Analyzing Sensor-Based Individual and Population Behavior Patterns via Inverse Reinforcement Learning

Abstract
:1. Introduction
1.1. Background
1.2. Related Work
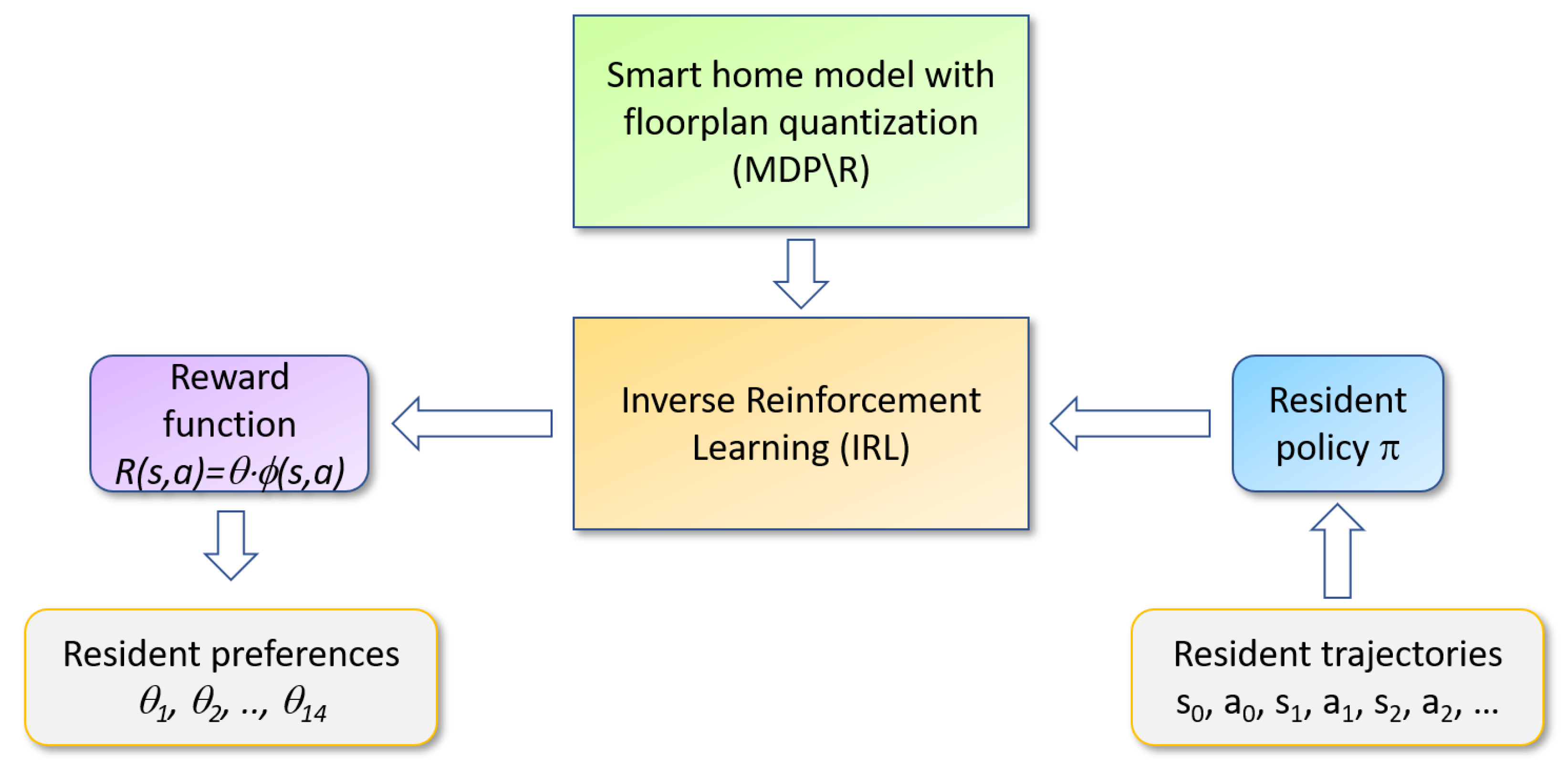
2. Materials and Methods
2.1. Inverse Reinforcement Learning
2.1.1. Markov Decision Process
2.1.2. Reinforcement Learning
2.1.3. RRE-IRL
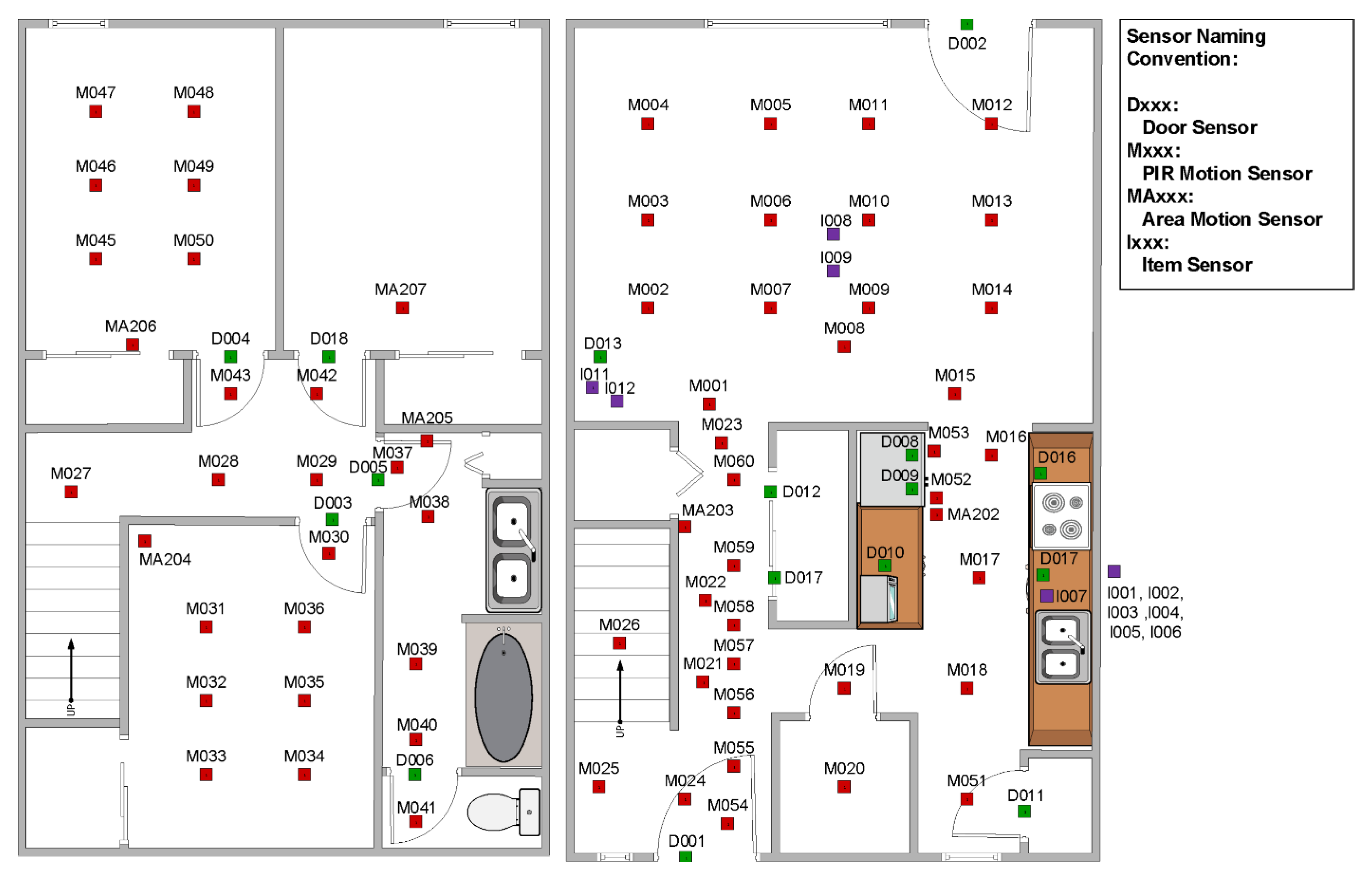
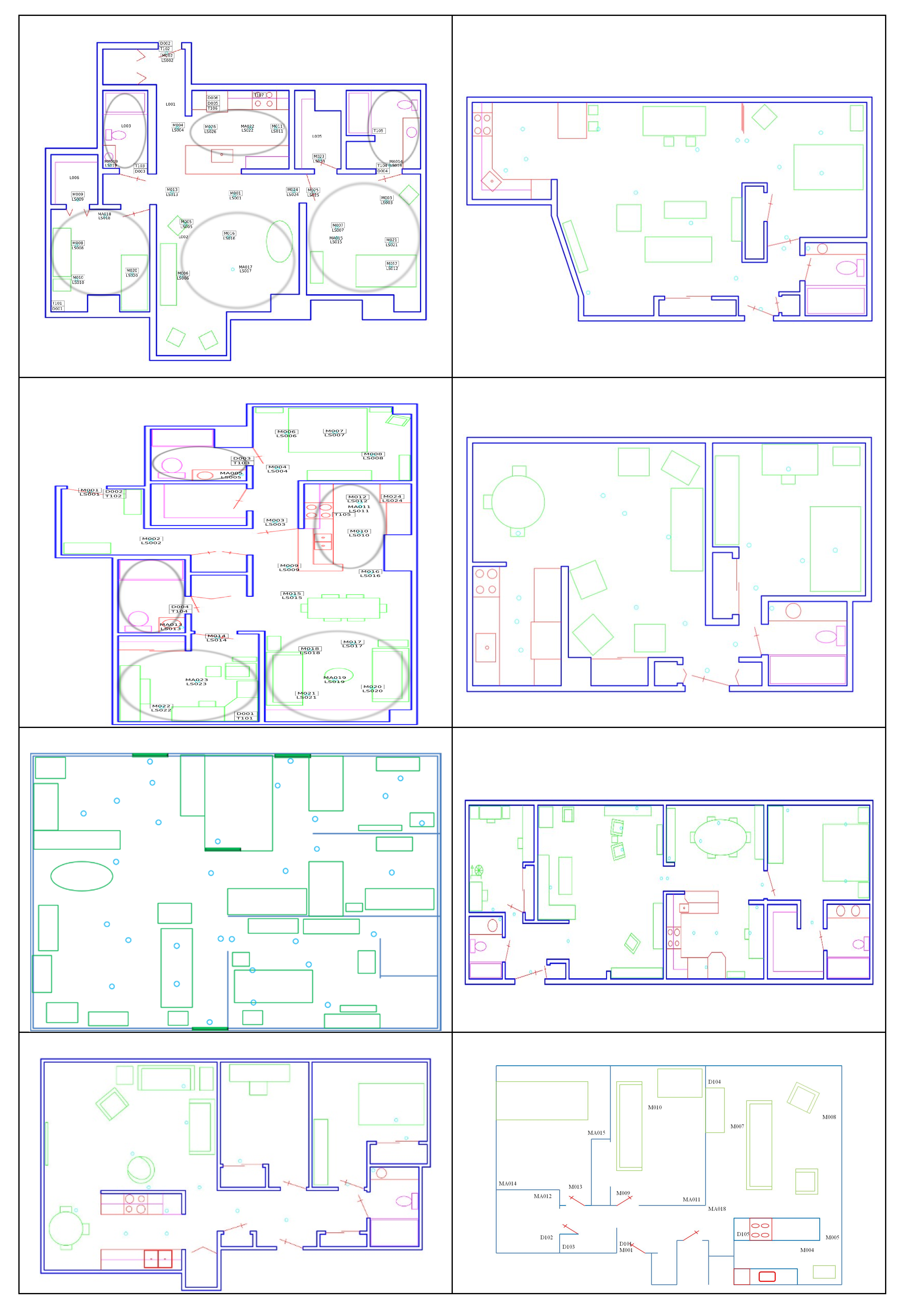
2.2. CASAS Smart Home
2.3. Modeling the Smart Home
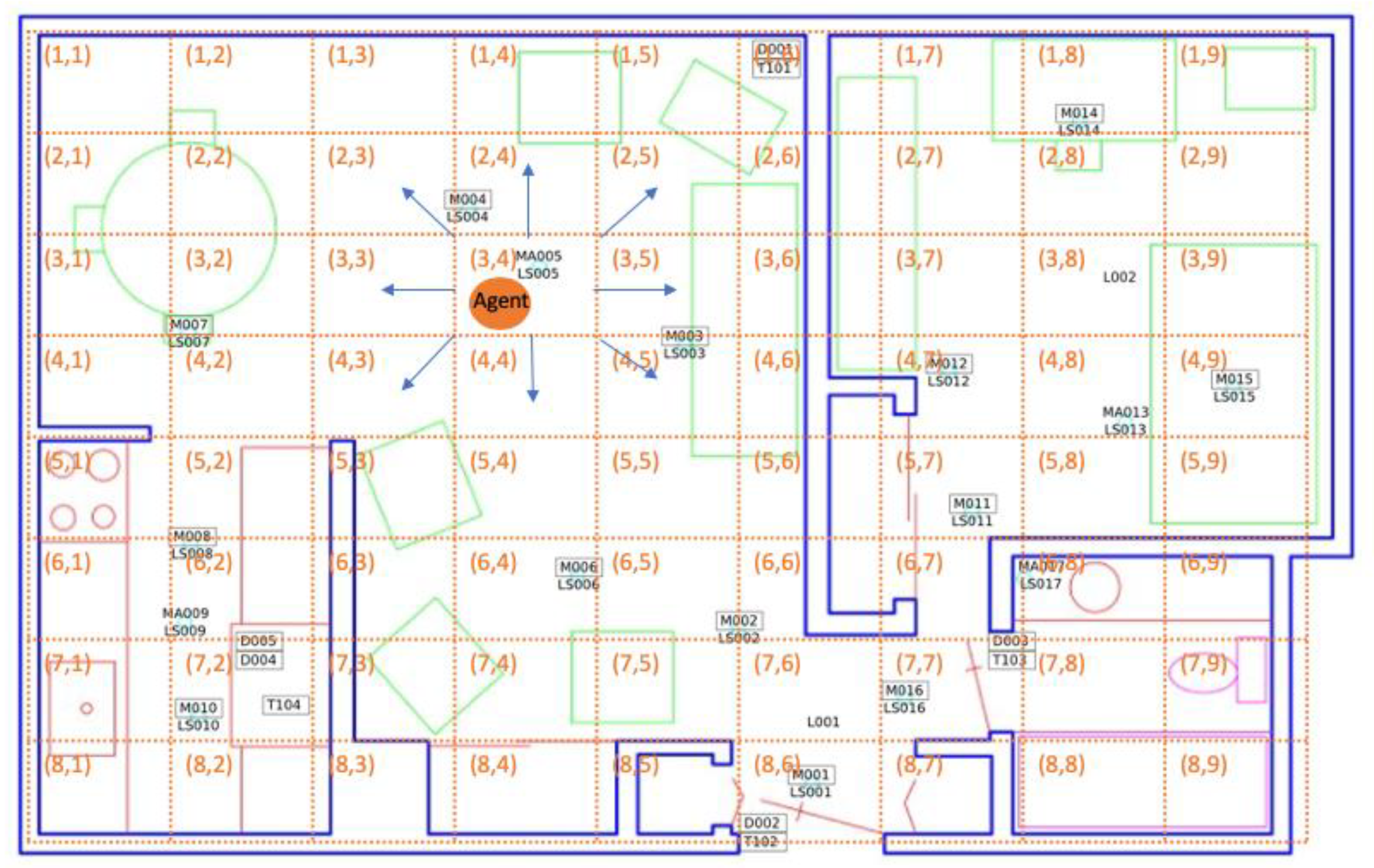
2.3.1. Floorplan Quantization
2.3.2. Feature Extraction
2.4. Relative Entropy IRL
| Algorithm 1: Resident Relative Entropy IRL | |
| input: | set of trajectories T |
| set of sample trajectories TN(TN⊂T) | |
| policy π approximated by TN | |
| threshold vector ε | |
| learning rate vector α | |
| N×k feature matrix Ф # N=number of trajectories, k=number of features | |
| output: | preference/weight vector θ |
