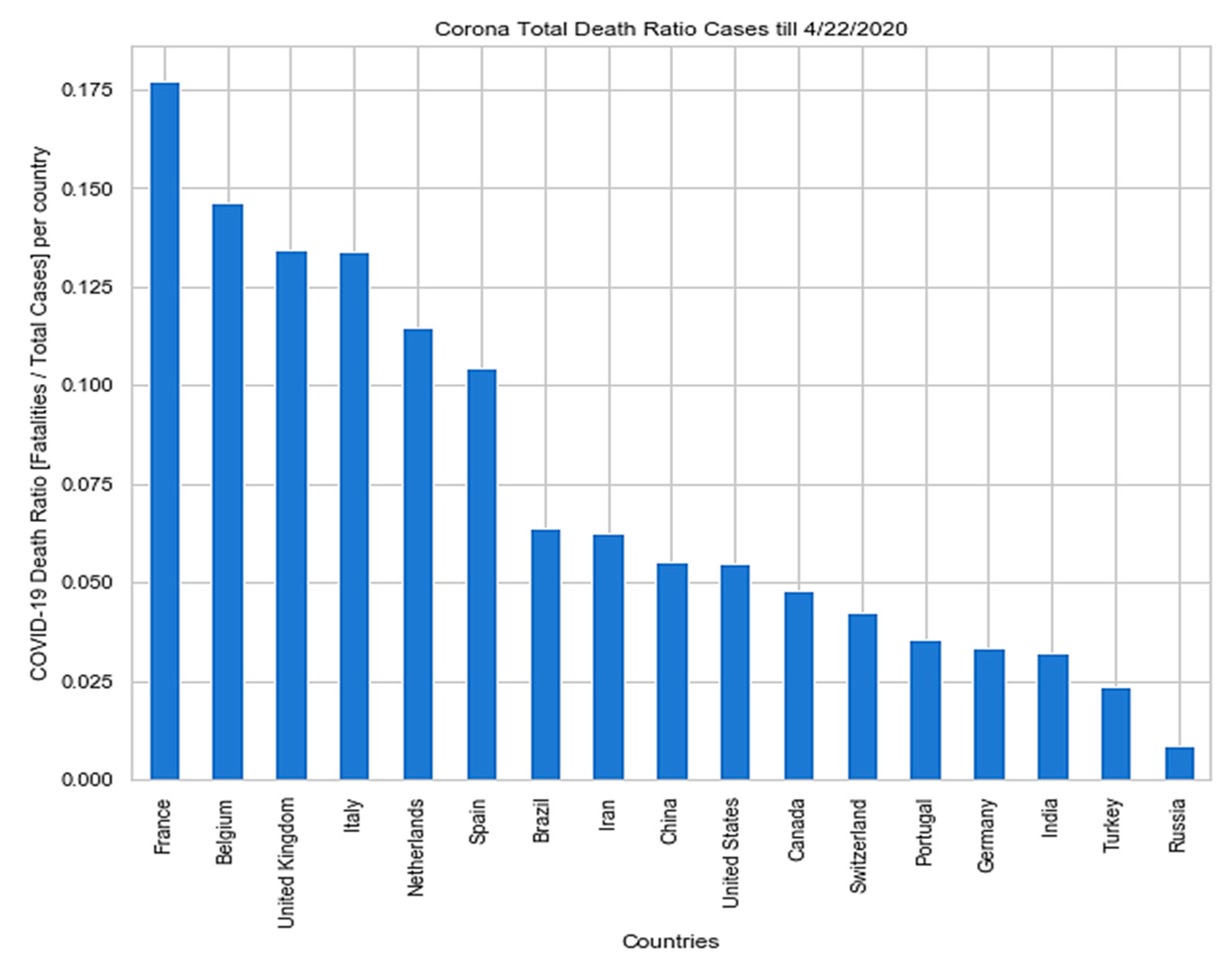
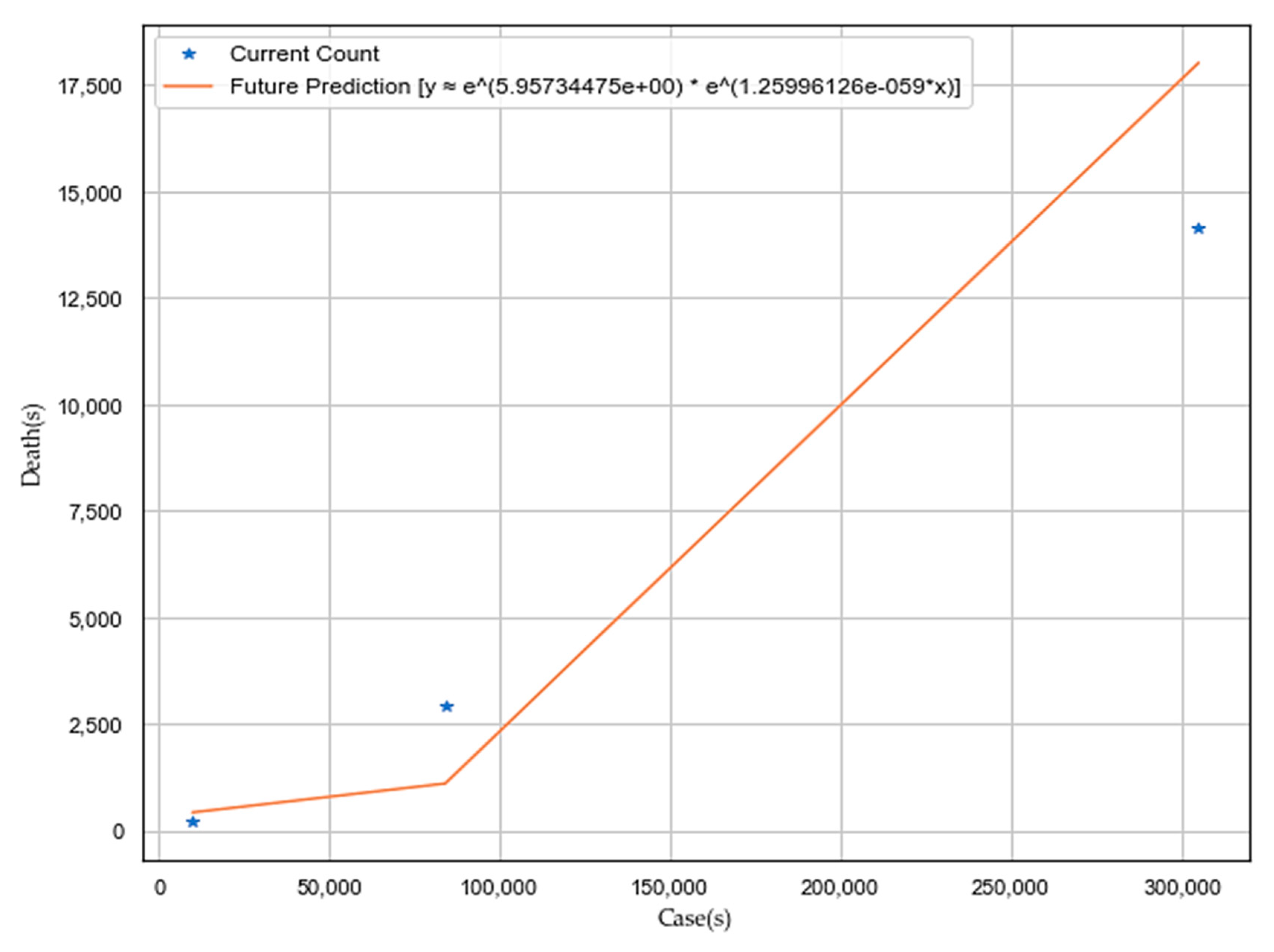
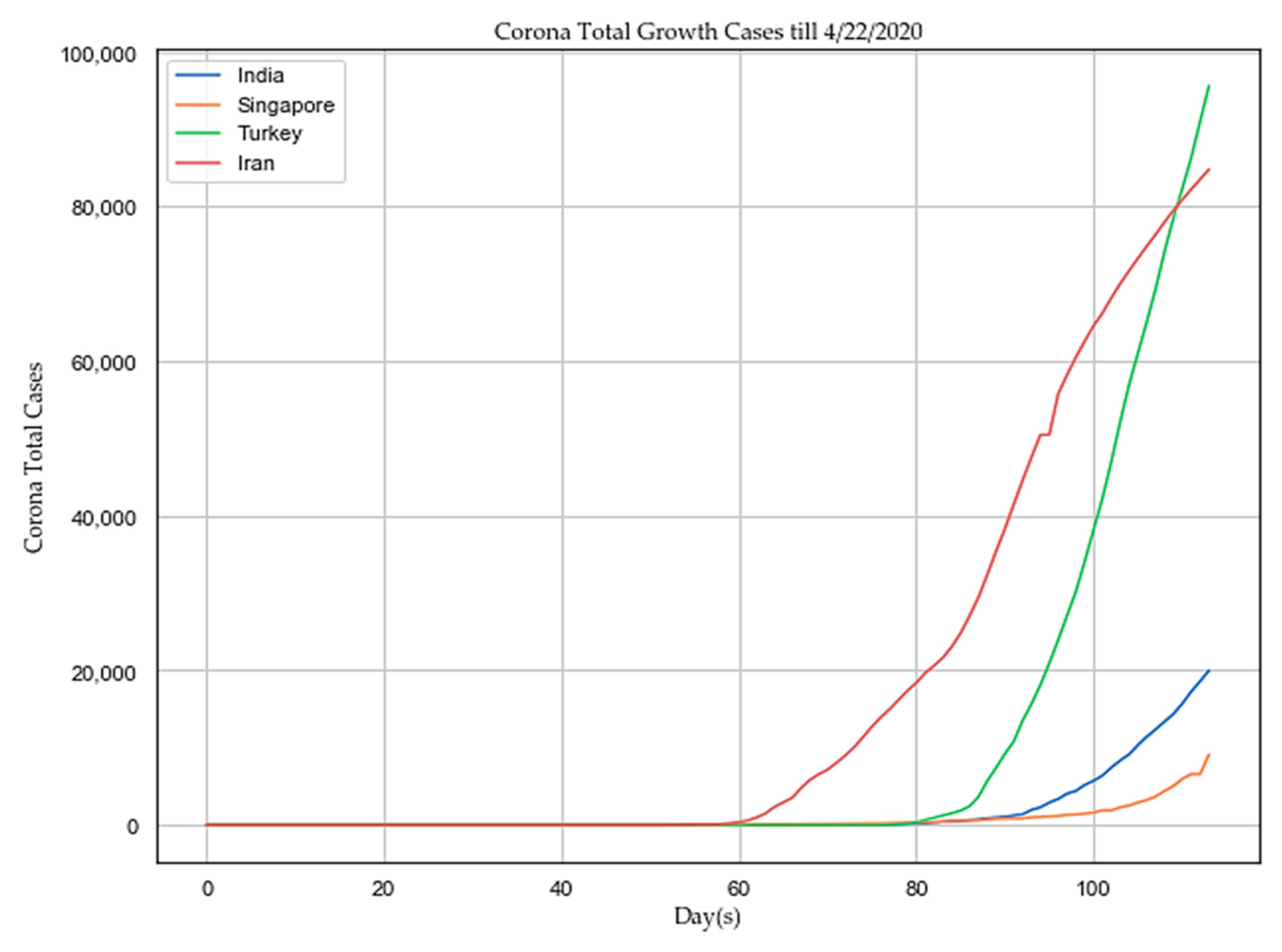
4. Results and Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wu, F.; Zhao, S.; Yu, B.; Chen, Y.-M.; Wang, W.; Song, Z.-G.; Hu, Y.; Tao, Z.-W.; Tian, J.-H.; Pei, Y.-Y.; et al. A new coronavirus associated with human respiratory disease in China. Nature 2020, 579, 265–269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Pan, B.; Ge, L. Reply to Wu et al.: Commentary on insomnia and risk of mortality. Sleep Med. Rev. 2020, 50, 101256. [Google Scholar] [CrossRef] [PubMed]
- Andersen, K.G.; Rambaut, A.; Lipkin, W.I.; Holmes, E.C.; Garry, R.F. The proximal origin of SARS-CoV-2. Nat. Med. 2020, 26, 450–452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization. COVID-19 Page; WHO: Geneva, Switzerland, 2019; Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed on 26 May 2020).
- Our World in Data (University of Oxford). Available online: https://ourworldindata.org/coronavirus-source-data (accessed on 15 May 2020).
