Remaining Useful Life Prediction of Airplane Engine Based on PCA–BLSTM


Abstract
:1. Introduction
2. Design of Hybrid Model based on PCA–BLSTM
2.1. Principal Component Analysis
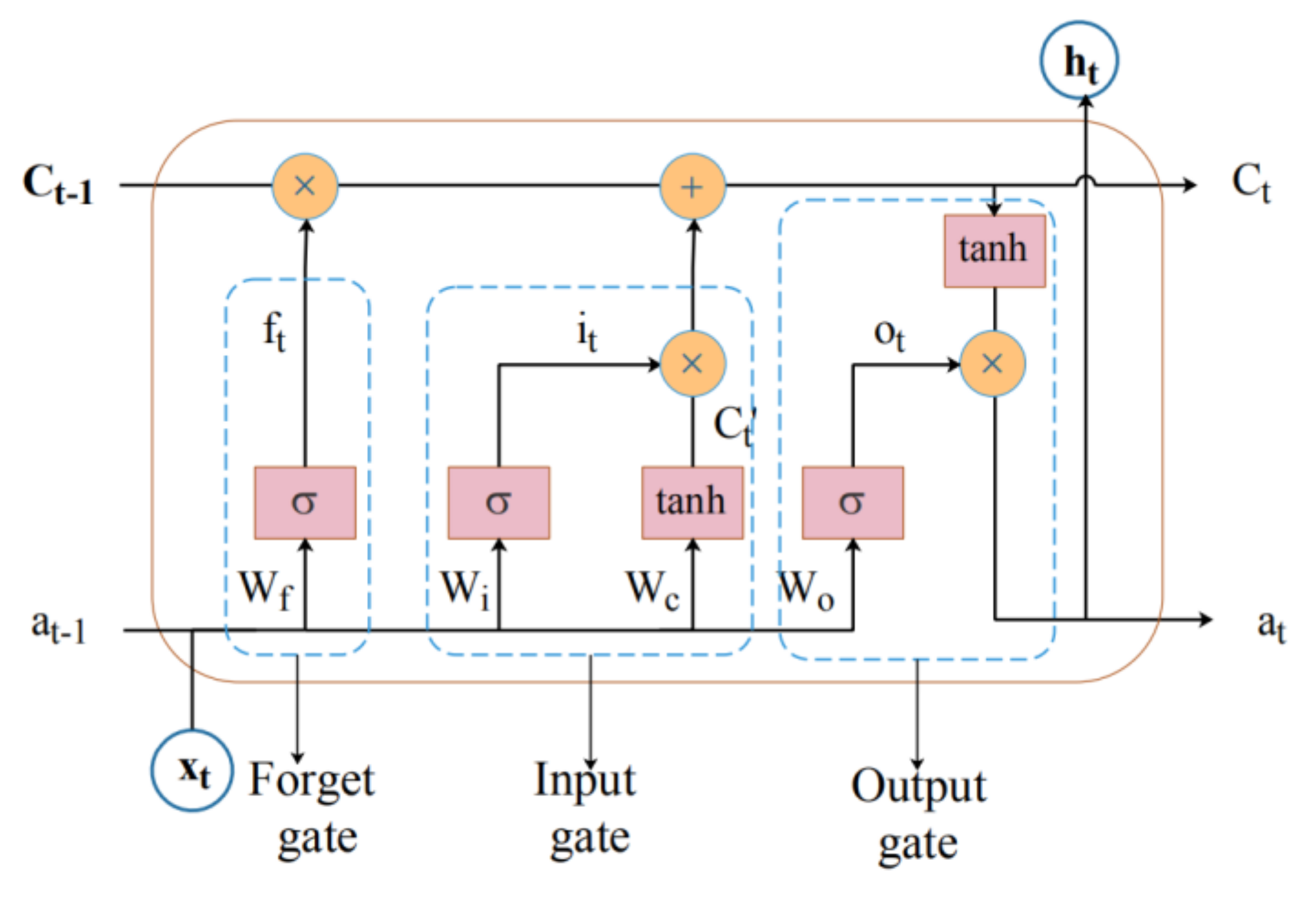
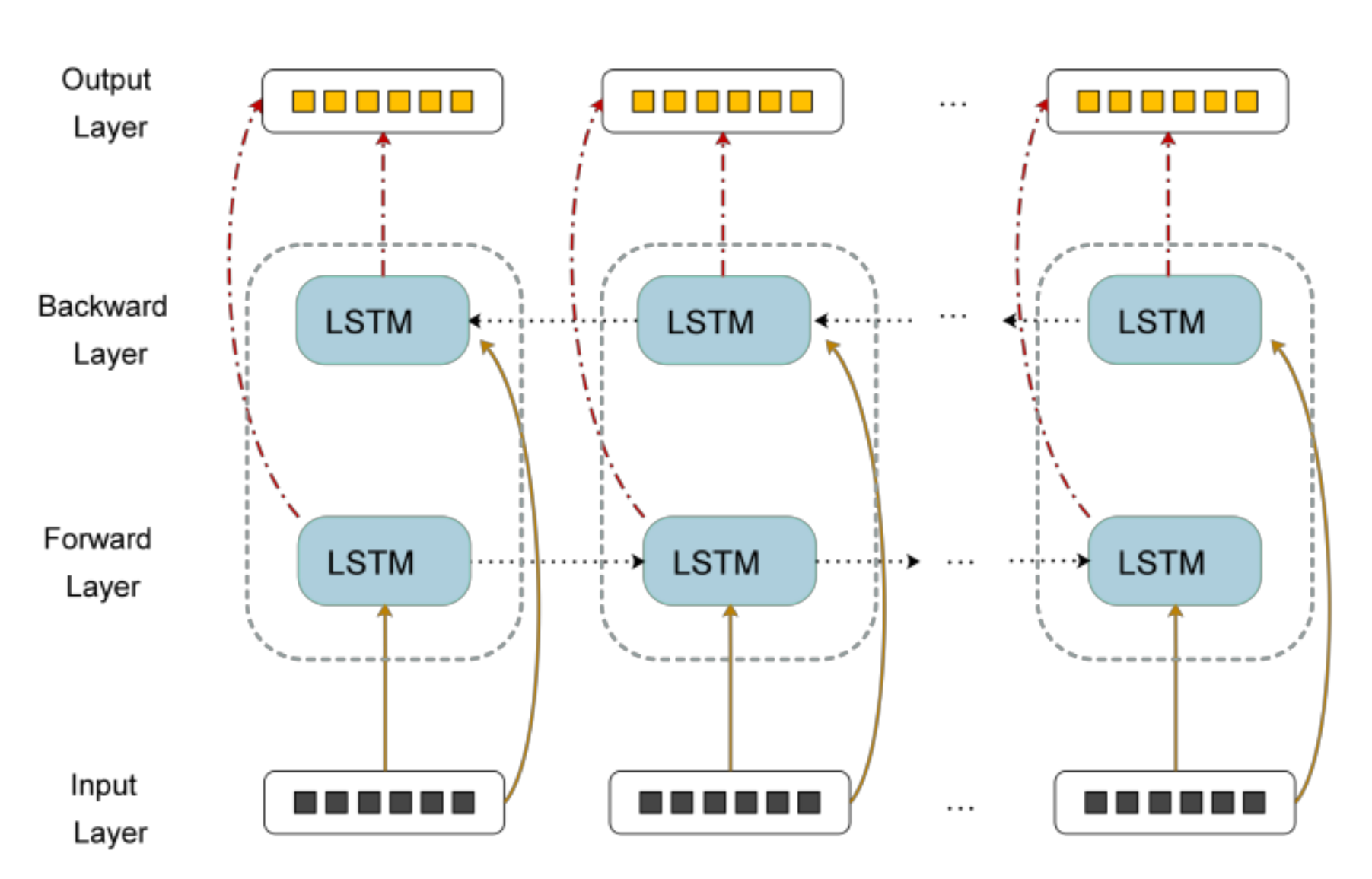
2.2. BLSTM Neural Network
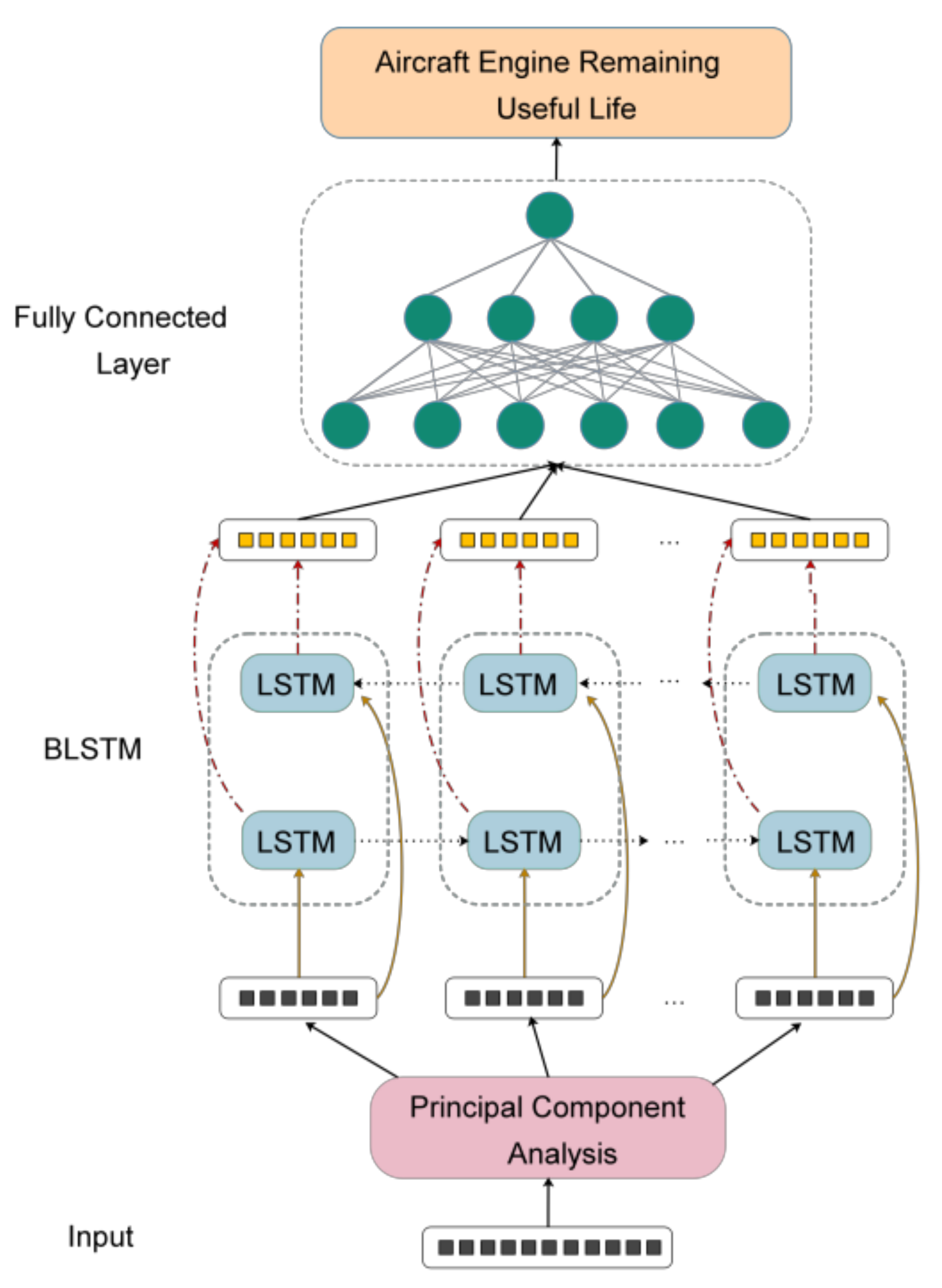
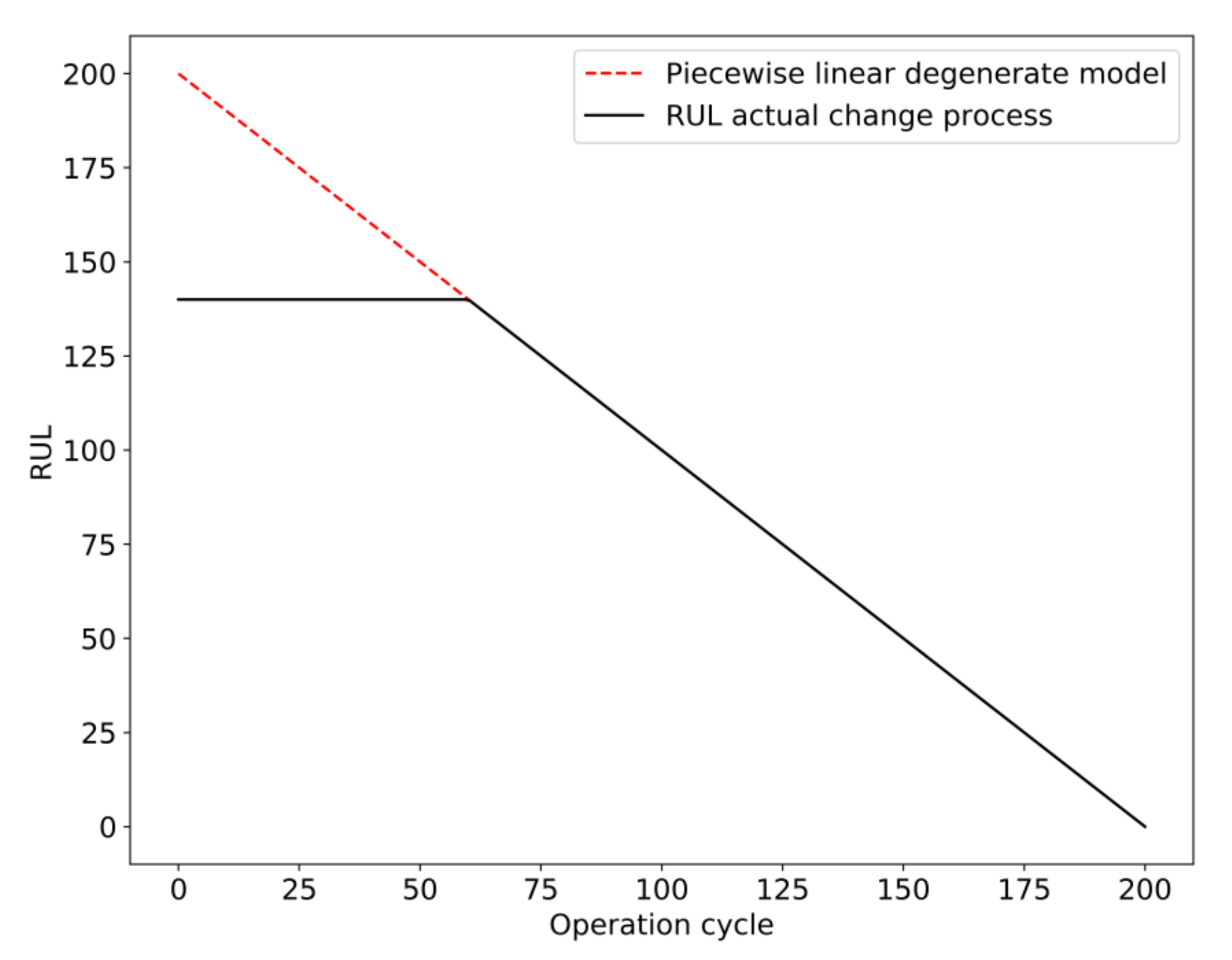
