1. Introduction
Cardiovascular diseases are the leading cause of death worldwide [
1,
2]. According to [
3], this trend will continue and deteriorate in the future. Apart from the personal consequences, the healthcare costs are a huge burden for society [
3].
One approach to tackle this problem is the daily monitoring of vital parameters, e.g., from the electrocardiogram (ECG) and phonocardiogram (PCG) (
Supplementary Materials) by use of wearable sensors [
4], since abnormal properties can indicate cardiac diseases. For the latter type of signals, automatic heart sound detection and classification algorithms are under research. The most successful approaches are the envelope-based, probabilistic-based and the feature-based methods [
5].
Feature-based methods, as e.g., proposed by [
6,
7,
8,
9,
10], extract features such as the Shannon entropy, discrete wavelet transform (DWT), continuous wavelet transform (CWT) or mel-frequency cepstral coefficients (MFCC) out of the PCG signal. With the use of classifiers (for example support vector machine (SVM), twin support vector machine (TWSVM) or deep neural networks (DNN)), it can be determined, if the features correspond to a heart sound [
5]. However, feature-based methods have the disadvantages of high computational effort and strong dependency on datasets for training [
5]. As the PCG strongly varies between the subjects as well as with the posture, heart rate and auscultation point, this would require separate data sets for each of these conditions.
Probabilistic-based methods classify heart sounds by different features, e.g., time-frequency energy or average distance between two peaks. The hidden-Markov model (HMM) is a well-established probabilistic-based model for the classification of heart sounds [
11]. In [
12,
13] the HMM, which Schmidt et al. proposed for the heart sound classification, was improved to the hidden-semi-Markov model (HSMM) and tested with a huge amount of test persons. Renna et al. used convolutional neural networks (CNN) together with an underlying HMM in order to outperform the state of the art on heart sound classification [
14]. However, the probabilistic-based methods also have a strong dependency on datasets for training and the computational effort is similar to that of the feature-based methods.
Envelope-based approaches, in contrast, are characterized by low computational costs and promise applicability under various situations in the daily life of the subjects without a dedicated training for these conditions. This robustness is of particular importance, as some pathological behaviour can only be observed during physical effort [
