ACE: ARIA-CTR Encryption for Low-End Embedded Processors


Abstract
:1. Introduction
1.1. Contribution
1.1.1. First Efficient Implementations of ARIA on Low-End Microcontrollers
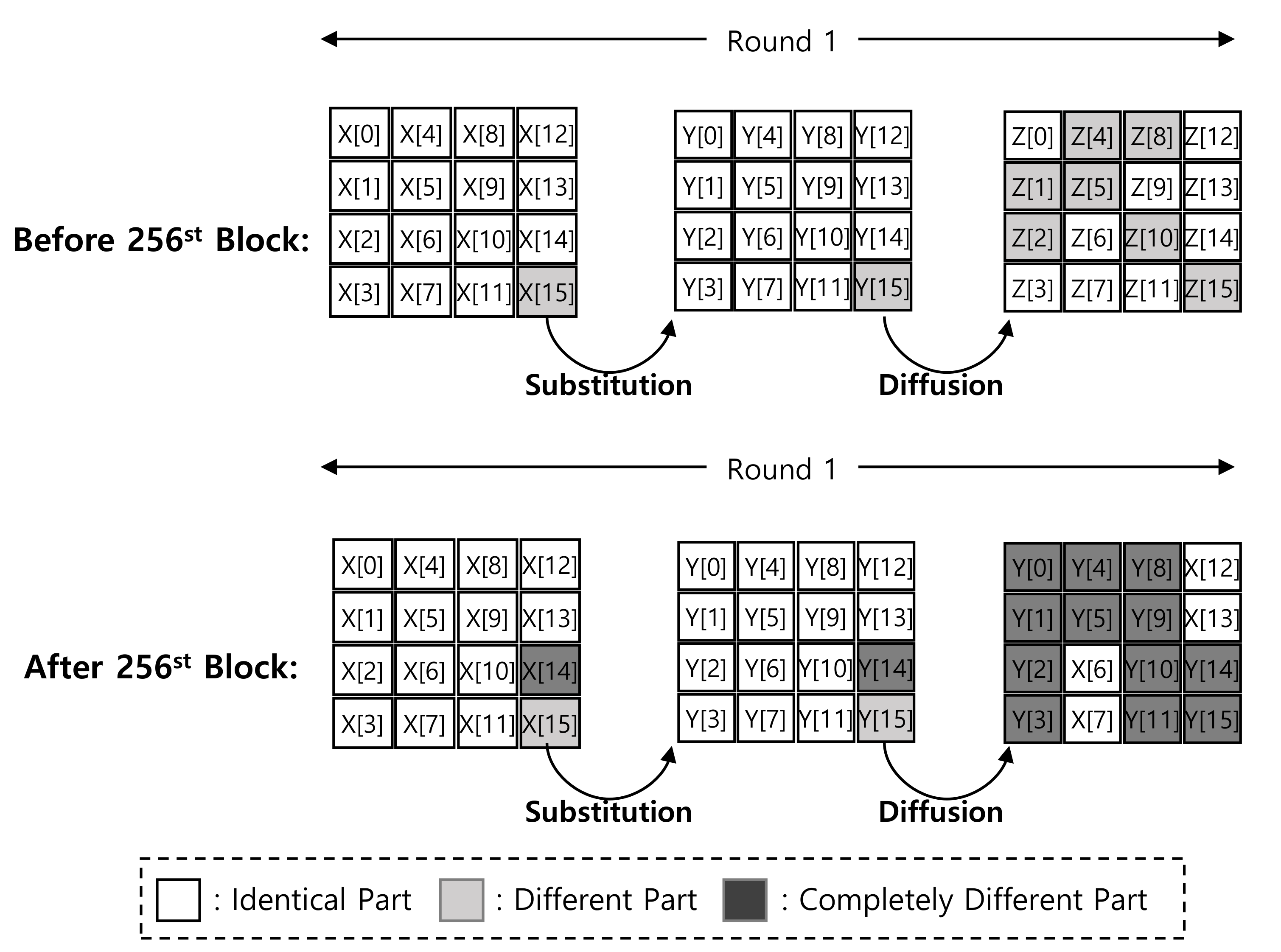
1.1.2. Optimized ARIA-CTR Encryption with Pre-Computation
2. Related Works
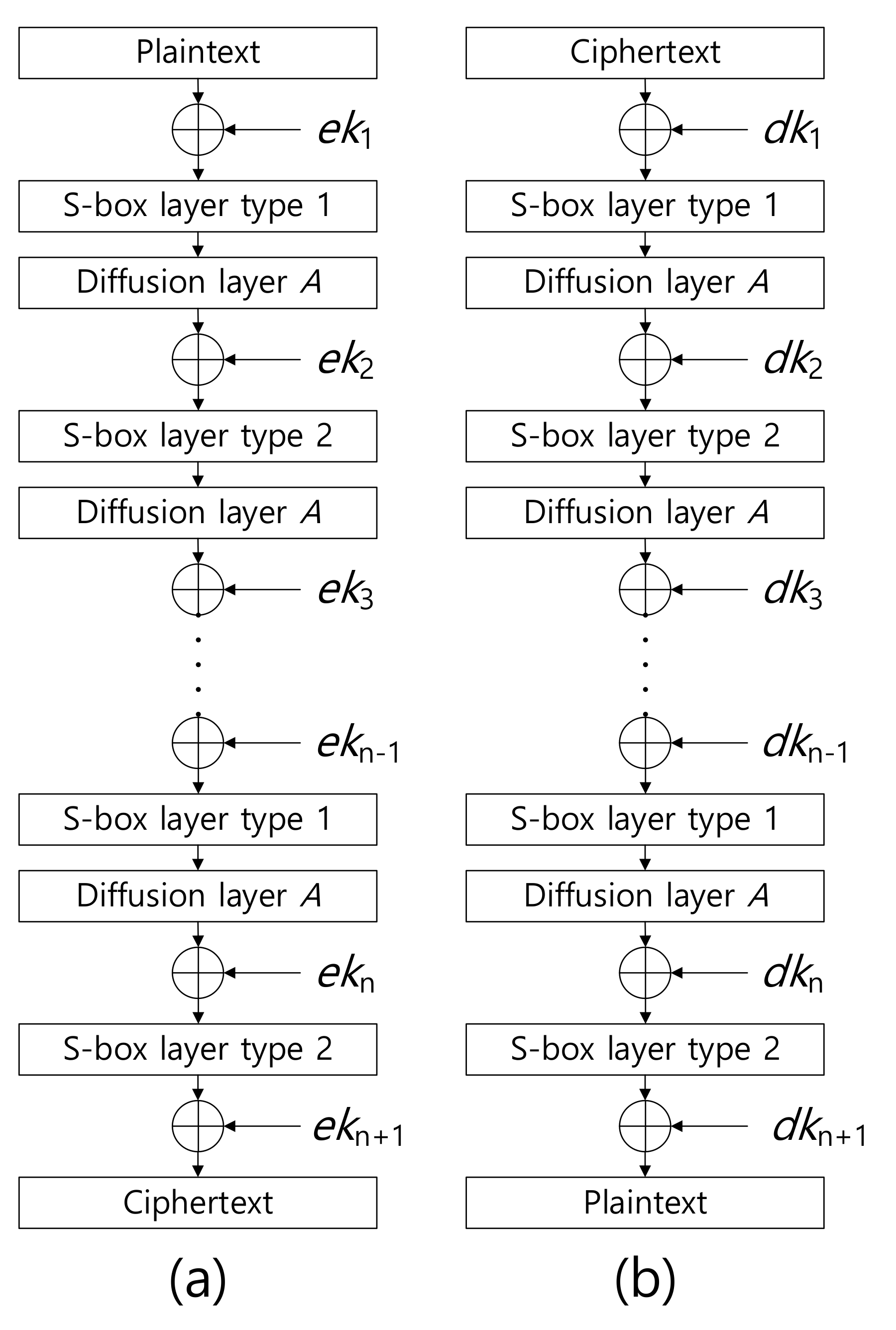
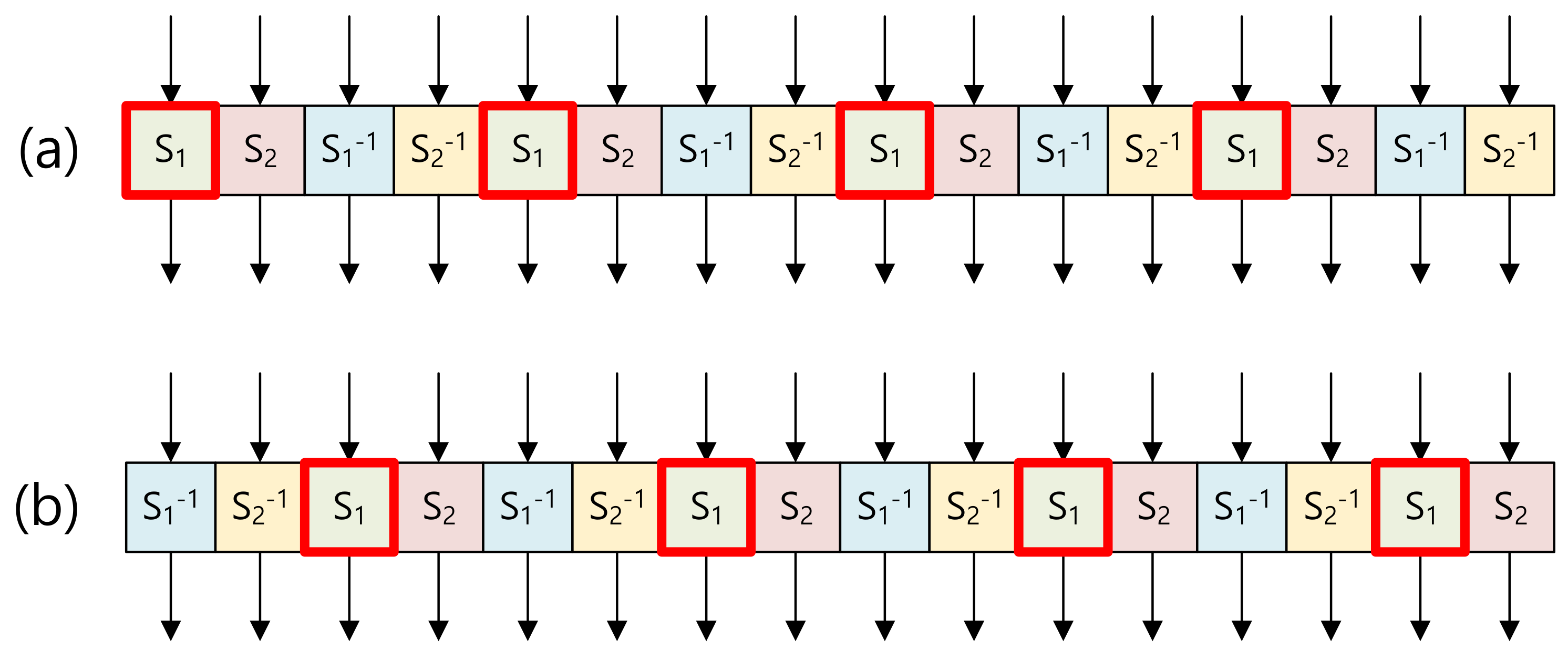
2.1. ARIA Block Cipher
2.2. Block Cipher Mode of Operation
2.3. Previous Block Cipher Implementations on 8-Bit AVR Microcontrollers
3. Proposed Methods
3.1. Efficient Implementation of ARIA-ECB
3.1.1. Key Scheduling
| Algorithm 1 Optimized four S-BOX1 accesses in a source code level. | |
| Input: Higher address of S-BOX1 SBOX1_tbl, intermediate results (reg1, reg2, reg3, reg4). | 4: MOV R30, reg2 |
| Output: Output results (reg1, reg2, reg3, reg4) | 5: LPM reg2, Z |
| 1: LDI R31, hi8(SBOX1_tbl) | 6: MOV R30, reg |
| 2: MOV R30, reg1 | 8: MOV R30, reg4 |
| 3: LPM reg1, | 9: LPM reg4, Z |
| Algorithm 2 8-bit optimized diffusion layer [6]. | |
| Input: Intermediate results (), temporal registers (, , , ) | 10: |
| Output: Output of diffusion layer(). | 11: |
| 1: | 12: |
| 2: | 13: |
| 3: | 14: |
| 4: | 15: |
| 5: | |
| 16: | |
| 6: | 17: |
| 7: | 18: |
