Efficient Noisy Sound-Event Mixture Classification Using Adaptive-Sparse Complex-Valued Matrix Factorization and OvsO SVM


 , ,
, ,
Abstract
:1. Introduction
2. Background
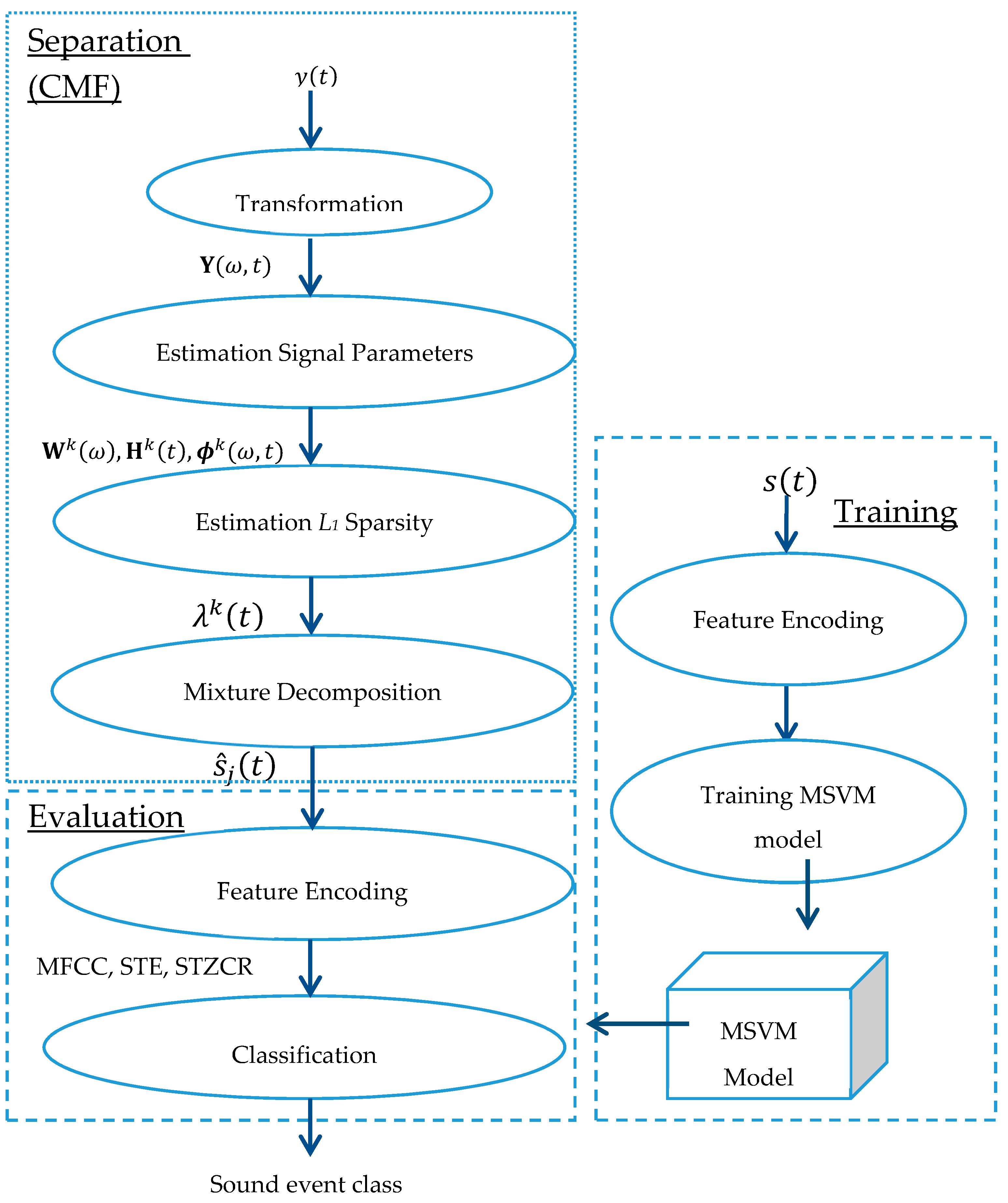
2.1. Single-Channel Sound Event Separation
2.2. Formulation of Proposed CMF Based Adaptive Variable Regularization Sparsity
2.2.1. Estimation of the Spectral Basis and Temporal Code
2.2.2. Estimation of L1-Optimal Sparsity Parameter
2.3. Sound Event Classification
| Algorithm 1 Overview of the proposed algorithm. |
|
3. Experimental Results and Analysis
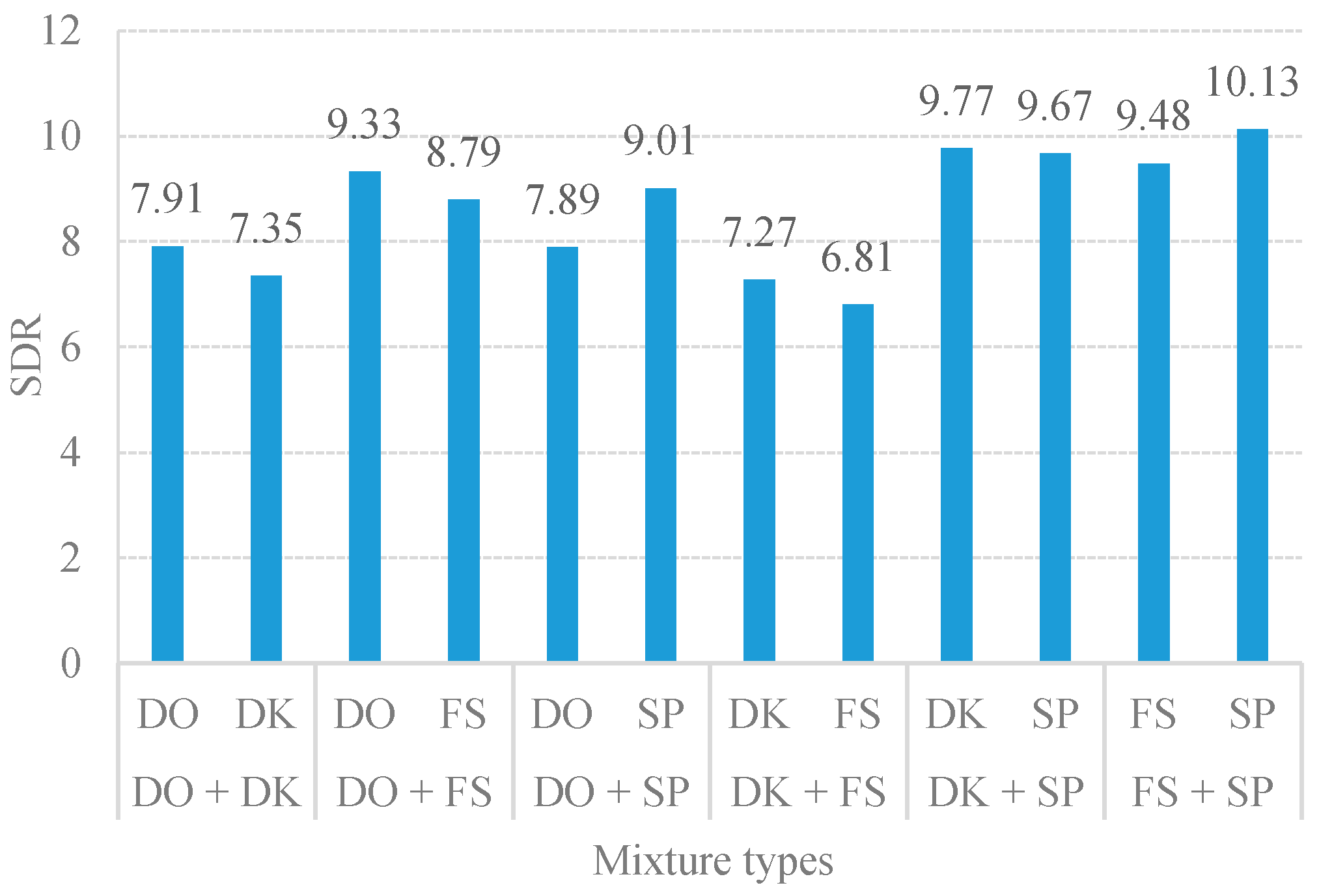
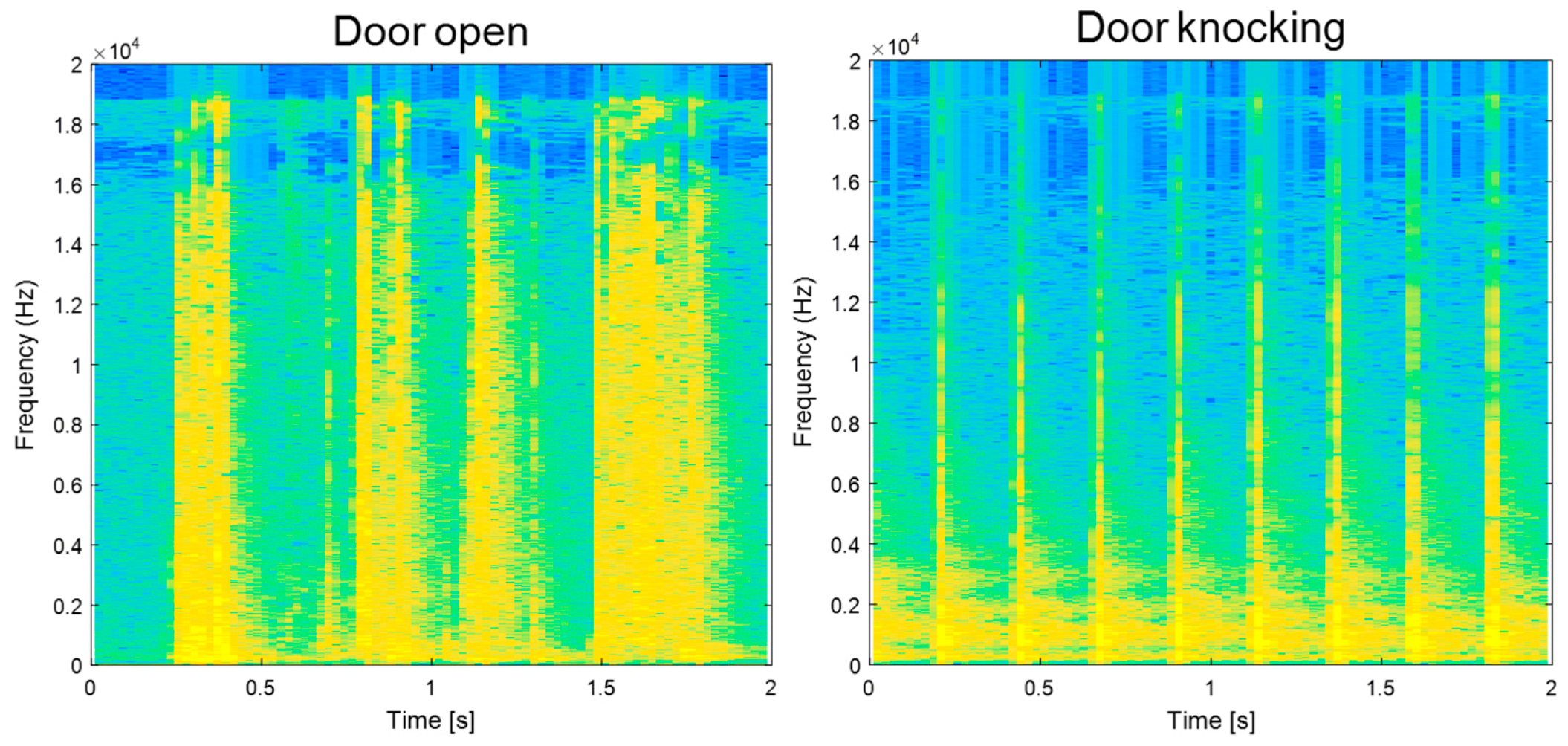
3.1. Sound-Event Separation and Classification Performance
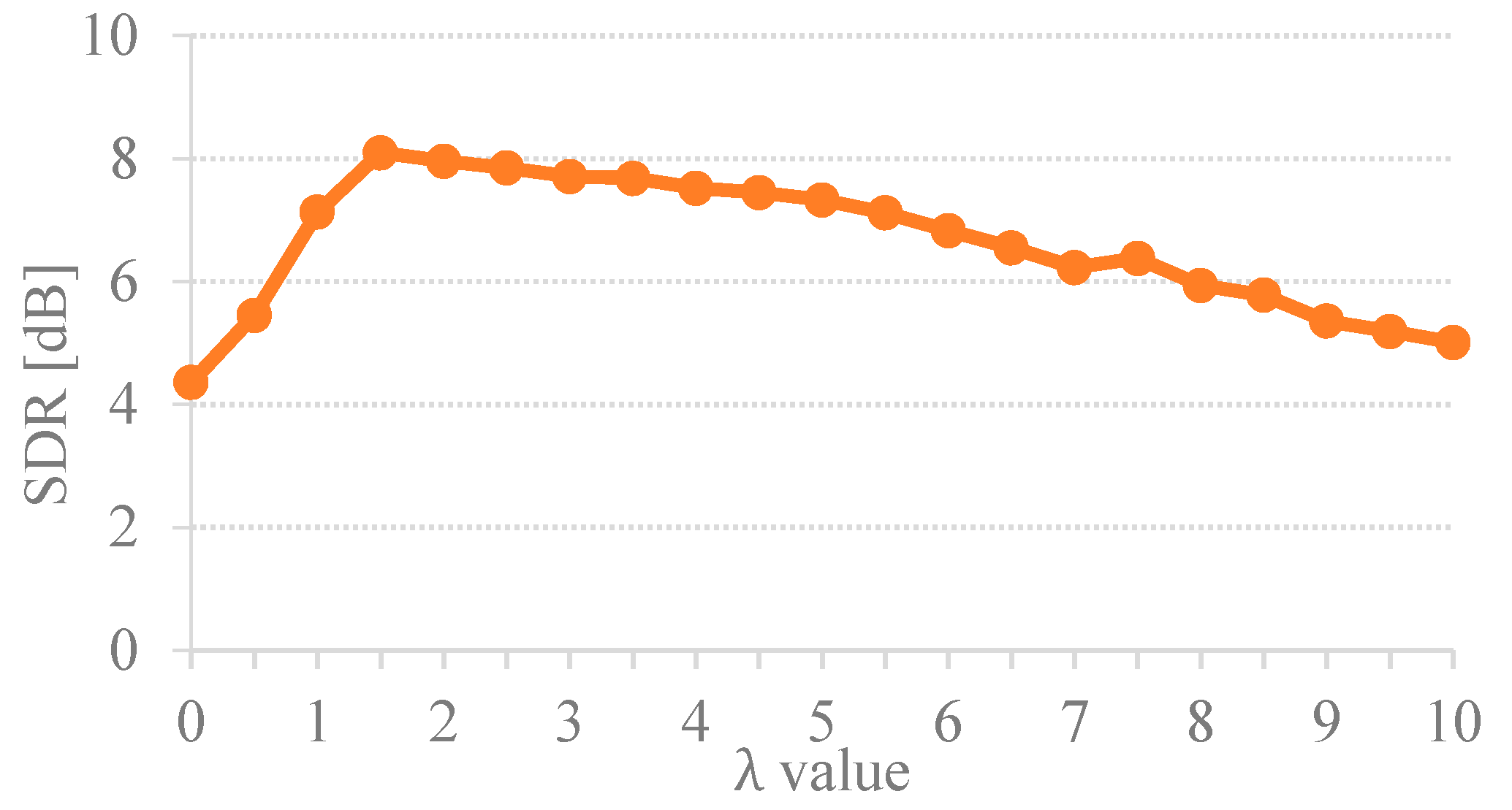
3.1.1. Variational Sparsity Versus Fixed Sparsity
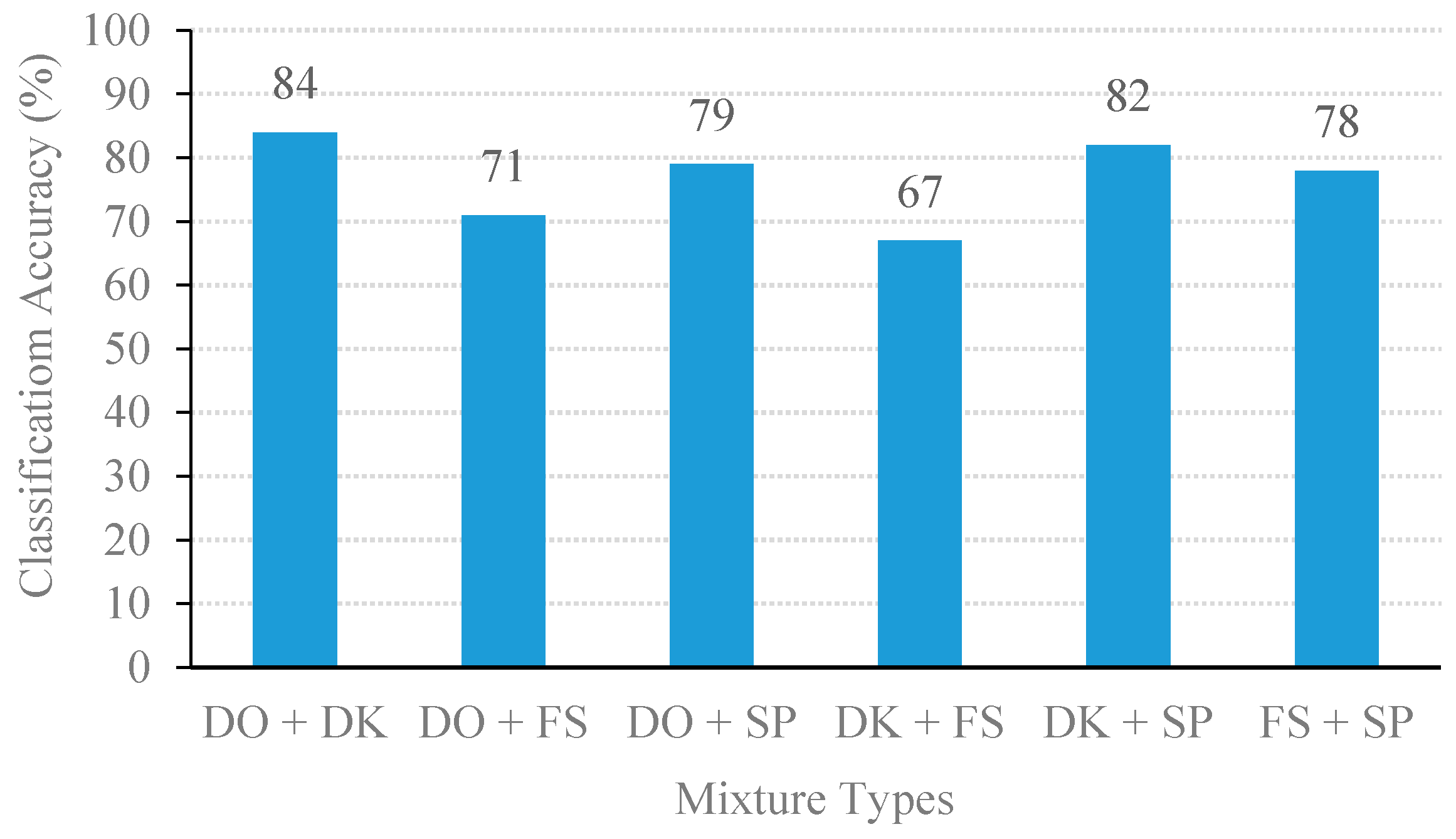
3.1.2. Comparison of the Proposed Adaptive CMF with Other SCBSS Methods Based on NMF
3.2. Performance of Event Classification Based on MSVM Algorithm
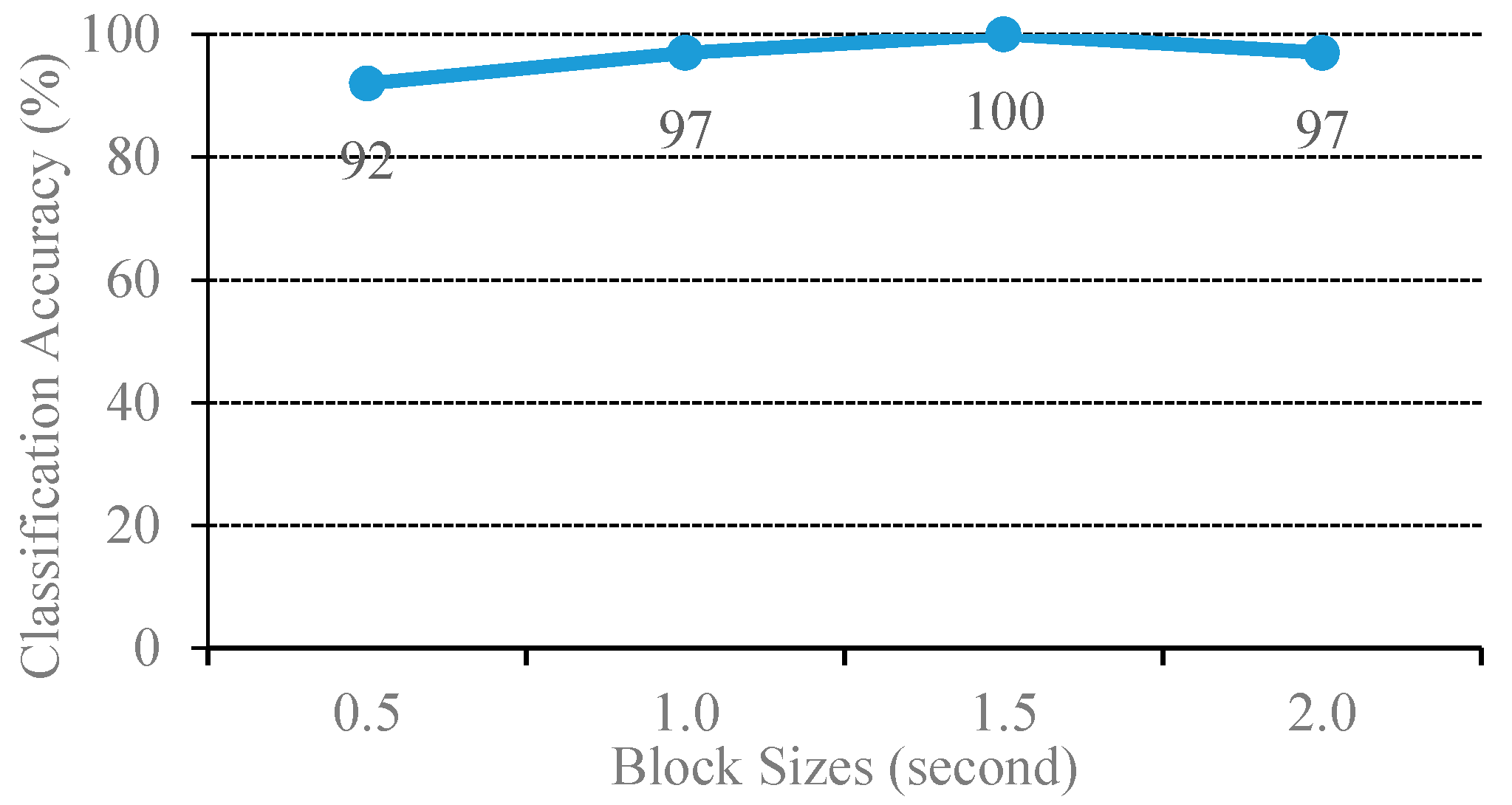
3.2.1. Determination Optimal Window Length for Feature Encoding
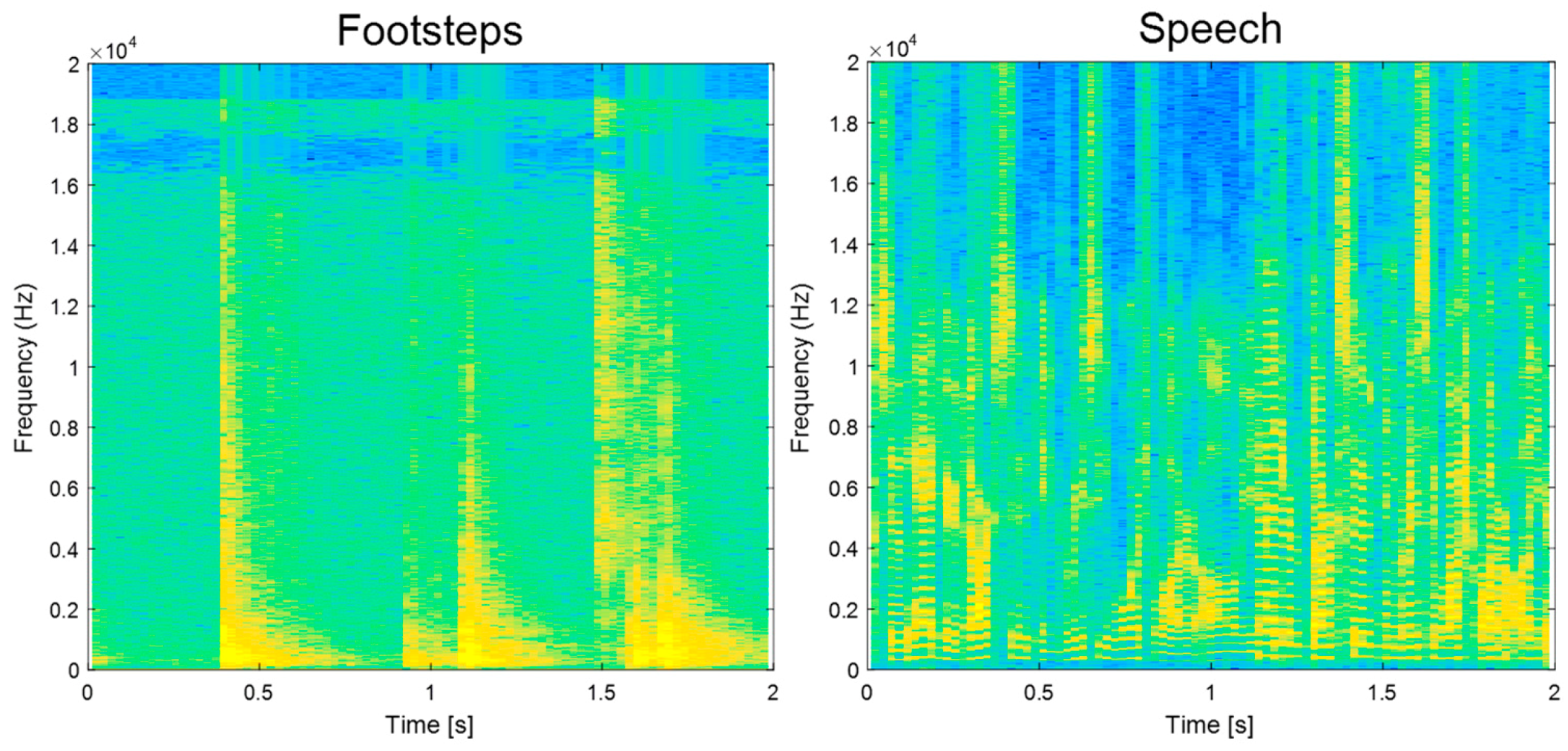
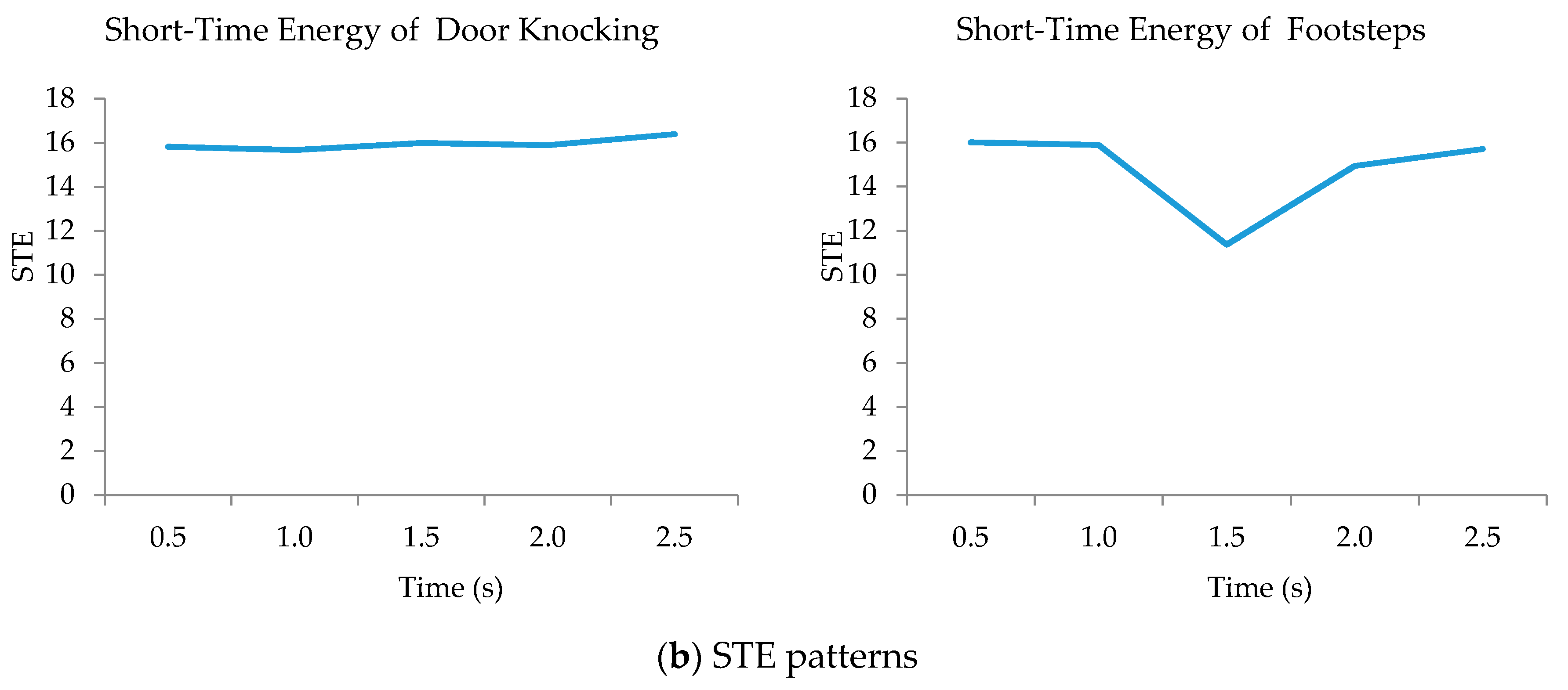
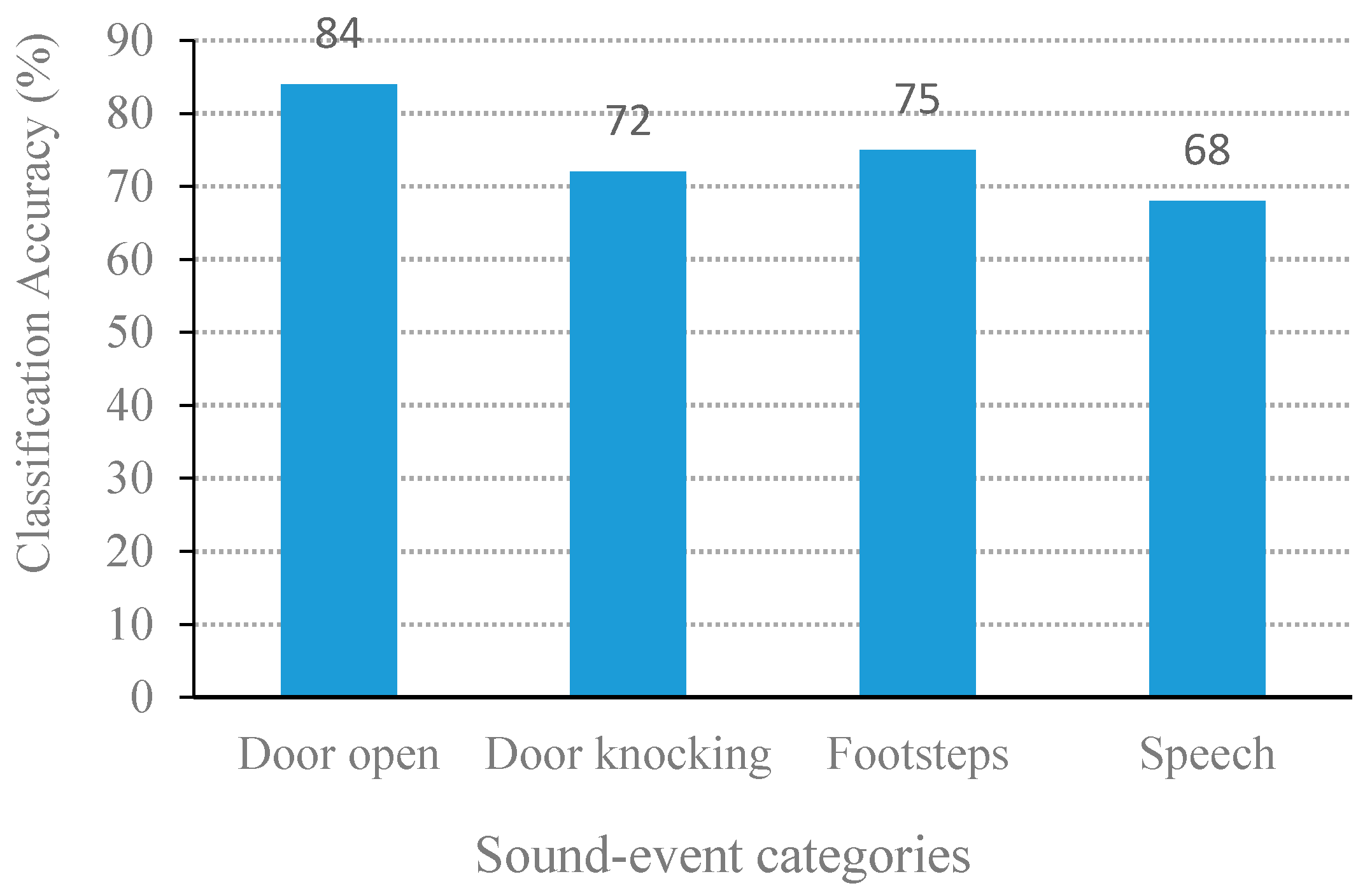
3.2.2. Determination of Sound-Event Features
| Actual | ||||||||
| Predict | DO | DK | DO | FS | DO | SP | ||
| DO | 19 | 3 | DO | 12 | 8 | DO | 19 | 5 |
| DK | 3 | 15 | FS | 4 | 16 | SP | 3 | 13 |
| DK | FS | DK | SP | FS | SP | |||
| DK | 12 | 4 | DK | 16 | 2 | FS | 14 | 6 |
| FS | 9 | 15 | SP | 5 | 17 | SP | 3 | 17 |
3.2.3. Performance of MSVM Classifier
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Single-Channel Sound Event Separation
