Although the concept of smart city (SC) was coined more than twenty years ago [
1], nowadays it has a wide range of semantic interpretations and covers different meanings, which include many viewpoints of professionals and institutions involved [
2]. Commonly, a SC is considered as an urban space where Information and Communication Technologies (ICT) are intensively applied to improve the quality and performance of urban services such as transportation, energy, water, infrastructures and other services (e.g., public safety) in order to reduce resource energy consumption, wastage and overall costs. The application of the best strategies, resources and available technologies to the SC environments will continuously improve the quality of life of their citizens and also the operational efficiency of these complex urban systems.
Physical and, specially, digital advertisements are becoming more common than ever in smart cities. Out-of-home (also called outdoor) advertising continues to be very effective nowadays. The deployment and maintenance of such publicity infrastructures (including their support platforms) need funds from city governments, which are mainly paid by commercial brands in order to make more visible the products and services offered. Ads have a clear impact on SCs and people notice that outdoor advertising (such as posters, billboards and digital screens) have a positive influence on them [
3]. Many citizens admitted that they still have a dependence on such advertising types to know about brands and to make their buying preferences. Moreover, in their opinion, these ads contribute in making the cities appear renewed and more colorful.
The outdoor advertising industry has experienced an important growth in recent years [
4]. In streets of urban environments, ads panels and billboards are everywhere, and they are also the only media that drivers and pedestrians cannot escape (i.e., differently from other forms of publicity, outdoor advertising cannot be “blocked by people”). In consequence, this is one of the most cost-effective forms of advertising available. Moreover, since current smartphones are equipped with a variety of embedded sensors like cameras, GPS or 3G/4G/5G, it is possible to get closer to the final user via a variety of Augmented Reality (AR) applications [
5]. This way, the citizens using their smartphones can better develop and, perhaps, enjoy the contents associated with urban advertisements. Moreover, with the emergence of digital billboards/panels, the outdoor advertising industry is even more valuable since going digital gives advertisers the flexibility to schedule short and long-term publicity campaigns.
Advertising panels are a type of urban furniture that commonly presents a normalized shape and a more reduced size than billboards. Publicity panel detection in images offers important advantages both in the real world as well as in the virtual world. In the first case, after detection of panels, it is possible to recognize the product included in the publicity and get more information about it through AR applications. Moreover, it is possible to analyze whether or not the information of a product advertised is currently updated. In addition, a brand can use this technology to analyze the campaigns of potential competitors. Regarding the publicity on the Internet, in urban scenes, and in applications like Google Street View, it would be possible, when detecting panels on these images, to replace the publicity that appears inside a panel by another one proposed by a paying company.
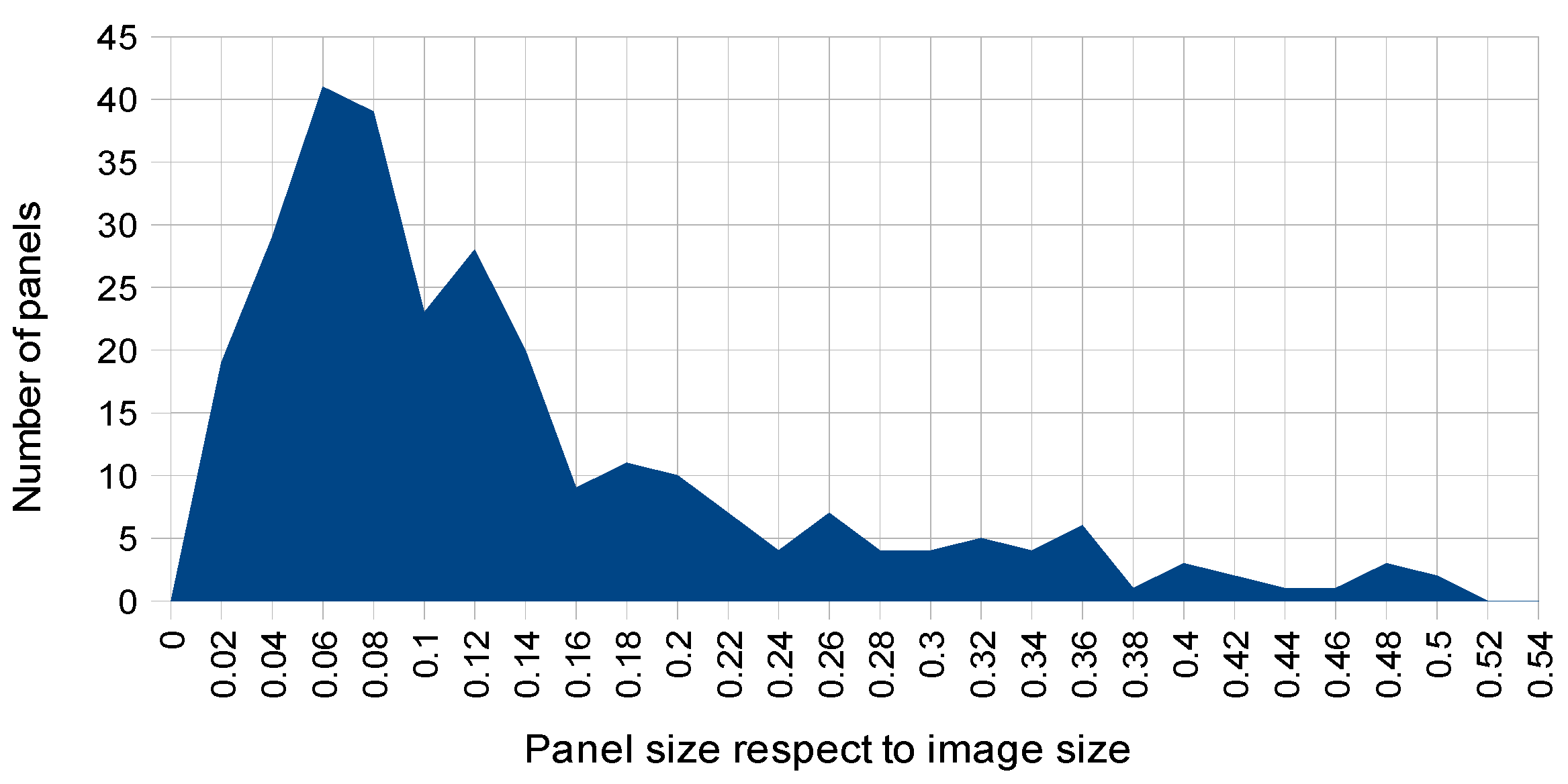
Automatic outdoor detection and localization of OPPI ads panels (named as ‘panels’ for brevity) in real urban outdoor images is a difficult task due to multiple variability conditions presenting in the scenes containing them. For example, variable weather conditions (sunny vs. cloudy), illumination conditions (natural vs. artificial), panel perspective view, size ratio of panels with respect to image size, partial occlusions of panels or complex background in the scene (i.e., presence of multiple elements surrounding the panels like buildings, shadows, vehicles and/or different infrastructures), among other factors.
Some of the motivations of the present work are as follows: (1) accurately detecting the panels is a previous stage to analyze the content of the publicity included on them; (2) after detecting the panels it is important to classify and count the types of publicity offered by each brand in a geographical area for market prospective purposes; (3) by analyzing the contents of detected panels it is also possible to measure the “impact” of a publicity campaign; (4) for the case of “virtual” publicity on the Internet, it is possible to update the panel contents for apps like Street View or similar ones which allows providing targeted advertisements for the customers; and, finally, (5) there is an interest of companies to evaluate the quality of “physical” support of the panels to repair or substitute them. Next, we analyze the previous work related to this study and then summarize the proposed approach and its main contributions.