| 8: | 19: |
| 9: | 20: |
| Algorithm 3 Proposed implementation of 8-bit optimized diffusion layer in a source code level. | ||
| Input: Intermediate results (Y0∼Y15), temporal register (Z0, Z5, Z11, Z14, Z1, Z4, Z10, Z15, TMP1, TMP2). Output: diffusion layer intermediate results (Y0∼Y15). // computation
// computation
|
// computation
// computation
|
//Finalization
|
| Algorithm 4ROR_1: 1-bit right rotation for 128-bit data. | ||
| Input: Intermediate results (reg1∼reg16) Output: 1-bit right rotated intermediate results (reg1∼reg16)
|
|
|
| Algorithm 5ROR_19: 19-bit right rotation for 128-bit data. | ||
| Input: Intermediate results (reg1∼reg16), temporal registers (tmp_reg1) Output: 19-bit right rotated intermediate results (reg1∼reg16).
|
|
|
| Algorithm 6ROL_1: 1-bit left rotation for 128-bit data. | ||
| Input: Intermediate results (reg1∼reg16), temporal register (tmp_reg). Output: 1-bit left rotated intermediate results (reg1∼reg16).
|
|
|
| Algorithm 7ROR_31: 31-bit right rotation for 128-bit data. | ||
| Input: Intermediate results (reg1∼reg16), temporal registers (tmp_reg1). Output: 31-bit right rotated intermediate results (reg1∼reg16).
|
|
|
3.1.2. Encryption & Decryption
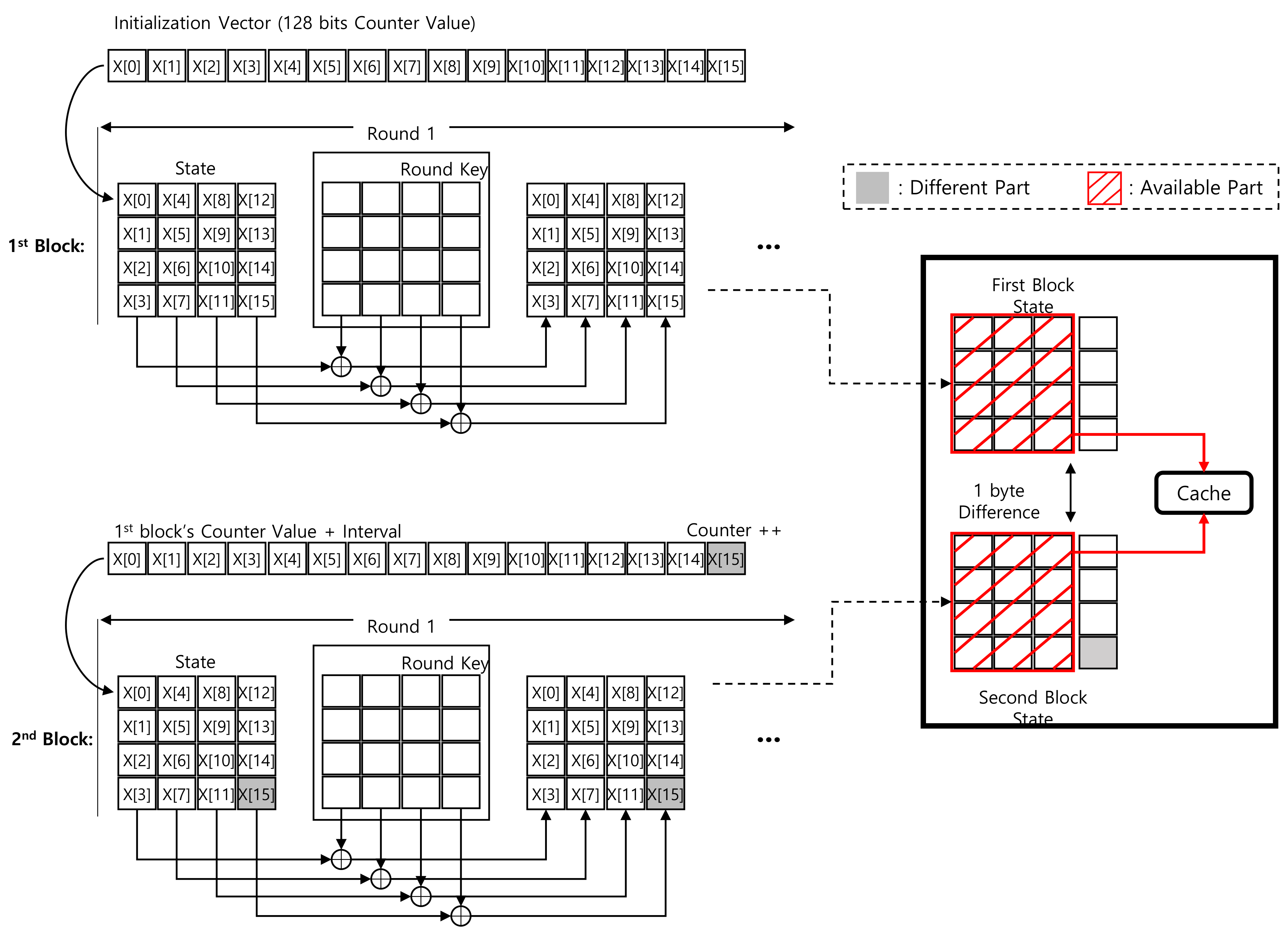
