1. Introduction
Accurate area and change of cultivated land is one of the fundamental types of data for precision agriculture, food security analysis, yields forecasting, and land-use/land-cover research [
1]. In the arid and semi-arid regions, this information is particularly important as it is related to the regional water balance and the local ecosystem health [
2]. Currently, the increasing free remote sensing data (such as U.S. Geological Survey (USGS) Landsat and European Space Agency (ESA) Sentinel) provides sufficient data sources and the opportunity to extract and monitor the dynamic change of the cultivated land [
3,
4,
5].
However, the cultivated land, as a man-made concept, usually shows different spectral characteristics due to the varying types of crops, different irrigation methods, and different soil types, as well as fallow land plots. As a result, for classification, the intra-class variation increases and the inter-class separability decreases [
6,
7]. The frequently used traditional pixel-based classifiers, such as support vector machine (SVM), K-nearest neighbors (KNN), and random forest (RF) [
8,
9], and the object-based farmland extraction models, such as the stratified object-based farmland extraction [
6], the superpixels and supervised machine-learning model [
10], and the time-series-based methods [
11], usually require the prior knowledge to model the high intra-class variation of the spatial or spectral features. Due to this, the features learned by these methods are often limited to the specific datasets, time, and locations, which is known as limited model generalization ability. The re-training process is usually required when applying these models to different datasets, time, and locations.
With the rapid development of deep learning [
12], convolutional neural networks (CNNs) have gained state-of-the-art performance in land cover classification, which overcomes the abovementioned difficulties [
13]. Possible reasons for its success include: (1) the capacity of learning from a large dataset; (2) the tolerance for larger intra-class variation of the object features; and (3) the high generalization ability. Benefitting from the large training dataset, the feature variation of the target object across different locations or time can be modeled. CNNs have shown great advantage in urban land use and land cover mapping [
14,
15,
16,
17,
18], scene classification [
19,
20,
21], and object extraction [
22,
23,
24,
25]. Among the popular CNNs, the U-Net is reported to achieve state-of-the-art performance on several benchmark datasets even with limited training data [
26,
27]. It was widely used in many fields as a result.
However, the “pooling” process in most deep convolutional networks, which (1) provides the invariance (translation, rotation, and scale-invariance) capacity for the model to capture the major feature of the target; (2) reduces the number of parameters for multi-scale training; and (3) increases the receptive field by involving the down-sampling process (converting images from the high to low spatial resolution) with certain calculation (maximum, average, etc.), leads to significant detail loss from the image, including edges, gradients, and image texture details [
28,
29]. This problem could decrease the accuracy of extraction of land cover type even more when dealing with remote sensing images considering the high intra-class spectral variation [
30]. Ideas to solve this problem can currently be organized in two categories: (1) learning and recovering high-resolution details from low-resolution feature maps or (2) maintaining high-resolution details throughout the network [
31].
In the first category, the detailed texture is recovered from the low-resolution feature maps after the pooling process by applying certain up-sampling methods (such as bilinear interpolation or deconvolution) [
32,
33,
34] of the representative model in this category, such as the fully convolutional network (FCN) [
35], In SegNet [
36], DeconvNet [
37], RefineNet [
38] et al.
For remotely sensed images, this idea was widely used. For instance, the FCN-based network achieved an overall accuracy of 89.1% on the International Society for Photogrammetry and Remote Sensing (ISPRS) Vaihingen Dataset without a down-sampling layer to obviate deconvolution in the latter part of the structure [
39]. Marmanis, et al. (2016) designed a segmentation network at the pixel-level that synthesized the FCN and deconvolution layers and refined the results using fully connected conditional random fields (CRF) [
40]. ASPP-Unet and ResASPP-Unet recovered the spatial texture by adding the Atrous Spatial Pyramid Pooling (ASPP) technique in network to increase the effective field-of-view in convolution and capture the features in multiple scales [
41]. MultiResoLCC provides a two-branch CNN architecture to improve the image details by jointly using panchromatic (PAN) and multi spectral (MS) imagery [
42]. For hyperspectral image classification tasks, the CNN structure can also improve the accuracy by extracting the hierarchical features [
43] and creating the low-dimensional feature space to increase the separability [
44].
This type of method recovers the high-resolution details by learning from low-resolution feature maps. Although various skip connection methods have been used to optimize the obtained high-resolution details, the effect is limited since the lost details are usually recovered only from low-spatial resolution features. This often causes the recovering procedural to be ill-posed as the number of pixels of the output is always bigger than that of the input.
In the second category, high-resolution details are first extracted and maintained through the whole process, typically by a network that is formed by connecting multi-level convolutions with repeated information exchange across parallel convolutions. Under this idea, the skip connection is usually redesigned between the pooling nodes and the up-sampling nodes. For instance, (1) adding more skip connections to link different convolution nodes at the same scale, and (2) adding more skip connections to link the convolution nodes at the different scales. Representative models include convolutional neural fabrics [
45], interlinked CNNs [
46], and high-resolution networks (HRNet) [
47]. This kind of method avoids the ill-posed problem; however, the time consumed in the training process can dramatically increase. More free parameters in the model require more data to train.