- Yan, Y.; Shin, W.; Pang, Y.; Meng, Y.; Lai, J.; You, C.; Zhao, H.; Lester, E.; Wu, T.; Pang, C.H. The First 75 Days of Novel Coronavirus (SARS-CoV-2) Outbreak: Recent Advances, Prevention, and Treatment. Int. J. Environ. Res. Public Health 2020, 17, 2323. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Yang, X.-L.; Wang, X.-G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.-R.; Zhu, Y.; Li, B.; Huang, C.-L.; et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef] [Green Version]
- World Economic Forum Page. Available online: https://www.weforum.org/agenda/2020/04/covid-19-latest-scientific-developments?fbclid=IwAR2oTLWYnoihWa4W-vxr82uW8xgKynmQafpgDh5FEoEpHy5xmuOYDqRjNQ0 (accessed on 22 April 2020).
- Guo, Z.D.; Wang, Z.Y.; Zhang, S.F.; Li, X.; Li, L.; Li, C.; Cui, Y.; Fu, R.B.; Dong, Y.Z.; Chi, X.Y.; et al. Aerosol and Surface Distribution of Severe Acute Respiratory Syndrome Coronavirus 2 in Hospital Wards, Wuhan, China. Emerg. Infect. Dis. 2020, 26. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, Z.; Wang, Y.; Zhou, Y.; Ma, Y.; Zuo, W. Single-cell RNA expression profiling of ACE2, the putative receptor of Wuhan 2019-nCov. BioRxiv 2020. [Google Scholar] [CrossRef]
- Worldometer Page. Available online: https://www.worldometers.info/coronavirus/ (accessed on 24 May 2020).
- WHO, SARS Page. Available online: https://www.who.int/csr/sars/en/ (accessed on 22 April 2020).
- World Health Organization. Middle East Respiratory Syndrome Coronavirus (MERS-CoV). 2020. Available online: https://www.who.int/news-room/fact-sheets/detail/middle-eastrespiratory-syndrome-coronavirus-(mers-cov) (accessed on 5 February 2020).
- John Hopkins COVID-19 Research Page. Available online: https://coronavirus.jhu.edu/ (accessed on 22 April 2020).
- Nature Editorial. Calling All Coronavirus Researchers: Keep Sharing, Stay Open. Nature 2020, 578, 7. Available online: https://pubmed.ncbi.nlm.nih.gov/32020126/ (accessed on 22 April 2020). [CrossRef] [Green Version]
- Wiley Page. Available online: https://novel-coronavirus.onlinelibrary.wiley.com/ (accessed on 24 May 2020).
