On the Effect of Training Convolution Neural Network for Millimeter-Wave Radar-Based Hand Gesture Recognition


Abstract
:1. Introduction
2. Parameterized Representation of Dynamic Hand Gestures
2.1. Dataset Collection
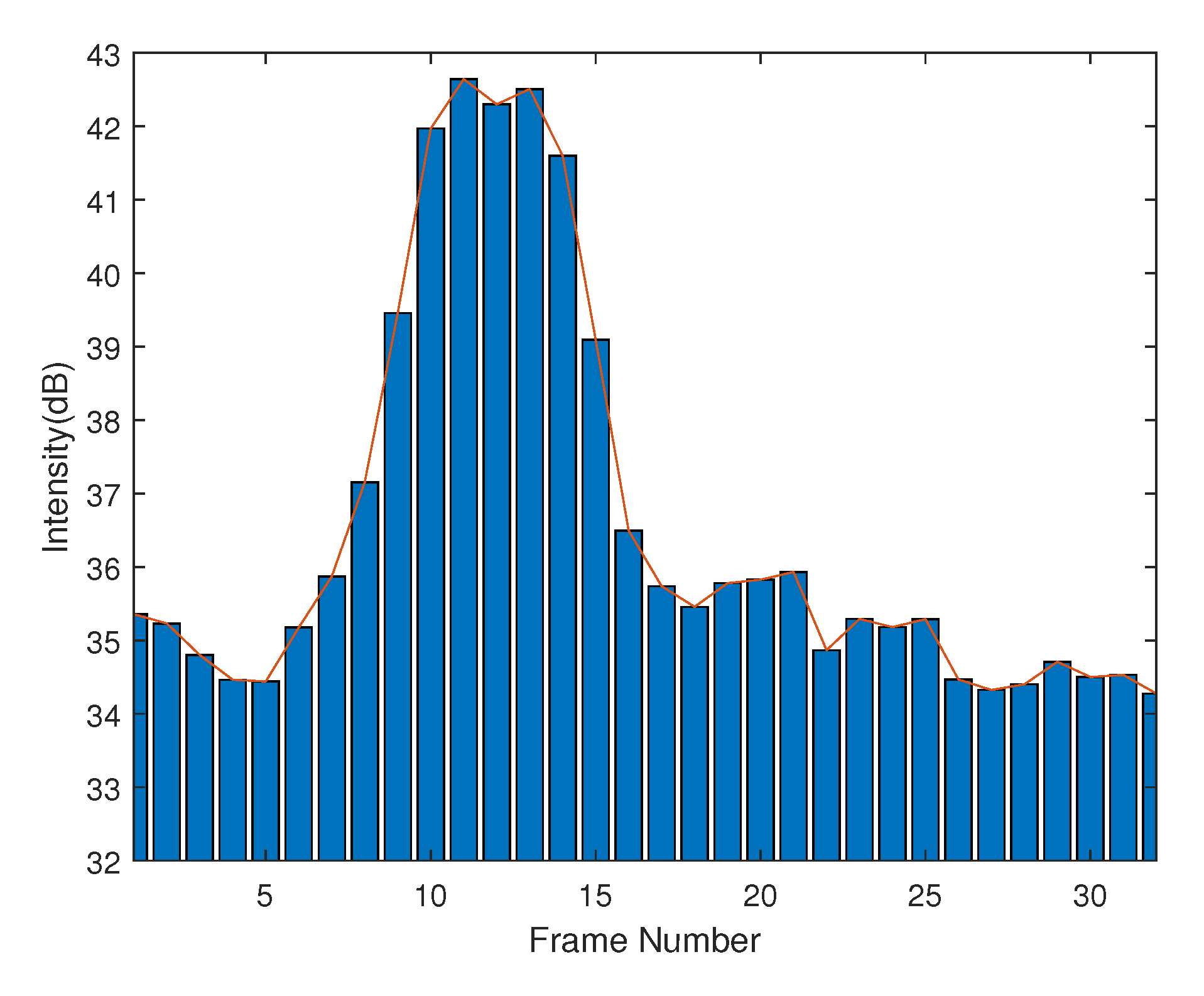
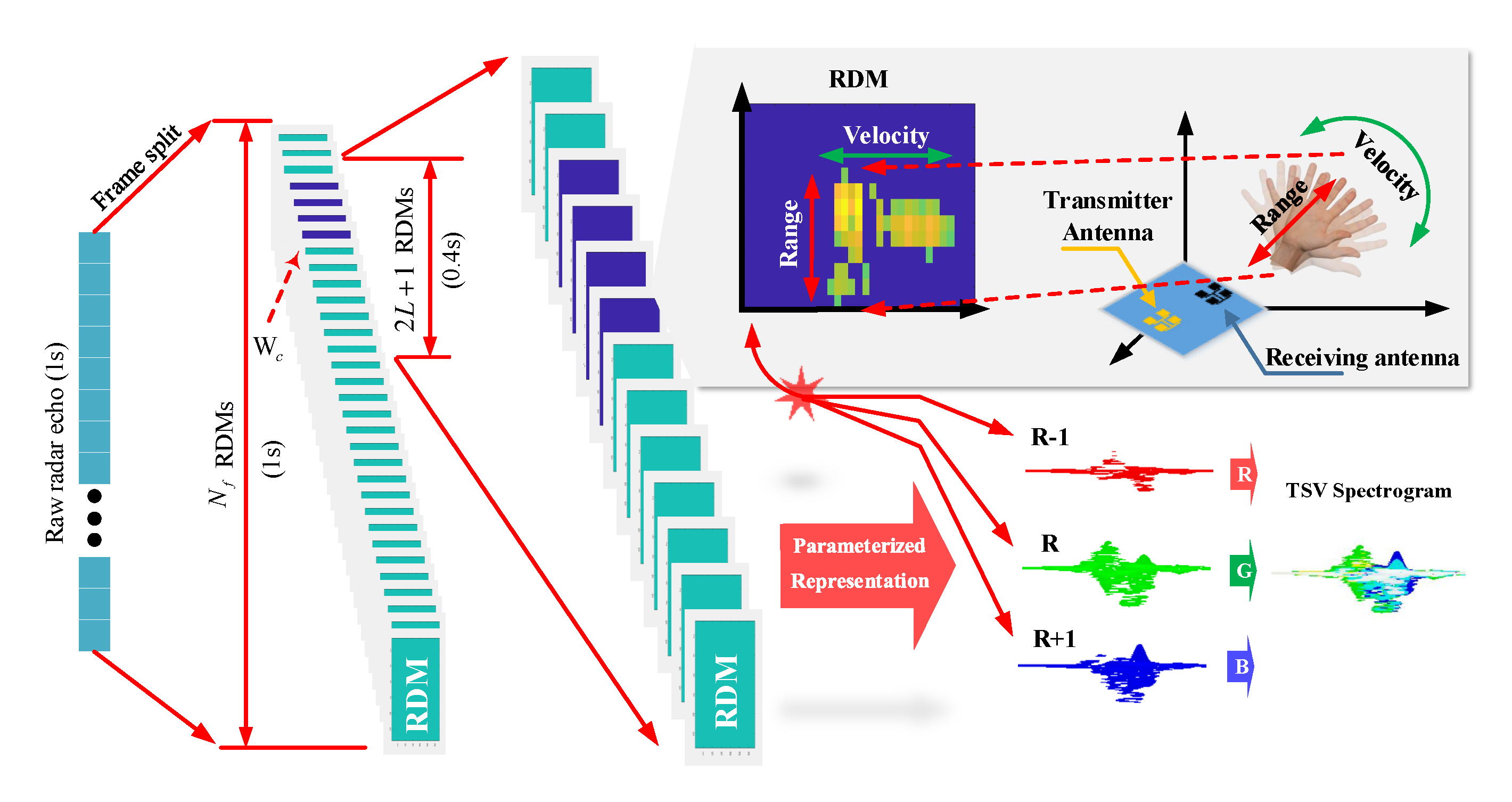
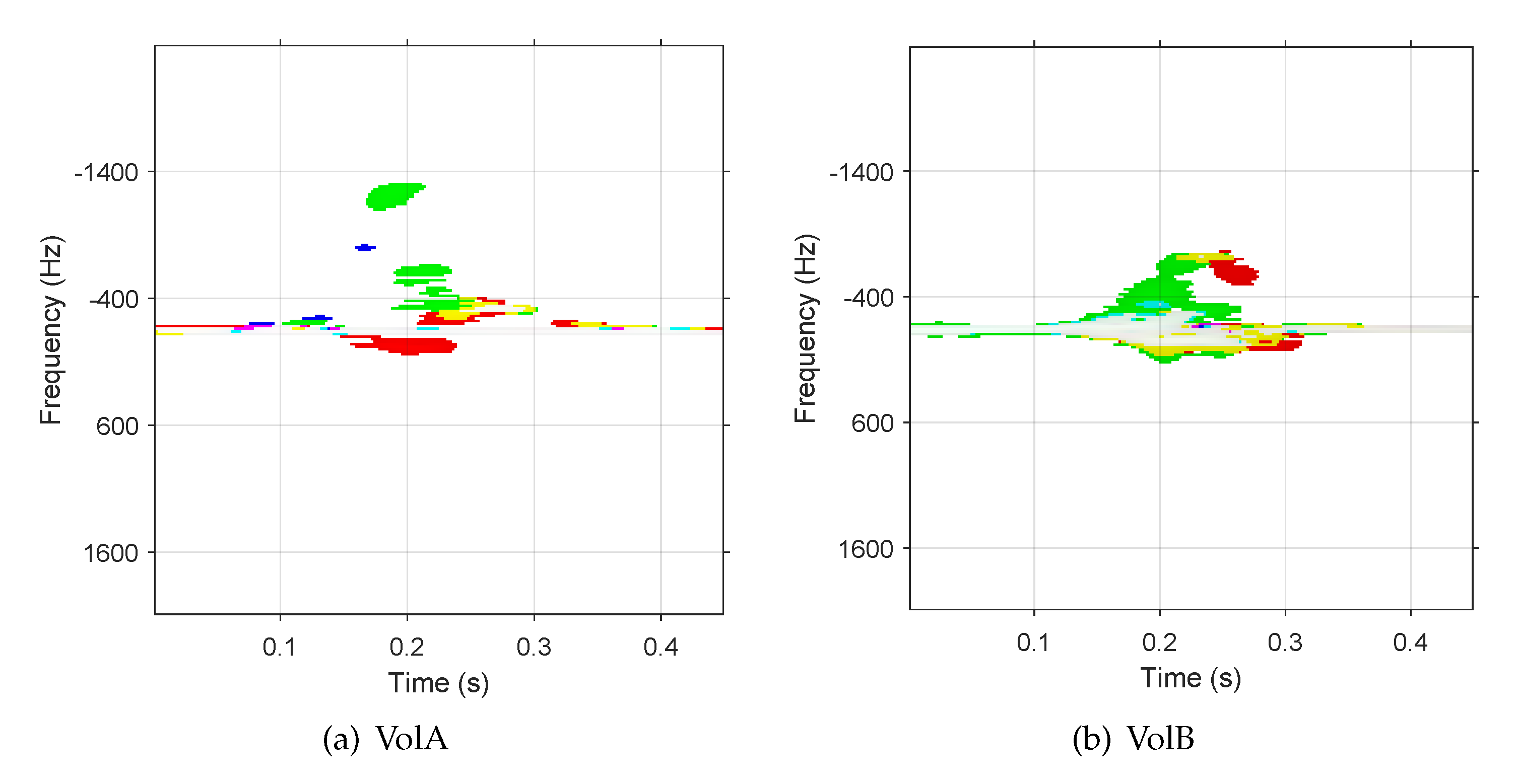
2.2. Temporal Space-Velocity Spectrograms
3. Transfer Learning for Mr-Hgr
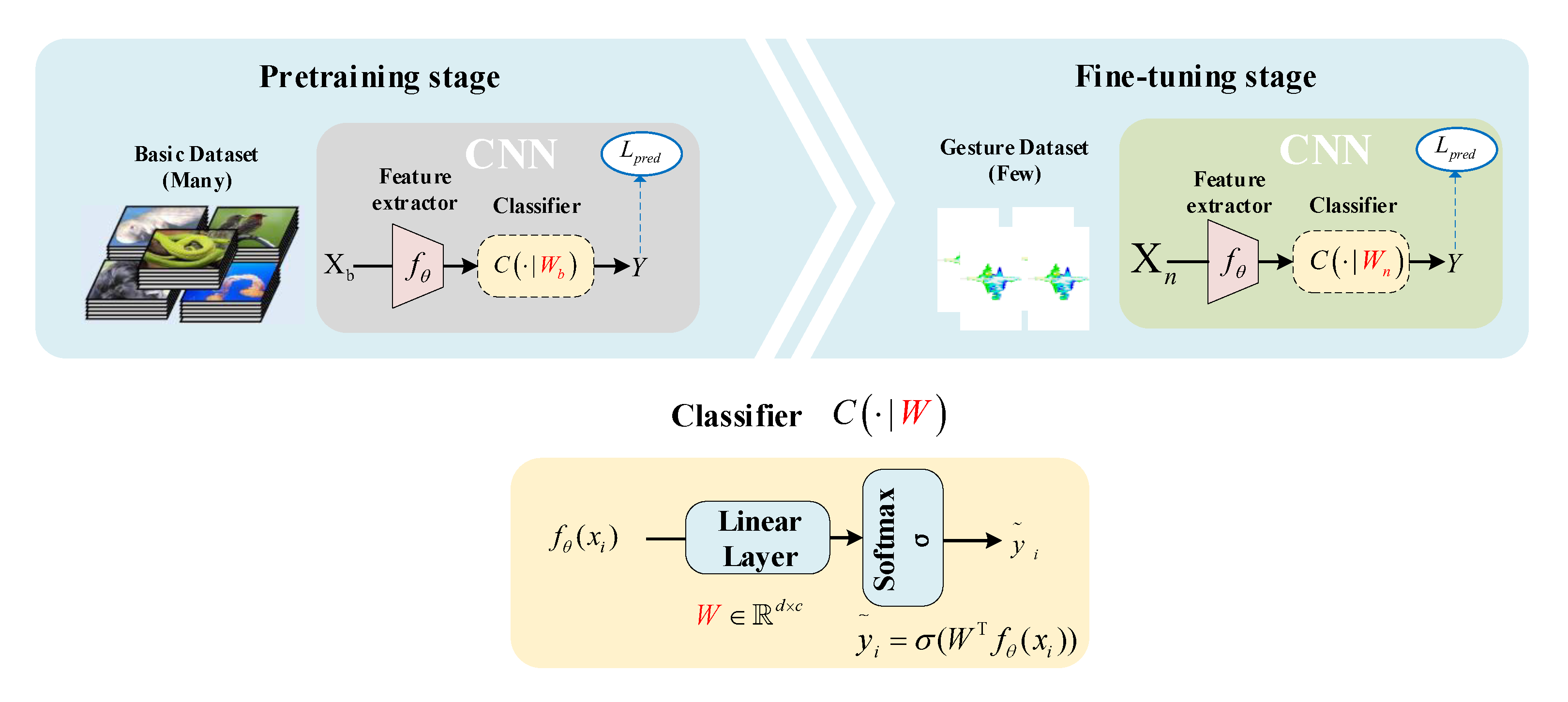
3.1. Pretraining and Fine-Tuning
3.2. Customization of State-of-the-Art CNN Models for Fine-Tuning
