1. Introduction
Developmental studies, particularly those with preverbal young children, pose a unique challenge in that participants are unable to provide an oral account of their decision or preferences. Noninvasive techniques which do not require verbal abilities, such as pupil dilation and fixation time measures, have been successfully employed in studies with infants and young children to gain insight into their cognition [
1,
2,
3,
4,
5,
6]. One looking time method taps on young children’s spontaneous responses to events which violate their expectations given their understanding of the world [
7,
8,
9]. In Setoh et al. [
6], for example, eight-month-old infants’ looking time was used as a measure to investigate their abstract biological expectations about animals. The violation-of-expectation (VOE) paradigm has also been used to examine infants’ understanding of basic numeracy [
10], false beliefs [
11], and even whether objects can fly [
12]. This paradigm has even been successfully utilised in infant studies on newborns as young as four days old [
13]. The VOE framework is based on the premise that young children tend to fixate at events that violate their expectation for a longer amount of time than at events that do not. In both adult [
14] and infant [
15] populations, contemporary researchers have used eye-tracking technology to measure changes in the eyes, such as fixation timing and pupil dilation, in response to experimental tasks. For instance, pupil dilation and constriction in adult participants varied as a function of the presentation of pictures with different emotional valence [
16]. Moreover, a recent review by Moch et al. [
17] found that duration, as well as location of eye fixations can be reliable indices of underlying numerical processing in adults. Employing methods based on habituation and VOE, researchers have been able to investigate preverbal children’s moral understanding. Similar methods have been employed to show that preverbal toddlers disapprove of disgusting acts [
18], show prosocial behavior [
19,
20], differentiate between good and evil [
21,
22], and display empathy and compassion [
23].
Despite the benefits of the approach, fixation time paradigms present some limitations. In a recent ethnographic study, Peterson [
24] discussed the problems related to the VOE paradigm. In VOE experiments, infants or young children’s attention is typically measured as the interval of time that occurs between the offset of presentation of a stimuli to the moment in which the infant or child loses interest towards the scene [
5]. Children’s looking time at the scene is used as an indicator of the attention [
25]. Although eye-tracking devices can be employed to automatically record looking time, a visual inspection of recorded videos is usually performed to manually verify the usability of a sample. This is because testing children presents its own set of challenges. While it is possible to ask adult participants to stay still after the eye-tracking machine has been calibrated, the same cannot be expected for infants and toddlers. For example, a child may look away frequently because he is distracted, but the sample will be reported by the eye-tracking device as acceptable if each fixation away from the screen is shorter than a preset look-away threshold, which is usually set at 2 s [
5]. Another scenario could be that a sample may be reported as
unusable if the child moved away from the eye-tracker calibration point despite being attentive. The manual inspection stage is generally performed by trained researchers and is often conducted by multiple individuals in order to ascertain observer reliability. The problem with manual inspection and selection of samples after data collection is not only in the additional time incurred but also that these judgements of what makes a sample
usable or
unusable may not be reproducible or consistent across different studies or different laboratories [
24,
26]. As pointed out by Peterson [
24], working with young children requires researchers to practice constant and active decision making, in both the execution of the experiment and coding of the children’s behavioural recordings. Despite the wide adoption of the VOE paradigm in infant and child studies, standardised impartial methods to code for inclusion or exclusion of samples based on behavioural measures have not been developed.