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Yang, Z.; Zeng, Z.; Wang, K.; Wong, S.-S.; Liang, W.; Zanin, M.; Liu, P.; Cao, X.; Gao, Z.; Mai, Z.; et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J. Thorac. Dis. 2020, 12, 165–174. [Google Scholar] [CrossRef]
- Rao, A.S.R.S.; Vazquez, J.A. Identification of COVID-19 can be quicker through artificial intelligence framework using a mobile phone–based survey when cities and towns are under quarantine. Infect. Control. Hosp. Epidemiol. 2020, 1–5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, H. Estimate the incubation period of coronavirus 2019 (COVID-19). MedRxiv 2020. [Google Scholar] [CrossRef]
- Pandey, R.; Gautam, V.; Bhagat, K.; Sethi, T. A Machine Learning Application for Raising WASH Awareness in the Times of Covid-19 Pandemic. arXiv 2020, arXiv:2003.07074. [Google Scholar]
- Li, X.; Zhao, X.; Lou, Y.; Sun, Y. Risk map of the novel coronavirus (2019-nCoV) in China: Proportionate control is needed. MedRxiv 2020. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, H.T.; Xiao, Y.; Wang, M.; Sun, C.; Liang, J.; Li, S.; Zhang, M.; Guo, Y.; Xiao, Y.; et al. Prediction of criticality in patients with severe Covid-19 infection using three clinical features: A machine learning-based prognostic model with clinical data in Wuhan. MedRxiv 2020. [Google Scholar] [CrossRef]
- Jia, L.; Li, K.; Jiang, Y.; Guo, X. Prediction and analysis of Coronavirus Disease 2019. arXiv 2020, arXiv:2003.05447. [Google Scholar]
- Randhawa, G.S.; Soltysiak, M.P.; El Roz, H.; de Souza, C.P.; Hill, K.A.; Kari, L. Machine learning using intrinsic genomic signatures for rapid classification of novel pathogens: COVID-19 case study. PLoS ONE 2020, 15, e0232391. [Google Scholar] [CrossRef] [Green Version]
- Randhawa, G.S.; Soltysiak, M.P.; El Roz, H.; De Souza, C.P.; Hill, K.A.; Kari, L. Machine learning analysis of genomic signatures provides evidence of associations between Wuhan 2019-nCoV and bat betacoronaviruses. BioRxiv 2020. [Google Scholar] [CrossRef]
- Gozes, O.; Frid-Adar, M.; Greenspan, H.; Browning, P.D.; Zhang, H.; Ji, W.; Bernheim, A.; Siegel, E. Rapid ai development cycle for the coronavirus (covid-19) pandemic: Initial results for automated detection & patient monitoring using deep learning ct image analysis. arXiv 2020, arXiv:2003.05037. [Google Scholar]
- Zhang, H.; Saravanan, K.M.; Yang, Y.; Hossain, M.T.; Li, J.; Ren, X.; Wei, Y. Deep learning based drug screening for novel coronavirus 2019-nCov. Preprints 2020. [Google Scholar] [CrossRef]
- Xu, X.; Jiang, X.; Ma, C.; Du, P.; Li, X.; Lv, S.; Yu, L.; Chen, Y.; Su, J.; Lang, G.; et al. Deep learning system to screen coronavirus disease 2019 pneumonia. arXiv 2020, arXiv:2002.09334. [Google Scholar]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Artificial Intelligence Distinguishes COVID-19 from Community Acquired Pneumonia on Chest CT. Radiology 2020, 200905. [Google Scholar] [CrossRef] [PubMed]
- Shan, F.; Gao, Y.; Wang, J.; Shi, W.; Shi, N.; Han, M.; Xue, Z.; Shen, D.; Shi, Y. Lung infection quantification of covid-19 in ct images with deep learning. arXiv 2020, arXiv:2003.04655. [Google Scholar]
- Wang, L.; Wong, A. COVID-Net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest radiography images. arXiv 2020, arXiv:2003.09871. [Google Scholar]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. arXiv 2020, arXiv:2003.10849. [Google Scholar]
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769. [Google Scholar]
- Santosh, K.C. AI-Driven Tools for Coronavirus Outbreak: Need of Active Learning and Cross-Population Train/Test Models on Multitudinal/Multimodal Data. J. Med Syst. 2020, 44, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Hu, Z.; Ge, Q.; Jin, L.; Xiong, M. Artificial intelligence forecasting of covid-19 in china. arXiv 2020, arXiv:2002.07112. [Google Scholar]
- Maghdid, H.S.; Ghafoor, K.Z.; Sadiq, A.S.; Curran, K.; Rabie, K. A novel ai-enabled framework to diagnose coronavirus covid 19 using smartphone embedded sensors: Design study. arXiv 2020, arXiv:2003.07434. [Google Scholar]
- Zhou, Y.; Hou, Y.; Shen, J.; Huang, Y.; Martin, W.; Cheng, F. Network-based drug repurposing for novel coronavirus 2019-nCoV/SARS-CoV-2. Cell Discov. 2020, 6, 14–18. [Google Scholar] [CrossRef] [Green Version]
- Gautret, P.; Lagier, J.-C.; Parola, P.; Hoang, V.T.; Meddeb, L.; Sevestre, J.; Mailhe, M.; Doudier, B.; Aubry, C.; Amrane, S.; et al. Clinical and microbiological effect of a combination of hydroxychloroquine and azithromycin in 80 COVID-19 patients with at least a six-day follow up: A pilot observational study. Travel Med. Infect. Dis. 2020, 34, 101663. [Google Scholar] [CrossRef] [PubMed]
- Duan, K.; Liu, B.; Li, C.; Zhang, H.; Yu, T.; Qu, J.; Zhou, M.; Chen, L.; Meng, S.; Hu, Y.; et al. The feasibility of convalescent plasma therapy in severe COVID-19 patients: A pilot study. MedRxiv 2020. [Google Scholar] [CrossRef]
- Moriyama, M.; Hugentobler, W.J.; Iwasaki, A. Seasonality of Respiratory Viral Infections. Annu. Rev. Virol. 2020, 7. [Google Scholar] [CrossRef] [PubMed]
- CDC, COVID-19 Page. Available online: https://www.cdc.gov/coronavirus/2019-ncov/index.html (accessed on 22 April 2020).