3.2.1. ResNet
3.2.2. DenseNet
3.2.3. MobileNet
3.2.4. ShuffleNet
4. Experiment Results and Discussions
4.1. Hardware Setup
4.2. Training Setup
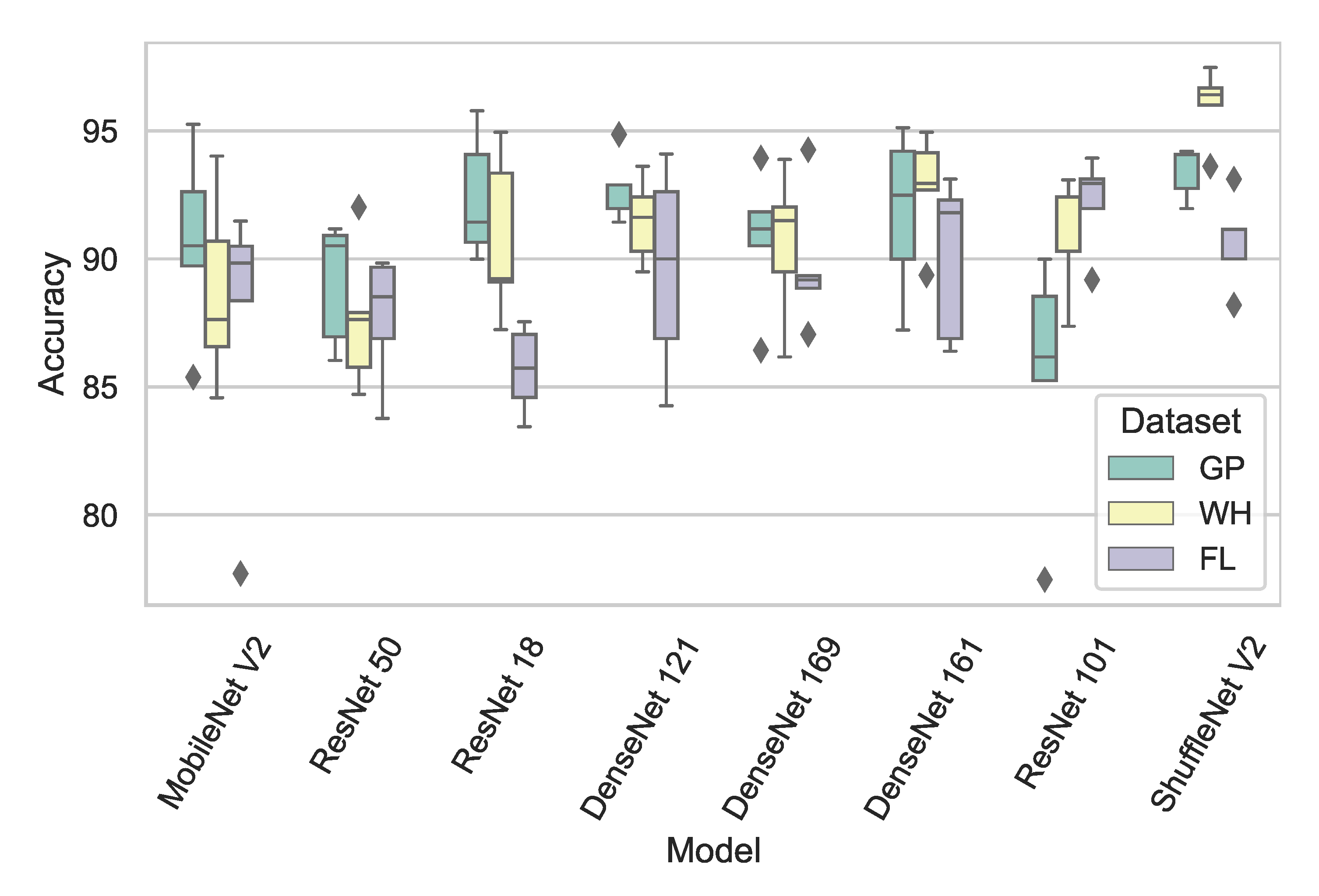
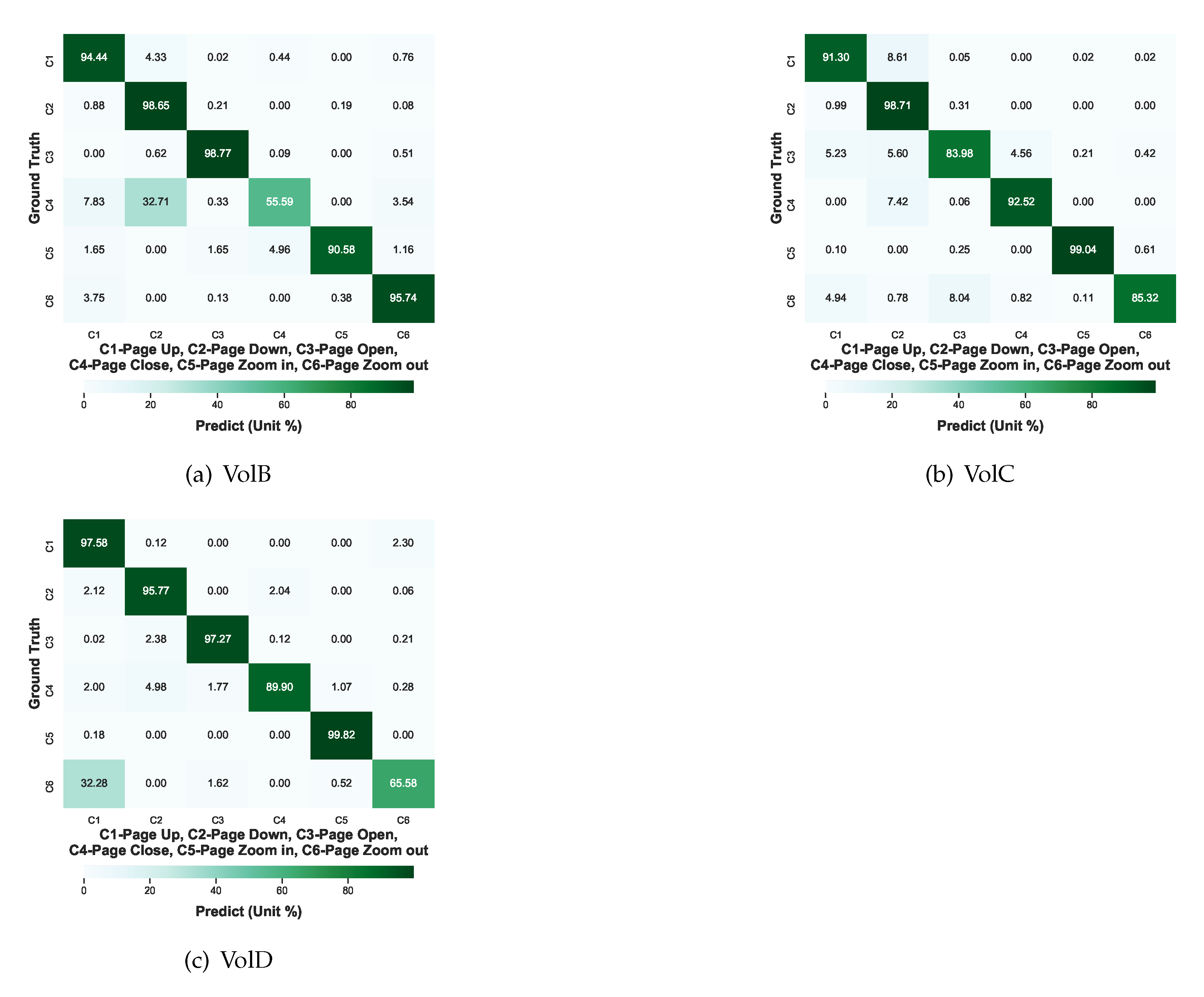
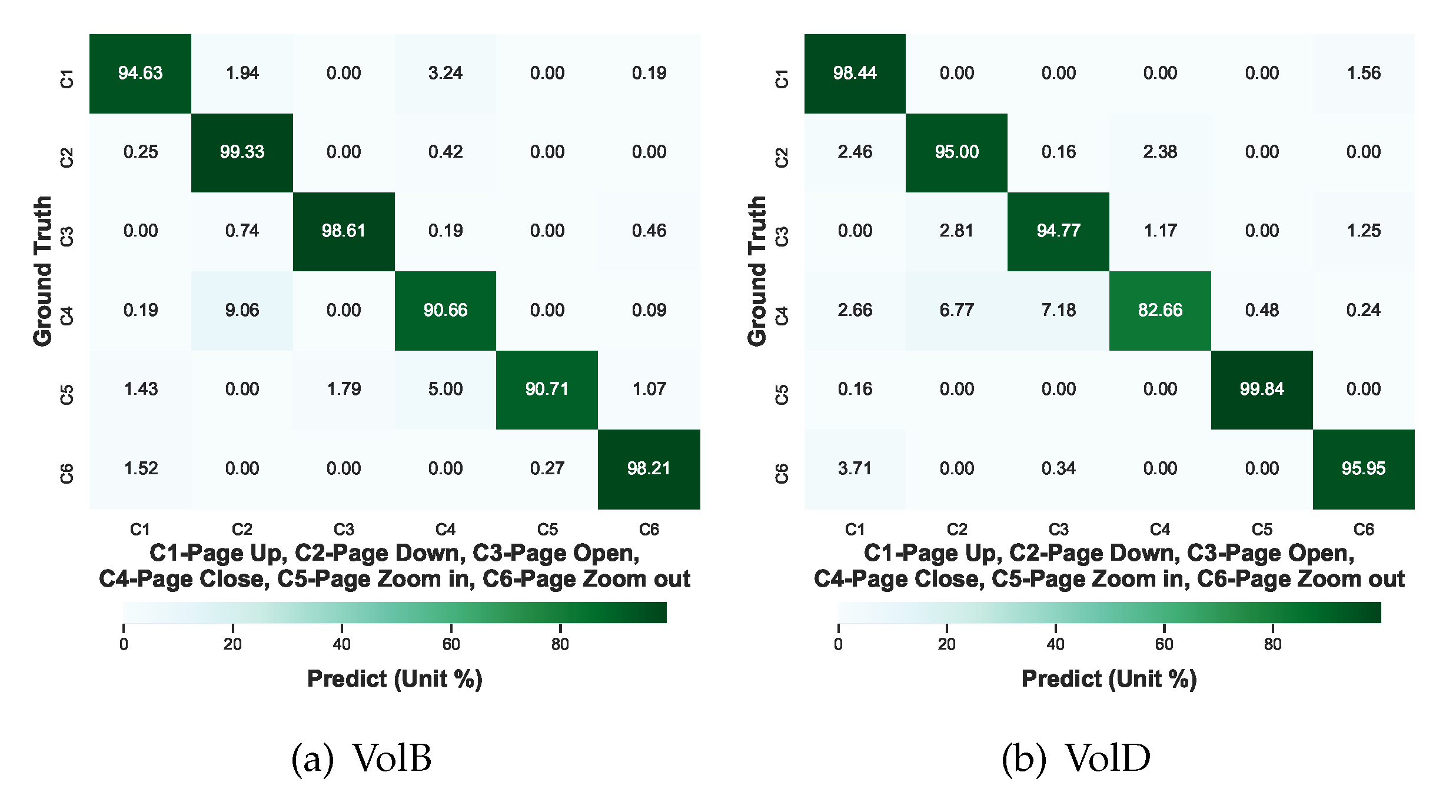
4.3. Test Results and Analysis
4.3.1. Baseline Test
4.3.2. Fine-Tuning Test
4.3.3. Enriching Test
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A Framework for Hand Gesture Recognition Based on Accelerometer and EMG Sensors. IEEE