In this section, we will describe the experimental settings and performance evaluation of the proposed scheme.
5.1. Experimentation Settings
We conduct extensive experiments using off-the-shelf WiFi devices with 802.11n enabled protocols. In our experiments, a Lenovo laptop is used as a receiver with Ubuntu 11.04 LTS operating system. The receiver is equipped with a network interface card (NIC) Intel 5300 to collect WiFi CSI data with three antennas. The receiver connects to WiFi Access Point (AP); a TP-Link (TL-WR742N) router as transmitter operating at 2.4 GHz with a single antenna. The experimentation equipment is shown in
Figure 6. The receiver can ping the AP at a rate of 80 packets/s. The system is generating 3 CSI streams of 30 subcarriers each with
and
(
MIMO system). We conduct experiments using 802.11n-based CSI Tool as described in Reference [
41] on the receiver to acquire WiFi CSI measurements on 30 subcarriers. We have used MATLAB R2016a for signal processing throughout our experiments.
We test the proposed prototype in two cluttered scenarios, given as:
Scenario-I (Actual driving): In this scenario, attentive activities are performed with actual driving a vehicle. Due to safety purposes, inattentive activities are performed by parking the vehicle on a side of the road.
Scenario-II (Vehicle standing in a garage): In this scenario, all prescribed activities are performed inside a vehicle while standing in a garage of size feet.
For in-vehicle scenarios, we set up testbed in a locally manufactured vehicle that was not equipped with pre-installed WiFi devices. Due to the unavailability of a WiFi access point in the test vehicle, we configured a TP-Link (TL-WR742N) router as AP, placed on the dashboard in front of the driver. The receiver is placed at co-pilot’s seat to collect CSI data of the WiFi signal, as demonstrated in
Figure 7a. For scenario-I, the vehicle is derived on a road of about 18 km long (with left and right turns on both ends) inside the university campus with an average speed of 20 km/h, as shown in
Figure 7b.
In our experiments both attentive and inattentive activities are considered to get detailed classification results. For attentive class, we considered driving maneuvers and other primary activities that are necessary for driving, while distraction and fatigue are regarded as an inattentive class, as shown in
Table 1. In each experiment scenario, 15 possible driver’s activities are performed (4-driving maneuvers, 2-primary activities, 5-distraction activities, and 4-fatigue activities). Some pre-defined activities are shown in
Figure 8. Five volunteers (3-males and 2-females university students) were deployed to perform the activities, who do not know very much about activity recognition. Each activity is performed within a window of 5 seconds and repeated 20 times by each volunteer. During the performance of pre-defined activities, no other activity is performed to avoid interference. In total, the data set comprising of 1500 samples (15-activities × 5-volunteers × 20-times repeated) for each experiment scenario; of which
are used for training and
for testing. In our experiments, the training data do not contain the samples from testing data, and we keep the testing samples out for cross-validation.
