Recognition of Emotion According to the Physical Elements of the Video


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experiment
2.1.1. Modeling Method
- 1)
- negative arousal: valence score is −3 or −2, arousal score is +2 or +3;
- 2)
- arousal: valence score is −1.0 or +1, arousal score is +2 or +3;
- 3)
- positive arousal: valence score is +2 or +3, arousal score is +2 or +3;
- 4)
- negative: valence score is −3 or −2, arousal score is −1.0 or +1;
- 5)
- neutral: valence score is −1.0 or +1, arousal score is −1.0 or +1;
- 6)
- positive: valence score is +2 or +3, arousal score is −1.0 or +1;
- 7)
- negative relaxed: valence score is −3 or −2, arousal score is −3 or −2;
- 8)
- relaxed: valence score is +2 or +3, arousal score is −3 or −2;
- 9)
- positive relaxed: valence score is −1.0 or +1, arousal score is –3 or –2.
2.1.2. Stimuli
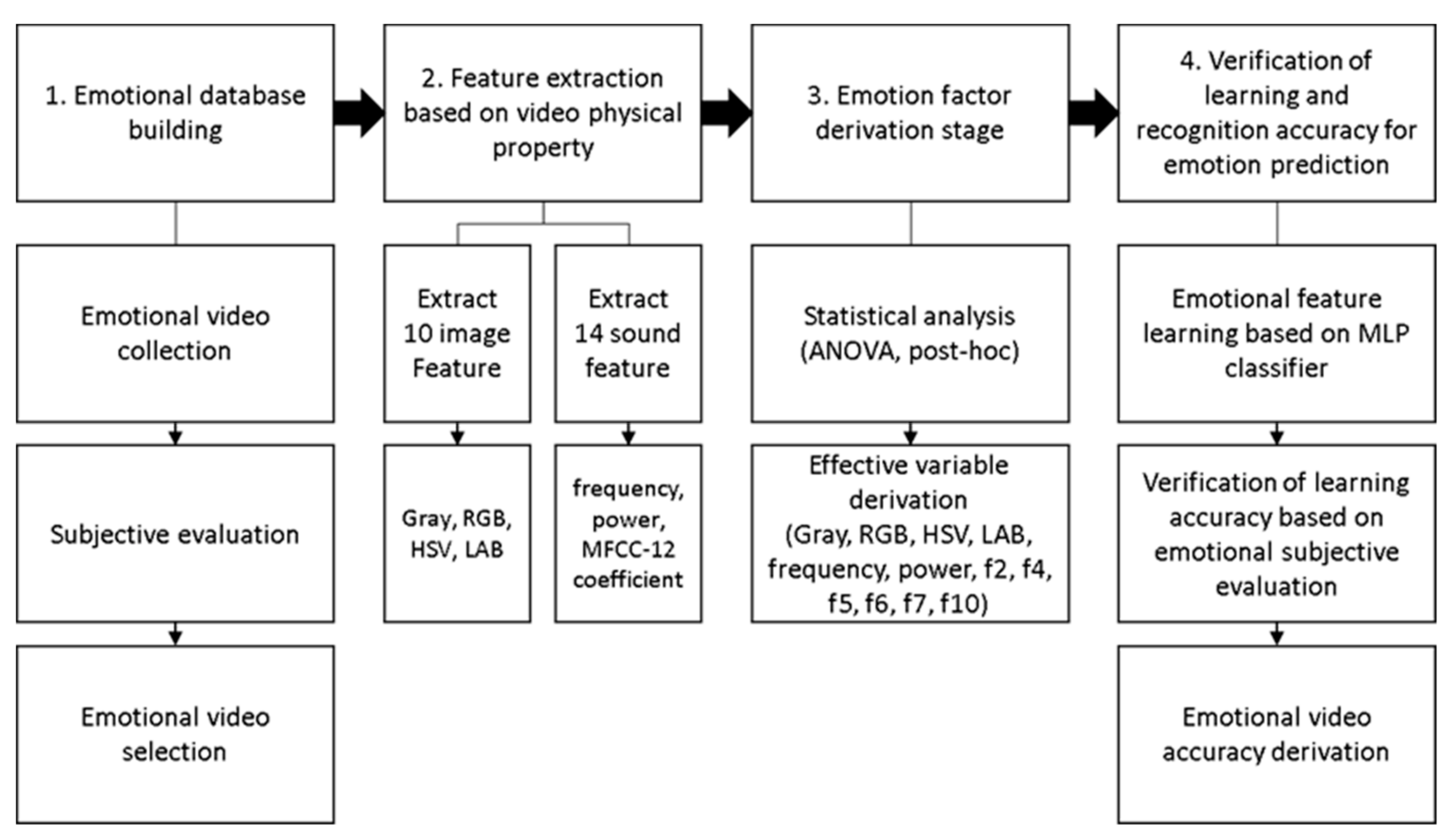
2.2. Feature Extraction
- (1)
- Step one—Emotional database building.
