In-Situ Screening of Soybean Quality with a Novel Handheld Near-Infrared Sensor

 ,
, 


Abstract
:1. Introduction
2. Materials and Methods
2.1. Sample Preparation
2.2. Reference Analysis
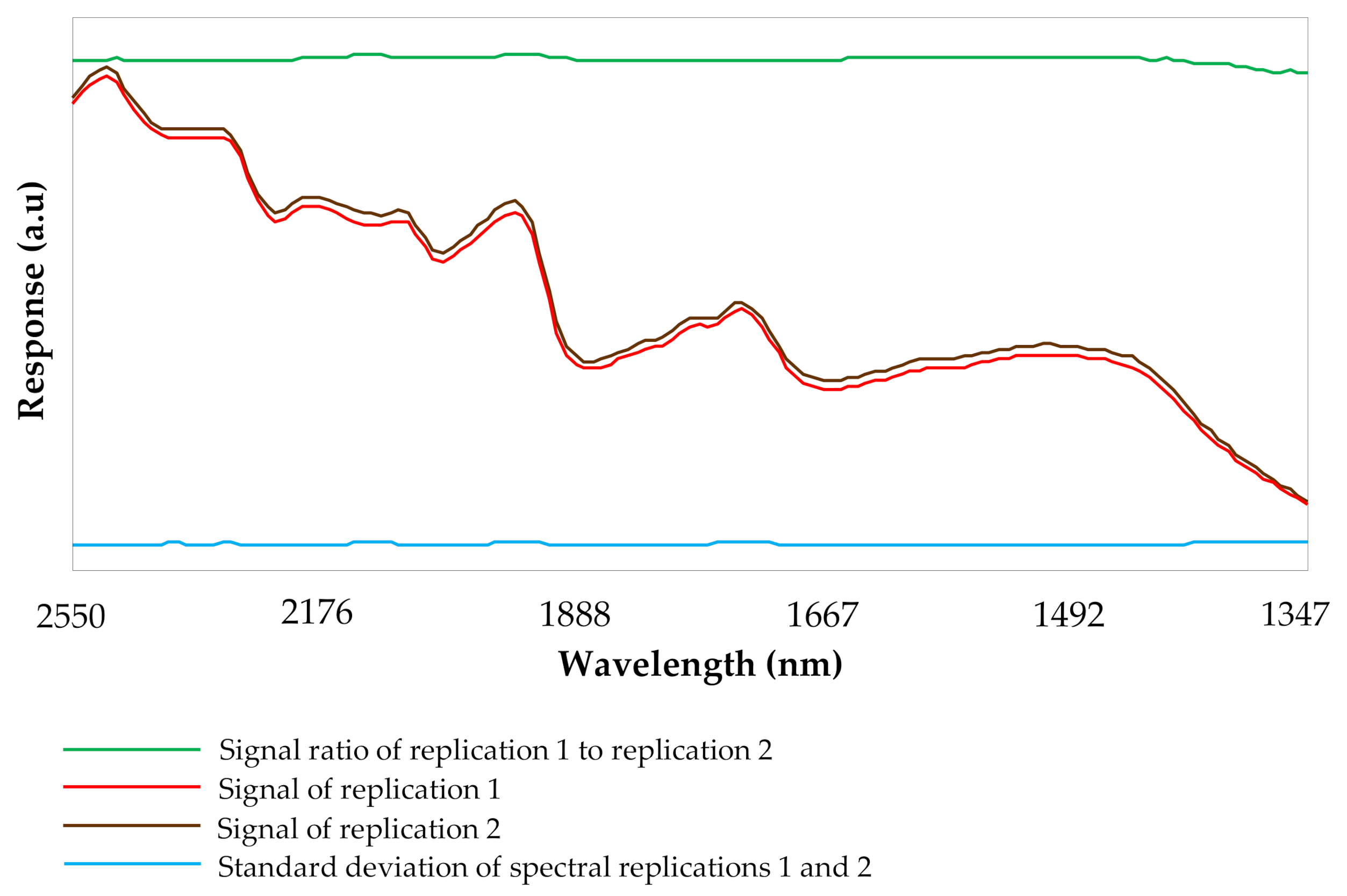
2.3. NIR Spectroscopic Analysis
2.4. Statistical Analysis
2.5. Multivariate Analysis