| initialize: | weight vector θ with random numbers and feature expectation μ |
| while | () do |
| calculate using Equation (9) | |
| update | |
| end | |
| return | θ |
3. Results
- Experiment 1: Analyze and compare smart home behavior patterns for a single resident at two points in time. Determining whether the learned preference/weight vectors are significantly different gives us an indication of whether a person’s behavior is changing over time due to influences such as seasonal changes, changes in the environment, or changes in health;
- Experiment 2: Quantify change in smart home behavior patterns for multiple smart home residents within the same diagnosis group. We hypothesized that the amount of change we would observe in the behavior patterns, as defined by the learned preference/weight vectors, would be greater between different individuals than for one individual at different time points. We hypothesized that this would be particularly true when multiple individuals were drawn from the same health diagnosis sub-population;
- Experiment 3: Quantify change in smart home behavior patterns for multiple smart home residents from different diagnosis groups. We hypothesized that the amount of change we would observe in behavior patterns would be greater between individuals from different diagnosis groups than for either Experiment 1 or Experiment (2);
- Experiment 4: Characterize the nature of behavioral change that is observed between smart home residents from different diagnosis groups. We analyzed the preference/weight vectors that were learned for different smart home residents to determine the nature of the change that was observed between individuals who were healthy and those who were experiencing cognitive decline. We also used the preference vectors to predict the diagnosis group for an individual smart home resident.
