1. Introduction
Blind signal separation (BSS) is one of the areas of blind signal processing (BSP), a rapidly developing and very promising field of signal processing. The term “blind” refers to the fact that BPS methods make it possible to separate source signal from mixed signals without the aid of any information or training data. These methods have numerous applications in many research fields, including medical imaging and engineering [
1,
2,
3,
4], image processing and speech recognition [
5,
6] and communication systems [
7], as well as astrophysics [
8]. In audio engineering, besides speech recognition, BSS can also be used for automatic transcription or speech and musical instrument identification [
9].
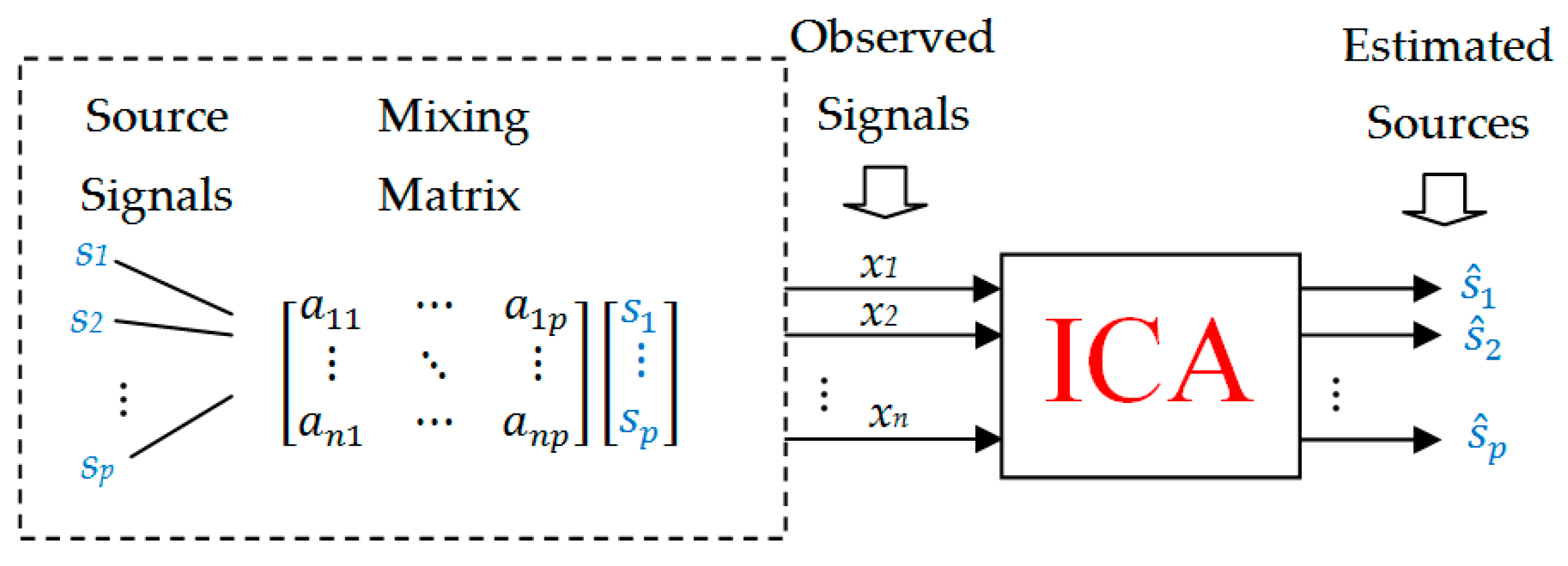
One of the BSS methods is independent component analysis (ICA) [
10], which has gained popularity in a wide range of applications due to its conceptual simplicity and results quality. The ICA technique is a method that uses linear transformation to find statistically independent components from multidimensional mixed data (mixed multichannel signals), assuming that the source signals are statistically independent too. Examples of such multichannel data are audio or vibration signals generated by microphones or vibration sensors recording signals from different measurement points. Standard ICA consists in finding the extreme value of the cost function describing statistical independence, which means that the obtained components will be maximally statistically independent. The efficiency of ICA depends on the cost function selection and the employed optimization strategy [
10].
Standard ICA makes use of a multichannel signal, with the number of channels
n (the number of microphones or sensors) not being lower than the number of source signals
p. ICA consists in calculating statistically independent components (source signals)
and a
mixing matrix
A for
only based on
n values of observed signals (signals generated by microphones or sensors)
. A standard linear ICA model has the form of Equation (1):
where
is a vector of observed signals,
is a vector of source signals,
is an
mixing matrix (
Figure 1). The separation problem is solved by ICA as Equation (2):
where
is an estimation of
and matrix
is an estimation of the inverse of
called filtration matrix. When
, the filtration matrix
belongs to the general linear group
of non-singular matrices
.
Usually, the computational complexity of ICA is reduced at the pre-processing stage by so-called whitening the observed signal, which yields a signal
, where
is the whitening matrix characterized by unitary variance and decorrelation
. Assuming that for source signals
we obtain Equation (3):
This shows that , or , is an orthogonal matrix (transformation from to takes place via an orthogonal matrix ). Therefore, if , then the matrix is a permutation matrix, and thus a new filtering matrix (after whitening) must also satisfy the orthogonality condition. The solving of the ICA task (when ) is therefore reduced to an optimization on the orthogonal group or the special orthogonal group when compared to the original optimization problem on the group (matrices only satisfying the invertibility condition ). This is connected with a reduction of the degrees of freedom in the problem containing for the matrix on for the matrix .
Standard ICA is based on the assumption that the number of source signals
is known and equal to the number of observed signals
, i.e.,
. Still, the ICA estimation can also be performed for a more general case, i.e., when the number of estimated sources
p is unknown. In this case, it is possible that
. When
, i.e., when the number of observed signals is lower than that of source signals, we are dealing with over-complete ICA bases, but when
we are dealing with under-complete ICA [
11,
12]. From a mathematical point of view, such problem can be considered an unconstrained optimization on the Stiefel manifold [
13,
14,
15,
16,
17].