- (2)
- Step two—Extract the features in the video.
2.3. Statistical Analysis
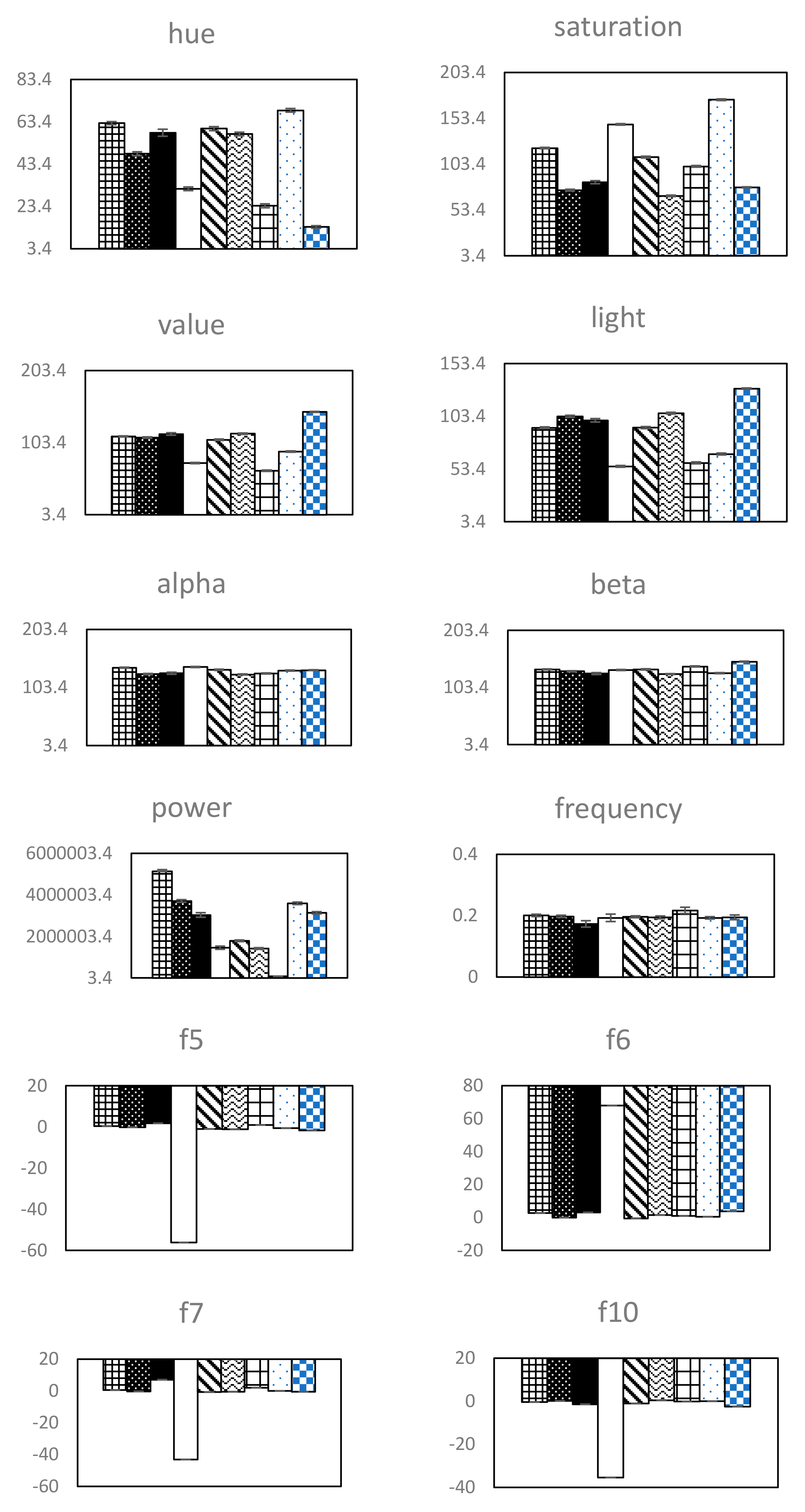
2.3.1. ANOVA
2.3.2. Principal Component Analysis (PCA)
2.3.3. Classification Model (K-NN, SVM, MLP)
2.4. Evaluation
3. Results
3.1. Statistical Result
3.2. Machine Learning Accuracy Result
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bianchin, M.; Angrilli, A. Gender differences in emotional responses: A psychophysiological study. Physiol. Behav. 2012, 105, 925–932. [Google Scholar] [CrossRef]
- LeDoux, J.E.; Brown, R. A higher-order theory of emotional consciousness. PNAC 2017, 114, E2016–E2025. [Google Scholar] [CrossRef] [Green Version]
- Brosch, T.; Scherer, K.R.; Grandjean, D.M.; Sander, D. The impact of emotion on perception, attention, memory, and decision-making. Swiss Med. Weekly 2013, 143, w13786. [Google Scholar] [CrossRef] [PubMed]
- Smith, G.M. Film structure and the emotion system. Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Nack, F.; Dorai, C.; Venkatesh, S. Computational media aesthetics: Finding meaning beautiful. IEEE Multimed. 2001, 8, 10–12. [Google Scholar] [CrossRef]
- Philippot, P.; Schaefer, A.; Herbette, G. Consequences of specific processing of emotional information: Impact of general versus specific autobiographical memory priming on emotion elicitation. Emotion 2003, 3, 270–283. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Poria, S.; Gelbukh, A.; Thelwall, M. Sentiment analysis is a big suitcase. IEEE Intell. Syst. 2017, 32, 74–80. [Google Scholar] [CrossRef]
- Rosas, V.P.; Mihalcea, R.; Morency, L.P. Multimodal sentiment analysis of spanish online videos. IEEE Intell. Syst. 2013, 28, 38–45. [Google Scholar] [CrossRef]
- Schaefer, A.; Nils, F.; Sanchez, X.; Philippot, P. Assessing the effectiveness of a large database of emotion-eliciting films: A new tool for emotion researchers. Cogn. Emot. 2010, 24, 1153–1172. [Google Scholar] [CrossRef]
- Newhagen, J.E.; Reeves, B. The evening’s bad news: Effects of compelling negative television news images on memory. J. Commun. 1992, 42, 25–41. [Google Scholar] [CrossRef]
- Mo, S.; Niu, J.; Su, Y.; Das, S.K. A novel feature set for video emotion recognition. Neurocomputing 2018, 291, 11–20. [Google Scholar] [CrossRef]
