SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards



Abstract
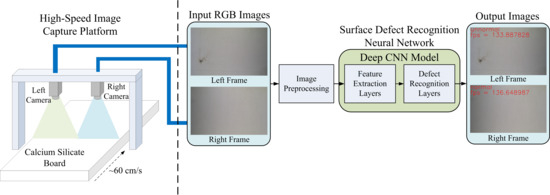
:
1. Introduction
- We propose a new CNN model called SurfNetv2, which improves the existing SurfNet so that it can achieve higher recognition accuracy with higher processing speed.
- We create a new CSB dataset for training and testing the proposed CNN model. Based on this CSB dataset, the performance of the proposed CNN model is evaluated by comparing it with other state-of-the-art methods.
- When combined with a high-speed image capture platform, we can realize an automatic optical surface defect recognition system to achieve real-time recognition of CSB surface defects on the production line.
2. Literature Review
2.1. Defect Recognition
2.2. Deep Learning Method
2.3. Convolutional Neural Network
3. System Architecture
4. The Proposed Method
4.1. Neural Network Architecture
4.2. Model Training
5. Results and Discussion
5.1. Hardware and Software Specifications
5.2. Data Collection and Dataset Creation
5.3. Training Datasets Used in the Experiment
5.4. Performance Evaluation
5.4.1. Private CSB dataset
- All proposed SurfNetv2, SurfNetv2(RP), and SurfNetv2(5 × 5) models performed well on all metrics. Moreover, The SurfNetv2 model with an input size of 128 × 128 obtained the best recognition performance across all metrics, followed by the SurfNetv2(RP) model with input sizes of 128 × 128 and 256 × 256.
- In addition to the ResNet18 and VGG16 models, the remaining CNN models had better recognition performance when the input size was 128 × 128.
- The MobileNetv2 model had the least amount of parameters, followed by SurfNet, DenseNet and the proposed SurfNetv2 model. In addition, by observing the parameters of SurfNetv2(RP) and SurfNetv2(5 × 5) models, we found that using 5 × 5 convolution blocks instead of 3 × 3 Convolution blocks greatly increased the network model parameters and reduced the network processing speed. This approach also reduced the recognition performance of the proposed SurfNetv2 model.
- Although DenseNet requires fewer parameters than the proposed SurfNetv2 model, its processing speed was the slowest one of all comparison methods. The main reason is that DenseNet uses a concatenation operation to perform feature fusion, which makes the computations of each CNN layer greatly increased due to the increase in the number of feature channels, resulting in a slow network processing speed.
- The VGG16 model with an input size of 128 × 128 had the fastest network processing speed, followed by the proposed SurfNetv2 model, and the existing SurfNet model. However, the VGG16 model had the worst recognition performance in the experiment.
- By comparing the results of the SurfNetv2 and SurfNetv2(RP) models, the use of the PReLU activation function in the proposed SurfNetv2 block did not have much impact on the recognition results. However, this approach slightly increased the network model parameters and reduced the network processing speed.
5.4.2. Public NEU dataset
- The proposed SurfNetv2, SurfNetv2(RP), and SurfNetv2(5 × 5) models also performed well on all metrics. Furthermore, the SurfNetv2 model with an input size of 128 × 128 still obtained the best recognition performance across all metrics, followed by the DenseNet and ResNet18 models with the input size of 128 × 128.
- In addition to the SurfNet and SurfNetv2(5 × 5) models, the remaining CNN models also had better recognition performance when the input size was 128 × 128.
- The recognition performance of the VGG16 model was also the worst and was greatly affected by the image scale.
- By observing the results of the SurfNetv2(5 × 5) model, we found that when the input size was 64 × 64, using 5 × 5 Convolution blocks instead of 3 × 3 Convolution blocks could improve the recognition performance of the proposed SurfNetv2 model.
- By comparing the results of the SurfNet and SurfNetv2(RP) models, when the input size was 64 × 64, using the PReLU activation function in the proposed SurfNetv2 block could provide a similar recognition performance as the original SurfNet model.