- LiveScience Page. Available online: https://www.livescience.com/coronavirus-six-feet-enough-social-distancing.html (accessed on 22 April 2020).
- Ogen, Y. Assessing nitrogen dioxide (NO2) levels as a contributing factor to the coronavirus (COVID-19) fatality rate. Sci. Total Environ. 2020, 138605. [Google Scholar] [CrossRef]
- Medema, G.; Heijnen, L.; Elsinga, G.; Italiaander, R.; Brouwer, A. Presence of SARS-Coronavirus-2 in sewage. MedRxiv 2020. [Google Scholar] [CrossRef]
- Gulf News Page. Available online: https://gulfnews.com/world/europe/covid-9-minuscule-traces-of-coronavirus-in-non-potable-paris-water-1.71071175 (accessed on 22 April 2020).
- Lu, J.; Gu, J.; Li, K.; Xu, C.; Su, W.; Lai, Z.; Zhou, D.; Yu, C.; Xu, B.; Yang, Z. COVID-19 Outbreak Associated with Air Conditioning in Restaurant, Guangzhou, China, 2020. Emerg. Infect. Dis. 2020, 26. [Google Scholar] [CrossRef]
- Pica, N.; Bouvier, N.M. Environmental factors affecting the transmission of respiratory viruses. Curr. Opin. Virol. 2012, 2, 90–95. [Google Scholar] [CrossRef]
- Kutter, J.S.; Spronken, M.; Fraaij, P.L.; Fouchier, R.; Herfst, S. Transmission routes of respiratory viruses among humans. Curr. Opin. Virol. 2018, 28, 142–151. [Google Scholar] [CrossRef]
- Ong, S.W.X.; Tan, Y.K.; Chia, P.Y.; Lee, T.H.; Ng, O.-T.; Wong, M.S.Y.; Marimuthu, K. Air, Surface Environmental, and Personal Protective Equipment Contamination by Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) From a Symptomatic Patient. JAMA 2020, 323, 1610. [Google Scholar] [CrossRef] [Green Version]
- Bourouiba, L. Turbulent Gas Clouds and Respiratory Pathogen Emissions: Potential Implications for Reducing Transmission of COVID-19. JAMA 2020. [Google Scholar] [CrossRef]
- AFRICA, A. Modes of Transmission of Virus Causing COVID-19: Implications for IPC Precaution Recommendations; WHO: Geneva, Switzerland, 2020. [Google Scholar]
- Van Doremalen, N.; Bushmaker, T.; Morris, D.H.; Holbrook, M.G.; Gamble, A.; Williamson, B.N.; Tamin, A.; Harcourt, J.L.; Thornburg, N.J.; Gerber, S.I.; et al. Aerosol and Surface Stability of SARS-CoV-2 as Compared with SARS-CoV-1. N. Engl. J. Med. 2020. [Google Scholar] [CrossRef] [PubMed]
- Santarpia, J.L.; Rivera, D.N.; Herrera, V.; Morwitzer, M.J.; Creager, H.; Santarpia, G.W.; Crown, K.K.; Brett-Major, D.; Schnaubelt, E.; Broadhurst, M.J.; et al. Transmission Potential of SARS-CoV-2 in Viral Shedding Observed at the University of Nebraska Medical Center. MedRxiv 2020. [Google Scholar] [CrossRef]
- Imperial College of London, COVID-19 Page. Available online: http://www.imperial.ac.uk/mrc-global-infectious-disease-analysis/covid-19/ (accessed on 22 April 2020).
- Brandt, S. Statistical and Computational Methods in Data Analysis, No. 04; QA273; North-Holland Publishing Company: Amsterdam, The Netherlands, 1976. [Google Scholar]
- Schapire Robert, E.; Freund, Y. Boosting: Foundations and algorithms. Kybernetes 2013. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- World Weather Page. Available online: https://www.weather2visit.com/ (accessed on 22 April 2020).
- Wikipedia Page. Available online: https://en.wikipedia.org/wiki/Main_Page (accessed on 22 April 2020).
- Sklearn Page. Available online: https://scikit-learn.org/stable/supervised_learning.html (accessed on 22 April 2020).
- Cheung, Y.-W.; Lai, K.S. Lag Order and Critical Values of the Augmented Dickey–Fuller Test. J. Bus. Econ. Stat. 1995, 13, 277–280. [Google Scholar]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Python Page. Available online: https://docs.python.org/ (accessed on 22 April 2020).
