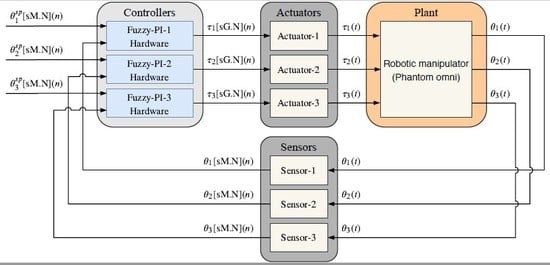
7.1. Throughput Comparison
Table 7 shows a comparison with other works in the literature. Parameters like inference machine (IM) type (Takagi–Sugeno or Mamdani), number of inputs (NI), number of rules (NR), number of outputs (NO), number of bits (NB), throughput in Msps,
and Mflips (Mega fuzzy logic inference per second) are showed. In additional,
Table 7 also shows the speedups (in Msps and Mflips) achieved of the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI controller with TS-FIMM-OS (Fuzzy-PI-OS) and with TS-FIMM-P (Fuzzy-PI-P) over the other works in the literature. The value in flips can be calculated as
.
In the work presented in [
11], the results were obtained for several cases and, for one with two inputs, 35 rules, and one output (vehicle parking problem), the proposed hardware achieved a maximum clock about
with 10 bits [
12,
13]. However, the FIM takes 10 clocks to complete the inference step; in other words, the hardware proposal in [
11] achieves a throughput in Msps of about
and in Mflips of about
. The speedup in Msps for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. As the hardware proposal in this paper used 49 rules, the speedup in Mflips can be calculated as the throughput in Msps
that is, the speedup for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS and Fuzzy-PI-P are
,
,
, and
, respectively.
The work presented in [
5] proposes a Takagi–Sugeno fuzzy controller on FPGA with two inputs, six rules, and three outputs. The hardware achieved a throughput of about
with 8 bits on the bus. With 8 bits, the speedup in Msps for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. The speedup in Mflips is about
over the speedup in Msps.
In [
16], a Mamdani fuzzy logic controller on FPGA was proposed. The hardware carries out a throughput of about
with two inputs, 49 rules, one output, and 16 bits. Using 16 bits, the speedup in Mflips for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. As the number of rules is 49, the speedup in Msps is equal to Mflips.
The work presented in [
31] uses a Mamdani inference machine and the throughput in Mflips is about
. The hardware designed in [
31] operated with 8 bits, four inputs, nine rules, and one output. The speedup in Mflips, with 8 bits, for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. The speedup in Msps is about
over the speedup in Mflips.
The hardware used in [
14] takes six clock cycles over
(in four states) to execute a M-IM with 16 bits. This is equivalent to a throughput of about
. The scheme proposed in [
14] used two inputs, 25 rules, and one output. The speedup in Msps for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. The speedup in Mflips is about
over the speedup in Msps.
The works presented in [
18,
20] show that a piece of hardware can achieve about
. The work presented in [
18] uses two inputs, 25 rules, one output, and 8 bits, and the designer presented in [
20] was projected with three inputs, 42 rules, and one output. The speedup in Msps for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are equal to previously calculated values used in [
5]. The speedups in Mflips are about
and
over the speedup in Msps for works [
18] and [
20], respectively.
The hardware proposes in [
7] achieved a throughput of about
with three inputs, two outputs, and 24 bits. The speedup in Msps for the TS-FIMM-OS, TS-FIMM-P, Fuzzy-PI-OS, and Fuzzy-PI-P are
,
,
, and
, respectively. The fuzzy system proposed in [
7] does not use linguistic fuzzy rules, and it cannot calculate the throughput in Mflips.
There are multiple differences between the devices used for comparison, starting with the number of bits in the LUTs (4-bits LUTs [
5,
11], 5-bits LUTs [
16], and 6-bit LUTs [
7,
14,
18,
20,
31]), board manufacturer (Altera [
5,
16] and Xilinx [
7,
14,
18,
20,
31]), and families used (Spartan-3A [
5], Cyclone-II [
11], Arria-V GX [
16], Spartan-6 [
18,
20], Virtex-5 [
7], and Virtex-7 [
7] ). However, these differences have no significant influence on the throughput; the transmission rates of storage elements, such as LUTs, are in most cases of the same order of magnitude for devices using the same or similar technology. FPGAs have dedicated wires (called carry chains) between neighboring LUTs, and these circuits have a fast transmission rate that allows combining multiple LUTs [
51,
52]. Therefore, differences in size of LUTs do not significantly affect throughput. Unlike the referenced works, for which most use a serial structure, in this work, we use a completely parallel approach. Thus, the design of the hardware architecture is primarily responsible for the resulting performance.
