Joint Content Placement and Storage Allocation Based on Federated Learning in F-RANs



Abstract
:1. Introduction
2. Related Work
- We jointly considered storage resource allocation and content placement in the network to formulate an optimization problem to minimize the network traffic cost.
- Due to the dynamic change of content popularity in the network, the federated learning framework is applied to predict the content popularity accurately in the region to develop an efficient content caching strategy. To the best of our knowledge, the problem of federated learning-based joint content placement and storage allocation has not been well studied in previous works.
- Two heuristic algorithms are proposed, and the experimental results based on real-worlds datasets verify the performance superiority of our proposed algorithm.
3. System Model
3.1. System Architecture
- (1)
- Retrieve user’s requested content from the cloud computing server;
- (2)
- Maintain an index table for storing cached content locations in the network;
- (3)
- Forward the user’s content request to the neighboring F-APs that cache the content;
- (4)
- Collect information about the requested content in F-APs;
- (5)
- Decide when to update the entire content cache of F-APs, which can be refreshed at specific intervals or when content popularity changes significantly.
3.2. Caching Process
3.3. Content Popularity
3.3.1. Global Content Popularity
3.3.2. Federated Learning Prediction
- ①
- Model Download:
- ②
- Local Model Training:
- ③
- Upload Updated Model:
- ④
- Weighted Aggregation:
4. Problem Formulation
5. Problem Solution
5.1. Storage Resource Allocation Problem
| Algorithm 1: Traffic-based allocation Algorithm |
 |
5.2. Cache Content Placement Problem
5.2.1. Greedy Algorithm based on Global Content Popularity
| Algorithm 2: Greedy Algorithm based on Global Content Popularity |
 |
5.2.2. Local Popularity Knapsack Algorithm based on Federated Learning
| Algorithm 3: Local Popularity Knapsack Algorithm based on Federated Learning |
 |
6. Simulation Results
6.1. Simulation Parameters
6.2. Datasets
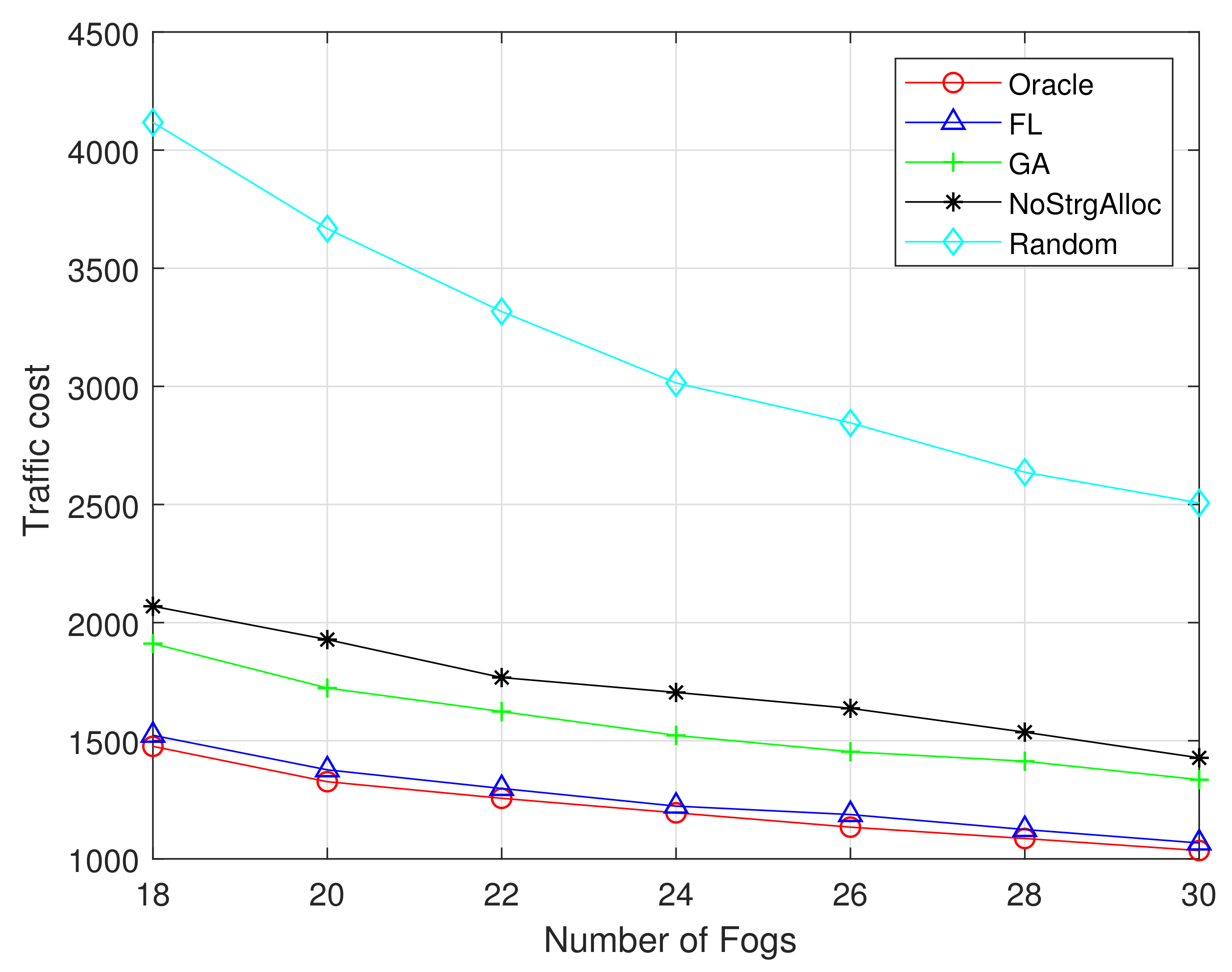
6.3. Evaluation and Discussion
- (i)
- Oracle: The algorithm has a priori knowledge of content popularity and provides optimal cache performance.
- (ii)
- No storage allocation (NoStrgAlloc): The content popularity follows the Zipf distribution and does not consider the storage resource allocation of the fog computing server.
- (iii)
- Random: The random algorithm randomly selects F content for caching, which provides the lowest caching performance.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, V.; Chiang, C.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When edge meets learning: Adaptive control for resource-constrained distributed machine learning. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 63–71. [Google Scholar]
- Fortino, G.; Rovella, A.; Russo, W.; Savaglio, C. Towards cyberphysical digital libraries: Integrating IoT smart objects into digital libraries. In Management of Cyber Physical Objects in the Future Internet of Things; Springer: Cham, Switzerland, 2016; pp. 135–156. [Google Scholar]
