1. Introduction
Sign language is the most important way of communication between hearing-impaired people. It plays an irreplaceable role in the hearing-impaired community, but most normal people cannot understand it. Therefore, research on automatic sign language recognition algorithms will help build a bridge of communication between hearing-impaired people and others, which will greatly facilitate the life of hearing-impaired people. Sign language mainly conveys semantic information through hand shapes, motion trajectory, facial expressions, lip movements, and eye contact, etc. It is usually composed of one or more gestures, movements, and transitions between them. A slight change in one of these components may lead to another completely different meaning.
According to different data modalities, sign language recognition can be divided into sensor-based and vision-based methods. Some researchers use sensors such as EMU, data gloves or IMUs to recognize sign language. Zhang et al. [
1] combined 3-axis accelerometer signals and the 5-channel EMG signal on the user’s hand to recognize 72 sign language words with 93.1% accuracy. The sensor-based methods have fast recognition speed and high accuracy, but it is inconvenient for signers to wear sensors for the following reasons: (1) the users have to take the electronic devices with them, which could be a burden for people; (2) all the portable electronic devices need batteries that have to be charged frequently; (3) signals from the wearable devices can only be processed by the specific equipment instead of commonly used cameras. In contrast, vision-based methods have the advantages of low cost and convenience, and the users do not have to take anything with them, just need to “say” the words in front of a common cameras, and the others can understand what they’re expressing. For example, setting up vision-based sign language translators at ticket counters and bank counters could greatly facilitate the daily life of hearing-impaired people. Therefore, vision-based methods have become the main research direction of sign language recognition. However, there are still several problems in vision-based sign language recognition:
low recognition efficiency caused by too much redundant information.
poor recognition accuracy caused by finger occlusion and motion blurring.
poor generalization of algorithms caused by differences in signing style between sign language speakers.
small recognizable vocabulary caused by the existence of similar words in large vocabulary datasets.
In this work, we propose an attention-enhanced multi-scale and dual Sign Language Recognition Network based on Graph Convolution Network (GCN), which is capable if matching the performance of the state-of-the-art on two large Chinese sign language datasets. A large body of work has been proposed for sign language recognition (SLR) [
2,
3]. Before 2016, the traditional sign language recognition technology based on vision has been studied extensively, see [
4] for details. Traditional sign language recognition methods are complex to implement, and can only recognize limited vocabularies, which cannot fully express human’s intelligent understanding of sign language. In recent years, deep learning technology has greatly exceeded the performance of manual features in many computer vision tasks and therefore has become a new method for sign language recognition.
Many vision-based methods have used video RGB data for sign language vocabulary recognition. Vincent et al. [
5] combined a Convolutional Neural Network (CNN) and a Long Short-Term Memory Network (LSTM) for the recognition of American Sign Language words, and used data enhancement techniques such as scaling and smoothing to improve the generalization of the network. Huang et al. [
6] proposed a 3D-CNN network based on spatiotemporal attention mechanism for large vocabulary sign language recognition.
Some research works have used depth images, skeleton data, optical flow, and other different modal data for identification. Duan et al. [
7] combined RGB data, depth images, and optical flow to recognize isolated gestures. They provided a convolutional two-stream consensus voting network (2SCVN) to explicitly model the short-term and long-term structure of the RGB sequences. To reduce the interference of complex backgrounds, a 3d depth-saliency convolution network (3DDSN) is used in parallel to extract motion features. The two networks, 2SCVN and 3DDSN, have been integrated into a framework to improve recognition accuracy. Huang et al. [
8] proposed a deep sign language recognition model using a 3D CNN from multi-modal input (including RGB, depth, and skeleton data) to improve recognition accuracy. They verified the model’s effectiveness on their dataset and reported a recognition accuracy of 94.2%.
Recognition algorithms based on multi-modal data can extract various features of different modal data, and while improving accuracy, they also greatly increase the computational complexity. With the development of human pose estimation technology, we can extract the skeleton data of the body and hands from a single RGB frame [
9,
10]. Compared with other modal sign language data, skeleton data reduces a lot of redundant information and is more robust to lighting and scene changes.