Appendix B. Estimation of the Spectral Basis and Temporal Code
Appendix C. Estimation of L1-Optimal Sparsity Parameter
References
- Wang, Q.; Woo, W.L.; Dlay, S. Informed single-channel speech separation using hmm–gmm user-generated exemplar source. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 2087–2100. [Google Scholar] [CrossRef]
- Gao, B.; Bai, L.; Woo, W.L.; Tian, G.; Cheng, Y. Automatic defect identification of eddy current pulsed thermography using single channel blind source separation. IEEE Trans. Instrum. Meas. 2013, 63, 913–922. [Google Scholar] [CrossRef]
- Yin, A.; Gao, B.; Tian, G.; Woo, W.L.; Li, K. Physical interpretation and separation of eddy current pulsed thermography. J. Appl. Phys. 2013, 113, 64101. [Google Scholar] [CrossRef]
- Cheng, L.; Gao, B.; Tian, G.; Woo, W.L.; Berthiau, G. Impact damage detection and identification using eddy current pulsed thermography through integration of PCA and ICA. IEEE Sens. J. 2014, 14, 1655–1663. [Google Scholar] [CrossRef]
- Cholnam, O.; Chongil, G.; Chol, R.K.; Gwak, C.; Rim, K.C. Blind signal separation method and relationship between source separation and source localisation in the TF plane. IET Signal Process. 2018, 12, 1115–1122. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Woo, W.L.; Dlay, S.S.; Gao, B. Online noisy single-channel blind separation by spectrum amplitude estimator and masking. IEEE Trans. Signal Process 2016, 64, 1881–1895. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Gao, B.; Woo, W.L.; Dlay, S.S. Single-Channel Blind Separation Using Pseudo-Stereo Mixture and Complex 2-D Histogram. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1722–1735. [Google Scholar] [CrossRef]