- Chiang, M.; Zhang, T. Fog and IoT: An overview of research opportunities. IEEE Internet Things J. 2016, 3, 854–864. [Google Scholar] [CrossRef]
- Peng, M.; Yan, S.; Zhang, K.; Wang, C. Fog-computing-based radio access networks: Issues and challenges. IEEE Netw. 2016, 30, 46–53. [Google Scholar] [CrossRef] [Green Version]
- Park, S.-H.; Simeone, O.; Shitz, S.S. Joint optimization of cloud and edge processing for fog radio access networks. IEEE Trans. Wirel. Commun. 2016, 15, 7621–7632. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Lu, H.; Zhao, Z.; Wang, H.; Georgalas, N. Federated Learning Based Proactive Content Caching in Edge Computing. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018; pp. 1–6. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. Acm Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Mcmahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Wang, X.; Han, Y.; Wang, C.; Zhao, Q.; Chen, X.; Chen, M. In-Edge AI: Intelligentizing Mobile Edge Computing, Caching and Communication by Federated Learning. IEEE Netw. 2019, 33, 156–165. [Google Scholar] [CrossRef] [Green Version]
- Asad, M.; Moustafa, A.; Yu, C. A Critical Evaluation of Privacy and Security Threats in Federated Learning. Sensors 2020, 20, 7182. [Google Scholar] [CrossRef]
- Fantacci, R.; Picano, B. Federated learning framework for mobile edge computing networks. Caai Trans. Intell. Technol. 2020, 5, 15–21. [Google Scholar] [CrossRef]
- Han, T.; Ansari, N. Network utility aware traffic load balancing in backhaul-constrained cache-enabled small cell networks with hybrid power supplies. IEEE Trans. Mobile Comput. 2017, 16, 2819–2832. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, K. Recent Advances in Fog Radio Access Networks: Performance Analysis and Radio Resource Allocation. IEEE Access 2016, 4, 5003–5009. [Google Scholar] [CrossRef]
- Tandon, R.; Simeone, O. Cloud-aided wireless networks with edge caching: Fundamental latency trade-offs in fog radio access networks. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 2029–2033. [Google Scholar]
- Fan, X.; Zheng, H.; Jiang, R.; Zhang, J. Optimal Design of Hierarchical Cloud-Fog & Edge Computing Networks with Caching. Sensors 2020, 20, 1582. [Google Scholar]
- Wang, X.; Leng, S.; Yang, K. Social-aware edge caching in fog radio access networks. IEEE Access 2017, 5, 8492–8501. [Google Scholar] [CrossRef] [Green Version]
- Hung, S.; Hsu, H.; Lien, S.; Chen, K. Architecture Harmonization Between Cloud Radio Access Networks and Fog Networks. IEEE Access 2015, 3, 3019–3034. [Google Scholar] [CrossRef]
- Aggarwal, C.; Wolf, J.L.; Yu, P.S. Caching on the world wide Web. IEEE Trans. Knowl. Data Eng. 1999, 11, 94–107. [Google Scholar] [CrossRef] [Green Version]
- Ahlehagh, H.; Dey, S. Video caching in radio access network: Impact on delay and capacity. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 2276–2281. [Google Scholar]
- Wang, X.; Chen, M.; Taleb, T.; Ksentini, A.; Leung, V.C.M. Cache in the air: Exploiting content caching and delivery techniques for 5G systems. IEEE Commun. Mag. 2014, 52, 131–139. [Google Scholar] [CrossRef]