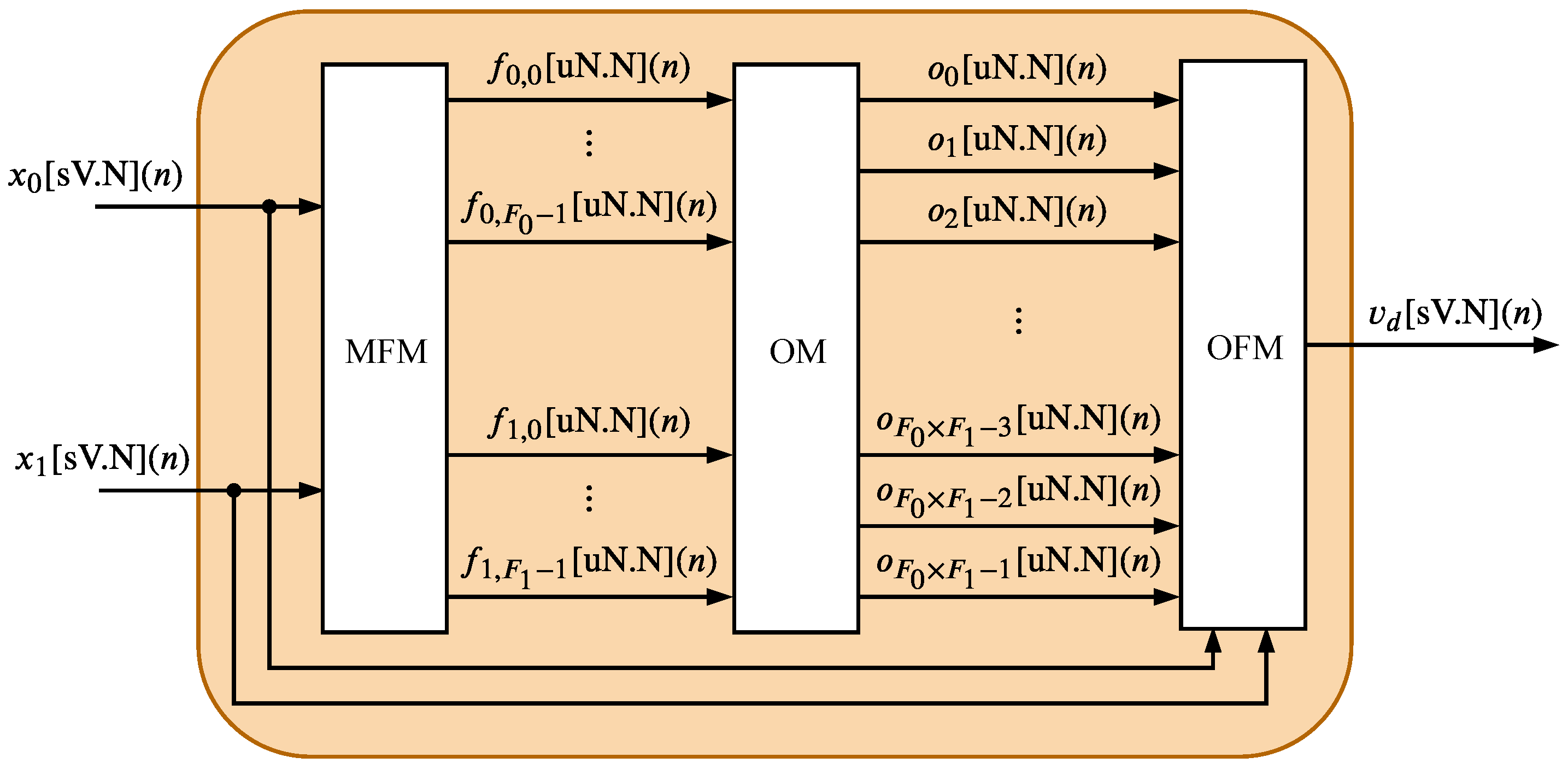
7.2. Hardware Occupation Comparison
Table 8 shows a comparison regarding the hardware occupation between the proposed hardware in this work and other literature works presented in
Table 7. The second, third, fourth, and fifth columns show the type of FPGA, the number of logic cells (NLC), the number of multipliers (NMULT), and the number of bits in memory block RAMs (NBitsM), respectively, and the last three columns show the ratio of the hardware occupation between the proposal presented here,
, and literature works,
, presented in
Table 7. The ratio of the hardware occupation can be expressed as
where
and
can be replaced by NLC, NMULT, or NBitsM.