3. Results
3.1. Characterization of Soybean Samples
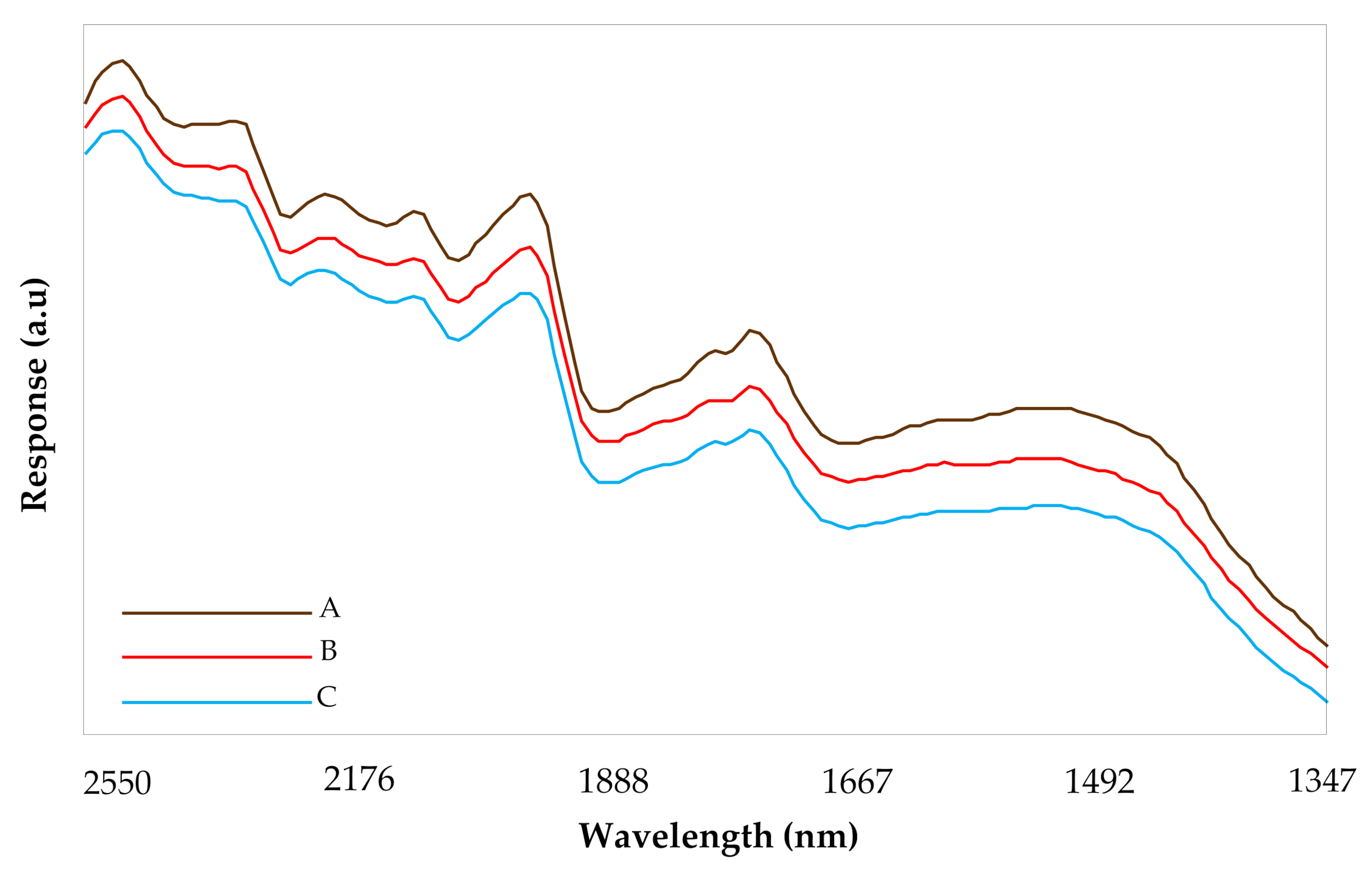
3.2. Characterization of NIR Spectra
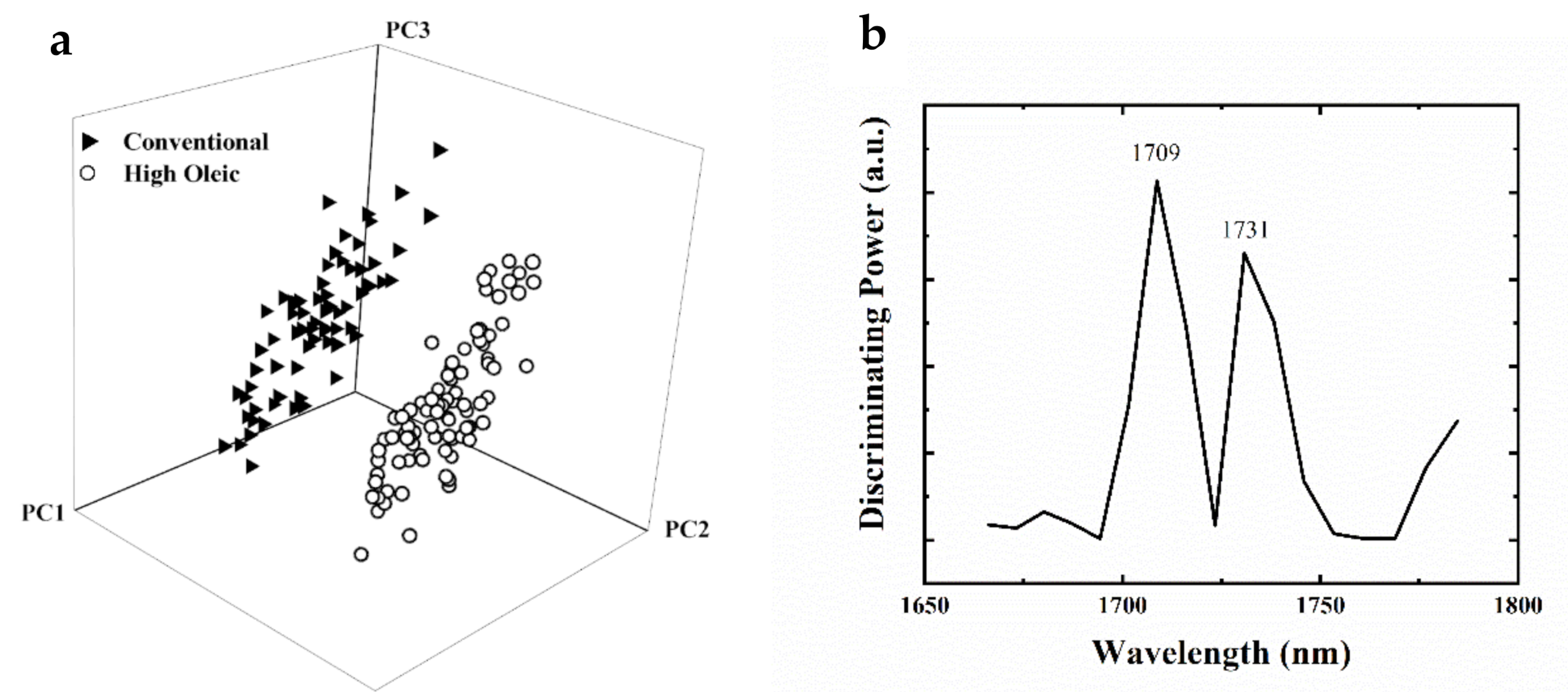
3.3. SIMCA Classification Model for High-Oleic vs. Conventional Soybeans
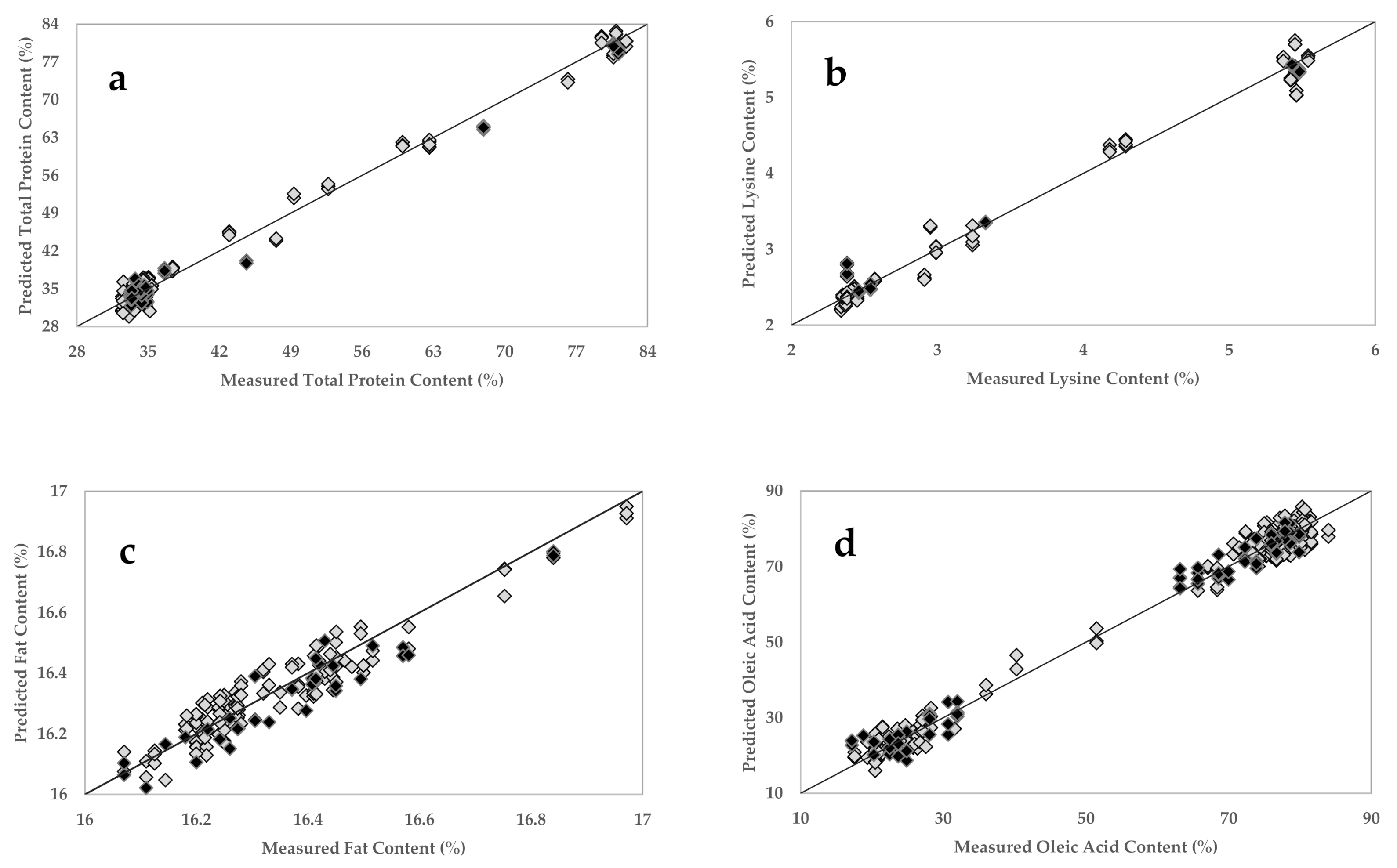