2.3. PCA–BLSTM Model Construction
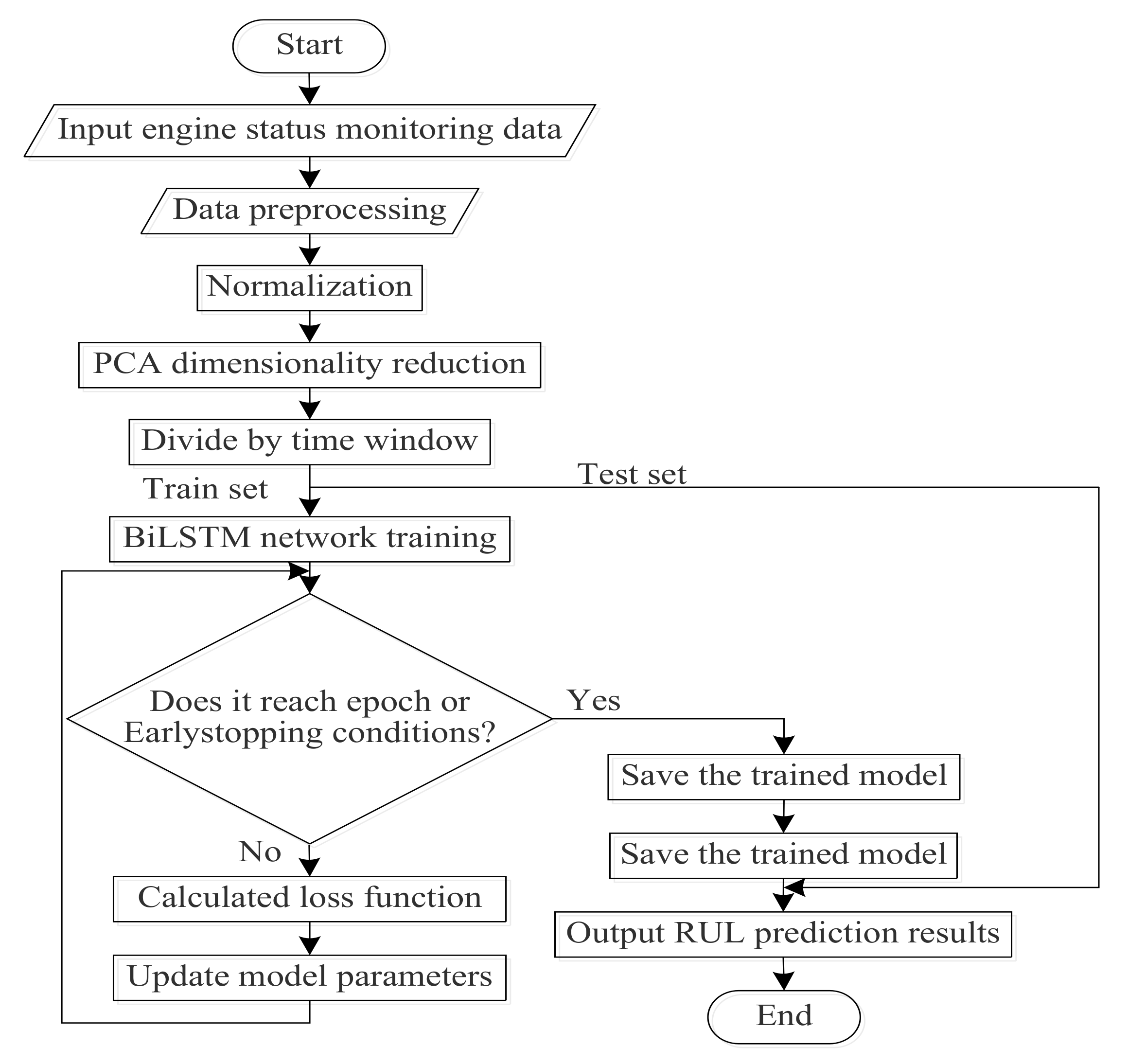
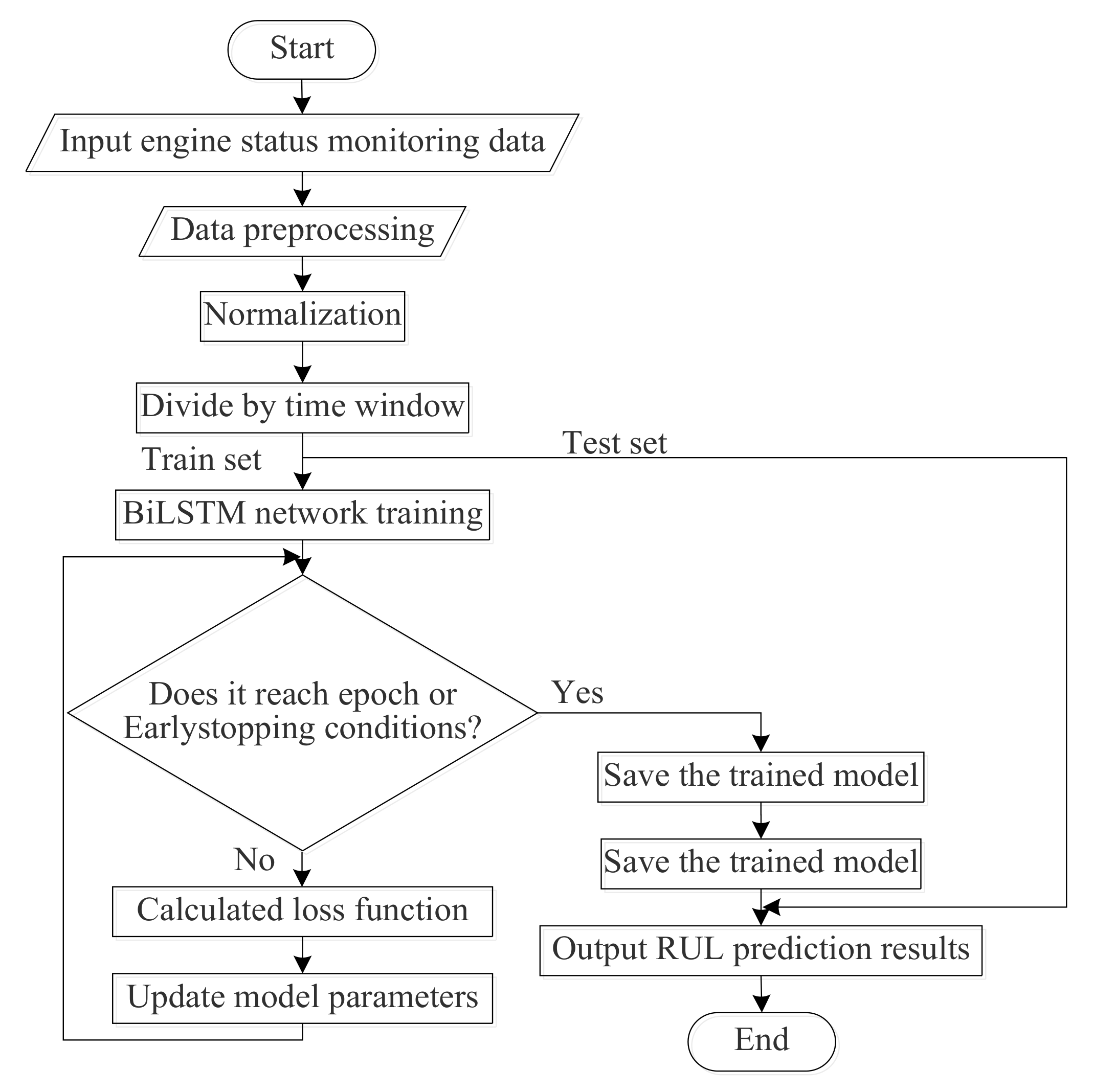
2.4. Training Process
3. Experimental Verification
3.1. Introduce NASAC-MAPSS
3.2. Data Set Validation
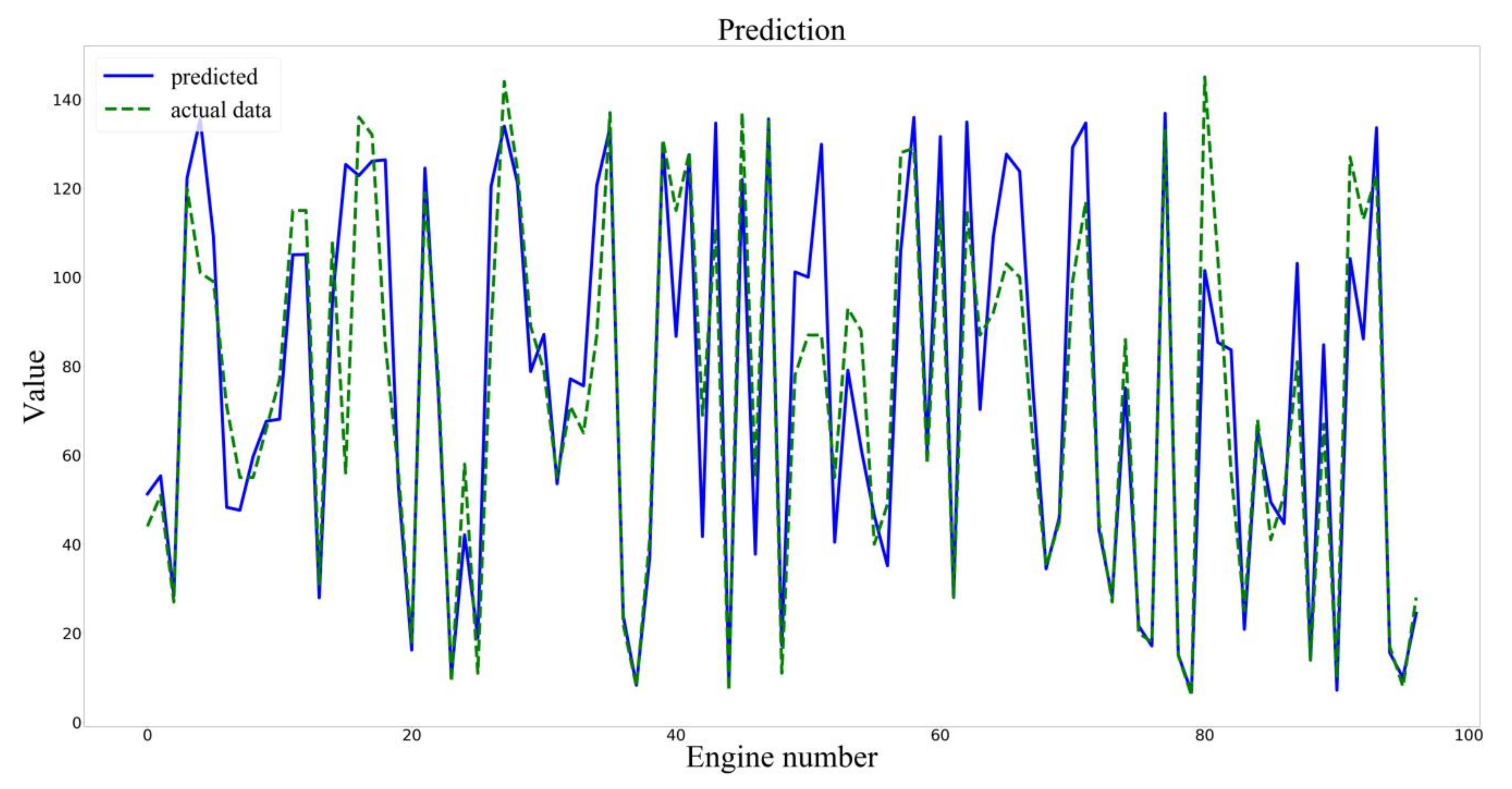
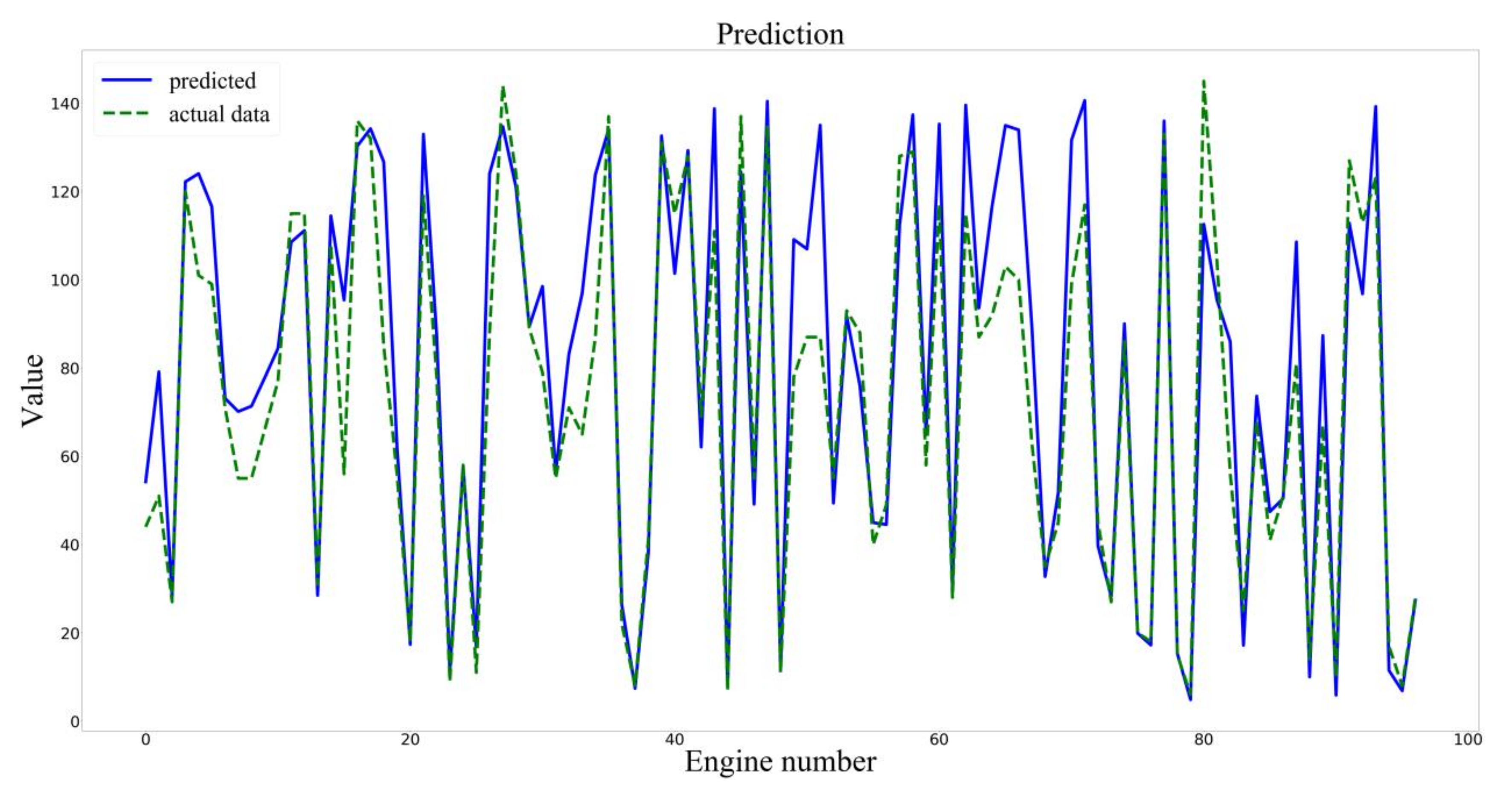
4. Comparison of Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Heng, A.; Zhang, S.; Tan, A.C.; Mathew, J. Rotating machinery prognostics: State of the art, challenges and opportunities. Mech. Syst. Sig. Process. 2009, 23, 724–739. [Google Scholar] [CrossRef]
- Wei, Y. The Research of Projective Nonnegative Matrix Factorization and application in Machine Remain Useful Life Prediction. Master’s Thesis, Shanghai Jiao Tong University, Shanghai, China, 2014. [Google Scholar]
- Chen, H.; Jiang, B. A Review of Fault Detection and Diagnosis for the Traction System in High-Speed Trains. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1–16. [Google Scholar] [CrossRef]
- Meng, L.; Xu, A. Prediction of Residual Life of a Multivariate Airborne Electromechanical System. Ship Electron. Eng. 2018, 38, 109–113. [Google Scholar]
- Ju, J.; Hu, S.; Zhu, C.; Xu, Y. Fault Prediction Method Based on Improved SVM Algorithm. Electron. Opt. Control. 2018, 25, 6–9. [Google Scholar]
- Yuan, N.; Yang, H.; Fang, H. Aero-engine Prognostic Method Based on Convolutional Neural Network. Comput. Meas. Control. 2019, 27, 74–78. [Google Scholar]
- Tang, X.; Xu, W.; Tan, J.; Tan, Y. Prediction for remaining useful life of rolling bearings based on Long Short-Term Memory. J. Mach. Des. 2019, 36, 117–119. [Google Scholar]
- Zeng, H.; Guo, J. Fault Prognostic of Aeroengine Using Bidirectional LSTM Neural Network. J. Air Force Eng. Univ. Nat. Sci. Ed. 2019, 20, 26–32. [Google Scholar]
- Ge, Y.; Guo, L.; Niu, S.; Dou, Y. Prediction of remaining useful life based on t-SNE and LSTM for rotating machinery. J. Vib. Shock. 2020, 39, 223–231. [Google Scholar]
- Kang, S.; Zhou, Y.; Wang, Y.; Xie, J.; Mikulovich, V.I. Rolling Bearing RUL Prediction Method Based on Improved SAE and Bidirectional LSTM. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?doi=10.16383/j.aas.c190796 (accessed on 11 August 2020).
