Convolutional Neural Networks-Based Object Detection Algorithm by Jointing Semantic Segmentation for Images

 ,
,  , , and
, , and
Abstract
:1. Introduction
- Object detection not only needs to maintain a high detection accuracy, but also has certain requirements for detection speed. However, most of the existing algorithms have slow detection speeds and cannot keep up with the playback speed of the video stream, which may cause the detection of important frames to be missed.
- Overlap and occlusions in the image may cause false detection.
- Objects often appear in complex backgrounds, which will cause interference and make detection difficult.
- We inherit the idea of one-stage target detection algorithm, and the entire model adopts the network structure in the form of full convolution to ensure the detection speed is fast enough.
- We use the hourglass structure to generate multi-scale features with high-level semantic information, which enables the algorithm to detect small-scale objects more effectively, and we use semantic segmentation as an auxiliary task for object detection to extract more detailed features with pixel-level semantic segmentation to better detect partially occluded objects.
- We use the attention mechanism to make the model pay more attention to the object, reduce the influence of the image background without causing model degradation.
- The experimental results show that our algorithm substantially enhances object detection performance and consistently outperforms other comparison algorithms, and the detection speed can reach real-time, which can be used for real-time detection.
2. Materials and Methods
2.1. Framework
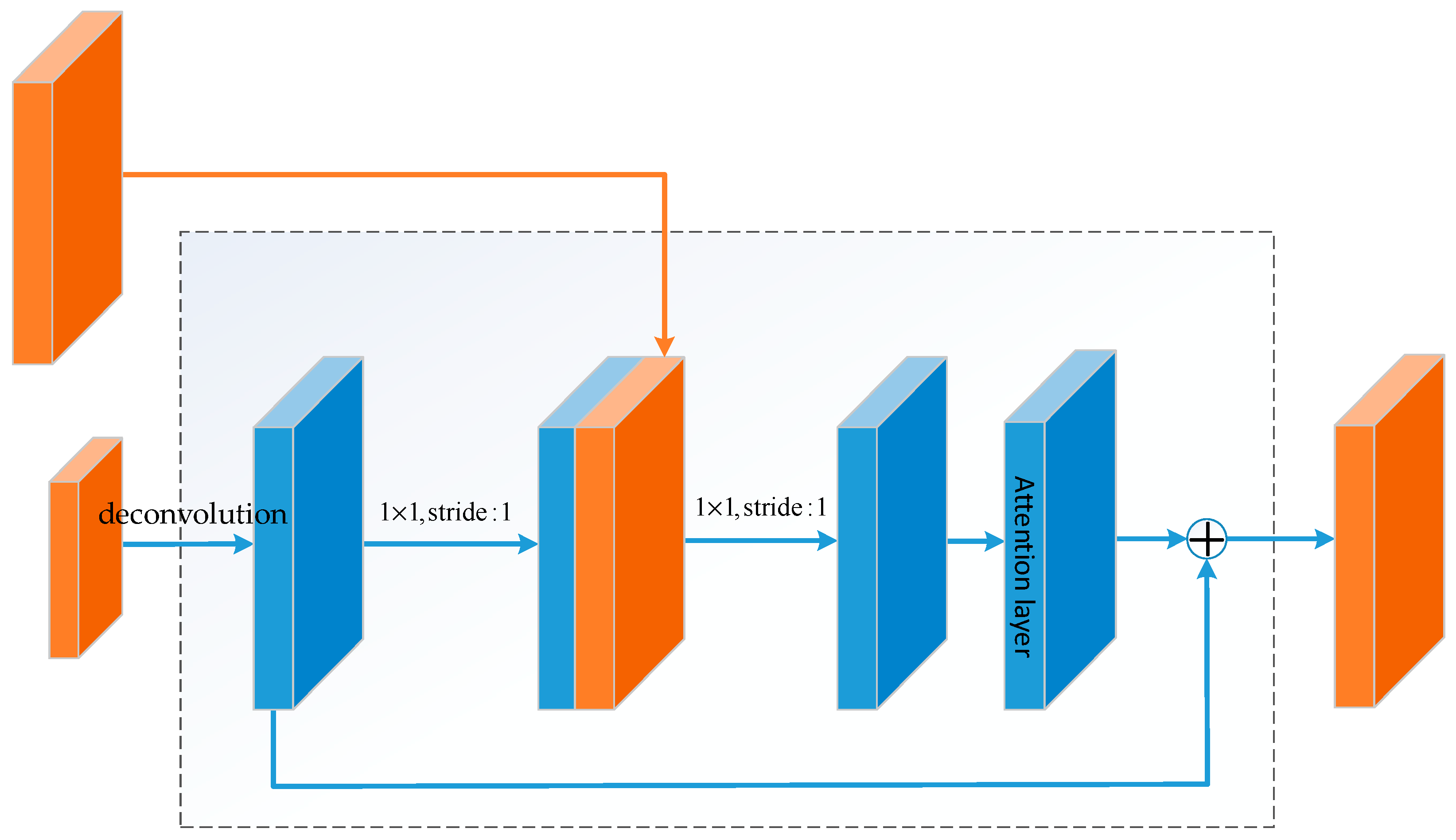
2.2. Feature Extraction
2.3. Semantic Segmentation Branch
2.4. Prediction Part
2.5. Summary of the Proposed Algorithm
| Algorithm 1 Entire process of the proposed algorithm | ||
| 1: | Initialization: | Parameters of the semantic segmentation branch; |
| Parameters of the prediction part; | ||
| mini-batch size . | ||
| 2: | update until convergence: | |
| 3: | for k step do | |
| 4: | Randomly sample points to construct a mini-batch. | |
| 5: | For each sampled point in the mini-batch, calculate Equations (1), (2), and (5) using forward propagation. | |
| 6: | Calculate the derivatives and by Adam algorithm [35]. | |
| 7: | Update the parameters and using backpropagation. | |
| 8: | end for | |
3. Experiment
3.1. Experimental Setting
3.2. Comparison of State-of-the-Art Algorithms
3.3. Speed and Performance
3.4. Further Analysis
3.4.1. Comparison of the Variant Algorithms
3.4.2. Speed and Performance
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cvar, N.; Trilar, J.; Kos, A.; Volk, M.; Stojmenova Duh, E. The Use of IoT Technology in Smart Cities and Smart Villages: Similarities, Differences, and Future Prospects. Sensors 2020, 20, 3897. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Duan, J.; Zhong, M.; Li, P.; Wang, J. VNF Chain Placement for Large Scale IoT of Intelligent Transportation. Sensors 2020, 20, 3819. [Google Scholar] [CrossRef] [PubMed]