15]. Nevertheless, the influence of the posture, auscultation point, physical stress and breathing on heart sound classification has not been addressed so far, to the best of the authors’ knowledge.
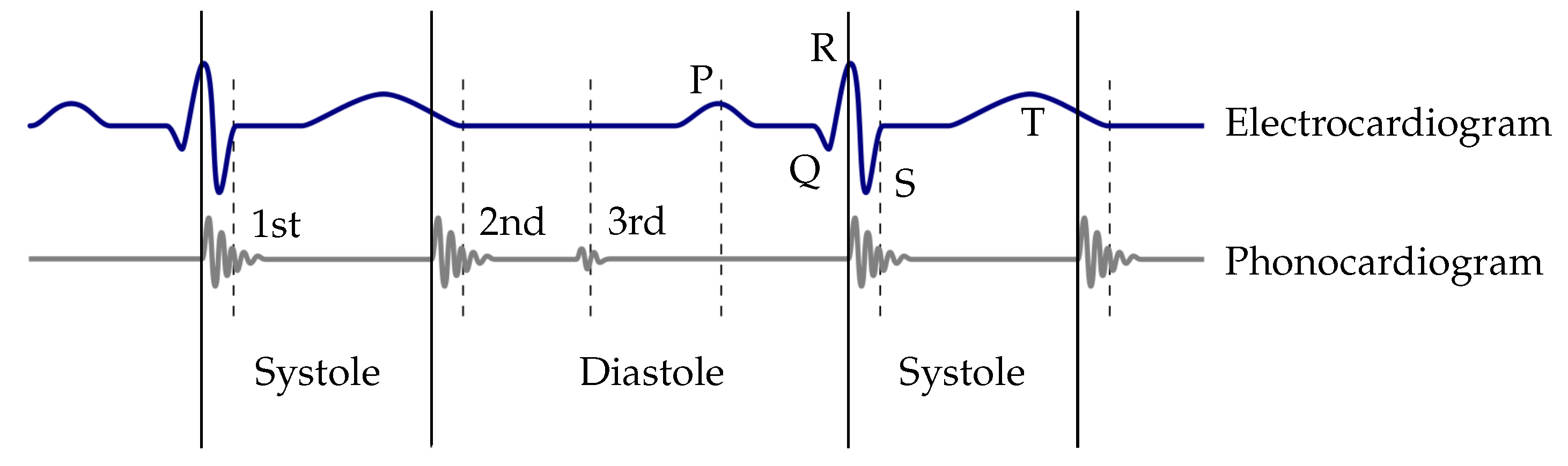
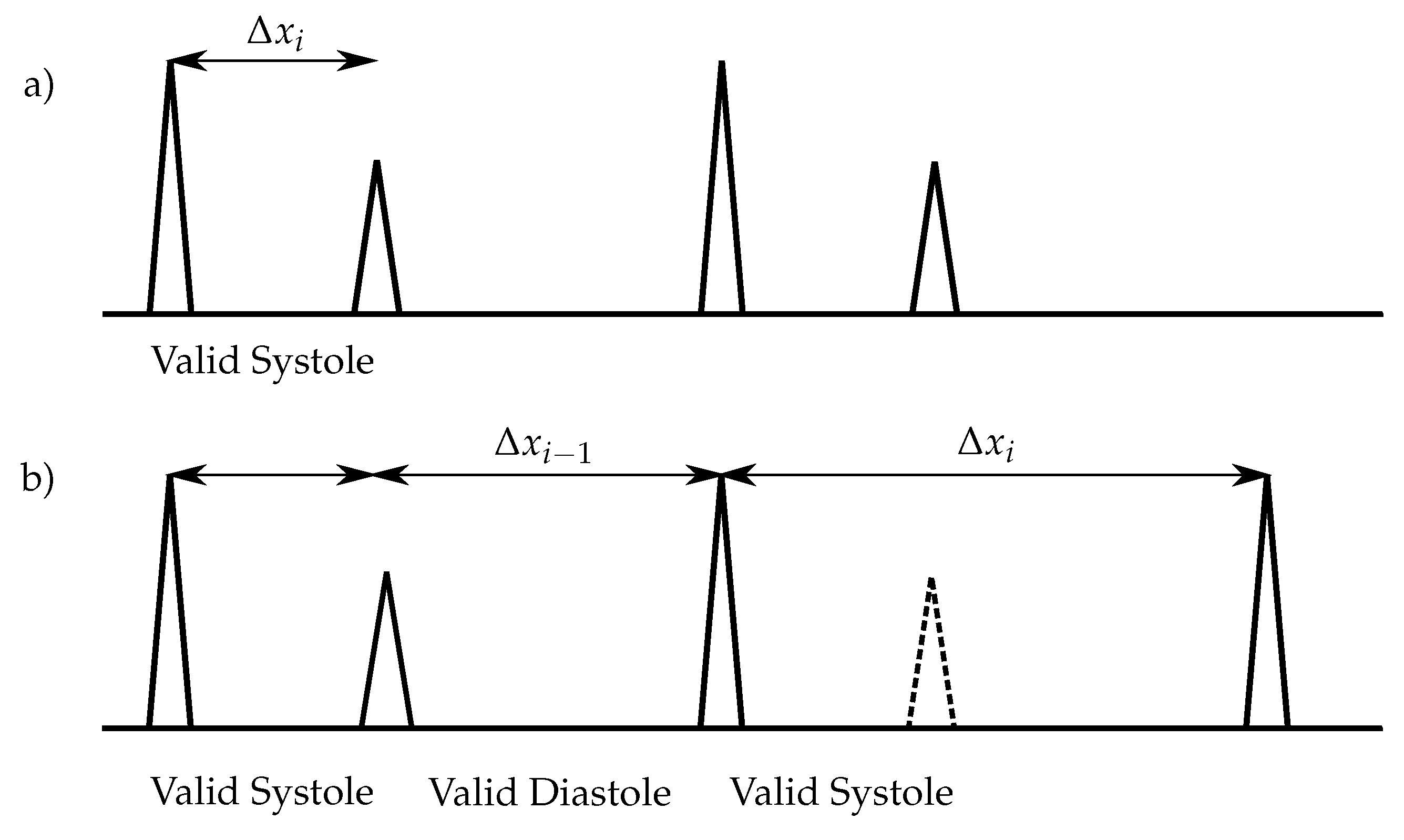
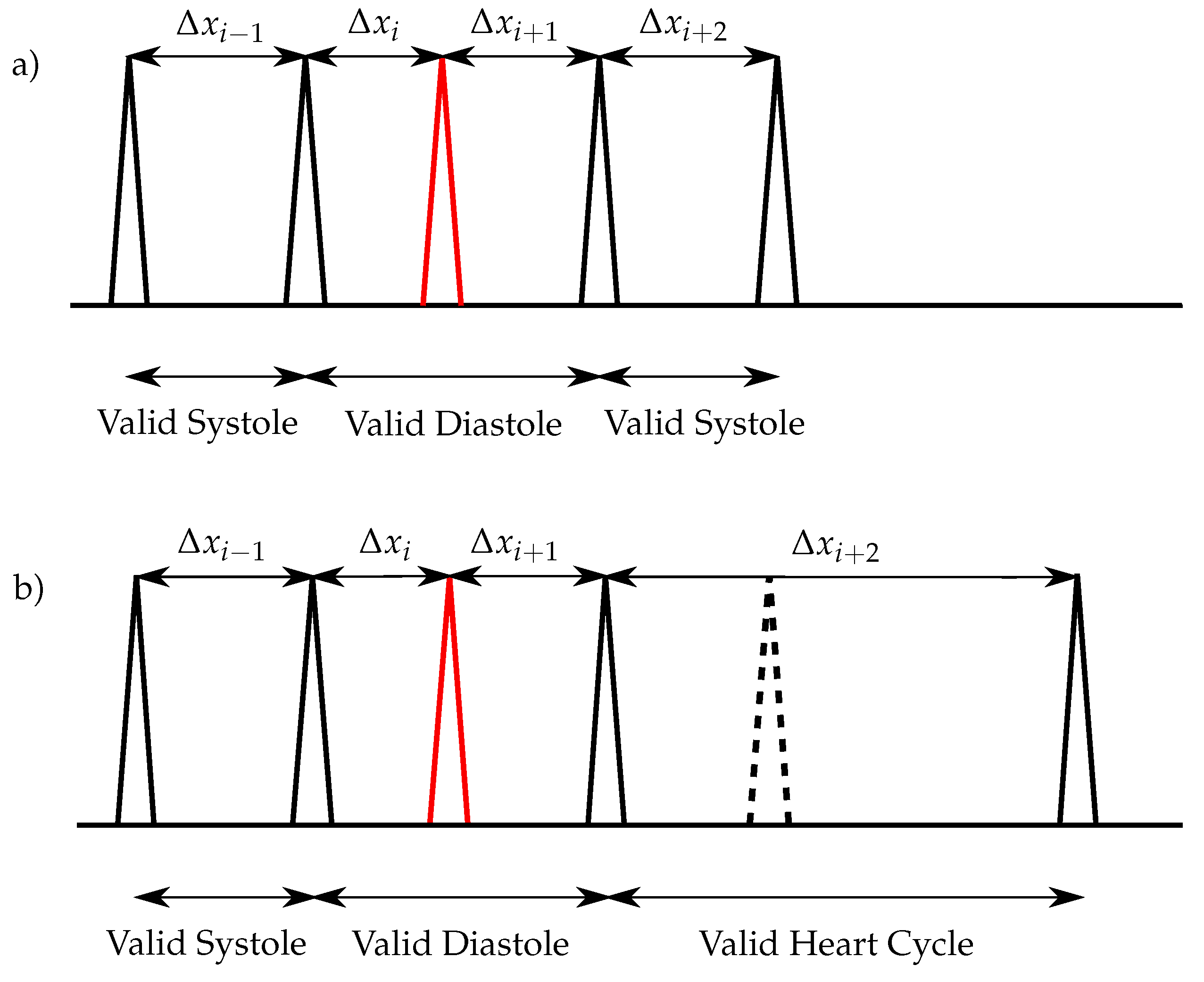
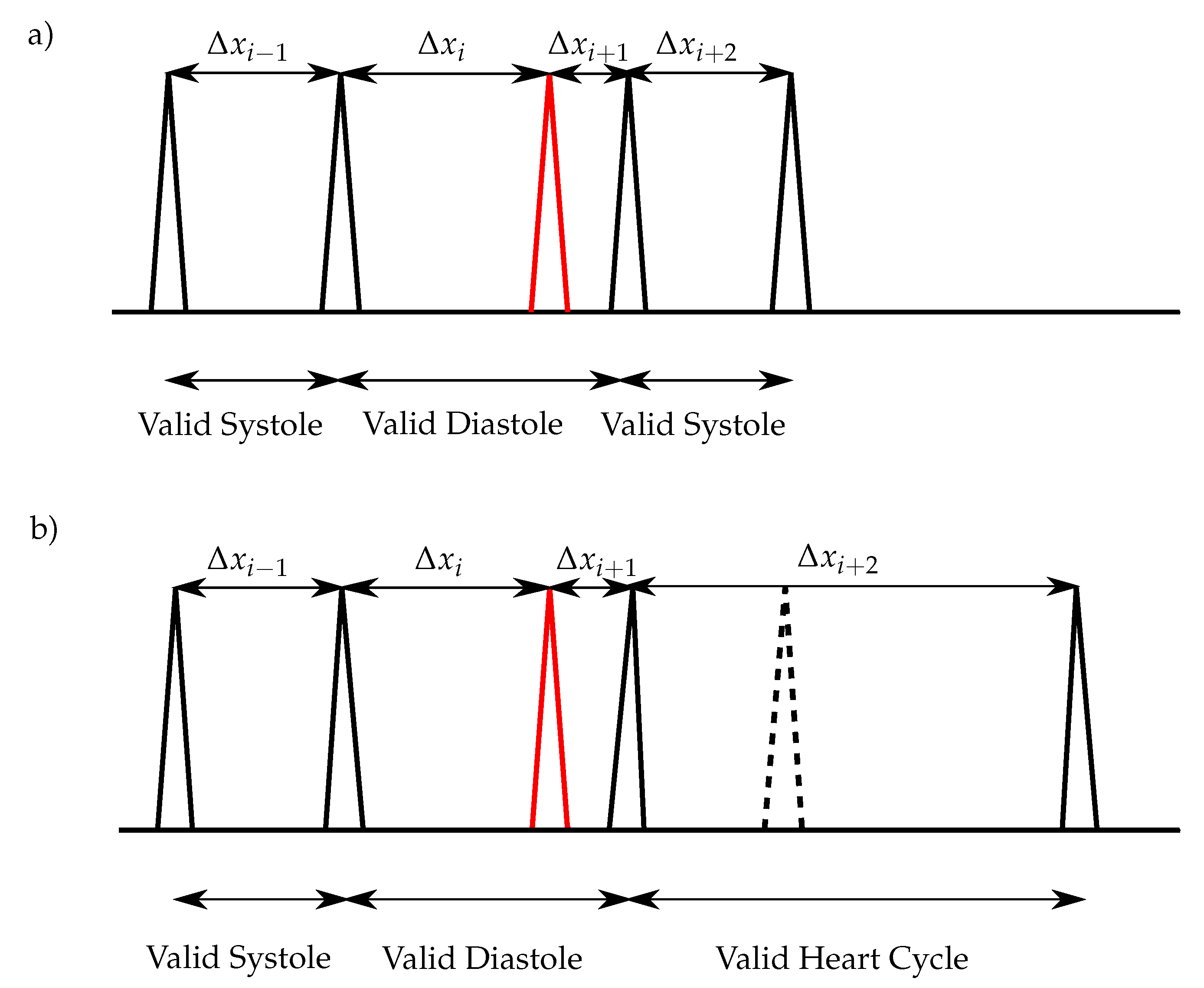
Typical methods used for the extraction of the envelope curve are the normalized average Shannon energy [
16,
17] or Hilbert transform (respectively short-time modified Hilbert transform (STMHT)) [
18]. For the classification of the heart sounds, the peaks in the envelope curve are detected. The distances between two consecutive peaks are segmented in systoles and diastoles. Therefore, the first heart sound must be located at the beginning of the systole, whereas the second heart sound at the beginning of the diastole. The heart sound classification of the envelope-based algorithms use the assumption that the systole is shorter than the diastole [
5,
19]. However, at increased heart rates, the systole and diastole period are roughly equal in time, which can lead to errors in the detection of heart sounds [
19,
20]. Moreover, additional peaks e.g., noise, split heart sounds, third and forth heart sounds are problematic for envelope-based approaches [
5,
21].
