Event-Based Feature Extraction Using Adaptive Selection Thresholds



Abstract
:1. Introduction
1.1. Neuromorphic Vision Sensors
1.2. Feature Extraction in Neuromorphic Systems
2. Adaptive Threshold Clustering
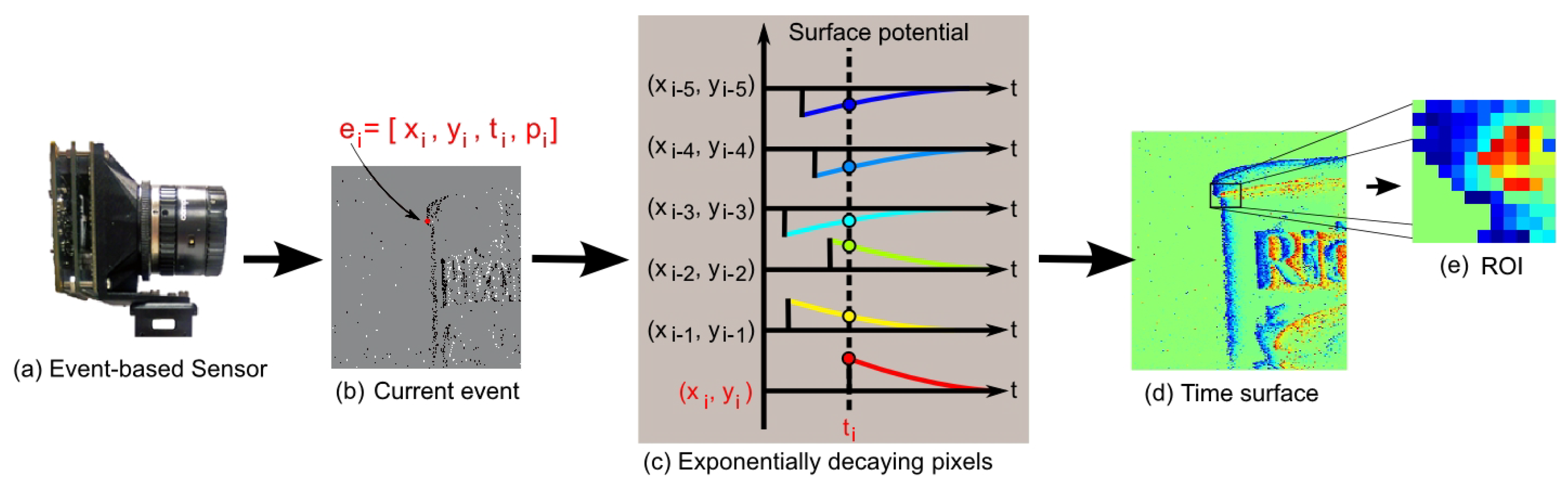
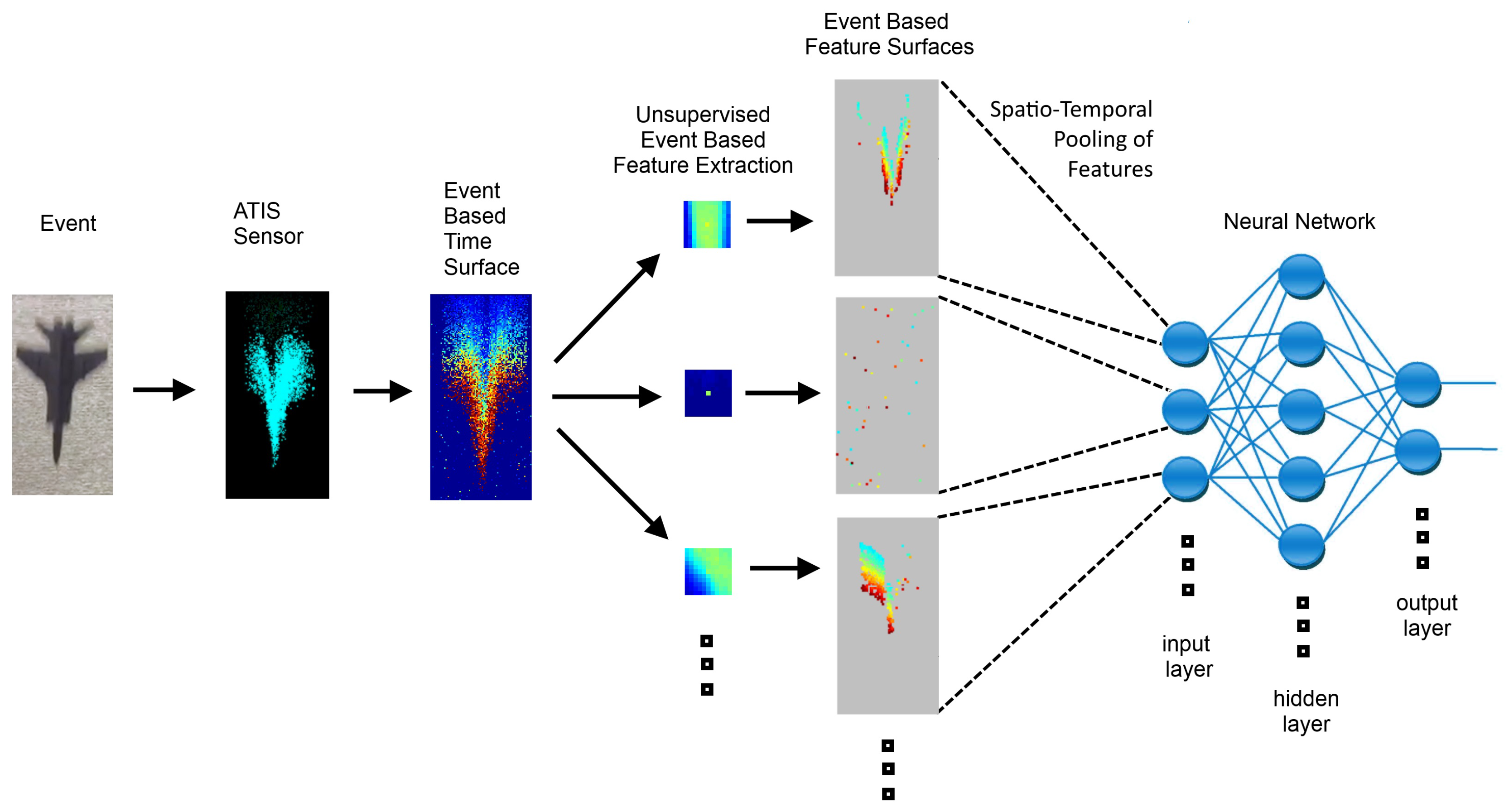
2.1. Feature Detection from Time Surfaces
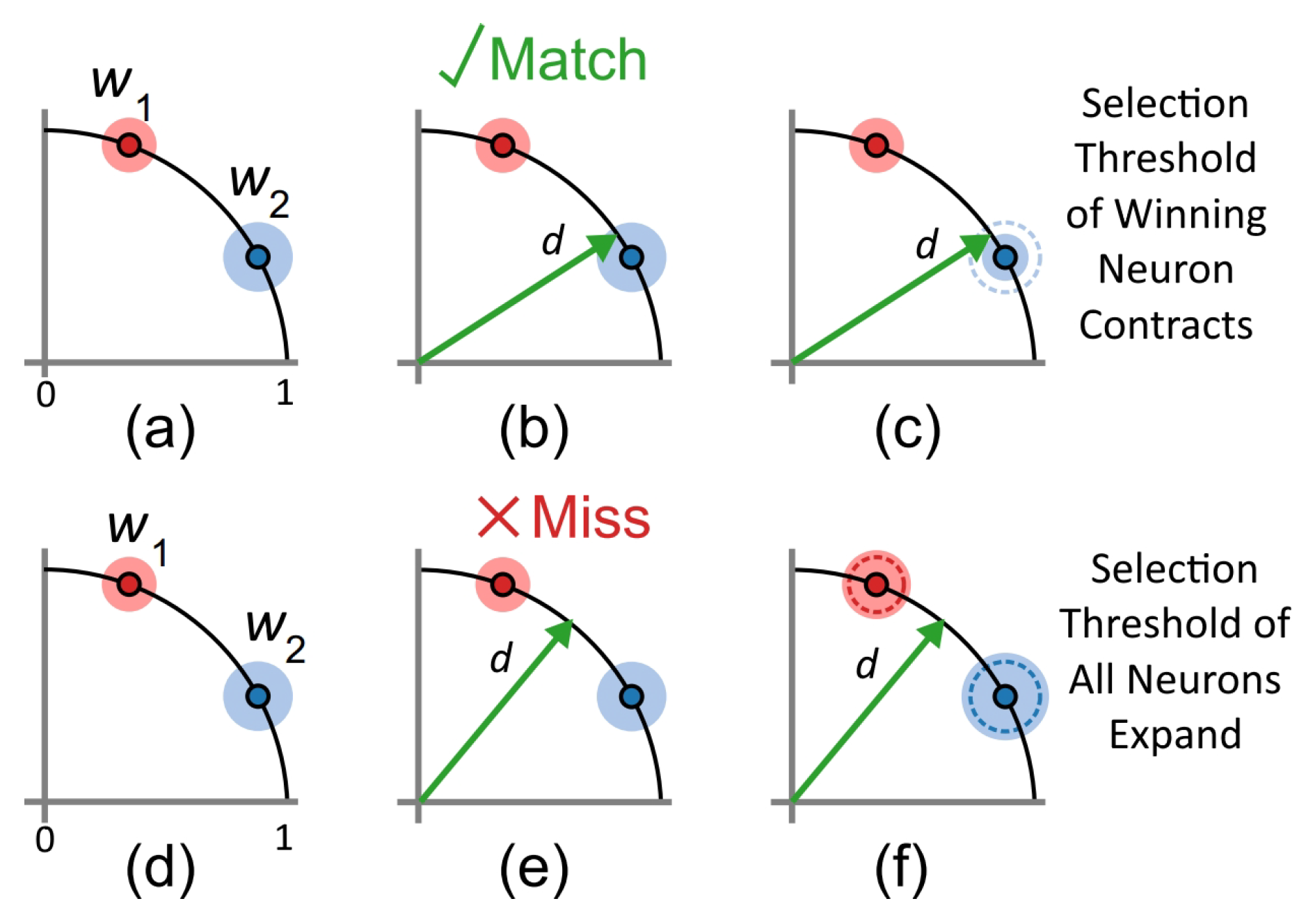
2.2. Adaptive Threshold Clustering
- If the input ROI matches any feature (the cosine distance between its weights and the input ROI is within the feature’s threshold), then the threshold is decreased for feature i by a fixed amount . (If multiple features match the input, the best matching feature is selected).
- If an incoming ROI does not match any of the features, then all thresholds are increased by a fixed amount .