5.2. Performance Evaluation
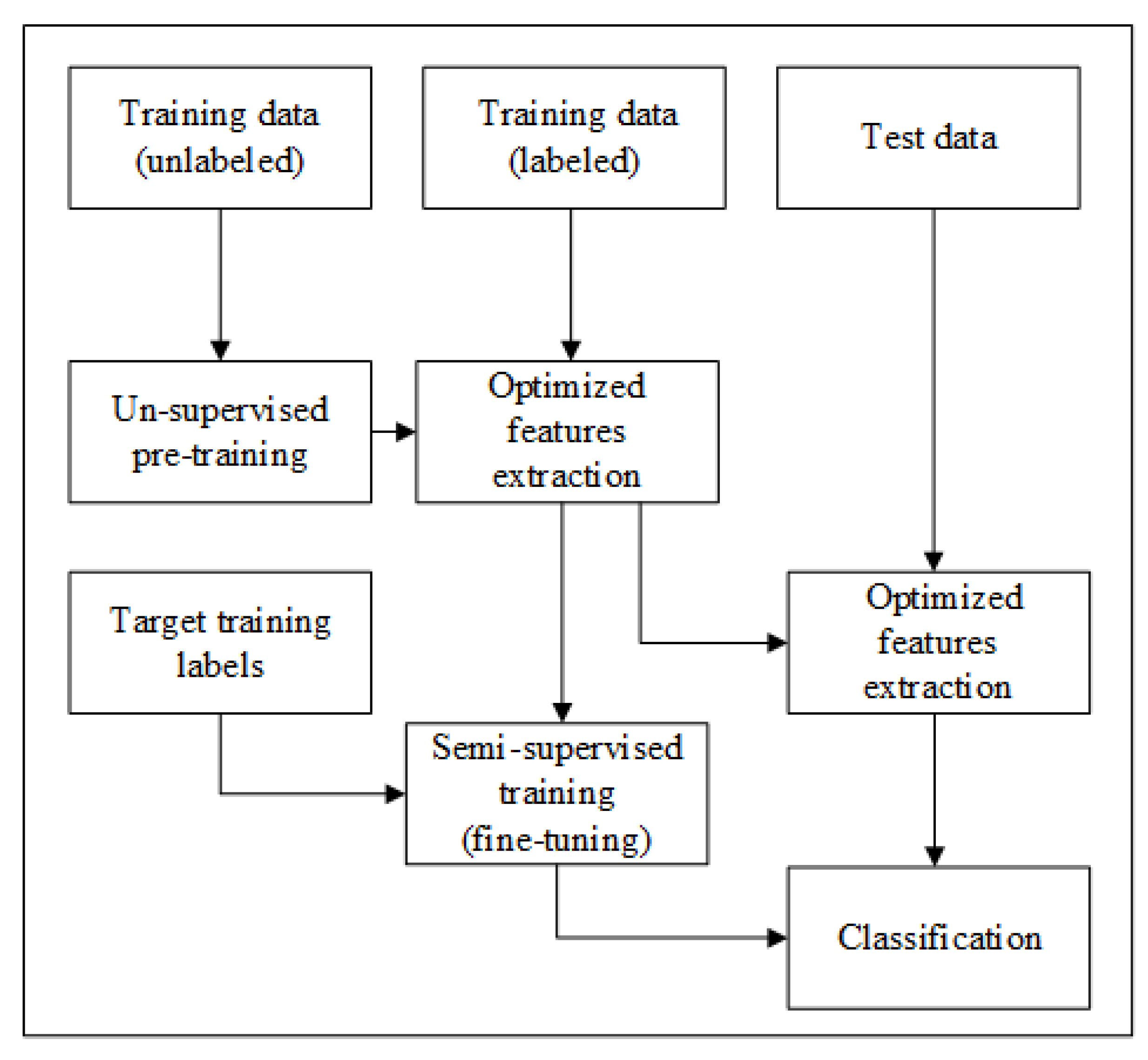
In this section, we will evaluate the performance of proposed framework. For simplicity, we use abbreviated terms for the suggested feature extraction method, i.e., the combination of Gabor and GLCM features from discriminant component selection, as GC. We used the Stacked Sparse Auto-Encoder (S-SAE) model in all experiments unless it is mentioned. GC feature extraction scheme with the S-SAE algorithm is abbreviated as GC-S.
We particularly select recognition accuracy and confusion matrix to show the obtained results. The occurrence of actual activity performed is represented by the column of the confusion matrix, whereas the occurrence of activity classified is represented by the row. From the confusion matrix in
Figure 9, it is clear that the proposed GC-S algorithm can recognize fifteen activities very accurately with an average recognition rate of 88.7% and
for scenarios I and II respectively.
To validate the efficacy and reliability of the proposed prototype, we investigate the obtained results using state-of-the-art evaluation metrics including precision, recall, and
-score. We abbreviate false positive, true positive and false negative as FP, TP and FN respectively, then these evaluation metrics are mathematically defined as [
56]:
The results related to precision, recall, and
-score using proposed GC-S method are illustrated in
Figure 10. It can be seen that both scenarios have acceptable performance using GC-S method. The average minimum and maximum values are summarized in
Table 2.