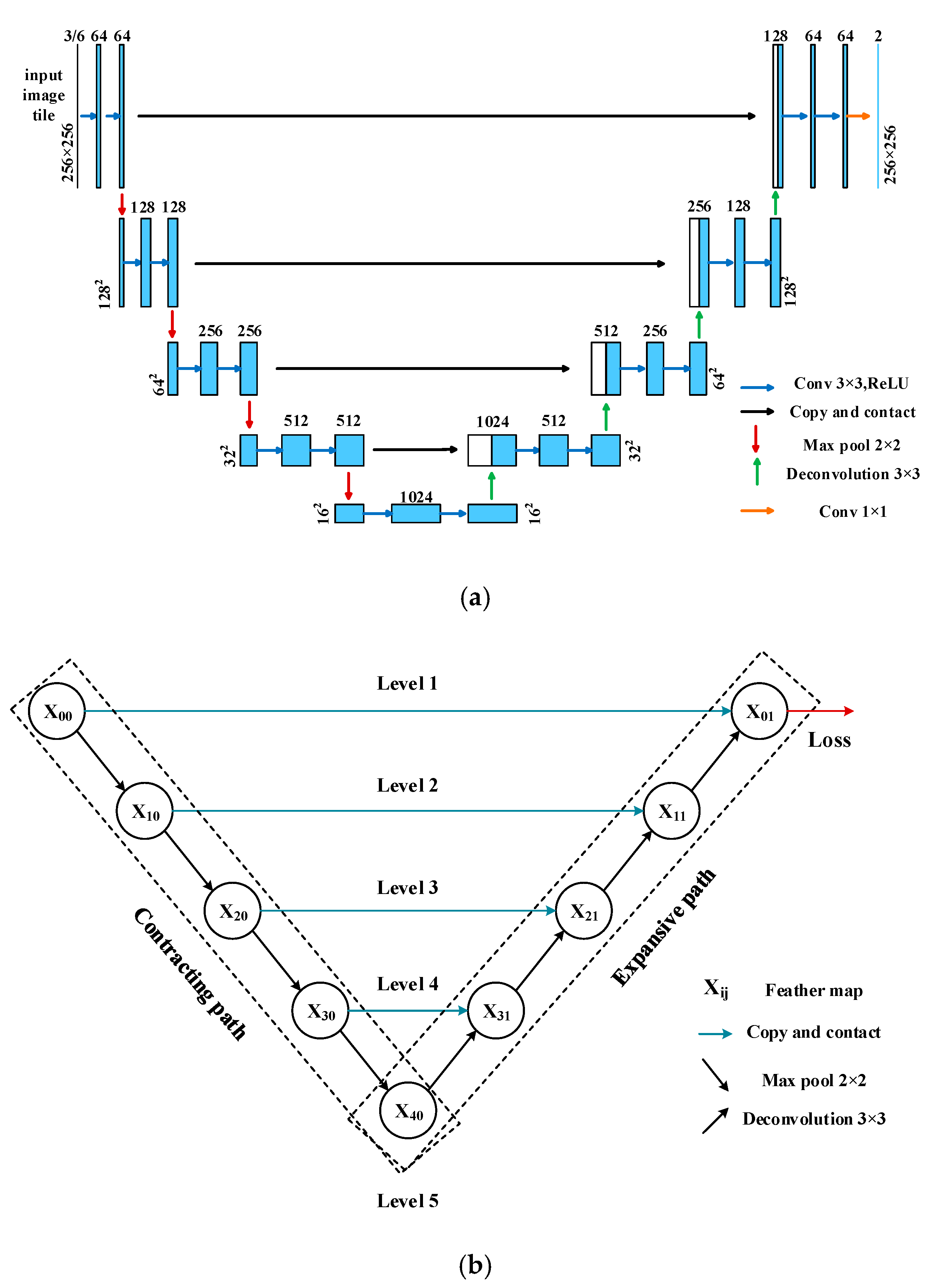
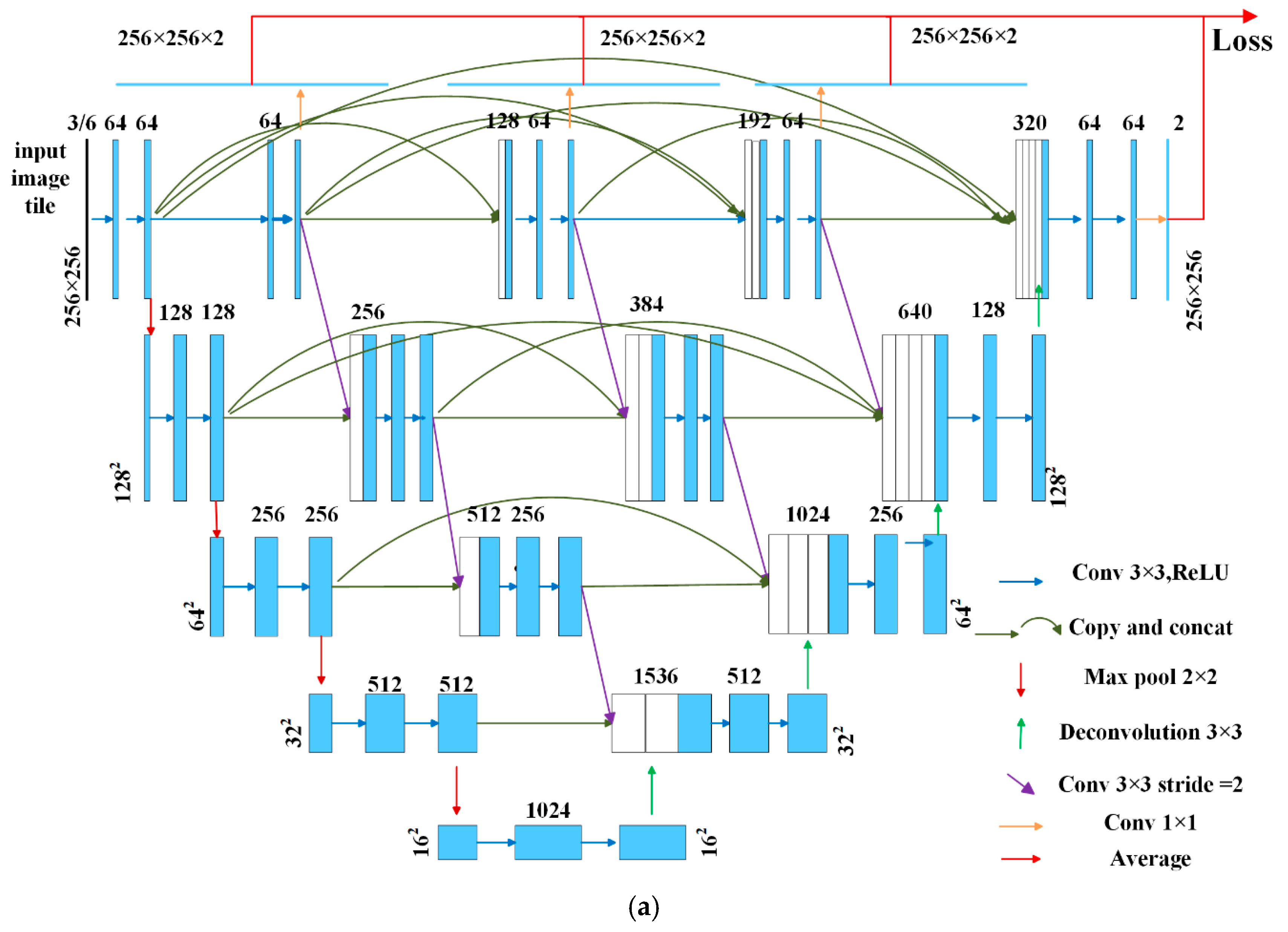
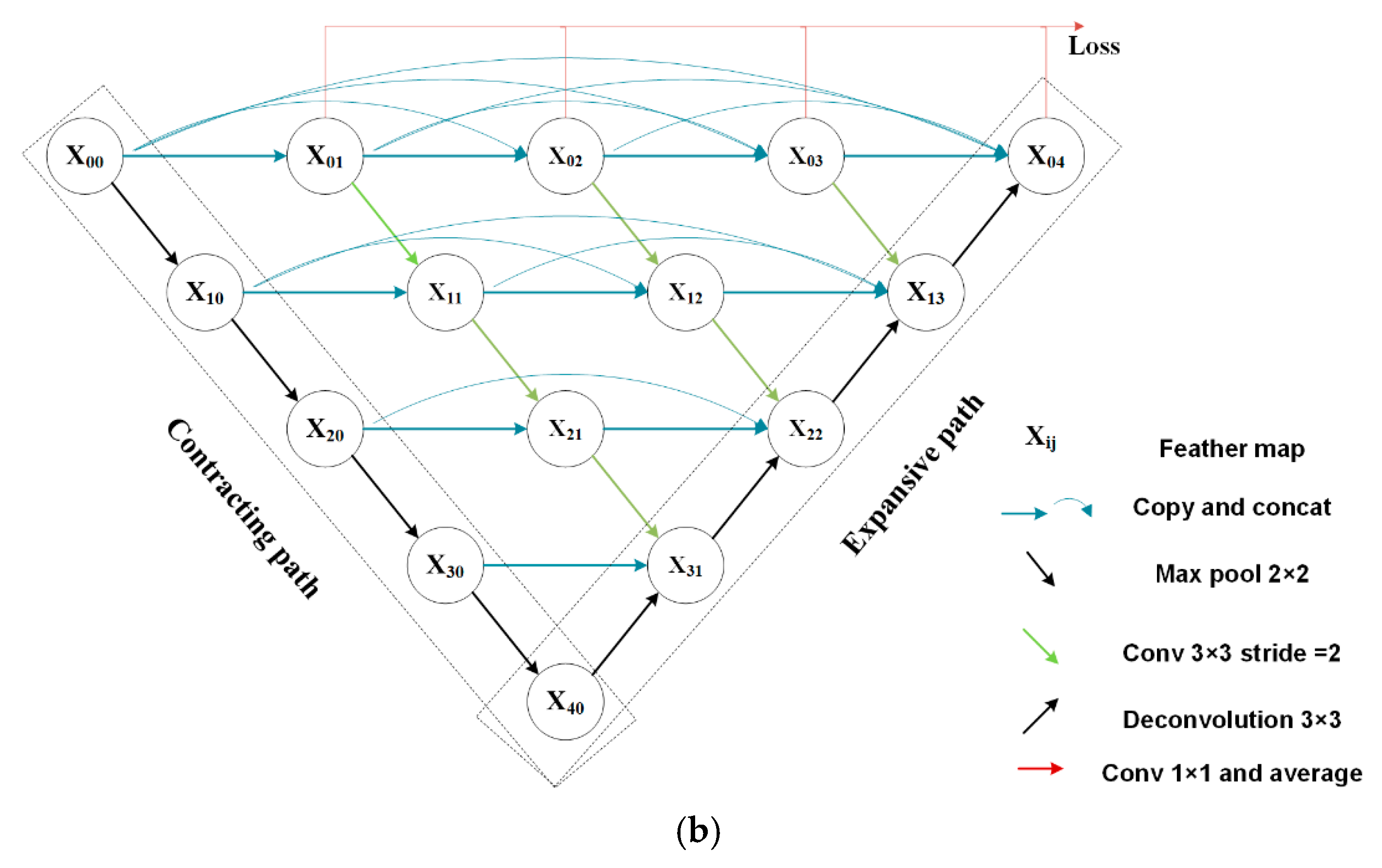
In this paper, we propose a new end-to-end cultivated land extraction algorithm, high-resolution U-Net (HRU-Net), to extract cultivated land from Landsat TM images. The new network is based on the U-Net structure, in which the skip connections are redesigned following the ideas of the second category mentioned above to obtain more details. Inspired by HRNet, the loss function of the original U-Net is also improved to take into account features extracted at both shallow and deep levels. The proposed HRU-Net was tested in Xinjiang Province, China for the cultivated land extraction based on three years’ worth of Landsat TM images, and was compared with the original U-Net, U-Net++, and the RF method. The major contributions of this study can be summarized as: (1) we redesigned the skip connection structure of the U-Net to keep the high-resolution details for remote sensing image classification; (2) we modified the original U-Net loss function to achieve a higher extraction accuracy for the target with a high intra-class variation; (3) we