The work presented in [
11] used a Spartan 3A DSP FPGA from Xilinx, and it has a hardware occupation of about 199 slices, four multipliers, and one block RAM. As this FPGA uses about
LC per slice, it used about 447 LC and it has
bits per block RAM. The scheme proposed in [
5] used a Cyclone II EP2C35F672C6 FPGA from Intel, and it has a hardware occupation of about 1622 logic cells and
Kbits of memory. The EP2C35 FPGA has 105 block RAM and 4096 memory bits per block (4608 bits per block including 512 parity bits).
In [
16], the work assigns an Arria V GX 5AGXFB3H4F40C5NES FPGA from Intel and it has a hardware occupation of about 3248 ALMs and
Kbits of memory. The Arria V GX 5AGX has two combinational logic cells per ALM. The hardware proposed in [
31] employs a Spartan 6 FPGA from Xilinx, and it has a hardware occupation of about 544 LUTs and 32 multipliers. As this FPGA uses about
LC per LUT, it used about 447 LC.
The hardware presented in the manuscript [
14] utilizes a Spartan 6 FPGA from Xilinx, and it has a hardware occupation of about 1802 slices and five multipliers. As this FPGA works with
LC per slice, it used about
LC. The proposal described in [
20] take advantage of Virtex 5 xc5vfx70t-3ff1136 FPGA from Xilinx, and it has a hardware occupation of about 8195 LUTs and 53 multipliers. As this FPGA uses about