2.3. Noise Features and Network Size Selection
3. Methodology
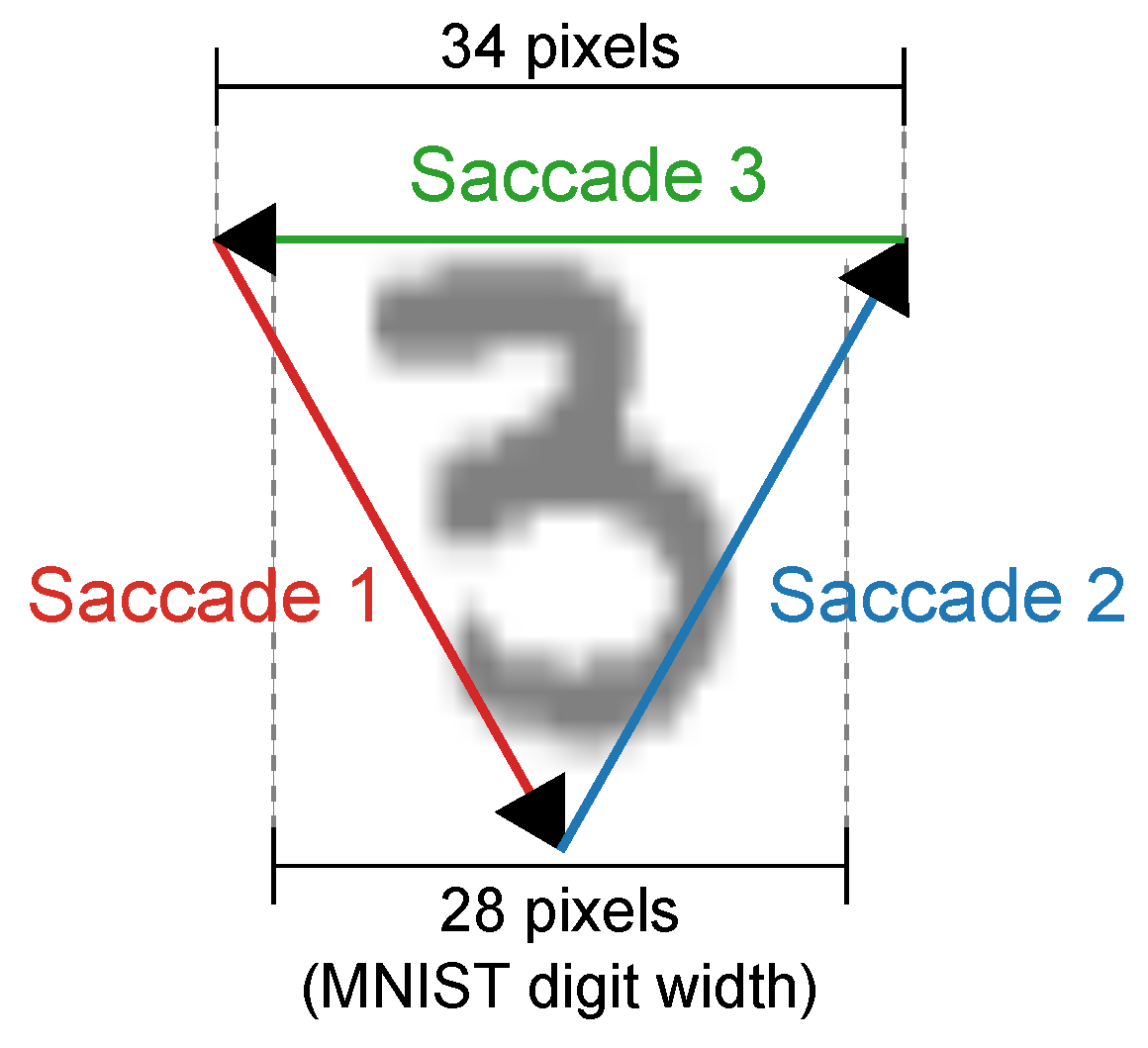
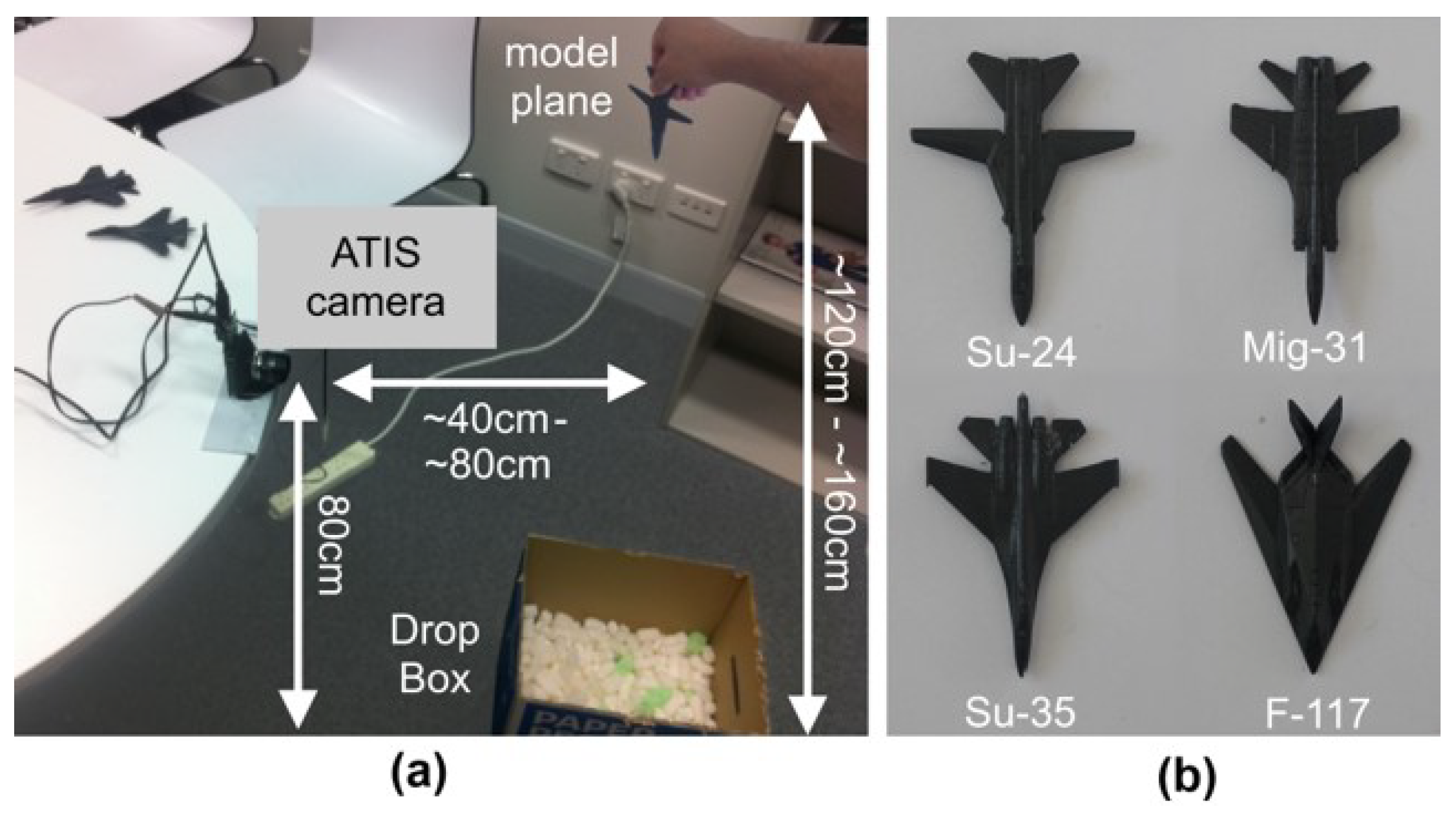
3.1. Datasets
3.2. Classifiers
4. Results
4.1. N-MNIST Digit Classification Results
4.2. Plane Dropping Dataset Results
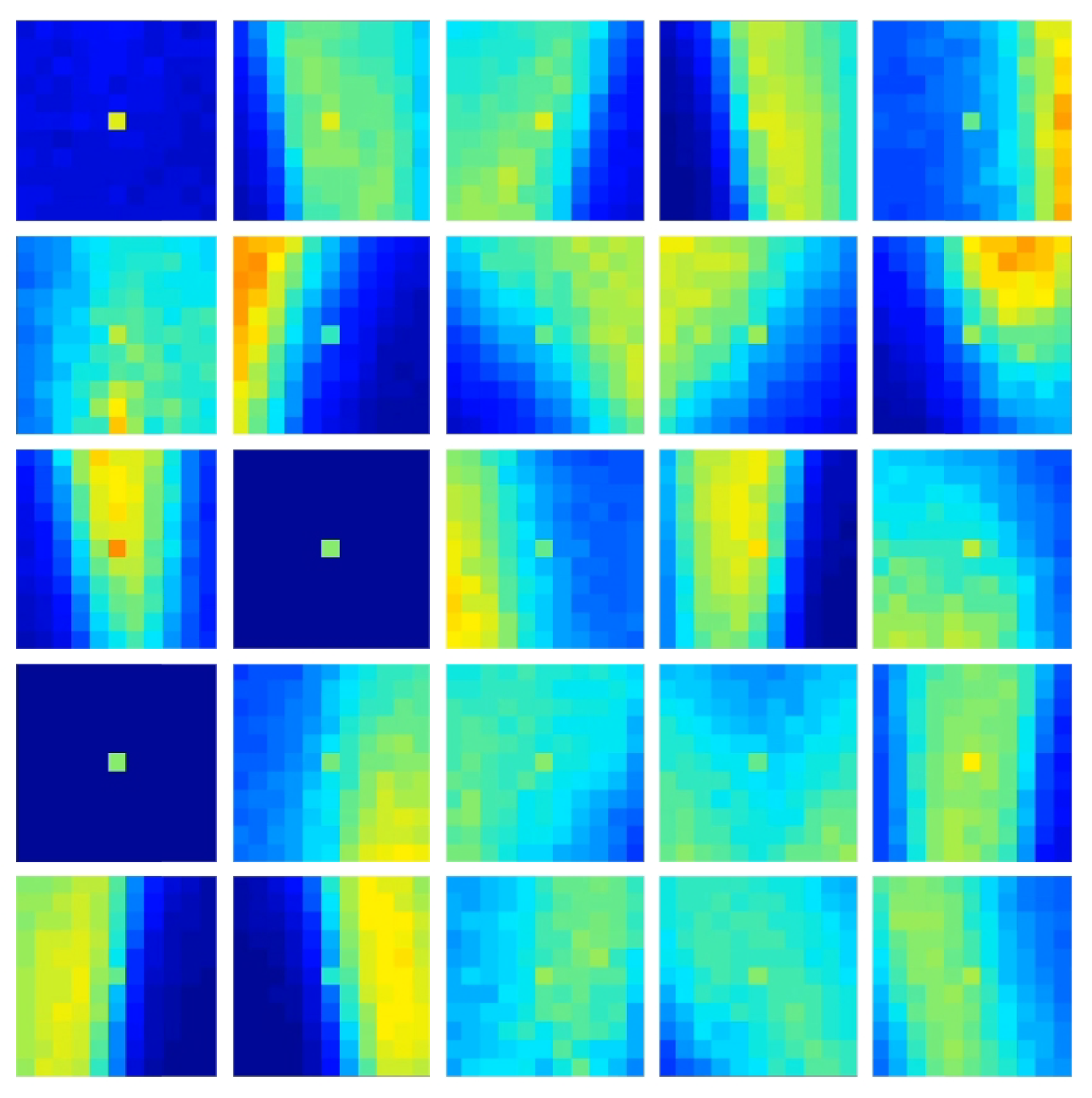
4.3. Evaluating Feature Sets via Feature Activation
5. Discussion
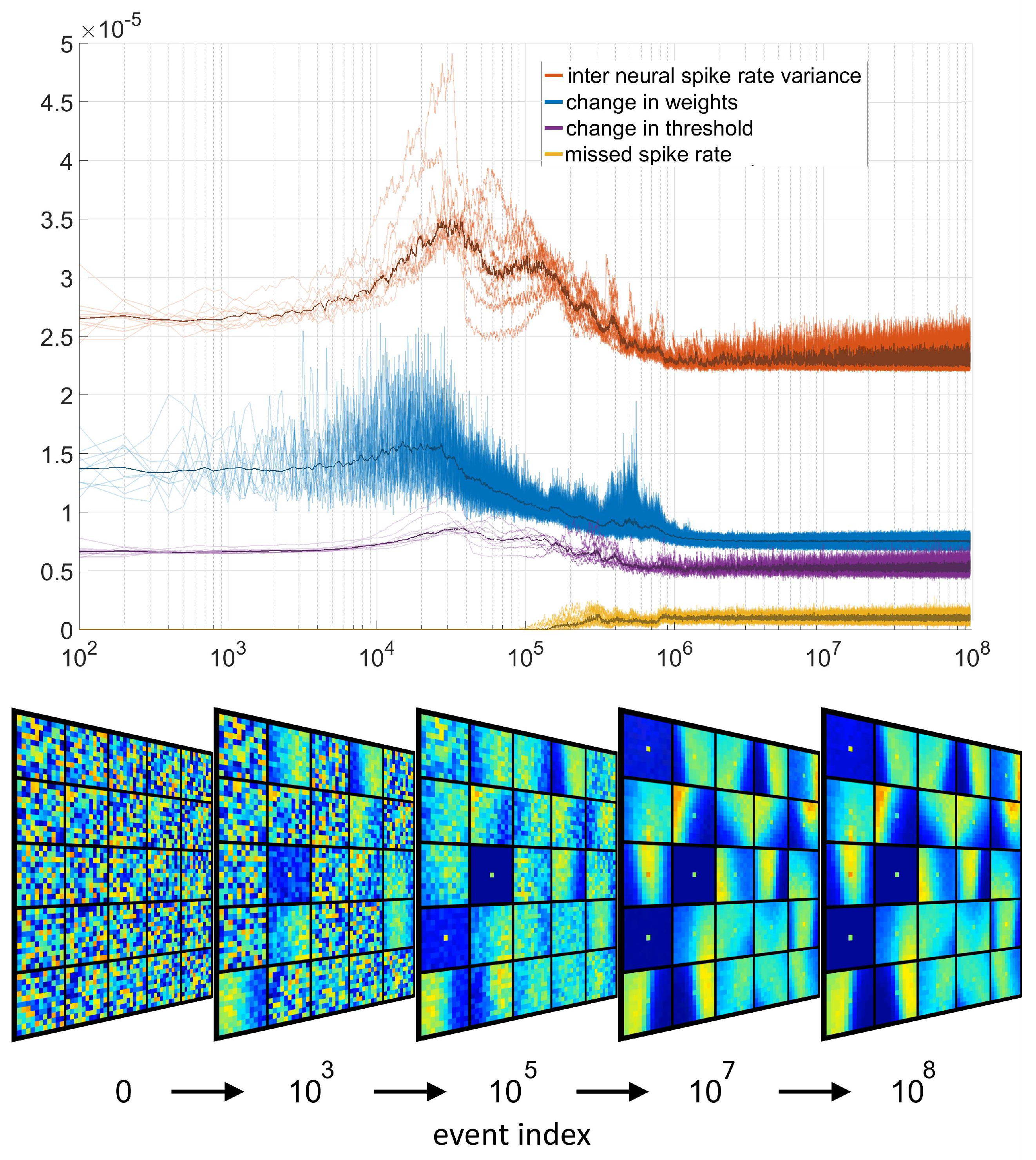
5.1. Missed Events during Learning
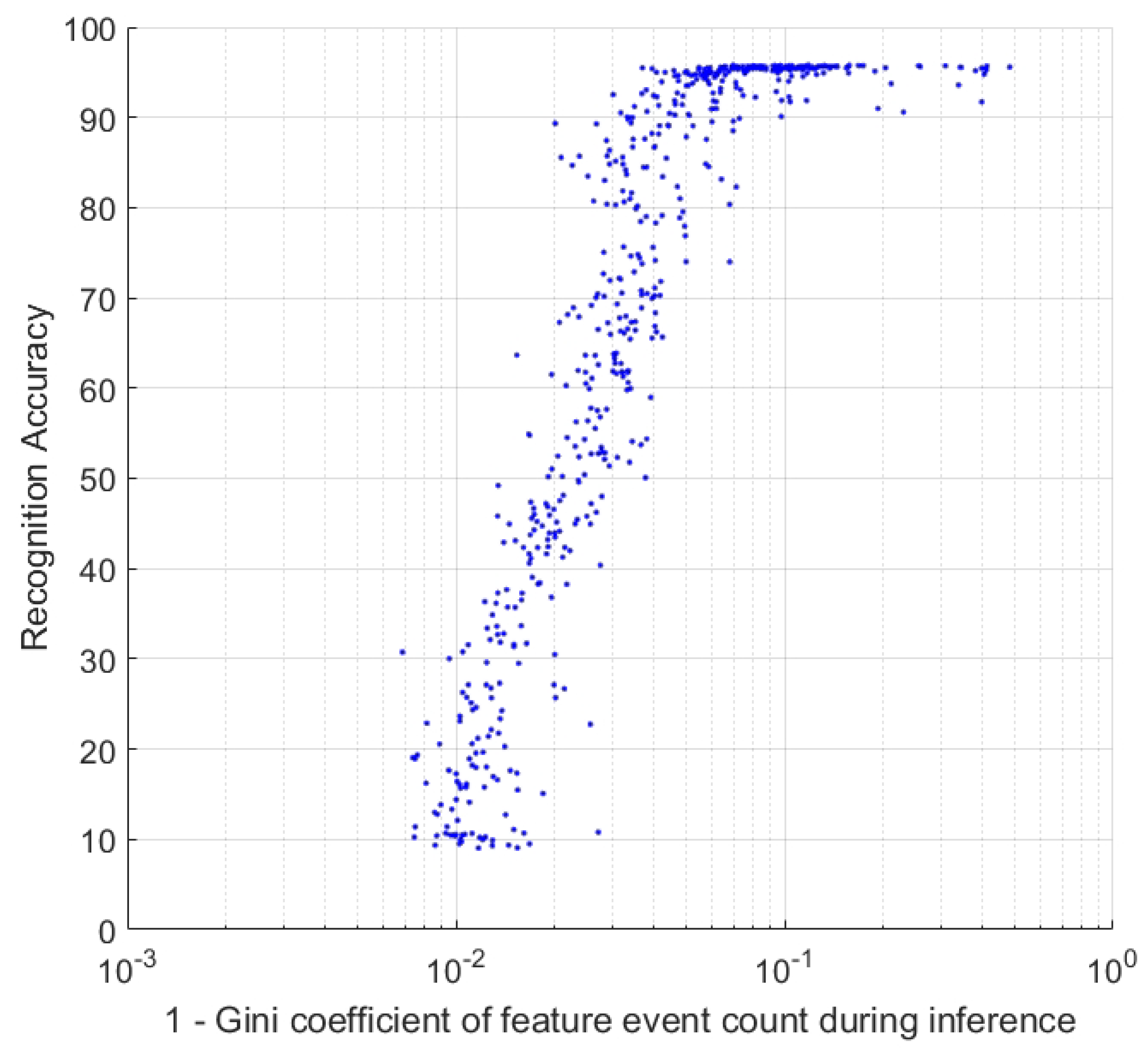
5.2. Thresholds During Learning and Inference
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Skeletal graphs for efficient structure from motion. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef]
- Yang, J.; Jiang, Y.G.; Hauptmann, A.G.; Ngo, C.W. Evaluating bag-of-visual-words representations in scene classification. In Proceedings of the International Workshop on Workshop on Multimedia Information Retrieval—MIR’07, Augsburg, Germany, 28–29 September 2007; ACM Press: New York, NY, USA, 2007; p. 197. [Google Scholar] [CrossRef] [Green Version]
- Laptev, I.; Lindeberg, T. Local Descriptors for Spatio-temporal Recognition. In Spatial Coherence for Visual Motion Analysis; MacLean, W., Ed.; Springer: Berlin/Heidelberg, Geramny, 2006; pp. 91–103. [Google Scholar] [CrossRef] [Green Version]
- Dollar, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior Recognition via Sparse Spatio-Temporal Features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; pp. 65–72. [Google Scholar] [CrossRef] [Green Version]
- Se, S.; Lowe, D.; Little, J. Mobile Robot Localization and Mapping with Uncertainty using Scale-Invariant Visual Landmarks. Int. J. Robot. Res. 2002, 21, 735–758. [Google Scholar] [CrossRef]
- Posch, C.; Serrano-Gotarredona, T.; Linares-Barranco, B.; Delbrück, T. Retinomorphic Event-Based Vision Sensors: Bioinspired Cameras With Spiking Output. Proc. IEEE 2014, 102, 1470–1484. [Google Scholar] [CrossRef] [Green Version]
