Two-Tier PSO Based Data Routing Employing Bayesian Compressive Sensing in Underwater Sensor Networks


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
- (1)
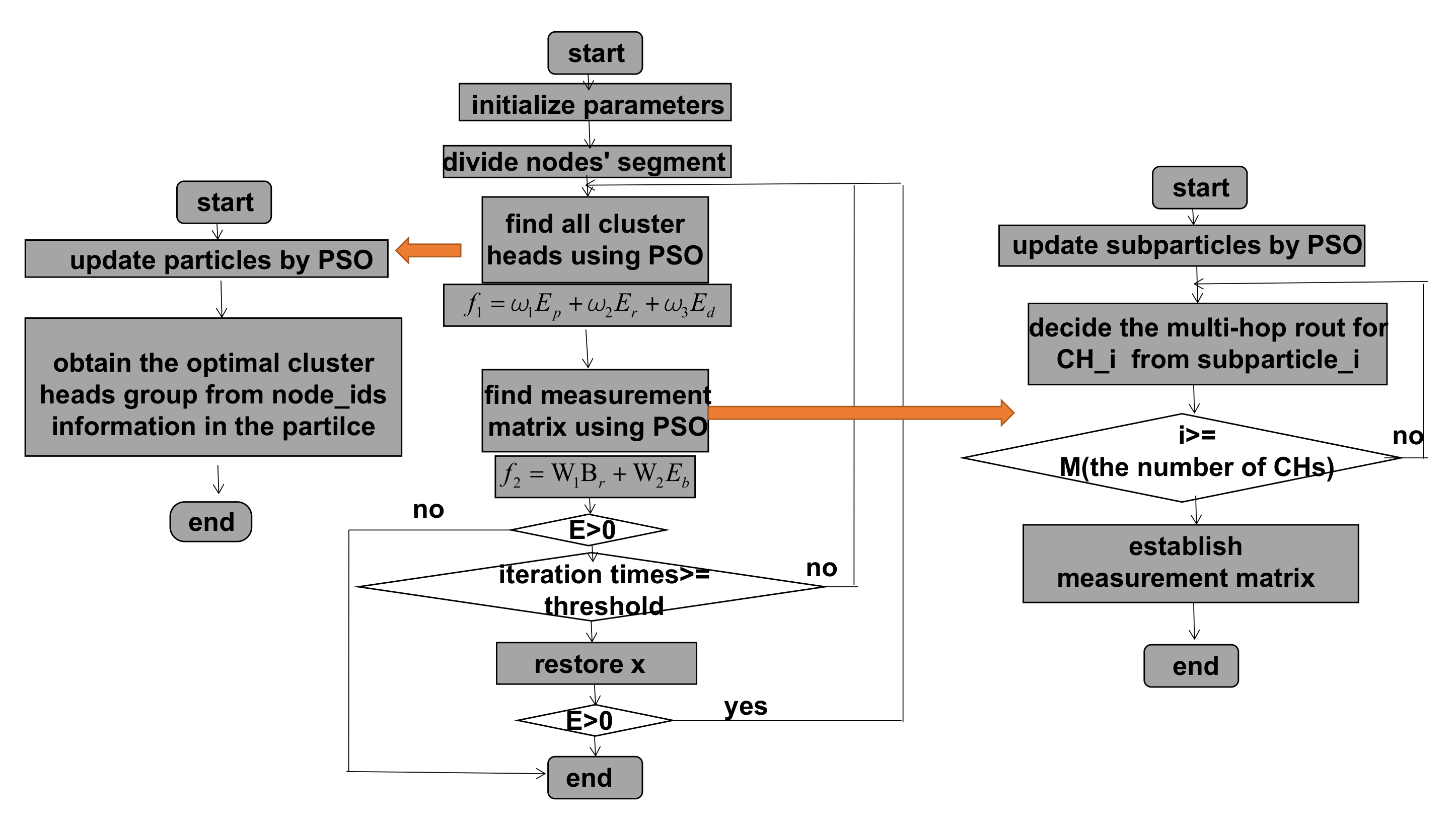
- In the first tier, a PSO-based clustering protocol is proposed to find appropriate CHs with the comprehensive consideration of energy consumption efficiency and CH distribution uniformity.
