Feature Sensing and Robotic Grasping of Objects with Uncertain Information: A Review



Abstract
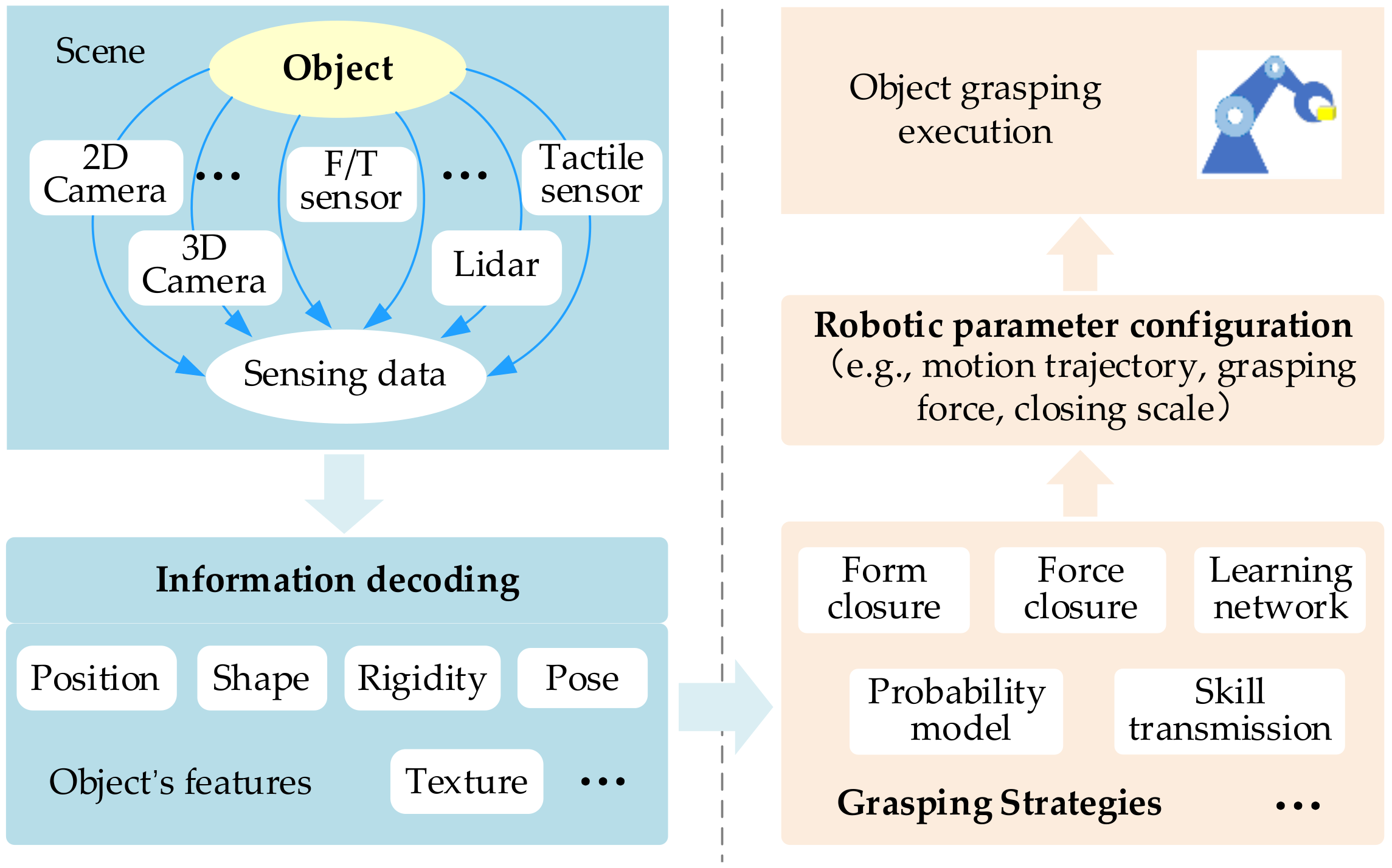
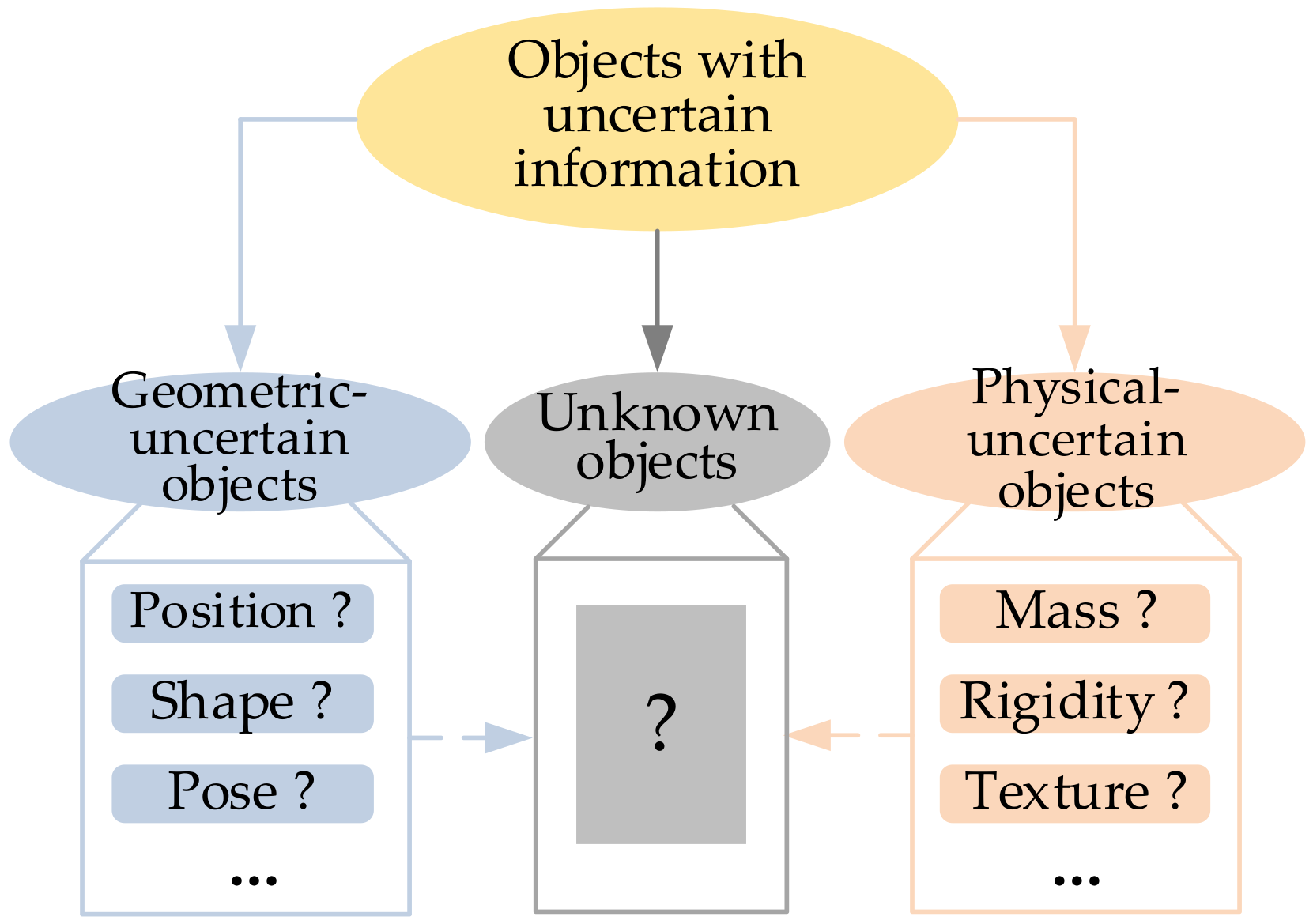
:1. Introduction
2. Geometric-Uncertain Objects
2.1. Position Detection
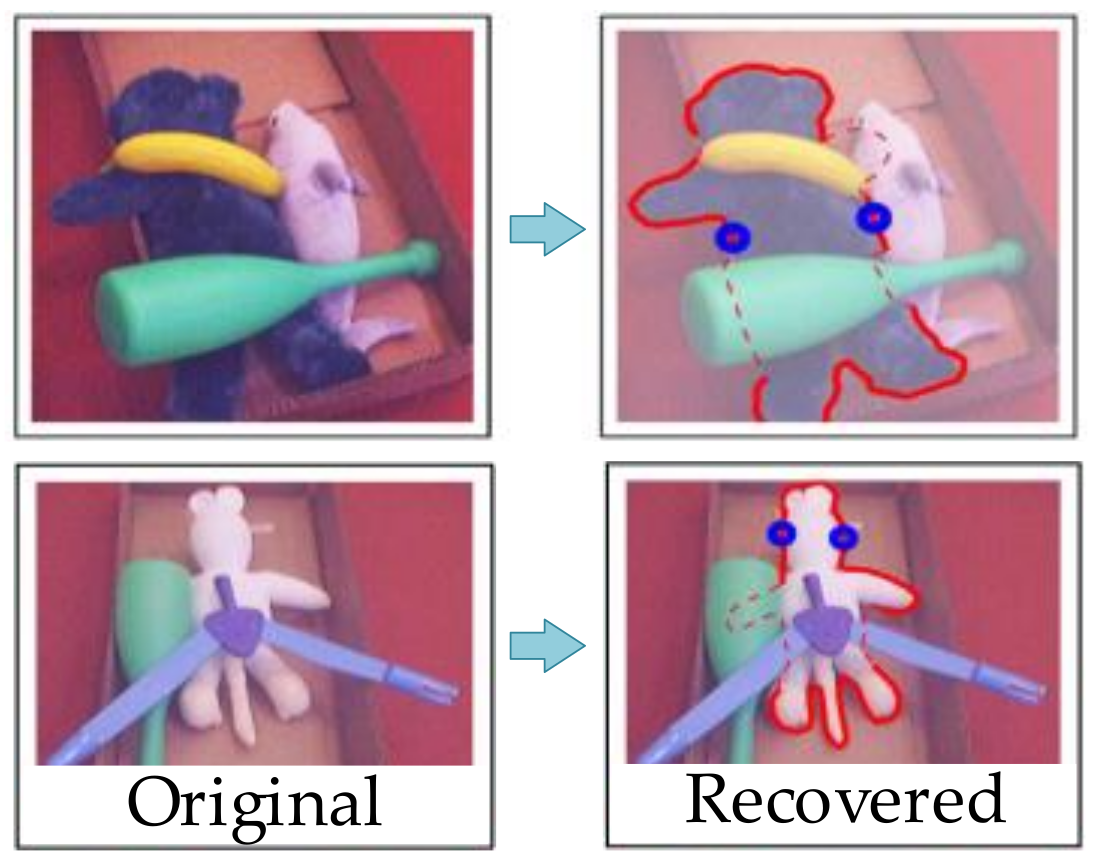
2.2. Shape Identification
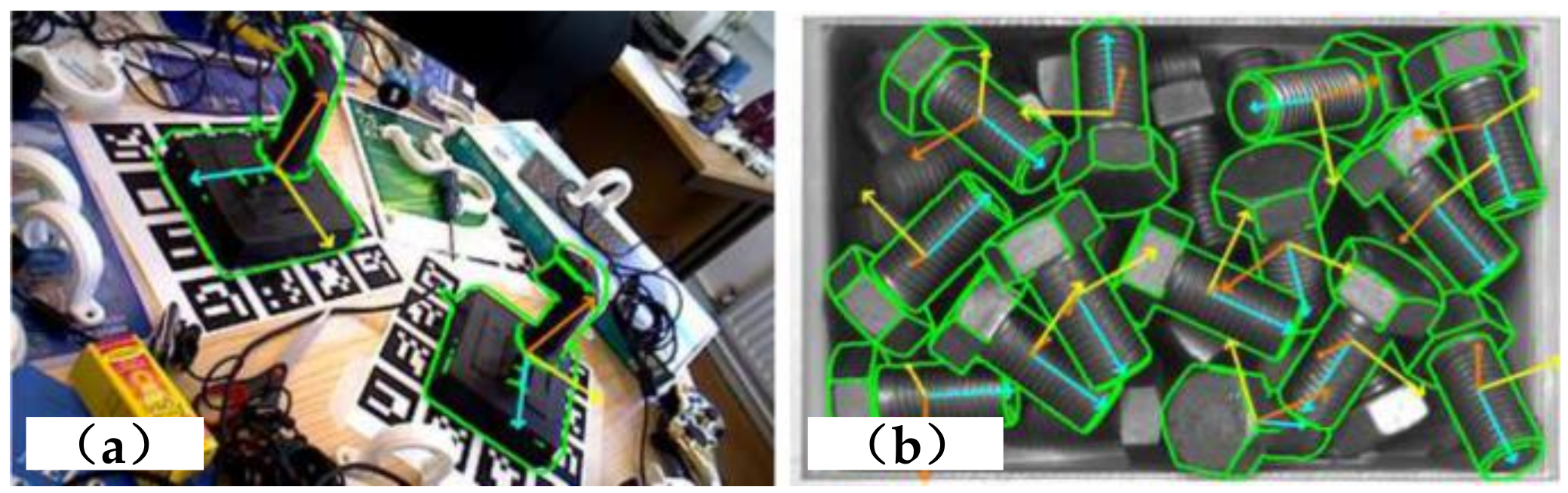
2.3. Pose Estimation
2.4. Robotic Grasping
3. Physical-Uncertain Objects
3.1. Mass Estimation
3.2. Rigidity Prediction
3.3. Texture Detection
3.4. Robotic Grasping
3.4.1. Robotic Grasping of Rigid Objects
3.4.2. Robotic Grasping of Deformable Objects
4. Unknown Objects
4.1. Search and Localization
4.2. Feature Identification
4.2.1. Pose Estimation
4.2.2. Shape Detection
4.2.3. Other Properties Identification
4.3. Robotic Grasping
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hu, L.; Miao, Y.; Wu, G.; Hassan, M.M.; Humar, I. iRobot-Factory: An intelligent robot factory based on cognitive manufacturing and edge computing. Future Gener. Comput. Syst. 2019, 90, 569–577. [Google Scholar] [CrossRef]
- Bera, A.; Randhavane, T.; Manocha, D. The Emotionally Intelligent Robot: Improving Socially-aware Human Prediction in Crowded Environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, BC, Canada, 16–20 June 2019. [Google Scholar]
- Wang, T.M.; Tao, Y.; Liu, H. Current researches and future development trend of intelligent robot: A review. Int. J. Autom. Comput. 2018, 15, 525–546. [Google Scholar] [CrossRef]
- Thanh, V.N.; Vinh, D.P.; Nghi, N.T. Restaurant Serving Robot with Double Line Sensors Following Approach. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation, Tianjin, China, 4–7 August 2019; pp. 235–239. [Google Scholar]
- Yamazaki, K.; Ueda, R.; Nozawa, S.; Kojima, M.; Okada, K.; Matsumoto, K.; Ishikawa, M.; Shimoyama, I.; Inaba, M. Home-assistant robot for an aging society. Proc. IEEE 2012, 100, 2429–2441. [Google Scholar] [CrossRef]
- Dogar, M.; Spielberg, A.; Baker, S.; Rus, D. Multi-robot grasp planning for sequential assembly operations. Auton. Robots 2019, 43, 649–664. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.D. Constructing force-closure grasps. Int. J. Robot. Res. 1988, 7, 3–16. [Google Scholar] [CrossRef]
- Ponce, J.; Faverjon, B. On computing three-finger force-closure grasps of polygonal objects. IEEE Trans. Robot. Autom. 1995, 11, 868–881. [Google Scholar] [CrossRef]
- Guo, F.; Lin, H.; Jia, Y.B. Squeeze grasping of deformable planar objects with segment contacts and stick/slip transitions. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3736–3741. [Google Scholar]
- Sanchez, J.; Corrales, J.A.; Bouzgarrou, B.C.; Mezouar, Y. Robotic manipulation and sensing of deformable objects in domestic and industrial applications: A survey. Int. J. Robot. Res. 2018, 37, 688–716. [Google Scholar] [CrossRef]
- Murray, R.M.; Li, Z.; Sastry, S.S. A Mathematical Introduction to Robotic Manipulation; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Prattichizzo, D.; Trinkle, J.C.; Siciliano, B.; Khatib, O. Springer Handbook of Robotics. In Grasping; Springer: Berlin/Heidelberg, Germany, 2008; pp. 671–700. [Google Scholar]
- Sahbani, A.; El-Khoury, S.; Bidaud, P. An overview of 3D object grasp synthesis algorithms. Robot. Auton. Syst. 2012, 60, 326–336. [Google Scholar] [CrossRef] [Green Version]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-driven grasp synthesis—A survey. IEEE Trans. Robot. 2013, 30, 289–309. [Google Scholar] [CrossRef] [Green Version]
- Caldera, S.; Rassau, A.; Chai, D. Review of deep learning methods in robotic grasp detection. Multimodal Technol. Interact. 2018, 2, 57. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Martin, E.; Del Pobil, A.P. Vision for Robust Robot Manipulation. Sensors 2019, 19, 1648. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, A.; Wadhwa, I.; Kala, R. Monocular camera based object recognition and 3d-localization for robotic grasping. In Proceedings of the International Conference on Signal Processing, Computing and Control, Waknaghat, India, 24–26 September 2015; pp. 225–229. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Farag, M.; Ghafar, A.N.A.; Alsibai, M.H. Grasping and Positioning Tasks for Selective Compliant Articulated Robotic Arm Using Object Detection and Localization: Preliminary Results. In Proceedings of the International Conference on Electrical and Electronics Engineering, Istanbul, Turkey, 16–17 April 2019; pp. 284–288. [Google Scholar]