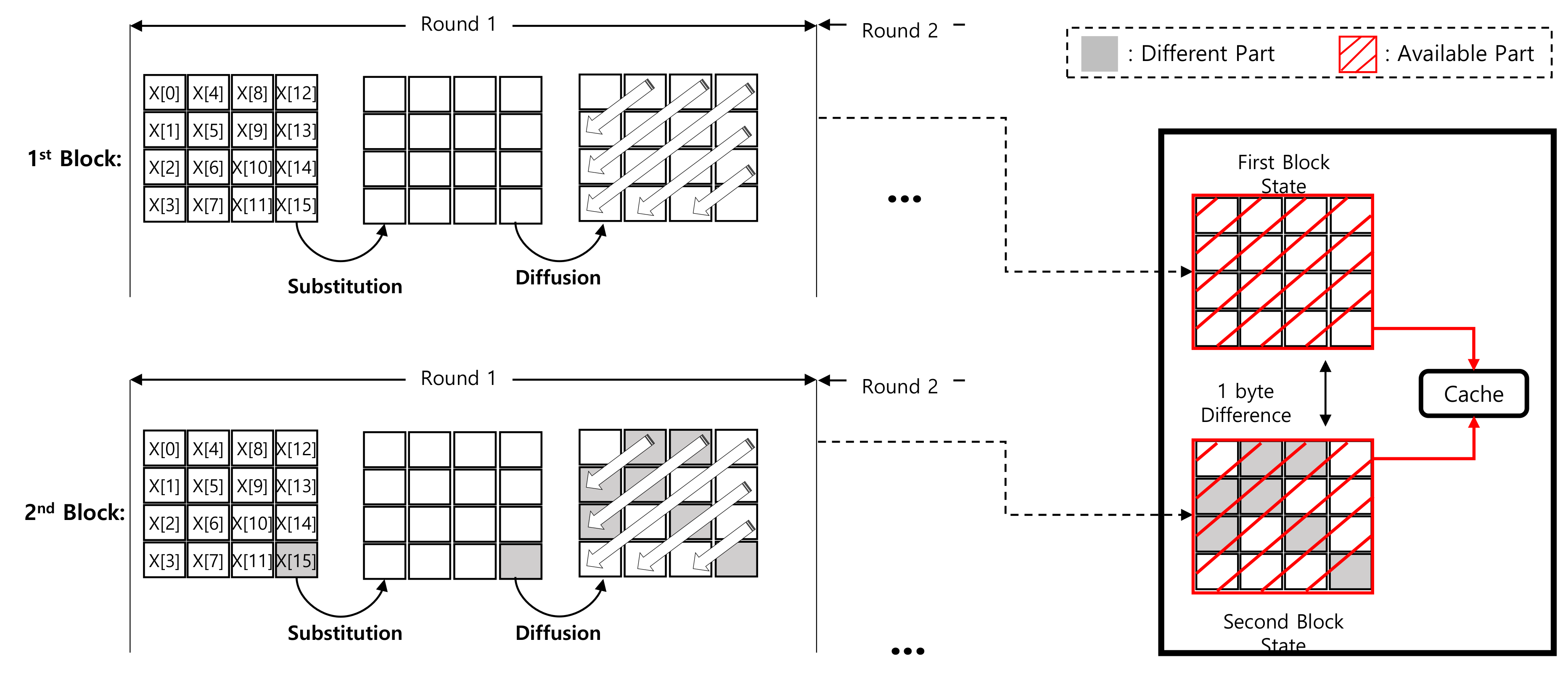
3.2. ACE: ARIA-CTR Encryption for Low-End Processors
3.2.1. Add Round Key
3.2.2. Substitution and Diffusion Layers
| Algorithm 8 Offline: LUT computations for ARIA-CTR. | |
| Input: Plaintext (), First round key (), Second round key (). Output: Pre-computed diffusion layer (), Pre-computed S-BOX ().
|
|
| Algorithm 9 Online: LUT based computations for ARIA-CTR. | ||
| Input: Plaintext (), Pre-computed diffusion layer (), Pre-computed S-BOX (). Output: Intermediate result ().
|
|
|
4. Evaluation
5. Discussion
5.1. AVR Specific Optimization
5.2. Generic Optimization
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Daemen, J.; Rijmen, V. AES Proposal: Rijndael; NIST: Gaithersburg, MD, USA, 1999. [Google Scholar]
- Standard, N.F. Announcing the advanced encryption standard (AES). Fed. Inf. Process. Stand. Publ. 2001, 197, 3. [Google Scholar]
- Osvik, D.A.; Bos, J.W.; Stefan, D.; Canright, D. Fast software AES encryption. In Proceedings of the International Workshop on Fast Software Encryption, Seoul, Korea, 13–16 February 2010; pp. 75–93. [Google Scholar]