- Afshar, S.; George, L.; Tapson, J.; van Schaik, A.; Hamilton, T.J. Racing to learn: Statistical inference and learning in a single spiking neuron with adaptive kernels. Front. Neurosci. 2014, 8, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Afshar, S.; George, L.; Thakur, C.S.; Tapson, J.; van Schaik, A.; De Chazal, P.; Hamilton, T.J. Turn down that noise: Synaptic encoding of afferent SNR in a single spiking neuron. IEEE Trans. Biomed. Circuits Syst. 2015, 9, 188–196. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roska, B.; Werblin, F. Rapid global shifts in natural scenes block spiking in specific ganglion cell types. Nat. Neurosci. 2003, 6, 600–608. [Google Scholar] [CrossRef] [PubMed]
- Fukushima, K.; Yamaguchi, Y.; Yasuda, M.; Nagata, S. An electronic model of the retina. Proc. IEEE 1970, 58, 1950–1952. [Google Scholar] [CrossRef]
- Mahowald, M. An Analog VLSI System for Stereoscopic Vision; Springer US: Boston, MA, USA, 1994. [Google Scholar] [CrossRef]
- Posch, C.; Matolin, D.; Wohlgenannt, R. A QVGA 143 dB Dynamic Range Frame-Free PWM Image Sensor With Lossless Pixel-Level Video Compression and Time-Domain CDS. IEEE J. Solid-State Circuits 2011, 46, 259–275. [Google Scholar] [CrossRef]
- Boahen, K. Point-to-point connectivity between neuromorphic chips using address events. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 2000, 47, 416–434. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Shao, L.; Zheng, F.; Wang, L.; Song, Z. Recent advances and trends in visual tracking: A review. Neurocomputing 2011, 74, 3823–3831. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference 1988, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar] [CrossRef]
- Marĉelja, S. Mathematical description of the responses of simple cortical cells. J. Opt. Soc. Am. 1980, 70, 1297. [Google Scholar] [CrossRef] [PubMed]
- Vasco, V.; Glover, A.; Bartolozzi, C. Fast event-based Harris corner detection exploiting the advantages of event-driven cameras. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; pp. 4144–4149. [Google Scholar] [CrossRef]
- Clady, X.; Ieng, S.H.; Benosman, R. Asynchronous event-based corner detection and matching. Neural Netw. 2015, 66, 91–106. [Google Scholar] [CrossRef] [PubMed]
- Ieng, S.H.; Posch, C.; Benosman, R. Asynchronous Neuromorphic Event-Driven Image Filtering. Proc. IEEE 2014, 102, 1485–1499. [Google Scholar] [CrossRef]