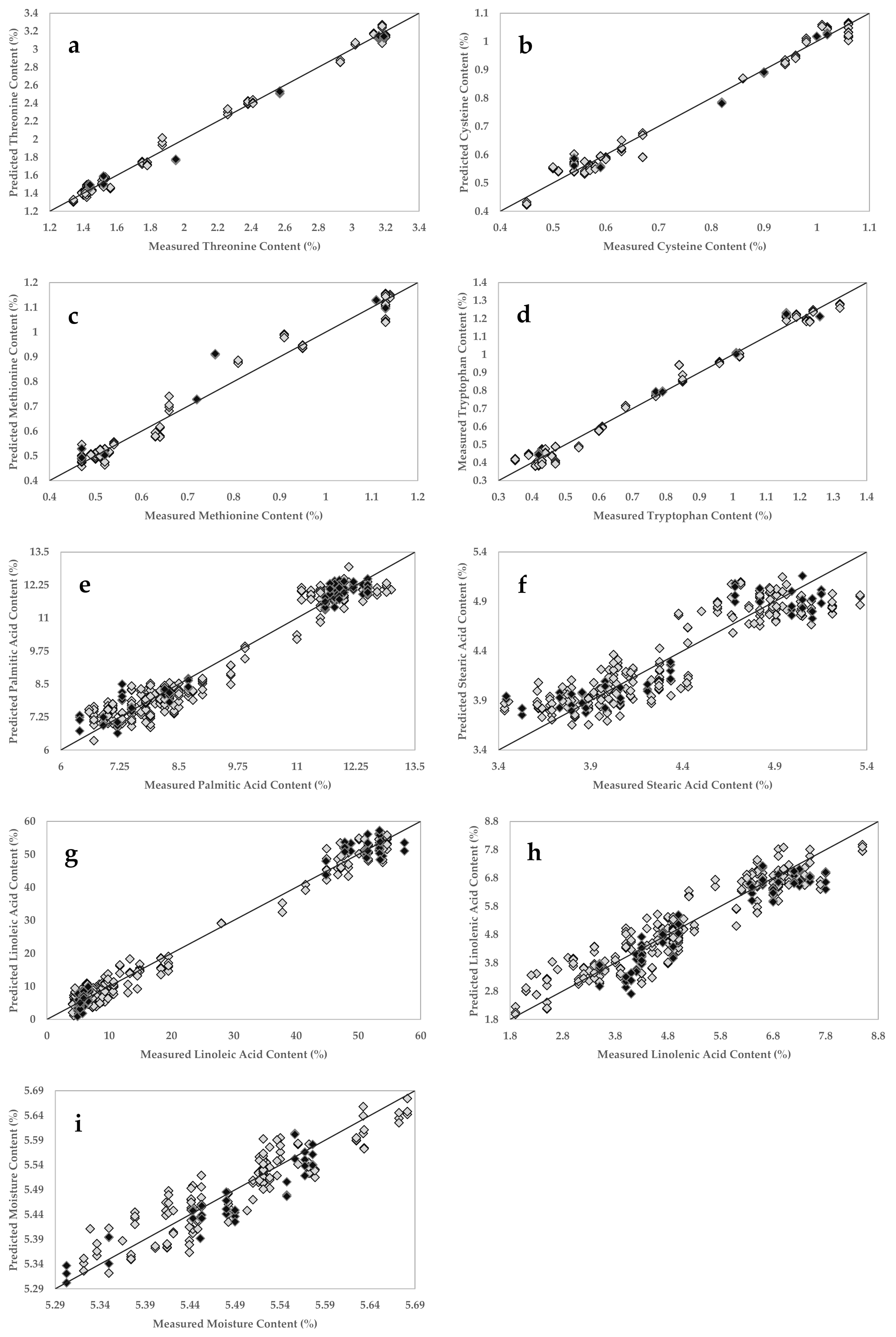
3.4. Regression Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B

Appendix C

References
- U.S. Department of Agriculture World Agricultural Supply and Demand Estimates. Available online: https://www.usda.gov/oce/commodity/wasde/wasde0920.pdf (accessed on 10 June 2020).