1.1. Related Work
Visual detection and recognition problems applied to specific elements in outdoor images have been previously investigated in the literature. For example, this is the case of vehicle localization [
6], traffic sign detection [
7] or car plates [
8]. Another related problem which resembles the considered one is the detection of solar panel structures (and their orientations) in images of photovoltaic plants with no lighting restrictions, and using texture features combined with image processing techniques [
9]. Some other related applications to be considered here are text and objects detection inside segmented billboard images [
10] or the localization of billboards on streamed sport videos [
11]. Another investigated problem is the insertion of virtual ads in street images based on localization of specific regions on them (e.g., buildings facades) [
5]. Hussain et al. in [
12] more recently have worked on how to build vision systems so they can understand ads, and these authors have presented a solution for automatically understanding the advertisement content.
The problem of text detection in natural scene images has also received attention in recent years (see the recent survey by Liu et al. [
13]). Text detection and recognition in outdoor scenes is a key component of many content-based image analysis applications, for example the indexation of shops in a street. There are also actual conference competitions (like the one in ICDAR 2019 [
14]) on the specific topic of scene text detection and recognition. Yin et al. [
15] extract Maximally Stable Extremal Regions (MSERs) as character candidates which are grouped into text candidates by a clustering algorithm where parameters are learned automatically by a self-training distance metric algorithm. An effective method for scene text detection and segmentation based on cascaded Convolutional Neural Networks (CNN) is proposed by Tang et al. [
16]. More recently, Xie and collaborators [
17] have published a method based on Feature Pyramid Network (FPN) and instance segmentation to precisely locate text regions while suppressing false positives.
However, as far as we know, there are very few published works on detecting outdoor ads panels using a modern deep learning approach. Recently, Hossari et al. [
18] have proposed the deep learning architecture ADNet, inspired in VGG19 model that automatically detects the presence of billboards with advertisements in video frames of outdoor scenes. ADNet uses the pre-trained weights of the VGG network, trained on the ImageNet dataset. After that, they re-trained the network with images of a composite dataset from Mapillary Vistas [
19] and Microsoft COCO (MS-COCO) datasets [
20], and achieved good test accuracy in detections.
These same authors in 2019 have also published a related work [
21] for automatically detecting existing billboards in videos and replacing the advertisements contained in them with new ones. The interest is focused in learning candidate placement of billboards in outdoor scenes in order to place regularly shaped billboards in street view images. Three types of semantic segmentation networks were used in detection experiments: Fully Convolutional Network (FCN) [
22], Pyramid Scene Parsing Network (PSP-Net) [
23], and U-Net [
24], respectively. Experimental results were evaluated using metrics derived from pixel accuracy and Intersection over Union (IoU) metrics.
Previous works on billboard detection [
18,
21] have considered the detection problem as a semantic segmentation one, where classification and localization was performed at the level of image pixels. Moreover, the authors have used specific deep learning networks for such a semantic segmentation task. Although semantic segmentation can be employed for the detection of billboards, from the application perspective, the annotation of images semantic segmentation is much more time-consuming, which makes it challenging for collecting large datasets. Another point is that basic detection metrics for analysis such as True Positives (TP), False Positives (FP) or False Negatives (FN) make more sense and should be redefined at the “object” level (i.e., the billboards and panels) and not at the pixel level.