- Brandli, C.; Strubel, J.; Keller, S.; Scaramuzza, D.; Delbruck, T. ELiSeD-An event-based line segment detector. In Proceedings of the 2016 2nd International Conference on Event-Based Control, Communication, and Signal Processing (EBCCSP 2016-Proceedings), Krakow, Poland, 13–15 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Tedaldi, D.; Gallego, G.; Mueggler, E.; Scaramuzza, D. Feature detection and tracking with the dynamic and active-pixel vision sensor (DAVIS). In Proceedings of the 2016 Second International Conference on Event-Based Control, Communication, and Signal Processing (EBCCSP), Krakow, Poland, 13–15 June 2016; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.-C.; Delbruck, T. A 240 × 180 130 dB 3 us Latency Global Shutter Spatiotemporal Vision Sensor. IEEE J. Solid-State Circuits 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Orchard, G.; Meyer, C.; Etienne-Cummings, R.; Posch, C.; Thakor, N.; Benosman, R. HFirst: A Temporal Approach to Object Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 8828. [Google Scholar] [CrossRef] [Green Version]
- Serre, T.; Wolf, L.; Bileschi, S.; Riesenhuber, M.; Poggio, T. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 411–426. [Google Scholar] [CrossRef]
- Lagorce, X.; Ieng, S.H.; Clady, X.; Pfeiffer, M.; Benosman, R. Spatiotemporal features for asynchronous event-based data. Front. Neurosci. 2015, 9, 1–13. [Google Scholar] [CrossRef]
- Domínguez-Morales, M.; Domínguez-Morales, J.P.; Jiménez-Fernández, Á.; Linares-Barranco, A.; Jiménez-Moreno, G. Stereo matching in address-event-representation (AER) bio-inspired binocular systems in a field-programmable gate array (FPGA). Electronics 2019, 8, 410. [Google Scholar] [CrossRef] [Green Version]
- Dikov, G.; Firouzi, M.; Röhrbein, F.; Conradt, J.; Richter, C. Spiking cooperative stereo-matching at 2 ms latency with neuromorphic hardware. In Proceedings of the Conference on Biomimetic and Biohybrid Systems, Stanford, CA, USA, 26–28 July 2017; pp. 119–137. [Google Scholar]