- Shen, J.; Gans, N. Robot-to-human feedback and automatic object grasping using an RGB-D camera–projector system. Robotica 2018, 36, 241–260. [Google Scholar] [CrossRef]
- Lin, C.C.; Gonzalez, P.; Cheng, M.Y.; Luo, G.Y.; Kao, T.Y. Vision based object grasping of industrial manipulator. In Proceedings of the International Conference on Advanced Robotics and Intelligent Systems, Taipei, Taiwan, 31 August–2 September 2016; pp. 1–5. [Google Scholar]
- Alam, F.; Mehmood, R.; Katib, I. D2TFRS: An object recognition method for autonomous vehicles based on RGB and spatial values of pixels. In Proceedings of the International Conference on Smart Cities, Infrastructure, Technologies and Applications, Jeddah, Saudi Arabia, 27–29 November 2017; pp. 155–168. [Google Scholar]
- Wang, A.; Lu, J.; Cai, J.; Cham, T.J.; Wang, G. Large-margin multi-modal deep learning for RGB-D object recognition. IEEE Trans. Multimed. 2015, 17, 1887–1898. [Google Scholar] [CrossRef]
- Bo, L.; Ren, X.; Fox, D. Learning hierarchical sparse features for RGB-(D) object recognition. Int. J. Robot. Res. 2014, 33, 581–599. [Google Scholar] [CrossRef]
- Asif, U.; Bennamoun, M.; Sohel, F.A. RGB-D object recognition and grasp detection using hierarchical cascaded forests. IEEE Trans. Robot. 2017, 33, 547–564. [Google Scholar] [CrossRef] [Green Version]
- Loghmani, M.R.; Planamente, M.; Caputo, B.; Vincze, M. Recurrent convolutional fusion for RGB-D object recognition. IEEE Robot. Autom. Lett. 2019, 4, 2878–2885. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Song, W.; Sun, S.; Fong, S.; Zou, S. 3D object recognition method with multiple feature extraction from LiDAR point clouds. J. Supercomput. 2019, 75, 4430–4442. [Google Scholar] [CrossRef]
- Qin, B.; Chong, Z.J.; Soh, S.H.; Bandyopadhyay, T.; Ang, M.H.; Frazzoli, E.; Rus, D. A Spatial-Temporal Approach for Moving Object Recognition with 2d Lidar. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2016; pp. 807–820. [Google Scholar]
- Börcs, A.; Nagy, B.; Benedek, C. Instant object detection in lidar point clouds. IEEE Geosci. Remote Sens. Lett. 2017, 14, 992–996. [Google Scholar] [CrossRef] [Green Version]
- Gangineni, S.R.; Nalla, H.R.; Fathollahzadeh, S.; Teymourian, K. Real-Time Object Recognition from Streaming LiDAR Point Cloud Data. In Proceedings of the 13th ACM International Conference on Distributed and Event-based Systems, Darmstadt, Germany, 24–28 June 2019; pp. 214–219. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost: Joint appearance, shape and context modeling for multi-class object recognition and segmentation. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 1–15. [Google Scholar]
- Glover, J.; Rus, D.; Roy, N. Probabilistic models of object geometry with application to grasping. Int. J. Robot. Res. 2009, 28, 999–1019. [Google Scholar] [CrossRef]
- Chiu, H.P.; Liu, H.; Kaelbling, L.P.; Lozano-Pérez, T. Class-specific grasping of 3d objects from a single 2d image. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 579–585. [Google Scholar]
- Kalogerakis, E.; Averkiou, M.; Maji, S.; Chaudhuri, S. 3D shape segmentation with projective convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3779–3788. [Google Scholar]
- Kong, C.; Lin, C.H.; Lucey, S. Using locally corresponding CAD models for dense 3D reconstructions from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4857–4865. [Google Scholar]
- Kurenkov, A.; Ji, J.; Garg, A.; Mehta, V.; Gwak, J.; Choy, C.; Savarese, S. Deformnet: Free-form deformation network for 3d shape reconstruction from a single image. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; pp. 858–866. [Google Scholar]