LC per LUT, it used about
LC. For 6-input LUT, they use the multiplier 1.6. The work presented in [
7] used a Virtex 7 VX485T-2 FPGA from Xilinx, and it has a hardware occupation of about 1948 slices and 38 multipliers. As this FPGA uses about
LC per slice, it used about
LC.
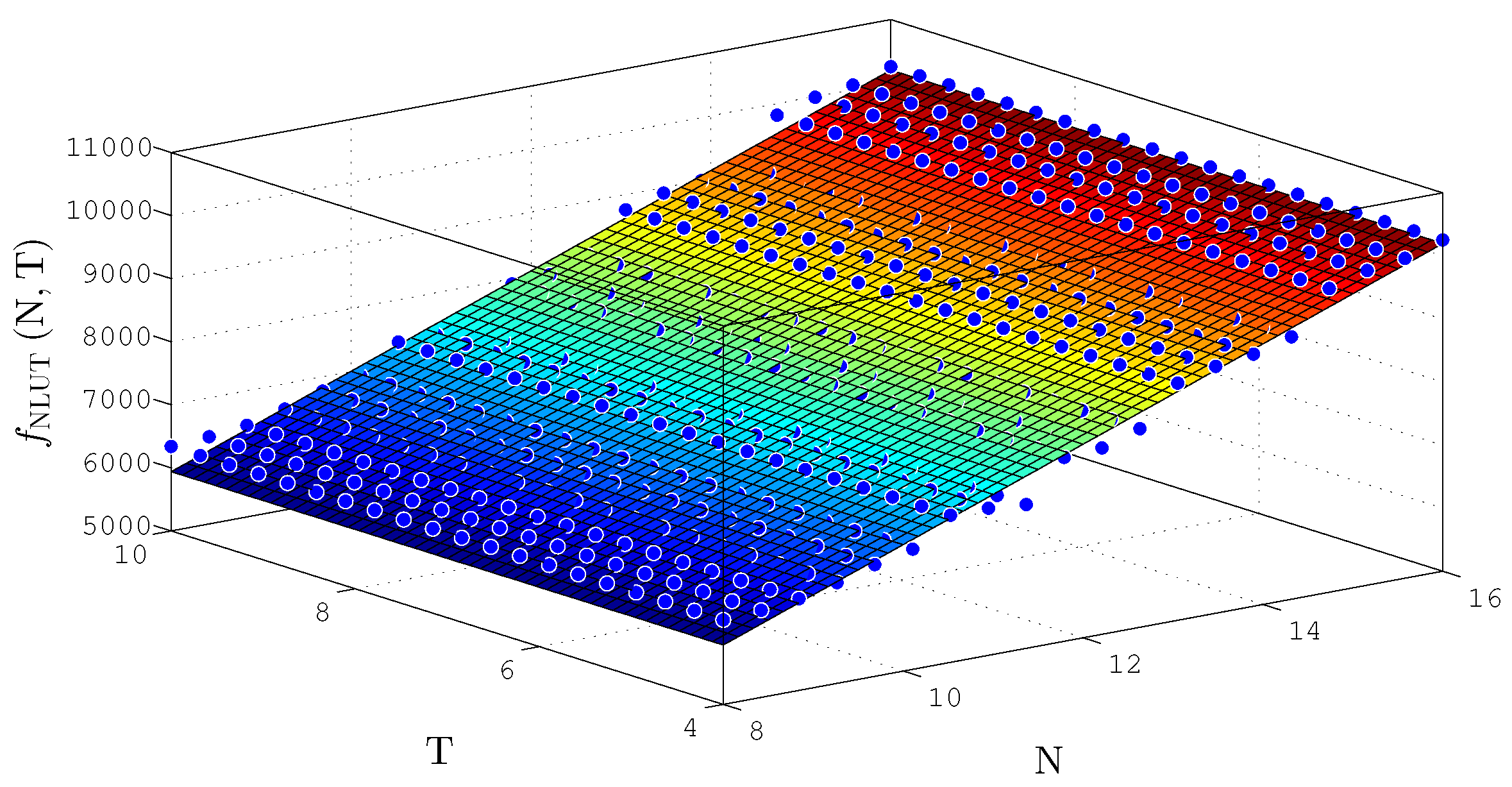
Regarding hardware utilization, the size in bits of the LUTs can have influence when comparing the NLCs in different FPGAs. Since the Virtex 6 (the FPGA board used in this work) has 6-bit LUTs, we can apply a relation factor
to compare between 4-bit and 6-bit LUTs and
for comparisons between 5-bit and 6-bit LUTs. In the case of 4-bit LUTs (the works presented in [
5,
11]), the NLC is reduced by
and the hardware utilization ratio,
, increases by
. For 5-bit LUTs (the work presented in [
16]), the NLC is reduced by
and the
increases by
.
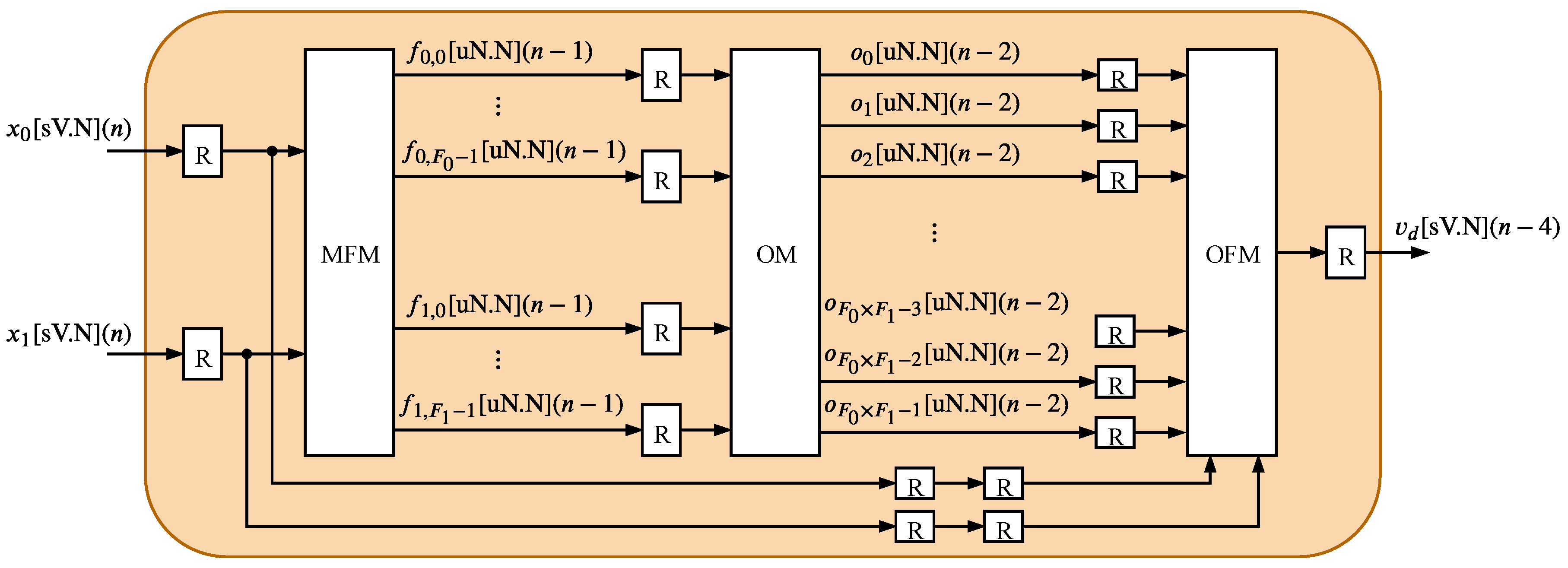
7.3. Power Consumption Comparison
Table 9 shows the dynamic power saving regarding the dynamic power. The dynamic power can be expressed as
where
is the number of elements (or gates),
is the maximum clock frequency, and
is the supply voltage. The frequency dependence is more severe than Equation (
31) suggests, given that the frequency at which a CMOS circuit can operate is approximately proportional to the voltage [
41]. Thus, the dynamic power can be expressed as
For all comparisons, the number of elements,
, was calculated as
Based on Equation (
30), the dynamic power saving can be expressed as
where the
and
are the number of elements (
) and the maximum clock frequency of the literature works, respectively, and the
and
are the number of elements (
) and the maximum clock frequency of this work, respectively. Differently from the literature, the hardware proposed here uses a fully parallelization layout, and it spends a one clock cycle per sample processing. In other words, the maximum clock frequency is equivalent to the throughput,
.
With the exception of the Spartan-3A (presented in [
11]), which uses 4-bit LUTs and the Arria-V GX (presented in [
16]), which uses 5-bit LUTs, the other devices used for power analysis have 6-bit LUTs such as the Virtex-6. Thus, as indicated previously (see
Section 7.2), in the case of the Spartan-3A and the Arria-V GX, the NLC value is recalculated using a 6-bit LUT as reference. For the Spartan-3A, the NLC becomes
, with a dynamic power saving of approximately
. For the Arria-V GX, the NLC becomes
, with a dynamic power saving of approximately
. However, according to Equation (
30), this reduction of NLCs will not have a significant impact on the dynamic power saving since it increases with frequency cube.