- Chandrapala, T.N.; Shi, B.E. Invariant feature extraction from event based stimuli. In Proceedings of the 2016 6th IEEE International Conference on Biomedical Robotics and Biomechatronics (BioRob), Singapore, 26–29 June 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Chandrapala, T.N.; Shi, B.E. The generative Adaptive Subspace Self-Organizing Map. In Proceedings of the Proceedings of the International Joint Conference on Neural Networks, Beijing, China, 6–11 July 2014; pp. 3790–3797. [Google Scholar] [CrossRef]
- Lagorce, X.; Orchard, G.; Gallupi, F.; Shi, B.E.; Benosman, R. HOTS: A Hierarchy Of event-based Time-Surfaces for pattern recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 8828. [Google Scholar] [CrossRef]
- Ballard, D. Dynamic coding of signed quantities in cortical feedback circuits. Front. Psychol. 2012, 3, 254. [Google Scholar] [CrossRef] [Green Version]
- Benosman, R.; Clercq, C.; Lagorce, X.; Ieng, S.H.H.; Bartolozzi, C. Event-based visual flow. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 407–417. [Google Scholar] [CrossRef] [PubMed]
- Macqueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California: Oakland, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Liu, H.; Pfeiffer, M.; Delbruck, T. DVS Benchmark Datasets for Object Tracking, Action Recognition, and Object Recognition. Front. Neurosci. 2016, 10, 1–5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rueckauer, B.; Delbruck, T. Evaluation of Event-Based Algorithms for Optical Flow with Ground-Truth from Inertial Measurement Sensor. Front. Neurosci. 2016, 10, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Barranco, F.; Fermuller, C.; Aloimonos, Y.; Delbruck, T. A dataset for visual navigation with neuromorphic methods. Front. Neurosci. 2016, 10, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Orchard, G.; Jayawant, A.; Cohen, G.K.; Thakor, N. Converting Static Image Datasets to Spiking Neuromorphic Datasets Using Saccades. Front. Neurosci. 2015, 9, 1–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef] [Green Version]
- Cohen, G.K.; Orchard, G.; Leng, S.h.; Tapson, J.; Benosman, R.B.; van Schaik, A. Skimming Digits: Neuromorphic Classification of Spike-Encoded Images. Front. Neurosci. 2016, 10. [Google Scholar] [CrossRef]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training deep spiking neural networks using backpropagation. Front. Neurosci. 2016, 10. [Google Scholar] [CrossRef] [Green Version]