- Kim, K.; Choi, S.; Kwon, H.; Liu, Z.; Seo, H. FACE–LIGHT: Fast AES–CTR Mode Encryption for Low-End Microcontrollers. In Proceedings of the International Conference on Information Security and Cryptology, Seoul, Korea, 4–6 December 2019; pp. 102–114. [Google Scholar]
- Park, J.H.; Lee, D.H. FACE: Fast AES CTR mode Encryption Techniques based on the Reuse of Repetitive Data. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 469–499. [Google Scholar] [CrossRef]
- Kwon, D.; Kim, J.; Park, S.; Sung, S.H.; Sohn, Y.; Song, J.H.; Yeom, Y.; Yoon, E.J.; Lee, S.; Lee, J.; et al. New block cipher: ARIA. In Proceedings of the International Conference on Information Security and Cryptology, Seoul, Korea, 27–28 November 2003; pp. 432–445. [Google Scholar]
- Mazidi, M.A.; Naimi, S.; Naimi, S. AVR Microcontroller and Embedded Systems; Pearson Education, Inc.: Harlow, UK, 2010. [Google Scholar]
- Hong, D.; Lee, J.K.; Kim, D.C.; Kwon, D.; Ryu, K.H.; Lee, D.G. LEA: A 128-bit block cipher for fast encryption on common processors. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 19–21 August 2013; pp. 3–27. [Google Scholar]
- Seo, H.; Liu, Z.; Choi, J.; Park, T.; Kim, H. Compact implementations of LEA block cipher for low-end microprocessors. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 20–22 August 2015; pp. 28–40. [Google Scholar]