Previous works have shown that Machine Learning (ML) models can be successfully employed to study neurophysiological signals. In Gabrieli et al. [
27], for example, different machine learning models were tested to verify the possibility of classifying infants’ vocalisations while in other works the technique was shown to be suitable for the automatic identification of physiological signal quality [
28,
29]. Li et al. [
29], for example, employed Support Vector Machines (SVM) models to distinguish between clean and noisy electrocardiogram (ECG) recording. For what concerns SVMs application to eye-tracking, Pauly et al. Pauly and Sankar [
30] demonstrated the suitability of the models for the detection of drowsiness from adults’ eye-tracked blinks. Similarly, Kang et al. [
31] employed SMV classifiers to distinguish between autistic versus typically developing three to six year old children using eye-tracking and EEG recordings. In an analogue way, different studies employed a Linear SVM for different classification tasks involving eye-tracking data. Dalrymple et al. [
32], for example, successfully employed Linear SVM classifiers on eye-tracking data to identify the age of toddlers, while Wang et al. [
33] used Linear SVM, in combination with gaze data to quantify atypical visual saliency in children diagnosed with autism spectrum disorder. Linear and Non-Linear SVM are not the only classifiers that have been successfully employed on eye-tracking data. K-nearest neighbor (kNN) classifiers have been widely employed to make classification out of eye-tracking and gazing data. Zhang et al. [
34], Kacur et al. [
35] used a kNN classifier to diagnose schizophrenia disorders using an eye-tracking system during Rorschach Inkblot Test [
36].
It is therefore possible that ML models can be employed to objectively classify the usability of infants’ and young children’s fixation time recordings, and in doing so, reduce the subjectivity of behavioural codings as decided by researchers themselves.
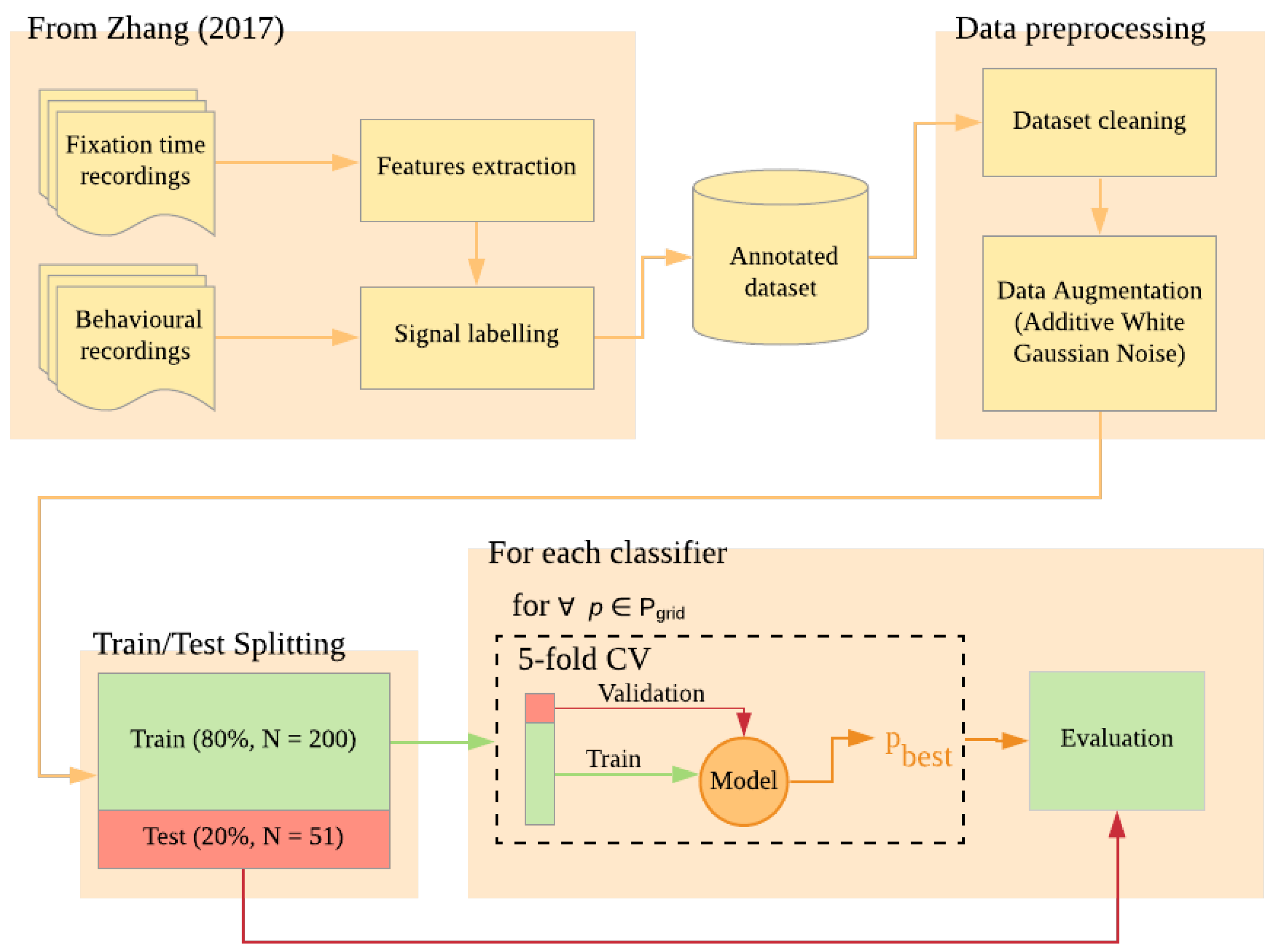
Here we aim at testing three different classifiers: a Linear SVM, a Non-Linear SVM, and a kNN classifiers. Our method involves a binary classification task, where data of one trial have to be classified as usable or unusable. For each trial, three repetitions are conducted with each child, therefore resulting in a dataset with a small number of features. Given the typical number of participants of toddlers’ studies, the total number of samples within the database is expected to be small. Typical of this type of data, it is expected that different trials in toddlers’ VOE studies have similar duration—which is the time elapsed between the onset of a stimuli and the moment in which the toddler loses focus on the stimuli. If the duration of the trials is similar, and it is longer for valid trials—which is when toddlers