In sign language recognition, there have been two methods to extract skeleton data features in the past. One is to map the skeleton data to the image and use a CNN for processing. For example, Devineau et al. [
11] proposed a CNN algorithm based on hand skeleton data for the recognition of three-dimensional dynamic gestures, using parallel convolution to process the position sequence of hand joints, and achieved high recognition accuracy. The other method is to use the Recurrent Neural Network (RNN) to recognize the skeleton data. For instance, Konstantinidis et al. [
12] used the multi-stream LSTM algorithm to recognize an Argentine sign language dataset (LSA64). However, neither RNNs nor CNNs can fully represent the structure of skeleton data, because skeleton data is natural graph data, not sequences data or European data. Yan et al. [
13] first applied a graph convolution network (GCN) to model skeletal data for the field of action recognition. The model they developed which aims to use body skeleton data to recognize some daily actions like sit up, bowing, etc., is named ST-GCN. After that, various GCN algorithms for action recognition have been proposed. Shi et al. [
14] proposed an adaptive algorithm to construct graph data, and alternately used spatial convolution and temporal convolution to learn spatial and temporal features. Liu et al. [
15] proposed the MS-G3D network to learn different levels of semantic information by using multiple parallel GCN networks, which inspired us. Si et al. [
16] used GCN to learn the spatial features of each frame separately and then used LSTM to learn the temporal features to recognize actions. Although these algorithms have achieved great success in the field of action recognition, there are still many demerits in applying them to the task of sign language recognition:
(1) The graph structure is fixed and is constructed through the natural connection of human bones, which may not be suitable for SLR. For example, in many sign language vocabularies, the relationship between the left and right fingers is significant, but in natural connection, their distances are too long to allow GCN to learn the dependencies between the joints over such long distances. (2) The above methods learned spatial and temporal features separately, so that the complex spatiotemporal features in sign language cannot be learned. (3) Due to the phenomenon of figure occlusion, some hand joints are difficult to accurately identify, and these occluded joints are not so important for recognizing this word. If they are treated equally, this can easily cause misjudgments. (4) The temporal dependences of sign language are longer than that of actions. This includes sign language actions and transition actions. The former are the key to recognition, while transition actions are interference. The above algorithms treat sign language movements and transition movements equally. Moreover, there are motion blur frames in sign language videos, which makes it difficult to accurately extract the joint points of this frame, which seriously affects the subsequent recognition accuracy.