- Qiang, B.; Zhang, S.; Zhan, Y.; Xie, W.; Zhao, T. Improved Convolutional Pose Machines for Human Pose Estimation Using Image Sensor Data. Sensors 2019, 19, 718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borghgraef, A.; Barnich, O.; Lapierre, F.; van Droogenbroeck, M.; Philips, W.; Acheroy, A. An Evaluation of Pixel-Based Methods for the Detection of Floating Objects on the Sea Surface. EURASIP J. Adv. Signal Process. 2010, 33, 434–451. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.-C.; Yang, C.-Y.; Huang, D.-Y. Robust real-time ship detection and tracking for visual surveillance of cage aquaculture. J. Vis. Commun. Image Represent. 2011, 22, 543–556. [Google Scholar] [CrossRef]
- Shi, G.; Suo, J.; Liu, C.; Wan, K.; Lv, X. Moving target detection algorithm in image sequences based on edge detection and frame difference. In Proceedings of the 2017 IEEE 3rd Information Technology and Mechatronics Engineering Conference, Chongqing, China, 3–5 October 2017; pp. 740–744. [Google Scholar]
- Kang, Y.; Huang, W.; Zheng, S. An improved frame difference method for moving target detection. In Proceedings of the 2017 Chinese Automation Congress, Jinan, China, 20–22 October 2017; pp. 1537–1541. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Zeiler, M.D.; Taylor, G.W.; Fergus, R. Adaptive deconvolutional networks for mid and high level feature learning. In Proceeding of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2018–2025. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 Ieee International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proceeding of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards accurate region proposal generation and joint object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. DSOD: Learning deeply supervised object detectors from scratch. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the 2019 IEEE/Cvf International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the 2019 IEEE/Cvf International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Shinohara, T.; Xiu, H.; Matsuoka, M. FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors 2020, 20, 3568. [Google Scholar] [CrossRef] [PubMed]
- Saez, A.; Bergasa, L.M.; Lopez-Guillen, E.; Romera, E.; Tradacete, M.; Gomez-Huelamo, C.; del Egido, J. Real-Time Semantic Segmentation for Fisheye Urban Driving Images Based on ERFNet. Sensors 2019, 19, 503. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Eom, H.; Lee, D.; Han, S.; Hariyani, Y.S.; Lim, Y.; Sohn, I.; Park, K.; Park, C. End-To-End Deep Learning Architecture for Continuous Blood Pressure Estimation Using Attention Mechanism. Sensors 2020, 20, 2338. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, F.; Wang, X.; Wang, D.; Shao, F.; Fu, L. Spatial-Semantic and Temporal Attention Mechanism-Based Online Multi-Object Tracking. Sensors 2020, 20, 1653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 816–832. [Google Scholar]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive Margin Softmax for Face Verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ponn, T.; Kröger, T.; Diermeyer, F. Identification and Explanation of Challenging Conditions for Camera-Based Object Detection of Automated Vehicles. Sensors 2020, 20, 3699. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2018. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layer | Kernel Parameter | Repeat | Output |
|---|---|---|---|
| Input | |||
| Block1 | 2 | ||
| Block2 | 4 | ||