Many ICA-based methods were used to separate mixed signals [
18,
19,
20,
21]. In audio engineering, observed (mixed) signals usually have the form of double channel (stereophonic) or single channel signals. In the case of a single channel signal, which is an “extremely over-complete” ICA model, Equations (1) and (2) cannot be directly employed. In the case of a stereophonic signal, which is known as the problem of under-complete ICA (
), differences between channels in intensity and phase of the signals are used for demixing [
22,
23,
24,
25]. Wang and Brown [
26] introduced a perceptually motivated technique known as the computational auditory scene analysis (CASA) for single channel separation. Nevertheless, it must be emphasized that the effectiveness of such methods is limited and thus some additional a priori information about source signals is required. Most studies in this field are devoted to the extraction (separation) of speech signals [
27,
28], a commonly used approach is the so-called the W-disjoint orthogonality of signals that assumes their non-overlapping in the time-frequency plane [
25,
29,
30]. Jang and Lee [
20] proposed a single channel separation method that use the basis signals obtained by learning the probabilistic properties of sources [
31]. Taghia and Doostari [
32] used band-wide decomposition of mixed signal components and used ICA for signals mixed in time domain. Davies and James [
33] proposed the Single Channel ICA (SCICA) method which is also based on the time domain. In [
19] Casey used a single channel separation method that is based on the use of spectrograms of observed signals. In this method, the time-frequency representation of a signal (spectrogram) is treated as a multichannel observed signal and can this be separated by ICA. ICA-obtained statistically independent time-frequency components are then grouped by the Kullback–Liebler measure in order to reconstruct source signals. A similar albeit less complicated approach was adopted by Barry et al. [
21]. They separate two signals by using only two spectrogram rows (spectrogram matrix) separated by 330 ms assuming additionally that spectrum of the signals was stationary over this time. A similar approach was taken by Wang and Plumbley [
34]. They employed the nonnegative matrix factorisation (NMF) method on the Short Time Fourier Transform (STFT) representation of a single channel observed signal. Their algorithm, however, required the use of an additional training data. In [
35], Mijovic employed both wavelet transforms and a combination of empirical mode decomposition (EMD) and ICA for ECG signals decomposition. Methods based on spectral representation of the observed signal are usually known as spectral decomposition-based methods. In [
36] Litvin et al. used the bark scale aligned wavelet packet decomposition (BS-WPD) instead of the Fourier transform and at the stage of separation they use the Gaussian mixture model (GMM). In [
37], Duan proposed a combination of various single channel separation methods, including some elements of the CASA, spectral decomposition based techniques and model based methods. An excellent overview of single channel source separation methods can be found in [
38,
39].
The paper is organized as follows. In
Section 2 the proposed method of separating single-channel signals is described. There we present subsequent stages of the process and define distance measures used in the method. In addition, the use of linear ICA to solve this type of problem is also explained. In
Section 3 the proposed procedure is used to signal source separation of two- and three-component mixed signals, and the quality of obtained separation is discussed in the context of the signal variance used in the analysis.
Section 4 presents the results of an auditory test carried out on separated signals.
Section 5 discusses the problem of computational complexity of the proposed method and offers a comparative analysis with other simple single-channel separation methods. The results of the analysis are presented in both quantitative and qualitative form. Finally, in
Section 6 (Conclusions) the obtained separation results are summarized with respect to the impact of the number of source components, the spectral type of sources, as well as the impact of the signal variance used in the analysis.
2. Model Definition and Procedure
The proposed concept involves the use of ICA for the time-frequency t-f representation (spectrogram) of a single-channel observed signal. The representation of signal in the form of a spectrogram is actually a non-linear transformation (quadratic transformation). In this case, the use of non-linear BSS (non-linear ICA) would be appropriate. It is well known that nonlinear ICA is a difficult problem and it is generally impossible to identify unambiguously true sources [
40,
41]. However, under certain conditions linear ICA can be used to solve nonlinear BSS. The theoretical conditions for the use of a linear encoder, i.e., cascade PCA and linear ICA to solve a non-linear problem and reconstruct of real independent sources, are presented in [
42]. Solutions are asymptotically achieved when the number of sources is high, and the numbers of inputs
(mixed signals) and non-linear bases
are large relative to the number of sources
. In our approach, this condition is satisfied, i.e.,
, which means that the use of linear ICA is justified in this case.
To this end, the time signal
was analysed by the Short Time Fourier Transform (STFT) in compliance with Equation (4):
where
is the
complex matrix of t-f containing in
-rows instantaneous signal spectra (
is the number of STFT time frames). The input data for ICA is a spectrogram (autospectrum) of the signal
[
43,
44]. The rows of the
matrix are treated as individual channels in a multichannel signal. By applying the ICA on this multichannel signal, we obtain spectral components
of the t-f representation of a single channel signal which are statistically independent. The following relation holds between a
and matrix
a matrix of statistically independent spectral components as seen in Equation (5):
where
is a
mixing matrix,
is an
i-th column of
,
is an
i-th row of
,
is an
i-th t-f component of a mixed one-channel signal.
Throughout this paper, the components
are called spectral bases whereas the columns of
T describing time variation of
are called time bases and denoted by
. The matrix
, which is the product of the time basis
and the spectral basis
, is called
i-th t-f component. By an appropriate grouping of
bases into subgroups generating constituent components of the mixed signal, this mix can be decomposed into
components (for comparison, see Equation (1)) using Equation (6):
where
are
index sets obtained by grouping
bases.
In [
45,
46], the single channel signal decomposition was done by the grouping of time bases
and frequency bases
.
For practical reason, to reduce computational complexity, it is convenient to only use the
bases which “carry” a specified variance of the mixed signal. Assuming that in the analysis we use
of signal variance, Equation (5) has the following form in Equation (7):
where the index
corresponds to the number of
bases “carrying”
variance of the mixed signal. The selection of
determines the number
of
bases that are subsequently used in ICA estimation. These bases span a subspace
of the primary
which is maximally energetic.
The grouping of bases is, in fact, a clustering process, i.e., collecting elements into clusters [
47,
48]. Clustering results depend on many factors, such as the employed distance measure and clustering algorithm. The distance between base components can be defined in many ways. The selection of a given distance measure type depends on many factors, including the frequency composition of signals, degree of overlapping of signals in time and frequency, the required quality of separation and frequency-related similarity of constituent signals of the mix. In the present experiment, two types of grouping were applied. The first was based on the use of clustering algorithms (hierarchical and
k-mean clustering), while the other involved the maximization of negentropy of separated components. ICA-based single channel separation methods primarily use component grouping based on similarity in time or frequency domain. We suggest the use of a time-frequency structure to measure the similarity features in both time and spectral domain. We cluster the (TFD)^i bases using two types of distance between
bases, i.e., the classic Euclidean distance
and the distance
, which we call in this study as the
distance of Gaussian distribution. The Euclidean distance
is defined as Equation (8):
where
denotes the Frobenius norm. The generalized Gaussian distribution is expressed by Equation (9) [
49]:
where
are the expected value and the standard deviation of a random variable
, respectively. The parameter
describes the type of a random variable
, i.e., its deviation from normal distribution. The parameters
and
are defined by Equations (10) and (11):
where
is the Gamma-Euler function.