To address these shortcomings, we proposed our method based on the following hypotheses: (1) a human’s head, arms and hands can clearly express the sign language information, which can be analyzed and processed using mathematical graph theory; (2) it is better to use spatiotemporal features from the video frames than spatial or temporal features separately; (3) although there are a lot of frames in the sign language video, we believe that not all the frames play the same roles, and attention mechanism and key frames technique can improve the accuracy and speed of the algorithm.
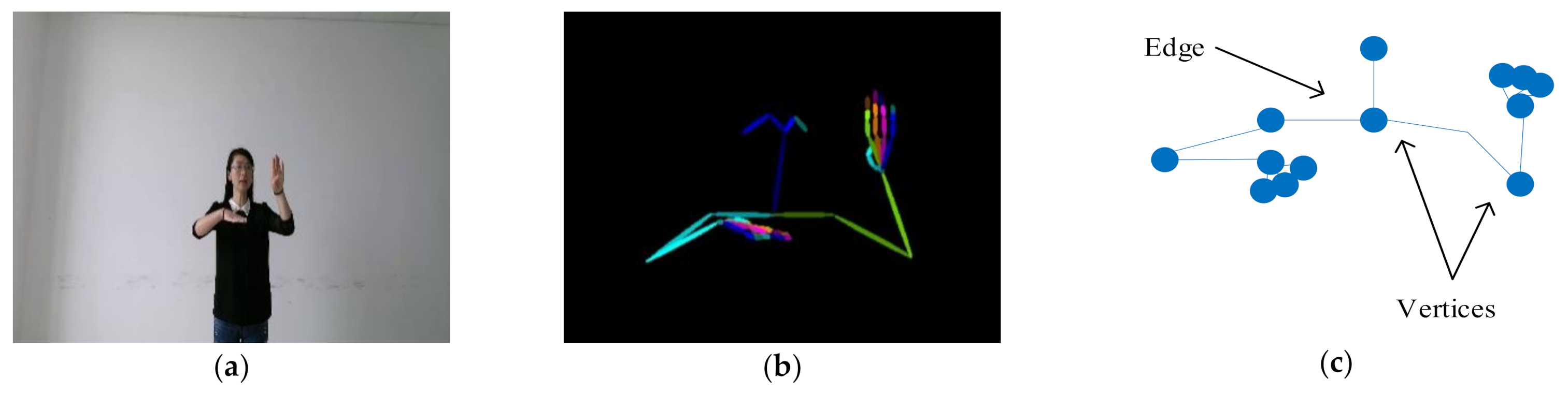
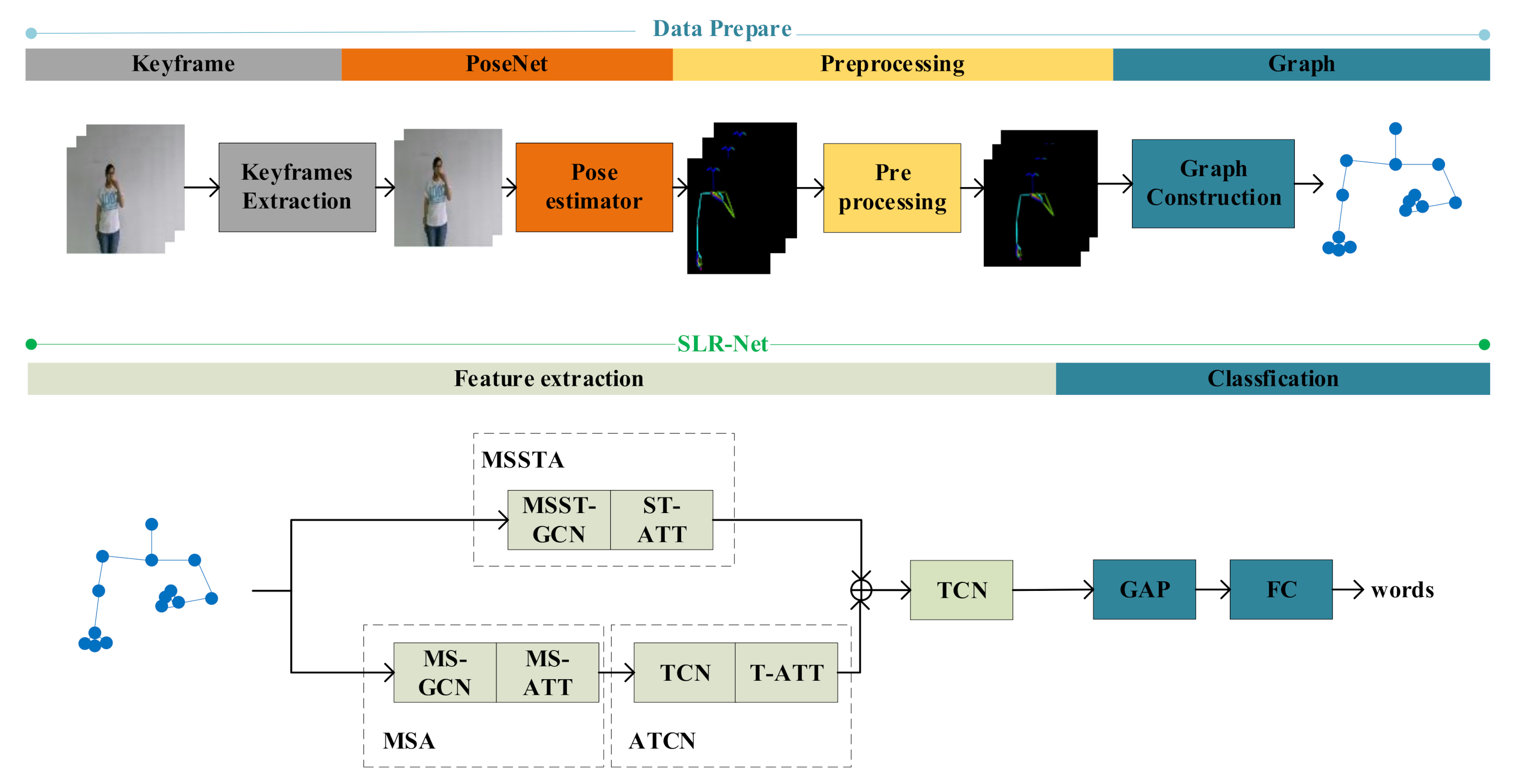
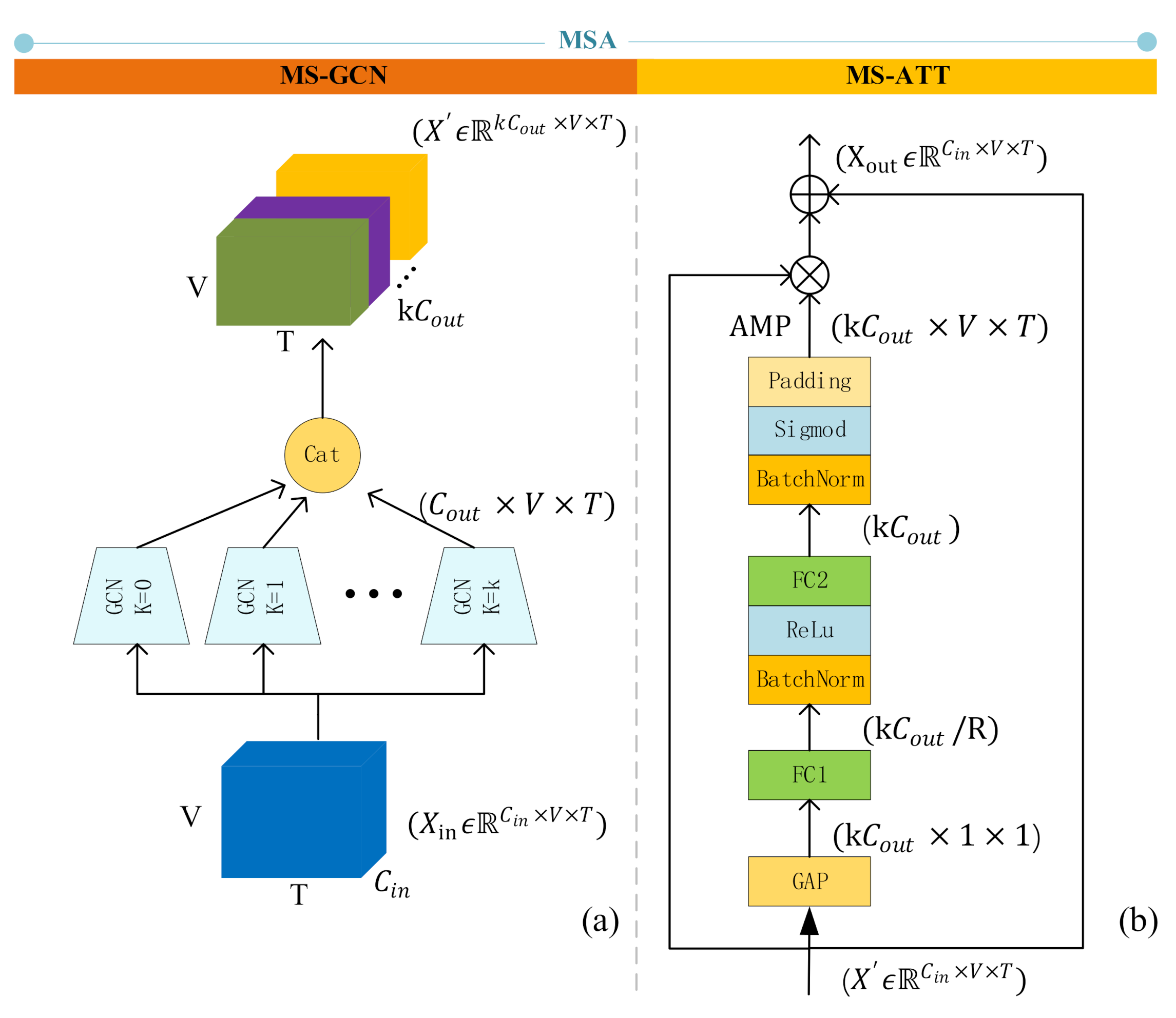
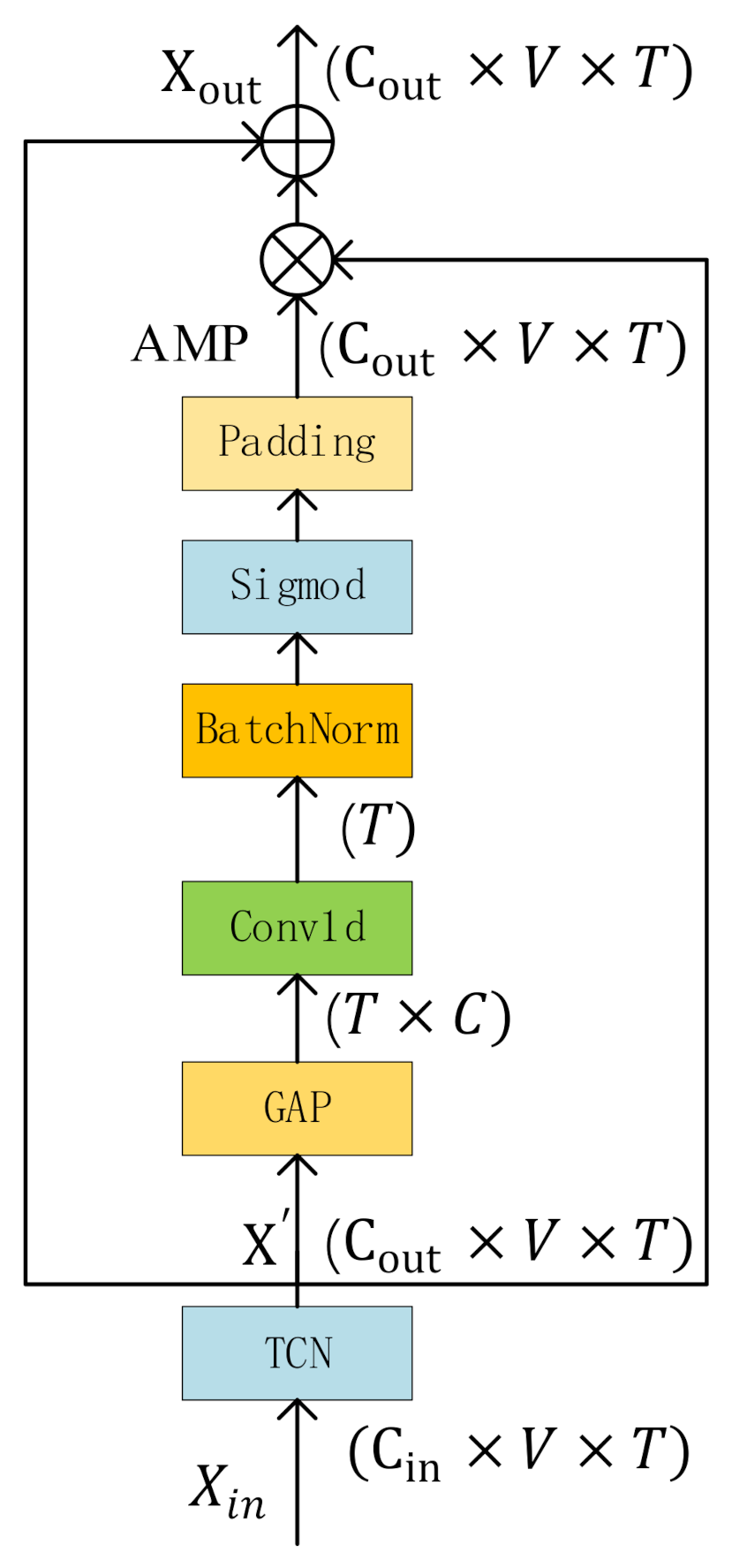
In this work, we first extracted the skeleton data of the body, hands, and part of the face from the RGB images based on the works of [
9,
10]. The original skeleton data is normalized to eliminate the differences in height and body shape of different sign language speakers. We applied the GCN algorithm to sign language recognition tasks for the first time and proposed a multi-scale attention network (MSA) to learn the long-distance dependencies, which can model the dependencies between remote vertices without considering the distance. We also proposed a multi-scale spatiotemporal attention network (MSSTA) to learn the complex spatiotemporal dependencies in sign language. Aiming at the problem of long-temporal dependencies in sign language and inaccurate recognition of motion blur frame joints, we proposed an attention enhanced temporal convolutional network, which can automatically assign different weights to different frames, thereby improving the recognition accuracy. For example, blurry motion frames are often not helpful for vocabulary recognition, so under the action of temporal attention, the weight of the blurred frame should be minimal, thereby improving the robustness of the algorithm. Finally, two-stream network integration of joints and bone data is used to improve performance. Besides, we also proposed a keyframe detection algorithm, which can significantly improve the practice of the algorithm while maintaining high recognition accuracy.
In summary, the main contributions of our work are: (1) Estimate the skeleton data of the body, hands, and part of the face from the RGB data, and mormalize the original skeleton data to eliminate the differences in height and body shape caused by different sign speakers. (2) We used the GCN algorithm to isolate sign language recognition for the first time, which provides a new idea for sign language recognition. We designed the SLR-Net network, which allows the GCN network to directly learn the spatiotemporal features and the dependencies between long-distance vertices. (3) We proposed three attention mechanisms based on SLR-Net to further improve the robustness and accuracy of the algorithm. (4) We proposed a keyframe extraction algorithm, which can greatly improve recognition efficiency while maintaining high recognition accuracy. (5) We conducted a lot of experiments on two large-vocabulary public sign language datasets and reached state of the art.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}