Deep learning is machine learning with deep artificial neural networks [
25]. The essence of deep learning is the application to learning problems of artificial neural networks that contain many hidden layers. In recent years, deep learning has been applied to many scientific domains and, in particular to image recognition problems where it has drastically improved the performance of other previous machine-learning techniques [
26].
Convolutional Neural Networks (CNN) [
27] are supervised shallow neural networks composed by sequences of convolutional layers followed by max-pooling layers, and so on (used for feature learning), which is followed by a fully-connected network (used for classification). Differently from previous networks like Multilayer Perceptrons where features were hand-crafted, CNN are also able to efficiently learn robust and high-level feature representations of images along the training process. Due to the impressive success of AlexNet in 2012 on the ImageNet challenge [
27], CNNs have started to be used for many diverse image processing applications. AlexNet presented significant improvements upon previous image classification methods: ReLU activation function for reducing the effect of gradient vanishing during backpropagation, use of GPUs for accelerating the overall training process, data augmentation to increase the training dataset, and “dropout” (i.e., dropping out a percentage of neuron units, both hidden and visible) for reducing overfitting. In recent years, numerous deeper CNN models have appeared presenting specific refinements over previous architectures. Among these CNN-based models it is worth noting the following ones: Visual Geometry Group (VGG) networks [
28] make the improvement over AlexNet by replacing large kernel-sized filters with multiple much smaller ones, one after another; GoogleNet [
29] which introduced Inception layers, which can apply in parallel convolutions of different sizes to capture details at varied scales; and ResNet [
30] which makes possible the stacking of layers without degrading the network performance, among others.
Object detection is a challenging task in Computer Vision that has received large attention in last twenty years, especially with the development of Deep Learning [
31,
32]. It presents many applications related with video surveillance, automated vehicle system robot vision or machine inspection, among many others [
26,