- (2)
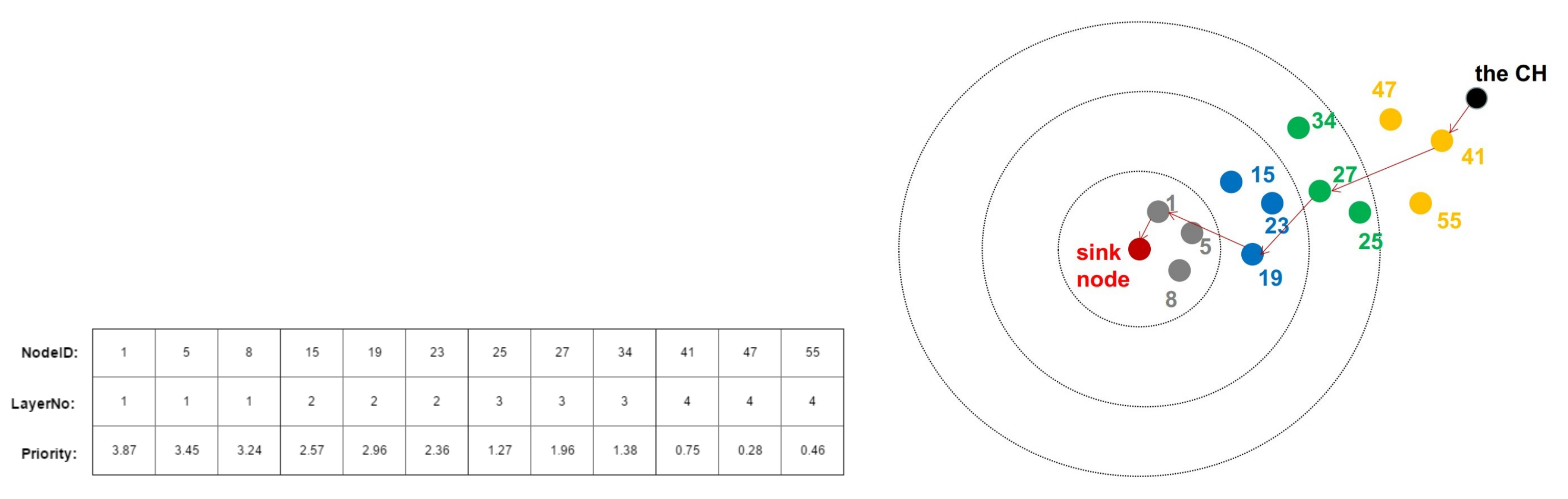
- In the second tier, a PSO-based routing protocol is introduced to find appropriate routs. A routing path consists of inner-cluster one-hop routing and outer-cluster multi-hop routing and each path corresponds to one cluster. Hence the number of paths equals to the number of clusters. It is worth mention that the multi-hop routing in our scheme is not restricted to consisting of CHs only. Note that these paths correspond to the rows of the measurement matrix for CS. In this way, we implement the combination of routing and nodes selection based on CS. Hence, the fitness function of PSO-based routing protocol comprises of several factors, including the criterions for energy efficiency, network balance, and data recovery qualities. To measure network balance, we divide the nodes in the 3-D model into different layers in accordance with their horizontal distance to the sink node. As we adopt Bayesian CS (BCS), Bayesian Cramér-Rao Bound (BCRB) is added in the fitness function to reflect the recovery performance.