| Block3 | 1 | ||
| Block4 | 1 | ||
| Block5 | 1 | ||
| Block6 | 1 | ||
| Block7 | 1 | ||
| Number | Category | Faster R-CNN (%) | SSD (%) | Mask R-CNN (%) | SSOD (ours) (%) |
|---|---|---|---|---|---|
| 1 | aeroplane | 84.9 | 85.6 | 86.5 | 84.3 |
| 2 | bicycle | 79.8 | 80.1 | 83.9 | 87.8 |
| 3 | bird | 74.3 | 70.5 | 77.6 | 79.4 |
| 4 | boat | 53.9 | 57.6 | 58.8 | 73.2 |
| 5 | bottle | 49.8 | 46.2 | 63.7 | 54.5 |
| 6 | bus | 77.5 | 79.4 | 80.4 | 84.3 |
| 7 | car | 75.9 | 76.1 | 78.2 | 86.1 |
| 8 | cat | 88.5 | 89.2 | 87.6 | 87.1 |
| 9 | chair | 45.6 | 53.0 | 56.0 | 60.8 |
| 10 | cow | 77.1 | 77.0 | 80.1 | 85.0 |
| 11 | dining table | 55.3 | 60.8 | 63.2 | 80.2 |
| 12 | dog | 86.9 | 87.0 | 88.0 | 86.6 |
| 13 | horse | 81.7 | 83.1 | 84.4 | 88.1 |
| 14 | motorbike | 80.9 | 82.3 | 85.7 | 84.5 |
| 15 | person | 79.6 | 79.4 | 79.9 | 79.8 |
| 16 | potted plant | 40.1 | 45.9 | 46.3 | 56.2 |
| 17 | sheep | 72.6 | 75.9 | 74.4 | 81.1 |
| 18 | sofa | 60.9 | 69.5 | 66.8 | 80.8 |
| 19 | train | 81.2 | 81.9 | 81.3 | 87.5 |
| 20 | tv/monitor | 61.5 | 67.5 | 75.0 | 80.6 |
| - | mAP | 70.4 | 72.4 | 74.9 | 79.4 |
| Algorithm | SSD | Faster R-CNN | Mask R-CNN | SSOD |
|---|---|---|---|---|
| mAP (%) | 72.4 | 70.4 | 74.9 | 79.4 |
| detection speed (fps) | 46 | 5 | 5 | 24 |
| Number | Category | SSOD-att-seg (%) | SSOD-att (%) | SSOD (%) |
|---|---|---|---|---|
| 1 | aeroplane | 88.4 | 90.1 | 84.3 |
| 2 | bicycle | 83.1 | 82.7 | 87.8 |
| 3 | bird | 75.5 | 85.2 | 79.4 |
| 4 | boat | 62.5 | 74.0 | 73.2 |
| 5 | bottle | 46.9 | 48.3 | 54.5 |
| 6 | bus | 82.5 | 90.4 | 84.3 |
| 7 | car | 79.3 | 75.2 | 86.1 |
| 8 | cat | 92.4 | 87.9 | 87.1 |
| 9 | chair | 59.2 | 51.5 | 60.8 |
| 10 | cow | 81.3 | 81.4 | 85.0 |
| 11 | dining table | 65.9 | 75.8 | 80.2 |
| 12 | dog | 90.1 | 87.3 | 86.6 |
| 13 | horse | 84.5 | 82.8 | 88.1 |
| 14 | motorbike | 86.8 | 92.0 | 84.5 |
| 15 | person | 82.5 | 84.2 | 79.8 |
| 16 | potted plant | 51.5 | 58.0 | 56.2 |
| 17 | sheep | 80.9 | 83.2 | 81.1 |
| 18 | sofa | 75.7 | 71.1 | 80.8 |
| 19 | train | 85.8 | 88.2 | 87.5 |
| 20 | tv/monitor | 72.1 | 84.9 | 80.6 |
| - | mAP | 76.4 | 78.7 | 79.4 |
| Algorithm | SSOD-att-seg | SSOD-att | SSOD |
|---|---|---|---|
| mAP (%) | 76.4 | 78.7 | 79.4 |
| detection speed (fps) | 25 | 24 | 24 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiang, B.; Chen, R.; Zhou, M.; Pang, Y.; Zhai, Y.; Yang, M. Convolutional Neural Networks-Based Object Detection Algorithm by Jointing Semantic Segmentation for Images. Sensors 2020, 20, 5080. https://doi.org/10.3390/s20185080
Qiang B, Chen R, Zhou M, Pang Y, Zhai Y, Yang M. Convolutional Neural Networks-Based Object Detection Algorithm by Jointing Semantic Segmentation for Images. Sensors. 2020; 20(18):5080. https://doi.org/10.3390/s20185080
Chicago/Turabian StyleQiang, Baohua, Ruidong Chen, Mingliang Zhou, Yuanchao Pang, Yijie Zhai, and Minghao Yang. 2020. "Convolutional Neural Networks-Based Object Detection Algorithm by Jointing Semantic Segmentation for Images" Sensors 20, no. 18: 5080. https://doi.org/10.3390/s20185080
APA StyleQiang, B., Chen, R., Zhou, M., Pang, Y., Zhai, Y., & Yang, M. (2020). Convolutional Neural Networks-Based Object Detection Algorithm by Jointing Semantic Segmentation for Images. Sensors, 20(18), 5080. https://doi.org/10.3390/s20185080