- Seo, H.; Jeong, I.; Lee, J.; Kim, W.H. Compact implementations of ARX-based block ciphers on IoT processors. ACM Trans. Embed. Comput. Syst. (TECS) 2018, 17, 1–16. [Google Scholar] [CrossRef]
- Seo, H.; An, K.; Kwon, H. Compact LEA and HIGHT implementations on 8-bit AVR and 16-bit MSP processors. In Proceedings of the International Workshop on Information Security Applications, Jeju Island, Korea, 23–25 August 2018; pp. 253–265. [Google Scholar]
- Hong, D.; Sung, J.; Hong, S.; Lim, J.; Lee, S.; Koo, B.S.; Lee, C.; Chang, D.; Lee, J.; Jeong, K.; et al. HIGHT: A new block cipher suitable for low-resource device. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Yokohama, Japan, 10–13 October 2006; pp. 46–59. [Google Scholar]
- Eisenbarth, T.; Gong, Z.; Güneysu, T.; Heyse, S.; Indesteege, S.; Kerckhof, S.; Koeune, F.; Nad, T.; Plos, T.; Regazzoni, F.; et al. Compact implementation and performance evaluation of block ciphers in ATtiny devices. In Proceedings of the International Conference on Cryptology in Africa, Ifrance, Morocco, 10–12 July 2012; pp. 172–187. [Google Scholar]