- Chatterjee, A.; Gerdes, M.W.; Martinez, S. eHealth Initiatives for The Promotion of Healthy Lifestyle and Allied Implementation Difficulties. In Proceedings of the 2019 IEEE International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Barcelona, Spain, 21–23 October 2019; pp. 1–8. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Size | Transmission Distance |
|---|---|---|
| 1 | Larger respiratory droplets (>5–10 μm diameter) | Travel only short distances, generally < 1 m, but in extraordinary cases up to 4 m |
| 2 | Virus-laden small (<5 μm diameter) aerosolized droplets (droplet nuclei) | Travel long distances, >1 m |
| 3 | Combinations of an individual patient’s physiology and environmental conditions, such as humidity and temperature, the gas cloud, and its payload of pathogen-bearing droplets of all sizes | Travel 7–8 m |
| 4 | Strong airflow from the air conditioner | Distance above 1 m |
| No. | Features | Description |
|---|---|---|
| 1 | Temp-Jan | Average temperature of the country in January 2020 [59] |
| 2 | Temp-Feb | Average temperature of the country in February 2020 [59] |
| 3 | Temp-Mar | Average temperature of the country in March 2020 [59] |
| 4 | Rainfall-Jan | Average rainfall of the country in January 2020 [59] |
| 5 | Rainfall-Feb | Average rainfall of the country in February 2020 [59] |
| 6 | Rainfall-Mar | Average rainfall of the country in March 2020 [59] |
| 7 | Sunshine-Jan | Average sunshine of the country in January 2020 [59] |
| 8 | Sunshine-Feb | Average sunshine of the country in February 2020 [59] |
| 9 | Sunshine-Mar | Average sunshine of the country in March 2020 [59] |
| 10 | Population | Total population of the country [60] |
| 11 | Area | Total area of the country [60] |
| 12 | Population Density | Population density of the country [60] |
| 13 | Case-Jan | Total infected cases of the country in January 2020 [5] |
| 14 | Case-Feb | Total infected cases of the country in February 2020 [5] |
| 15 | Case-Mar | Total infected cases of the country in March 2020 [5] |
| 16 | Death-Jan | Total deceased of the country in January 2020 [5] |
| 17 | Death-Feb | Total deceased of the country in February 2020 [5] |
| 18 | Death-Mar | Total deceased of the country in March 2020 [5] |
| 19 | Country | Name of the country selected for analysis |
| No | Name | External Source | Purpose | Description |
|---|---|---|---|---|
| 1 | COVID-19 datasets | www.ourworldindata.org [5] | Univariate LSTM forecasting | It is containing world-wide and country specific data, such as total cases, death, recoveries. |