- Hartman, G.L.; West, E.D.; Herman, T.K. Crops that feed the World 2. Soybean-worldwide production, use, and constraints caused by pathogens and pests. Food Secur. 2011, 3, 5–17. [Google Scholar] [CrossRef]
- USDA Economic Research Service Soybeans & Oil Crops. Available online: https://www.ers.usda.gov/topics/crops/soybeans-oil-crops/ (accessed on 10 June 2020).
- Goldsmith, P.D. Economics of soybean production, marketing, and utilization. In Soybeans-Chemistry, Production Processing, and Utilization; Johnson, L.A., White, P.J., Galloway, R., Eds.; AOCS Press: Urbana, IL, USA, 2008; Volume 2, pp. 117–150. [Google Scholar]
- Miller-Garvin, J.; Naeve, S. United States Soybean Quality Annual Report 2017. Available online: https://ussec.org/wp-content/uploads/2017/12/2017.12.21-U.S.-Soy-Quality-Report.pdf (accessed on 29 December 2018).
- Demorest, Z.L.; Coffman, A.; Baltes, N.J.; Stoddard, T.J.; Clasen, B.M.; Luo, S.; Retterath, A.; Yabandith, A.; Gamo, M.E.; Bissen, J.; et al. Direct stacking of sequence-specific nuclease-induced mutations to produce high oleic and low linolenic soybean oil. BMC Plant Biol. 2016, 16, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Flores, T.; Karpova, O.; Su, X.; Zeng, P.; Bilyeu, K.; Sleper, D.A.; Nguyen, H.T.; Zhang, Z.J. Silencing of GmFAD3 gene by siRNA leads to low α-linolenic acids (18:3) of fad3-mutant phenotype in soybean [Glycine max (Merr.)]. Transgenic Res. 2008, 17, 839–850. [Google Scholar] [CrossRef] [PubMed]
- Kanai, M.; Yamada, T.; Hayashi, M.; Mano, S.; Nishimura, M. Soybean (Glycine max L.) triacylglycerol lipase GmSDP1 regulates the quality and quantity of seed oil. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Darrigues, A.; Lamkey, K.R.; Scott, M.P. Breeding for Grain Amino Acid Composition in Maize. In Plant Breeding: The Arnel R. Hallauer International Symposium; Lamkey, K.R., Lee, M., Eds.; Blackwell Publishing: Ames, IA, USA, 2006; pp. 335–344. [Google Scholar]
- Perrin, R. The Impact of Component Pricing of Soybeans and Milk. Am. Agric. Econ. Assoc. 1980, 62, 445–455. [Google Scholar] [CrossRef]
- U.S. Soybean Export Council. U.S. Soy’s Superior Value is Demonstrated Through More Nutrients, Greater Consistency. Available online: https://ussec.org/u-s-soys-superior-demonstrated-nutrients-greater-consistency/ (accessed on 10 June 2020).
- Carbas, B.; Machado, N.; Oppolzer, D.; Ferreira, L.; Brites, C.; Rosa, E.A.S.; Barros, A.I.R.N.A. Comparison of near-infrared (NIR) and mid-infrared (MIR) spectroscopy for the determination of nutritional and antinutritional parameters in common beans. Food Chem. 2020, 306, 125509. [Google Scholar] [CrossRef]
- Hacisalihoglu, G.; Freeman, J.; Armstrong, P.R.; Seabourn, B.W.; Porter, L.D.; Settles, A.M.; Gustin, J.L. Protein, weight, and oil prediction by single-seed near-infrared spectroscopy for selection of seed quality and yield traits in pea (Pisum sativum). J. Sci. Food Agric. 2020, 100, 3488–3497. [Google Scholar] [CrossRef] [PubMed]
- Weng, Y.; Shi, A.; Ravelombola, W.S.; Yang, W.; Qin, J.; Motes, D.; Moseley, D.O.; Chen, P. A Rapid Method for Measuring Seed Protein Content in Cowpea (Vigna unguiculata (L.) Walp). Am. J. Plant Sci. 2017, 8, 2387–2396. [Google Scholar] [CrossRef] [Green Version]
- Bagchi, T.B.; Sharma, S.; Chattopadhyay, K. Development of NIRS models to predict protein and amylose content of brown rice and proximate compositions of rice bran. Food Chem. 2016, 191, 21–27. [Google Scholar] [CrossRef]
- Ferreira, D.S.; Galão, O.F.; Pallone, J.A.L.; Poppi, R.J. Comparison and application of near-infrared (NIR) and mid-infrared (MIR) spectroscopy for determination of quality parameters in soybean samples. Food Control 2014, 35, 227–232. [Google Scholar] [CrossRef]
- Holse, M.; Larsen, F.H.; Hansen, Å.; Engelsen, S.B. Characterization of marama bean (Tylosema esculentum) by comparative spectroscopy: NMR, FT-Raman, FT-IR and NIR. Food Res. Int. 2011, 44, 373–384. [Google Scholar] [CrossRef]
- Laporte, M.F.; Paquin, P. Near-infrared analysis of fat, protein, and casein in cow’s milk. J. Agric. Food Chem. 1999, 47, 2600–2605. [Google Scholar] [CrossRef]