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In Proceedings of the 2011 international conference on computer vision, Barcelona, Spain, 6–13 November 2011; pp. 858–865. [Google Scholar]
- Haghighi, R.; Rasouli, M.; Ahmed, S.M.; Tan, K.P.; Al–Mamun, A.; Chew, C.M. Depth-based Object Detection using Hierarchical Fragment Matching Method. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering, Munich, Germany, 20–24 August 2018; pp. 780–785. [Google Scholar]
- Konishi, Y.; Hattori, K.; Hashimoto, M. Real-time 6D object pose estimation on CPU. arXiv 2018, arXiv:1811.08588. [Google Scholar]
- Gall, J.; Yao, A.; Razavi, N.; Van Gool, L.; Lempitsky, V. Hough forests for object detection, tracking, and action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef]
- Tejani, A.; Tang, D.; Kouskouridas, R.; Kim, T.K. Latent-class hough forests for 3d object detection and pose estimation. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 462–477. [Google Scholar]
- Tejani, A.; Kouskouridas, R.; Doumanoglou, A.; Tang, D.; Kim, T.K. Latent-class hough forests for 6 DoF object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 119–132. [Google Scholar] [CrossRef] [Green Version]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Vidal, J.; Lin, C.Y.; Martí, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics, Auckland, New Zealand, 20–23 April 2018; pp. 405–409. [Google Scholar]
- Zhang, H.; Cao, Q. Fast 6D object pose refinement in depth images. Appl. Intell. 2019, 49, 2287–2300. [Google Scholar] [CrossRef]
- Georgakis, G.; Karanam, S.; Wu, Z.; Kosecka, J. Matching RGB images to CAD models for object pose estimation. arXiv 2018, arXiv:1811.07249. [Google Scholar]
- Suzhou Rochu Robotics Co. Ltd. The Exhibition of Rochu-Soft Gripper-Finger & Telescopic Sucker Combination. Available online: http://www.rorobot.cc/texingzhanshi/show/198.html (accessed on 12 October 2019).
- DH-Robotics Technology Co. Ltd. The Application Demos. Available online: http://en.dh-robotics.com/solutions/ (accessed on 12 October 2019).
- Barrett Technology. The BarrettHand Models. Available online: http://support.barrett.com/wiki/Hand (accessed on 12 October 2019).
- Shadow Robot Company. Shadow Dexterous Hand. Available online: http://www.shadowrobot.com/products/ (accessed on 12 October 2019).
- Fan, Y.; Tomizuka, M. Efficient Grasp Planning and Execution with Multifingered Hands by Surface Fitting. IEEE Robot. Autom. Lett. 2019, 4, 3995–4002. [Google Scholar] [CrossRef] [Green Version]
- Calli, B.; Wisse, M.; Jonker, P. Grasping of unknown objects via curvature maximization using active vision. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 995–1001. [Google Scholar]
- Hussain, I.; Renda, F.; Iqbal, Z.; Malvezzi, M.; Salvietti, G.; Seneviratne, L.; Gan, D.; Prattichizzo, D. Modeling and prototyping of an underactuated gripper exploiting joint compliance and modularity. IEEE Robot. Autom. Lett. 2018, 3, 2854–2861. [Google Scholar] [CrossRef]
- Psomopoulou, E.; Karashima, D.; Doulgeri, Z.; Tahara, K. Stable pinching by controlling finger relative orientation of robotic fingers with rolling soft tips. Robotica 2018, 36, 204–224. [Google Scholar] [CrossRef]
- Rosales, C.; Suárez, R.; Gabiccini, M.; Bicchi, A. On the synthesis of feasible and prehensile robotic grasps. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 550–556. [Google Scholar]
- Kubus, D.; Kroger, T.; Wahl, F.M. On-line estimation of inertial parameters using a recursive total least-squares approach. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3845–3852. [Google Scholar]
- Petković, D.; Shamshirband, S.; Iqbal, J.; Anuar, N.B.; Pavlović, N.D.; Kiah, M.L.M. Adaptive neuro-fuzzy prediction of grasping object weight for passively compliant gripper. Appl. Soft Comput. 2014, 22, 424–431. [Google Scholar] [CrossRef]