31]. The problem consists in recognizing and localizing some classes of objects present in a static image or in a video. Recognizing (or classifying) means determining the categories (from a given set of classes) of all object instances present in the scene together with their respective network confidence values on these detections. Localizing consists in returning the coordinates of each bounding box containing any considered object instance in the scene. The detection problem is different from (semantic) instance segmentation where the goal is identifying for each pixel of the image the object instance (for every considered type of object) to which the pixel belongs. Some difficulties in the object detection problem include aspects such as geometrical variations like scale changes (e.g., small size ratio between the object and the image containing it) and rotations of the objects (e.g., due to scene perspective the objects may not appear as frontal); partial occlusion of objects by other elements in the scene; illumination conditions (i.e., changes due to weather conditions, natural or artificial light); among others but not limited to these ones. Note that some images may contain several combined variabilities (e.g., small, rotated and partially occluded objects). In addition to detection accuracy, another important aspect to consider is how to speed up the detection task.
Neural-based object detectors [
31] have produced, along their evolution, a state-of-the-art performance on main datasets for such a purpose. These detectors are commonly classified in two categories: two-stage detectors and one-stage detectors, respectively. The first type uses a Region Proposal Network to generate regions of interests in the first stage and then send these region proposals to the pipeline for object classification and bounding-box regression. These network models produce higher accuracy rates but are usually slower. Faster R-CNN (Region-based Convolutional Neural Networks) and Mask R-CNN are networks belonging to this group.
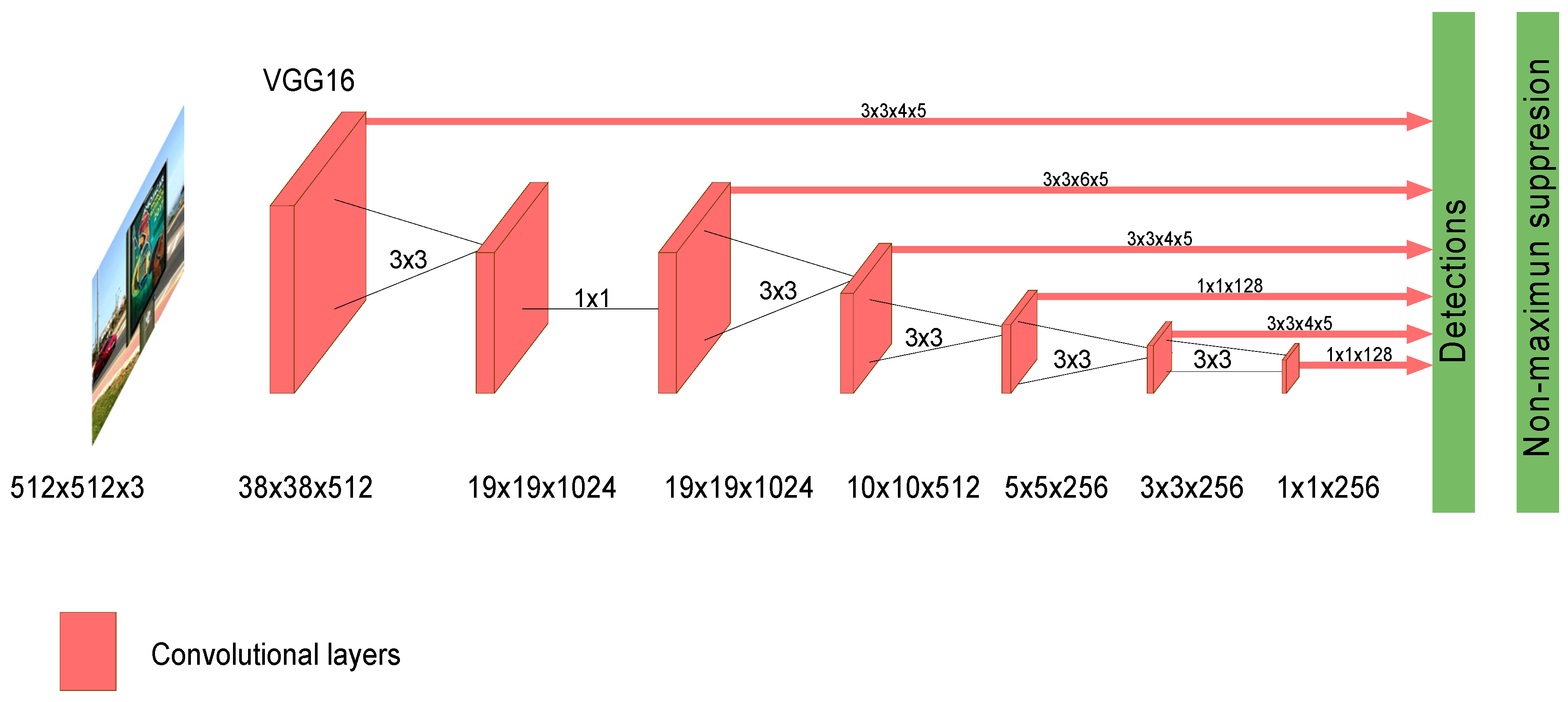
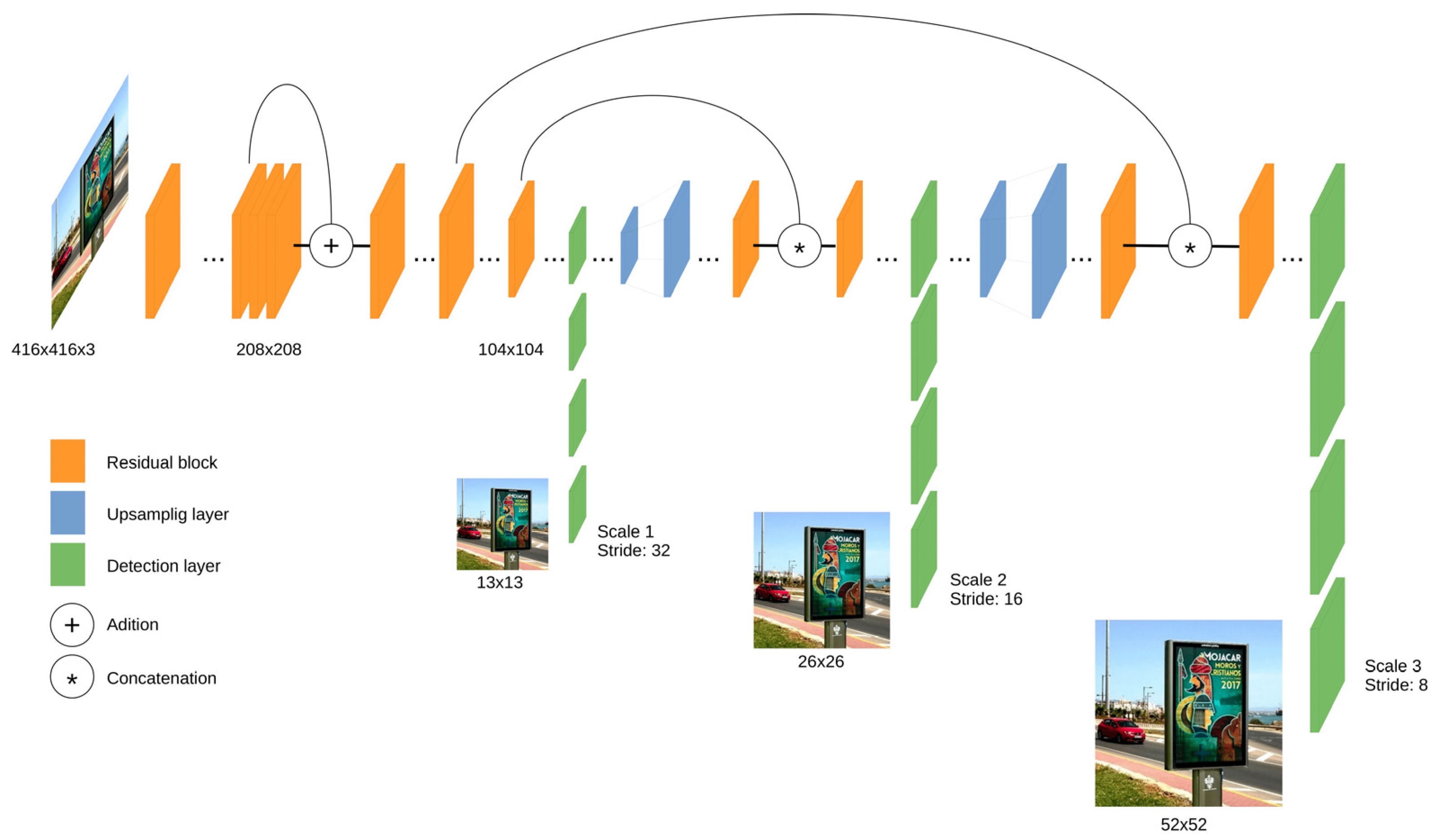
On the other hand, one-stage detectors handle the object detection as a regression problem by taking an input image and learning simultaneously the class probabilities and bounding box coordinates. These models initially produced lower accuracy rates but were much faster than two-stage object detectors. SSD (Single Shot MultiBox Detector) and YOLO (You Only Look Once) are included in this one-stage group.