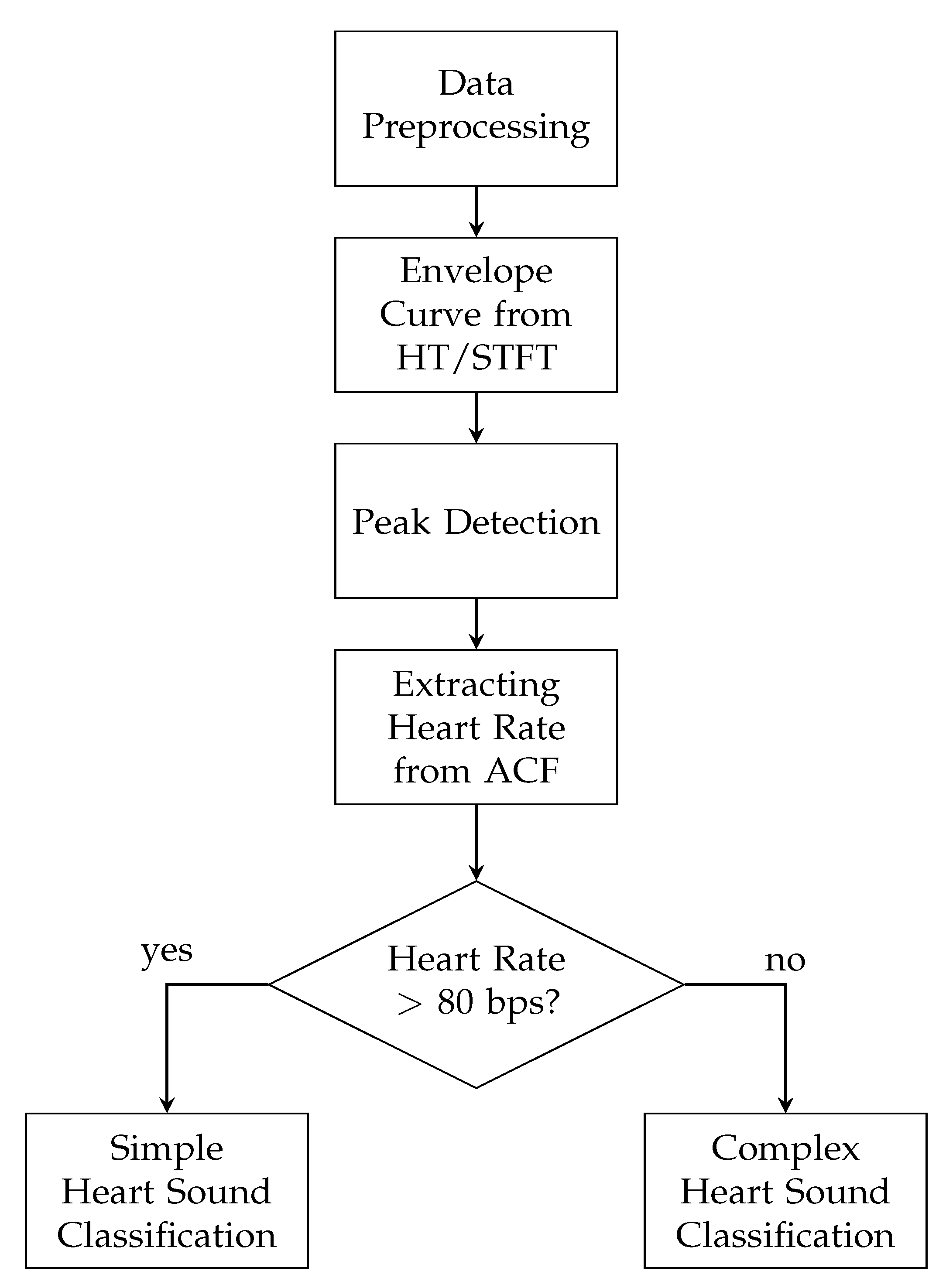
In this paper, an enhanced envelope-based algorithm for automatic real-time detection and classification of the first and second heart sound is presented. The proposed algorithm distinguishes between increased (>80 bps) and normal heart rates, and in this way deals with the aforementioned problem that for increased heart rates, the length of the systole and diastole are almost equal. Furthermore, a real-time capable algorithm is needed for daily monitoring of heart sounds. In the literature, the autocorrelation (ACF) is well-established for heart rate estimation out of PCG signals [
11,
13,
20,
22]. In 2019, Dia et al. proposed a method for extracting the heart rate from noisy PCG signals by using the non-negative matrix factorization (NMF) [
23]. They applied the NMF on the spectrogram of a PCG in order to estimate the heart rate. In the proposed paper an approach is made to keep the overall computational effort as low as possible. This is accomplished by using the ACF for heart rate estimation and an envelope-based classification algorithm.
For evaluating the proposed algorithm, measurements of the ECG and PCG were conducted on twelve male subjects with different age and body-mass index (BMI). The posture, the auscultation point and the physical stress were varied in order to evaluate the robustness of the presented algorithm in daily routine activities of a subject. Finally, the algorithm for heart sound classification was tested and evaluated with two different methods for envelope curve extraction, namely the Hilbert transform (HT) and short-time Fourier transform (STFT) and their corresponding results were compared.
This paper is organized as follows.
Section 2 explains the fundamentals of the heart cycle and the applied signal processing methods of the algorithm. In
Section 3, the developed algorithm for heart sound classification is introduced. The algorithm is tested with two different approaches for envelope curve extraction, namely the HT and the STFT. The proposed parameters for evaluating and optimization the performance of the algorithm are presented in
Section 4. The process of the data acquisition, the study population and the used hardware setup is introduced in
Section 5. The results for the classification process for the two different approaches are evaluated, compared and discussed in
Section 6. Finally, in
Section 7 the findings are concluded.