- Silva, A.; Brites, M.; Paulino, T.; Moreno, P. Estimation of Lightweight Object’s Mass by a Humanoid Robot During a Precision Grip with Soft Tactile Sensors. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing, Naples, Italy, 25–27 February 2019; pp. 344–348. [Google Scholar]
- Sundaram, S.; Kellnhofer, P.; Li, Y.; Zhu, J.Y.; Torralba, A.; Matusik, W. Learning the signatures of the human grasp using a scalable tactile glove. Nature 2019, 569, 698–702. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lines, J.A.; Tillett, R.D.; Ross, L.G.; Chan, D.; Hockaday, S.; McFarlane, N.J.B. An automatic image-based system for estimating the mass of free-swimming fish. Comput. Electron. Agric. 2001, 31, 151–168. [Google Scholar] [CrossRef]
- Bailey, D.G.; Mercer, K.A.; Plaw, C.; Ball, R.; Barraclough, H. High speed weight estimation by image analysis. In Proceedings of the New Zealand National Conference on Non Destructive Testing, Palmerston North, New Zealand, 27–29 June 2004; pp. 27–39. [Google Scholar]
- Omid, M.; Khojastehnazhand, M.; Tabatabaeefar, A. Estimating volume and mass of citrus fruits by image processing technique. J. Food Eng. 2010, 100, 315–321. [Google Scholar] [CrossRef]
- Zang, D.; Schrater, P.R.; Doerschner, K. Object rigidity and reflectivity identification based on motion analysis. In Proceedings of the International Conference on Image Processing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Drimus, A.; Kootstra, G.; Bilberg, A.; Kragic, D. Design of a flexible tactile sensor for classification of rigid and deformable objects. Robot. Auton. Syst. 2014, 62, 3–15. [Google Scholar] [CrossRef]
- Drimus, A.; Kootstra, G.; Bilberg, A.; Kragic, D. Classification of rigid and deformable objects using a novel tactile sensor. In Proceedings of the 2011 15th International Conference on Advanced Robotics, Tallinn, Estonia, 20–23 June 2011; pp. 427–434. [Google Scholar]
- Tsatsanis, M.K.; Giannakis, G.B. Object and texture classification using higher order statistics. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 733–750. [Google Scholar] [CrossRef]
- Satpathy, A.; Jiang, X.; Eng, H.L. LBP-based edge-texture features for object recognition. IEEE Trans. Image Process. 2014, 23, 1953–1964. [Google Scholar] [CrossRef] [PubMed]
- Zhong, L.; Lu, M.; Zhang, L. A direct 3D object tracking method based on dynamic textured model rendering and extended dense feature fields. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2302–2315. [Google Scholar] [CrossRef]
- Subudhi, P.; Mukhopadhyay, S. A novel texture segmentation method based on co-occurrence energy-driven parametric active contour model. Signal Image Video Process. 2018, 12, 669–676. [Google Scholar] [CrossRef]
- Luo, S.; Yuan, W.; Adelson, E.; Cohn, A.G.; Fuentes, R. Vitac: Feature sharing between vision and tactile sensing for cloth texture recognition. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 2722–2727. [Google Scholar]
- Liu, L.; Chen, J.; Fieguth, P.; Zhao, G.; Chellappa, R.; Pietikäinen, M. From BoW to CNN: Two decades of texture representation for texture classification. Int. J. Comput. Vis. 2019, 127, 74–109. [Google Scholar] [CrossRef] [Green Version]
- Saadat, M.; Nan, P. Industrial applications of automatic manipulation of flexible materials. Ind. Robot Int. J. 2002. [Google Scholar] [CrossRef]
- Aspragathos, N.A. Intelligent Robot Systems for Manipulation of Non-Rigid Objects. Solid State Phenomena Trans. Tech. Publ. Ltd. 2017, 260, 20–29. [Google Scholar] [CrossRef]
- Mueller, C.; Venicx, J.; Hayes, B. Robust robot learning from demonstration and skill repair using conceptual constraints. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 6029–6036. [Google Scholar]
- Lin, Y.; Sun, Y. Robot grasp planning based on demonstrated grasp strategies. Int. J. Robot. Res. 2015, 34, 26–42. [Google Scholar] [CrossRef]
- Welschehold, T.; Dornhege, C.; Burgard, W. Learning manipulation actions from human demonstrations. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 3772–3777. [Google Scholar]