- Koundinya, S.; Karmakar, A. Homotopy optimisation based NMF for audio source separation. IET Signal Process. 2018, 12, 1099–1106. [Google Scholar] [CrossRef]
- Kim, M.; Smaragdis, P. Single channel source separation using smooth Nonnegative Matrix Factorization with Markov Random Fields. In Proceedings of the 2013 IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Southapmton, UK, 22–25 September 2013; pp. 1–6. [Google Scholar]
- Yoshii, K.; Itoyama, K.; Goto, M. Student’s T nonnegative matrix factorization and positive semidefinite tensor factorization for single-channel audio source separation. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 51–55. [Google Scholar]
- Al-Tmeme, A.; Woo, W.L.; Dlay, S.; Gao, B. Underdetermined convolutive source separation using gem-mu with variational approximated optimum model order NMF2D. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2016, 25, 35–49. [Google Scholar] [CrossRef]
- Woo, W.L.; Gao, B.; Bouridane, A.; Ling, B.W.-K.; Chin, C.S. Unsupervised learning for monaural source separation using maximization–minimization algorithm with time–frequency deconvolution. Sensors 2018, 18, 1371. [Google Scholar] [CrossRef] [Green Version]
- Gao, B.; Woo, W.L.; Dlay, S.S. Unsupervised single channel separation of non-stationary signals using Gammatone filterbank and Itakura-Saito nonnegative matrix two-dimensional factorizations. IEEE Trans. Circuits Syst. I 2013, 60, 662–675. [Google Scholar] [CrossRef]