proposed a new end-to-end cultivated land extraction algorithm, the high-resolution U-Net (HRU-Net), which demonstrated good performance in extracting the target with high edge details and high intra-class spectral variation.
3. Study Area and Datasets
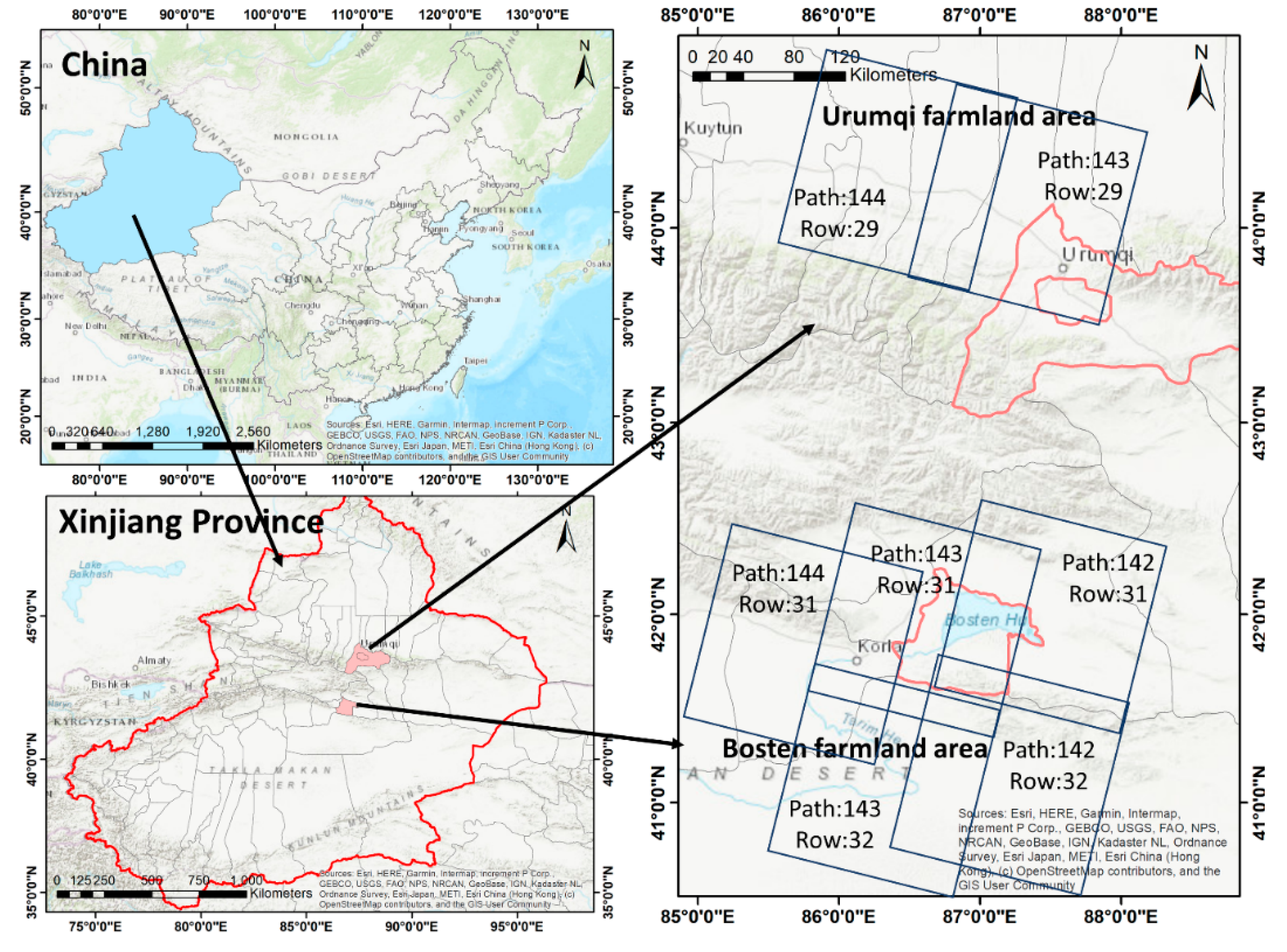
In this paper, the intra-class spectral variation of cultivated land can be reflected in three perspectives: (1) intra-class spectral variation over different time, (2) intra-class spectral variation over different geo-locations, (3) intra-class spectral variation over different crop types. These three variation factors can be represented with multiple times (both winter and summer) and different locations within a large area. The study area is located in the Urumqi and Bosten farmlands in Xinjiang, China (
Figure 1), which mainly grow cash crops, such as cotton and pears. The crops are planted in large areas with high yield and require a huge amount of water supply every year. Extracting cultivated land of these two regions is of great significance to the agricultural and water resource monitoring to ensure the national food security of Xinjiang and China.