- Müller, S.; Atan, O.; van der Schaar, M.; Klein, A. Smart caching in wireless small cell networks via contextual multi-armed bandits. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–7. [Google Scholar]
- Song, J.; Sheng, M.; Quek, T.Q.S.; Xu, C.; Wang, X. Learning-Based Content Caching and Sharing for Wireless Networks. IEEE Trans. Commun. 2017, 65, 4309–4324. [Google Scholar] [CrossRef]
- Jiang, W.; Feng, G.; Qin, S.; Yum, T.S.P.; Cao, G. Multi-Agent Reinforcement Learning for Efficient Content Caching in Mobile D2D Networks. IEEE Trans. Wirel. Commun. 2019, 18, 1610–1622. [Google Scholar] [CrossRef]
- Muller, S.; Atan, O.; van der Schaar, M.; Klein, A. Context-Aware Proactive Content Caching With Service Differentiation in Wireless Networks. IEEE Trans. Wirel. Commun. 2017, 16, 1024–1036. [Google Scholar] [CrossRef]
- Abboud, A.; Baştuğ, E.; Hamidouche, K.; Debbah, M. Distributed caching in 5G networks: An Alternating Direction Method of Multipliers approach. In Proceedings of the 2015 IEEE 16th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Stockholm, Sweden, 28 June–1 July 2015; pp. 171–175. [Google Scholar]
- Hassine, N.B.; Milocco, R.; Minet, P. ARMA based popularity prediction for caching in Content Delivery Networks. In Proceedings of the 2017 Wireless Days, Porto, Portugal, 29–31 March 2017; pp. 113–120. [Google Scholar]
- Bastug, E.; Bennis, M.; Debbah, M. Living on the edge: The role of proactive caching in 5g wireless networks. IEEE Commun. Mag. 2014, 52, 82–89. [Google Scholar] [CrossRef] [Green Version]
- Hou, T.; Feng, G.; Qin, S.; Jiang, W. Proactive Content Caching by Exploiting Transfer Learning for Mobile Edge Computing. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Tanzil, S.M.S.; Hoiles, W.; Krishnamurthy, V. Adaptive Scheme for Caching YouTube Content in a Cellular Network: Machine Learning Approach. IEEE Access 2017, 5, 5870–5881. [Google Scholar] [CrossRef]
- Yu, Z.; Hu, J.; Min, G.; Zhao, Z.; Miao, W.; Hossain, M.S. Mobility-Aware Proactive Edge Caching for Connected Vehicles Using Federated Learning. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Wang, X.; Wang, C.; Li, X.; Leung, V.C.M.; Taleb, T. Federated Deep Reinforcement Learning for Internet of Things With Decentralized Cooperative Edge Caching. IEEE Internet Things J. 2020, 7, 9441–9455. [Google Scholar] [CrossRef]
- Blasco, P.; Gündüz, D. Learning-based optimization of cache content in a small cell base station. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 1897–1903. [Google Scholar]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, E.C.H.; Zhou, L.; Wei, J.; Cheng, J.; Hu, B.; Leung, V.C.M. Joint Resource Allocation for Latency-Sensitive Services Over Mobile Edge Computing Networks With Caching. IEEE Internet Things J. 2019, 6, 4283–4294. [Google Scholar] [CrossRef]
- Golrezaei, N.; Shanmugam, K.; Dimakis, A.G.; Molisch, A.F.; Caire, G. FemtoCaching: Wireless video content delivery through distributed caching helpers. In Proceedings of the IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 1107–1115. [Google Scholar]