- Lazarus, R.S. Emotions and adaptation: Conceptual and empirical relations. Neb. Symp. Motiv. 1968, 16, 175–266. [Google Scholar]
- Paul, E.; Wallace, V.F.; Maureen, O.; Anthony, C.; Irene, D.T.; Karl, H.; Rainer, K.; Ayhan, L.W.; Tom, P.; Pio E, R.B.; et al. Universals and cultural differences in the judgments of facial expressions of emotion. J. Per. Soc. Psychol. 1987, 53, 712–717. [Google Scholar]
- Schlosberg, H. The description of facial expressions in terms of two dimensions. J. Exp. Psychol. 1952, 44, 229–237. [Google Scholar] [CrossRef]
- Bradley, M.M.; Greenwald, M.K.; Petry, M.C.; Lang, P.J. Remembering pictures: Pleasure and arousal in memory. J. Exp. Psychol. Learn. Mem. Cogn. 1992, 18, 379–390. [Google Scholar] [CrossRef]
- Watson, D.; Auke, T. Toward a consensual structure of mood. Psychol. Bull. 1985, 98, 219–235. [Google Scholar] [CrossRef]
- Lertsuksakda, R.; Netisopakul, P.; Pasupa, K. Thai sentiment terms construction using the Hourglass of Emotions. In Proceedings of the 2014 6th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 30–31 January 2014. [Google Scholar]
- Mehrabian, A. Basic dimensions for a general psychological theory: Implications for personality, social, environmental, and developmental studies. Oelgeschlager, Gunn & Hain: Cambridge, UK, 1980. [Google Scholar]
- Lövheim, H. A new three-dimensional model for emotions and monoamine neurotransmitters. Med. Hypotheses 2012, 78, 341–348. [Google Scholar]
- Osgood, C.E.; Suci, G.J.; Tannenbaum, P. The Measurement of Meaning; University of Illinois Press: Champaign, IL, USA, 1957. [Google Scholar]
- Lang, P.J.; Greenwald, M.K.; Bradley, M.M.; Hamm, A.O. Looking at pictures: Affective, facial, visceral, and behavioral reactions. Psychophysiology 1993, 30, 261–273. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Pers. Soc. Psychol. 1980, 39, 1161–1178. [Google Scholar] [CrossRef]
- Schlosberg, H. Three dimensions of emotion. Psychological Rev. 1954, 61, 81–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef]
- Chanel, G.; Kronegg, J.; Grandjean, D.; Pun, T. Emotion assessment: Arousal evaluation using EEG’s and peripheral physiological signals. In Multimedia Content Representation, Classification and Security; Springer: Berlin, Germany, 2006; pp. 530–537. [Google Scholar]