- Van Molle, P.; Verbelen, T.; De Coninck, E.; De Boom, C.; Simoens, P.; Dhoedt, B. Learning to grasp from a single demonstration. arXiv 2018, arXiv:1806.03486. [Google Scholar]
- Gat, E.; Bonnasso, R.P.; Murphy, R. On three-layer architectures. Artif. Intell. Mob. Robots 1998, 195, 210. [Google Scholar]
- Schou, C.; Andersen, R.S.; Chrysostomou, D.; Bøgh, S.; Madsen, O. Skill-based instruction of collaborative robots in industrial settings. Robot. Comput. Integr. Manuf. 2018, 53, 72–80. [Google Scholar] [CrossRef]
- Akkaladevi, S.C.; Pichler, A.; Plasch, M.; Ikeda, M.; Hofmann, M. Skill-based programming of complex robotic assembly tasks for industrial application. Elektrotech. Inftech. 2019, 136, 326–333. [Google Scholar] [CrossRef]
- Huang, P.C.; Hsieh, Y.H.; Mok, A.K. A skill-based programming system for robotic furniture assembly. In Proceedings of the IEEE 16th International Conference on Industrial Informatics, Porto, Portugal, 18–20 July 2018; pp. 355–361. [Google Scholar]
- Herrero, H.; Moughlbay, A.A.; Outón, J.L.; Sallé, D.; de Ipiña, K.L. Skill based robot programming: Assembly, vision and Workspace Monitoring skill interaction. Neurocomputing 2017, 255, 61–70. [Google Scholar] [CrossRef]
- Lakani, S.R.; Rodríguez-Sánchez, A.J.; Piater, J. Exercising Affordances of Objects: A Part-Based Approach. IEEE Robot. Autom. Lett. 2018, 3, 3465–3472. [Google Scholar] [CrossRef]
- Song, D.; Ek, C.H.; Huebner, K.; Kragic, D. Task-based robot grasp planning using probabilistic inference. IEEE Trans. Robot. 2015, 31, 546–561. [Google Scholar] [CrossRef]
- Cavalli, L.; Di Pietro, G.; Matteucci, M. Towards affordance prediction with vision via task oriented grasp quality metrics. arXiv 2019, arXiv:1907.04761. [Google Scholar]
- Fang, K.; Zhu, Y.; Garg, A.; Kurenkov, A.; Mehta, V.; Fei-Fei, L.; Savarese, S. Learning task-oriented grasping for tool manipulation from simulated self-supervision. Int. J. Robot. Res. 2020, 39, 202–216. [Google Scholar] [CrossRef] [Green Version]
- Pastor, P.; Righetti, L.; Kalakrishnan, M.; Schaal, S. Online movement adaptation based on previous sensor experiences. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 365–371. [Google Scholar]
- Antanas, L.; Moreno, P.; Neumann, M.; de Figueiredo, R.P.; Kersting, K.; Santos-Victor, J.; De Raedt, L. Semantic and geometric reasoning for robotic grasping: A probabilistic logic approach. Auton. Robots 2019, 43, 1393–1418. [Google Scholar] [CrossRef]
- Yamakawa, Y.; Namiki, A.; Ishikawa, M.; Shimojo, M. Knotting manipulation of a flexible rope by a multifingered hand system based on skill synthesis. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 2691–2696. [Google Scholar]
- Yamakawa, Y.; Namiki, A.; Ishikawa, M. Simple model and deformation control of a flexible rope using constant, high-speed motion of a robot arm. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 2249–2254. [Google Scholar]
- Nakagaki, H.; Kitagaki, K.; Ogasawara, T.; Tsukune, H. Study of deformation and insertion tasks of a flexible wire. Proc. Int. Conf. Robot. Autom. 1997, 3, 2397–2402. [Google Scholar]
- Wang, W.; Berenson, D.; Balkcom, D. An online method for tight-tolerance insertion tasks for string and rope. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; pp. 2488–2495. [Google Scholar]
- Balkcom, D.J.; Mason, M.T. Robotic origami folding. Int. J. Robot. Res. 2008, 27, 613–627. [Google Scholar] [CrossRef]
- Elbrechter, C.; Haschke, R.; Ritter, H. Folding paper with anthropomorphic robot hands using real-time physics-based modeling. In Proceedings of the 2012 12th IEEE-RAS International Conference on Humanoid Robots, Osaka, Japan, 29 November–1 December 2012; pp. 210–215. [Google Scholar]
- Namiki, A.; Yokosawa, S. Robotic origami folding with dynamic motion primitives. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 5623–5628. [Google Scholar]
- Gopalakrishnan, K.; Goldberg, K. D-space and deform closure: A framework for holding deformable parts. IEEE Int. Conf. Robot. Autom. 2004, 1, 345–350. [Google Scholar]