3.1. Experimental Conditions
3.2. Within-Home Analysis
3.3. Between-Person Analysis Within the Same Diagnosis Group
3.4. Between-Group Analysis
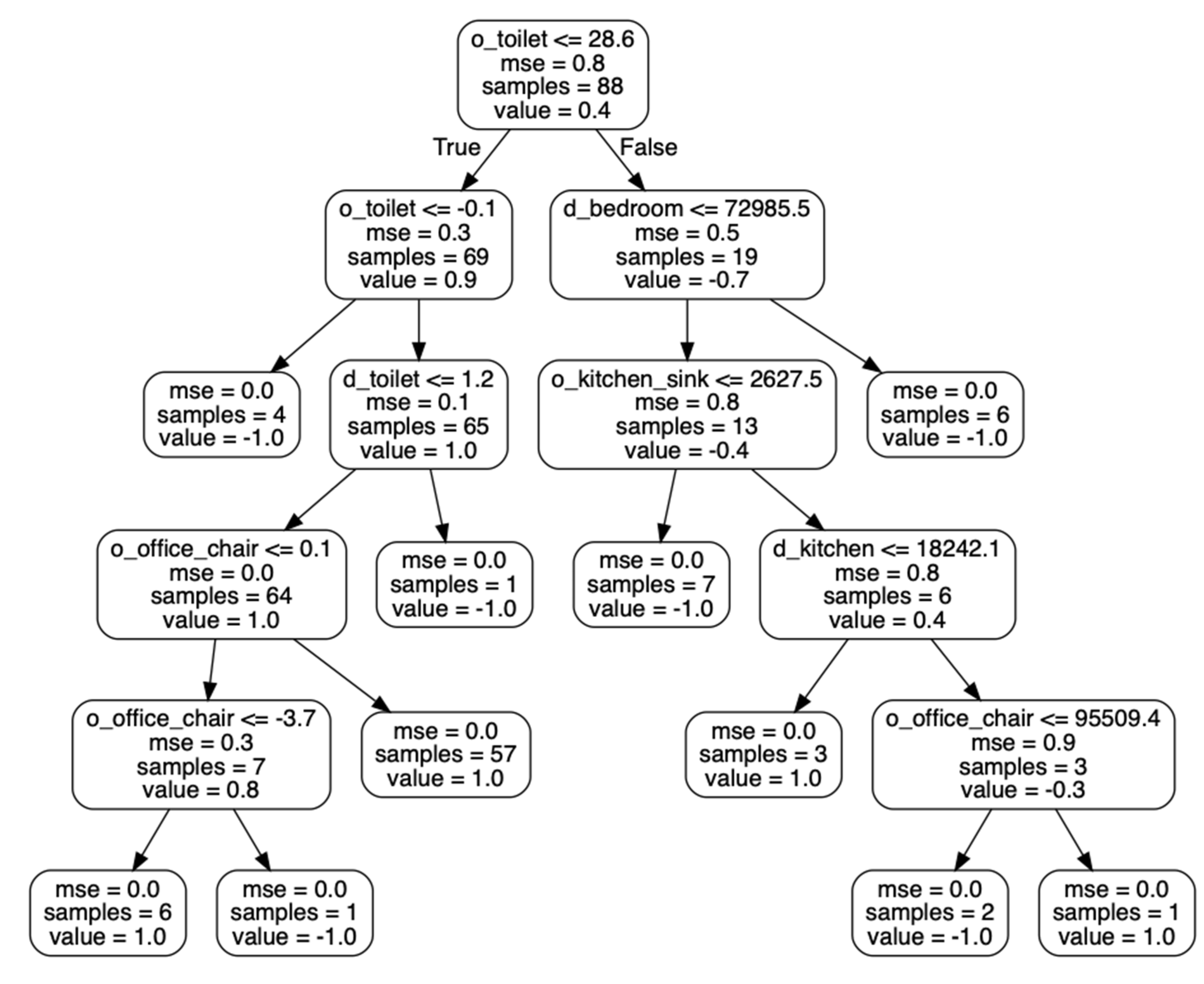
3.5. Characterizing Behavioral Change for Automated Health Assessment
3.6. Determining Behavior Indicators that Distinguish Population Subgroups
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yu, Z.; Du, H.; Yi, F.; Wang, Z.; Guo, B. Ten scientific problems in human behavior understanding. CCF Trans. Pervasive Comput. Interact. 2019, 1, 3–9. [Google Scholar] [CrossRef] [Green Version]
- Candia, J.; Gonzalez, M.C.; Wang, P.; Schoenharl, T.; Madey, G.; Barabasi, A.L. Uncovering individual and collective human dynamics from mobile phone records. J. Phys. A Math. Theor. 2008, 41, 224015. [Google Scholar] [CrossRef] [Green Version]
- Schunk, D.H.; DiBenedetto, M.K. Motivation and social cognitive theory. Contemp. Educ. Psychol. 2020, 60, 101832. [Google Scholar] [CrossRef]
- Tourangeau, R.; Rips, L.J.; Rasinski, K. The Psychology of Survey Response; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Palmer, M.G.; Johnson, C.M. Experimenter presence in human behavior analytic laboratory studies: Confound it? Behav. Anal. Res. Pr. 2019, 19, 303–314. [Google Scholar] [CrossRef]
- Lu, J.; Zhang, L.; Matsumoto, S.; Hiroshima, H.; Serizawa, K.; Hayase, M.; Gotoh, T. Miniaturization and packaging of implantable wireless sensor nodes for animals monitoring. 2016 IEEE SENSORS 2016, 1–3. [Google Scholar] [CrossRef]
- William, G.W. Wearable clinical-grade medical sensors get even smaller. Available online: https://www.electronicdesign.com/technologies/iot/article/21808327/wearable-clinicalgrade-medical-sensors-get-even-smaller (accessed on 1 July 2020).
- Shukla, R.; Kiran, N.; Wang, R.; Gummeson, J.; Lee, S.I. Skinny power:enabling batteryless wearable sensors via intra-body power transfer. In Proceedings of the 17th ACM Conference on Embedded Networked Sensor Systems(SenSys’19), New York, NY, USA, 10–13 November 2019; pp. 68–82. [Google Scholar]
- Chen, L.; Xiong, J.; Chen, X.J.; Lee, S.I.; Chen, K.; Han, D.H.; Fang, D.Y.; Tang, Z.Y.; Wang, Z. WideSee: Towards wide-area contactless wireless sensing. In Proceedings of the 17th ACM Conference on Embedded Networked Sensor Systems(SenSys’19), New York, NY, USA, 10–13 November 2019. [Google Scholar]
- Li, H.; Wan, C.; Shah, R.C.; Sample, A.P.; Patel, S.N. Idact: Towards unobtrusive recognition of user presence and daily activities. In Proceedings of the 2019 IEEE International Conference on RFID (RFID), Phoenix, AZ, USA, 2–4 April 2019. [Google Scholar]
- Elflein, J. Amount of time U.S. primary care physicians spent with each patient as of 2018. Available online: https://www.statista.com/statistics/250219/us-physicians-opinion-about-their-compensation/ (accessed on 13 June 2020).