- Williams, P.C.; Stevenson, S.G.; Starkey, P.M.; Hawtin, G.C. The application of near infrared reflectance spectroscopy to protein-testing in pulse breeding programmes. J. Sci. Food Agric. 1978, 29, 285–292. [Google Scholar] [CrossRef]
- Jiang, G.L. Comparison and application of non-destructive NIR evaluations of seed protein and oil content in soybean breeding. Agronomy 2020, 10, 77. [Google Scholar] [CrossRef] [Green Version]
- Xu, R.; Hu, W.; Zhou, Y.; Zhang, X.; Xu, S.; Guo, Q.; Qi, P.; Chen, L.; Yang, X.; Zhang, F.; et al. Use of near-infrared spectroscopy for the rapid evaluation of soybean [Glycine max (L.) Merri.] water soluble protein content. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 224, 117400. [Google Scholar] [CrossRef]
- Dunmire, K.M.; Dhakal, J.; Stringfellow, K.; Stark, C.R.; Paulk, C.B. Evaluating Soybean Meal Quality Using Near-Infrared Reflectance Spectroscopy Evaluating Soybean Meal Quality Using Near-Infrared Reflectance Spectroscopy. Kans. Agric. Exp. Stn. Res. Rep. 2019, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Boisen, S.; Hvelplund, T.; Weisbjerg, M.R. Ideal amino acid profiles as a basis for feed protein evaluation. Livest. Prod. Sci. 2000, 64, 239–251. [Google Scholar] [CrossRef]
- Pazdernik, D.L.; Killam, A.S.; Orf, J.H. Analysis of amino and fatty acid composition in soybean seed, using near infrared reflectance spectroscopy. Agron. J. 1997, 89, 679–685. [Google Scholar] [CrossRef]
- Chen, G.L.; Zhang, B.; Wu, J.G.; Shi, C.H. Nondestructive assessment of amino acid composition in rapeseed meal based on intact seeds by near-infrared reflectance spectroscopy. Anim. Feed Sci. Technol. 2011, 165, 111–119. [Google Scholar] [CrossRef]
- Fontaine, J.; Hörr, J.; Schirmer, B. Near-infrared reflectance spectroscopy enables the fast and accurate prediction of the essential amino acid contents in soy, rapeseed meal, sunflower meal, peas, fishmeal, meat meal products, and poultry meal. J. Agric. Food Chem. 2001, 49, 57–66. [Google Scholar] [CrossRef]
- Rosales, A.; Galicia, L.; Oviedo, E.; Islas, C.; Palacios-Rojas, N. Near-infrared reflectance spectroscopy (NIRS) for protein, tryptophan, and lysine evaluation in quality protein maize (QPM) breeding programs. J. Agric. Food Chem. 2011, 59, 10781–10786. [Google Scholar] [CrossRef]
- Tallada, J.G.; Palacios-Rojas, N.; Armstrong, P.R. Prediction of maize seed attributes using a rapid single kernel near infrared instrument. J. Cereal Sci. 2009, 50, 381–387. [Google Scholar] [CrossRef]
- Plans, M.; Simó, J.; Casañas, F.; Sabaté, J.; Rodriguez-saona, L. Characterization of common beans (Phaseolus vulgaris L.) by infrared spectroscopy: Comparison of MIR, FT-NIR and dispersive NIR using portable and benchtop instruments. FRIN 2013, 54, 1643–1651. [Google Scholar] [CrossRef]
- Teixeira Dos Santos, C.A.; Lopo, M.; Páscoa, R.N.M.J.; Lopes, J.A. A review on the applications of portable near-infrared spectrometers in the agro-food industry. Appl. Spectrosc. 2013, 67, 1215–1233. [Google Scholar] [CrossRef]
- Crocombe, R.A. Portable Spectroscopy. Appl. Spectrosc. 2018, 72, 1701–1751. [Google Scholar] [CrossRef]
- Rodriguez-Saona, L.; Aykas, D.P.; Borba, K.R.; Urtubia, A. Miniaturization of optical sensors and their potential for high-throughput screening of foods. Curr. Opin. Food Sci. 2020, 31, 136–150. [Google Scholar] [CrossRef]
- Jones, B. Factors for Converting Percentages of Nitrogen in Foods and Feeds into Percentages of Proteins; U.S. Department of Agriculture Circular No. 183; U.S. Department of Agriculture: Washington, DC, USA, 1931; pp. 1–22. [Google Scholar]
- U.S. Department of Agriculture Composition of Foods Raw, Processed, Prepared. USDA National Nutrient Database for Standard Reference SR, Release 27. Available online: https://data.nal.usda.gov/dataset/composition-foods-raw-processed-prepared-usda-national-nutrient-database-standard-referenc-0 (accessed on 7 July 2020).
- Tome, D.; Cordella, C.; Dib, O.; Peron, C. Nitrogen and Protein Content Measurement and Nitrogen to Protein Conversion Factors for Dairy and Soy Protein-Based Foods: A Systematic Review and Modelling Analysis. Available online: https://www.who.int/publications/i/item/9789241516983 (accessed on 24 June 2020).