- Févotte, C.; Bertin, N.; Durrieu, J.-L. Nonnegative matrix factorization with the itakura-saito divergence: With application to music analysis. Neural Comput. 2009, 21, 793–830. [Google Scholar] [CrossRef] [PubMed]
- Pu, X.; Yi, Z.; Zheng, Z.; Zhou, W.; Ye, M. Face recognition using fisher non-negative matrix factorization with sparseness constraints. Comput. Vis. 2005, 3497, 112–117. [Google Scholar] [CrossRef]
- Magron, P.; Virtanen, T. Towards complex nonnegative matrix factorization with the beta-divergence. In Proceedings of the 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Tokyo, Japan, 17–20 September 2018; pp. 156–160. [Google Scholar]
- King, B. New Methods of Complex Matrix Factorization for Single-Channel Source Separation and Analysis. Ph.D. Thesis, University of Washington, Seattle, WA, USA, 2012. [Google Scholar]
- Parathai, P.; Tengtrairat, N.; Woo, W.L.; Gao, B. Single-channel signal separation using spectral basis correlation with sparse nonnegative tensor factorization. Circuits Syst. Signal Process. 2019, 38, 5786–5816. [Google Scholar] [CrossRef]
- Woo, W.L.; Dlay, S.; Al-Tmeme, A.; Gao, B. Reverberant signal separation using optimized complex sparse nonnegative tensor deconvolution on spectral covariance matrix. Digit. Signal Process. 2018, 83, 9–23. [Google Scholar] [CrossRef] [Green Version]
- Tengtrairat, N.; Parathai, P.; Woo, W.L. Blind 2D signal direction for limited-sensor space using maximum likelihood estimation. Asia-Pac. J. Sci. Technol. 2017, 22, 42–49. [Google Scholar]
- Gao, B.; Woo, W.L.; Tian, G.Y.; Zhang, H. Unsupervised diagnostic and monitoring of defects using waveguide imaging with adaptive sparse representation. IEEE Trans. Ind. Inform. 2016, 12, 405–416. [Google Scholar] [CrossRef]