- Iriondo, J.; Jordan, J. Older People Projected to Outnumber Children for First Time in U.S. History. Available online: https://www.census.gov/newsroom/press-releases/2018/cb18-41-population-projections.html (accessed on 1 July 2020).
- An aging, U.S. Population and the Health Care Workforce: Factors Affecting the Need for Geriatric Care Workers. Available online: https://healthforce.ucsf.edu/publications/aging-us-population-and-health-care-workforce-factors-affecting-need-geriatric-care (accessed on 1 July 2020).
- Healthy Aging Facts. 2018. Available online: https://www.ncoa.org/news/resources-for-reporters/get-the-facts/healthy-aging-facts/ (accessed on 1 July 2020).
- Center for Medicare and Medicaid Services. Available online: https://www.cms.gov/Research-Statistics-Data-and-Systems/Statistics-Trends-and-Reports/NationalHealthExpendData/NHE-Fact-Sheet (accessed on 1 July 2020).
- Administration On Aging. Available online: https://acl.gov/aging-and-disability-in-america/data-and-research/profile-older-americans (accessed on 1 July 2020).
- Office of The Assistant Secretary for Planning and Evaluation, ASPE. Available online: https://aspe.hhs.gov/national-plans-address-alzheimers-disease (accessed on 1 July 2020).
- Fowler, N.R.; Head, K.; Perkins, A.J.; Gao, S.; Callahan, C.M.; Bakas, T.; Suarez, S.D.; Boustani, M. Examining the benefits and harms of Alzheimer’s disease screening for family members of older adults: Study protocol for a randomized controlled trial. Trials 2020, 21, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Herman, W.H.; Ye, W.; Griffin, S.J.; Simmons, R.K.; Davies, M.J.; Khunti, K.; Rutten, G.E.; Sandbaek, A.; Lauritzen, T.; Borch-Johnsen, K.; et al. Early Detection and Treatment of Type 2 Diabetes Reduce Cardiovascular Morbidity and Mortality: A Simulation of the Results of the Anglo-Danish-Dutch Study of Intensive Treatment in People With Screen-Detected Diabetes in Primary Care (ADDITION-Europe). Diabetes Care 2015, 38, 1449–1455. [Google Scholar] [CrossRef] [Green Version]
- Akl, A.; Snoek, J.; Mihailidis, A. Unobtrusive Detection of Mild Cognitive Impairment in Older Adults Through Home Monitoring. IEEE J. Biomed. Health Inform. 2015, 21, 339–348. [Google Scholar] [CrossRef] [Green Version]
- Naslund, J.A.; Aschbrenner, K.A.; Kim, S.J.; McHugo, G.J.; Unützer, J.; Bartels, S.J.; Marsch, L.A. Health behavior models for informing digital technologyinterventions for individuals with mental illness. Psychiatr. Rehabil. J. 2017, 40, 325–335. [Google Scholar] [CrossRef]
- Shen, Y.; Phan, N.; Xiao, X.; Jin, R.; Sun, J.; Piniewski, B.; Kil, D.; Dou, D. Dynamic socialized Gaussian process models for human behavior prediction in ahealth social network. Knowl. Inf. Syst. 2016, 49, 455–479. [Google Scholar] [CrossRef] [Green Version]
- Meurisch, C. Intelligent personal guidance of human behavior utilizing anticipa-tory models. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016. [Google Scholar]
- Coyne, S.M.; Rogers, A.A.; Zurcher, J.D.; Stockdale, L.; Booth, M. Does timespent using social media impact mental health?: An eight year longitudinal study. Comput. Human Behav. 2020, 104, 106160. [Google Scholar] [CrossRef]
- Levonian, Z.; Erikson, D.R.; Luo, W.; Narayanan, S.; Rubya, S.; Vachher, P.; Terveen, L.; Yarosh, S. Bridging qualitative and quantitative methods for user model-ing: Tracing cancer patient behavior in an online health community. In Proceedings of the ICWSM-2020 14th International Conference on Web and Social Media, Atlanta, GA, USA,, 8–11 June 2020; 2020. [Google Scholar]
- Sprint, G.; Cook, D.J.; Weeks, D.L.; Dahmen, J.; La Fleur, A. Analyzing Sensor-Based Time Series Data to Track Changes in Physical Activity during Inpatient Rehabilitation. Sensors 2017, 17, 2219. [Google Scholar] [CrossRef] [PubMed]