- Chen, B.; Yang, C. Caching policy optimization for D2D communications by learning user preference. In Proceedings of the 2017 IEEE 85th Vehicular Technology Conference (VTC Spring), Sydney, NSW, Australia, 4–7 June 2017; pp. 1–7. [Google Scholar]
- Leighton, T. Improving performance on the Internet. Commun. ACM 2009, 52, 44–51. [Google Scholar] [CrossRef] [Green Version]
- Kellerer, H.; Pferschy, U.; Pisinger, D. Knapsack Problems; Springer: Heidelberg, Germany, 2004. [Google Scholar]
- Li, X.; Wang, X.; Leung, V.C.M. Weighted network traffic offloading in cache-enabled heterogeneous networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 1–6. [Google Scholar]
- Harper, F.; Konstan, J. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 12. [Google Scholar] [CrossRef]
- Li, S.; Xu, J.; van der Schaar, M.; Li, W. Popularity-driven content caching. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | [23,24,25] | [26] | [27,28] | [29] | [30] | [31] | This Work |
|---|---|---|---|---|---|---|---|
| Online/Offline-Learning | Online | Online | Online | Offline | Offline | Offline | Online |
| High Computational | Yes | Yes | Yes | Yes | No | Yes | No |
| Accuracy | No | Yes | Yes | No | No | No | Yes |
| Real-Time | No | No | No | No | No | No | Yes |
| Privacy Protection | No | No | No | No | No | No | Yes |
| Notation | Definition |
|---|---|
| Set of F-APs | |
| N | Number of F-APs |
| Set of mobile users | |
| U | Number of mobile users |
| C | Storage budget of F-APs |
| Library of popular contents | |
| F | Total number of contents |
| Size of content f | |
| Global content popularity | |
| The skewness factor of Zipf | |
| Local content popularity | |
| The storage capacity of F-AP n | |
| A binary content cache matrix | |
| Content cache decisions | |
| Local dataset | |
| Learning rate | |
| Local parameter vector | |
| ,, | The traffic cost of wireless link, Fog-Fog link and fronthaul link, respectively |
| Parameter Name | Value |
|---|---|
| Number of F-APs | N = 30 |
| Number of users | U = 1000 |
| The traffic cost of wireless link | MB |
| The traffic cost of Fog-Fog link | MB |
| The traffic cost of fronthaul link | MB |
| The total storage budgets of F-APs | MB |
| The average content size | MB |
| Zipf distribution skewness parameter |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, T.; Cui, T.; Islam, S.M.R.; Chen, Q. Joint Content Placement and Storage Allocation Based on Federated Learning in F-RANs. Sensors 2021, 21, 215. https://doi.org/10.3390/s21010215
Xiao T, Cui T, Islam SMR, Chen Q. Joint Content Placement and Storage Allocation Based on Federated Learning in F-RANs. Sensors. 2021; 21(1):215. https://doi.org/10.3390/s21010215
Chicago/Turabian StyleXiao, Tuo, Taiping Cui, S. M. Riazul Islam, and Qianbin Chen. 2021. "Joint Content Placement and Storage Allocation Based on Federated Learning in F-RANs" Sensors 21, no. 1: 215. https://doi.org/10.3390/s21010215
APA StyleXiao, T., Cui, T., Islam, S. M. R., & Chen, Q. (2021). Joint Content Placement and Storage Allocation Based on Federated Learning in F-RANs. Sensors, 21(1), 215. https://doi.org/10.3390/s21010215