1.2. Outline and Contributions of This Work
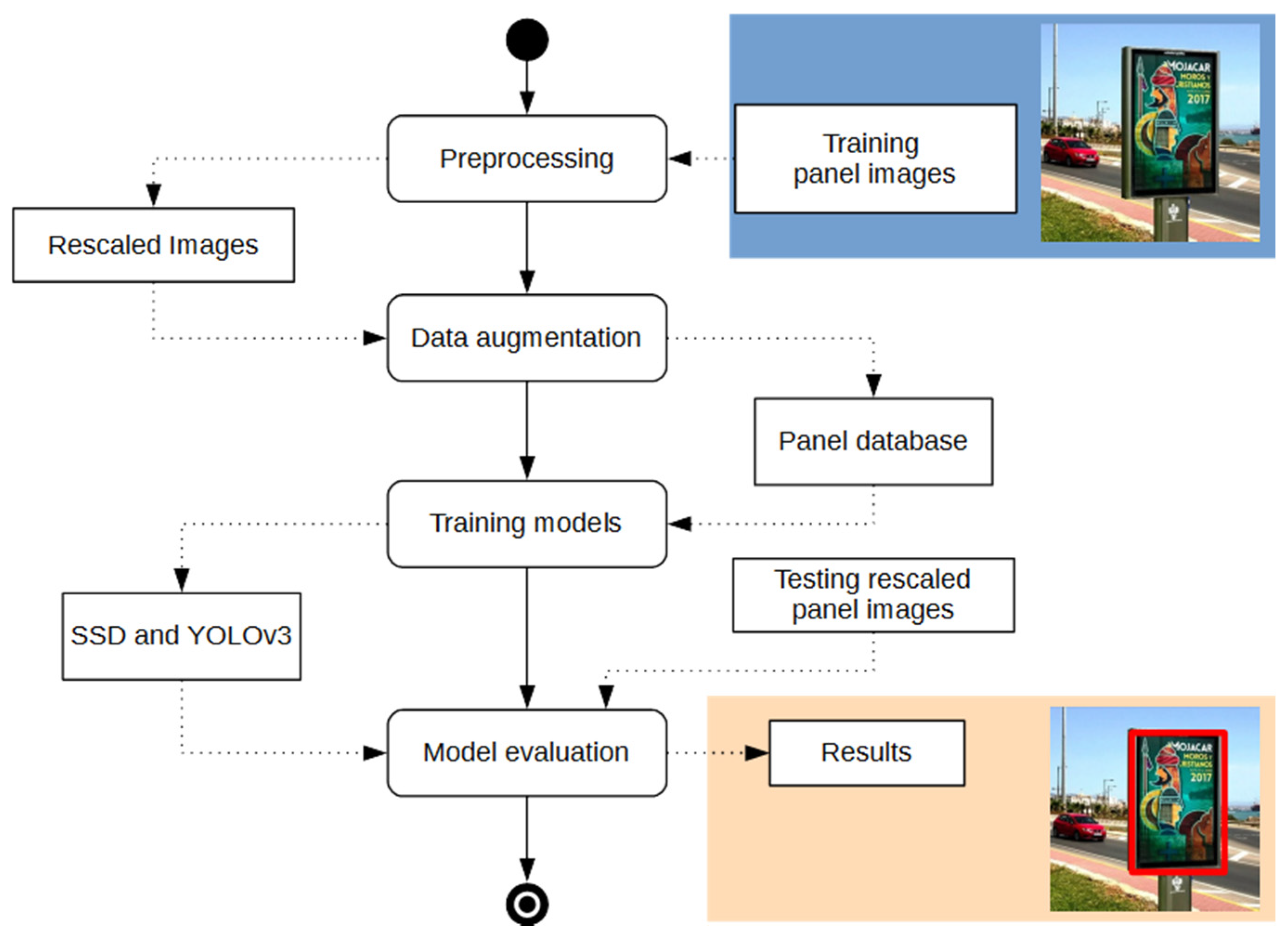
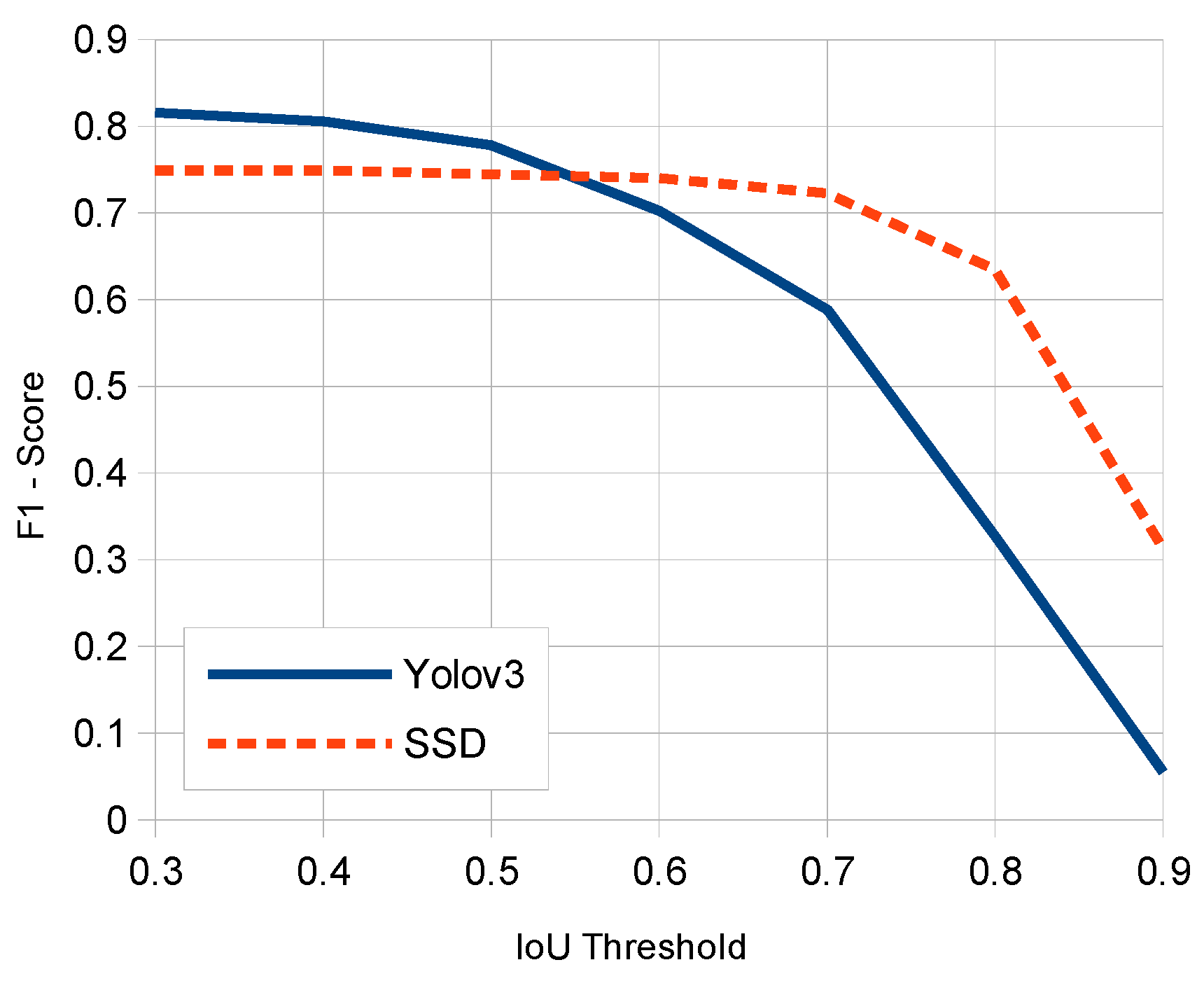
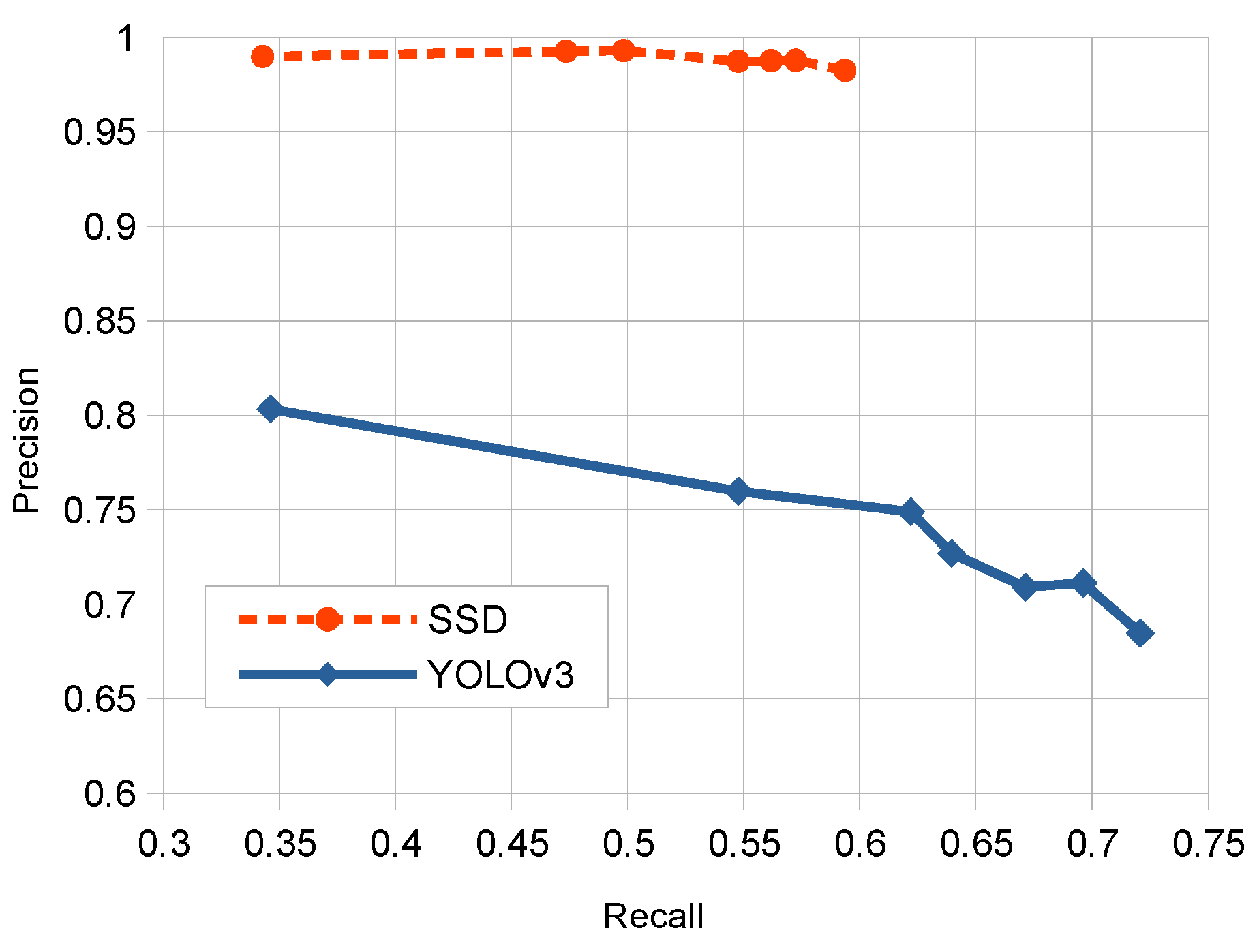
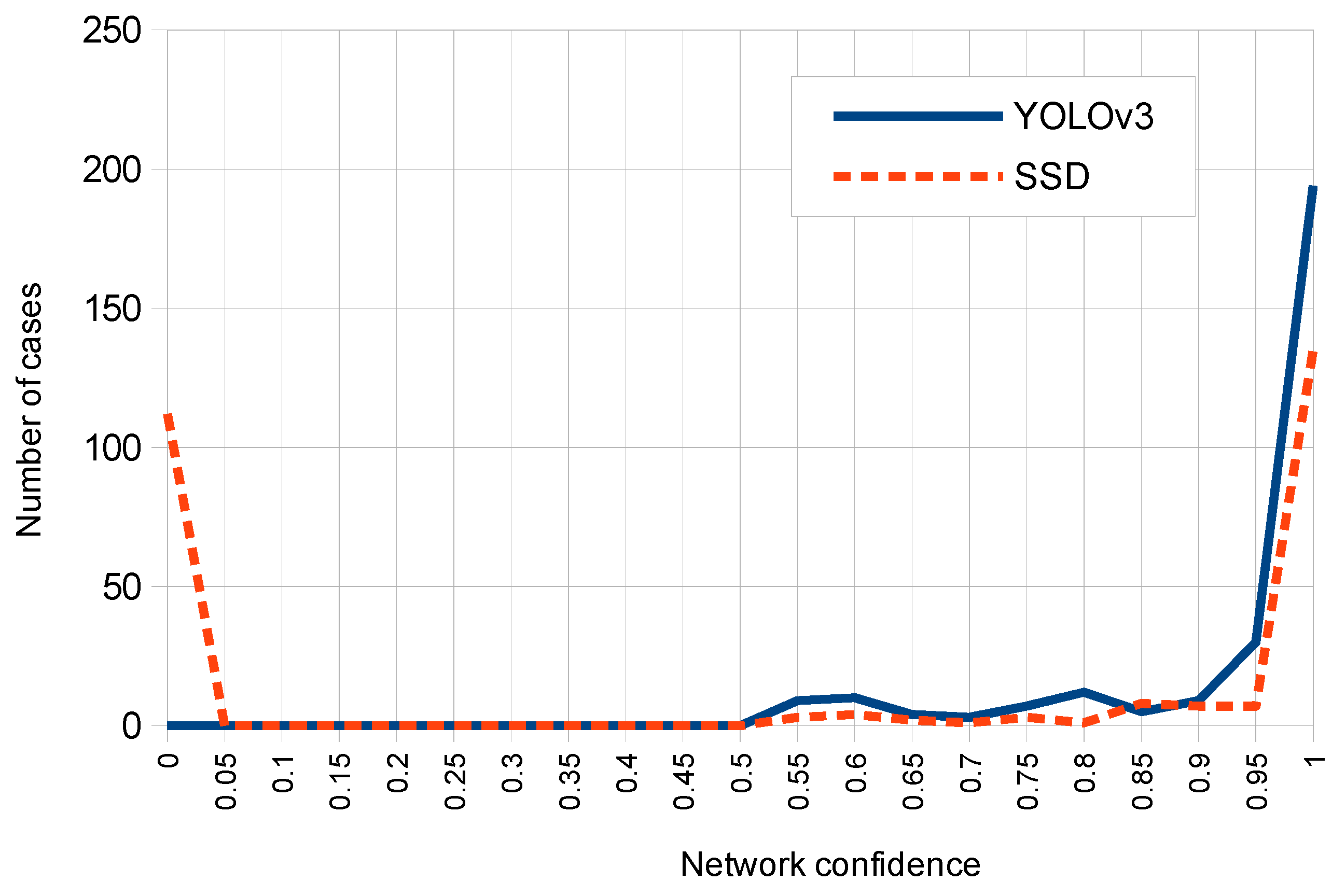
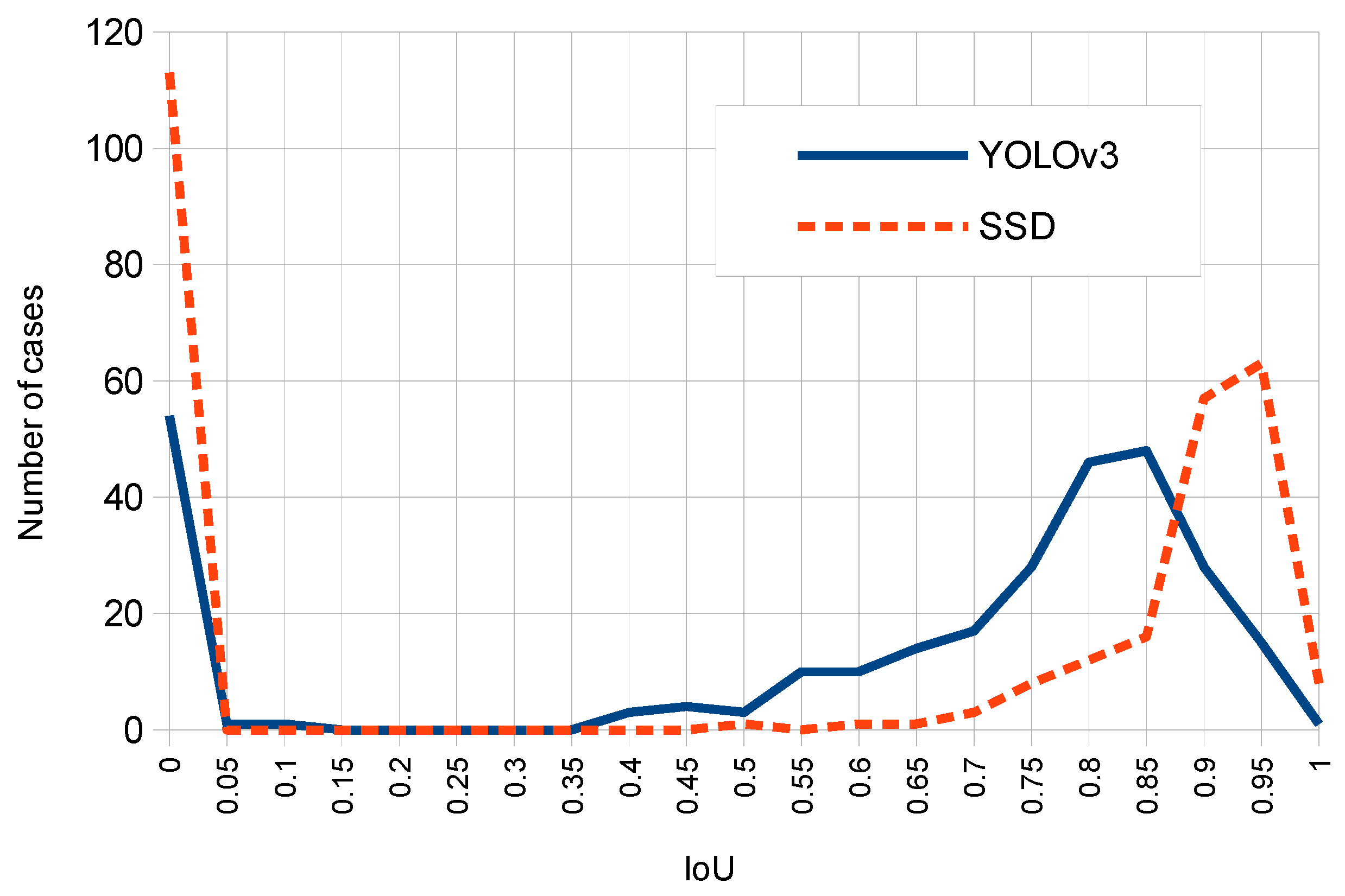
This work presents robust solutions which work at the “object” level, and using specific object detection networks for an automatic localization of panels in outdoor images. More specifically we experimented with two detectors: Single Shot MultiBox Detector (SSD) and You Only Look Once (YOLO), which were systematically compared for the