Landsat5 thematic mapper (TM) top of atmosphere (TOA) reflectance (the USGS Earth Explorer:
https://earthexplorer.usgs.gov/) from 2009 to 2011 was collected as the dataset in this study. The TM sensor has seven spectral bands (
Table 1), but we only selected six bands with a resolution of 30 m: B1 (blue), B2 (green), B3 (red), B4 (near-infrared, NIR), B5 (short-wave-infrared, SWIR 1), and B7 (short-wave-infrared, SWIR 2). The thermal band was not used in this study as it could vary during the different observation dates, which was caused by the different local environmental factors, such as the radiative energy the land received or the wind speed. Only cloud free images were chosen in this study. The image details are shown in
Table 2.
We used the historical landcover map in the 2010 version from the local government to extract the ground truth manually based on the Landsat 5 image at 30 m scale. The changes in the land cover types were considered to be consistent from 2009 to 2011 and were neglected in this study. The original historical landcover map contained five land cover types (the urban area, cultivated land, forest, water, and desert). We classified the historical landcover map by only two types (cultivated land and other). The historical landcover map was then transformed from the original polygon to the raster format with the same spatial resolution of the Landsat data. For convenience, we added the ground truth data (the historical landcover map) to the Landsat dataset as the seventh band. After that, the TM images and corresponding ground truth were split into 256 × 256-pixel tiles to keep the memory consumption low during the training and validation. These tiles were adjacent and non-overlapping.
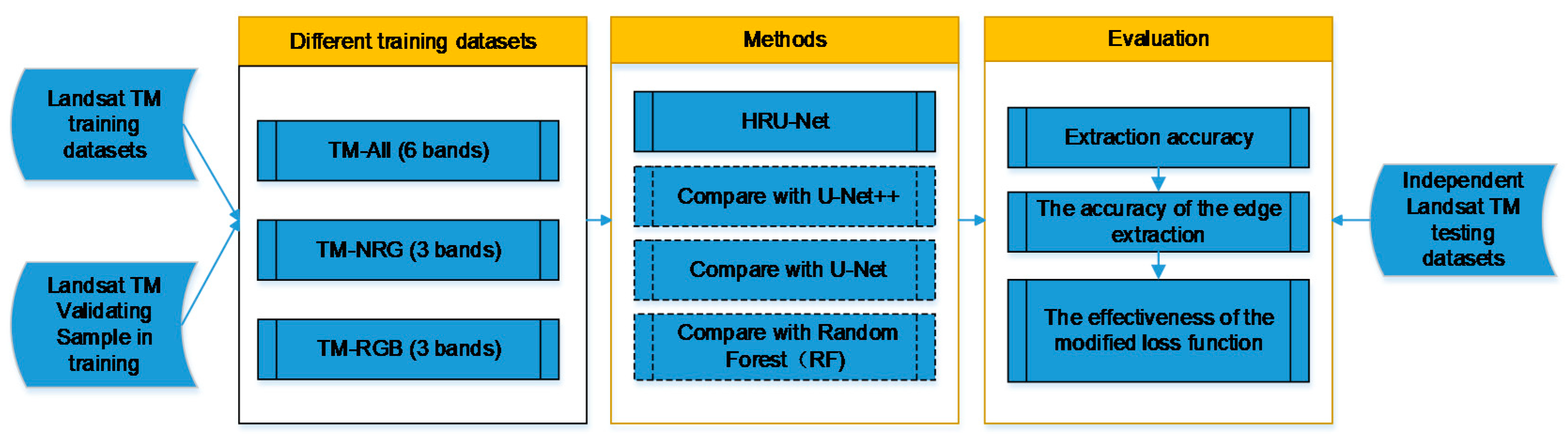
To evaluate different combinations of spectral bands on the performance of cultivated land extraction, we defined three datasets, namely, TM-NRG, TM-RGB, TM-All, with a varying number of spectral bands. An overview of each dataset is provided in
Table 3. To avoid overfitting during training, we selected 4050 tiles (approximately 70%) randomly for training, 867 tiles (approximately 15%) as validation data for adjusting the model hyperparameters during training, and the remaining 868 tiles (approximately 15%) for independent testing. The methods we used for comparation (RF, U-Net, and U-Net++) were all based and tested on the same datasets.
5. Results and Discussion
5.1. The Learning Process of the HRU-Net
In this study, we hoped to make full use of the advantage of the multi-band data of remote-sensing images instead of only RGB images. Thus, we decided to train the all network (HRU-Net, U-Net++, the original U-Net, and RF) from scratch. To compare the performance of the different numbers of bands, three datasets were prepared (
Table 2). The performance of the near-infrared (NIR) band can be analyzed when comparing the results of the TM-NRG with those of the TM-RGB. Similarly, comparing the results from the TM-All to the TM-NRG datasets, the improvement of the shortwave-infrared (SWIR) can be investigated.
The HRU-Net, U-Net++, U-Net, and RF were trained and tested on the three datasets (
Table 2) separately. In each dataset, all samples were randomly split into three: the training set, the validation set, and the testing set. The training set was used for model training. The validation set was used to calibrate the hyperparameters of the deep learning model, and the testing set was used to apply the independent assessment for the different models.
All experiments of the HRU-Net, the U-Net++, and U-Net were carried out on four TITAN X GPUs. We used PyTorch backend as the deep-learning framework (
https://pytorch.org/). To maximize the GPU memory usage, we set a different batch size for each network (HRU-Net and U-Net++:24, U-Net:48), and each network model was trained by starting with a different initial learning rate (HRU-Net:0.0015, U-Net++:0.002, U-Net:0.0002). For three networks, the gradient descent optimization (SGD) optimizer with a momentum of 0.95 and a weight decay of
was adopted, and the learning rate was decreased every iteration by a factor of
. The batch-norm parameters were learned with a decay rate of 0.9, and the input crop size for each training image was set to
.