- Lang, P.J. A bio-informational theory of emotional imagery. Psychophysiology 1979, 16, 495–512. [Google Scholar] [CrossRef] [PubMed]
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. Emotion, motivation, and anxiety: Brain mechanisms and psychophysiology. Biol. Psychiatry 1998, 44, 1248–1263. [Google Scholar] [CrossRef]
- Joshi, N.A.; Fass, J.N. Sickle: A sliding-window, adaptive, quality-based trimming tool for FastQ files (Version 1.33). Available online: https://github.com/najoshi/sickle (accessed on 20 October 2019).
- Izard, C.E. Basic emotions, natural kinds, emotion schemas, and a new paradigm. Perspect. Psychol. Sci. 2007, 2, 260–280. [Google Scholar] [CrossRef] [PubMed]
- Machajdik, J.; Allan, H. Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 83–92. [Google Scholar]
- Kragel, P.A.; Reddan, M.C.; LaBar, K.S.; Wager, T.D. Emotion schemas are embedded in the human visual system. Sci. Adv. 2019, 5, eaaw4358. [Google Scholar] [CrossRef] [Green Version]
- Zhao, S.; Gao, Y.; Jiang, X.; Yao, H.; Chua, T.S.; Sun, X. Exploring principles-of-art features for image emotion recognition. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 47–56. [Google Scholar]
- Tuuri, K.; Mustonen, M.S.; Pirhonen, A. Same sound–different meanings: A novel scheme for modes of listening. In Proceedings of the Audio Mostly, Ilmenau, Germany, 27–28 September 2007; pp. 13–18. [Google Scholar]
- Ward, M. Art in noise: An embodied simulation account of cinematic sound design. In Embodied Cognition and Cinema; Leuven University Press: Leuven, Belgium, 2015; pp. 155–186. [Google Scholar]
- Nordström, H.; Laukka, P. The time course of emotion recognition in speech and music. J. Acoust. Soc. Am. 2019, 145, 3058–3074. [Google Scholar] [CrossRef]
- Forrester, M.A. Auditory perception and sound as event: Theorising sound imagery in psychology. Available online: https://theearoftheduck.wordpress.com/2012/10/15/auditory-perception-and-sound-as-event-theorising-sound-imagery-in-psychology/. (accessed on 20 October 2019).
- Cabredo, R.; Legaspi, R.; Inventado, P.S.; Numao, M. An Emotion Model for Music Using Brain Waves. Available online: file:///C:/Users/mdpi/Downloads/e82afc279aa8479631eff5abeb491f51710a.pdf. (accessed on 20 October 2019).