4. Statistical Evaluation and Optimization
For the first heart sounds, the peaks of the R-wave out of the ECG are used as a reference, whereas the classification of the second heart sounds is not evaluated with the ECG. Therefore, the performance of the classification algorithm is statistically evaluated in terms of the sensitivity, specificity, accuracy, precision and the F
1-score only for S
1. These parameters are defined as
For evaluating the proposed algorithm, a tolerance window
, which was applied around the peak of the R-wave, was introduced. The window was necessary, since the synchronization of the PCG and ECG was only an approximation and the maximum of a heart sound did not always occur at the beginning of the corresponding heart sound. Taking the maximal duration of a heart sound in consideration, a tolerance window of 150 ms was appropriate [
34,
43]. If a peak, which was classified as S
1, lay within the window, the heart sound was correct.
is the number of wrongly classified S
1 peaks, which were outside of
and
are correct heart sounds, which were not detected by the algorithm.
is the number of correctly classified S
1 peaks and
is the number of correctly as false classified S
1 peaks.
All performance parameters were computed for all measurements for both, the HT and the STFT. The classification of the heart sounds was optimized to achieve the highest F
1-score. In case of a high heart rate, the threshold
n for peak detection was optimized separately. The results of the optimization process can be found in
Section 6.1.
6. Results and Discussion
6.1. Results of Optimization
The performance of the presented algorithm was optimized regarding the F
1-score. The values of the optimized parameters are listed in
Table 3. The threshold parameters
nnormal and
nhigh were greater for the HT, since through the averaging effect of the STFT, its resulting envelope curve was smoother. The cut-off frequencies of the HT and STFT for the low-pass filter were 40 Hz and 20 Hz, respectively, and the cut-off frequencies of the HT and STFT for the high-pass filter were 190 Hz and 120 Hz, respectively. The filter for both, the HT and STFT, were from the order of 10 for the low-pass filter and 4 for the high-pass, respectively.
The filter suppressed noise, which was caused by human voice, respiration or lung sounds. The fundamental frequency of human voice is approximately 120 Hz for male and 190 Hz for female, respectively [
44]. Therefore, the applied filter eliminated the majority of human voices. However, no study about the influence of speaking during the measurements was made. The frequency range of lung sounds and respiration is approximately 60–1200 Hz [
45,
46]. Thus, lung sounds and breathing were partly suppressed by the filtering. However, artefacts from the lung could not be fully eliminated, since heart sounds occurred within that frequency range. The cut-off frequencies were the result of the optimization process, regarding the average F
1-score.
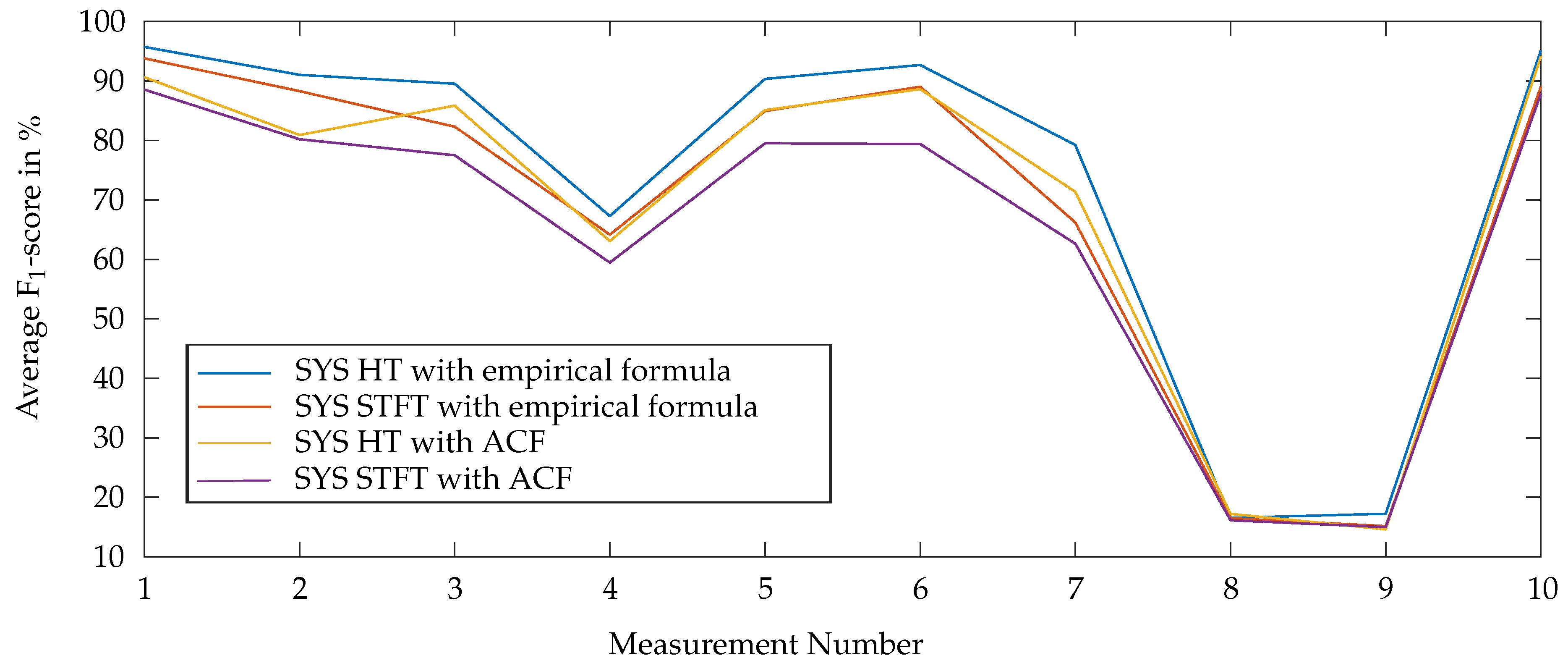
6.2. Comparison of the Two Approaches for Systolic Length Estimation
As introduced in
Section 3, two different methods were considered for the systolic length extraction: based on the ACF and based on the empirical formula
6. For each of these methods and for both, the HT- and STFT-based approach, F
1-scores were calculated. The results for these combinations are shown in
Figure 9. The proposed algorithm achieves a better performance by using the empirical formula for the systolic length estimation. Therefore, in the following the algorithm is evaluated by using the empirical approach.