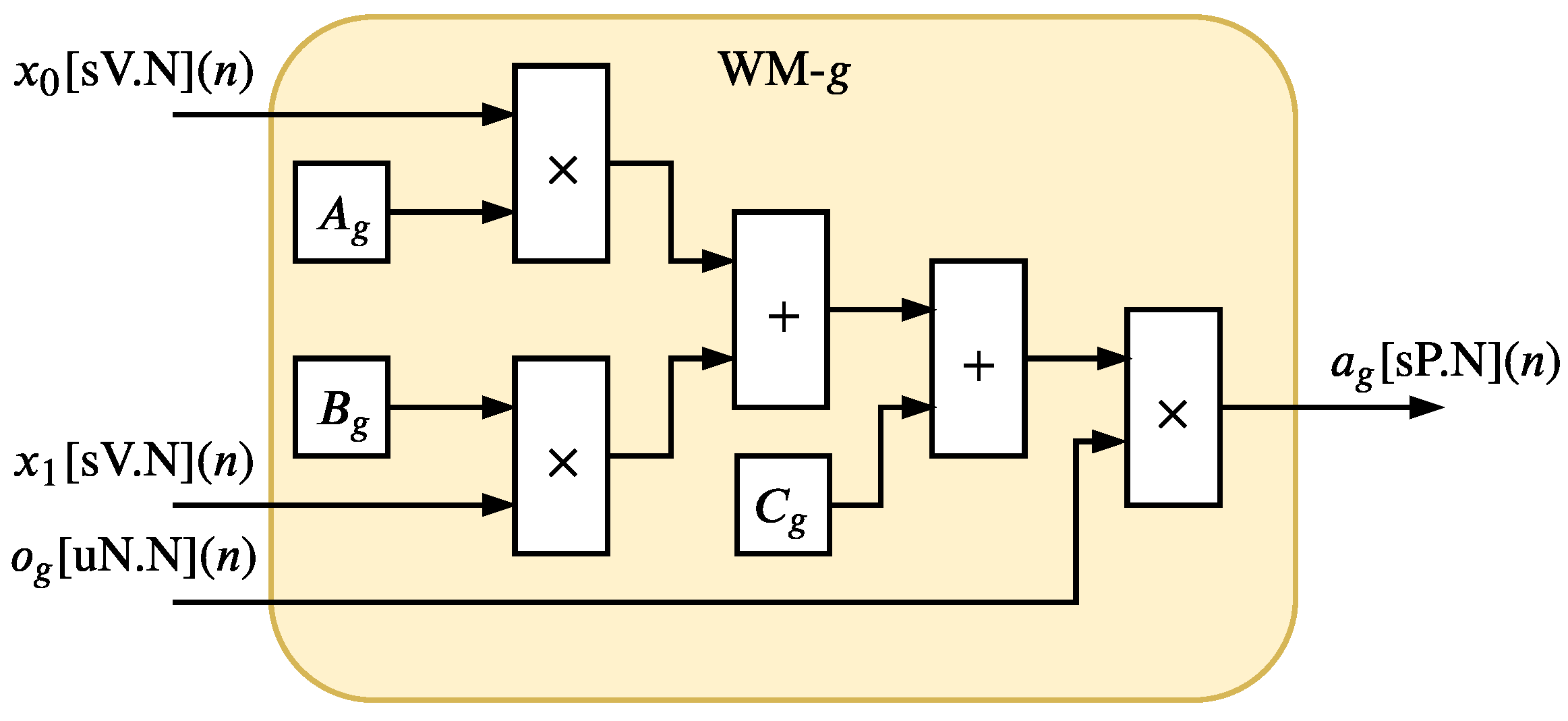
7.4. Analysis of the Comparisons
Results presented in
Table 7 and
Table 9 demonstrate that the fully parallelization strategy adopted here can achieve significant speedups and power consumption reductions. On the other hand, the fully parallelization scheme can increase the hardware consumption, see
Table 8.
The mean value of speedup was about
in Msps and
in Mflips (see
Table 7) and this results are very expressive to big data and MMD applications [
1,
2,
3]. High-throughput fuzzy controllers are also important for speed control systems such as tactile internet applications [
21,
22].
This manuscript proposal has LC resources with higher utilization than the literature proposals (
Table 8). The mean value regarding NLC utilization was about
; in other words, the fuzzy hardware scheme proposed here has used
more LC than the literature proposals. In the case of multipliers (NMULT), the mean value of the additional hardware was about
. Despite being large relative values,
Table 1,
Table 2,
Table 3 and
Table 4 show that the fuzzy hardware proposals in this work expend no more than
of the FPGA resource. Another important aspect is the block RAM resource utilization (NBitsM). The fully parallel computing scheme proposed here does not spend clock time to access information in block RAM, and this can increase the throughput and decrease the power consumption (see [
5,
11,
16] in
Table 7,
Table 8 and
Table 9).
The fully parallel designer allows for executing many operations per clock period, and this reduces the clock frequency operation and increases the throughput. Due to the nonlinear relationship with clock frequency operation (see Equation (
30)), this strategy permits a considerable reduction of the dynamic power consumption (see
Table 9). The results presented in
Table 9 show that the power saving can achieve values from 4 until
times, and these results are quite significant and enable the use of the proposed hardware here in several IoT applications.

 ,
, 

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}