- Abdi, H. Partial least squares regression and projection on latent structure regression (PLS Regression). Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 97–106. [Google Scholar] [CrossRef]
- Kvalheim, O.M.; Karstang, T.V. SIMCA-classification by means of disjoint cross validated principal components models. In Multivariate Pattern Recognition in Chemometrics, Illustrated by Case Studies; Brereton, R.G., Ed.; Elsevier: Amsterdam, The Netherlands, 1992; pp. 209–248. [Google Scholar]
- Karunathilaka, S.R.; Yakes, B.J.; He, K.; Chung, J.K.; Mossoba, M. Non-targeted NIR spectroscopy and SIMCA classification for commercial milk powder authentication: A study using eleven potential adulterants. Heliyon 2018, 4, e00806. [Google Scholar] [CrossRef] [Green Version]
- Sivakesava, S.; Irudayaraj, J. A rapid spectroscopic technique for determining honey adulteration with corn syrup. J. Food Sci. 2001, 66, 787–791. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Banaszkiewicz, T. Nutritional Value of Soybean Meal. In Soybean and Nutrition; El-Shemy, H.A., Ed.; InTech: Rijeka, Croatia, 2011; pp. 1–20. ISBN 978-953-307-536-5. [Google Scholar]
- U.S. Department of Agriculture. 2011 Soybean Export Farmgate Assesment Data. Available online: https://www.ams.usda.gov/sites/default/files/media/soyexport2011data.pdf (accessed on 24 June 2020).
- Singh, P.; Kumar, R.; Sabapathy, S.N.; Bawa, A.S. Functional and edible uses of soy protein products. Compr. Rev. Food Sci. Food Saf. 2008, 7, 14–28. [Google Scholar] [CrossRef]
- Preece, K.E.; Hooshyar, N.; Zuidam, N.J. Whole soybean protein extraction processes: A review. Innov. Food Sci. Emerg. Technol. 2017, 43, 163–172. [Google Scholar] [CrossRef] [Green Version]
- Assefa, Y.; Bajjalieh, N.; Archontoulis, S.; Casteel, S.; Davidson, D.; Kovács, P.; Naeve, S.; Ciampitti, I.A. Spatial Characterization of Soybean Yield and Quality (Amino Acids, Oil, and Protein) for United States. Sci. Rep. 2018, 8, 1–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- dos Santos, E.L.; Pípolo, A.E.; de Faria, R.T.; Prete, C.E.C. Influence of genotype on protein and oil concentration of soybean seeds. Braz. Arch. Biol. Technol. 2010, 53, 793–799. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.J.; Ha, B.K.; Ha, K.S.; Chae, J.H.; Park, J.H.; Kim, M.S.; Asekova, S.; Shannon, J.G.; Son, C.K.; Lee, J.D. Comparison of a high oleic acid soybean line to cultivated cultivars for seed yield, protein and oil concentrations. Euphytica 2015, 201, 285–292. [Google Scholar] [CrossRef]
- Zhu, Z.; Chen, S.; Wu, X.; Xing, C.; Yuan, J. Determination of soybean routine quality parameters using near-infrared spectroscopy. Food Sci. Nutr. 2018, 6, 1109–1118. [Google Scholar] [CrossRef]
- Bazoni, C.H.V.; Ida, E.I.; Barbin, D.F.; Kurozawa, L.E. Near-infrared spectroscopy as a rapid method for evaluation physicochemical changes of stored soybeans. J. Stored Prod. Res. 2017, 73, 1–6. [Google Scholar] [CrossRef]
- Zarkadas, C.G.; Gagnon, C.; Gleddie, S.; Khanizadeh, S.; Cober, E.R.; Guillemette, R.J.D. Assessment of the protein quality of fourteen soybean [Glycine max (L.) Merr.] cultivars using amino acid analysis and two-dimensional electrophoresis. Food Res. Int. 2007, 40, 129–146. [Google Scholar] [CrossRef]
- Carrera, C.S.; Reynoso, C.M.; Funes, G.J.; Martinez, M.J.; Dardanelli, J.; Resnik, S.L. Amino acid composition of soybean seeds as affected by climatic variables. Pesqui. Agropecuária Bras. 2011, 46, 1579–1587. [Google Scholar] [CrossRef]
- Singh, S.; Patel, S.; Litoria, N.; Gandhi, K.; Faldu, P.; Patel, K.G. Comparative Efficiency of Conventional and NIR Based Technique for Proximate Composition of Pigeon Pea, Soybean and Rice Cultivars Comparative Efficiency of Conventional and NIR Based Technique for Proximate Composition of Pigeon Pea, Soybean and Rice C. Int. J. Curr. Microbiol. Appl. Sci. 2018, 7, 773–782. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Qu, S.Y. Nondestructive Method for Analysis of the Soybean Quality Nondestructive Method for Analysis of the Soybean Quality. Int. J. Food Eng. 2012, 8. [Google Scholar] [CrossRef]
- Napolitano, G.E.; Ye, Y.; Cruz-Hernandez, C. Chemical Characterization of a High-Oleic Soybean Oil. JAOCS J. Am. Oil Chem. Soc. 2018, 95, 583–589. [Google Scholar] [CrossRef]
- Cournoyer, P. Biotechnology Notification File No. 000164 CFSAN Note to the File. Available online: https://www.fda.gov/media/120708/download (accessed on 18 June 2020).