By treating a signal spectrogram as a random variable one can describe its distribution in parametric terms, i.e., it is possible to estimate the parameters
based on the model in Equation (9). When the source spectrograms are known, we can find the parameter
. The
distance is defined as the difference between
and the parameter
characterising the spectrogram of a constituent signal reconstructed after grouping
(index
was defined in Equation (6)) in the following way in Equation (12):
By minimizing the
distance for individual constituent signals one can group
bases so that the reconstructed signals are statistically as close as possible to the original signals. The
parameter we estimated by
a posteriori determination of the maximum of
. When observations of the random variable
are available the
a posteriori distribution of the
parameter is given by Equation (13) [
10,
18]:
where
denotes a data likelihood [
18] and
is an
a priori distribution of the
parameter. The study [
18] offers practical recommendations (solutions) for calculating the
distribution.
The other way of grouping
bases consists in maximizing negentropy (negative entropy) of reconstructed constituent signals
. Statistically independent constituent signals have the maximum negentropy [
10,
50]. By finding of reconstructed constituent signals
with the maximum negentropy, we group the
bases in a correct way. The negentropy function
was approximated as Equation (14) [
10]:
where
is the normalized Gaussian random variable (
) and
is a nonlinear function of the random variable usually having the form
or
. This type of approximation has numerous advantages including conceptual simplicity and rapid calculation rate [
10]. As a result, it is very often used as a cost function in algorithms for solving ICA problems [
51].
3. Experiment
The proposed idea of single channel separation was verified by experimental tests. The experiments involved demixing single-channel signal consisting of two and three constituent signals. The constituent signals