- Cohen, G.; Afshar, S.; Orchard, G.; Tapson, J.; Benosman, R.; van Schaik, A. Spatial and Temporal Downsampling in Event-Based Visual Classification. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 5030–5044. [Google Scholar] [CrossRef]
- Afshar, S.; Hamilton, T.J.; Tapson, J.; van Schaik, A.; Cohen, G. Investigation of Event-Based Surfaces for High-Speed Detection, Unsupervised Feature Extraction, and Object Recognition. Front. Neurosci. 2018, 12, 1047. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- van Schaik, A.; Tapson, J. Online and adaptive pseudoinverse solutions for ELM weights. Neurocomputing 2015, 149, 233–238. [Google Scholar] [CrossRef] [Green Version]
- Tapson, J.; Cohen, G.; Afshar, S.; Stiefel, K.; Buskila, Y.; Wang, R.M.; Hamilton, T.J.; van Schaik, A. Synthesis of neural networks for spatio-temporal spike pattern recognition and processing. Front. Neurosci. 2013, 7, 153. [Google Scholar] [CrossRef] [Green Version]
- Cohen, G.; Afshar, S.; van Schaik, A.; Wabnitz, A.; Bessel, T.; Rutten, M.; Morreale, B. Event-based Sensing for Space Situational Awareness. In Proceedings of the Advanced Maui Optical and Space Surveillance Technologies Conference (AMOS), Maui, HI, USA, 19–22 September 2017; pp. 1–13. [Google Scholar]
- Kendall, M.G. The Advanced Theory of Statistics; Charles Griffin and Co., Ltd.: London, UK, 1946. [Google Scholar]
- Sen, A.; Sen, M.A.; Amartya, S.; Foster, J.E.; Foster, J.E. On Economic Inequality; Oxford University Press: Oxford, UK, 1997. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ELM + Random Features | ELM + FEAST Features | SKIM | SKIM + FEAST | |||||
|---|---|---|---|---|---|---|---|---|
| Hidden Layer | Mean | Mean | Mean | Mean | ||||
| 1000 Neurons | 75.53% | 0.28% | 84.93% | 0.31% | 81.75% | 0.38% | 85.97% | 0.69% |
| 2000 Neurons | 83.03% | 0.25% | 89.56% | 0.28% | 86.80% | 0.29% | 90.47% | 0.45% |
| 3000 Neurons | 86.37% | 0.28% | 91.45% | 0.22% | 88.79% | 0.26% | 91.88% | 0.34% |
| 4000 Neurons | 87.92% | 0.24% | 92.39% | 0.18% | 89.97% | 0.19% | 92.75% | 0.21% |
| 5000 Neurons | 89.01% | 0.17% | 92.87% | 0.16% | 90.69% | 0.25% | 93.43% | 0.25% |
| 6000 Neurons | 89.74% | 0.23% | 93.30% | 0.20% | 91.25% | 0.21% | 93.73% | 0.08% |