- (3)
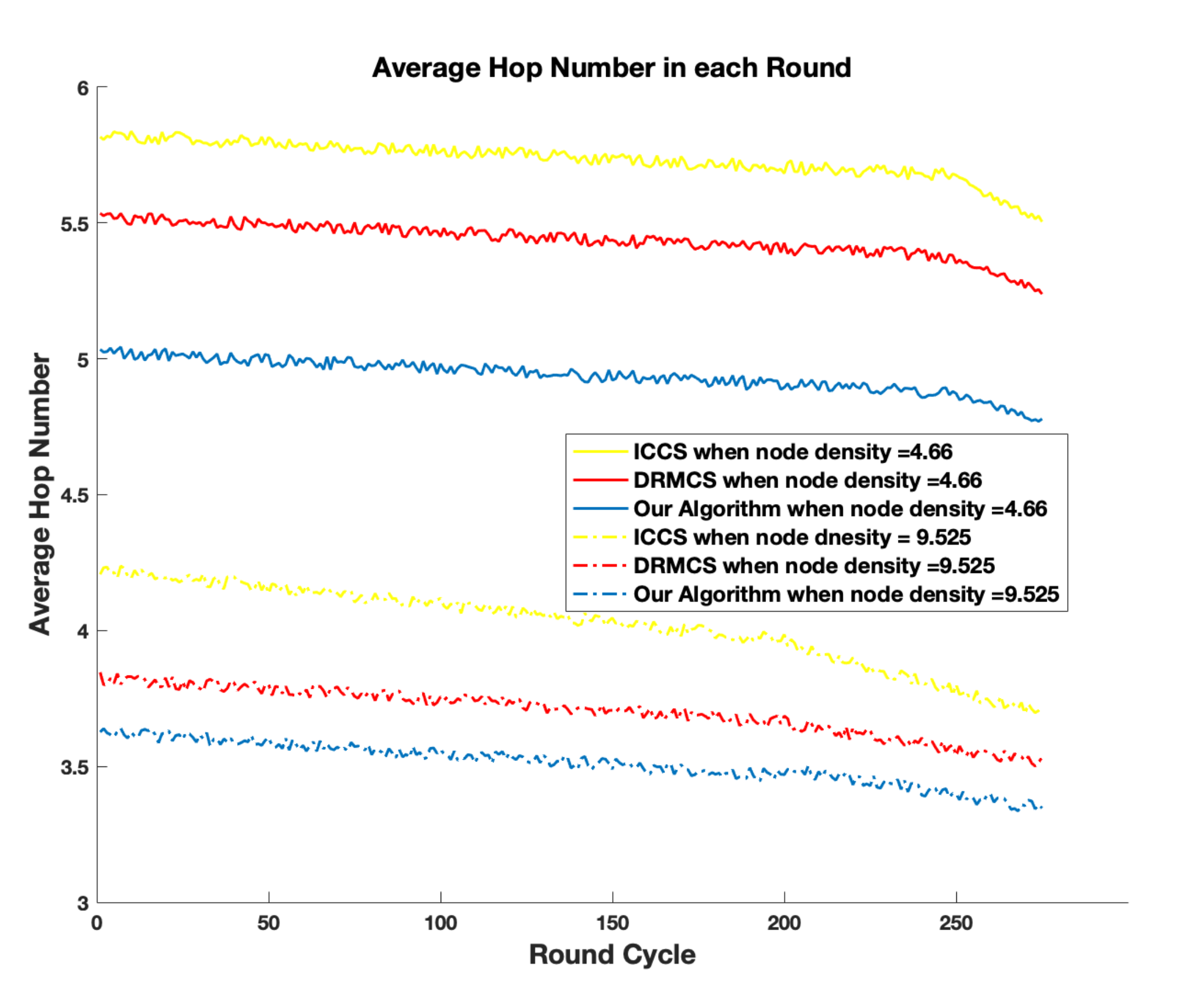
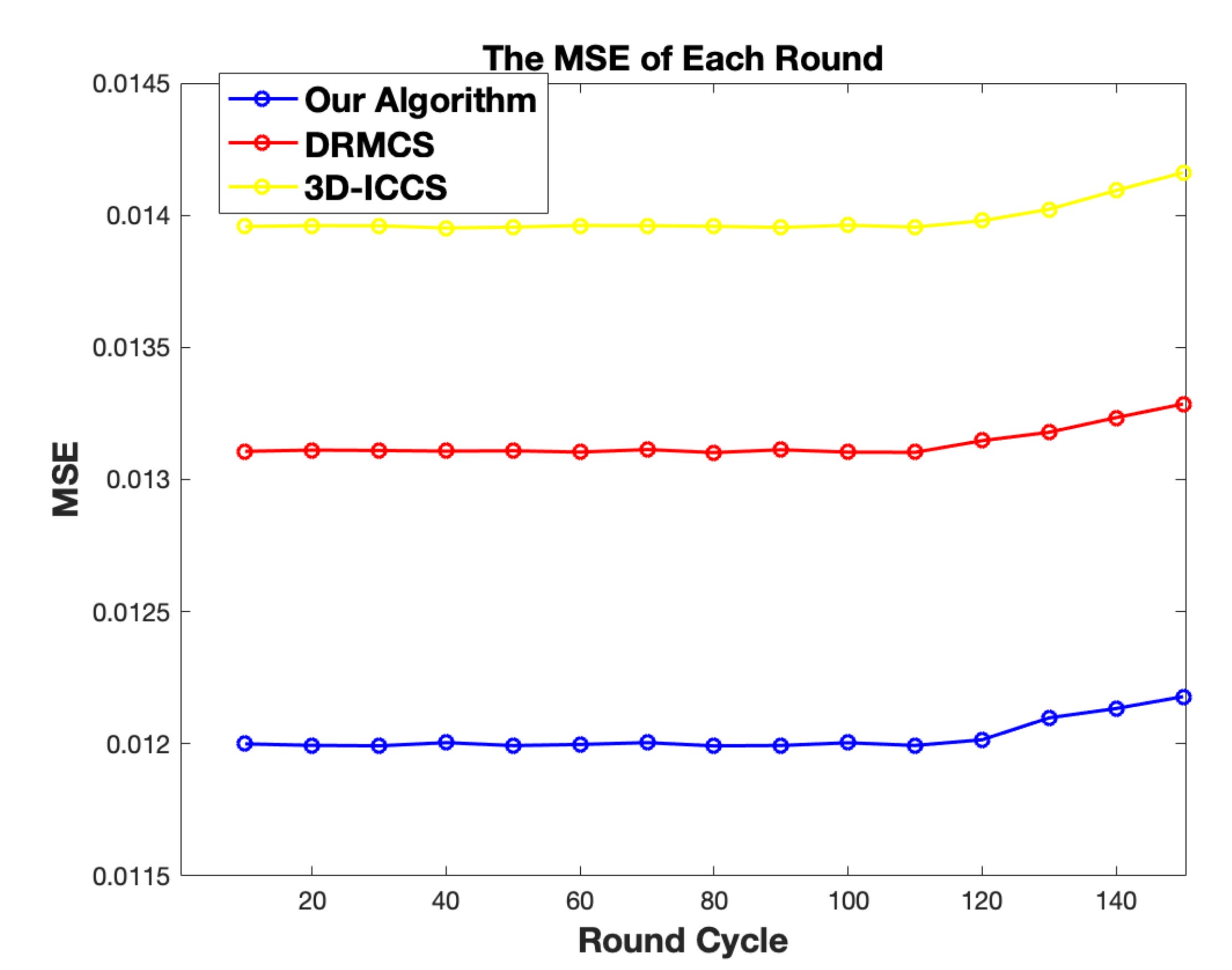
- With optimization in CH and routing chosen progress, the network could survive longer with relatively lower measurement error as demonstrated by the simulation results. What’s more, taking energy-balancing into consideration contributes to form a more balanced energy-consuming network every round cycle, and also prolongs the network lifetime and reduces the sensing error.
2. Preliminary
2.1. Compressive Sensing
2.2. Bayesian Estimation
2.3. Particle Swarm Optimization
| Algorithm 1: PSO algorithm |
| for each particle do |
| initialize particle |
| end for |
| while target fitness or maximum epoch is not attained do |
| for each particle do |
| calculate fitness |
| if current fitness value better than (pbest) then |
| pbest = current fitness |
| end if |
| end for |
| set gbest to the best one among all pbest |
| for each particle do |
| update velocity |
| update position |
| end for |
| end while |
3. Proposed System Model
4. Proposed Algorithm
4.1. BCRB Derivation
4.2. Underwater Energy Consumption Model
4.3. PSO for Clustering
- , represents the energy evaluation factor and is given bywhich measures the remaining energy of the chosen CHs.Note that is the initial energy of the i-th node while is the residual energy of the m-th node and equals to , andwhere measures the hop length when node m is the receiver and measures the hop length when node m is the transceiver.We tend to choose nodes with higher residual energy to be CHs due to the fact that cluster heads consume more energy than normal nodes.
- indicates the evaluation factor for the intra-cluster compactness and measures the average distance between nodes and their cluster heads.We calculatewhich measures the maximum average Euclidean distance between nodes and their CHs. measures the distance between node i and . is the number of nodes that belong to cluster . Our aim is to minimize f because the nodes are closer to its cluster heads with smaller f. Therefore, .