,
and
were selected so that their spectral composition and their respective types of sources were different. The
signal (“ringer”) was generated by an electric device and was a recording of an electric ringer, while the
signal (”baby”) was a baby cry, which means that it had a specific stochastic variation of the spectre, as do all sounds generated by living beings. The
signal (“tom”) was a sound generated by a percussion instrument and, as such, was a typical impulsive signal. The above constituent signals were mixed in the following combinations:
and
. The signals were recorded at the sampling frequency
and their duration was 1.2 s. Mixed single channel signal was transformed to the frequency domain using the STFT. We use blocks 256 samples long, 50% overlapped. The t-f analysis was performed in two separate blocks of 3968 and 5888 samples corresponding to the time intervals of 0–0.51 s and 0.51–1.2 s, respectively, in order to ensure higher stationarity of signal spectra in individual blocks. We used full signals of 9856 samples to determine the
distance.
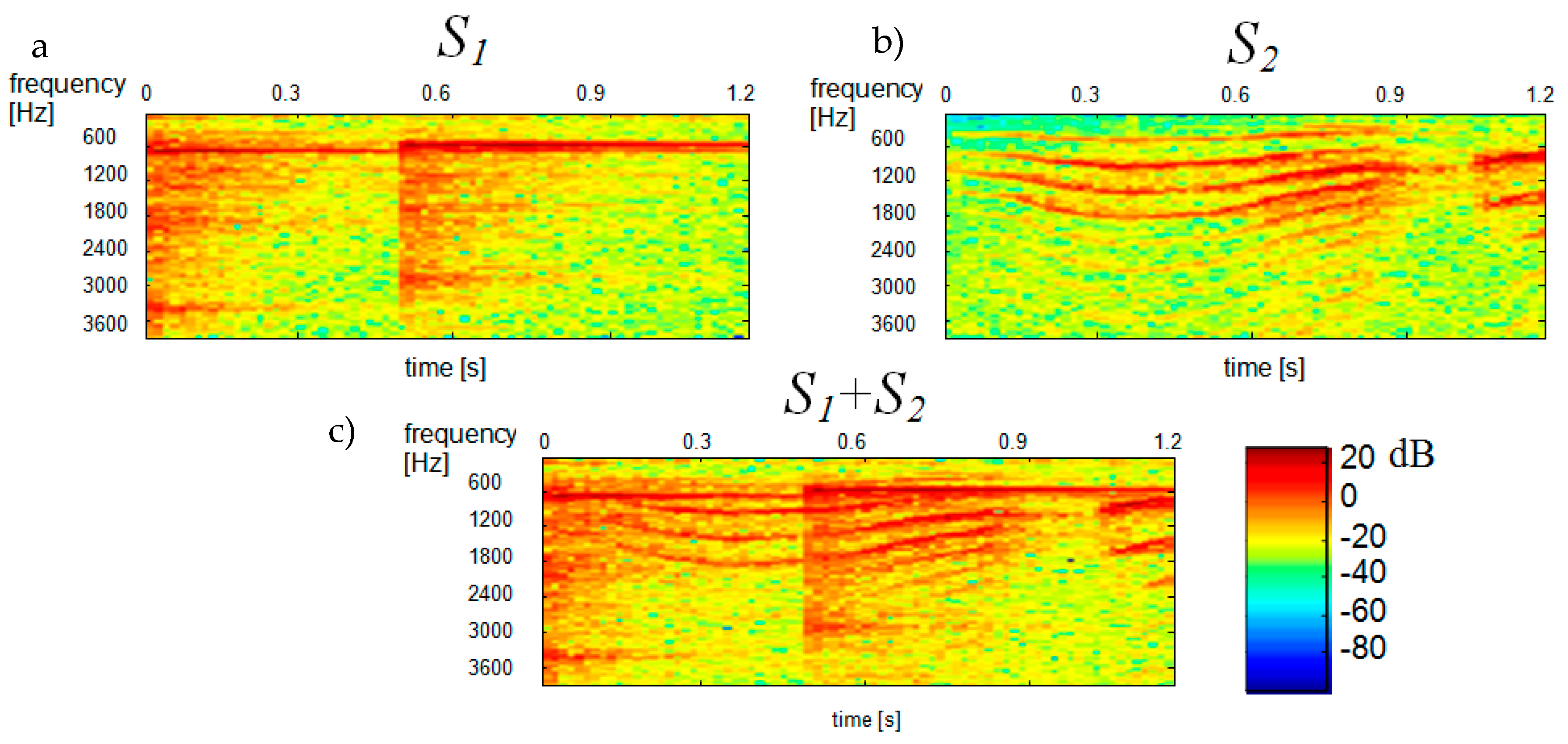
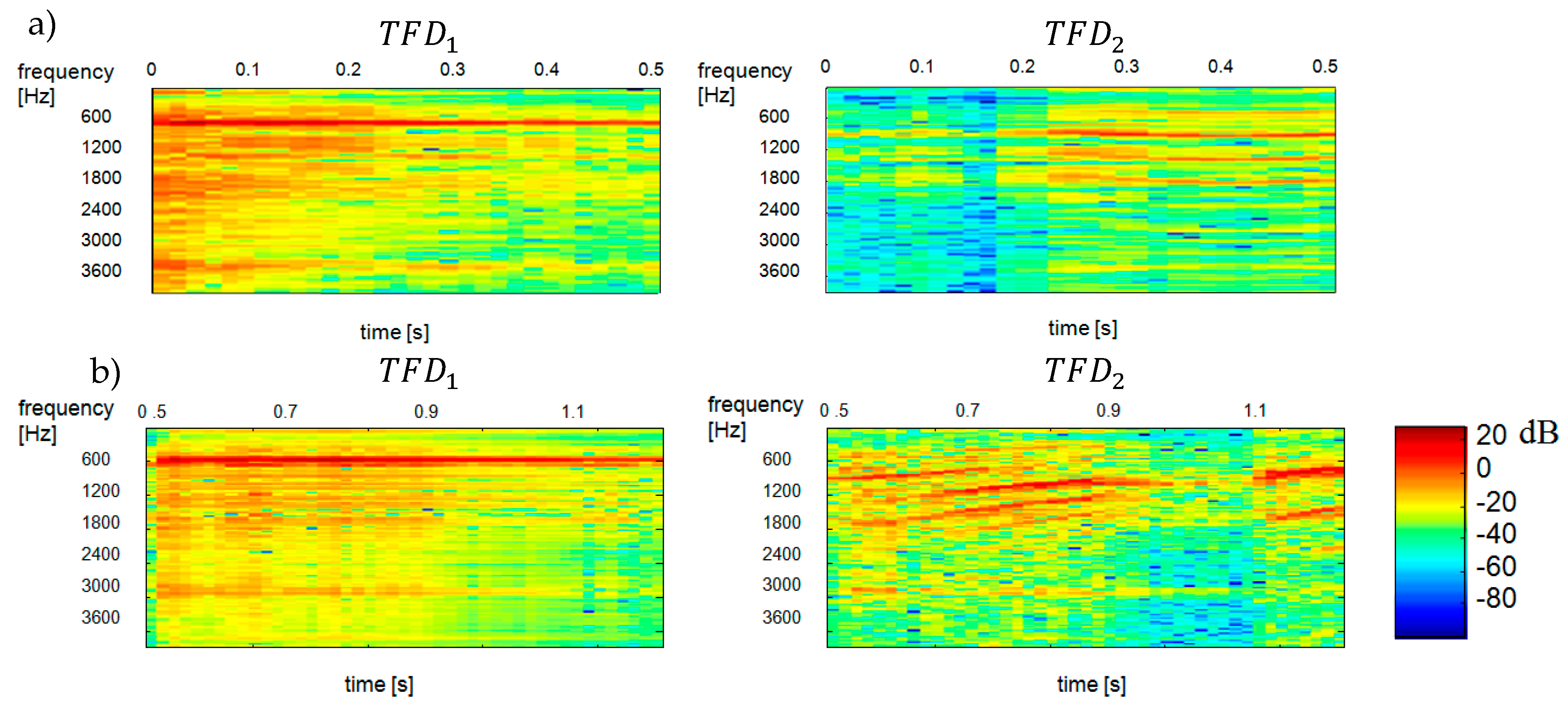
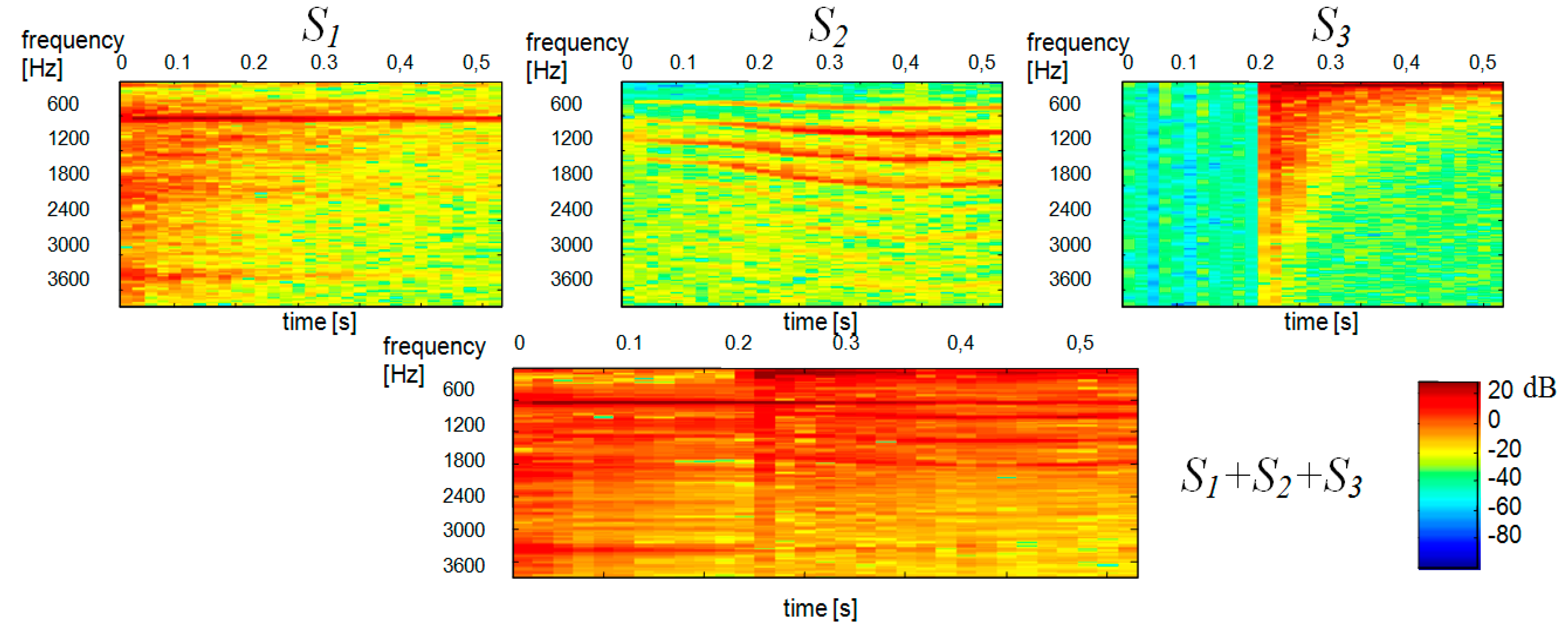
Figure 2 shows the spectrograms of constituent signals
and
, with the spectrogram on the left showing the
signal (“ringer”) and the spectrogram on the right showing the
signal (“baby”).
The STFT-generated spectrogram of
(bottom diagram in
Figure 2) was treated as a multichannel signal and estimated by ICA. This was done using the FastICA Matlab function algorithm based on [
14]. Signal whitening was performed by singular value decomposition (SVD) using the Matlab function
svd. ICA-generated statistically independent spectral bases
, time bases
and time-frequency bases
for the variance
of the input signal are shown in
Figure 3,
Figure 4 and
Figure 5, respectively.