6.3. Results of Heart Sound Classification
The respective average values of the performance parameters are listed in
Table 4. Furthermore, the average performance parameters were calculated without the measurements 4, 8 and 9, since the reference ECG was noisy for the measurement 4 and the measurements at the back (8 and 9) had a noisy PCG. The evaluation results for the F
1-score for the single probands and measurements are shown in
Table 5 and
Table 6. Measurement 1 was the reference for the other measurements. It showd the best results, since it was conducted under optimal circumstances at Erb’s point.
6.4. Influence of Different Measurement Conditions
6.4.1. Varying the Auscultation Point
The measurements 1, 7, 8 and 9 were conducted during a sitting position and in the resting state. Only the auscultation point was varied. As the results in
Table 4,
Table 5 and
Table 6 suggest, the F
1-score was best for Erb’s point (Measurement 1) as expected, whereas measurement 7 was performed at the sternum. The average F
1-score was lower compared to the reference measurement 1 and varied largely between the single subjects. The reason for that performance is the lower amplitude of the heart sounds (see
Section 2.1). Therefore, the signal-to-noise ratio suffered and noise could be misinterpreted as heart sounds.
The results for measurements 8 and 9, which were performed on the back of the subjects, provided poor results for heart sound classification. The reason for that is the weak acoustic signal, which is attenuated by the lunges and the backbone. In consequence, it is not advisable to place a wearable system for heart sound monitoring on the back, as suggested in [
47]. Therefore, the average of the evaluation parameters was calculated without the measurements 8 and 9 as well.
6.4.2. Varying the Posture
The measurements 1, 3, 4, 5 and 6 were conducted with different postures of the probands. Measurement 3, 5 and 6, where the probands were lying on the back, lying on the right side and lying on the left side, showed similar values regarding the performance parameters. However, compared to measurement 1, the results were slightly worse.
The results for measurement 4 were poor, since during the measurement the subjects were lying on the stomach. This led in some cases to noise in the ECG, which was caused by movement of the electrodes. In consequence, the reference signal was distorted and the evaluation of the classification performance suffered. However, the PCG was not affected.
6.4.3. Varying the Physical Stress
Measurement 2 was conducted with deep breathing and measurement 10 after 5 minutes of sport, respectively. This reflects physical stress situations. The results of measurement 10 show that the classification of heart sounds worked well for increased heart rates. The average ratio of the amplitudes of S1 and S2 for increased heart rates was 1.8 for the STFT and 3.4 for the HT. Therefore, S1 could be distinguished easily from noise as well as from S2. Moreover, the results of measurement 2 showed that deep breathing hardly affected the classification algorithm.
6.4.4. Influence of BMI
The probands were arranged according to their BMI and, therefore, divided into two groups of equal size. Group “low BMI” consists of proband 1, 3, 4, 6, 8 and 10 and group “high BMI” of 2, 5, 7, 9, 11 and 12. The average F
1-score without the measurements 4, 8 and 9 was computed for both the HT and STFT and compared for both groups (see
Table 7). The results for the group “high BMI” showed that the average F
1-score was approximately 4% worse than the group “low BMI”, regarding for both, the HT and STFT, since the heart sounds were more attenuated for higher BMIs. In consequence, the algorithm was quite robust towards a variation of the BMI, for envelope extraction for both the HT and STFT.
6.5. Comparison of HT and STFT
Overall, the average F1-score by using the HT for extracting the envelope curve was approx. 5% better than those with the STFT. Due to the fact that the STFT was computed within a time window, the time resolution was limited, since an appropriate frequency resolution was needed. In consequence, the number of samples was reduced and, therefore, the accuracy of the derived length of the systoles was smaller, resulting in incorrectly removed S1. This effect was even increased in case of split S1.