- is the evaluation factor of the uniformity of CH distribution. It measures the uniformity of CH distribution. Firstly we calculate all nodes’ distances to each other. where and measures the distance between node j and node i. In an unevenly distributed network, the sum of must be higher than relatively evenly distributed network. As a consequence, we add this value on our fitness function.
4.4. PSO for Choosing Routing Paths
- Choosing candidate nodes
- ii.
- Initialization
- iii.
- Iteration
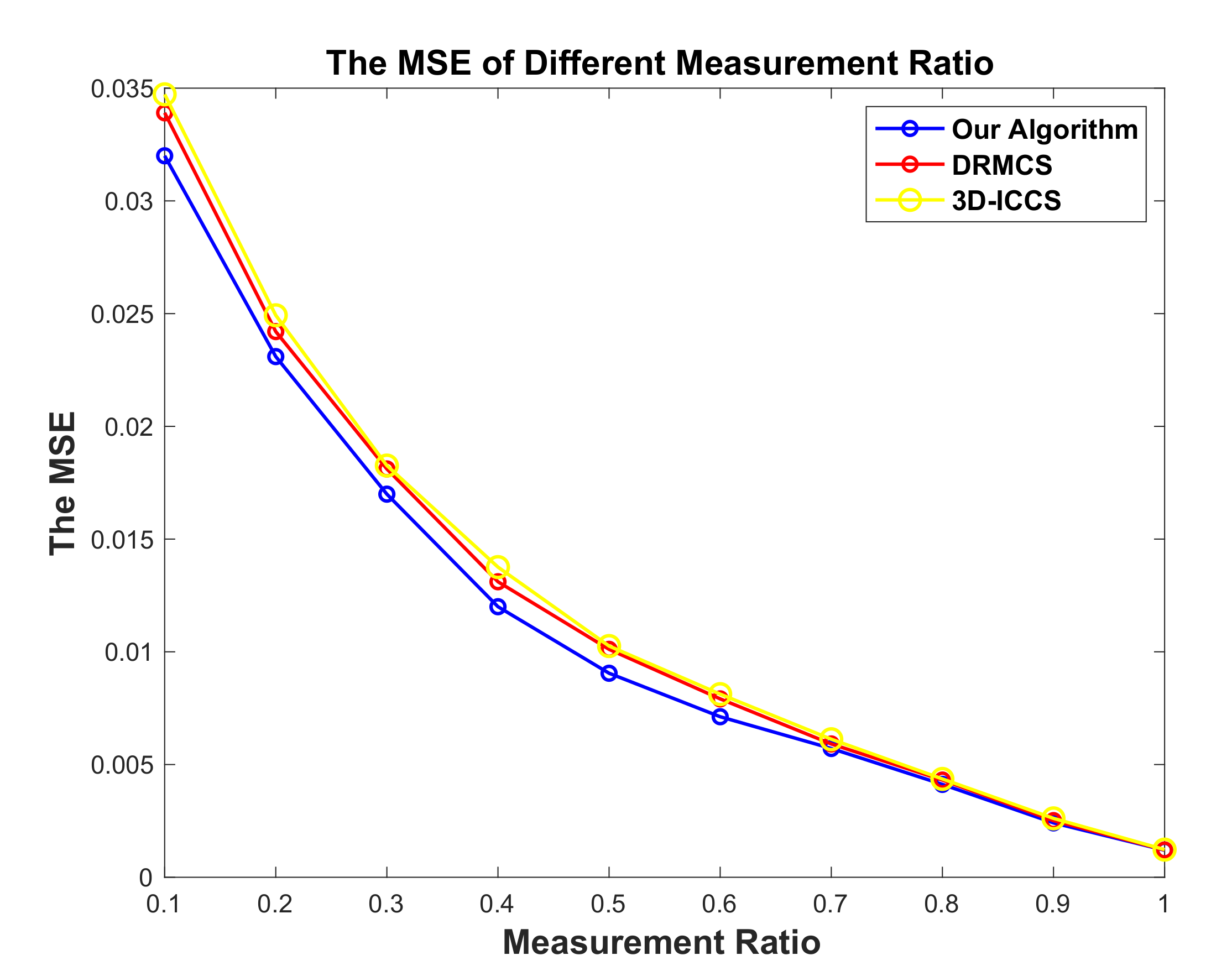
5. Simulation Results
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, Y.C.; Chen, G.W. Efficient Data Gathering and Estimation for Metropolitan Air Quality Monitoring by Using Vehicular Sensor Networks. IEEE Trans. Veh. Technol. 2017, 66, 7234–7248. [Google Scholar] [CrossRef]
- Jin, J.; Gubbi, J.; Marusic, S.; Palaniswami, M. An Information Framework for Creating A Smart City through Internet of Things. IEEE Internet Things J. 2014, 1, 112–121. [Google Scholar] [CrossRef]
- Ramírez, C.A.; Barragán, R.C.; García-Torales, G.; Larios, V.M. Low-Power Device for Wireless Sensor Network for Smart Cities. In Proceedings of the Microwave Conference (LAMC) IEEE MTT-S Latin America, Puerto Vallarta, Mexico, 12–14 December 2016. [Google Scholar]
- Mahamuni, C.V. A Military Surveillance System Based on Wireless Sensor Networks with Extended Coverage Life. In Proceedings of the 2016 International Conference on Global Trends in Signal Processing Information Computing and Communication (ICGTSPICC), Jalgaon, India, 22–24 December 2016. [Google Scholar]
- Goyal, N.; Dave, M.; Verma, A.K. Data Aggregation in Underwater Wireless Sensor Network: Recent Approaches and Issues. J. King Saud Univ.-Comput. Inf. Sci. 2019, 31, 275–286. [Google Scholar] [CrossRef]
- Chu, Y.; Hsieh, Y.; Wang, C.; Pan, Y.; Chang, R. UPHSM: Ubiquitous Personal Health Surveillance and Management System via WSN Agent on Open Source Smartphone. In Proceedings of the 13th IEEE International Conference on e-Health Networking, Applications and Services, Columbia, MO, USA, 13–15 June 2011. [Google Scholar]
- Heidemann, J.; Ye, W.; Wills, J. Research Challenges and Applications for Underwater Sensor Networking. In Proceedings of the 2006 IEEE Wireless Communications and Networking Conference (WCNC), Las Vegas, NV, USA, 3–6 April 2006. [Google Scholar]
- Wang, Z.; Han, G.; Qin, H.; Zhang, S.; Sui, Y. An Energy-Aware and Void-Avoidable Routing Protocol for Underwater Sensor Networks. IEEE Access 2018, 6, 7792–7801. [Google Scholar] [CrossRef]
- Guan, Q.; Ji, F.; Liu, Y.; Yu, H.; Chen, W. Distance-Vector-Based Opportunistic Routing for Underwater Acoustic Sensor Networks. IEEE Internet Things J. 2019, 6, 3831–3839. [Google Scholar] [CrossRef]