- Gao, B.; Woo, W.L.; He, Y.; Tian, G.Y. Unsupervised sparse pattern diagnostic of defects with inductive thermography imaging system. IEEE Trans. Ind. Inform. 2016, 12, 371–383. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Woo, W.L. Single-channel separation using underdetermined blind autoregressive model and lest absolute deviation. Neurocomputing 2015, 147, 412–425. [Google Scholar] [CrossRef]
- Gao, B.; Woo, W.; Ling, B.W.-K. Machine learning source separation using maximum a posteriori nonnegative matrix factorization. IEEE Trans. Cybern. 2013, 44, 1169–1179. [Google Scholar] [CrossRef]
- Tengtrairat, N.; Woo, W. Extension of DUET to single-channel mixing model and separability analysis. Signal Process. 2014, 96, 261–265. [Google Scholar] [CrossRef]
- Zhou, Q.; Feng, Z.; Benetos, E. Adaptive noise reduction for sound event detection using subband-weighted NMF. Sensors 2019, 19, 3206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, L.; Zhang, Y.; He, Y.; Gao, S.; Zhu, D.; Ran, B.; Wu, Q. Hazardous traffic event detection using markov blanket and sequential minimal optimization (MB-SMO). Sensors 2016, 16, 1084. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.-L.; Chiang, H.-H.; Chiang, C.-Y.; Liu, J.; Yuan, S.-M.; Wang, J.-H. A vision-based driver nighttime assistance and surveillance system based on intelligent image sensing techniques and a heterogamous dual-core embedded system architecture. Sensors 2012, 12, 2373–2399. [Google Scholar] [CrossRef] [PubMed]