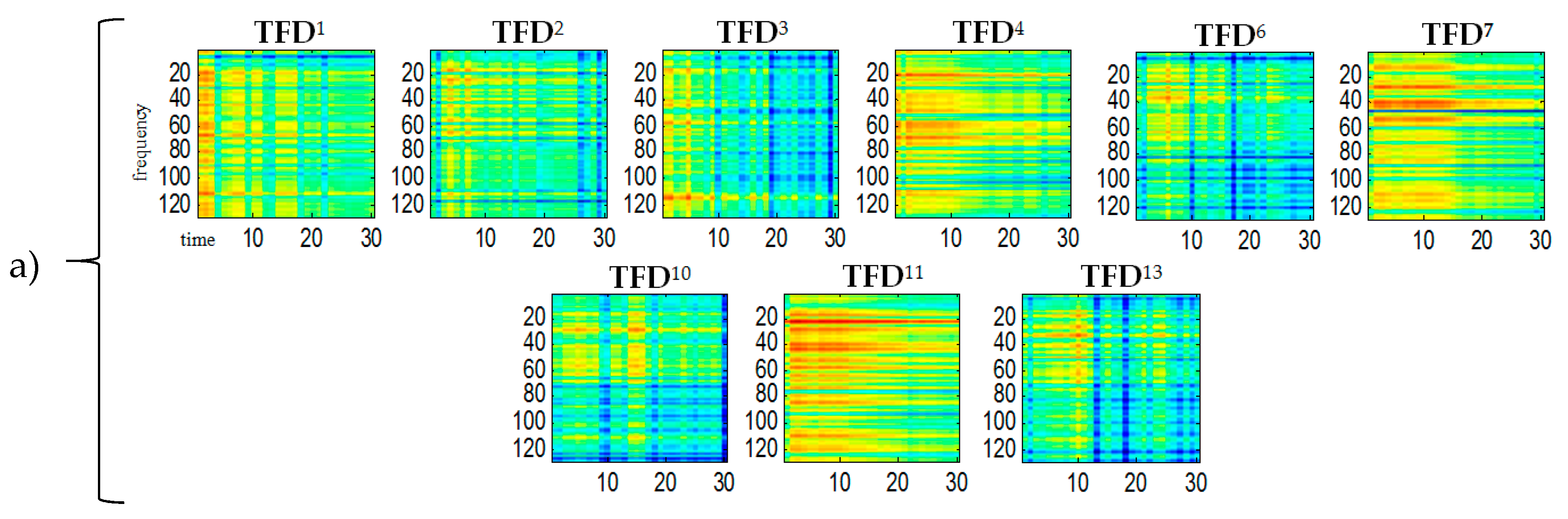
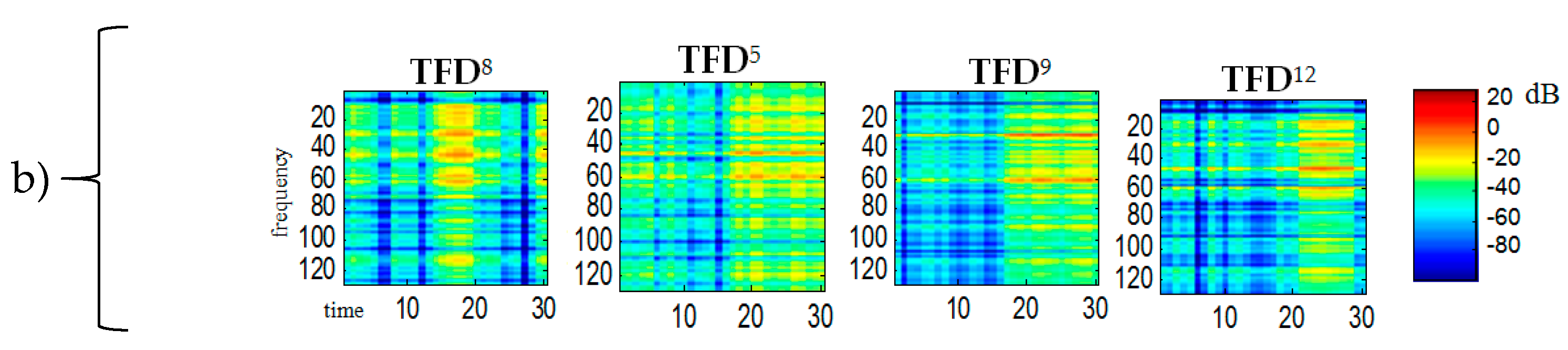
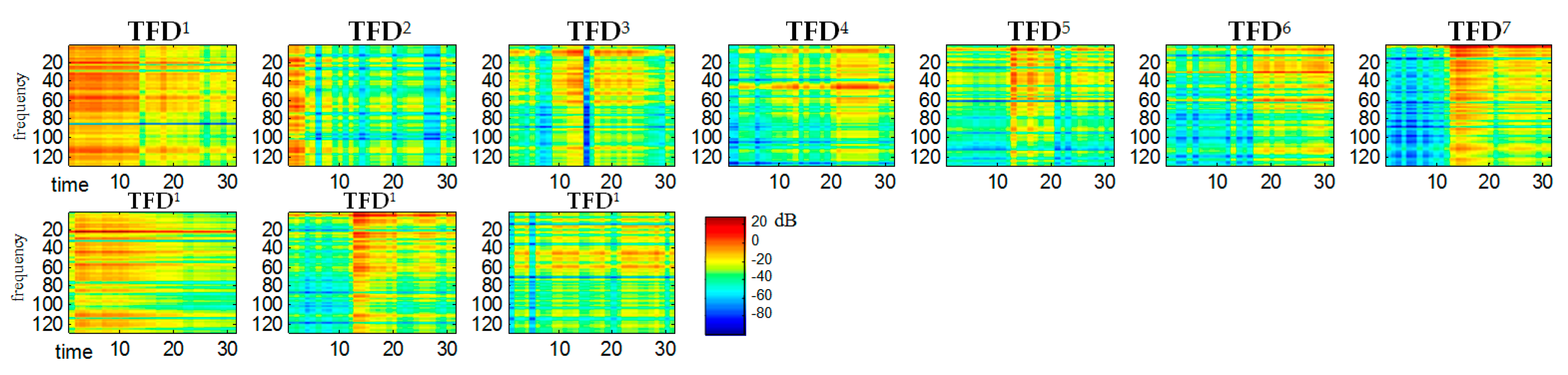
For all
shown in the
Figure 5 the ordinate axes scales range 0–129, which corresponds to the frequency range 0–4 kHz. The time scale range 0–30 corresponds to the range 0–0.51 s. A comparison of the obtained
bases in
Figure 2 reveals that bases 4, 7, 11 belong to the spectrogram of the
S1 signal (ringer). Both this figure and some subsequent figures show the ICA results made in the first sample block (from 0 to 0.51 s).
The clustering was performed by hierarchical [
48] and
k-mean partitional clustering [
52] using two standard Matlab functions:
dendrogram and
kmeans.