- Jovan, F.; Wyatt, J.; Haawes, N.; Krajnik, T. A Poisson-spectral model for mod-elling temporal patterns in human data observed by a robot. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, South Korea, 9–14 October 2016. [Google Scholar]
- Lin, B.; Cook, D.J.; Schmitter-Edgecombe, M.; Maureen, S.-E. Using continuous sensor data to formalize a model of in-home activity patterns. J. Ambient. Intell. Smart Environ. 2020, 12, 183–201. [Google Scholar] [CrossRef]
- Yu, L.; Cui, P.; Song, C.; Zhang, T.; Yang, S. A temporally heterogeneous survival framework with application to social behavior dynamic. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Hasan, M.; Chowdhury, A.K.R. Context aware active learning of activity recognition models. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Reynolds, A.M.; Jones, H.B.C.; Hill, J.K.; Pearson, A.J.; Wilson, K.; Wolf, S.; Lim, K.S.; Reynolds, D.R.; Chapman, J.W. Evidence for a pervasive ‘idling-mode’ activity template in flying and pedestrian insects. R. Soc. Open Sci. 2015, 2, 150085. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.C.; Kurose, J.; Towsley, D. A mixed queueing network model of mo-bility in a campus wireless networ. In Proceedings of the 31st Annual IEEE International Conference on Computer Communications: Mini-Conferencein, Orlando, FL, USA, 25–30 March 2012. [Google Scholar]
- Qiao, Y.; Si, Z.; Zhang, Y.; Ben Abdesslem, F.; Zhang, X.; Yang, J. A hybrid Markov-based model for human mobility prediction. Neurocomputing 2018, 278, 99–109. [Google Scholar] [CrossRef]
- Wen, Y.T.; Yeh, P.W.; Tsai, T.H.; Peng, W.C.; Shuai, H.H. Customer purchase behavior prediction from payment dataset. In Proceedings of the 11th ACM International Conference on Web Search and Data Mining-WSDM, Marina Del Rey, CA, USA, 5–9 February 2018. [Google Scholar]
- Hadachi, A.; Batrashev, O.; Lind, A.; Singer, G.; Vainikko, E. Cell phone subscribers mobility prediction using enhanced Markov chain algorithm. In Proceedings of the IEEE Intelligent Vehicles Symposium, Dearborn, MI, USA, 8–11 June 2014. [Google Scholar]
- Huang, W.; Li, S.; Liu, X.; Ban, Y. Predicting human mobility with activity changes. Int. J. Geogr. Inf. Sci. 2015, 29, 1569–1587. [Google Scholar] [CrossRef]
- Hussein, A.; Gaber, M.M.; Elyan, E.; Jayne, C. Imitation Learning. ACM Comput. Surv. 2017, 50, 1–35. [Google Scholar] [CrossRef]
- Wu, Z.; Sun, L.; Zhan, W.; Yang, C.; Tomizuka, M. Efficient Sampling-Based Maximum Entropy Inverse Reinforcement Learning with Application to Autonomous Driving. IEEE Robot. Autom. Lett. 2020, 5, 1. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Maas, A.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Lamas, C.; De Lorenzo, A.R. COVID-19 and the cardiovascular system. Hear. Vessel. Transplant. 2020, 4, 37. [Google Scholar] [CrossRef]
- Boularias, A.; Kober, J.; Peters, J. Relative entropy inverse reinforcement learn-ing. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Brown, D.S.; Niekum, S. Machine teaching for inverse reinforcement learning: Algorithms and applications. In Proceedings of the 31th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, K.; Rath, M.; Burdick, J.W. Inverse reinforcement learning via function approximation for clinical motion analysis. In Proceedings of the 2018 IEEE International Conferenceon Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar]
- Jain, R.; Doshi, P.; Banerjee, B. Model-free IRL using maximum likelihood estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Li, Y.; Huang, W. Imitation learning from human-generated spatial-temporal data. In Proceedings of the ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Chicago, IL, USA, 5–8 November 2019. [Google Scholar]
- Banovic, N.; Buzali, T.; Chevalier, F.; Mankoff, J.; Dey, A.K. Modeling and understanding human routine behavior. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016. [Google Scholar]