are looking at the stimuli—and given the small dimensionality of the dataset, we should expect a classifier based on a Linear SVM to be suitable for the task. The limitations with this approach are that the assumption of linearity does not take into account the possibility that subsequent trials may be valid but have different duration, such as in the case in which one trial is significantly longer than the previous or subsequent one, nor does it take into account the effect of repetitions. While we can expect a novelty effect on the first trial, the effect will be reduced on subsequent trials. For these reasons, a SVM based on a non-linear kernel may provide better performances, as compared to a SVM classifier that employs a linear kernel. Additionally, given the nature of the data, we expect high similarity between valid and invalid trials between different participants in toddlers’ VOE studies. For this reason, it is well-founded to assume that to obtain a classifier that can be easily extended to future studies, a nonparametric classifier which is less influenced by autocorrelation and multicollinearity should be preferred over a parametric classifier [
37]. Therefore, we decided to test a kNN classifier, which is a nonparametric instance-based learning classifier that can be effectively deployed and integrated with other tools.
Aim and Hypothesis
In this work, we investigated the possibility of using ML models on toddlers’ fixation time data to automatically separate usable from unusable trials. More specifically, we hypothesise that novel machine learning models can be trained on human-labelled fixation signal trials to predict the usability of these trials at a greater than chance level.
3. Results
Results of models’ performances on the validation—with the best set of parameters obtained during the hyperparameters tuning procedure—and on the test set are reported in
Table 3. The best set of parameters, selected through the hyperparameter tuning phase, are reported in
Appendix A.
Results show that all the employed classifiers achieved an accuracy above chance level (Accuracy ). In terms of Accuracy and Recall on the test set, the Nearest Neighbors classifier outperformed the models based on Linear and Non-Linear SVC. A comparison of the models based on the McNemar’s test (Python 3.8.5, statsmodels 0.12.0), revealed significant differences in the performances of the Linear-SVC models with both the Non-Linear SVC () and the K-neighbors () classifiers; however, no significant differences are present between the performances of the Non-Linear SVC and the K-neighbors classifiers ().
Additionally, the K-Neighbors classifiers scored higher on both the F1 Score and the MCC measures (F1 = 0.875, MCC = 0.493), as compared to the Linear (F1 = 0.676, 0.262) and Non-Linear SVC (F1 = 0.795, MCC = 0.492) Classifiers, as shown in
Table 3.