- Khan, W.; Wang, H. A Multi-Layer Cluster Based Energy Efficient Routing Scheme for UWSNs. IEEE Access 2019, 7, 77398–77410. [Google Scholar] [CrossRef]
- Anuradha, D.; Srivatsa, S.K. Optimal Visiting Tour Scheduling for Mobile Data Gathering in UWSN. In Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 22–24 March 2017. [Google Scholar]
- Donoho, D. Compressed Sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candés, E.J.; Romberg, J.K.; Tao, T. Stable Signal Recovery from Incomplete and Inaccurate Measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Li, F.; Liu, X. Efficient and Robust Distributed Digital Codec Framework for Jointly Sparse Correlated Signals. IEEE Access 2019, 7, 77374–77386. [Google Scholar] [CrossRef]
- Wu, F.; Yang, K.; Duan, R.; Tian, T. Compressive Sampling and Reconstruction of Acoustic Signal in Underwater Wireless Sensor Networks. IEEE Sens. J. 2018, 18, 5876–5884. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Z. Quantized Compressive Sensing for Low-Power Data Compression and Wireless Telemonitoring. IEEE Sens. J. 2016, 16, 8206–8213. [Google Scholar] [CrossRef]
- Haupt, J.; Bajwa, W.; Rabbat, M.; Nowak, R. Compressed Sensing for Networked Data. IEEE Signal Process. Mag. 2008, 25, 92–101. [Google Scholar] [CrossRef]
- Quer, G.; Masiero, R.; Pillonetto, G.; Rossi, M.; Zorzi, M. Sensing, Compression, and Recovery for Wsns: Sparse Signal Modeling and Monitoring Framework. IEEE Trans. Wirel. Commun. 2012, 11, 3447–3461. [Google Scholar] [CrossRef] [Green Version]
- Davenport, M.; Laska, J.; Treichler, J.; Baraniuk, R. The Pros and Cons of Compressive Sensing for Wideband Signal Acquisition: Noise Folding Versus Dynamic Range. IEEE Trans. Signal Process 2012, 60, 4628–4642. [Google Scholar] [CrossRef]
- Hwang, S.; Ran, R.; Yang, J.; Kim, D.K. Multivariated Bayesian Compressive Sensing in Wireless Sensor Networks. IEEE Sens. J. 2016, 16, 2196–2206. [Google Scholar] [CrossRef]
- Luo, C.; Wu, F.; Sun, J.; Chen, C.W. Efficient Measurement Generation and Pervasive Sparsity for Compressive Data Gathering. IEEE Trans. Wirel. Commun. 2010, 9, 3728–3738. [Google Scholar] [CrossRef]
- Xie, R.; Jia, X. Transmission-Efficient Clustering Method for Wireless Sensor Networks Using Compressive Sensing. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 806–815. [Google Scholar]
- Razzaque, M.A.; Dobson, S. Energy-Efficient Sensing in Wireless Sensor Networks Using Compressed Sensing. Sensors 2014, 14, 2822–2859. [Google Scholar] [CrossRef] [Green Version]
- Dengiz, O.; Konak, A.; Smith, A.E. Connectivity Management in Mobile Ad Hoc Networks using Particle Swarm Optimization. Ad Hoc Netw. 2011, 9, 1312–1326. [Google Scholar] [CrossRef]