5.5. Block Number Evaluation
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Arikan, S.; Varanasi, K.; Stricker, D. Surface defect classification in real-time using convolutional neural networks. arXiv 2019, arXiv:1904.04671. [Google Scholar]
- Ma, H.-M.; Su, G.-D.; Wang, J.-Y.; Ni, Z. A glass bottle defect detection system without touching. In Proceedings of the International Conference on Machine Learning and Cybernetics, Beijing, China, 4–5 November 2002. [Google Scholar] [CrossRef]
- Chen, L.; Liang, Y.; Wang, K. Inspection of rail surface defect based on machine vision system. In Proceedings of the 2nd International Conference on Information Science and Engineering, Hangzhou, China, 4–6 December 2010. [Google Scholar] [CrossRef]
- Fu, S.; Jiang, Z. Research on image-based detection and recognition technologies for cracks on rail surface. In Proceedings of the 2019 International Conference on Robots & Intelligent System (ICRIS), Haikou, China, 15–16 June 2019. [Google Scholar] [CrossRef]
- Gao, F.; Li, Z.; Xiao, G.; Yuan, X.; Han, Z. An online inspection system of surface defects for copper strip based on computer vision. In Proceedings of the 2012 5th International Congress on Image and Signal Processing, Chongqing, China, 16–18 October 2012. [Google Scholar] [CrossRef]
- Zhou, A.; Zheng, H.; Li, M.; Shao, W. Defect inspection algorithm of metal surface based on machine vision. In Proceedings of the 2020 12th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Phuket, Thailand, 28–29 February 2020. [Google Scholar] [CrossRef]
- Wu, G.; Zhang, H.; Sun, X.; Xu, J.; Xu, K. A bran-new feature extraction method and its application to surface defect recognition of hot rolled strips. In Proceedings of the 2007 IEEE International Conference on Automation and Logistics, Jinan, China, 18–21 August 2007. [Google Scholar]
- Yu, Z.; Li, X.; Yu, H.; Xie, D.; Liu, A.; Lv, H. Research on surface defect inspection for small magnetic rings. In Proceedings of the 2009 International Conference on Mechatronics and Automation, Changchun, China, 9–12 August 2009. [Google Scholar] [CrossRef]
- Choi, J.; Kim, C. Unsupervised detection of surface defects: A two-step approach. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012. [Google Scholar] [CrossRef]
- Tsai, D.; Lin, C.; Huang, K. Defect detection in colored texture surfaces using Gabor filters. Imaging Sci. J. 2005, 53, 27–37. [Google Scholar] [CrossRef]
- Chang, Q.; Zhang, Y.; Sun, Z. Research on surface defect detection algorithm of ice-cream bars based on clustering. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar] [CrossRef]
- Chu, M.; Wang, A.; Gong, R.; Sha, M. Strip steel surface defect recognition based on novel feature extraction and enhanced least squares twin support vector machine. J. Int. 2014, 54, 1638–1645. [Google Scholar] [CrossRef] [Green Version]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic metallic surface defect detection and recognition with convolutional neural networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef] [Green Version]
- Sison, H.; Konghuayrob, P.; Kaitwanidvilai, S. A convolutional neural network for segmentation of background texture and defect on copper clad lamination surface. In Proceedings of the 2018 International Conference on Engineering, Applied Sciences, and Technology (ICEAST), Phuket, Thailand, 4–7 July 2018. [Google Scholar] [CrossRef]
- Qiu, L.; Wu, X.; Yu, Z. A high-efficiency fully convolutional networks for pixel-wise surface defect detection. IEEE Access 2019, 7, 15884–15893. [Google Scholar] [CrossRef]
- Chen, Y.-F.; Yang, F.-S.; Su, E.; Ho, C.-C. Automatic defect detection system based on deep convolutional neural networks. In Proceedings of the 2019 International Conference on Engineering, Science, and Industrial Applications (ICESI), Tokyo, Japan, 22–24 August 2019. [Google Scholar] [CrossRef]