- Kim, B.; Cho, J.; Choi, B.; Park, J.; Seo, H. Compact Implementations of HIGHT Block Cipher on IoT Platforms. Secur. Commun. Netw. 2019. [Google Scholar] [CrossRef]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK Families of Lightweight Block Ciphers. IACR Cryptol. Eprint Arch. 2013, 2013, 404–449. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK block ciphers on AVR 8-bit microcontrollers. In Proceedings of the International Workshop on Lightweight Cryptography for Security and Privacy, Istanbul, Turkey, 1–2 September 2014; pp. 3–20. [Google Scholar]
- McGrew, D.; Viega, J. The Galois/counter mode of operation (GCM). Submiss. NIST Modes Oper. Process 2004, 20, 10. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| asm | Operands | Description | Operation | #Clock |
|---|---|---|---|---|
| ADD | Rd, Rr | Add without Carry | Rd ← Rd+Rr | 1 |
| ADC | Rd, Rr | Add with Carry | Rd ← Rd+Rr+C | 1 |
| EOR | Rd, Rr | Exclusive OR | Rd ← Rd⊕Rr | 1 |
| LSL | Rd | Logical Shift Left | C∣Rd ← Rd<<1 | 1 |
| LSR | Rd | Logical Shift Right | Rd∣C ← 1>>Rd | 1 |
| ROL | Rd | Rotate Left Through Carry | C∣Rd ← Rd<<1C | 1 |
| ROR | Rd | Rotate Right Through Carry | Rd∣C ← C1>>Rd | 1 |
| BST | Rd, b | Bit store from Bit in Reg to T Flag | T ← Rd(b) | 1 |
| BLD | Rd, b | Bit load from T Flag to a Bit in Reg | Rd(b) ← T | 1 |
| MOV | Rd, Rr | Copy Register | Rd ← Rr | 1 |