| 2 | Simulated_data_1 | www.weather2visit.com [59], www.wikipedia.com [60] | For correlation analysis | It is containing features, such as external temperature, rainfall, sunshine, population, infected cases, death, country, population, area, and population density of the past three months-January, February, and March |
| 3 | Simulated_data_2 | Not available | For analyzing our proposed algorithm | Key variables used in the algorithm are as follows: days = 100, population = 200,000, days_to_recover = 10, inital_afflicted_people = 5, and spread_factor = [0.25, 0.5, 0.75, 1.0, 2.0, 3.0, 4.0, 5.0] |
| No. | Libraries | Purpose |
|---|---|---|
| 1 | Pandas | Data importing, structuring and analysis |
| 2 | NumPy | Computing with multidimensional array object |
| 3 | Matplotlib | Python 2-D plotting |
| 4 | SciPy | Statistical analysis |
| 5 | Seaborn, plotly | Plotting of high-level statistical graphs |
| 7 | Keras with TensorFlow | LSTM model development, training, and testing |
| Method | Description |
|---|---|
| Augmented Dickey-Fuller test | To test if a timeseries is stationary or non-stationary |
| |r| Value | Meaning |
|---|---|
| 0.00–0.2 | Very weak |
| 0.2–0.4 | Weak to moderate |
| 0.4–0.6 | Medium to substantial |
| 0.6–0.8 | Very strong |
| 0.8–1 | Extremely strong |
| No. | Methods | Purpose |
|---|---|---|
| 1 | Mean, standard deviation | Distribution test |
| 2 | Covariance, correlation | Association test |
| 3 | Histogram, line, bar, Scatter | Distribution plot |
| 4 | Quantile analysis | Outlier detection |
| Method | Implementation |
|---|---|
| Pickle string | Import pickle library |
| Pickled model | Import joblib from sklearn.externals library |
| “f” | Peak Active Cases | Span of Active Cases (Days) | Treatment Duration (Days) | Maximum Load (Week) | Avg Load (Patient/day) |
|---|---|---|---|---|---|
| 0.25 | 70,000–80,000 | 1–100 | 100 | 7–10 | Moderate |
| 0.50 | 140,000–160,000 | 1–50 | 50 | 4–5 | Medium |
| 0.75 | 175,000–190,000 | 1–40 | 40 | 3–4 | High |
| 1.00 | 175,000–200,000 | 1–36 | 36 | 2–4 | High |
| 2.00 | 200,000 | 1–23 | 23 | 2–3 | Very High |
| 3.00 | 200,000 | 1–19 | 19 | 2–3 | Very High |
| 4.00 | 200,000 | 1–17 | 17 | 1–2 | Very High |
| 5.00 | 200,000 | 1–18 | 18 | 1–2 | Very High |
| Timeseries Data | Test Result | Nature of Data |
|---|---|---|
| Total_deaths | ADF Statistic: −4.763,824 p-value: 0.000,064 Critical Values: 1%: −3.498 5%: −2.891 10%: −2.582 | Rejecting null hypothesis; no unit root and timeseries is stationary |
| New_deaths | ADF Statistic: −2.814,703 p-value: 0.056,204 Critical Values: 1%: −3.498 5%: −2.891 10%: −2.582 | Fail to reject null hypothesis; the data has a unit root and data is non-stationary |