Trans. Syst. Man Cybern. Part Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Pławiak, P.; Sośnicki, T.; Niedźwiecki, M.; Tabor, Z.; Rzecki, K. Hand Body Language Gesture Recognition Based on Signals From Specialized Glove and Machine Learning Algorithms. IEEE Trans. Ind. Inform. 2016, 12, 1104–1113. [Google Scholar] [CrossRef]
- Lien, J.; Gillian, N.; Karagozler, M.E.; Amihood, P.; Schwesig, C.; Olson, E.; Raja, H.; Poupyrev, I. Soli: Ubiquitous gesture sensing with millimeter wave radar. ACM Trans. Graph. (TOG) 2016, 35, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Song, J.; Lien, J.; Poupyrev, I.; Hilliges, O. Interacting with soli: Exploring fine-grained dynamic gesture recognition in the radio-frequency spectrum. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 851–860. [Google Scholar]
- Zhang, X.; Wu, Q.; Zhao, D. Dynamic Hand Gesture Recognition Using FMCW Radar Sensor for Driving Assistance. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Zhejiang, China, 18–20 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Suh, J.S.; Ryu, S.; Han, B.; Choi, J.; Kim, J.; Hong, S. 24 GHz FMCW Radar System for Real-Time Hand Gesture Recognition Using LSTM. In Proceedings of the 2018 Asia-Pacific Microwave Conference (APMC), Kyoto, Japan, 6–9 November 2018; pp. 860–862. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, Z.; Zhou, M. Latern: Dynamic continuous hand gesture recognition using FMCW radar sensor. IEEE Sens. J. 2018, 18, 3278–3289. [Google Scholar] [CrossRef]
- Kim, Y.; Toomajian, B. Hand gesture recognition using micro-Doppler signatures with convolutional neural network. IEEE Access 2016, 4, 7125–7130. [Google Scholar] [CrossRef]
- Skaria, S.; Al-Hourani, A.; Lech, M.; Evans, R.J. Hand-Gesture Recognition Using Two-Antenna Doppler Radar With Deep Convolutional Neural Networks. IEEE Sens. J. 2019, 19, 3041–3048. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, Z.; Zhang, Y.; Zhou, M.; Wang, B. u-DeepHand: FMCW radar-based unsupervised hand gesture feature learning using deep convolutional auto-encoder network. IEEE Sens. J. 2019, 19, 6811–6821. [Google Scholar] [CrossRef]
- Gurbuz, S.Z.; Gurbuz, A.C.; Malaia, E.A.; Griffin, D.J.; Crawford, C.; Rahman, M.M.; Aksu, R.; Kurtoglu, E.; Mdrafi, R.; Anbuselvam, A.; et al. A Linguistic Perspective on Radar Micro-Doppler Analysis of American Sign Language. In Proceedings of the 2020 IEEE International Radar Conference (RADAR), Washington, DC, USA, 27 April–1 May 2020; pp. 232–237. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks, Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling., M., Eds.; Springer: Berlin/Heidelberg, Germany; pp. 630–645.