- Schuller, B.; Hantke, S.; Weninger, F.; Han, W.; Zhang, Z.; Narayanan, S. Automatic recognition of emotion evoked by general sound events. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25−30 March 2012; pp. 341–344. [Google Scholar]
- Juslin, P.N.; Sloboda, J.A. Music and Emotion: Theory and Research; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Lang, A.; Newhagen, J.; Reeves, B. Negative video as structure: Emotion, attention, capacity, and memory. J. Broadcast. Electron. Media 1996, 40, 460–477. [Google Scholar] [CrossRef]
- Yiend, J. The effects of emotion on attention: A review of attentional processing of emotional information. Cognition Emotion 2010, 24, 3–47. [Google Scholar] [CrossRef]
- Teixeira, T.; Wedel, M.; Pieters, R. Emotion-induced engagement in internet video advertisements. J. Mark. Res. 2012, 49, 144–159. [Google Scholar] [CrossRef]
- Monaco, J. How to Read a Film: Movies, Media, Multimedia; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Wang, H.L.; Cheong, L.F. Affective understanding in film. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 689–704. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, Q.; Jiang, S.; Gao, W.; Tian, Q. Affective visualization and retrieval for music video. IEEE Trans. Multimed. 2010, 12, 510–522. [Google Scholar] [CrossRef]
- Zhang, S.; Tian, Q.; Jiang, S.; Huang, Q.; Gao, W. Affective MTV analysis based on arousal and valence features. In Proceedings of the 2008 IEEE International Conference on Multimedia and Expo, Hannover, Germany, 23–26 June 2008; pp. 1369–1372. [Google Scholar]
- Suk, H.J.; Irtel, H. Emotional response to color across media. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/col.20554. (accessed on 20 October 2019).
- Jing, P. Application of Color and Musical Language in Chinese Contemporary Animation Film. In Proceedings of the 3rd International Conference on Arts, Design and Contemporary Education (ICADCE 2017), Moscow, Russia, 29–30 May 2017. [Google Scholar]
- Li, M. Perfect interpretation of the influence of color background on animation art in my neighbor Totoro directed by Miyazaki Hayao. DEStech Transactions on Social Science. Available online: http://www.dpi-proceedings.com/index.php/dtssehs/article/view/9392 (accessed on 20 October 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| What Kind of Emotion Do You Think is Expressed in the Video? | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Video 1 | −3 | −2 | −1 | 0 | 1 | 2 | 3 | ||
| Negative | Positive | ||||||||
| arousal | relaxed | ||||||||
| Heading | Precision | Recall | F1 Score | Support |
|---|---|---|---|---|
| 1 | 0.91 | 0.94 | 0.93 | 630 |
| 2 | 0.89 | 0.88 | 0.86 | 840 |
| 3 | 0.86 | 0.97 | 0.91 | 175 |
| 4 | 0.56 | 0.96 | 0.71 | 222 |
| 5 | 0.94 | 0.79 | 0.86 | 1235 |
| 6 | 0.92 | 0.96 | 0.94 | 183 |
| 7 | 1.00 | 0.94 | 0.97 | 97 |
| 8 | 0.93 | 0.96 | 0.94 | 641 |
| 9 | 0.99 | 1.00 | 0.99 | 93 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wen, X.; Whang, M. Recognition of Emotion According to the Physical Elements of the Video. Sensors 2020, 20, 649. https://doi.org/10.3390/s20030649
Zhang J, Wen X, Whang M. Recognition of Emotion According to the Physical Elements of the Video. Sensors. 2020; 20(3):649. https://doi.org/10.3390/s20030649
Chicago/Turabian StyleZhang, Jing, Xingyu Wen, and Mincheol Whang. 2020. "Recognition of Emotion According to the Physical Elements of the Video" Sensors 20, no. 3: 649. https://doi.org/10.3390/s20030649
APA StyleZhang, J., Wen, X., & Whang, M. (2020). Recognition of Emotion According to the Physical Elements of the Video. Sensors, 20(3), 649. https://doi.org/10.3390/s20030649