- Gopalakrishnan, K.G.; Goldberg, K. D-space and deform closure grasps of deformable parts. Int. J. Robot. Res. 2005, 24, 899–910. [Google Scholar] [CrossRef]
- Jia, Y.B.; Guo, F.; Lin, H. Grasping deformable planar objects: Squeeze, stick/slip analysis, and energy-based optimalities. Int. J. Robot. Res. 2014, 33, 866–897. [Google Scholar] [CrossRef]
- Jørgensen, T.B.; Jensen, S.H.N.; Aanæs, H.; Hansen, N.W.; Krüger, N. An adaptive robotic system for doing pick and place operations with deformable objects. J. Intell. Robot. Syst. 2019, 94, 81–100. [Google Scholar] [CrossRef] [Green Version]
- Delgado, A.; Jara, C.A.; Mira, D.; Torres, F. A tactile-based grasping strategy for deformable objects’ manipulation and deformability estimation. In Proceedings of the 2015 12th International Conference on Informatics in Control, Automation and Robotics, Colmar, France, 21–23 July 2015; pp. 369–374. [Google Scholar]
- Delgado, Á.; Jara, C.A.; Torres, F.; Mateo, C.M. Control of robot fingers with adaptable tactile servoing to manipulate deformable objects. In Proceedings of the Robot 2015: Second Iberian Robotics Conference, Lisbon, Portugal, 19–21 November 2016; Springer: Cham, Switzerland, 2016; pp. 81–92. [Google Scholar]
- Howard, A.M.; Bekey, G.A. Intelligent learning for deformable object manipulation. Auton. Robots 2000, 9, 51–58. [Google Scholar] [CrossRef]
- Moore, P.; Molloy, D. A survey of computer-based deformable models. In Proceedings of the International Machine Vision and Image Processing Conference, Kildare, Ireland, 5–7 September 2007; pp. 55–66. [Google Scholar]
- Gao, M.; Jiang, J.; Zou, G.; John, V.; Liu, Z. RGB-D-based object recognition using multimodal convolutional neural networks: A survey. IEEE Access 2019, 7, 43110–43136. [Google Scholar] [CrossRef]
- Calli, B.; Caarls, W.; Wisse, M.; Jonker, P.P. Active vision via extremum seeking for robots in unstructured environments: Applications in object recognition and manipulation. IEEE Trans. Autom. Sci. Eng. 2018, 15, 1810–1822. [Google Scholar] [CrossRef]
- Li, J.K.; Hsu, D.; Lee, W.S. Act to see and see to act: POMDP planning for objects search in clutter. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 5701–5707. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 244–253. [Google Scholar]
- Hsiao, K.; Kaelbling, L.P.; Lozano-Pérez, T. Robust grasping under object pose uncertainty. Auton. Robots 2011, 31, 253. [Google Scholar] [CrossRef] [Green Version]
- Vezzani, G.; Pattacini, U.; Battistelli, G.; Chisci, L.; Natale, L. Memory unscented particle filter for 6-DOF tactile localization. IEEE Trans. Robot. 2017, 33, 1139–1155. [Google Scholar] [CrossRef]
- Kaboli, M.; Yao, K.; Feng, D.; Cheng, G. Tactile-based active object discrimination and target object search in an unknown workspace. Auton. Robots 2019, 43, 123–152. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xu, D.; Zhu, Y.; Martín-Martín, R.; Lu, C.; Li, F.F.; Savarese, S. Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3343–3352. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-time seamless single shot 6d object pose prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 292–301. [Google Scholar]
- Collet, A.; Martinez, M.; Srinivasa, S.S. The MOPED framework: Object recognition and pose estimation for manipulation. Inter. J. Robot. Res. 2011, 30, 1284–1306. [Google Scholar] [CrossRef] [Green Version]
- Ottenhaus, S.; Kaul, L.; Vahrenkamp, N.; Asfour, T. Active tactile exploration based on cost-aware information gain maximization. Int. J. Hum. Robot. 2018, 15, 1850015. [Google Scholar] [CrossRef] [Green Version]
- Matsubara, T.; Shibata, K. Active tactile exploration with uncertainty and travel cost for fast shape estimation of unknown objects. Robot. Auton. Syst. 2017, 91, 314–326. [Google Scholar] [CrossRef]
- Zhang, M.M.; Atanasov, N.; Daniilidis, K. Active end-effector pose selection for tactile object recognition through monte carlo tree search. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; pp. 3258–3265. [Google Scholar]