| MOVW | Rd, Rr | Copy Register Word | Rd+1:Rd ← Rr+1:Rr | 1 |
| LDI | Rd, K | Load Immediate | Rd ← K | 1 |
| LD | Rd, X | Load Indirect | Rd ← (X) | 2 |
| LPM | Rd, Z | Load Program Memory | Rd ← (Z) | 3 |
| ST | Z, Rr | Store Indirect | (Z) ← Rr | 2 |
| PUSH | Rr | Push Register on Stack | STACK ← Rr | 2 |
| POP | Rd | Pop Register from Stack | Rd ← STACK | 2 |
| Description | Number of Registers |
|---|---|
| STACK pointer | 2 |
| Round key address pointer | 2 |
| Intermediate results pointer | 16 |
| Temporal registers | 10 |
| Description | Number of Registers |
|---|---|
| STACK pointer | 2 |
| Round key address pointer | 2 |
| Intermediate results pointer | 16 |
| Temporal registers | 10 |
| Loop counter | 1 |
| Zero constant | 1 |
| Code Size | RAM | Execution Time | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Impl. | (Bytes) | (Bytes) | (Cycles per Byte) | |||||||
| EKS | ENC | DEC | SUM | EKS | ENC | DEC | EKS | ENC | DEC | |
| ARIA-128 | ||||||||||
| Kwon et al. [6] | 2890 | 1942 | - | 3406 | 1296 | 1248 | 1248 | 1967.9 | 618.8 | 618.8 |
| This work | 5938 | 2352 | - | 8290 | 306 | 242 | 242 | 214.9 | 198.3 | 198.3 |
| This work | 5938 | 3538 | - | 9476 | 306 | 242 | - | 214.9 | 187.1 | - |
| ARIA-192 | ||||||||||