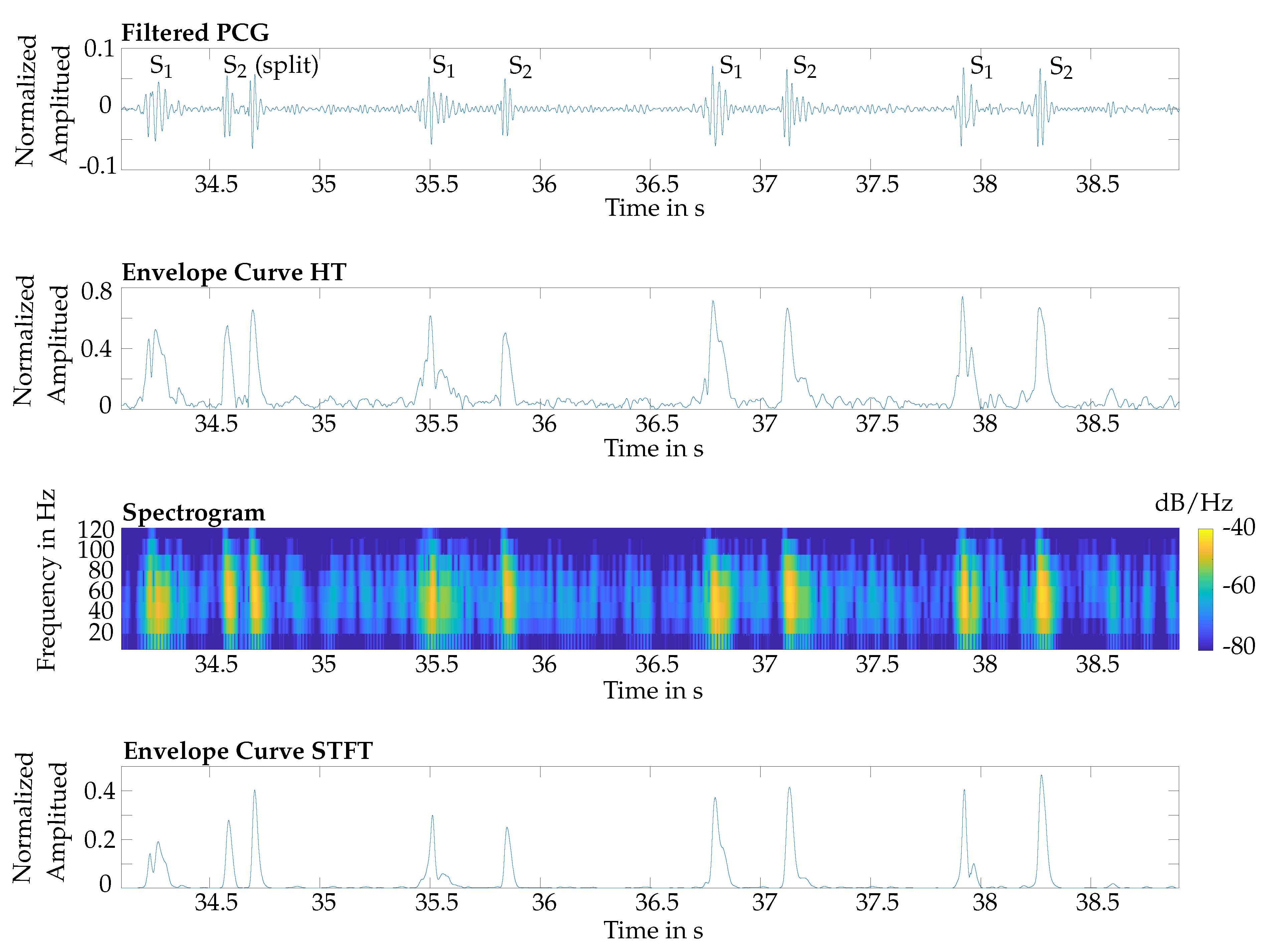
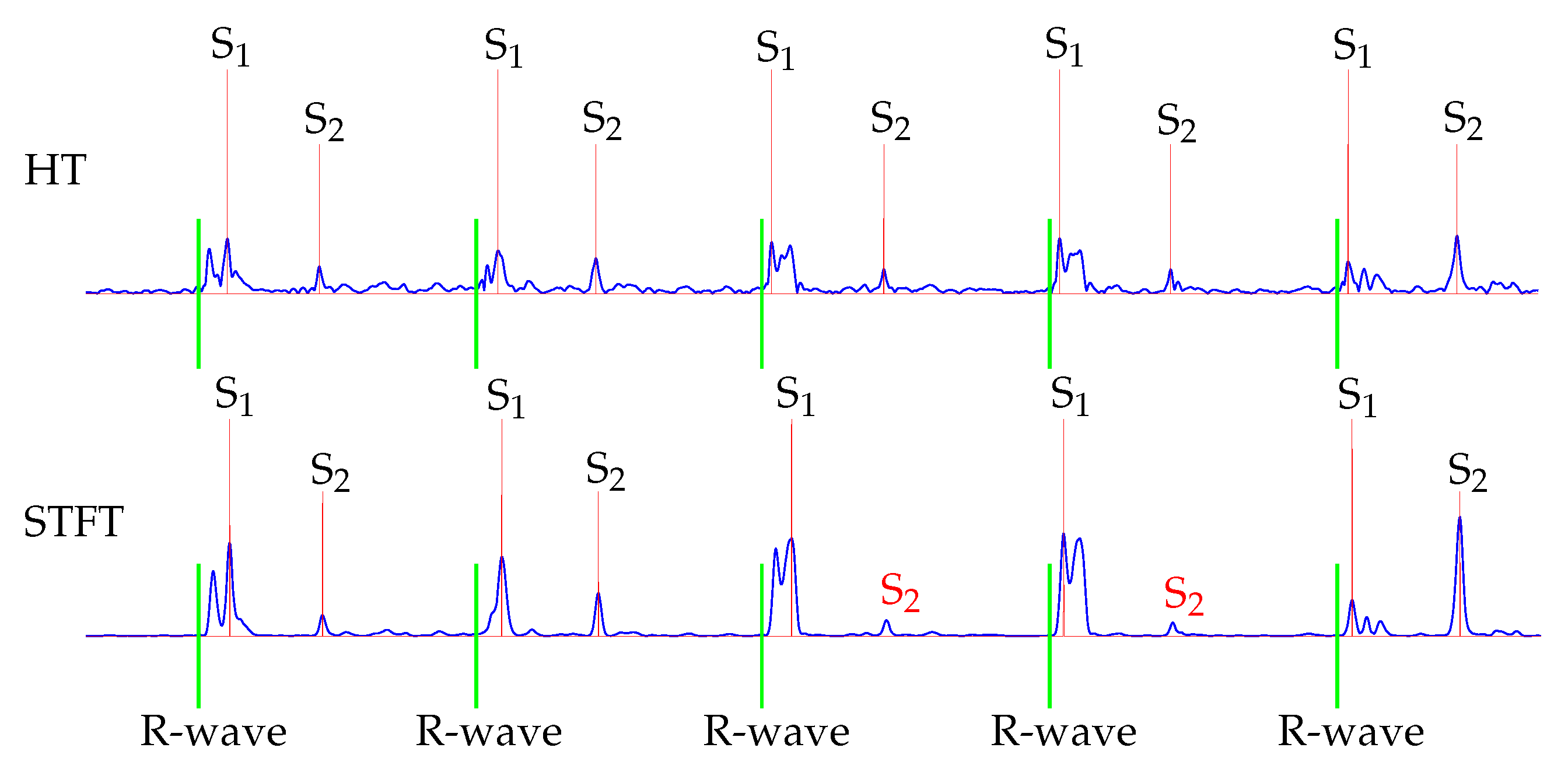
Furthermore, the classification for S
2 showed that the HT performed better. This is because the STFT was computed within a time interval, which led to an averaging of the amplitudes. Therefore, in some cases the maximal power spectral density was reduced, which was used as the envelope curve for the classification. An exemplary issue is shown in
Figure 10. The fourth and fifth S
2 were not detected by using the STFT for envelope curve extraction.