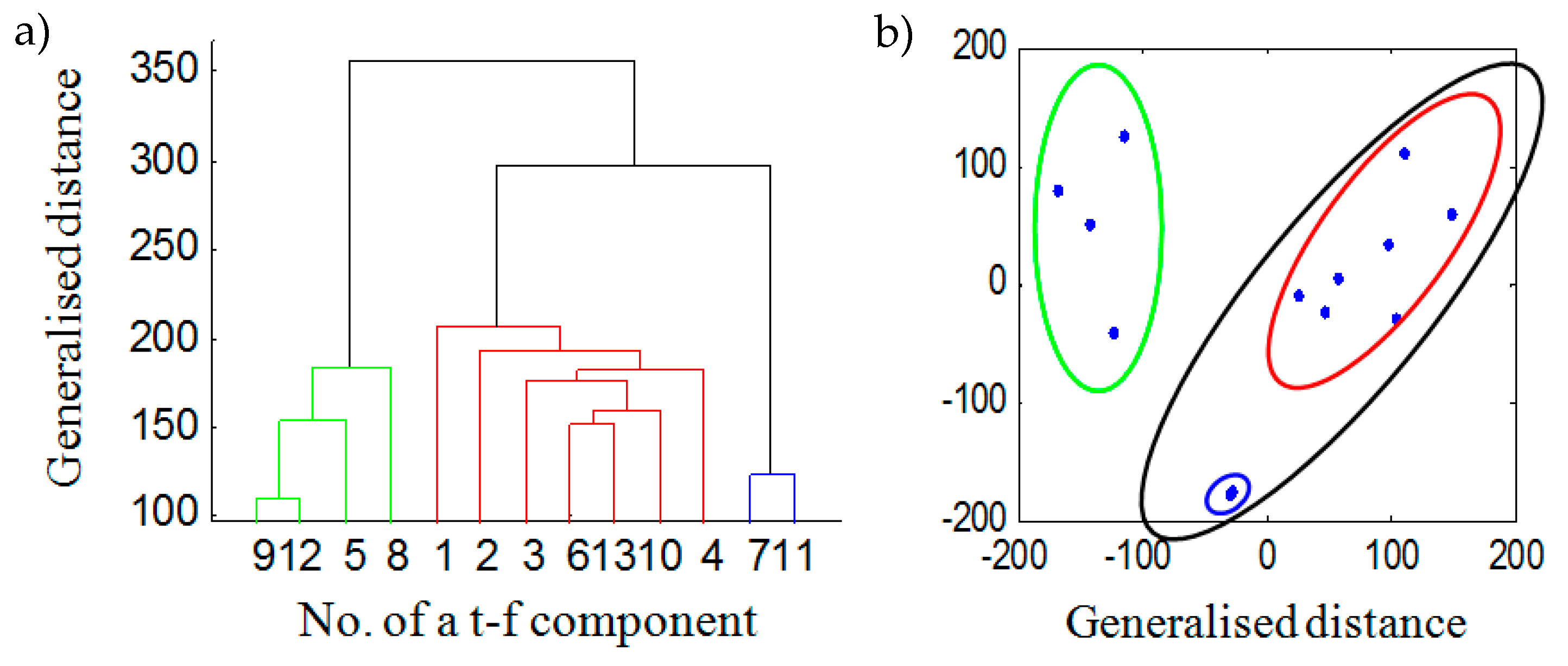
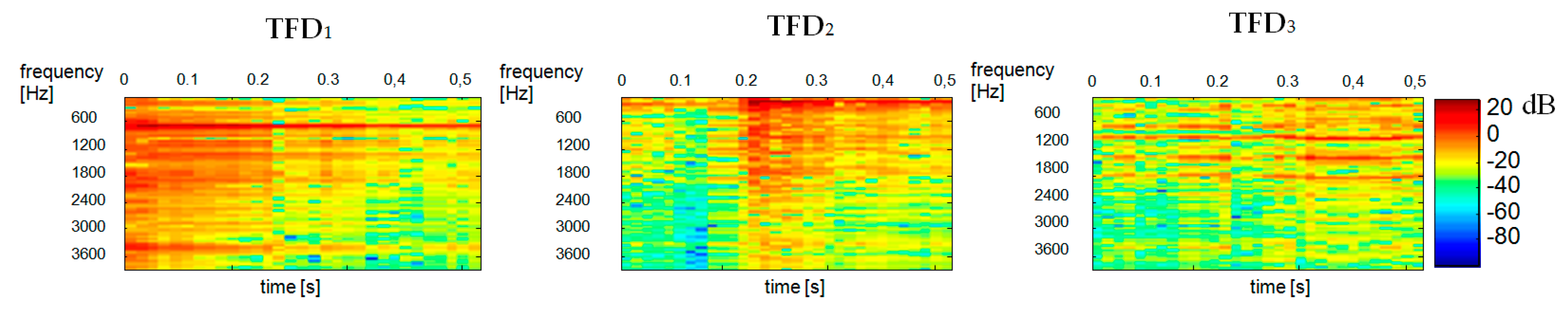
Figure 6a shows the separation results obtained with the Euclidean distance between
components and a dendrogram obtained by hierarchical clustering.
Figure 6b illustrates the “distances” between
components obtained by multidimensional scaling [
53]. Ellipses correspond to components collected in the dendrogram shown in
Figure 6a. By summing the
components grouped in
Figure 6b and shown as green and black ellipses, we obtain spectrograms of two separated components seen in Equation (15):
Figure 7 shows the reconstructed spectrograms of
and
components.