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), HI, Hawaii, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Sakamoto, T.; Gao, X.; Yavari, E.; Rahman, A.; Boric-Lubecke, O.; Lubecke, V.M. Radar-based hand gesture recognition using I-Q echo plot and convolutional neural network. In Proceedings of the 2017 IEEE Conference on Antenna Measurements Applications (CAMA), Tsukuba, Ibaraki, Japan, 4–6 December 2017; pp. 393–395. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. arXiv 2019, arXiv:1904.04232. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Volunteer Info | Name | VolA | VolB | VolC | VolD |
| Age | 22 | 21 | 21 | 23 | |
| Height/cm | 170 | 165 | 178 | 179 | |
| Gender | M | F | M | M | |
| Sample number per gesture category | Page-up | 200 | 128 | 128 | 128 |
| Page-down | 200 | 128 | 128 | 128 | |
| Page-open | 200 | 128 | 128 | 128 | |
| Page-close | 200 | 128 | 128 | 128 | |
| Page-zoom-in | 200 | 128 | 128 | 128 | |
| Page-zoom-out | 200 | 128 | 128 | 128 |
| Model | Baseline | Fine-Tuning | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Name | Param | CT | ST | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | CT | ST |
| ResNet 18 | 11.69 | 83.88 | 98.67 | 94.67 | 90.00 | 92.27 | 91.75 | 90.15 | 91.77 | 100.00 |
| ResNet 50 | 25.55 | 72.18 | 98.67 | 84.91 | 89.25 | 87.79 | 89.39 | 89.58 | 88.18 | 99.83 |
| ResNet 101 | 50.00 | 62.85 | 99.33 | 89.86 | 89.86 | 81.05 | 89.11 | 90.52 | 88.08 | 100.00 |
| DenseNet 121 | 7.89 | 79.54 | 100.00 | 91.04 | 92.08 | 91.70 | 92.69 | 89.77 | 91.46 | 99.58 |
| DenseNet 169 | 14.15 | 78.50 | 97.00 | 91.94 | 87.93 | 88.45 | 91.23 | 92.31 | 90.37 | 100.00 |
| DenseNet 161 | 28.68 | 82.37 | 99.67 | 93.68 | 92.36 | 87.74 | 92.60 | 91.98 | 91.67 | 100.00 |
| MobileNet V2 | 3.51 | 73.88 | 100.00 | 91.51 | 91.42 | 87.79 | 85.24 | 86.75 | 88.54 | 99.83 |
| ShuffleNet V2 | 1.37 | 85.34 | 99.33 | 94.48 | 93.16 | 93.92 | 92.98 | 92.83 | 93.47 | 100.00 |
| Classifier | Volunteer Number | Gesture Types | Self-Testing Accuracy | Cross-Testing Accuracy | Params (M) | Training Examples | Testing Examples |
|---|---|---|---|---|---|---|---|
| CNN + LSTM [4] | 10 | 11 | 87 | - | 689 | 1375 | 1375 |
| CNN + LSTM [6] | - | 7 | 91 | - | <1 | 840 | 1960 |
| CNN+LSTM+CTC [7] | 4 | 8 | 96 | - | 6 | 3200 | 400 |
| 3 layer DCNN [8] | - | 8 | 85.6 | - | <1 | 450 | 50 |
| 3 layer DCNN [9] | 2 | 14 | 92.9 | 48.36 | <1 | 1792 | 448 |
| u-DeepHand [10] | 4 | 8 | 95 | - | 29.2 | 2000 | 500 |
| CNN [19] | - | 3 | 96.6 | - | <<1 | 60 | 27 |
| LeNet [5] | - | 9 | 94.4 | - | 1.6 | 360 | 40 |
| Ours(ResNet 18) | 4 | 6 | 100.00 | 91.77 | 11.69 | 960 | 2124 |
| Ours(ShuffleNet V2) | 4 | 6 | 100.00 | 93.47 | 1.37 | 960 | 2124 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Lan, S.; Zhang, G. On the Effect of Training Convolution Neural Network for Millimeter-Wave Radar-Based Hand Gesture Recognition. Sensors 2021, 21, 259. https://doi.org/10.3390/s21010259
Zhang K, Lan S, Zhang G. On the Effect of Training Convolution Neural Network for Millimeter-Wave Radar-Based Hand Gesture Recognition. Sensors. 2021; 21(1):259. https://doi.org/10.3390/s21010259
Chicago/Turabian StyleZhang, Kang, Shengchang Lan, and Guiyuan Zhang. 2021. "On the Effect of Training Convolution Neural Network for Millimeter-Wave Radar-Based Hand Gesture Recognition" Sensors 21, no. 1: 259. https://doi.org/10.3390/s21010259
APA StyleZhang, K., Lan, S., & Zhang, G. (2021). On the Effect of Training Convolution Neural Network for Millimeter-Wave Radar-Based Hand Gesture Recognition. Sensors, 21(1), 259. https://doi.org/10.3390/s21010259