considered problem. These detection networks produce rectangular windows as output with the approximate detection of each panel instance in the images together with an associate network confidence on this detection. The performance of these detectors is compared to discover the strengths and weaknesses of each one on the considered problem. For such purpose, we have properly redefined TP, FP and FN metrics at ‘panel’ level. Additional evaluation measures were used for comparison purposes. Moreover, due to the lack of available datasets of annotated OPPI panel images, we have created our own dataset which will be available for research purposes.
The paper describes a detailed experimental comparative study on the application of SSD and YOLOv3 for the considered problem in practical conditions. The main contributions of this work are the following ones:
Experimental comparative study of deep one-stage detector networks applied to the outdoor OPPI panel detection problem. SSD and YOLO detectors are compared under multiple variability conditions (panel sizes, occlusions, rotations, and illumination conditions) to show the pros and cons of each model.
Comparison with semantic segmentation networks for a similar problem and under the same evaluation metrics.
Creation of an annotated dataset for this problem available to other researchers.
The manuscript is organized as follows.
Section 2 introduces the materials and methods used in this research on detection of outdoor ads panels.
Section 3 describes the experimental setup and presents the results achieved for the considered problem.
Section 4 analyzes and discusses these results. Finally, in
Section 5 we summarize the conclusions of the work.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}