- Abdelghany, A.M.; Zhang, S.; Azam, M.; Shaibu, A.S.; Feng, Y.; Qi, J.; Li, Y.; Tian, Y.; Hong, H.; Li, B. Natural Variation in Fatty Acid Composition of Diverse World Soybean Germplasms Grown in China. Agronomy 2020, 10, 24. [Google Scholar] [CrossRef] [Green Version]
- Narayan, R.; Chauhan, G.S.; Verma, N.S. Changes in the quality of soybean during storage. Part 1-Effect of storage on some physico-chemical properties of soybean. Food Chem. 1988, 27, 13–23. [Google Scholar] [CrossRef]
- La, T.C.; Pathan, S.M.; Vuong, T.; Lee, J.D.; Scaboo, A.M.; Smith, J.R.; Gillen, A.M.; Gillman, J.; Ellersieck, M.R.; Nguyen, H.T.; et al. Effect of high-oleic acid soybean on seed oil, protein concentration, and yield. Crop Sci. 2014, 54, 2054–2062. [Google Scholar] [CrossRef]
- Mermelstein, N.H. Improving soybean oil. Food Technol. 2010, 64, 72–77. [Google Scholar]
- Pasquini, C. Near infrared spectroscopy: Fundamentals, practical aspects and analytical applications. J. Braz. Chem. Soc. 2003, 14, 198–219. [Google Scholar] [CrossRef] [Green Version]
- Subramanian, A.; Rodriguez-Saona, L. Fourier Transform Infrared (FTIR) Spectroscopy. In Infrared Spectroscopy for Food Quality Analysis and Control; Sun, D.-W., Ed.; Elsevier Inc.: Burlington, NJ, USA, 2009; pp. 145–178. ISBN 9780123741363. [Google Scholar]
- Liu, Y.; Cho, R.K.; Sakurai, K.; Miura, T.; Ozaki, Y. Studies on spectra/structure correlations in near-infrared spectra of proteins and polypeptides. Part I: A marker band for hydrogen bonds. Appl. Spectrosc. 1994, 48, 1249–1254. [Google Scholar] [CrossRef]
- Wang, H.; Johnson, L.A.; Wang, T. Preparation of soy protein concentrate and isolate from extruded-expelled soybean meals. JAOCS J. Am. Oil Chem. Soc. 2004, 81, 713–717. [Google Scholar] [CrossRef]
- Sharma, S.; Kaur, M.; Goyal, R.; Gill, B.S. Physical characteristics and nutritional composition of some new soybean (Glycine max (L.) Merrill) genotypes. J. Food Sci. Technol. 2014, 51, 551–557. [Google Scholar] [CrossRef] [Green Version]
- Shenk, J.S.; Workman, J.J.; Westerhaus, M.O. Application of NIR Spectroscopy to Agricultural Products. In Handbook of Near-Infrared Analysis; Burns, D.A., Ciurczak, E.W., Eds.; CRC Press: Boca Raton, FL, USA, 2008; pp. 347–386. ISBN 978-0-8493-7393-0. [Google Scholar]
- Wold, S.; Sjöström, M. SIMCA: A Method for Analyzing Chemical Data in Terms of Similarity and Analogy. In Chemometrics: Theory and Application; Kowalski, B.R., Ed.; American Chemical Society: Washington, DC, USA, 1977; pp. 243–282. ISBN 9780841203792. [Google Scholar]
- Myrzakozha, D.; Turgaliev, D.; Sato, H. Determination of Fatty-Acid Composition in Oils of Animal Origin by Near-Infrared Spectroscopy. Food Nutr. Sci. 2014, 5, 1408–1414. [Google Scholar] [CrossRef] [Green Version]
- Hemmateenejad, B.; Akhond, M.; Samari, F. A comparative study between PCR and PLS in simultaneous spectrophotometric determination of diphenylamine, aniline, and phenol: Effect of wavelength selection. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2007, 67, 958–965. [Google Scholar] [CrossRef]
- Ingle, P.D.; Christian, R.; Purohit, P.; Zarraga, V.; Handley, E.; Freel, K.; Abdo, S. Determination of protein content by NIR spectroscopy in protein powder mix products. J. AOAC Int. 2016, 99, 360–363. [Google Scholar] [CrossRef]
- Ferreira, D.S.; Pallone, J.A.L.; Poppi, R.J. Fourier transform near-infrared spectroscopy (FT-NIRS) application to estimate Brazilian soybean [Glycine max (L.) Merril] composition. Food Res. Int. 2013, 51, 53–58. [Google Scholar] [CrossRef] [Green Version]
- Balastreri, C.; Baretta, D.; Paulino, A.T. Near-Infrared Spectroscopy and Multivariate Analysis for the Determination of Nutritional Value of Soybean Meal and Maize Bran. Anal. Lett. 2016, 49, 1548–1563. [Google Scholar] [CrossRef]
- Asekova, S.; Han, S.; Choi, H.; Park, S.; Shin, D.; Kwon, C.; Shannon, J.G.; Lee, J. Determination of forage quality by near-infrared reflectance spectroscopy in soybean. Turk. J. Agric. For. 2016, 40, 45–52. [Google Scholar] [CrossRef] [Green Version]
- Kovalenko, I.V.; Rippke, G.R.; Hurburgh, C.R. Determination of amino acid composition of soybeans (Glycine max) by near-infrared spectroscopy. J. Agric. Food Chem. 2006, 54, 3485–3491. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roberts, C.A.; Ren, C.; Beuselinck, P.R.; Benedict, H.R.; Bilyeu, K. Fatty Acid Profiling of Soybean Cotyledons by Near-Infrared Spectroscopy. Appl. Spectrosc. 2006, 60, 1328–1333. [Google Scholar] [CrossRef]
- Liang, L.; Wei, L.; Fang, G.; Xu, F.; Deng, Y.; Shen, K.; Tian, Q.; Wu, T.; Zhu, B. Prediction of holocellulose and lignin content of pulp wood feedstock using near infrared spectroscopy and variable selection. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 225, 117515. [Google Scholar] [CrossRef]