- Li, Y.; Zhong, A.; Qu, G.; Li, N. Online markov decision processes with time-varying transition probabilities and rewards. In Proceedings of the ICML Workshop on Real-World Sequential Decision Making, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Li, G.; Gomez, R.; Nakamura, K.; He, B. Human-centered reinforcement learning: A survey. IEEE Trans. Human-Machine Syst. 2019, 49, 337–349. [Google Scholar] [CrossRef]
- Kaelbling, L.; Littman, M.; Moore, A. Reinforcement learning: A survey. J. Artif. Intell. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Arora, S.; Doshi, P. A survey of inverse reinforcement learning: Challenges, methods and progress. arXiv 2018, arXiv:1806.06877. [Google Scholar]
- Jara-Ettinger, J. Theory of mind as inverse reinforcement learning. Curr. Opin. Behav. Sci. 2019, 29, 105–110. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Gonzales, M.M.; Wang, C.P.; Quiben, M.; MacCarthy, D.; Seshadri, S.; Jacob, M. Joint trajectories of cognition and gait speed in Mexican American and European American older adults: The San Antonio Longitudinal Study of Aging. Int. J. Geriatr. Psychiatry 2020, 35, 897–906. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, H.; Liu, A. Modeling and interpreting real-world human risk decision making with inverse reinforcement learning. arXiv 2019, arXiv:1906.05803. [Google Scholar]
- Austin, J.; Klein, K.; Mattek, N.; Kaye, J. Variability in medication taking is associated with cognitive performance in nondemented older adults. Alzheimer’s Dementia: Diagn. Assess. Dis. Monit. 2017, 6, 210–213. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
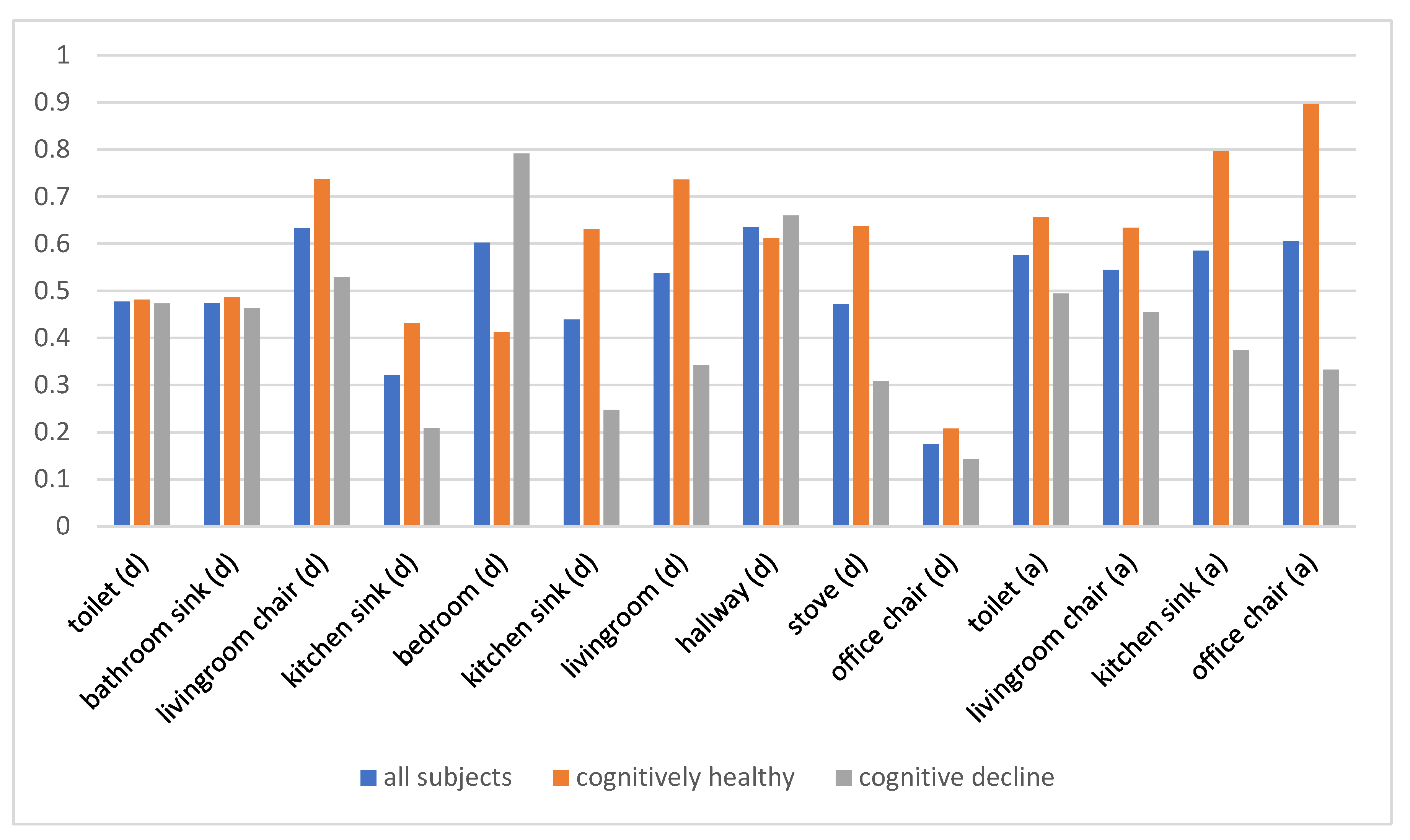{kind=link}
{kind=link}
| Timestamp | Sensor ID | Message |
|---|---|---|
| 02/06/2009 17:52:28 | M025 | ON |
| 02/06/2009 17:52:32 | M025 | OFF |
| 02/06/2009 17:52:35 | M025 | ON |
| 02/06/2009 17:52:36 | M025 | OFF |
| 02/06/2009 17:52:37 | M045 | ON |
| 02/06/2009 17:52:38 | M025 | ON |
| 02/06/2009 17:52:44 | M045 | OFF |
| 02/06/2009 17:53:31 | M024 | ON |
| 02/06/2009 17:53:32 | M019 | ON |
| 02/06/2009 17:53:33 | M021 | ON |
| 02/06/2009 17:53:33 | M025 | OFF |
| 02/06/2009 17:53:34 | M021 | OFF |
| 02/06/2009 17:53:34 | M018 | ON |
| 02/06/2009 17:53:36 | M051 | ON |
| 02/06/2009 17:53:36 | M024 | OFF |
| d_Toilet | d_Bathroom_Sink | d_Livingroom_Chair | d_Kitchen_Sink |
|---|---|---|---|
| d_bedroom | d_kitchen | d_livingroom | d_hallway |
| d_stove | d_office_chair | o_toilet | o_livingroom_chair |
| o_kitchen_sink | o_office_chair |
| Group | ID | Health Diagnosis | #Sensors | Duration of Data Collection | Number of Month-Long Samples | Total Number of Sensor Events |
|---|---|---|---|---|---|---|
| Cognitive decline | Home 1 | Mild Cognitive Impairment (MCI) | 21 downward-facing motion (motion); 2 motion area (ma) | 843 days | 26 | 4,785,969 |
| Home 2 | MCI | 19 motion; 2 ma | 223 days | 7 | 876,303 | |
| Home 3 | MCI | 26 motion; 0 ma | 682 days | 22 | 5,167,574 | |
| Home 4 | MCI, early dementia | 11 motion; 2 ma | 149 days | 5 | 24,948 | |
| Cognitively healthy | Home 5 | Healthy | 13 motion; 1 temperature | 1788 days | 56 | 5,761,601 |
| Home 6 | Healthy | 13 motion | 1591 days | 49 | 4,850,970 | |
| Home 7 | Healthy | 18 motion; 2 ma | 379 days | 12 | 2,292,312 | |
| Home 8 | Healthy | 10 motion; 1 ma | 969 days | 31 | 1,853,637 |
| Home ID | d_Toilet | d_Bath-Room Sink | d_Livingroom Chair | d_Kitchen Sink | d_Bedroom | d_Kitchen | d_Living-Room |
|---|---|---|---|---|---|---|---|
| 1 | 0.631 | 0.631 | 0.224 | 0.000 | 1.000 | 0.073 | 0.096 |
| 2 | 0.059 | 0.061 | 0.057 | 0.000 | 0.847 | 0.445 | 0.047 |
| 3 | 0.377 | 0.379 | 1.000 | 0.000 | 0.319 | 0.133 | 0.892 |
| 4 | 0.824 | 0.777 | 0.836 | 0.836 | 1.000 | 0.340 | 0.329 |
| 5 | 0.382 | 0.405 | 0.435 | 0.407 | 0.615 | 0.603 | 0.429 |
| 6 | 0.988 | 0.988 | 0.998 | 1.000 | 0.292 | 0.995 | 0.999 |
| 7 | 0.308 | 0.308 | 0.745 | 0.318 | 0.000 | 0.379 | 0.745 |
| 8 | 0.246 | 0.246 | 0.770 | 0.000 | 0.743 | 0.545 | 0.770 |