Regarding the goal of a wearable sensor solution for daily health monitoring, the computational cost and time were essential. A comparison between the computational effort of the HT and STFT is given in
Table 8. This means that a 60 s PCG signal was classified within approximately 140 ms for the HT and 480 ms for the STFT, respectively. In consequence, both methods can be regarded as real-time capable, but nevertheless, the algorithm based on the HT performed about 3 times faster than the STFT.
Wearable systems have limited computational capacity as well as power supply. Thus, it is essential to use a computational low complex algorithm for the real-time monitoring of daily life activities. Hence, the HT can be ranked as more appropriate for this purpose compared to the STFT approach.
6.6. Comparison with other Approaches
In the following, the performance parameters for the S
1 classification of the proposed algorithm are compared to other algorithms for the heart sound classification (see
Table 9). As aforementioned in
Section 1, there are three well-established groups of algorithms for heart sound classification: the feature-based, probabilistic-based and envelope-based methods. Therefore, the performance of algorithms, which represent the state of the art, was compared to the presented algorithm ones. However, it has to be noted that the performance parameters could not be directly compared to each other, since the proposed data set differed from the others. Therefore, the reference measurement of the proposed data set was used, since it was conducted under optimal conditions like it is normally applied in the literature. Furthermore, no standards for measurements and evaluation of the algorithms exist, which led to non-uniform performance parameters. Since the performance of the presented algorithm is best by using the HT, it was used for the comparison.
The database size in the literature is in most cases very small compared to the proposed one (
s). Only Springer et al. used a larger database than the proposed one [
12]. Furthermore, in many approaches very short recordings are included in their database, for example ~1 s by Renna et al. [
14], or in total 87 heart sounds by Chen et al. [
7]. Moreover, many researchers use a database like PhysioNet and do not declare their study population or recording length [
6,
9,
39]. Other researchers have conducted their measurements under optimal conditions (apart from [
39]) and no variation of the posture, auscultation point, physical stress and breathing was considered within their studies. Furthermore, the proposed study population includes only healthy subjects, in [
16,
18,
39] this was also the case.
The feature-based methods have the best performance parameters [
6,
9]. However, since feature- based methods have a strong dependency on their training datasets and a high computational effort, they are not the favourable methods for a low complex wearable sensor platform to monitor daily activities in real-time. This holds also true for probabilistic-based methods presented in [
12,
14]. However, in [
39] a real-time capable probabilistic-based method was realized with a low-cost smartphone platform. The performance, however, is poorer as the state of the art suggests, including the proposed one.
Even the average performance for different physiological conditions (e.g., physical stress, posture, BMI, auscultation point, breathing) of the presented algorithm is quite good compared with the state of the art. In consequence, the developed algorithm is robust and appropriate for a wearable sensor platform.
The presented algorithm is not able to deal with more than one extra peak, nor is able to classify pathological sounds (e.g., murmur). Thus, the performance suffers, if more than one detected peak exists within a diastole. For the probabilistic-based methods even one extra peak can be problematic, since it can lead to wrong states in their sequence.
7. Conclusions
This paper presents an enveloped-based and real-time capable algorithm for the detection and classification of the heart sounds S1 and S2 in phonocardiograms (PCG). The peaks of the envelope curve were classified and the found S1 were compared to the reference ECG. The algorithm was tested using the Hilbert transform (HT) and short-time Fourier transform (STFT) as methods to extract the envelope curve out of the PCG. The results for the heart sound classification suggested that using the HT is more favourable, due to the better performance parameters and lower computational effort. The developed algorithm is robust against the variation of the posture, heart rate, BMI, age and auscultation point, except for the back, since the PCG signals are attenuated by the lungs and backbone. As expected, the auscultation at Erb’s point provides the best result followed by the sternum. The posture and physical effort hardly effect the performance of the proposed algorithm for heart sound classification. Furthermore, the algorithm is adapted in order to deal with additional peaks caused by noise and an equal length of the systole and the diastole by an increased heart rate, respectively. Thus, the proposed measurements reflect and predict daily situations of the probands.
In the future, the envelope curves of the HT and STFT will be combined in order to increase the accuracy of the classification, since both envelope curves contain different information. Moreover, the heart rate could be estimated with the non-negative matrix factorization (NMF) out of the spectrogram, as suggested by [
23]. Therefore, the algorithm with the STFT approach could be improved. Furthermore, the presented algorithm will be combined with activity classification, as proposed in [
4]. For this purpose, the computational effort of the proposed algorithm must be reduced by an optimization of the implemented code as well as a reduction of the sampling rate of the PCG.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}