- McLoughlin, I.V.; Zhang, H.; Xie, Z.; Song, Y.; Xiao, W. Robust sound event classification using deep neural networks. IEEE/ACM Trans. Audio. Speech. Lang. Process. 2015, 23, 540–552. [Google Scholar] [CrossRef] [Green Version]
- Noh, K.; Chang, J.-H. Joint optimization of deep neural network-based dereverberation and beamforming for sound event detection in multi-channel environments. Sensors 2020, 20, 1883. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multi-class support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar]
- Martin-Morato, I.; Cobos, M.; Ferri, F.J. A case study on feature sensitivity for audio event classification using support vector machines. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Salerno, Italy, 13–16 September 2016; pp. 1–6. [Google Scholar]
- Candès, E.J.; Romberg, J.K.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar] [CrossRef] [Green Version]
- Selesnick, I. Resonance-based signal decomposition: A new sparsity-enabled signal analysis method. Signal Process. 2011, 91, 2793–2809. [Google Scholar] [CrossRef]
- Al-Tmeme, A.; Woo, W.L.; Dlay, S.; Gao, B. Single channel informed signal separation using artificial-stereophonic mixtures and exemplar-guided matrix factor deconvolution. Int. J. Adapt. Control. Signal Process. 2018, 32, 1259–1281. [Google Scholar] [CrossRef] [Green Version]
- Gao, B.; Woo, W.L.; Dlay, S.S. Single channel blind source separation using EMD-subband variable regularized sparse features. IEEE Trans. Audio. Speech Lang. Process. 2011, 19, 961–976. [Google Scholar] [CrossRef]
- Bertsekas, D.P. Nonlinear Programming, 2nd ed.; Athena Scientific: Belmont, MA, USA, 1999. [Google Scholar]