| Total_cases | ADF Statistic: 5.989,246 p-value: 1.000,000 Critical Values: 1%: −3.496 5%: −2.890 10%: −2.582 | Fail to reject null hypothesis; the data has a unit root and data is non-stationary |
| New_cases | ADF Statistic: 2.771,519 p-value: 1.000000 Critical Values: 1%: −3.498 5%: −2.891 10%: −2.582 | Fail to reject null hypothesis; the data has a unit root and data is non-stationary |
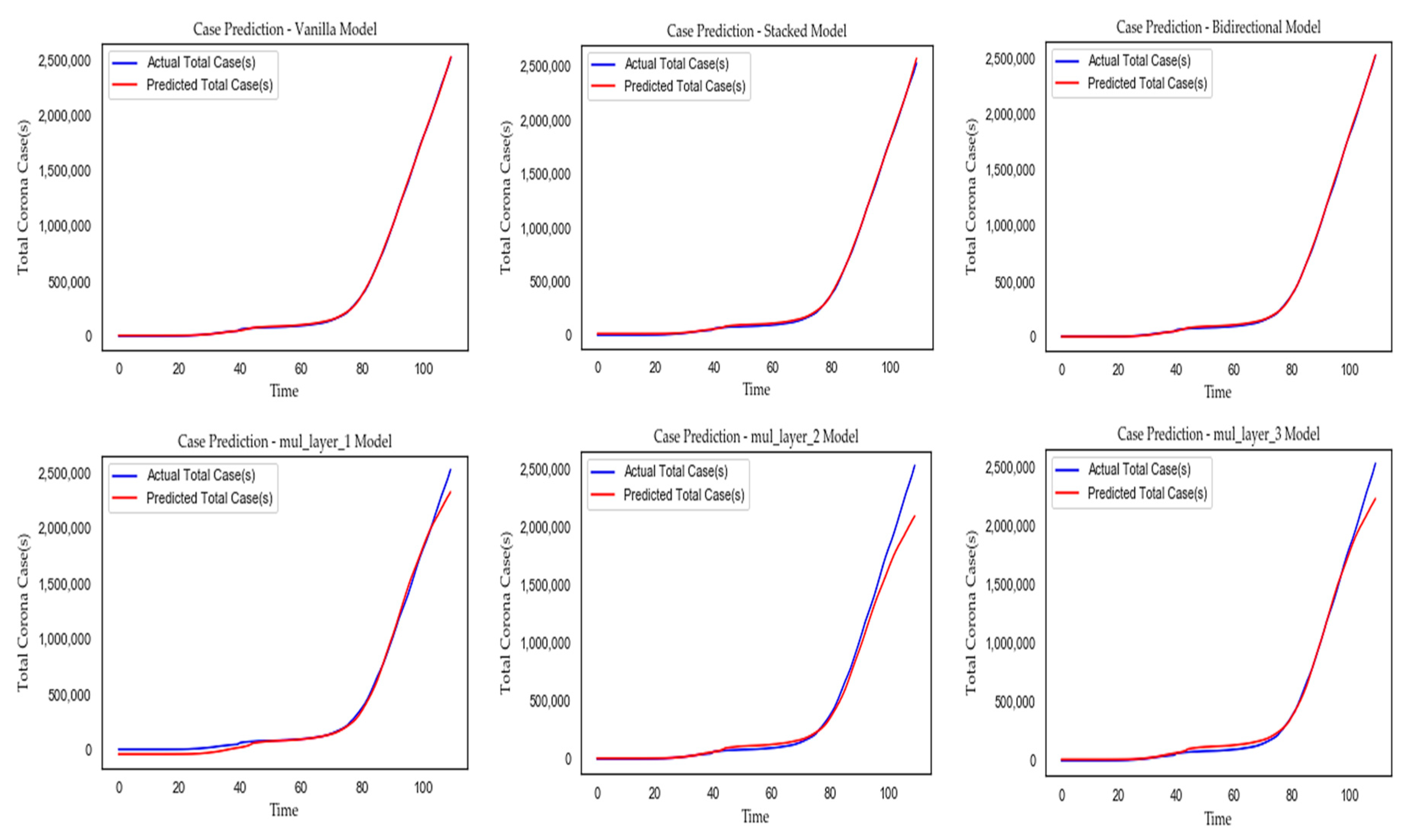
| LSTM Model(s) | MAE | MSE | RMSE | Forecast Error | |R2| | Compilation Time (ms) |
|---|---|---|---|---|---|---|
| Vanilla | 8,968.244 | 98,168,777.193 | 9,908.016 | 121.883 | 1.0 | 110.0 |
| Stacked | 6,597.784 | 82,779,520.484 | 9,098.325 | 1,120.341 | 1.0 | 192.0 |
| Bidirectional | 7,130.149 | 74,807,857.322 | 8,649.154 | 1,454.284 | 1.0 | 194.0 |
| Multi-Layer 1 | 37,438.048 | 2,338,577,178.93 | 48,358.838 | −37,075.648 | 0.995 | 520.0 |
| Multi-Layer 2 | 45,038.733 | 4,110,861,091.40 | 64,115.997 | 15,340.520 | 0.992 | 762.0 |
| Multi-Layer 3 | 51,890.187 | 10,545,625,824.0 | 102,691.898 | −45,213.395 | 0.970 | 680.0 |
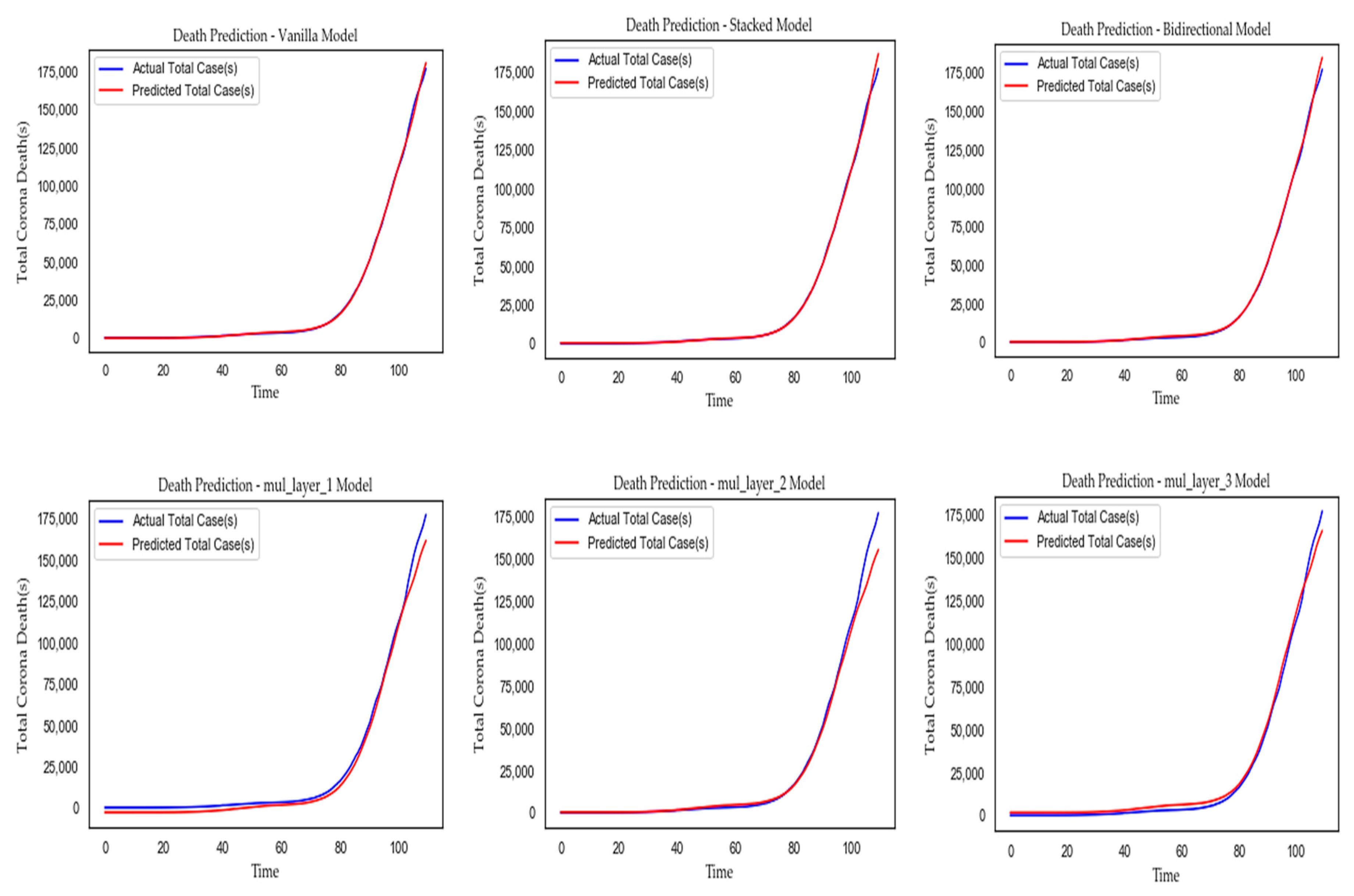
| LSTM Model(s) | MAE | MSE | RMSE | Forecast Error | |R2| | Compilation Time (ms) |
|---|---|---|---|---|---|---|
| Vanilla | 735.039 | 2,300,815.114 | 1,516.844 | −120.177 | 0.99 | 104.0 |
| Stacked | 738.703 | 4,637,553.996 | 2,153.498 | 341.605 | 0.98 | 190.0 |
| Bidirectional | 660.818 | 1,114,423.658 | 1,055.663 | 394.884 | 0.99 | 191.0 |
| Multi-Layer 1 | 3,573.872 | 30,177,345.174 | 5,493.391 | −3,573.872 | 0.983 | 400.0 |
| Multi-Layer 2 | 1,290.960 | 4,069,047.834 | 2,017.188 | −708.400 | 0.998 | 407.0 |
| Multi-Layer 3 | 3,108.016 | 52,959,914.784 | 7,277.356 | −3,033.915 | 0.966 | 400.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, A.; Gerdes, M.W.; Martinez, S.G. Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death. Sensors 2020, 20, 3089. https://doi.org/10.3390/s20113089
Chatterjee A, Gerdes MW, Martinez SG. Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death. Sensors. 2020; 20(11):3089. https://doi.org/10.3390/s20113089
Chicago/Turabian StyleChatterjee, Ayan, Martin W. Gerdes, and Santiago G. Martinez. 2020. "Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death" Sensors 20, no. 11: 3089. https://doi.org/10.3390/s20113089
APA StyleChatterjee, A., Gerdes, M. W., & Martinez, S. G. (2020). Statistical Explorations and Univariate Timeseries Analysis on COVID-19 Datasets to Understand the Trend of Disease Spreading and Death. Sensors, 20(11), 3089. https://doi.org/10.3390/s20113089