Figure 5 shows the training history of the HRU-Net, U-Net++, and U-Net. Considering the popularity and the success of the RF in the classification of remote-sensing images, we also trained the traditional RF classifier on the same datasets as a comparison. The Scikit-learn (
http://scikit-learn.org, 2018) implementation was adopted for RF in our experiments, which employed several optimized
C4.5 decision trees to improve the prediction accuracy while controlling the over-fitting at the same time [
55]. The detailed parameters of the random forest are shown in
Table 4.
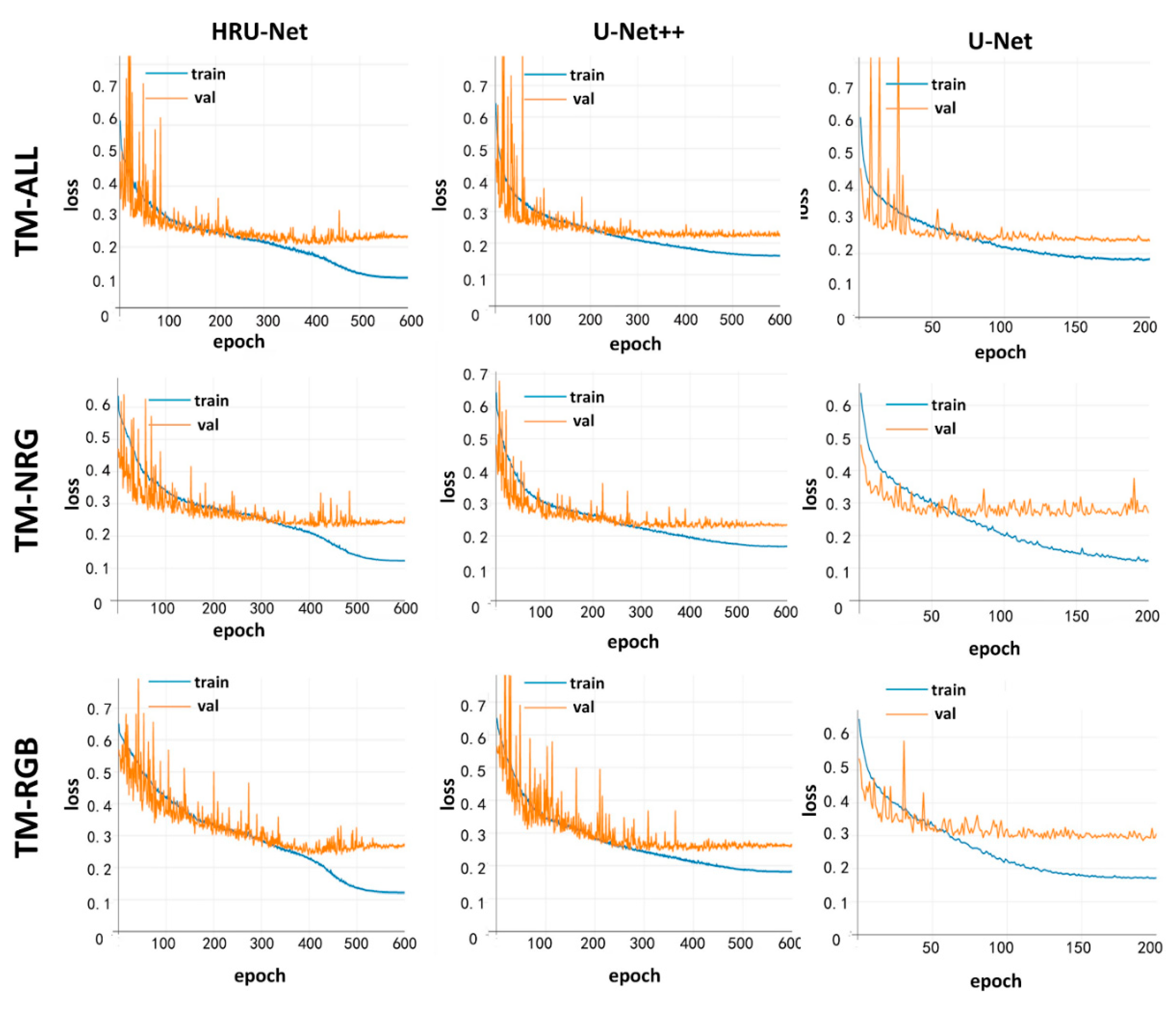
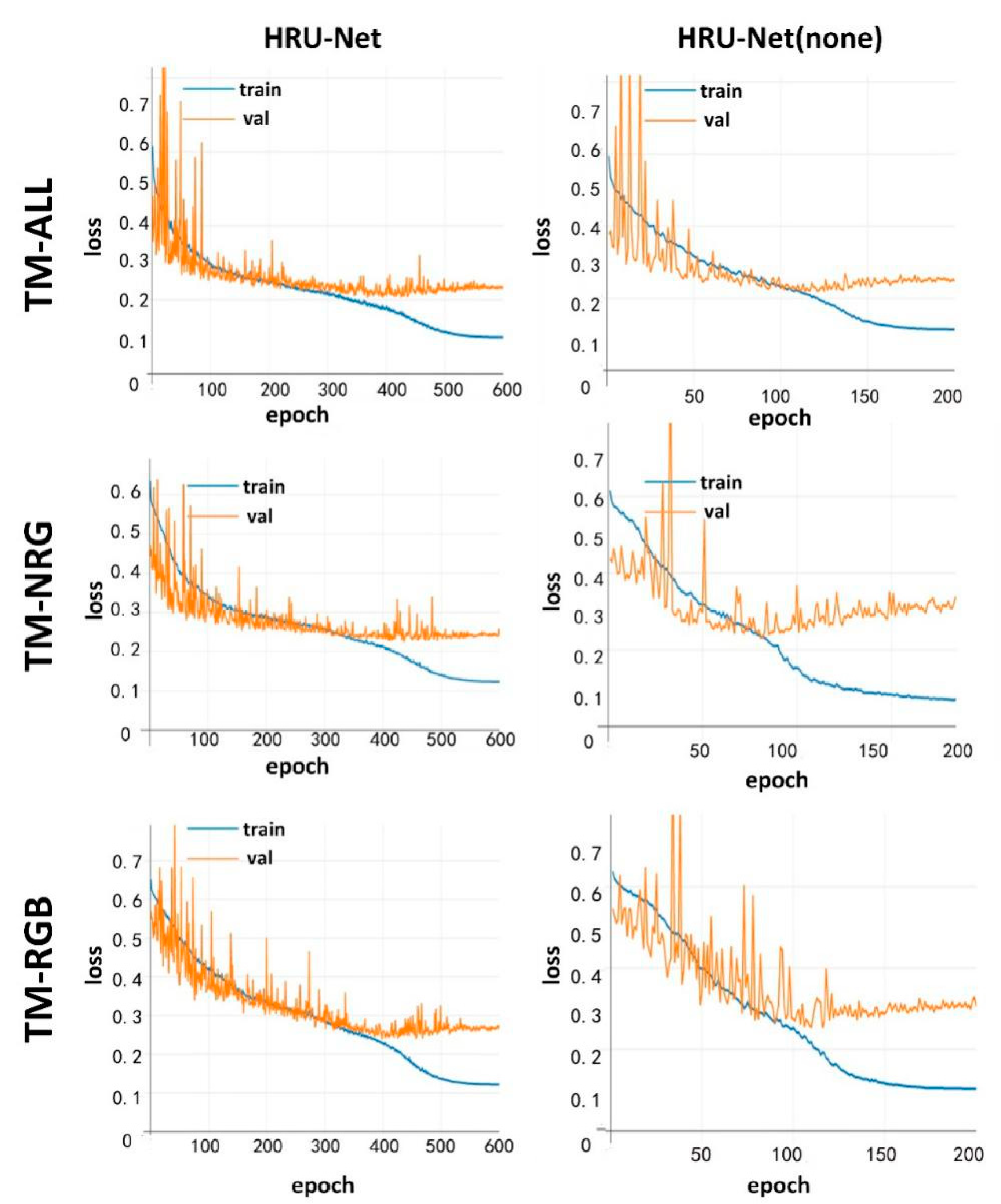
The visualizations of the training history for the HRU-Net, U-Net, and U-Net++ models are shown in
Figure 5. The blue line represents the loss calculated by the training set at each epoch. The orange line represents the loss calculated by the validation set at each epoch. Both values of the loss are high at the beginning of the training process. As the model developed by each epoch, both loss values decrease. The main purpose of
Figure 5 is to avoid overfitting during the training. As shown in
Figure 5, all orange lines converge to a certain value, indicating that there is no overfitting that happens during the training process. In other words, all three models were sufficiently trained and can be compared fairly with each other.