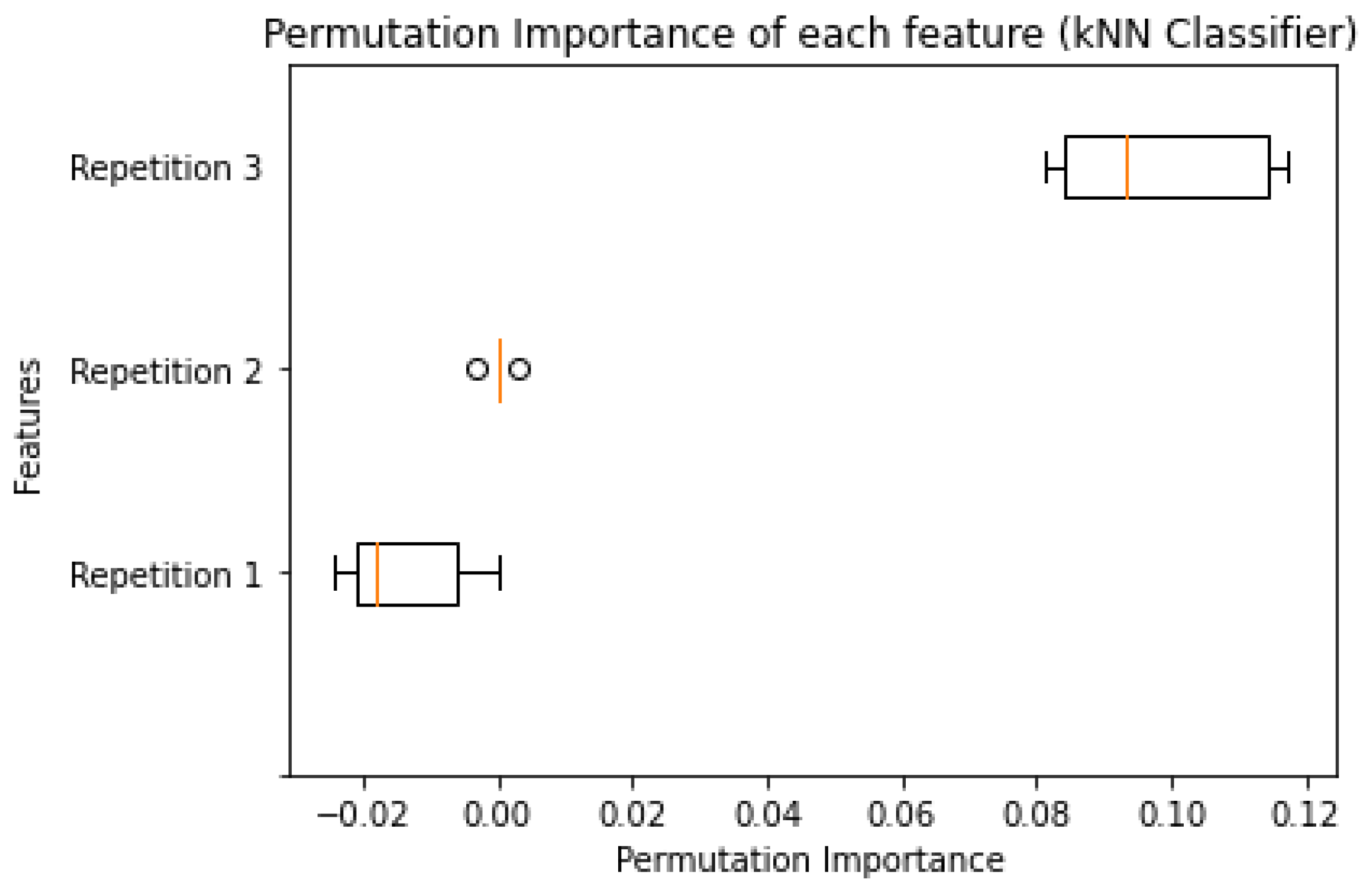
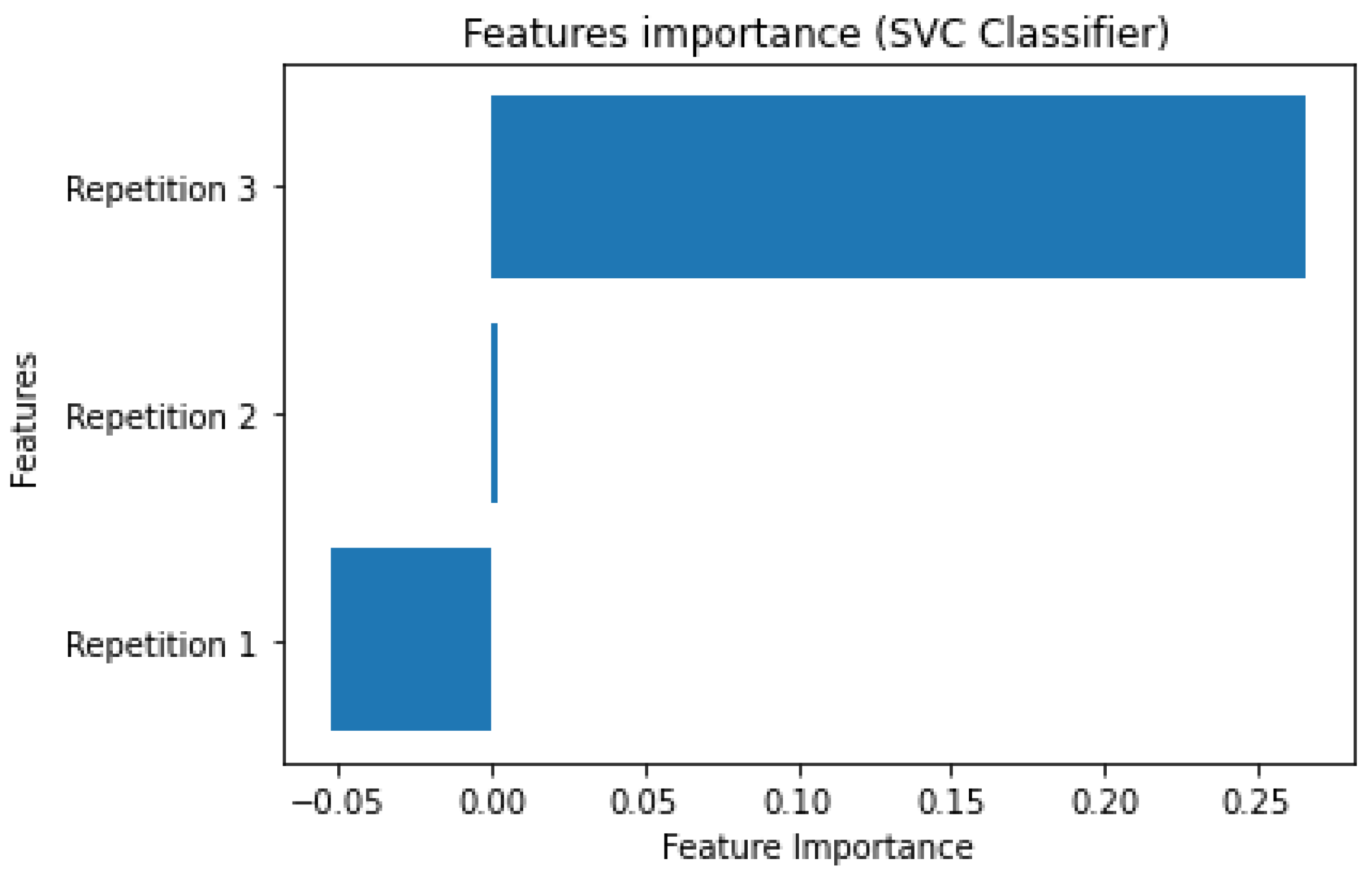
For what concerns the importance of employed features, both an analysis conducted using a Permutation Features importance model on the best kNN estimator and an inspection of SVC’s coefficients reveals how the third repetition (
"Repetition 3") is the most predictive feature, followed by the second repetition (
"Repetition 2"), and finally by the first (
"Repetition 1"). Details about the results are reported in
Appendix B.