- Shen, M.; Zhan, Z.; Chen, W.; Gong, Y.; Zhang, J.; Li, Y. Bi-Velocity Discrete Particle Swarm Optimization and Its Application to Multicast Routing Problem in Communication Networks. IEEE Trans. Ind. Electron. 2014, 61, 7141–7151. [Google Scholar] [CrossRef]
- Tukisi, T.W.; Mathaba, T.N.D. Multi-hop PSO Based Routing Protocol for Wireless Sensor Networks with Energy Harvesting. In Proceedings of the 2019 Conference on Information Communications Technology and Society (ICTAS), Durban, South Africa, 6–8 March 2019. [Google Scholar]
- RejinaParvin, J.; Vasanthanayaki, C. Particle Swarm Optimization-Based Clustering by Preventing Residual Nodes in Wireless Sensor Networks. IEEE Sens. J. 2015, 15, 4264–4274. [Google Scholar] [CrossRef]
- Nguye, M.T.; Rahnavard, N. Cluster-Based Energy-Efficient Data Collection in Wireless Sensor Networks Utilizing Compressive Sensing. In Proceedings of the Military Communications Conference, MILCOM 2013-2013 IEEE, San Diego, CA, USA, 18–20 November 2013. [Google Scholar]
- Nguyen, M.T.; Teague, K.A. Rahnavard, N. In Inter-Cluster Multi-hop Routing in Wireless Sensor Networks employing Compressive Sensing. In Proceedings of the 2014 IEEE Military Communications Conference, Baltimore, MD, USA, 6–8 October 2014. [Google Scholar]
- Nguye, M.T.; Teague, K.A.; Rahnavard, N. CCS: Energy-Efficient Data Collection in Clustered Wireless Sensor Networks Utilizing Block-Wise Compressive Sensing. Comput. Netw. 2016, 106, 171–185. [Google Scholar]
- Liu, G.; Kang, W. Distributed Random Multi-Hop Compressed Sensing in 3-D Underwater Sensor Networks. Inf. Technol. J. 2014, 13, 941–947. [Google Scholar]
- Chen, S.; Donoho, D.; Saunders, M. Atomic Decomposition by Basis Pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef] [Green Version]
- Fosson, S.M.; Matamoros, J.; Antόn-Haro, C. Distributed Recovery of Jointly Sparse Signals under Communication Constraints. IEEE Trans. Signal Process. 2016, 64, 3470–3482. [Google Scholar] [CrossRef]
- Matamoros, J.; Fosson, S.M.; Magli, E.; Antόn-Haro, C. Distributed ADMM for In-Network Reconstruction of Sparse Signals with Innovations. IEEE Trans. Signal Inf. Process. Netw. 2015, 1, 225–234. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.; Gilbert, A. Signal Recovery from Random Measurements via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Milenkovic, O. Subspace Pursuit for Compressive Sensing Signal Reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef] [Green Version]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative Signal Recovery from Incomplete and Inaccurate Samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef] [Green Version]
- Preisig, J.C. Performance Analysis of Adaptive Equalization for Coherent Acoustic Communications in the Time-Varying Ocean Environment. J. Acoust. Soc. AM 2005, 118, 263–278. [Google Scholar] [CrossRef] [Green Version]