5.2. Comparation of the HRU-Net with U-Net, U-Net++, and RF
We tested the results of the HRU-Net, U-Net, U-Net++, and RF from three aspects: (1) the overall accuracy, (2) the accuracy of the edge details, and (3) the robustness for the intra-class variation.
5.2.1. The Overall Extraction Accuracy
Table 5 and
Figure 6 show the assessment of each method on the independent testing datasets. Over the three datasets, the HRU-Net outperformed the other three models concerning the overall accuracy (Acc), Cohen’s kappa coefficient (K), and F1 score (F1).
First, the results in
Table 5 indicate that the NIR and SWIR bands could significantly improve the overall accuracy by 1–4%. The TM-All dataset achieved the highest accuracy compared to the results from the TM-NRG and TM-RGB datasets. The highest improvement appeared when adding NIR to the RF model (3.35%). This may be related to the model capacity to capture the higher-scale features (such as the possible nonlinear band combinations). As the deep learning model can do better at this perspective, less improvement appears when adding the new bands for training.
Secondly, the HRU-Net achieved the highest extraction accuracy in all three datasets. Especially on the TM-All dataset, the HRU-Net achieved an overall accuracy of 92.81%, improved by 1.07% compared with U-Net++, 2.98% to U-Net, and more than 16% compared with RF. The HRU-Net had the best kappa coefficient of 0.75–0.81, increased by 0.01–0.02 compared with U-Net++, 0.07–0.09 compared with U-Net and 0.33–0.50 compared with RF. A similar result can be found in the F1 score.
Thirdly, as we can see from the
Table 5, the NIR band and the SWIR band can provide some useful features to help to distinguish the cultivated land and others, but the improvement was bigger in the RF model (1–4% improvement in Acc) rather than in deep learning models (0.4–1% improvement in Acc). One possible reason could be that the deep learning models have more learning capacity which can extract deeper level features such as the shape and gradients. The other reason could be that under the high intra-class spectral variation, the benefit of the NIR and SWIR band to separate the vegetation and non-vegetation pixels is less effective to distinguish the cultivated land and non-cultivated land since cultivated land can be covered by vegetation or not during the different times.
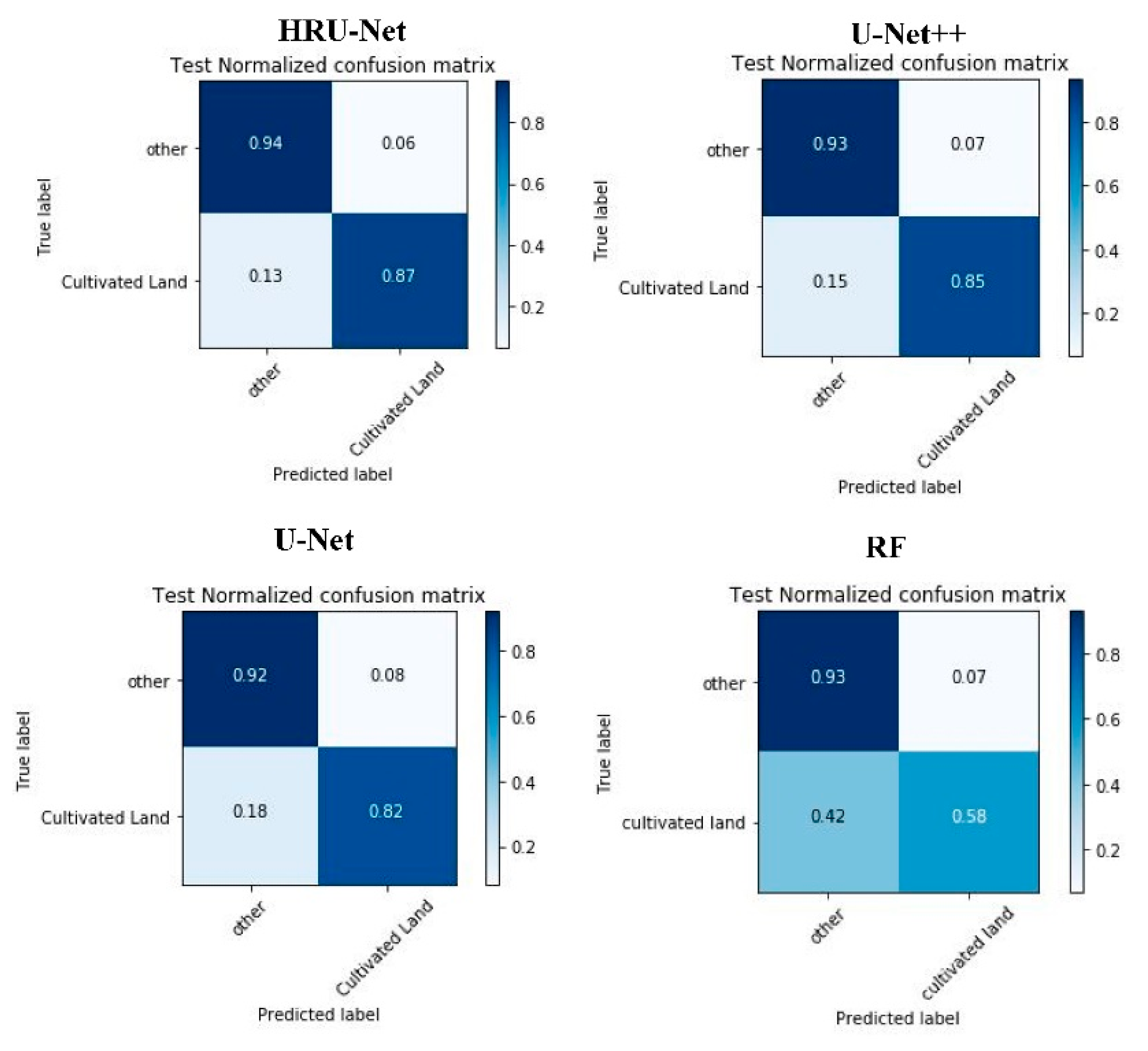
Figure 6 shows the confusion matrix for the three models over the TM-All dataset. The results indicated the HRU-Net achieved the highest recall and precision. The type 1 and type 2 error in the HRU-Net also remained the lowest compared to the U-Net++, U-Net, and RF.