- Jiang, H.; Jiang, X.; Ru, Y.; Chen, Q.; Xu, L.; Zhou, H. Sweetness Detection and Grading of Peaches and Nectarines by Combining Short- and Long-Wave Fourier-Transform Near-Infrared Spectroscopy. Anal. Lett. 2020. [Google Scholar] [CrossRef]
- Aykas, D.P.; Rodriguez-Saona, L.E. Assessing potato chip oil quality using a portable infrared spectrometer combined with pattern recognition analysis. Anal. Methods 2016, 8, 731–741. [Google Scholar] [CrossRef]
- Hayes, D.J.M.; Hayes, M.H.B.; Leahy, J.J. Use of near infrared spectroscopy for the rapid low-cost analysis of waste papers and cardboards. Faraday Discuss. 2017, 202, 465–482. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter (%) * | Minimum | Maximum | Mean | STDEV ** | CV% *** | |
|---|---|---|---|---|---|---|
| Threonine | Soybean | 1.34 | 1.56 | 1.45 | 0.06 | 4.17 |
| Soy Products | 1.75 | 3.20 | 2.64 | 0.54 | 20.46 | |
| Cysteine | Soybean | 0.45 | 0.60 | 0.55 | 0.04 | 7.20 |
| Soy Products | 0.63 | 1.06 | 0.92 | 0.14 | 15.52 | |
| Methionine | Soybean | 0.47 | 0.64 | 0.51 | 0.04 | 5.02 |
| Soy Products | 0.63 | 1.14 | 0.95 | 0.20 | 22.39 | |
| Lysine | Soybean | 2.34 | 2.57 | 2.43 | 0.07 | 2.88 |
| Soy Products | 2.91 | 5.54 | 4.50 | 1.08 | 24.37 | |
| Tryptophan | Soybean | 0.35 | 0.54 | 0.44 | 0.04 | 10.04 |
| Soy Products | 0.60 | 1.32 | 0.99 | 0.23 | 23.31 | |
| Total Protein | Soybean | 32.48 | 37.4 | 34.12 | 0.89 | 1.81 |
| Soy Products | 42.96 | 81.91 | 67.39 | 14.46 | 21.45 | |
| Palmitic Acid | Soybean | 6.22 | 13.4 | 9.19 | 2.57 | 22.93 |
| Stearic Acid | 3.53 | 5.21 | 4.40 | 0.54 | 11.79 | |
| Oleic Acid | 17.60 | 84.00 | 52.83 | 28.05 | 42.04 | |
| Linoleic Acid | 4.10 | 57.40 | 27.29 | 22.88 | 91.23 | |
| Linolenic Acid | 1.88 | 8.19 | 4.53 | 2.43 | 30.38 | |
| Fat | 16.07 | 16.97 | 16.35 | 0.18 | 1.11 | |
| Moisture | 5.30 | 5.68 | 5.49 | 0.09 | 1.59 |
| Parameter (%) * | High-Oleic | Conventional | p-Value ** |
|---|---|---|---|
| Total Protein | 34.17 ± 0.61 | 33.66 ± 0.60 | 0.000 |
| Fat | 16.42 ± 0.19 | 16.27 ± 0.10 | 0.000 |
| Palmitic Acid | 7.00 ± 0.52 | 11.95 ± 0.69 | 0.000 |
| Stearic Acid | 3.87 ± 0.33 | 4.91 ± 0.23 | 0.000 |
| Oleic Acid | 79.25 ± 2.00 | 23.35 ± 3.65 | 0.000 |
| Linoleic Acid | 5.99 ± 1.32 | 51.61 ± 3.13 | 0.000 |
| Linolenic Acid | 2.21 ± 0.32 | 7.09 ± 0.53 | 0.000 |
| Parameter (%) * | Calibration Model | External Validation Model | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Range | N a | Factor | RMSECV b | Rcv c | Range | n d | RMSEP e | RPre f | RPD g | RER h | |
| Threonine | 1.34–3.20 | 26 | 6 | 0.05 | 1.00 | 1.44–3.19 | 6 | 0.08 | 1.00 | 8.7 | 22.3 |
| Cysteine | 0.45–1.06 | 26 | 4 | 0.03 | 0.99 | 0.54–1.02 | 6 | 0.02 | 0.99 | 8.8 | 19.9 |
| Methionine | 0.47–1.14 | 26 | 4 | 0.04 | 0.99 | 0.47–1.13 | 6 | 0.07 | 0.97 | 3.8 | 9.7 |
| Lysine | 2.34–5.54 | 26 | 5 | 0.17 | 0.99 | 2.38–5.48 | 6 | 0.15 | 1.00 | 8.6 | 21.2 |
| Tryptophan | 0.35–1.32 | 26 | 4 | 0.04 | 0.99 | 0.42–1.26 | 6 | 0.04 | 0.99 | 8.2 | 21.2 |
| Total Protein | 32.48–81.91 | 73 | 4 | 1.51 | 0.99 | 33.28–81.15 | 18 | 1.64 | 0.99 | 8.3 | 29.2 |
| Palmitic Acid | 6.50–13.00 | 77 | 5 | 0.49 | 0.97 | 6.40–12.50 | 19 | 0.40 | 0.98 | 4.8 | 15.1 |
| Stearic Acid | 3.43–5.36 | 70 | 6 | 0.21 | 0.91 | 3.44–5.15 | 17 | 0.21 | 0.93 | 2.4 | 8.3 |
| Oleic Acid | 17.60–84.00 | 76 | 5 | 3.04 | 0.99 | 17.20–79.90 | 19 | 3.07 | 0.99 | 8.1 | 20.5 |
| Linoleic Acid | 4.10–54.60 | 77 | 5 | 2.48 | 0.99 | 4.90–57.40 | 19 | 2.71 | 0.99 | 7.2 | 19.4 |
| Linolenic Acid | 1.90–8.50 | 76 | 5 | 0.55 | 0.94 | 3.50–7.80 | 19 | 0.56 | 0.95 | 2.8 | 7.6 |
| Fat | 16.07–16.97 | 46 | 6 | 0.05 | 0.95 | 16.07–16.84 | 12 | 0.07 | 0.96 | 2.6 | 13.3 |
| Moisture | 5.32–5.68 | 45 | 6 | 0.04 | 0.91 | 5.30–5.58 | 11 | 0.04 | 0.92 | 2.4 | 7.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aykas, D.P.; Ball, C.; Sia, A.; Zhu, K.; Shotts, M.-L.; Schmenk, A.; Rodriguez-Saona, L. In-Situ Screening of Soybean Quality with a Novel Handheld Near-Infrared Sensor. Sensors 2020, 20, 6283. https://doi.org/10.3390/s20216283
Aykas DP, Ball C, Sia A, Zhu K, Shotts M-L, Schmenk A, Rodriguez-Saona L. In-Situ Screening of Soybean Quality with a Novel Handheld Near-Infrared Sensor. Sensors. 2020; 20(21):6283. https://doi.org/10.3390/s20216283
Chicago/Turabian StyleAykas, Didem Peren, Christopher Ball, Amanda Sia, Kuanrong Zhu, Mei-Ling Shotts, Anna Schmenk, and Luis Rodriguez-Saona. 2020. "In-Situ Screening of Soybean Quality with a Novel Handheld Near-Infrared Sensor" Sensors 20, no. 21: 6283. https://doi.org/10.3390/s20216283
APA StyleAykas, D. P., Ball, C., Sia, A., Zhu, K., Shotts, M. -L., Schmenk, A., & Rodriguez-Saona, L. (2020). In-Situ Screening of Soybean Quality with a Novel Handheld Near-Infrared Sensor. Sensors, 20(21), 6283. https://doi.org/10.3390/s20216283