- Khan, F.S.; Anwer, R.M.; Van de Weijer, J.; Bagdanov, A.D.; Vanrell, M.; Lopez, A.M. Color attributes for object detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3306–3313. [Google Scholar]
- Van De Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1582–1596. [Google Scholar] [CrossRef]
- Škoviera, R.; Bajla, I.; Škovierová, J. Object recognition in clutter color images using Hierarchical Temporal Memory combined with salient-region detection. Neurocomputing 2018, 307, 172–183. [Google Scholar] [CrossRef]
- Kroemer, O.B.; Detry, R.; Piater, J.; Peters, J. Combining active learning and reactive control for robot grasping. Robot. Auton. Syst. 2010, 58, 1105–1116. [Google Scholar] [CrossRef] [Green Version]
- Johns, E.; Leutenegger, S.; Davison, A.J. Deep learning a grasp function for grasping under gripper pose uncertainty. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 4461–4468. [Google Scholar]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In Proceedings of the 2016 IEEE international conference on robotics and automation, Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar]
- Fu, X.; Liu, Y.; Wang, Z. Active Learning-Based Grasp for Accurate Industrial Manipulation. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1610–1618. [Google Scholar] [CrossRef]
- Quillen, D.; Jang, E.; Nachum, O.; Finn, C.; Ibarz, J.; Levine, S. Deep reinforcement learning for vision-based robotic grasping: A simulated comparative evaluation of off-policy methods. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21 May 2018; pp. 6284–6291. [Google Scholar]
- Berscheid, L.; Rühr, T.; Kröger, T. Improving data efficiency of self-supervised learning for robotic grasping. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 2125–2131. [Google Scholar]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Ji, S.Q.; Huang, M.B.; Huang, H.P. Robot intelligent grasp of unknown objects based on multi-sensor information. Sensors 2019, 19, 1595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koval, M.C.; Pollard, N.S.; Srinivasa, S.S. Pre-and post-contact policy decomposition for planar contact manipulation under uncertainty. Int. J. Robot. Res. 2016, 35, 244–264. [Google Scholar] [CrossRef] [Green Version]
- Torres-Jara, E.; Natale, L. Sensitive manipulation: Manipulation through tactile feedback. Int. J. Hum. Robot. 2018, 15, 1850012. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.K.; Likhachev, M. Planning for grasp selection of partially occluded objects. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 3971–3978. [Google Scholar]
- Choi, C.; Schwarting, W.; DelPreto, J.; Rus, D. Learning object grasping for soft robot hands. IEEE Robot. Autom. Lett. 2018, 3, 2370–2377. [Google Scholar] [CrossRef]
- Murali, A.; Li, Y.; Gandhi, D.; Gupta, A. Learning to Grasp without Seeing; International Symposium on Experimental Robotics; Springer: Cham, Switzerland, 2018; pp. 375–386. [Google Scholar]
- Yuan, W.; Dong, S.; Adelson, E.H. Gelsight: High-resolution robot tactile sensors for estimating geometry and force. Sensors 2017, 17, 2762. [Google Scholar] [CrossRef] [Green Version]
- Lopez, A.; Bacelar, R.; Pires, I.; Santos, T.G.; Sousa, J.P.; Quintino, L. Non-destructive testing application of radiography and ultrasound for wire and arc additive manufacturing. Addit. Manuf. 2018, 21, 298–306. [Google Scholar] [CrossRef]
- Langenberg, K.J.; Marklein, R.; Mayer, K. Ultrasonic Nondestructive Testing of Materials: Theoretical Foundations; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Chapman, D.; Thomlinson, W.; Johnston, R.E.; Washburn, D.; Pisano, E.; Gmür, N.; Zhong, Z.; Menk, R.; Arfelli, F.; Sayers, D. Diffraction enhanced x-ray imaging. Phys. Med. Biol. 1997, 42, 2015. [Google Scholar] [CrossRef] [Green Version]
- Pfeiffer, F.; Weitkamp, T.; Bunk, O.; David, C. Phase retrieval and differential phase-contrast imaging with low-brilliance X-ray sources. Nat. Phys. 2006, 2, 258–261. [Google Scholar] [CrossRef]