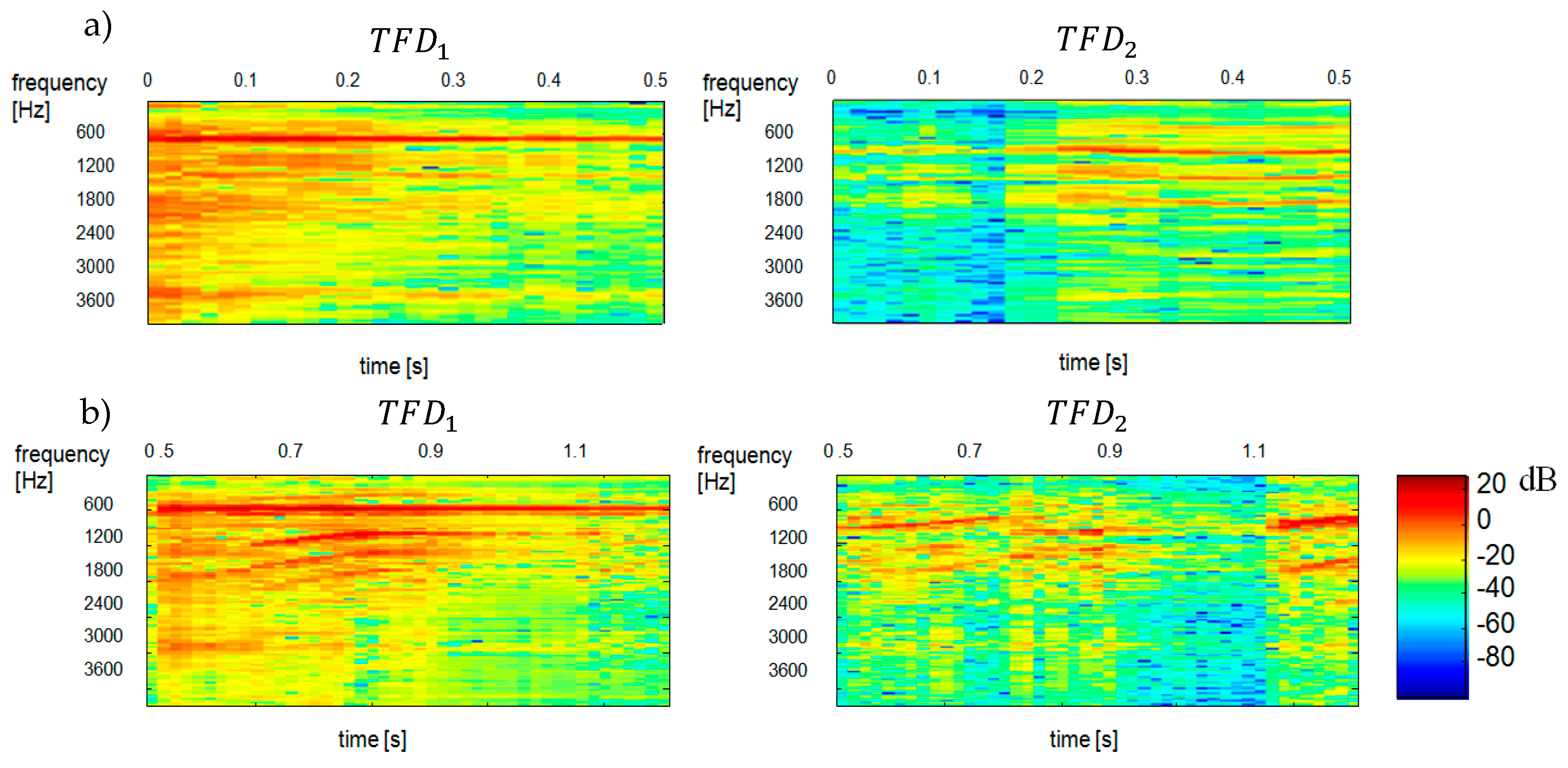
Figure 8 shows the results of separation obtained by maximizing the negentropy of components
and
.
An analysis of the data in
Figure 9 demonstrates that the separation is effective yet it depends on the length and the variance (parameter
) of the analysed signal, and hence on the number of obtained
bases. The lower the number of these bases is, the more effective the grouping results are obtained. Nevertheless, a decrease in the variance
results in a reduced quality of reconstruction spectrograms. The quality of separation is considerably lower for the variance
of the mixed signal, which is manifested in the interpenetration (interference) of spectra of the constituent signals.
Figure 9 shows the results of clustering process with
β distance of Gaussian distribution
. As it results from the presented
Figure 9 results of the separation seems to be efficient. They depend however on the length of the analysed signal and the used variance value of the analysed signal (parameter α) and therefore on the number of received
bases. The smaller the number, the better the grouping results. However, lowering the value of variance α also causes a reduction in the quality of spectrogram reconstruction. The quality of separation is significantly worse when using
variance of the mixed signal, which is manifested by the interpenetration (interference) of spectra of the signal components.
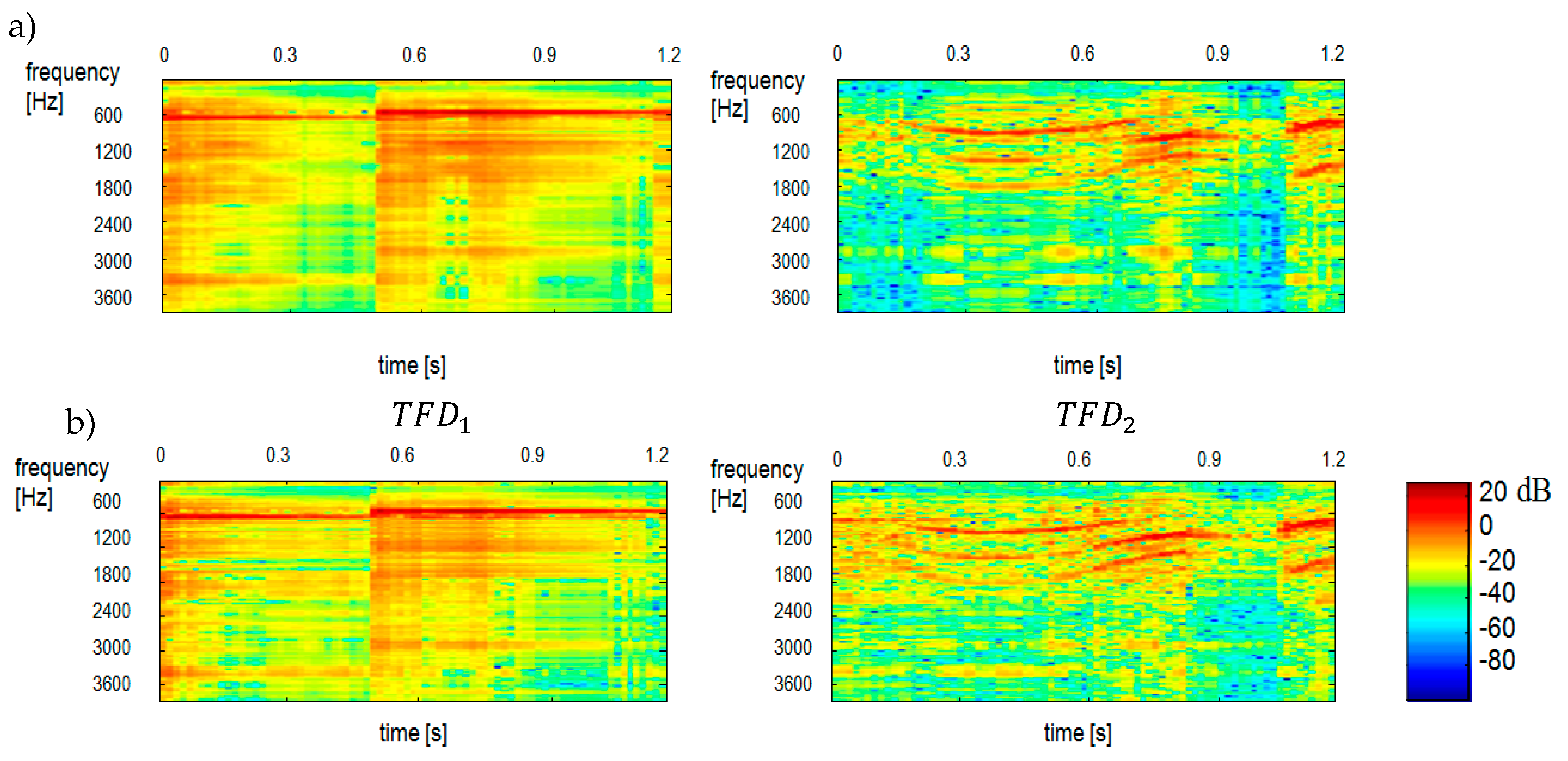
We used our method for the demixing a single-channel signal consisting of three component signals
. The spectrogram of the mixed signal as well as the spectrograms of its constituent signals were shown in
Figure 10. Like in
Figure 5 the scales range 0–129 for all
corresponds to the frequency range 0–4 kHz. The time scale range 0–30 corresponds to the range 0–0.51 s. Statistically independent
bases are shown in
Figure 11. One can notice a sharp similarity between
bases and the constituent sounds of the
mixed signal. To give an example,
,
,
are ringer sounds,
,
and
are tom sounds, while other bases are baby sounds. Hence, at the clustering stage, the
bases were grouped into 3 classes (clusters) by
k-mean partitional clustering.