Table 6 shows the overall accuracy of the HRU-Net under 50%, 60%, and 70% training sets. As we expected, the smaller training set, the lower the accuracy will be, but as we can see, even with the 50% training samples, the accuracy decreases slowly in HRU-Net.
Table 7 shows the time consumption during the training of the HRU-Net, U-Net++, and U-Net. The RF is excluded as it was trained by CPU rather than the GPU; thus, it is not comparable to the other three GPU-based algorithms. Compare to the original U-Net, the training time increased approximately 2.6 times as more model parameters were involved by adding more complex skip connections. The time consumption of the HRU-Net was similar to the U-Net++ as these two networks had a similar number of parameters when the level was the same.
5.2.2. The Accuracy of the Edge Details
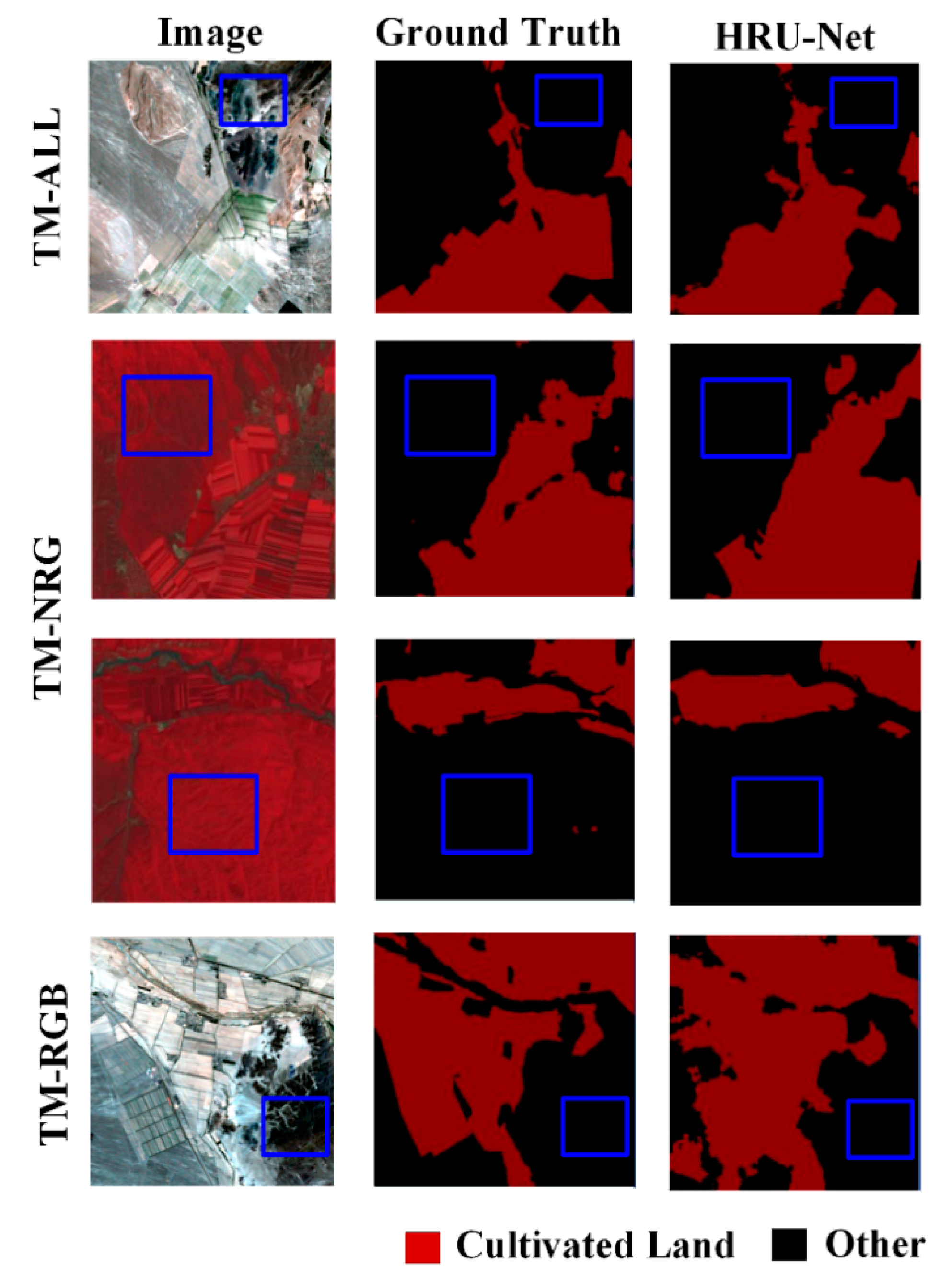
As shown in
Figure 7, the accuracy of the edge details was evaluated by visual interpretation. The results of the HRU-Net had clearer edges and richer details than those of the U-Net++ and U-Net. Specifically, comparing with the U-Net++, the more detailed edge remained in the output. The edge of the output from the HRU-Net was much more accurate than the edge of the original U-Net, as the loss of details could not be recovered from the lower nodes in the U-Net. In the output of the RF, the edge was sharp. However, the farmland without the crop covering was not detected correctly as it suffered from intra-class variation.