- Salvo, L.; Suéry, M.; Marmottant, A.; Limodin, N.; Bernard, D. 3D imaging in material science: Application of X-ray tomography. C. R. Phys. 2010, 11, 641–649. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensing | Position detection | 2D images [17,22], 3D images [23,24], Point clouds [18,25,26], Spatial-temporal feature [27,28,29,30], Sensory-fusion feature [31] |
| Shape identification | Learning-based [32], 2D boundary [33], 3D class model [34], FCNs and CRFs [35], Dense CAD model [36], DeformNet [37] | |
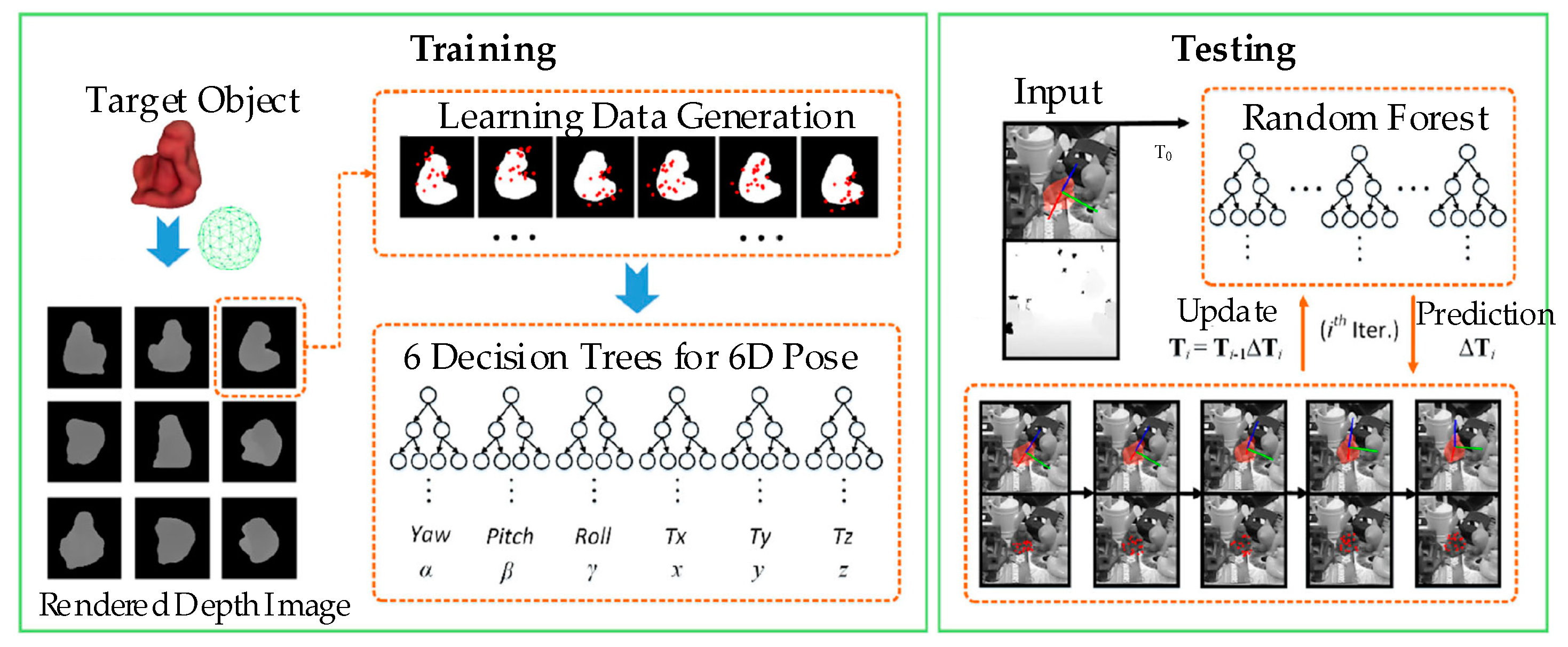
| Pose estimation | Template-based approaches (LINEMOD [38], Hierarchical fragment matching [39], PCOF-MOD template [40]); Voting-based approaches (Hough Forest [41,42,43], Point Pair Features [44,45]); Learning-based approaches (Random Forest [46], Deep quadruplet CNN [47]) | |
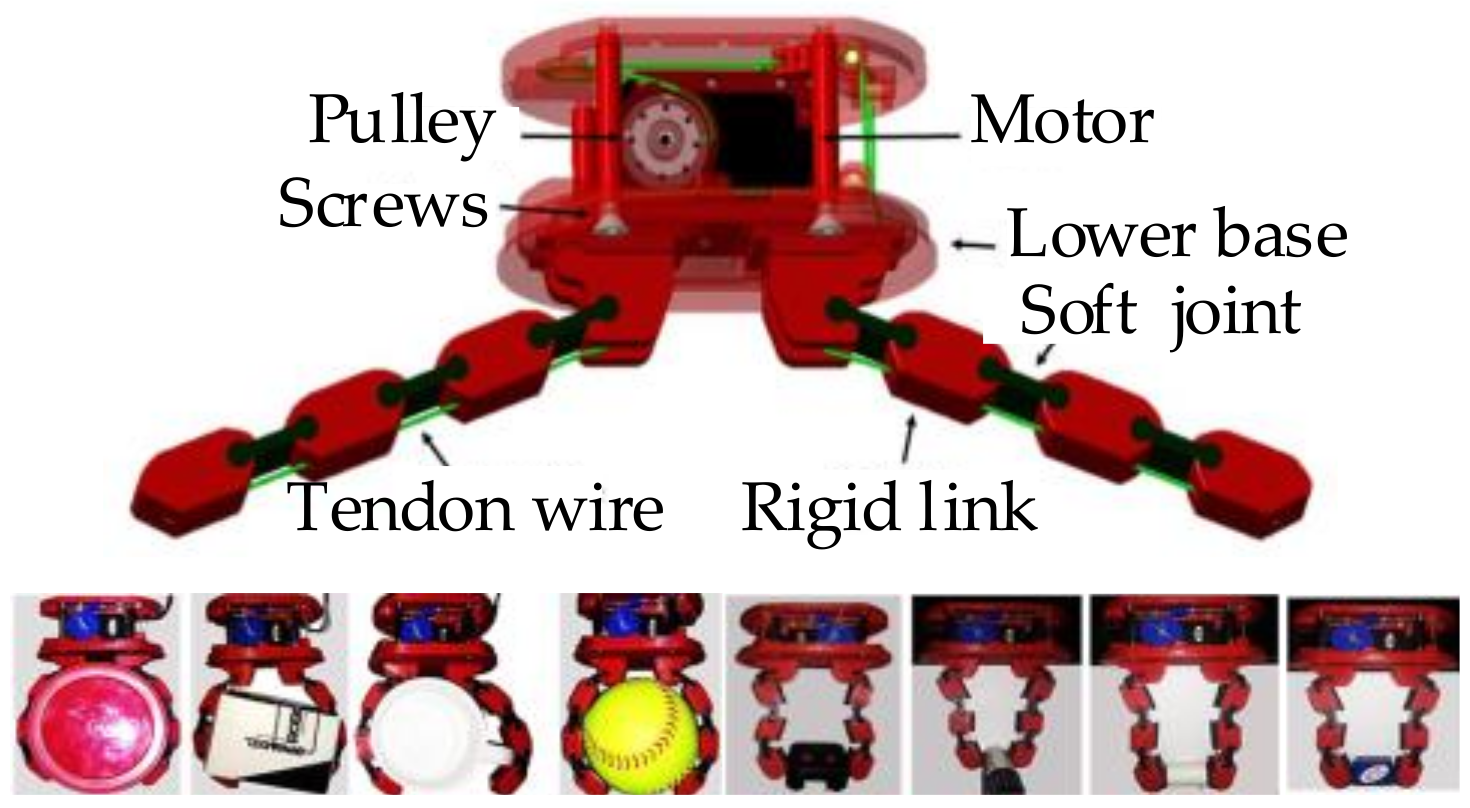
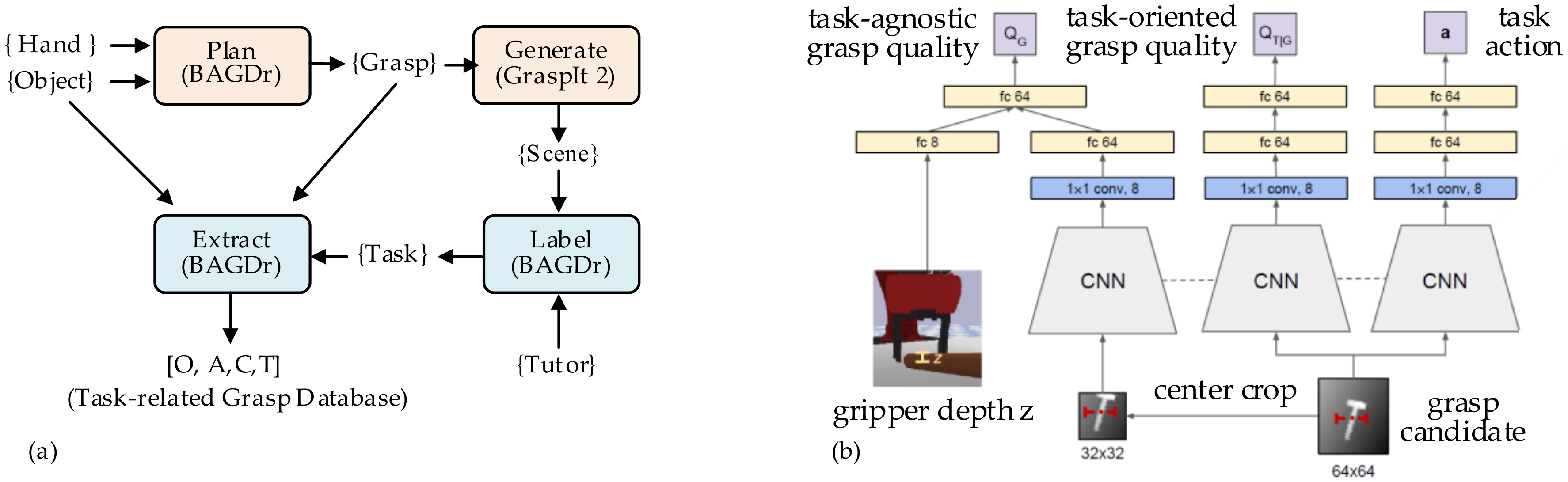
| Grasping | Direct configuration-based grasping | MDISF & GTO [52], Active vision [53], Underactuated tendon-driven [54] |
| Sensing | Mass estimation | Force and torque [57], 3D force vector [59], Deep learning and STAG [60], Geometric outline-mass model [62], Volume-mass model [63,64] |
| Rigidity prediction | Motion analysis model [65], Flexible tactile-sensor array [66,67] | |
| Texture detection | Higher order statistics [68], Edge-texture feature [69], Texture rendering model [70], Texture contour model [71], DMCA [72] | |
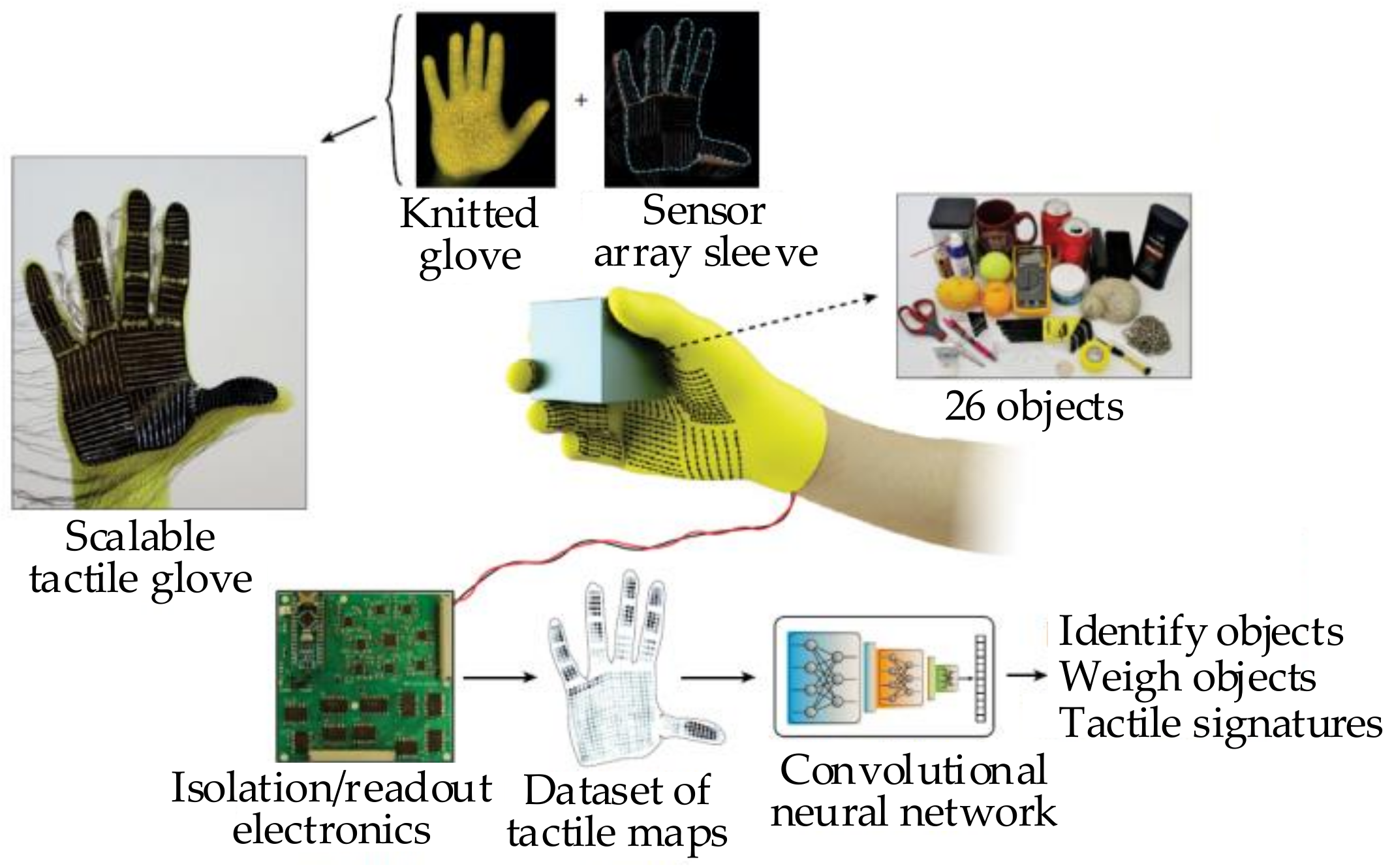
| Grasping | Rigid objects | LfD(CC-LfD [76], RGB-D observation-based demonstration [78]); Skill-based programming [80,81,82,83,84]; Task oriented-based grasping (RGB-D part-based [85], BADGr [86], TOG-Net [88]) |
| Deformable objects | Linear objects (Robotic individual skills [91], Flexible rope model [92]); Planar objects (Predefined parameter [95], Fiducial marker tracking [96], Mass–spring–damper model [97], Extended deformable model [98,99]); 3D objects (Point clouds [101], Tactile data [102,103], Kelvin–Voigt model [104], Finite-element model [105]) |
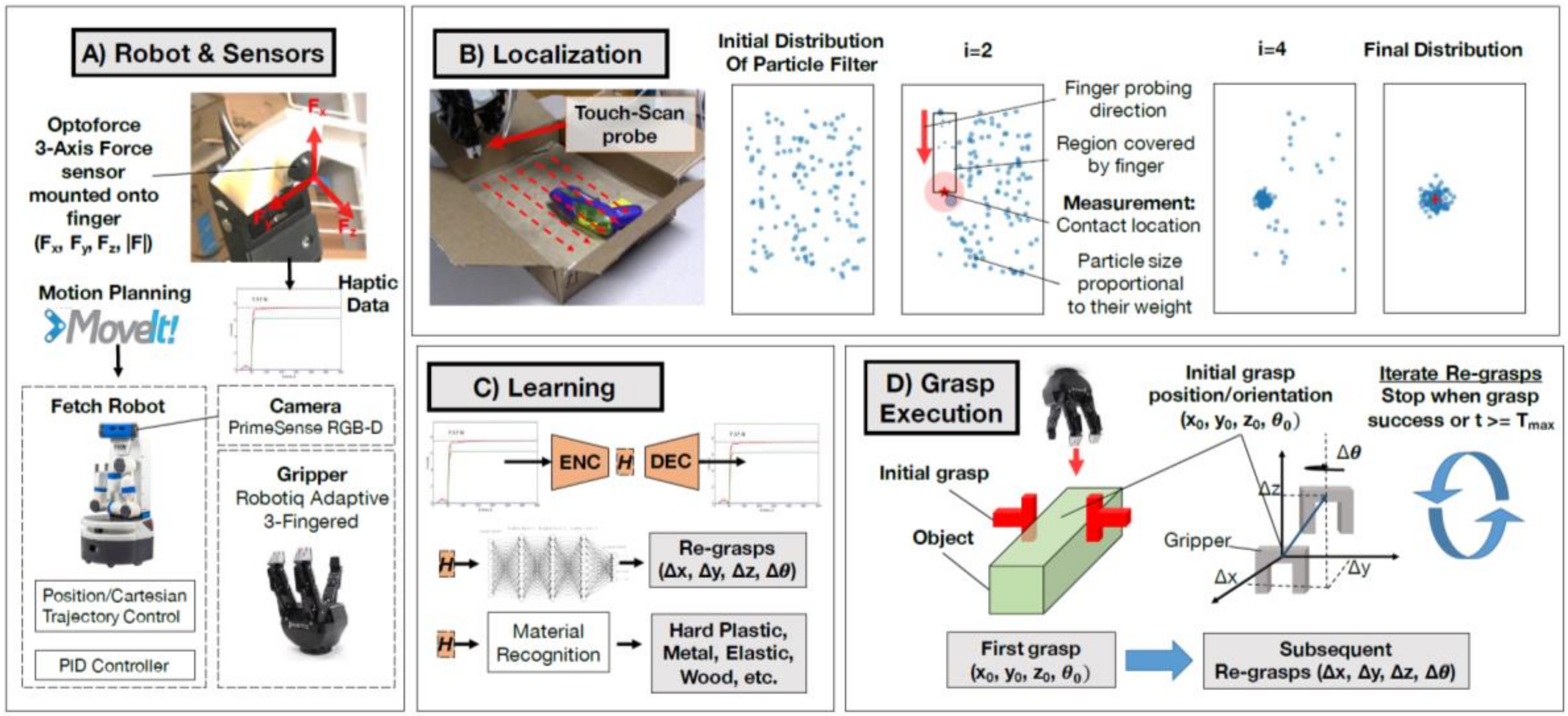
| Sensing | Search & localization | Image-based approaches (Extremum Seeking Control [107], POMDP [108]); Point cloud-based approaches (PointFusion architecture [109]); Tactile perception-based approaches (Decision-theoretic approach [110], Bayesian-based approach [111], Active exploration approach [112]) |
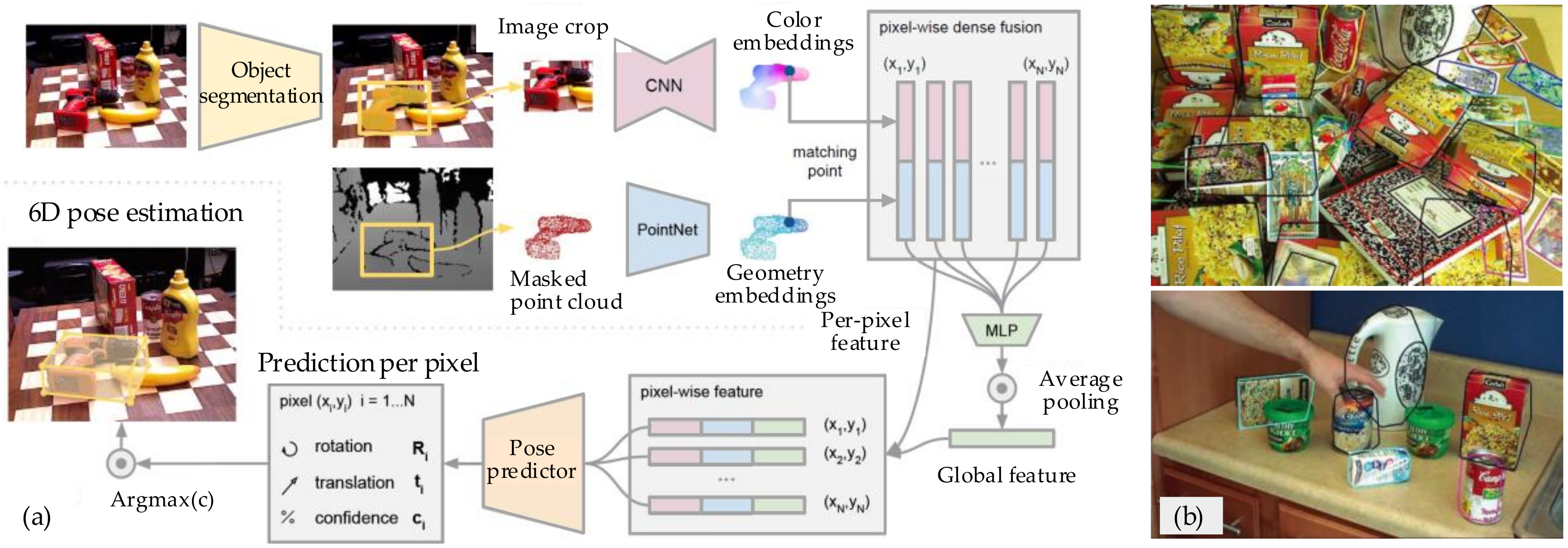
| Pose estimation | DenseFusion [113], CNN [114], MOPED [115] | |
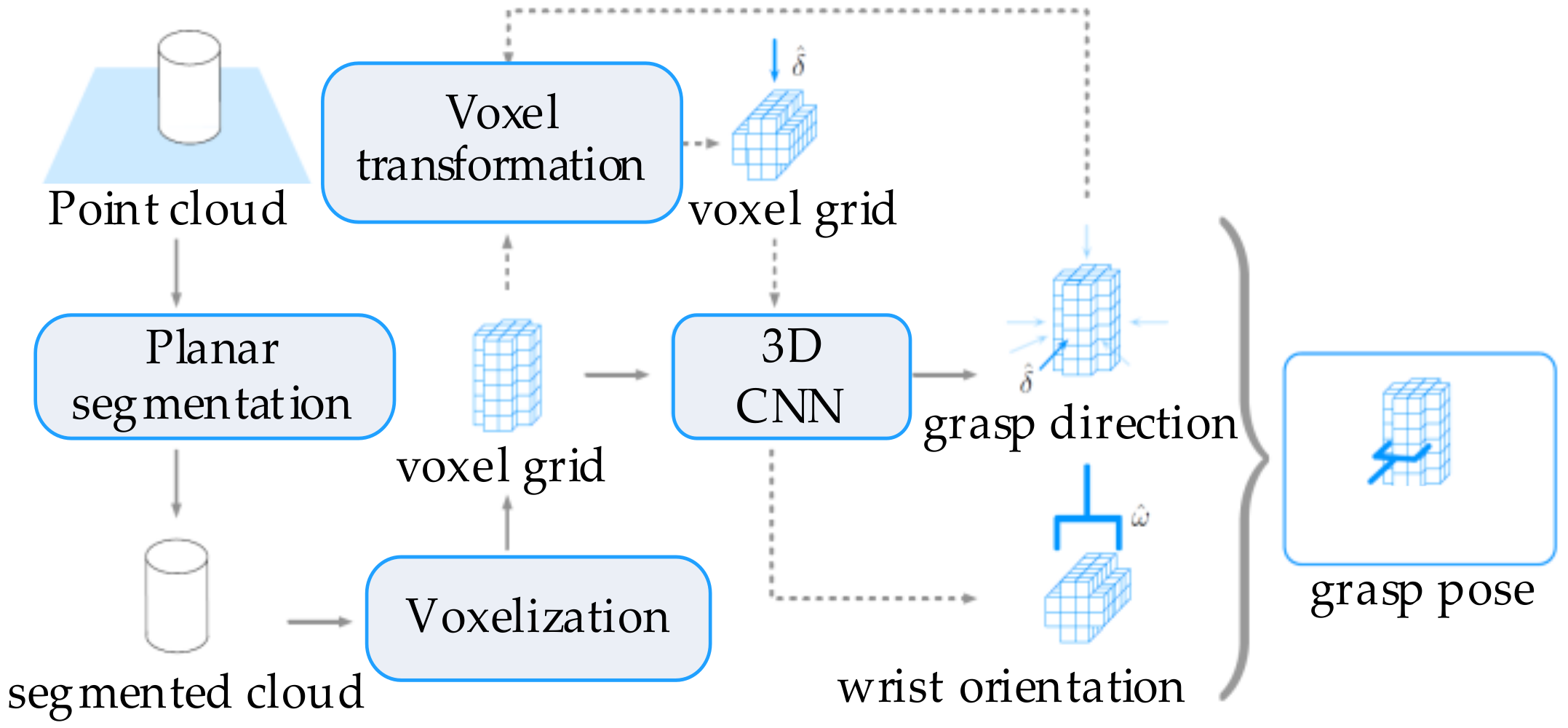
| Shape detection | Information Gain Estimation [116], Monte Carlo tree [118] | |
| Other properties identification | Color (Color descriptors [120], Hi-Erarchical Temporal Memory [121]); Mass (Approaches used for physical-uncertain objects could be extended to unknown objects); Material and Compactness (Not a very effective approach) | |
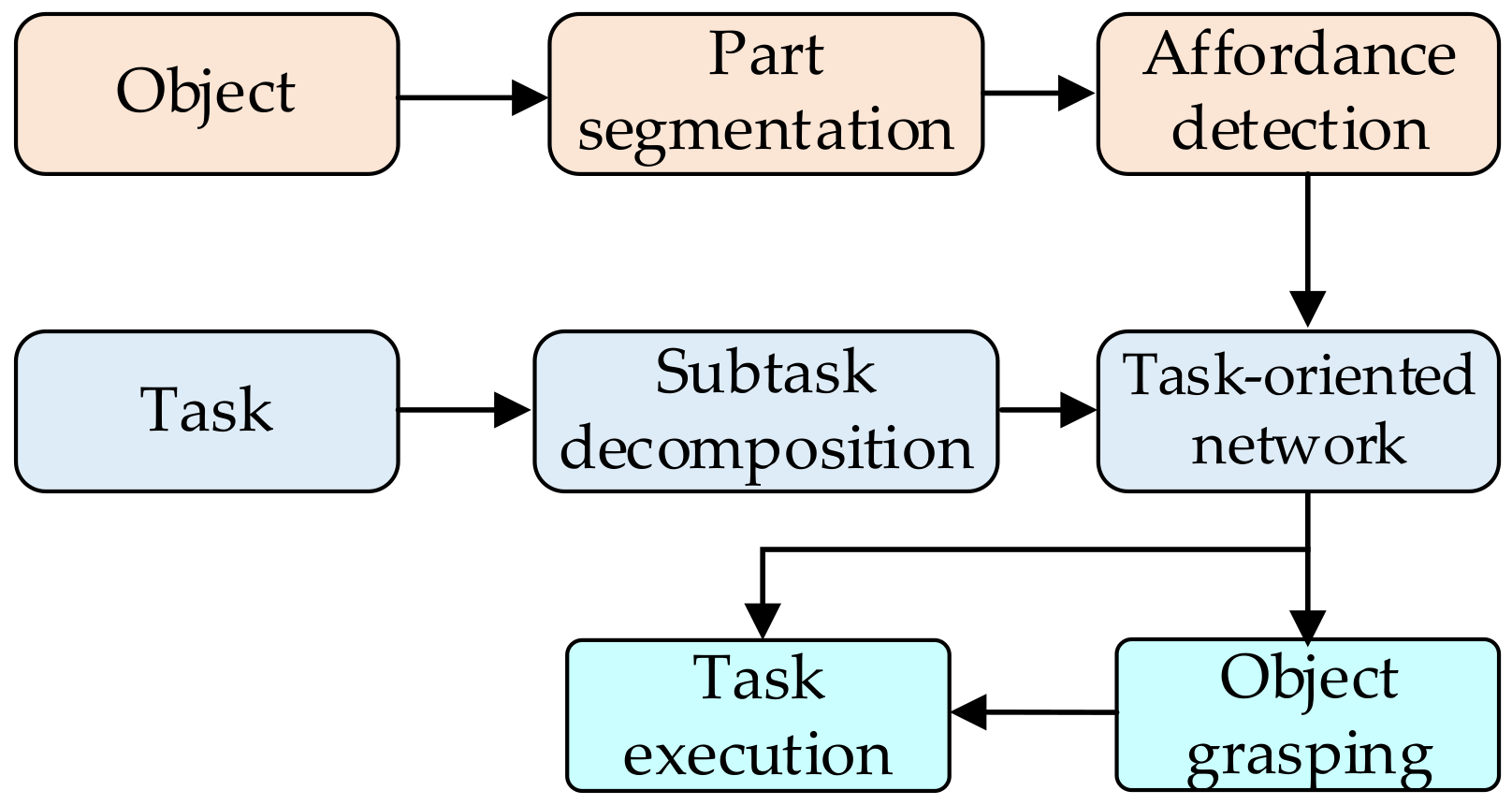
| Grasping | Learning-based grasping | Hierarchical controller [122], Active learning [125], Deep reinforcement learning [126], 3D deep CNN [133], Sensors and learning networks-based approach [134] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhang, X.; Zang, X.; Liu, Y.; Ding, G.; Yin, W.; Zhao, J. Feature Sensing and Robotic Grasping of Objects with Uncertain Information: A Review. Sensors 2020, 20, 3707. https://doi.org/10.3390/s20133707
Wang C, Zhang X, Zang X, Liu Y, Ding G, Yin W, Zhao J. Feature Sensing and Robotic Grasping of Objects with Uncertain Information: A Review. Sensors. 2020; 20(13):3707. https://doi.org/10.3390/s20133707
Chicago/Turabian StyleWang, Chao, Xuehe Zhang, Xizhe Zang, Yubin Liu, Guanwen Ding, Wenxin Yin, and Jie Zhao. 2020. "Feature Sensing and Robotic Grasping of Objects with Uncertain Information: A Review" Sensors 20, no. 13: 3707. https://doi.org/10.3390/s20133707
APA StyleWang, C., Zhang, X., Zang, X., Liu, Y., Ding, G., Yin, W., & Zhao, J. (2020). Feature Sensing and Robotic Grasping of Objects with Uncertain Information: A Review. Sensors, 20(13), 3707. https://doi.org/10.3390/s20133707