- Mei, S.; Yang, H.; Yin, Z. An unsupervised-learning-based approach for automated defect inspection on textured surfaces. IEEE Trans. Instrum. Meas. 2018, 67, 1266–1277. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, R.; Bi, Y. Research on recognition technology of aluminum profile surface defects based on deep learning. Materials 2019, 12, 1681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Yanan, S.; Hui, Z.; Li, L.; Hang, Z. Rail surface defect detection method based on YOLOv3 deep learning networks. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement; Technical Report; University of Washington: Seattle, WA, USA, April 2018. [Google Scholar]
- Azizah, L.M.; Umayah, S.F.; Riyadi, S.; Damarjati, C.; Utama, N.A. Deep learning implementation using convolutional neural network in mangosteen surface defect detection. In Proceedings of the 2017 7th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 24–26 November 2017. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Cheon, S.; Lee, H.; Kim, C.O.; Lee, S.H. Convolutional neural network for wafer surface defect classification and the detection of unknown defect class. IEEE Trans. Semicond. Manuf. 2019, 32, 163–170. [Google Scholar] [CrossRef]
- Kim, M.S.; Park, T.; Park, P. Classification of steel surface defect using convolutional neural network with few images. In Proceedings of the 2019 12th Asian Control Conference (ASCC), Kitakyushu-shi, Japan, 9–12 June 2019. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y. Signature verification using a “Siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef] [Green Version]
- Ren, J.; Ren, R.; Green, M.; Huang, X. Defect detection from X-Ray images using a three-stage deep learning algorithm. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, B.; Dong, R.; Zhao, P. A surface defect detection method based on positive samples. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Nanjing, China, 28–31 August 2018; pp. 473–481. [Google Scholar] [CrossRef]
- Kim, Y.-G.; Lim, D.-U.; Ryu, J.-H.; Park, T.-H. SMD defect classification by convolution neural network and PCB image transform. In Proceeding of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018. [Google Scholar]
- Gao, Y.; Gao, L.; Li, X.; Wang, X.V. A multilevel information fusion-based deep learning method for vision-based defect recognition. IEEE Trans. Instrum. Meas. 2019, 69, 3980–3991. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lu, Y.-W.; Liu, K.-L.; Hsu, C.-Y. Conditional generative adversarial network for defect classification with class imbalance. In Proceedings of the 2019 IEEE International Conference on Smart Manufacturing, Industrial & Logistics Engineering (SMILE), Hangzhou, China, 20–21 April 2019. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Guan, S.; Lei, M.; Lu, H. A steel surface defect recognition algorithm based on improved deep learning network model using feature visualization and quality evaluation. IEEE Access 2020, 8, 49885–49895. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Module | Feature Extraction | Detect Recognition | ||||
|---|---|---|---|---|---|---|
| Block Name | Block1 | Block2 | Block3 | Block4 | Block5 | Output |
| SurfNetv2 | 3 × 3 Convolution Block | BN, ReLU, GAP [43], Output SoftMax | ||||
| Residual-R Block | ||||||
| SurfNetv2(RP) | 3 × 3 Convolution Block | |||||
| Residual-P Block | ||||||
| SurfNetv2(5 × 5) | 5 × 5 Convolution Block | |||||
| Residual-R Block | ||||||
| Part | Item | Content |
|---|---|---|
| Hardware | CPU | IntelR Xeon(R)E5-2630 v3 |
| RAM | 32GB | |
| GPU | RTX 2080Ti | |
| Software | System | Ubuntu 18.04 LTS |
| Tool | Python 2.7.17 | |
| Tool | Keras | |
| Backend | Tensorflow-gpu 1.14.0 |
| Class | Sample Number | |
|---|---|---|
| Manual Collection | Data Augmentation | |
| Crash | 310 | 4960 |
| Dirty | 310 | 4960 |
| Uneven | 310 | 4960 |
| Normal | 310 | 4960 |
| Class | Sample Number |
|---|---|
| Rolled-in Scale (RS) | 300 |