- Song, Y.; Xia, T.; Zheng, Y.; Zhuo, P.; Pan, E. Remaining useful life prediction of turbofan engine based on Autoencoder-BLSTM. Comput. Integr. Manuf. Syst. 2019, 25, 1611–1619. [Google Scholar]
- Li, Y.; Li, T.; Liu, H. Recent advances in feature selection and its applications. Knowl. Inf. Syst. 2017, 53, 1–27. [Google Scholar] [CrossRef]
- Cunningham, J.P.; Ghahramani, Z. Linear dimensionality reduction: Survey, insights, and generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Ting, D.; Jordan, M.I. On Nonlinear Dimensionality Reduction, Linear Smoothing and Autoencoding. arXiv 2018, arXiv:1803.02432. [Google Scholar]
- Bianchi, F.M.; De Santis, E.; Rizzi, A.; Sadeghian, A. Short-Term Electric Load Forecasting Using Echo State Networks and PCA Decomposition. IEEE Access 2015, 3, 1931–1943. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Ramasso, E. Investigating computational geometry for failure prognostics. Int. J. Progn. Health Manag. 2014, 5, 1–18. [Google Scholar]
- Arcos-Garcia, A.; Alvarez-Garcia, J.A.; Soria-Morillo, L.M. Deep neural network for traffic sign recognition systems: An analysis of spatial transformers and stochastic optimisation methods. Neural Netw. 2018, 99, 158–165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shan, K. Research on Engine Fault Prediction Method Based on Deep Learning. Master’s Thesis, Civil Aviation University of China, Tianjin, China, 2019. [Google Scholar]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage Propagation Modeling for Aircraft Engine Run-to-Failure Simulation. In Proceedings of the 1st International Conference on Prognostics and Health Management (PHM08), Denver, CO, USA, 6–9 October 2008. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.; Gupta, C. Long Short-Term Memory Network for Remaining Useful Life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 88–95. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Number of Engines in Training Set | Number of Engines in Test Set | Types of Working Conditions | Type of Failure | Number of Sensors | Type of Working Condition Parameters |
|---|---|---|---|---|---|---|
| FD003 | 100 | 100 | 1 | 2 | 21 | 3 |
| Principal Component Sequence | Eigenvalue | Contribution Rate | Cumulative Contribution Rate |
|---|---|---|---|
| 1 | 3659.51 | 0.3787 | 0.3787 |
| 2 | 2469.95 | 0.2556 | 0.6342 |
| 3 | 1264.72 | 0.1309 | 0.7651 |
| 4 | 616.37 | 0.0638 | 0.8289 |
| 5 | 402.09 | 0.0416 | 0.8705 |
| 6 | 190.44 | 0.0197 | 0.8902 |
| 7 | 174.23 | 0.018 | 0.9082 |
| 8 | 165.91 | 0.0172 | 0.9254 |
| 9 | 141.84 | 0.0147 | 0.94 |
| 10 | 116.44 | 0.012 | 0.9521 |
| 11 | 93.17 | 0.0096 | 0.9617 |
| 12 | 89.98 | 0.0093 | 0.971 |
| 13 | 83.77 | 0.0087 | 0.9797 |
| 14 | 76.8 | 0.0079 | 0.9877 |
| 15 | 61.47 | 0.0064 | 0.994 |
| 16 | 35.34 | 0.0037 | 0.9977 |
| 17 | 7.79 | 0.0008 | 0.9985 |
| 18 | 7.42 | 0.0008 | 0.9992 |
| 19 | 7.3 | 0.0008 | 1 |
| Parameter | Value |
|---|---|
| Degradation threshold | 140 |
| Units in the first layer of BLSTM | 100 |
| Units in the second layer of BLSTM | 100 |
| Units in the first layer of the full connection layer | 30 |
| Units on the second layer of the full connection layer | 1 |
| Dropout | 0.2 |
| Bitch | 100 |
| Parameter | Value |
|---|---|
| Degradation threshold | 140 |
| Units in the first layer of BLSTM | 100 |
| Units in the second layer of BLSTM | 50 |
| Units of the full connection layer | 1 |
| Dropout | 0.2 |
| Bitch | 200 |
| Parameter | Value |
|---|---|
| Degradation threshold | 140 |
| Units in the first layer of BLSTM | 100 |
| Units in the second layer of BLSTM | 50 |
| Units in the first layer of the full connection layer | 30 |
| Units on the second layer of the full connection layer | 1 |
| Dropout | 0.2 |
| Bitch | 100 |
| Model | RMSE | Score |
|---|---|---|
| SVR | 25.69 | 52.84 |
| LSTM | 11.99 | 15.22 |
| BLSTM | 11.65 | 6.69 |
| PCA–BLSTM | 11.1 | 4.49 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, S.; Han, X.; Hou, Y.; Song, Y.; Du, Q. Remaining Useful Life Prediction of Airplane Engine Based on PCA–BLSTM. Sensors 2020, 20, 4537. https://doi.org/10.3390/s20164537
Ji S, Han X, Hou Y, Song Y, Du Q. Remaining Useful Life Prediction of Airplane Engine Based on PCA–BLSTM. Sensors. 2020; 20(16):4537. https://doi.org/10.3390/s20164537
Chicago/Turabian StyleJi, Shixin, Xuehao Han, Yichun Hou, Yong Song, and Qingfu Du. 2020. "Remaining Useful Life Prediction of Airplane Engine Based on PCA–BLSTM" Sensors 20, no. 16: 4537. https://doi.org/10.3390/s20164537
APA StyleJi, S., Han, X., Hou, Y., Song, Y., & Du, Q. (2020). Remaining Useful Life Prediction of Airplane Engine Based on PCA–BLSTM. Sensors, 20(16), 4537. https://doi.org/10.3390/s20164537