We have compared the accuracy of GC-S algorithm with stand-alone feature extraction methods, i.e., Gabor and GLCM features are extracted separately from CSI-transformed image (after discriminant components selection). Gabor method with S-SAE model is abbreviated as G-S, while the GLCM method with S-SAE is abbreviated as C-S. As can be seen in
Table 3, the proposed GC-S method has the best performance in comparison to stand-alone Gabor (G-S) and GLCM (C-S). The detailed comparison for each activity recognition is described in
Figure 11.
For the robustness evaluation of the proposed scheme, we investigate the recognition accuracy of suggested GC feature extraction algorithm with widely used state-of-the-art classifiers including Support Vector Machine (SVM), K Nearest Neighbors (KNN), and Decision Tree (DT). For the implementation of SVM and KNN classifier, we follow the procedure as described in Reference [
25]. For KNN, the presented system accomplishes the most accurate recognition performance at K = 3 nearest neighbors. For DT classifier, we adopt C4.5 algorithm as described in Reference [
57]. From the results highlighted in
Figure 12, it can be concluded that GC features have reasonable performance using conventional classifiers, but comparatively better results are obtained when using with S-SAE. This observation validates the significance of the S-SAE algorithm employed in classification scheme. The overall results are summarized in
Table 4.
To ensure the importance of discriminant components selection, we checked the recognition accuracy using all the information of radio-images. For the purpose, Gabor and GLCM features are extracted from the whole image (without adapting the discriminant component selection method). As expected, a significant drop in recognition accuracy is observed.
Figure 13 reveals the fact that the recognition accuracy drops to 79.6% and 82.4% for scenario-I and II, respectively. One can notice that discriminant components are playing a vital role in recognition accuracy.
We have calculated the execution time to evaluate the computational efficiency of proposed system, as shown in
Figure 14. The stand-alone Gabor and GLCM features are extracted without adapting discriminant components selection. In general, GC-S has relatively less execution time of 77.1 ms as compared to Gabor with execution time 89.2ms and GLCM method with 93.5 ms. Thus, it proves the computational efficiency of proposed GC-S algorithm with less execution time.
Table 5 demonstrates the execution time for each processing module of suggested framework. The major time is consumed in activity profile extraction and discriminant components selection that is still acceptable as the most significant part of presented model. Moreover, it is evident from
Table 3 that the recognition accuracy of GC-S is comparatively better as compared to conventional Gabor and GLCM features. Hence, the proposed GC-S scheme is low-cost solution with high recognition performance.
The training data has a vital impact on the results in terms of variation in classification accuracy. To verify this hypothesis, we performed a user independence test. We specifically adopt the Leave-One-Person-Out Cross-Validation (LOPO-CV) scheme [
58]. In this generalization technique, the test-user data is not included in training data. In particular, all data is considered to be the training data set, except a specific personś data that is selected as the test-user. This process is repeated for each entity individually until all users are treated as test-user. The results related to the LOPO-CV scheme are enclosed in
Figure 15. The presented algorithm has an acceptable performance with an average recognition accuracy of 81.5% and 84.3% for scenarios I and II, respectively. One can conclude that the proposed method has a generalization capability for new users.
To evaluate the performance of presented radio-image-based system, we compare the recognition accuracy of proposed GC feature extraction technique with the conventional time-domain and frequency-domain feature extraction method [
59]. We particularly select three widely used time-domain features including mean, variance and peak-to-peak value, and two commonly used frequency-domain features including entropy and energy. From
Table 6, it is clear that the proposed GC feature extraction technique outperforms as compared to conventional methods.
The proposed algorithm is tested with three different placements of transmitter and receiver, i.e., layout L (actual layout), L-1, and L-2, as shown in
Figure 16. From the results described in
Table 7, it is obvious that the presented mechanism is independent of in-vehicle layout, with acceptable recognition performance at all placements of transmitter and receiver.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}