| Home ID | d_Hallway | d_Stove | d_Office Chair | o_Toilet | o_Living-Room Chair | o_Kitchen Sink | o_Office Chair |
| 1 | 0.302 | 0.326 | 0.401 | 0.666 | 0.262 | 0.292 | 0.281 |
| 2 | 1.000 | 0.049 | 0.048 | 0.060 | 0.047 | 0.000 | 0.046 |
| 3 | 0.467 | 0.001 | 0.123 | 0.524 | 0.711 | 0.486 | 0.313 |
| 4 | 0.871 | 0.855 | 0.000 | 0.725 | 0.797 | 0.719 | 0.689 |
| 5 | 0.917 | 0.661 | 0.000 | 0.381 | 0.539 | 1.000 | 0.854 |
| 6 | 0.993 | 0.992 | 0.000 | 0.996 | 0.990 | 0.993 | 0.767 |
| 7 | 0.068 | 0.318 | 0.252 | 1.000 | 0.594 | 0.652 | 0.893 |
| 8 | 0.464 | 0.578 | 0.580 | 0.246 | 0.413 | 0.538 | 1.000 |
| ID | d_Toilet | d_Bath-Room Sink | d_Living-Room Chair | d_Kit-Chen Sink | d_Bed-Room | d_Kit-Chen | d_Living-Room | d_Hall-way | d_Stove | d_Office-Chair | Dura-tion Mean | Overall Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.39 | 0.39 | 0.10 | 0.35 | 0.07 | 0.30 | 0.35 | 0.40 | 0.25 | 0.96 | 0.36 | 0.40 |
| 2 | 0.45 | 0.38 | 0.33 | 0.27 | 0.04 * | 0.02 * | 0.03 * | 0.02 * | 0.29 | 0.07 | 0.19 | 0.29 |
| 3 | 0.74 | 0.74 | 0.37 | 0.55 | 0.46 | 0.47 | 0.54 | 0.47 | 0.55 | 0.48 | 0.54 | 0.54 |
| 4 | 0.46 | 0.40 | 0.32 | 0.28 | 0.35 | 0.09 | 0.84 | 0.12 | 0.30 | 0.09 | 0.33 | 0.39 |
| 5 | 0.42 | 0.87 | 0.28 | 0.56 | 0.54 | 0.65 | 0.28 | 0.81 | 0.73 | 0.37 | 0.55 | 0.51 |
| 6 | 0.56 | 0.03 * | 0.08 | 0.58 | 0.92 | 0.16 | 0.83 | 0.09 | 0.55 | 0.29 | 0.41 | 0.46 |
| 7 | 0.14 | 0.14 | 0.31 | 0.49 | 0.17 | 0.55 | 0.31 | 0.15 | 0.49 | 0.76 | 0.35 | 0.33 |
| 8 | 0.91 | 0.22 | 0.06 | 0.78 | 0.57 | 0.61 | 0.06 | 0.66 | 0.66 | 0.49 | 0.50 | 0.44 |
| Cognitive Decline | d_Toilet | d_Bath-Room Sink | d_Living-Room Chair | d_Kitchen Sink | d_Bed-Room | d_Kitchen | d_Living-Room | d_Hall-way |
| 0.29 | 0.29 | 0.29 | 0.24 | 0.67 | 0.56 | 0.79 | 0.62 | |
| d_Stove | d_Office Chair | o_Toilet | o_Living-Room Chair | o_Kitchen Sink | o_Office Chair | Overall Mean | ||
| 0.85 | 0.78 | 0.00 * | 0.12 | 0.10 | 0.35 | 0.42 | ||
| Cognitively Healthy | d_Toilet | d_Bath-Room Sink | d_Living-Room Chair | d_Kitchen Sink | d_Bed-Room | d_Kitchen | d_Living-Room | d_Hall-way |
| 0.10 | 0.10 | 0.02 * | 0.62 | 0.99 | 0.62 | 0.02 * | 0.58 | |
| d_Stove | d_Office Chair | o_Toilet | o_Living-Room Chair | o_Kitchen Sink | o_Office Chair | Overall Mean | ||
| 0.58 | 0.95 | 0.17 | 0.26 | 0.00 * | 0.00 * | 0.32 | ||
| d_Toilet | d_Bathroom Sink | d_Livingroom Chair | d_Kitchen Sink | d_Bedroom | d_Kitchen | d_Living-Room | d_Hallway |
| 0.10 | 0.10 | 0.02 * | 0.62 | 0.99 | 0.62 | 0.02 * | 0.58 |
| d_Stove | d_Office Chair | o_Toilet | o_Livingroom Chair | o_Kitchen Sink | o_Office Chair | Overall Mean | |
| 0.95 | 0.17 | 0.26 | 0.00 * | 0.00 * | 0.01 * | 0.32 | |
| Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|
| 0.84 | 0.88 | 0.90 | 0.89 |
| o_Toilet | d_Toilet | d_Hallway | d_Livingroom | o_Office Chair | d_Bathroom Sink | o_Living-Room Chair |
|---|---|---|---|---|---|---|
| 0.33 | 0.22 | 0.10 | 0.06 | 0.06 | 0.04 | 0.04 |
| d_Living-Room Chair | d_Bedroom | d_Kitchen | d_Stove | d_Office Chair | o_Kitchen Sink | d_Kitchen Sink |
| 0.03 | 0.02 | 0.02 | 0.02 | 0.02 | 0.02 | 0.01 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, B.; Cook, D.J. Analyzing Sensor-Based Individual and Population Behavior Patterns via Inverse Reinforcement Learning. Sensors 2020, 20, 5207. https://doi.org/10.3390/s20185207
Lin B, Cook DJ. Analyzing Sensor-Based Individual and Population Behavior Patterns via Inverse Reinforcement Learning. Sensors. 2020; 20(18):5207. https://doi.org/10.3390/s20185207
Chicago/Turabian StyleLin, Beiyu, and Diane J. Cook. 2020. "Analyzing Sensor-Based Individual and Population Behavior Patterns via Inverse Reinforcement Learning" Sensors 20, no. 18: 5207. https://doi.org/10.3390/s20185207
APA StyleLin, B., & Cook, D. J. (2020). Analyzing Sensor-Based Individual and Population Behavior Patterns via Inverse Reinforcement Learning. Sensors, 20(18), 5207. https://doi.org/10.3390/s20185207