- Kameoka, H.; Ono, N.; Kashino, K.; Sagayama, S. Complex NMF: A new sparse representation for acoustic signals. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 3437–3440. [Google Scholar] [CrossRef] [Green Version]
- Parathai, P.; Woo, W.L.; Dlay, S.; Gao, B. Single-channel blind separation using L1-sparse complex non-negative matrix factorization for acoustic signals. J. Acoust. Soc. Am. 2015, 137, 124–129. [Google Scholar] [CrossRef] [PubMed]
- Zdunek, R.; Cichocki, A. Nonnegative matrix factorization with constrained second-order optimization. Signal Process. 2007, 87, 1904–1916. [Google Scholar] [CrossRef]
- Yu, K.; Woo, W.L.; Dlay, S. Variational regularized two-dimensional nonnegative matrix factorization. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 703–716. [Google Scholar]
- Gao, B.; Woo, W.L.; Dlay, S. Adaptive sparsity non-negative matrix factorization for single-channel source separation. IEEE J. Sel. Top. Signal Process. 2011, 5, 989–1001. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
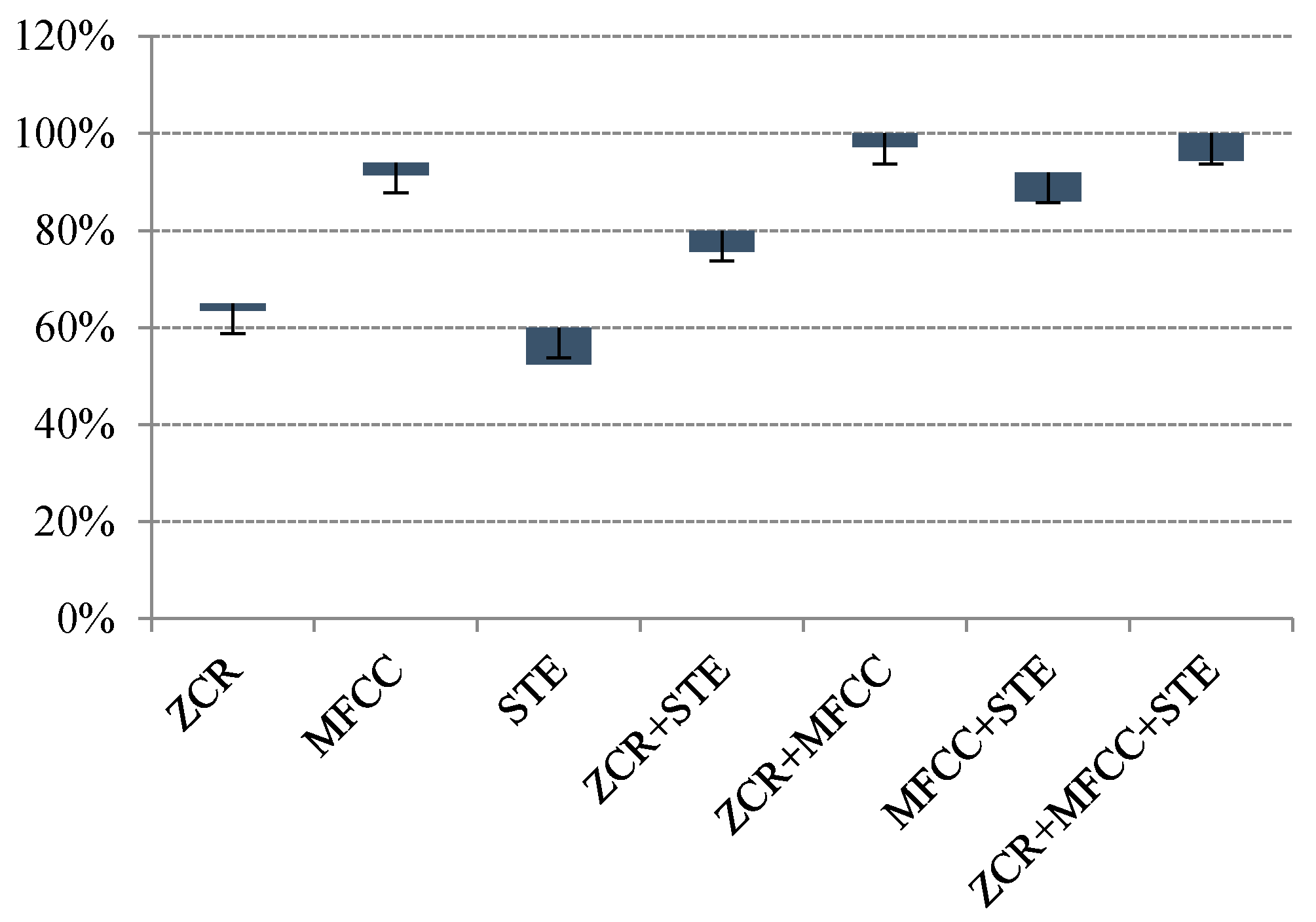{kind=link}
{kind=link}
{kind=link}
| Mixtures | Methods | SDR |
|---|---|---|
| DO + DK | Proposed method | 7.63 |
| (Best) Uniform regularization sparsity | 6.59 | |
| DO + FS | Proposed method | 9.06 |
| (Best) Uniform regularization sparsity | 8.74 | |
| DO + SP | Proposed method | 8.45 |
| (Best) Uniform regularization sparsity | 6.91 | |
| DK + FS | Proposed method | 7.04 |
| (Best) Uniform regularization sparsity | 6.35 | |
| DK + SP | Proposed method | 9.72 |
| (Best) Uniform regularization sparsity | 7.78 | |
| FS + SP | Proposed method | 9.81 |
| (Best) Uniform regularization sparsity | 7.42 |