- Iglesias, I.; Song, A.; Garcia-Frias, J.; Badiey, M.; Arce, G.R. Image Transmission Over the Underwater Acoustic Channel via Compressive Sensing. In Proceedings of the 2011 45th Annual Conference on Information Sciences and Systems, Baltimore, MD, USA, 23–25 March 2011. [Google Scholar]
- Hassanin, M.; Garcia-Frias, J. Analog Mappings for Non-linear Channels with Applications to Underwater Channels. IEEE Trans. Commun. 2020, 68, 445–455. [Google Scholar] [CrossRef]
- Ji, S.; Xue, Y.; Carin, L. Bayesian Compressive Sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Van, T.; Harry, L. Detection, Estimation and Modulation Theory; Wiley: New York, NY, USA, 2004. [Google Scholar]
- Zorzi, M.; Casari, P.; Baldo, N.; Harris, A.F. Energy-Efficient Routing Schemes for Underwater Acoustic Networks. IEEE J. Sel. Areas Commun. 2008, 26, 1754–1766. [Google Scholar] [CrossRef]
- Stojanovic, M. On the Relationship Between Capacity and Distance in an Underwater Acoustic Communication Channel. In Proceedings of the International Workshop on UnderWater Networks (WUWNet), Los Angeles, CA, USA, 25 September 2006. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Energy Consumption Parameter | Values |
|---|---|
| 0.5 | |
| (bps/Hz) | 0.5 |
| k | 1.5 |
| (dB) | 8 |
| (W) | 2 |
| b (dB re kHz) | 14.39 |
| (dB re kHz/km) | −0.55 |
| (km) | 3.5 |
| Energy Consumption | Reconstruction Error | |
|---|---|---|
| 0.2 | 3.164 | 0.01419 |
| 0.4 | 3.643 | 0.01201 |
| 0.6 | 4.445 | 0.01249 |
| 0.8 | 5.050 | 0.01240 |
| Energy Consumption | Reconstruction Error | |
| 0.2 | 3.157 | 0.01421 |
| 0.4 | 3.655 | 0.01203 |
| 0.6 | 4.426 | 0.01251 |
| 0.8 | 5.039 | 0.01242 |
| Energy Consumption | Reconstruction Error | |
| 0.2 | 3.168 | 0.01437 |
| 0.4 | 3.637 | 0.01208 |
| 0.6 | 4.439 | 0.01257 |
| 0.8 | 5.012 | 0.01248 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Xiong, W.; Chu, S. Two-Tier PSO Based Data Routing Employing Bayesian Compressive Sensing in Underwater Sensor Networks. Sensors 2020, 20, 5961. https://doi.org/10.3390/s20205961
Chen X, Xiong W, Chu S. Two-Tier PSO Based Data Routing Employing Bayesian Compressive Sensing in Underwater Sensor Networks. Sensors. 2020; 20(20):5961. https://doi.org/10.3390/s20205961
Chicago/Turabian StyleChen, Xuechen, Wenjun Xiong, and Sheng Chu. 2020. "Two-Tier PSO Based Data Routing Employing Bayesian Compressive Sensing in Underwater Sensor Networks" Sensors 20, no. 20: 5961. https://doi.org/10.3390/s20205961
APA StyleChen, X., Xiong, W., & Chu, S. (2020). Two-Tier PSO Based Data Routing Employing Bayesian Compressive Sensing in Underwater Sensor Networks. Sensors, 20(20), 5961. https://doi.org/10.3390/s20205961