4. Discussion
In this work, we tested the possibility of using different machine learning models to discriminate between
usable and
unusable fixation time signals collected from young children. Results of three models—a Linear SVC, a Non-Linear SVC, and a K-Neighbors, reported in
Table 3 confirm the possibility of adopting ML models for the automatic classification of fixation time signals quality. More specifically, our results suggest that ML classifiers could be successfully employed to support researchers in the coding of the usability of toddlers’ fixation time recordings, for example in VOE studies. Performances of the different models, reported in
Table 3, suggest that the Non-Linear SVC and and kNN are performing better than the Linear SVC Classifier. In our dataset, the binary classification has been conducted in such a way that the
usable samples were labelled as positives, while
unusable samples as negative. Therefore, Precision and Recall scores reflect respectively the ratio between True Positive, which are truly
usable samples, against True and False positive, and True positive and False negative respectively [
57].
Additionally, both the F1 scores and the MCC measures, which should be more accurate for binary classification [
51], support the finding that the kNN classifier provides the best performances for the task despite not performing significantly differently from the Non-Linear SVC classifier. Overall, these results confirm our hypothesis that ML models can be employed to help researchers and clinicians automatically discriminate between usable and unusable fixation time recording. However, our results are not able to confirm, from a statistical point of view, that the kNN classifier is performing significantly better than the Non-Linear SVM Classifier. With regards to the adoption of one classifier versus another, some considerations should be thoughtfully evaluated, such as the computational power of employed machines, possibility of retraining the model continuously with the addition of new samples, and the possibility of implementing the model within eye-tracking software of hardware devices.
With regards to Precision and Recall, all of our classifiers performed better in Precision than Recall. Taken together, these findings suggest that there are a low number of False Positives (unusable samples identified as usable) identified by the models, but the classifiers were missing usable samples by classifying them as unusable. This bias led our model to be highly selective. By reducing the number of False Positives, the classifiers can be successfully employed with the assumption that, if a trial as been classified automatically as usable, it most probably is. This suggests that classifiers can produce datasets that contain almost exclusively usable samples and that can therefore be automatically used by non expert users or raters to rapidly generate a subset of usable samples for hypothesis testing, piloting, testing of new analysis algorithm, or for other purposes that require the selection of usable samples. On the other hand, the classifier was discarding some samples or trials that were labelled by the human researcher as usable. Given the nature of toddler studies, which are difficult to conduct and that are usually conducted on a small number of participants, maximising the number of usable samples becomes critical. We can conclude that models can be successfully employed to identify a subset of usable samples from the total sample, with very low risk of selecting unusable samples. At the same time, a manual screening on samples that have been deemed as unusable by the classifier could be necessary to increase the number of usable samples. Assuming a scenario like the one presented with our three studies, with a ratio of unusable samples between the 15% and 40%, will result in the necessity of manually inspecting only between the 30% and 45% of the full recordings, assuming the recall rate of the kNN Classifier (Recall = 0.795). Overall, this results in a large reduction of the time necessary to manually label a collection of recordings.
Our findings can be useful for the development of smart tools to support researchers and especially coders working with behavioural and signal quality in young children’s fixation time studies. Future works may replicate the analysis with other types of pupillary measures, such as the pupil size, and may investigate the possibility of integrating a tool based on ML models directly into eye-tracking devices’ recording software. Future studies may investigate the possibility of adopting Cloud-Based Machine Learning Models to deploy the model as a software that can be integrated into different data analysis pipelines [
58,
59] or to devices connected to the Internet [
27].
Limitations
Despite these promising results, this study has some limitations. The dataset here used for training and testing of the models was based on three different studies recorded with the same instruments, and it contained a limited number of samples. Future studies should replicate this analysis by training and testing the models on more samples, collected from multiple projects. This would also allow for the testing of different classifiers that perform better on datasets containing higher number of samples, such as Decision Tree Classifiers. Moreover, our models are based on features already extracted and have no knowledge about the setup and the participants. Future studies may investigate the possibility of using Artificial Intelligence model that mingles estimated features with video recordings of the sessions to improve the accuracy of the models in automatically separating Usable from Unusable trials.




{kind=link}
{kind=link}
{kind=link}