| Mixtures | Methods | SDR |
|---|---|---|
| Door Open | Proposed method | 8.38 |
| CMF | 7.11 | |
| SNMF | 6.23 | |
| NMF-ISD | 6.17 | |
| Door Knocking | Proposed method | 8.13 |
| CMF | 7.06 | |
| SNMF | 6.52 | |
| NMF-ISD | 6.55 | |
| Footsteps | Proposed method | 8.36 |
| CMF | 7.89 | |
| SNMF | 6.62 | |
| NMF-ISD | 6.06 | |
| Speech | Proposed method | 9.60 |
| CMF | 6.73 | |
| SNMF | 5.61 | |
| NMF-ISD | 5.32 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parathai, P.; Tengtrairat, N.; Woo, W.L.; Abdullah, M.A.M.; Rafiee, G.; Alshabrawy, O. Efficient Noisy Sound-Event Mixture Classification Using Adaptive-Sparse Complex-Valued Matrix Factorization and OvsO SVM. Sensors 2020, 20, 4368. https://doi.org/10.3390/s20164368
Parathai P, Tengtrairat N, Woo WL, Abdullah MAM, Rafiee G, Alshabrawy O. Efficient Noisy Sound-Event Mixture Classification Using Adaptive-Sparse Complex-Valued Matrix Factorization and OvsO SVM. Sensors. 2020; 20(16):4368. https://doi.org/10.3390/s20164368
Chicago/Turabian StyleParathai, Phetcharat, Naruephorn Tengtrairat, Wai Lok Woo, Mohammed A. M. Abdullah, Gholamreza Rafiee, and Ossama Alshabrawy. 2020. "Efficient Noisy Sound-Event Mixture Classification Using Adaptive-Sparse Complex-Valued Matrix Factorization and OvsO SVM" Sensors 20, no. 16: 4368. https://doi.org/10.3390/s20164368
APA StyleParathai, P., Tengtrairat, N., Woo, W. L., Abdullah, M. A. M., Rafiee, G., & Alshabrawy, O. (2020). Efficient Noisy Sound-Event Mixture Classification Using Adaptive-Sparse Complex-Valued Matrix Factorization and OvsO SVM. Sensors, 20(16), 4368. https://doi.org/10.3390/s20164368