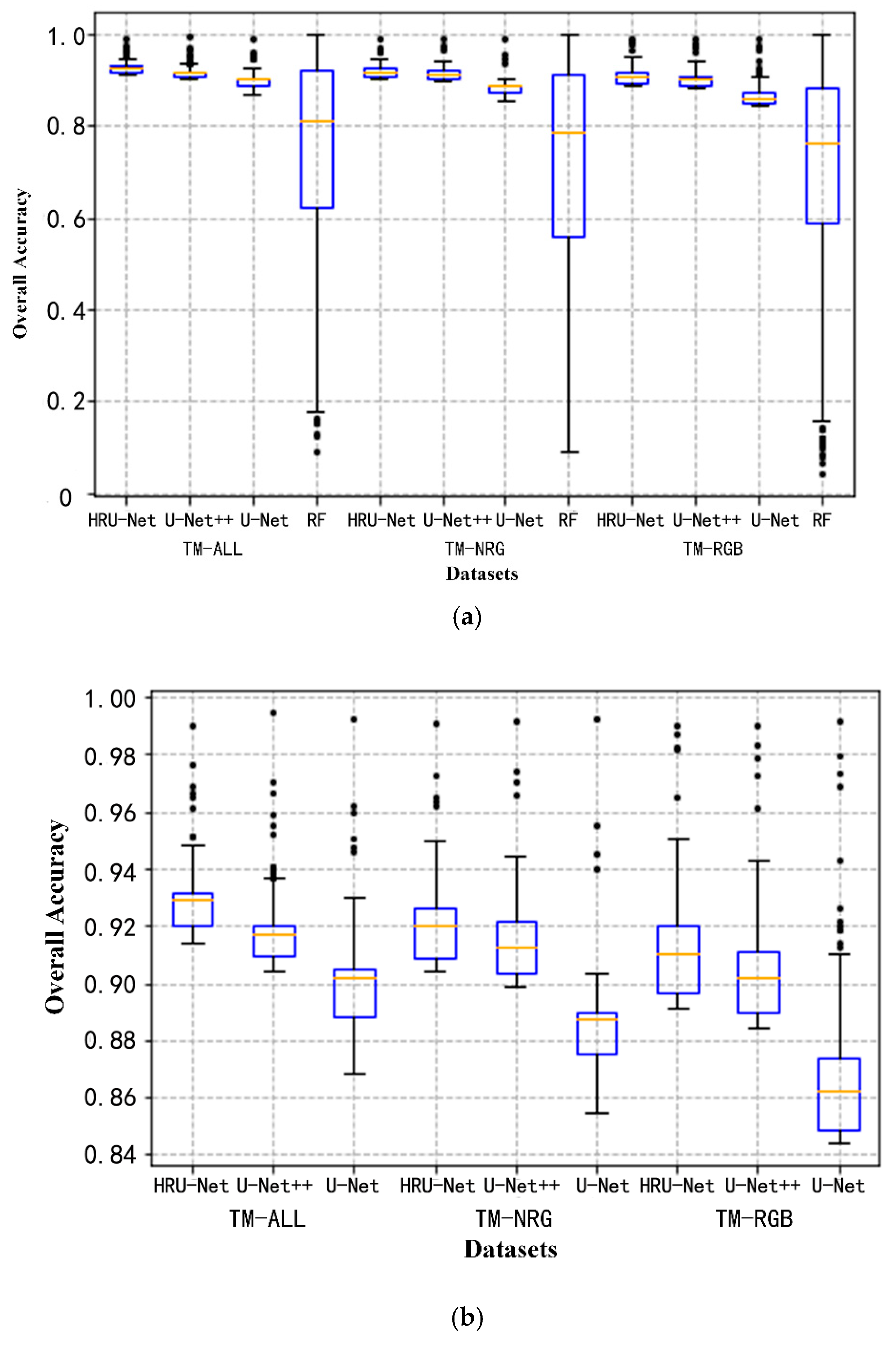
The robustness for the intra-class variation for the different models can be seen in
Figure 8. In
Figure 8, the overall accuracy of each tile in the testing dataset was plotted. The different tiles were randomly located and captured the main spectral variation of the cultivated land. The variation of the overall accuracy can be seen as the performance of the model handling the intra-class variation. As shown in
Figure 8a, the RF model had the highest variation as indicated by its limited generalization ability to cross different spectra.
Figure 8b shows a clearer comparison among the HRU-Net, U-Net++, and U-Net by removing RF from
Figure 8a. In
Figure 8b the variation of HRU-Net is similar to the U-Net++, however, it achieves higher accuracy in all three datasets. This indicates the effectiveness of the HRU-Net for solving the intra-class variation problem for accurate classification.
5.2.3. The Effectiveness of the Modified Loss Function in the HRU-Net
To clarify the effectiveness of the modified loss function, we compared the HRU-Net with the modified loss function and the HRU-Net with the original loss function designed by U-Net.
Figure 9 shows the difference in the training history of these two models. The HRU-Net with the modified loss function can be trained with more epochs; the slight overfitting happened after 500 epochs compared to after 125 epochs with the original U-Net loss function. In all three datasets, the HRU-Net with the original U-Net loss function (right column) appeared to have quicker overfitting, which was expected when training with a smaller number of bands (such as the TM-NRG and TM-RGB datasets).
Table 8 shows the overall accuracy compared with or without the modified loss function. The results indicated that the modified loss function contributed nearly 4–5%, 5–16%, and 2–8% improvement of the overall accuracy, kappa, and F1 score over the three datasets. This indicates the modified loss function in the HRU-Net can help the model learn the spectral features of cultivated land more effectively from any perspective.
5.3. Discussion
How to fix the smooth effectiveness of the pooling process to maintain or recover the image details for the deep learning model has become a topic of concern in recent years. The model we presented in this study followed the idea of maintaining and enhancing the image details during all convolution processes. The structure of the HRU-Net was similar to the 5-level U-Net++; however, the initial purposes were different. As mentioned before, the HRU-Net aimed to maintain and transfer the image details from shallow to deep levels. However, the purpose of the U-Net++ was to balance the speed and accuracy by redefining the original U-Net structure with the combination of the basic down-triangle units to achieve a more flexible structure for the different sizes of the network. The difference is that in U-Net++ more feature maps from lower levels were merged rather than higher-levels feature maps being combined in HRU-Net.
At a 30 m scale, the spectral mixing pixel is one of the sources of the classification uncertainty. The model, such as endmember extraction or mixed pixel decomposition, could help this situation. Fortunately, for the study area of this study, Xinjiang China, cultivated land is located in the huge flat area near the river or lake. The farmland is adjacent rather than separated, so the influence of the mixing pixels relatively low. This problem could be more serious when applying this model in more broken farmland, such as the southeast province of China.
The experiment in this study basically is a binary decision which mainly classify the cultivated land versus other (everything else). One of the questions is whether all the other vegetated areas (but non-cultivated) like grass fields or forest plots are well separated and classified as non-cultivated. To answer this question, we further evaluate the classification accuracy of the HRU-Net under the vegetated area. As we can see from
Figure 10, all vegetated areas (grassland and forest) are correctly classed to the “others” category. This indicated the deep features from the spectral, texture, and time series may help the deep learning model like HRU-Net to better distinguish the cultivated land with other vegetated land cover.
In this study, we used three years of data to capture the spectral variation of the cultivated land under different conditions. The labels of the training and testing data were obtained from historical landcover maps and manual interpretation of the corresponding satellite images. They may contain errors as the accuracy depended on the performance of a human analyst. In particular, regarding the accuracy of the edge and cultivated land extraction with different spectra, interpretation and delineation of cultivated land could be partially subjective.
More accurate extraction could be achieved by involving more prior knowledge, such as the time-series features of the cultivated land or by enhancing the spectral features of the soil or crops by adding the vegetation index as auxiliary channels.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}