Figure 12 shows the results of separation of a three-component signal.
4. Perceptual Evaluation
For each of the decomposition versions presented in
Section 3, the inverse STFT for every separated
was used. The proposed separation method has been implemented in Matlab. The inverse STFT involved reconstructing time signals based on the spectrograms of separated
bases. Given that such transformation is only based on amplitude information (spectrograms do not contain phase information), the time signals were additionally burdened with the error of “imprecise” invertibility of the STFT. In order to eliminate the effect of “imperfect” invertibility of the STFT (phase distortion), the reference signal’s sounds of the mix were also re-synthesized with zero phase. The RMS values of all separated and reference signals were normalised. All sounds were Microsoft Windows system sounds and were resampled to 8 kHz.
For the purpose of the test, 9 pairs of reference (original) and separated sound were prepared. These pairs are called “samples”. We generated 5 sets of samples (one set per every listener), each containing 9 samples. Sequence of samples was random and different in each set. The samples were separated by 3 to 4 s of silence. Each of five participants listened to five sets of samples. The participants included one sound engineer, two instrumental musicians and two individuals not related to music. Every listener listened to samples at the same loudness (over 80 dBA) over the AKG K271 closed-back (studio) headphones in studio room. Degradation category rating scale [
54] was used to rate the quality of separation by the listener. The original five-point scale was extended to six-point, as suggested by the listeners. A score of 1 means “very distorted” while a score of 6 means “inaudibly distorted”. Before the final test, each listener underwent a short training session.
Table 1 gives the scores (mean values and standard deviations) of perceptual quality of separation with
distance of Gaussian distribution
and the Euclidean distance for
components.
Table 2 shows the impact of the mixed signal variance used (
or
) on the perceptual quality of separation.
The best results were obtained for the separation performed with the use of the
distance. The ringer sound was most efficiently unmixed for every mixed signal type and distance measure. The results of the baby sound are worse. The tom sound was the most difficult to separate. These results demonstrate that the proposed method is the most effective for signals (sounds) with a quasi-stationary signals with harmonic spectrum (ringer) and the least effective for non-stationary signals with a noise-like spectrum (tom). The quality of separation is higher when the variance
of the mixed signal is higher (
Table 2) and, as expected, when separating from two-component mixes. In this case, specifically, the results are 0.5 points higher on the average.
5. Computational Complexity and Comparison Analysis
In this section, we evaluate the computational complexity of the proposed methods and compare our results with those obtained by other simple single-channel source separation methods. Our approach consists of five stages of processing: transformation of the time signal into a spectrogram, ICA stage with whitening as pre-processing, calculation of distance measure, grouping and inverse transform to the time domain. We consider the approximate number of floating point operations (flops). The code is implemented on a 2.8 GHz (CPU), 8 GHz (RAM) platform. At the transformation stage, we employ STFT with the FFT algorithm which is a very effective method because it involves overall
(only the most significant terms are retained) flops for the time window (time segment), where
2n is the number of samples in the time window used in STFT. Using the big
notation, the computational complexity of this stage is
. In the ICA stage, we used the Singular Value Decomposition (SVD) as pre-processing which involves
flops, where
is the number of time segments used in STFT stage. At the SVD sub-stage, we reduced the dimension of the analysis based on the desired signal variance value
. In the ICA stage, we used the FastICA algorithm which is a very effective algorithm and requires only
[
55] per iteration, where
is a dimension of ICA reduced in the SVD sub-stage. This means that the approximation of complexity in the ICA stage is of order
. In the stage of calculating the distance between the
bases we used two types of distances: the classic Euclidean distance
and the distance
, that require approximately
and
flops, respectively. In the clustering stage, we used the hierarchical clustering algorithm (single-linkage type) or the k-mean algorithm. Both algorithms have computational complexity of order
[
48] but it includes the complexity of distances
and
calculating as the main stage of clustering process. At the inverse transform stage, we used IFFT algorithm which requires, similar to FFT,
flops.
In order to compare our method with others solutions, we additionally carry out single-channel separation using the method proposed in [
19] and the method based on analysing the similarity of time bases
which are called here as TFD-SCSS, KL-SCSS and T-SCSS, respectively. In the KL-SCSS method, the Kullback–Leibler distance (symmetrical Kullback–Leibler divergence) is used as a measure of distance for the spectral bases
. In the T-SCSS method we use the Euclidean distance for time bases
. Separation efficiency is measured using the root mean square error indicator (RMSE) compared to the original sources. Considering the spectrograms of the original
sources and separate
sources, the RMSE is calculated as:
where
are the row and column indices of the
and
indices.
The same set of source and mixed signals as in the auditory tests (
Section 4) as well as the same analysis parameters are used in the comparative analysis.
Table 3 presents the average results of the RMSE index for four combinations of mixed signals. It can be stated that our method based on the time and frequency domain similarity generally yields better separation results than those obtained with the methods that only use time or spectral similarity. For the mixed signal ringer + tom, better separation results are obtained using T-SCSS. This probably results from the clear differences in the time structure of the signal sources and better matching of distance in the T-SCSS method.
In addition, the time-course results are subjected to auditory testing.
Table 4 gives the scores (mean values and standard deviations) of the perceptual quality of separation of our methods with the
distance of the Gaussian distribution
and the KL-SCSS and T-SCSS methods.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}