| Kwon et al. [6] | 2890 | 1942 | - | 3406 | 1336 | 1280 | 1,280 | 1494.7 | 713.3 | 713.3 |
| This work | 6194 | 2352 | - | 8546 | 346 | 274 | 274 | 158.0 | 228.0 | 228.0 |
| This work | 6194 | 3538 | - | 9732 | 346 | 274 | - | 158.0 | 216.8 | - |
| ARIA-256 | ||||||||||
| Kwon et al. [6] | 2890 | 1942 | - | 3406 | 1376 | 1312 | 1312 | 1260.3 | 807.9 | 807.9 |
| This work | 6706 | 2352 | - | 9058 | 386 | 306 | 306 | 130.1 | 257.8 | 257.8 |
| This work | 6706 | 3538 | - | 10,244 | 386 | 306 | - | 130.1 | 246.6 | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, H.; Kwon, H.; Kim, H.; Park, J. ACE: ARIA-CTR Encryption for Low-End Embedded Processors. Sensors 2020, 20, 3788. https://doi.org/10.3390/s20133788
Seo H, Kwon H, Kim H, Park J. ACE: ARIA-CTR Encryption for Low-End Embedded Processors. Sensors. 2020; 20(13):3788. https://doi.org/10.3390/s20133788
Chicago/Turabian StyleSeo, Hwajeong, Hyeokdong Kwon, Hyunji Kim, and Jaehoon Park. 2020. "ACE: ARIA-CTR Encryption for Low-End Embedded Processors" Sensors 20, no. 13: 3788. https://doi.org/10.3390/s20133788
APA StyleSeo, H., Kwon, H., Kim, H., & Park, J. (2020). ACE: ARIA-CTR Encryption for Low-End Embedded Processors. Sensors, 20(13), 3788. https://doi.org/10.3390/s20133788