| Patches (Pa) | 300 |
| Crazing (Cr) | 300 |
| Pitted Surface (PS) | 300 |
| Inclusion (In) | 300 |
| Scratches (Sc) | 300 |
| Model | Epoch Number | |
|---|---|---|
| CSB Dataset | NEU Dataset | |
| SurfNetv2 | 200 | 400 |
| SurfNetv2(PP) | ||
| SurfNetv2(5 × 5) | ||
| SurfNet [1] | 300 | 500 |
| ResNet18 [39] | 100 | 150 |
| DenseNet [35] | 150 | 150 |
| VGG16 [33] | 200 | 300 |
| MobileNetv2 [45] | 200 | 300 |
| Model | Image Size | Accuracy | Recall | Precision | F1-Measure | FPS | Parameters |
|---|---|---|---|---|---|---|---|
| SurfNetv2 | 128 × 128 | 99.90% | 99.89% | 99.90% | 99.90% | 199.38 | 8.2M |
| 256 × 256 | 99.83% | 99.83% | 99.84% | 99.84% | 157.91 | ||
| SurfNetv2(RP) | 128 × 128 | 99.88% | 99.88% | 99.88% | 99.88% | 182.68 | 8.7M |
| 256 × 256 | 99.86% | 99.86% | 99.87% | 99.86% | 153.15 | ||
| SurfNetv2(5 × 5) | 128 × 128 | 99.85% | 99.85% | 99.85% | 99.85% | 123.07 | 19.3M |
| 256 × 256 | 99.80% | 99.80% | 99.80% | 99.80% | 114.77 | ||
| SurfNet | 128 × 128 | 99.68% | 99.65% | 99.70% | 99.68% | 198.93 | 2.4M |
| 256 × 256 | 99.33% | 99.22% | 99.39% | 99.31% | 154.21 | ||
| ResNet18 | 128 × 128 | 99.79% | 99.79% | 99.80% | 99.79% | 142.36 | 11.1M |
| 256 × 256 | 99.82% | 99.81% | 99.82% | 99.82% | 124.21 | ||
| DenseNet | 128 × 128 | 99.71% | 99.71% | 99.71% | 99.71% | 42.77 | 7.0M |
| 224 × 224 | 99.37% | 99.37% | 99.38% | 99.38% | 40.20 | ||
| VGG16 | 128 × 128 | 83.45% | 83.38% | 83.53% | 83.45% | 230.07 | 14.7M |
| 256 × 256 | 85.88% | 85.77% | 85.92% | 85.84% | 128.05 | ||
| MobileNetv2 | 128 × 128 | 97.28% | 97.22% | 97.34% | 97.28% | 97.42 | 2.2M |
| 256 × 256 | 98.37% | 98.35% | 98.39% | 98.37% | 89.64 |
| Model | Image Size | Accuracy | Recall | Precision | F1-Measure |
|---|---|---|---|---|---|
| SurfNetv2 | 64 × 64 | 99.37% | 99.37% | 99.44% | 99.40% |
| 128 × 128 | 99.75% | 99.75% | 99.75% | 99.75% | |
| SurfNetv2(RP) | 64 × 64 | 99.38% | 99.31% | 99.38% | 99.34% |
| 128 × 128 | 99.56% | 99.56% | 99.56% | 99.56% | |
| SurfNetv2(5 × 5) | 64 × 64 | 99.44% | 99.44% | 99.44% | 99.44% |
| 128 × 128 | 99.44% | 99.38% | 99.44% | 99.41% | |
| SurfNet | 64 × 64 | 99.37% | 99.25% | 99.44% | 99.34% |
| 128 × 128 | 99.31% | 99.25% | 99.44% | 99.34% | |
| ResNet18 | 64 × 64 | 99.50% | 99.31% | 99.55% | 99.43% |
| 128 × 128 | 99.62% | 99.62% | 99.69% | 99.66% | |
| DenseNet | 64 × 64 | 99.06% | 98.94% | 99.43% | 99.17% |
| 128 × 128 | 99.62% | 99.62% | 99.75% | 99.69% | |
| VGG16 | 64 × 64 | 95.94% | 95.19% | 96.36% | 95.76% |
| 128 × 128 | 98.00% | 97.81% | 98.17% | 97.99% | |
| MobileNetv2 | 64 × 64 | 94.38% | 93.19% | 94.84% | 93.94% |
| 128 × 128 | 96.94% | 96.62% | 97.24% | 96.92% |
| Dataset | Image Size | Block Number | Accuracy | Recall | Precision | F1-Measure |
|---|---|---|---|---|---|---|
| Private CSB | 128 × 128 | 3 | 98.72% | 98.36% | 98.98% | 98.66% |
| 4 | 99.74% | 99.70% | 99.76% | 99.73% | ||
| 5 | 99.90% | 99.89% | 99.90% | 99.90% | ||
| 6 | 99.82% | 99.82% | 99.82% | 99.82% | ||
| 7 | 99.64% | 99.64% | 99.64% | 99.64% | ||
| Public NEU | 128 × 128 | 3 | 96.94% | 96.19% | 97.74% | 96.93% |
| 4 | 99.38% | 99.06% | 99.43% | 99.25% | ||
| 5 | 99.75% | 99.75% | 99.75% | 99.75% | ||
| 6 | 98.94% | 98.88% | 98.94% | 98.90% | ||
| 7 | 98.44% | 98.44% | 98.50% | 98.47% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, C.-Y.; Chen, H.-W. SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards. Sensors 2020, 20, 4356. https://doi.org/10.3390/s20164356
Tsai C-Y, Chen H-W. SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards. Sensors. 2020; 20(16):4356. https://doi.org/10.3390/s20164356
Chicago/Turabian StyleTsai, Chi-Yi, and Hao-Wei Chen. 2020. "SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards" Sensors 20, no. 16: 4356. https://doi.org/10.3390/s20164356
APA StyleTsai, C. -Y., & Chen, H. -W. (2020). SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards. Sensors, 20(16), 4356. https://doi.org/10.3390/s20164356