| 7000 Neurons | 90.27% | 0.27% | 94.06% | 0.13% | 91.54% | 0.12% | 94.11% | 0.24% |
| 8000 Neurons | 90.50% | 0.11% | 94.00% | 0.12% | 91.85% | 0.16% | 94.25% | 0.15% |
| Per Frame | Per Drop | |||||
|---|---|---|---|---|---|---|
| Classifier | Raw Events | Random | FEAST | Raw Events | Random | FEAST |
| Linear | 26.1 +/−3.1% | 64.2 +/−4.9% | 83.8 +/−2.5% | 26.1 +/−3.1% | 69.6 +/−5.8% | 87.9 +/−2.7% |
| SKIM 8K | N/A | N/A | N/A | N/A | 74.4 +/−5.0% | 77.0 +/−3.8% |
| ELM 8K | 38.3 +/−2.8% | 67.9 +/−5.0% | 87.2 +/−1.9% | 39.1 +/−2.7% | 75.9 +/−5.3% | 90.1 +/−2.2% |
| ELM 30K | 40.2 +/−2.6% | 69.2 +/−4.7% | 92.8 +/−1.8% | 41.1 +/−2.5% | 77.8 +/−5.5% | 96.2 +/−2.0% |
| # FEAST Neurons | 1 | 4 | 9 | 16 | 25 | 36 | 49 | 64 | 81 | 100 |
| Mean Events per Second | 80,068 | 69,046 | 63,035 | 57,855 | 50,525 | 45,375 | 40,788 | 36,438 | 32,186 | 26,037 |
| STD Events per Second | 1986 | 1057 | 806 | 793 | 640 | 586 | 477 | 486 | 520 | 351 |
| Predicted | ||||||
|---|---|---|---|---|---|---|
| Actual | F117 | Mig-31 | Su-24 | Su-35 | Accuracy | |
| F117 | 24.5% | 0.1% | 0% | 0.5% | 97.7% | |
| Mig-31 | 0% | 20.8% | 0.5% | 3.1% | 85.3% | |
| Su-24 | 0% | 0% | 24.79% | 0.07% | 99.1% | |
| Su-35 | 0.5% | 2.0% | 0.3% | 21.7% | 88.7% | |
| Precision | 97.9% | 90.8% | 97.0% | 85.3% | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Afshar, S.; Ralph, N.; Xu, Y.; Tapson, J.; Schaik, A.v.; Cohen, G. Event-Based Feature Extraction Using Adaptive Selection Thresholds. Sensors 2020, 20, 1600. https://doi.org/10.3390/s20061600
Afshar S, Ralph N, Xu Y, Tapson J, Schaik Av, Cohen G. Event-Based Feature Extraction Using Adaptive Selection Thresholds. Sensors. 2020; 20(6):1600. https://doi.org/10.3390/s20061600
Chicago/Turabian StyleAfshar, Saeed, Nicholas Ralph, Ying Xu, Jonathan Tapson, André van Schaik, and Gregory Cohen. 2020. "Event-Based Feature Extraction Using Adaptive Selection Thresholds" Sensors 20, no. 6: 1600. https://doi.org/10.3390/s20061600
APA StyleAfshar, S., Ralph, N., Xu, Y., Tapson, J., Schaik, A. v., & Cohen, G. (2020). Event-Based Feature Extraction Using Adaptive Selection Thresholds. Sensors, 20(6), 1600. https://doi.org/10.3390/s20061600